AWS의 자동화된 데이터 분석(ADA) 간단하고 직관적인 사용자 인터페이스를 통해 몇 분 만에 데이터에서 의미 있는 통찰력을 얻을 수 있는 AWS 솔루션입니다. ADA는 데이터 분석가가 다양한 사용 사례에 즉시 사용할 수 있는 AWS 기반 데이터 분석 플랫폼을 제공합니다. ADA를 사용하면 팀은 전문적인 기술 없이도 다양한 데이터 소스에서 다양한 데이터 세트를 수집, 변환, 관리 및 쿼리할 수 있습니다. ADA는 다음과 같은 세트를 제공합니다. 사전 제작된 커넥터 다음을 포함한 다양한 소스에서 데이터를 수집합니다. 아마존 단순 스토리지 서비스 (아마존 S3), Amazon Kinesis 데이터 스트림, 아마존 클라우드 워치, 아마존 클라우드트레일및 아마존 DynamoDB 뿐만 아니라 많은 다른 사람들.
ADA는 IT, 금융, 마케팅, 영업, 보안을 포함한 다양한 사용 사례에서 데이터 분석가가 사용할 수 있는 기본 플랫폼을 제공합니다. ADA의 기본 CloudWatch 데이터 커넥터를 사용하면 ADA가 배포된 동일한 AWS 계정의 CloudWatch 로그 또는 다른 AWS 계정에서 데이터를 수집할 수 있습니다.
이 게시물에서는 애플리케이션 개발자 또는 애플리케이션 테스터가 ADA를 사용하여 AWS에서 실행되는 애플리케이션의 운영 통찰력을 얻을 수 있는 방법을 보여줍니다. 또한 ADA 솔루션을 사용하여 AWS의 다양한 데이터 소스에 연결하는 방법도 보여줍니다. 우리가 먼저 ADA 솔루션 배포 AWS 계정에 ADA 솔루션 설정 창조함으로써 데이터 제품 데이터 커넥터를 사용합니다. 그런 다음 ADA Query Workbench를 사용하여 별도의 데이터 세트를 결합하고 친숙한 구조적 쿼리 언어(SQL)를 사용하여 상관 데이터를 쿼리하여 통찰력을 얻습니다. 또한 ADA를 Tableau와 같은 비즈니스 인텔리전스(BI) 도구와 통합하여 데이터를 시각화하고 보고서를 작성하는 방법을 보여줍니다.
솔루션 개요
이 섹션에서는 데모용 솔루션 아키텍처를 제시하고 워크플로를 설명합니다. 데모 목적으로 맞춤형 애플리케이션은 다음을 사용하여 시뮬레이션됩니다. AWS 람다 로그인을 내보내는 함수 Apache 로그 형식 미리 설정된 간격으로 아마존 이벤트 브리지. 이 표준 형식은 다양한 웹 서버에서 생성될 수 있으며 다양한 로그 분석 프로그램에서 읽을 수 있습니다. 애플리케이션(Lambda 함수) 로그는 CloudWatch 로그 그룹으로 전송됩니다. 기록 애플리케이션 로그는 참조 및 쿼리 목적으로 S3 버킷에 저장됩니다. 목록이 포함된 조회 테이블 HTTP 상태 코드 설명과 함께 DynamoDB 테이블에 저장됩니다. 이 세 가지는 상관 관계, 쿼리 및 분석을 위해 데이터가 ADA에 수집되는 소스 역할을 합니다. 우리 ADA 솔루션 배포 AWS 계정에 ADA 설정. 그런 다음 데이터 제품 ADA 내에서 CloudWatch 로그 그룹, S3 버킷및 DynamoDB. 데이터 제품이 구성되면 ADA는 소스에서 데이터를 수집하기 위해 데이터 파이프라인을 프로비저닝합니다. ADA Query Workbench를 사용하면 애플리케이션 문제 해결 또는 문제 진단을 위해 일반 SQL을 사용하여 수집된 데이터를 쿼리할 수 있습니다.
다음 다이어그램은 ADA를 사용하여 애플리케이션 로그에 대한 통찰력을 얻는 아키텍처 및 워크플로에 대한 개요를 제공합니다.
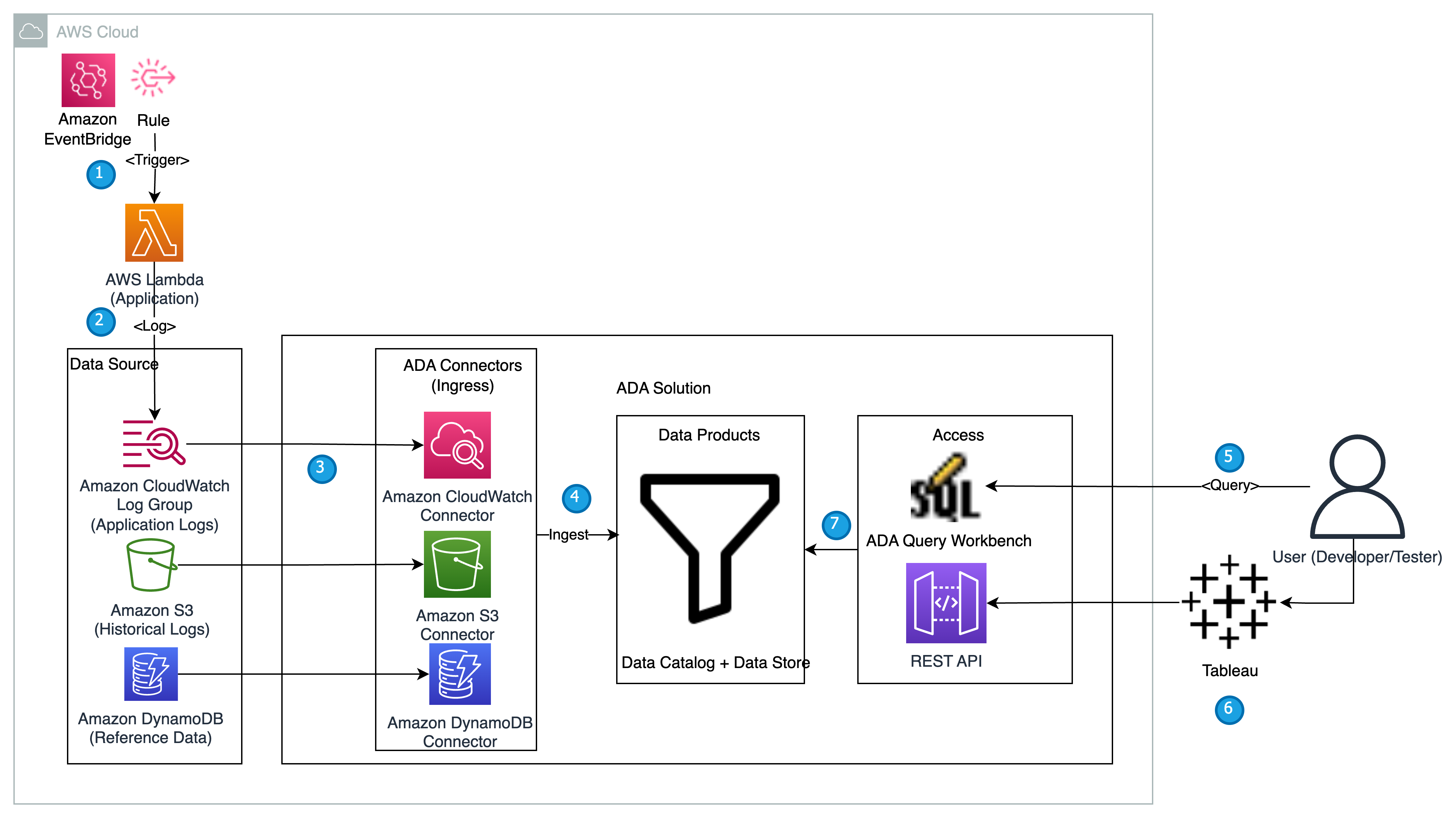
워크 플로우에는 다음 단계가 포함됩니다.
- Lambda 함수는 EventBridge를 사용하여 2분 간격으로 트리거되도록 예약되어 있습니다.
- Lambda 함수는 지정된 CloudWatch 로그 그룹에 저장된 로그를 내보냅니다.
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. 애플리케이션 로그는 Apache 로그 형식 스키마를 사용하여 생성되지만 JSON 형식으로 CloudWatch 로그 그룹에 저장됩니다. - CloudWatch, Amazon S3 및 DynamoDB용 데이터 제품은 ADA에서 생성됩니다. CloudWatch 데이터 제품은 애플리케이션(Lambda 함수) 로그가 저장되는 CloudWatch 로그 그룹에 연결됩니다. Amazon S3 커넥터는 기록 로그가 저장되는 S3 버킷 폴더에 연결됩니다. DynamoDB 커넥터는 애플리케이션에서 참조하는 상태 코드와 기록 로그가 저장되는 DynamoDB 테이블에 연결됩니다.
- 각 데이터 제품에 대해 ADA는 데이터 파이프라인 인프라를 배포하여 소스에서 데이터를 수집합니다. 데이터 수집이 완료되면 ADA Query Workbench를 통해 SQL을 사용하여 쿼리를 작성할 수 있습니다.
- ADA 포털에 로그인하고 Query Workbench에서 SQL 쿼리를 작성하여 애플리케이션 로그에 대한 통찰력을 얻을 수 있습니다. 선택적으로 쿼리를 저장하고 동일한 도메인의 다른 ADA 사용자와 쿼리를 공유할 수 있습니다. ADA 쿼리 기능은 다음을 통해 구동됩니다. 아마존 아테나는 페타바이트 규모의 데이터를 간단하고 유연하게 분석할 수 있는 방법을 제공하는 서버리스 대화형 분석 서비스입니다.
- Tableau는 ADA 송신 끝점을 통해 ADA 데이터 제품에 액세스하도록 구성되어 있습니다. 그런 다음 두 개의 차트가 포함된 대시보드를 만듭니다. 첫 번째 차트는 애플리케이션 API 엔드포인트와 관련된 HTTP 오류 코드의 출현율을 보여주는 히트맵입니다. 두 번째 차트는 기록 데이터의 총 HTTP 오류 코드 수와 함께 상위 10개 애플리케이션 API를 표시하는 막대형 차트입니다.
사전 조건
이 게시물을 위해서는 다음 전제 조건을 완료해야 합니다.
- 설치 AWS 명령 줄 인터페이스 (AWS CLI), AWS 클라우드 개발 키트 (AWS 씨디케이) 전제 조건, TypeScript 전용 전제 조건및 자식.
- 배포 AWS 계정의 ADA 솔루션
us-east-1부위.- ADA를 시작하는 동안 관리자 이메일을 제공하세요 AWS 클라우드 포메이션 스택. 이는 ADA가 루트 사용자 비밀번호를 보내는 데 필요합니다. MFA(다단계 인증)가 활성화된 경우 일회용 비밀번호 메시지를 받으려면 관리자 전화번호가 필요합니다. 이 데모에서는 MFA가 활성화되지 않습니다.
- 샘플 애플리케이션을 빌드하고 배포합니다(다음에서 사용 가능). GitHub 레포) 솔루션을 사용하면 다음 리소스를 계정에 프로비저닝할 수 있습니다.
us-east-1지역 :- 로깅 애플리케이션을 시뮬레이션하는 Lambda 함수와 2분 간격으로 애플리케이션 함수를 호출하는 EventBridge 규칙.
- 관련 버킷 정책이 포함된 S3 버킷과 기록 애플리케이션 로그가 포함된 CSV 파일.
- 조회 데이터가 있는 DynamoDB 테이블.
- 관련된 AWS 자격 증명 및 액세스 관리 (IAM) 서비스에 필요한 역할 및 권한입니다.
- 선택적으로 설치 태블로 데스크톱, 타사 BI 제공업체입니다. 이 게시물에서는 Tableau Desktop 버전 2021.2를 사용합니다. Tableau Desktop 응용 프로그램의 라이선스 버전을 사용하는 데는 비용이 듭니다. 자세한 내용은 다음을 참조하세요. Tableau 라이선스 정보.
ADA 배포 및 설정
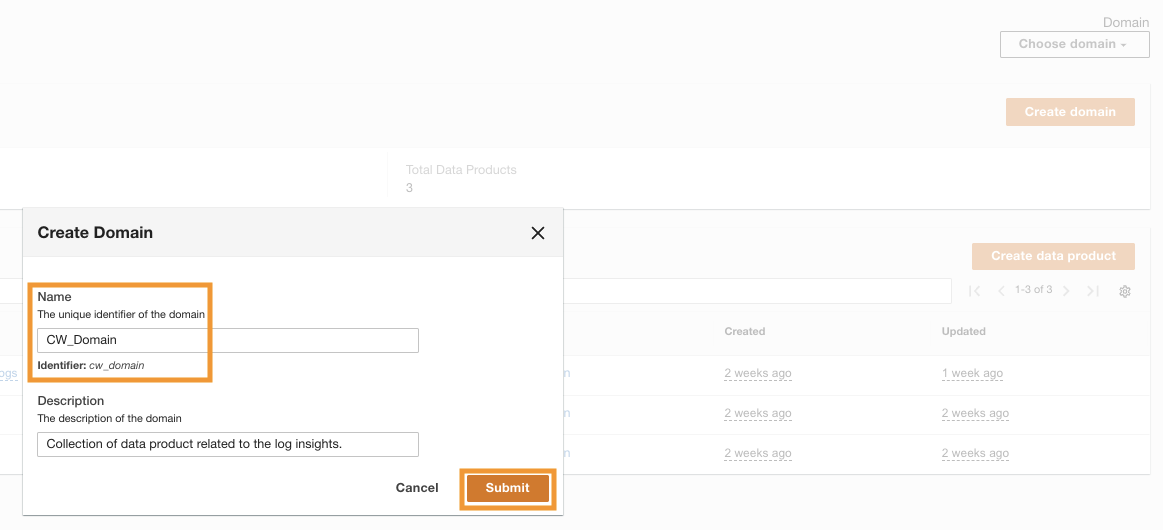
ADA가 성공적으로 배포되면 다음을 수행할 수 있습니다. 로그인 설치 중에 제공된 관리자 이메일을 사용합니다. 그런 다음 도메인 이름 CW_Domain. 도메인은 사용자가 정의한 데이터 제품 모음입니다. 예를 들어 도메인은 팀 또는 프로젝트일 수 있습니다. 도메인은 사용자가 데이터 제품을 구성하고 액세스 권한을 관리할 수 있는 구조화된 방법을 제공합니다.
- ADA 콘솔에서 다음을 선택합니다. 도메인 탐색 창에서
- 왼쪽 메뉴에서 도메인 생성.
- 이름을 입력하세요(
CW_Domain) 및 설명을 선택한 다음 문의하기.
AWS CDK를 사용하여 샘플 애플리케이션 인프라 설정
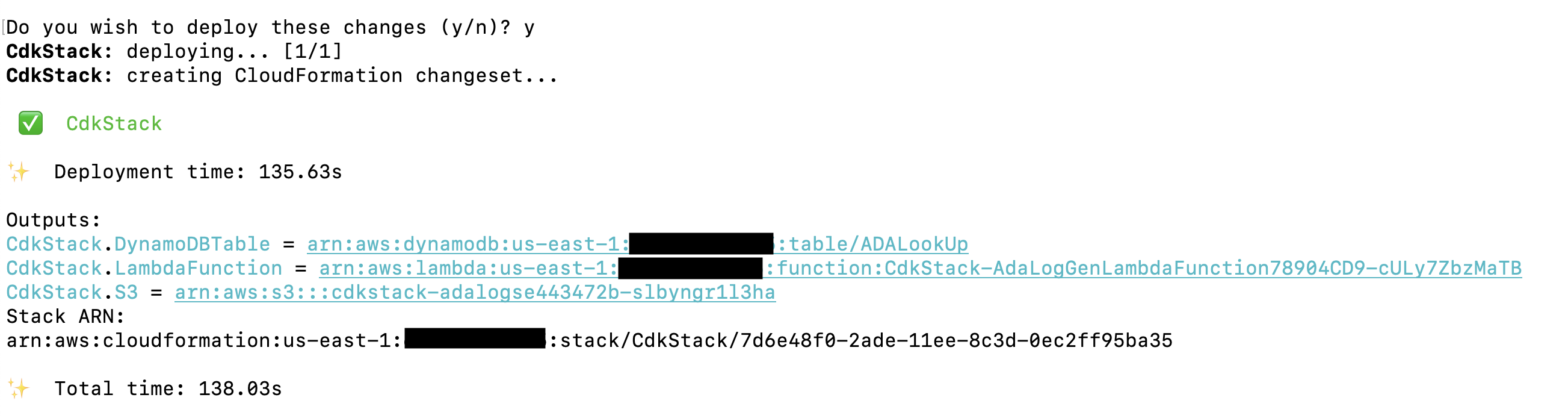
데모 애플리케이션을 배포하는 AWS CDK 솔루션은 다음에서 호스팅됩니다. GitHub의. 리포지토리를 복제하고 AWS CDK 프로젝트를 설정하는 단계는 이 섹션에 자세히 설명되어 있습니다. 이 명령을 실행하기 전에 다음 사항을 확인하세요. 구성 귀하의 AWS 자격 증명. 폴더를 생성하고 터미널을 연 다음 AWS CDK 솔루션을 설치해야 하는 폴더로 이동합니다. 다음 코드를 실행하세요.
이러한 단계에서는 다음 작업을 수행합니다.
- 라이브러리 종속성 설치
- 프로젝트 구축
- 유효한 CloudFormation 템플릿 생성
- AWS 계정에서 AWS CloudFormation을 사용하여 스택 배포
배포에는 약 1~2분이 소요되며 기록 로그 파일을 출력으로 포함하는 DynamoDB 조회 테이블, Lambda 함수 및 S3 버킷이 생성됩니다. 메모장과 같은 텍스트 편집 응용 프로그램에 이러한 값을 복사합니다.
ADA 데이터 제품 만들기
이 데모에서는 운영 통찰력을 얻기 위해 쿼리할 각 데이터 원본에 대해 하나씩 세 가지 데이터 제품을 만듭니다. 데이터 제품은 ADA로 성공적으로 가져왔고 쿼리할 수 있는 데이터 세트(테이블 또는 CSV 파일과 같은 데이터 모음)입니다.
CloudWatch 데이터 제품 생성
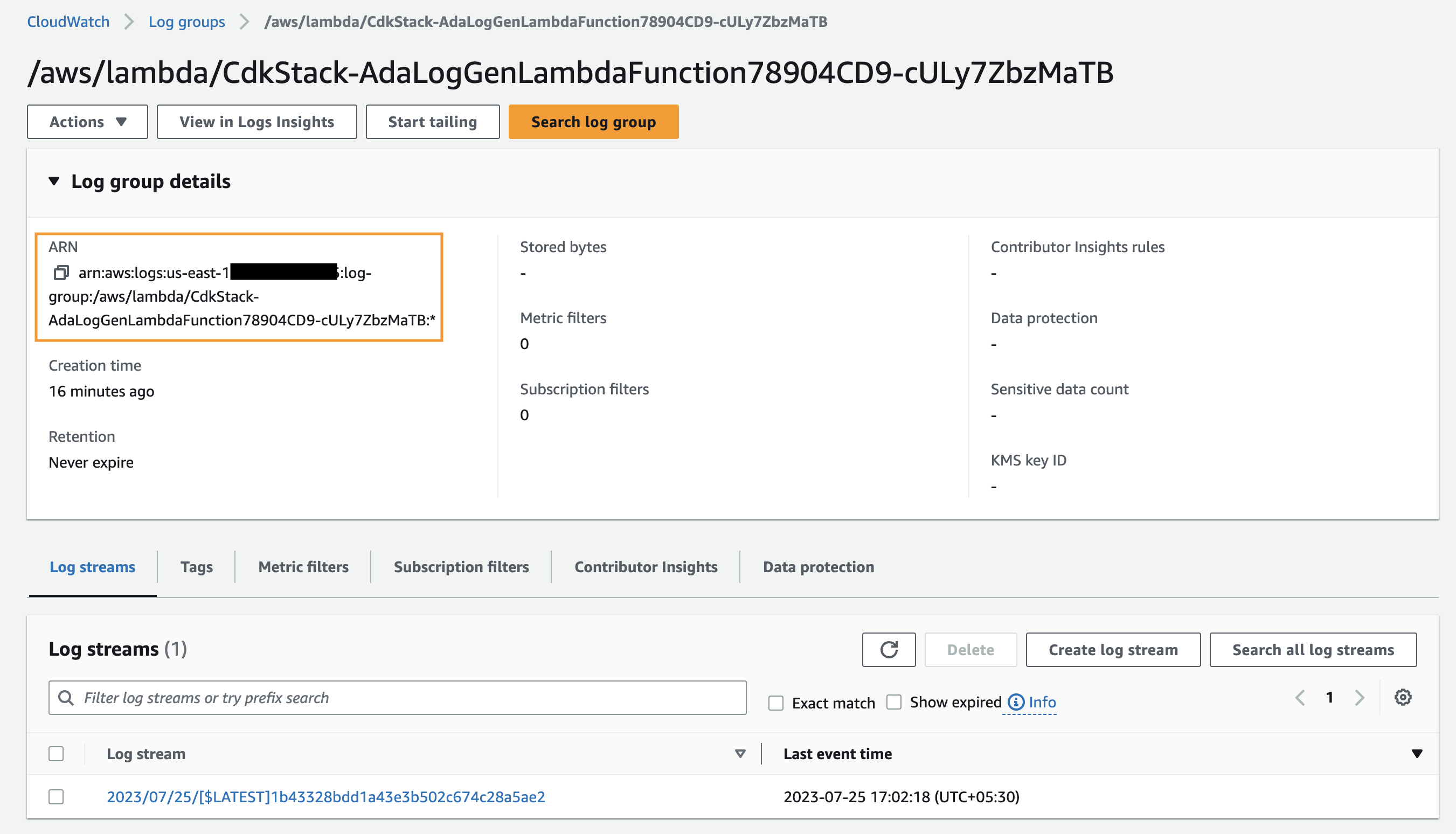
먼저 샘플 애플리케이션(Lambda 함수)에 대한 CloudWatch 로그 그룹을 수집하도록 ADA를 설정하여 애플리케이션 로그에 대한 데이터 제품을 생성합니다. 사용 CdkStack.LambdaFunction 출력을 통해 Lambda 함수 ARN을 가져오고 CloudWatch 콘솔에서 해당 CloudWatch 로그 그룹 ARN을 찾습니다.
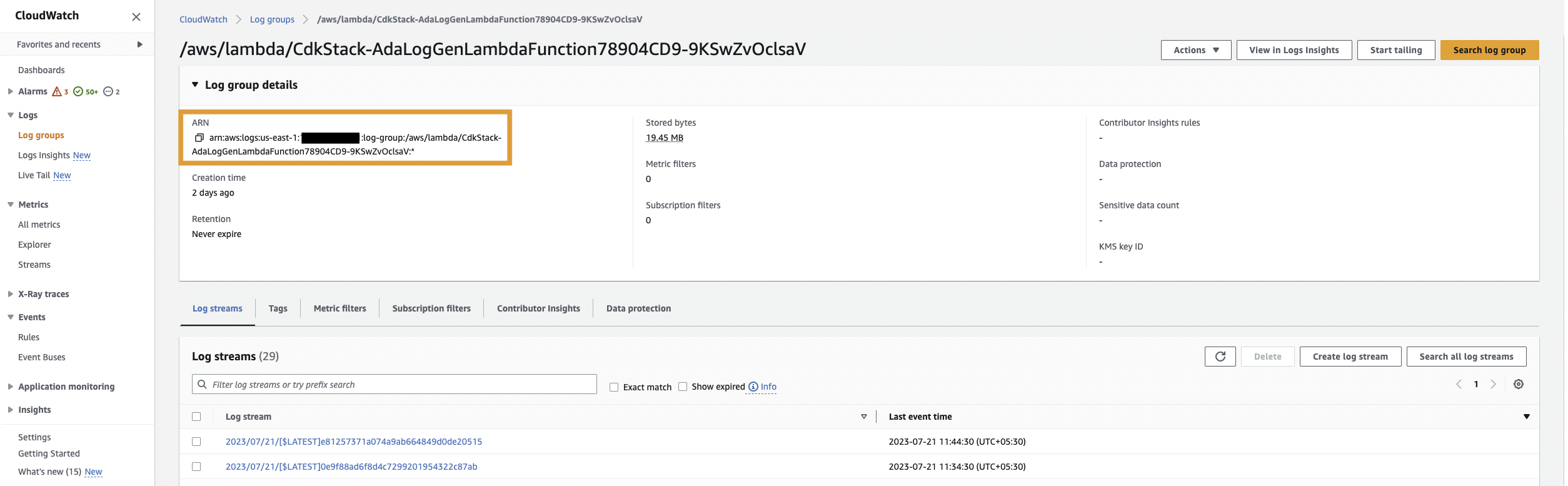
그런 다음 다음 단계를 완료하십시오.
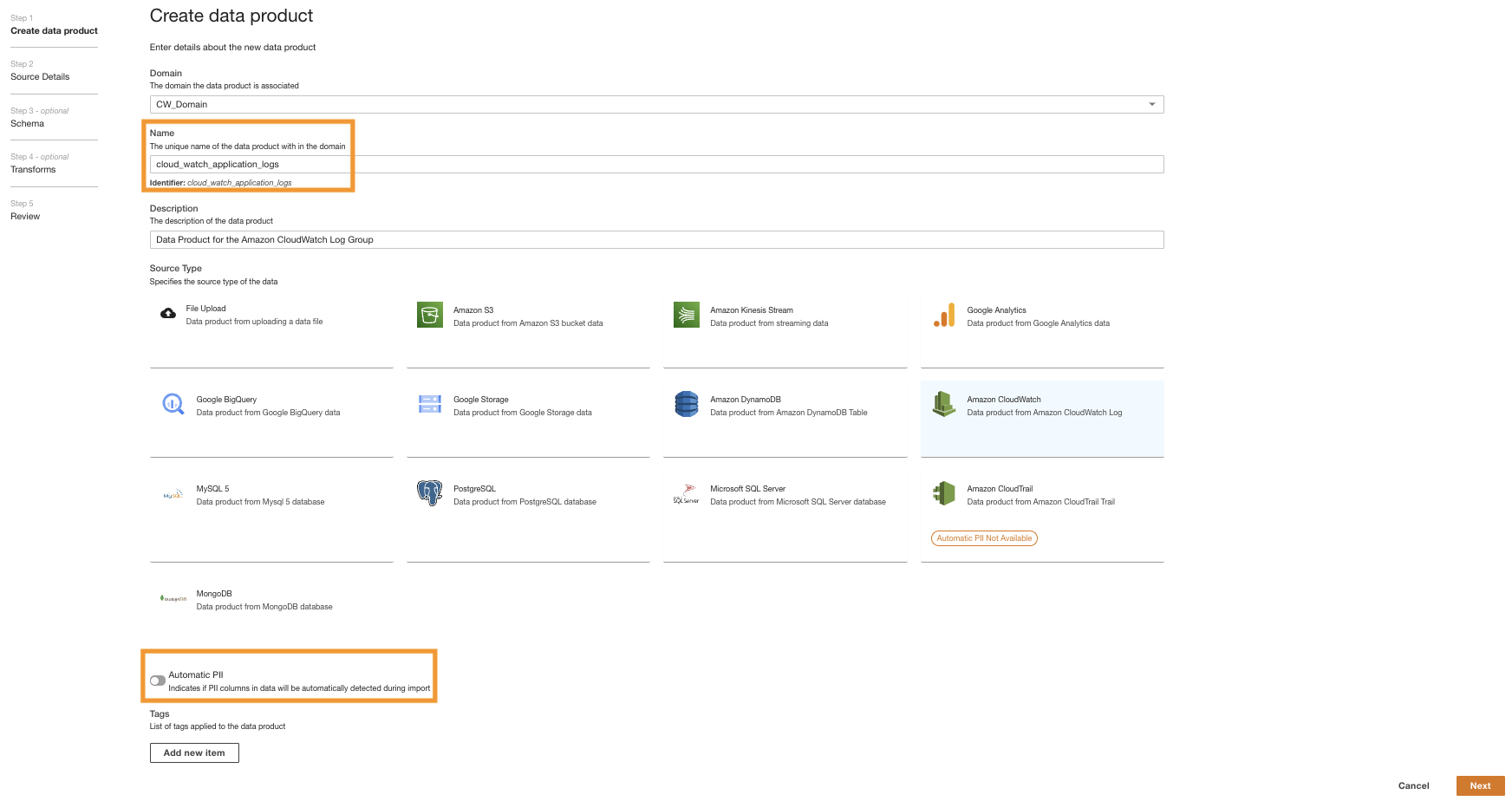
- ADA 콘솔에서 ADA 도메인으로 이동하여 CloudWatch 데이터 제품을 생성합니다.
- 럭셔리 성함¸ 이름을 입력하십시오.
- 럭셔리 소스 유형, 선택 아마존 클라우드 워치.
- 사용 안 함 자동 PII.
ADA에는 가져오는 동안 개인 식별 정보(PII) 데이터를 자동으로 감지하는 기능이 기본적으로 활성화되어 있습니다. 이 데모에서는 PII 데이터 검색이 이 데모의 범위에 속하지 않기 때문에 데이터 제품에 대해 이 옵션을 비활성화합니다.
- 왼쪽 메뉴에서 다음 보기.
- 이전 단계에서 복사한 CloudWatch 로그 그룹 ARN을 검색하여 선택합니다.

- 로그 그룹 ARN 복사.
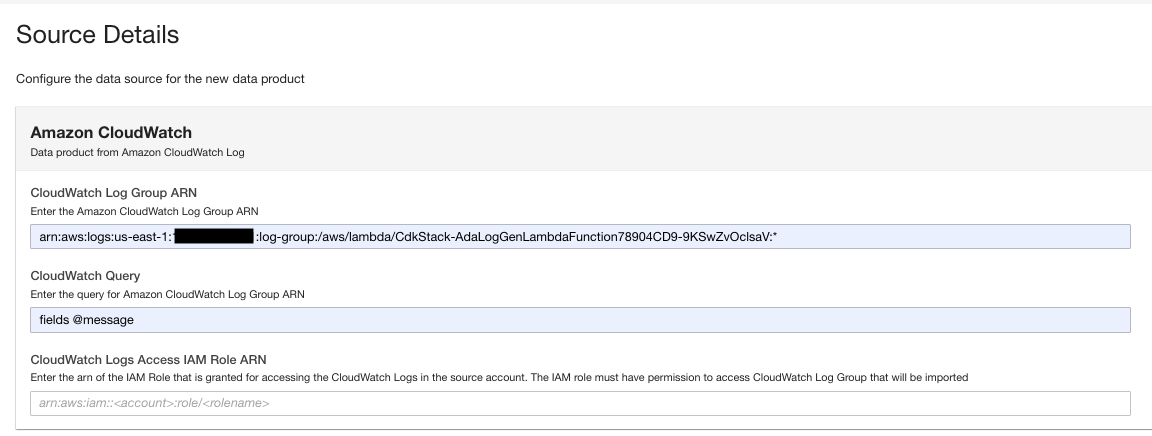
- 데이터 제품 페이지에서 로그 그룹 ARN을 입력합니다.
- 럭셔리 CloudWatch 쿼리에서 ADA가 로그 그룹에서 가져오기를 원하는 쿼리를 입력하세요.
이 데모에서는 로그 그룹에서 애플리케이션 로그를 가져오는 데 관심이 있기 때문에 @message 필드를 쿼리합니다.
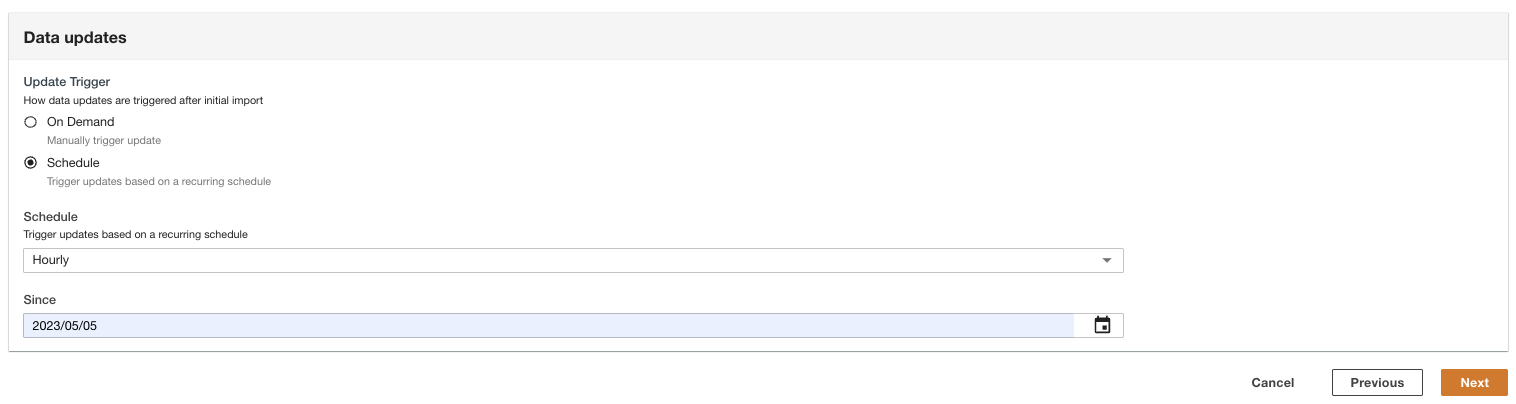
- 초기 가져오기 후 데이터 업데이트가 트리거되는 방법을 선택합니다.
ADA는 유연한 간격(최대 15분 이상) 또는 요청 시 소스에서 데이터를 수집하도록 구성할 수 있습니다. 데모에서는 데이터 업데이트가 매시간 실행되도록 설정했습니다.
- 왼쪽 메뉴에서 다음 보기.
다음으로 ADA는 로그 그룹에 연결하고 스키마를 쿼리합니다. 로그는 Apache 로그 형식이므로 특정 로그 필드에 대해 쿼리를 실행할 수 있도록 로그를 별도의 필드로 변환합니다. ADA는 XNUMX가지를 제공합니다. 디폴트 값 변환을 수행하고 Python 스크립트를 통해 사용자 정의 변환을 지원합니다. 이 데모에서는 사용자 정의 Python 스크립트를 실행하여 JSON 메시지 필드를 Apache 로그 형식 필드로 변환합니다.
- 왼쪽 메뉴에서 스키마 변환.
- 왼쪽 메뉴에서 새 변환 만들기.
- 업로드
apache-log-extractor-transform.py의 스크립트/asset/transform_logs/폴더에 있습니다. - 왼쪽 메뉴에서 문의하기.
ADA는 스크립트를 사용하여 CloudWatch 로그를 변환하고 처리된 스키마를 제공합니다.
- 왼쪽 메뉴에서 다음 보기.
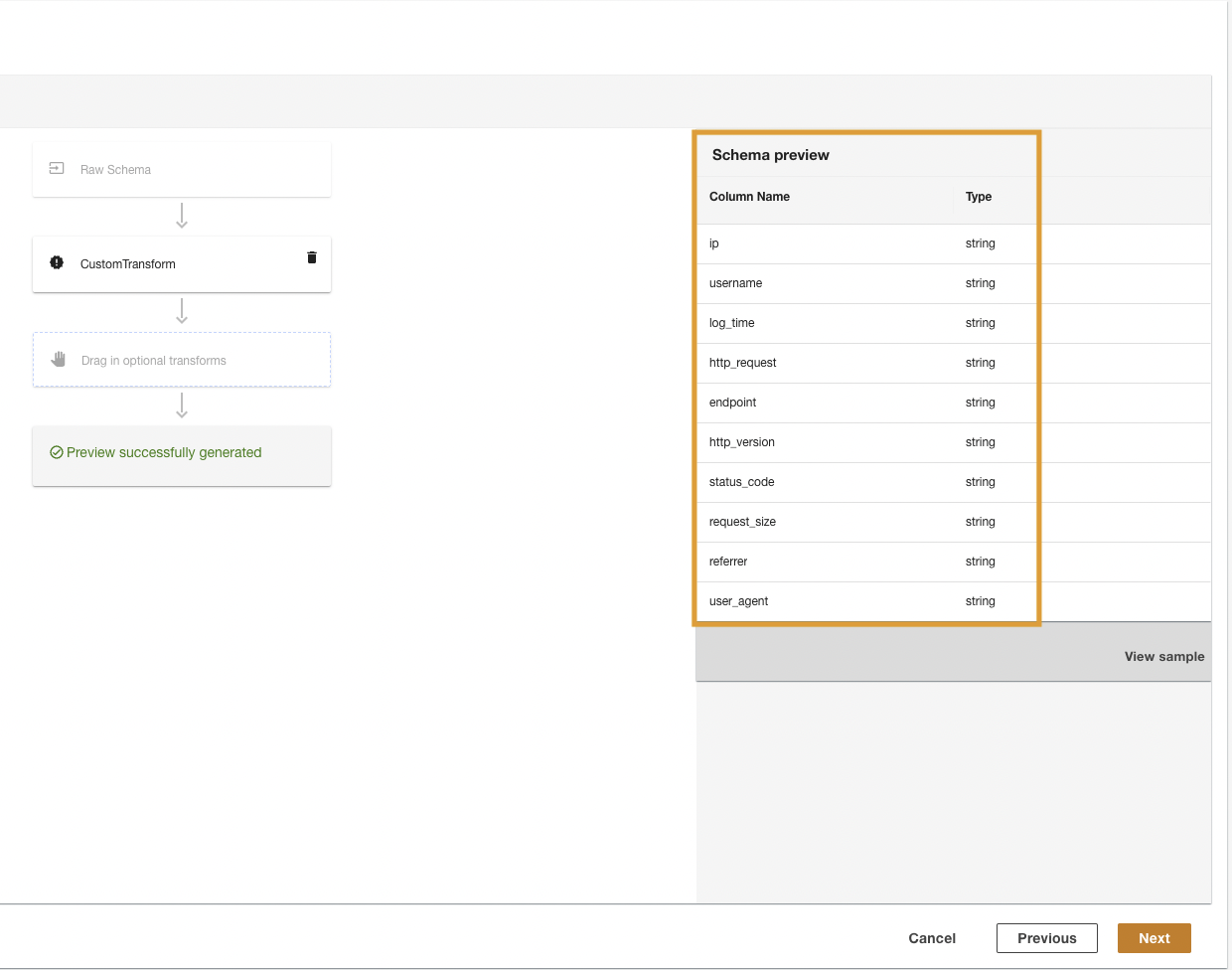
- 마지막 단계에서 단계를 검토하고 선택하세요. 문의하기.
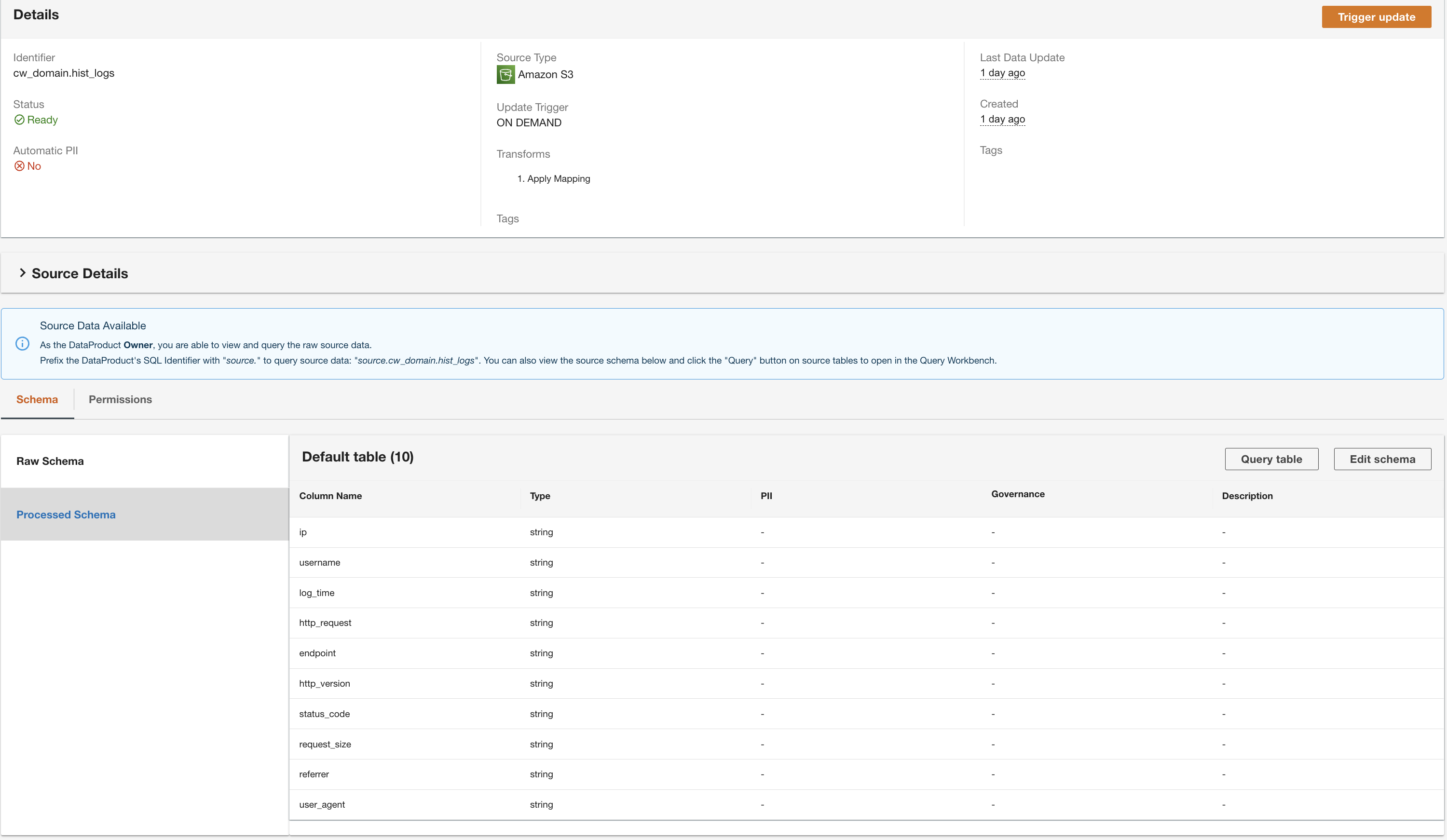
ADA는 데이터 처리를 시작하고, 데이터 파이프라인을 생성하고, Query Workbench에서 쿼리할 CloudWatch 로그 그룹을 준비합니다. 이 프로세스는 완료하는 데 몇 분 정도 걸리며 아래 ADA 콘솔에 표시됩니다. 데이터 제품.
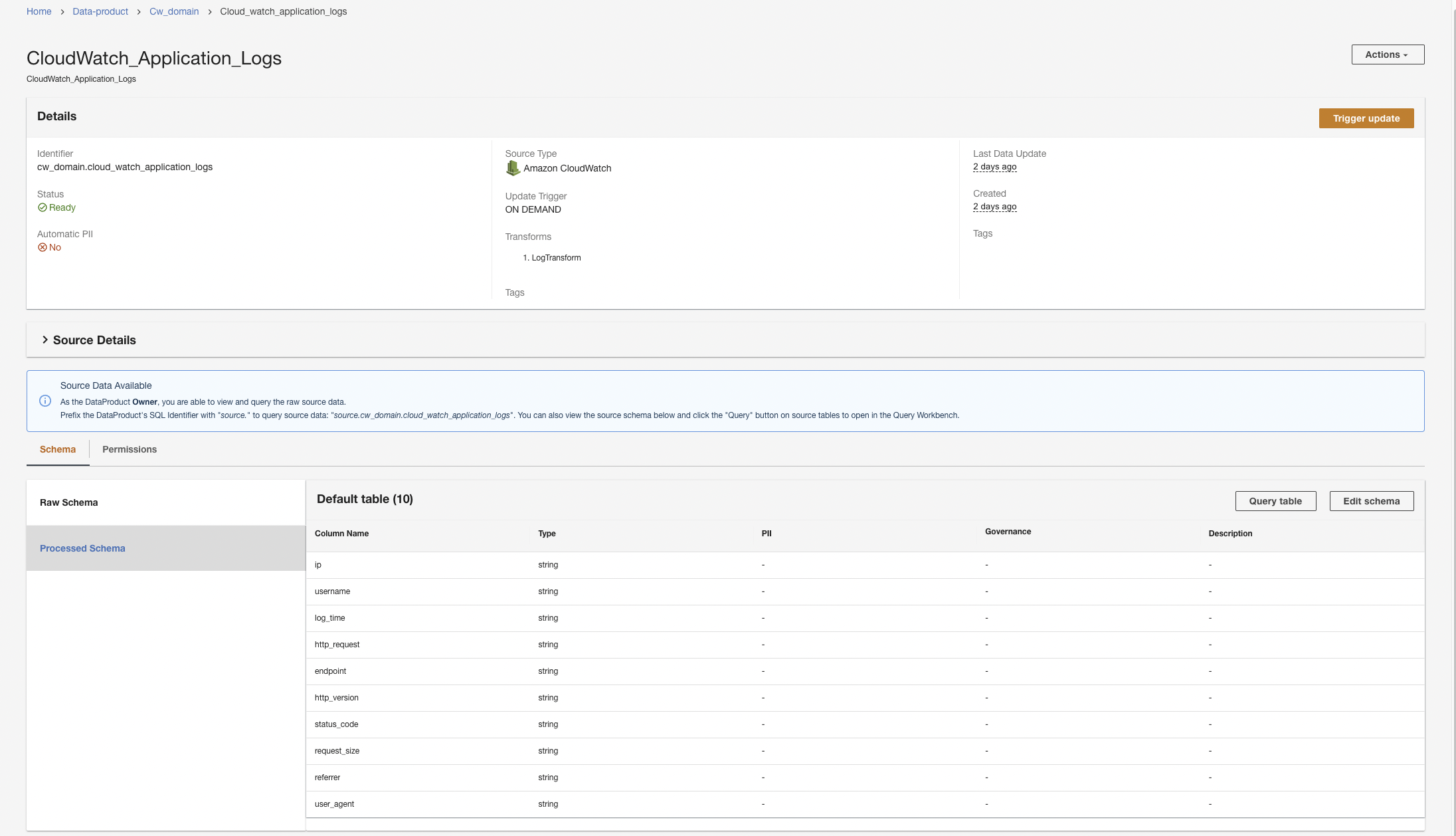
Amazon S3 데이터 제품 생성
Amazon S3 데이터 소스의 기록 로그를 추가하고 DynamoDB 테이블에서 참조 데이터를 조회하는 단계를 반복합니다. 이 두 데이터 소스의 경우 데이터 형식이 CSV(기록 로그용) 및 주요 속성(참조 조회 데이터용)이기 때문에 사용자 정의 변환을 생성하지 않습니다.
- ADA 콘솔에서 새 데이터 제품을 생성합니다.
- 이름을 입력하세요(
hist_logs) 및 선택 아마존 S3.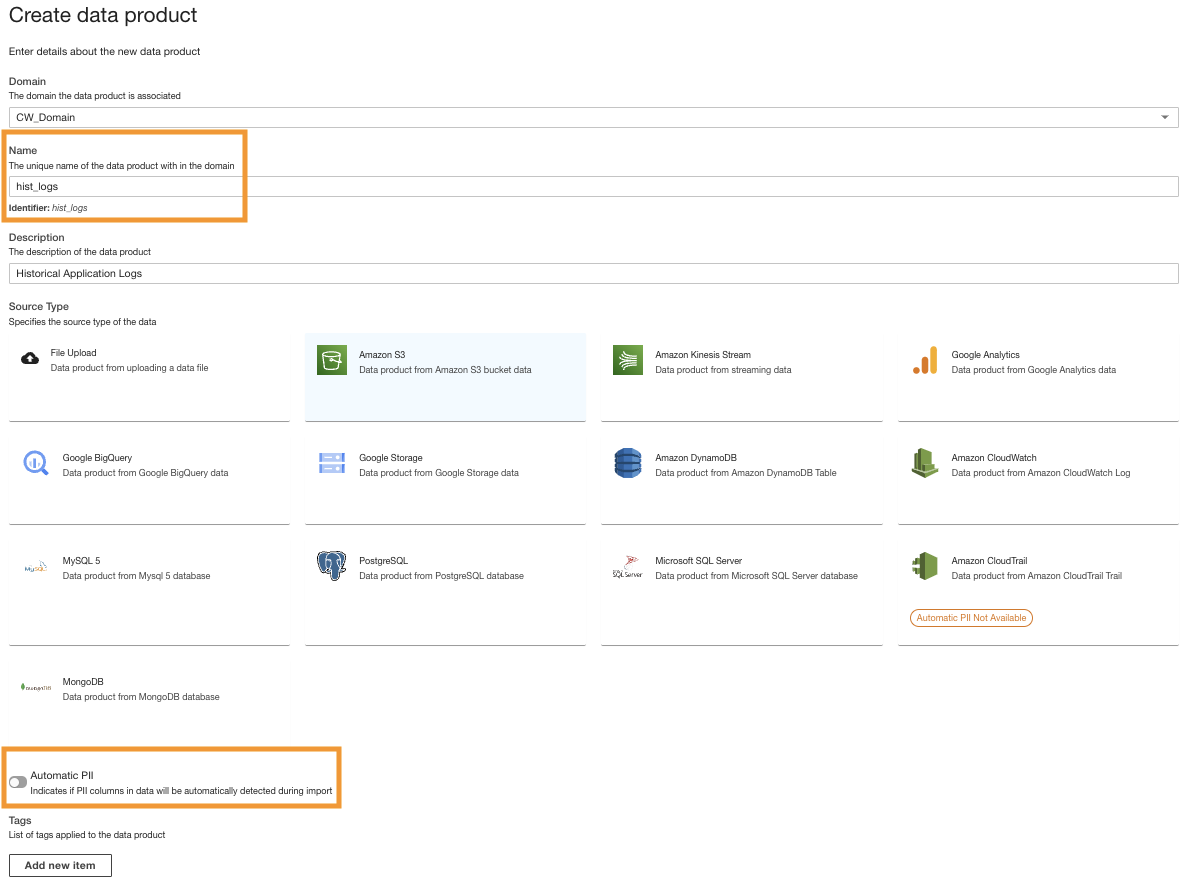
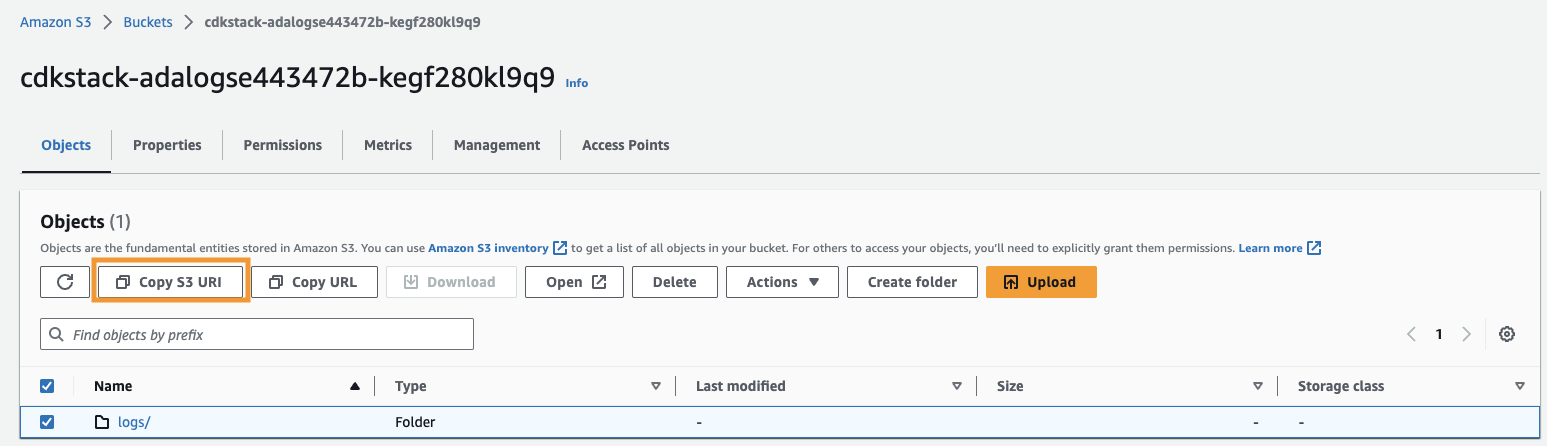
- Amazon S3 URI(다음 텍스트)를 복사합니다.
arn:aws:s3:::) 로부터CdkStack.S3변수를 출력하고 Amazon S3 콘솔로 이동합니다. - 검색 상자에 복사한 텍스트를 입력하고 S3 버킷을 열고
/logs폴더를 선택하고 S3 URI 복사를 선택합니다.
기록 로그는 이 경로에 저장됩니다.
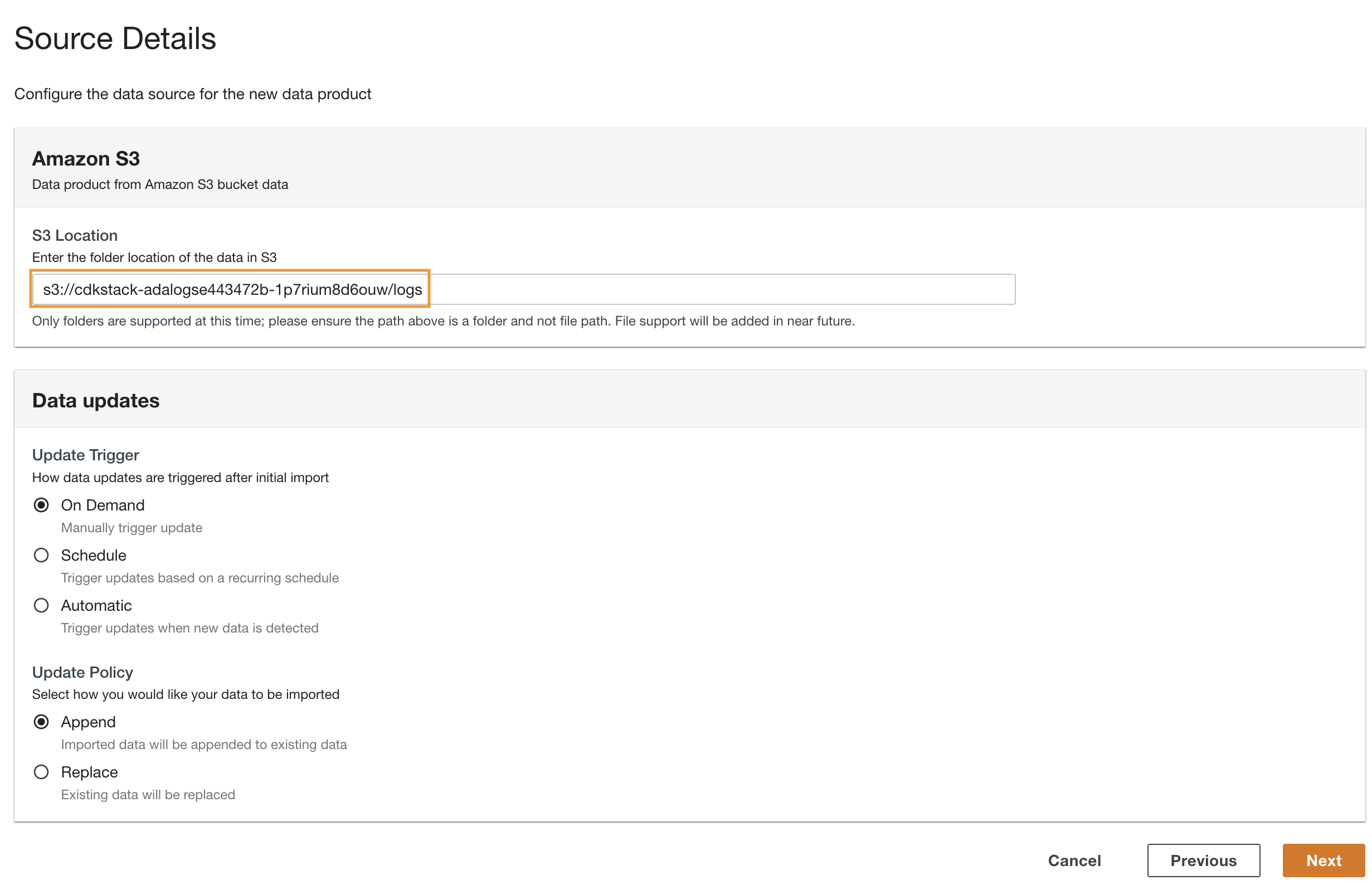
- ADA 콘솔로 다시 이동하여 복사된 S3 URI를 입력합니다. S3 위치.
- 럭셔리 업데이트 트리거, 고르다 온 디맨드 기록 로그는 지정되지 않은 빈도로 업데이트되기 때문입니다.
- 럭셔리 정책 업데이트, 고르다 추가 새로 가져온 데이터를 기존 데이터에 추가합니다.
- 왼쪽 메뉴에서 다음 보기.
ADA는 선택한 폴더 경로에 있는 파일의 스키마를 처리합니다. 로그는 CSV 형식이므로 ADA는 추가 변환 없이 열 이름을 읽을 수 있습니다. 그러나 열은 status_code 및 request_size ADA에서는 long 유형으로 추론됩니다. 데이터 테이블을 조인하고 데이터를 쿼리할 수 있도록 데이터 제품 간에 열 데이터 유형을 일관되게 유지하려고 합니다. 칼럼 status_code 데이터 테이블 전체에 걸쳐 조인을 만드는 데 사용됩니다.
- 왼쪽 메뉴에서 스키마 변환 두 열의 데이터 유형을 문자열 데이터 유형으로 변경합니다.
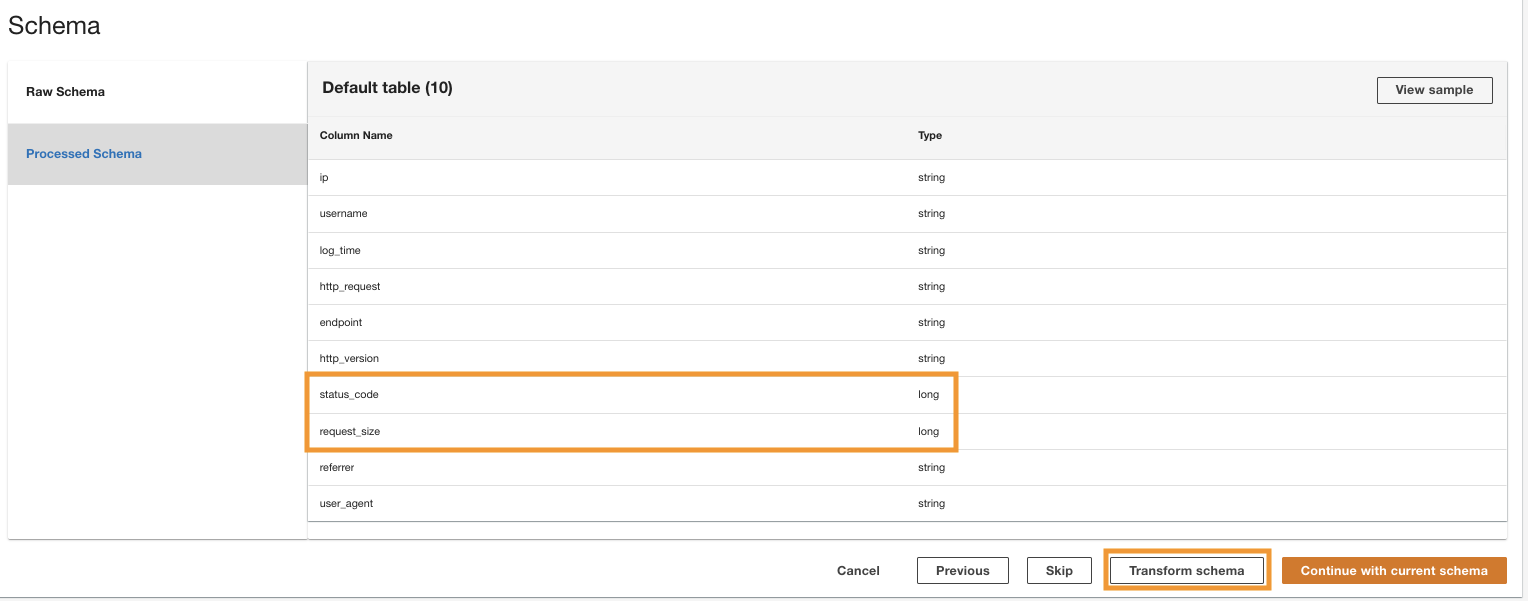
강조 표시된 열 이름을 참고하세요. 스키마 미리보기 데이터 유형 변환을 적용하기 전의 창입니다.
- . 계획 전환 창, 아래 내장된 변환선택한다. 매핑 적용.
이 옵션을 사용하면 데이터 유형을 한 유형에서 다른 유형으로 변경할 수 있습니다.
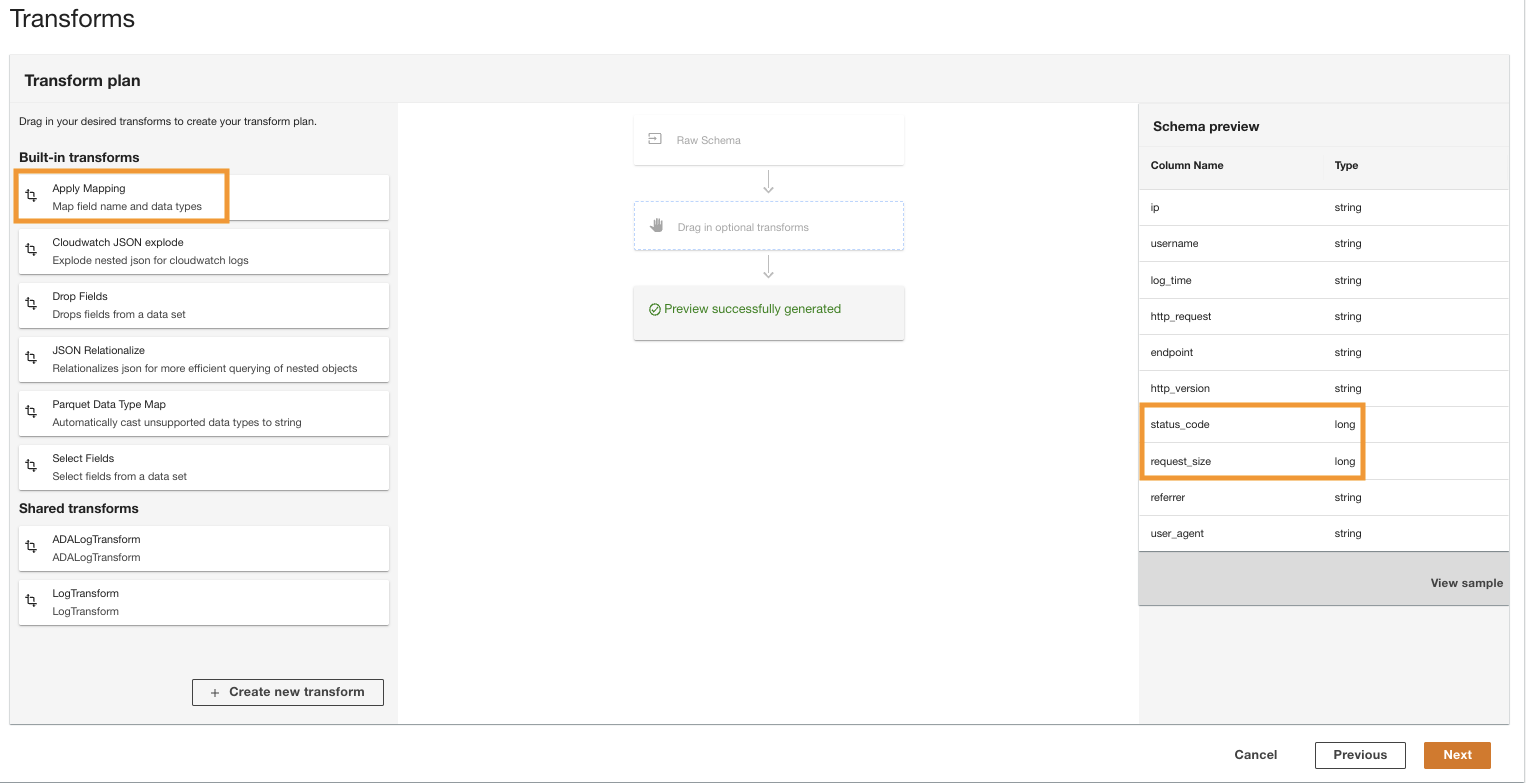
- . 매핑 적용 섹션, 선택 해제 다른 필드 삭제.
이 옵션을 비활성화하지 않으면 변환된 열만 유지되고 다른 모든 열은 삭제됩니다. 모든 열을 유지하려고 하므로 이 옵션을 비활성화합니다.
- $XNUMX Million 미만 필드 매핑을위한 고명 및 새 이름, 입력
status_code~을 위해 새로운 유형, 입력string.
- 왼쪽 메뉴에서 아이템 추가.
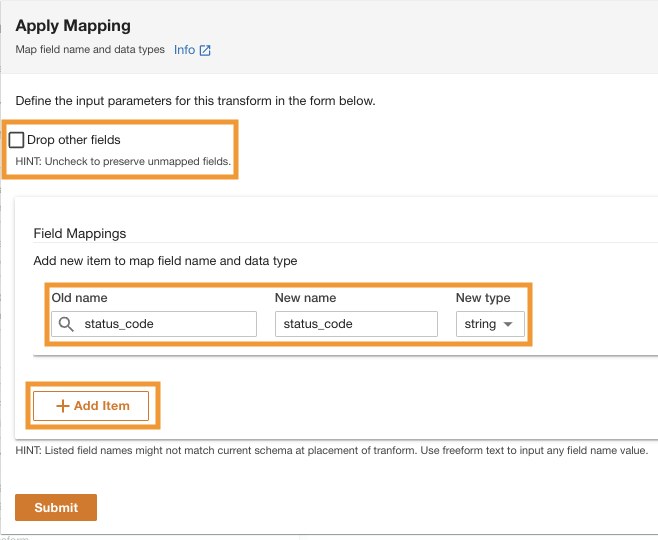
- 럭셔리 고명 및 새 이름¸ request_size를 입력하고 새로운 데이터 유형, 문자열을 입력하세요.
- 왼쪽 메뉴에서 문의하기.
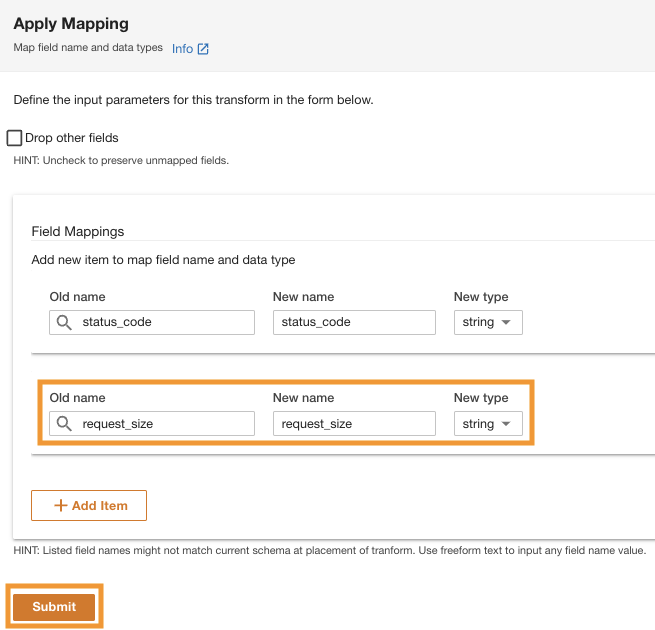
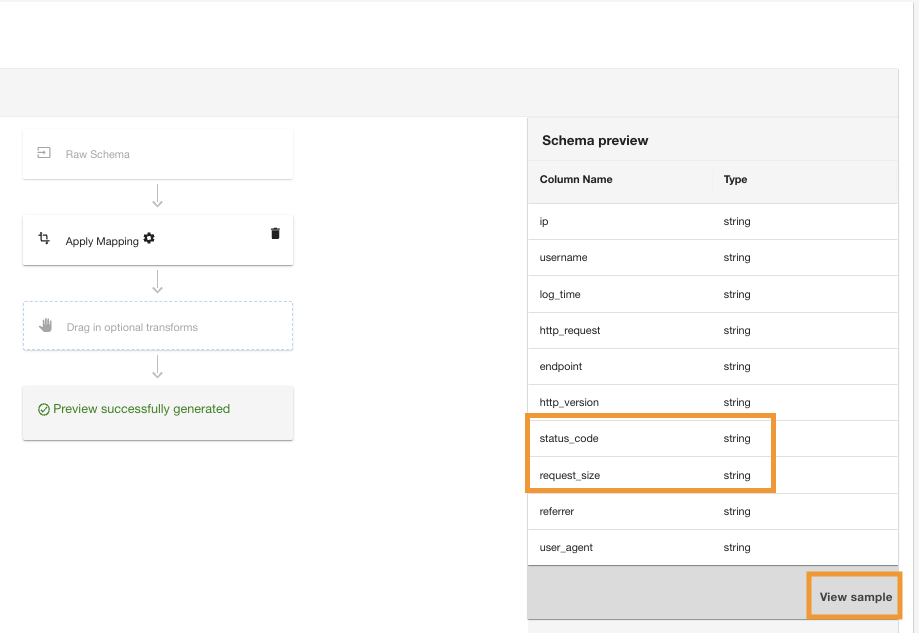
ADA는 Amazon S3 데이터 소스에 매핑 변환을 적용합니다. 열 유형을 참고하세요. 스키마 미리보기 창유리.
- 왼쪽 메뉴에서 샘플 보기 변환이 적용된 데이터를 미리 봅니다.
ADA는 승인된 사용자만 데이터를 볼 수 있는지 또는 데이터 세트에 PII 데이터가 포함되어 있지 않은지 확인하기 위해 PII 데이터 승인을 표시합니다.
- 왼쪽 메뉴에서 동의 샘플 데이터를 계속 보려면
현재 애플리케이션 로그와 기록 애플리케이션 로그가 모두 Apache 로그 형식이기 때문에 스키마는 CloudWatch 로그 그룹 스키마와 동일합니다.
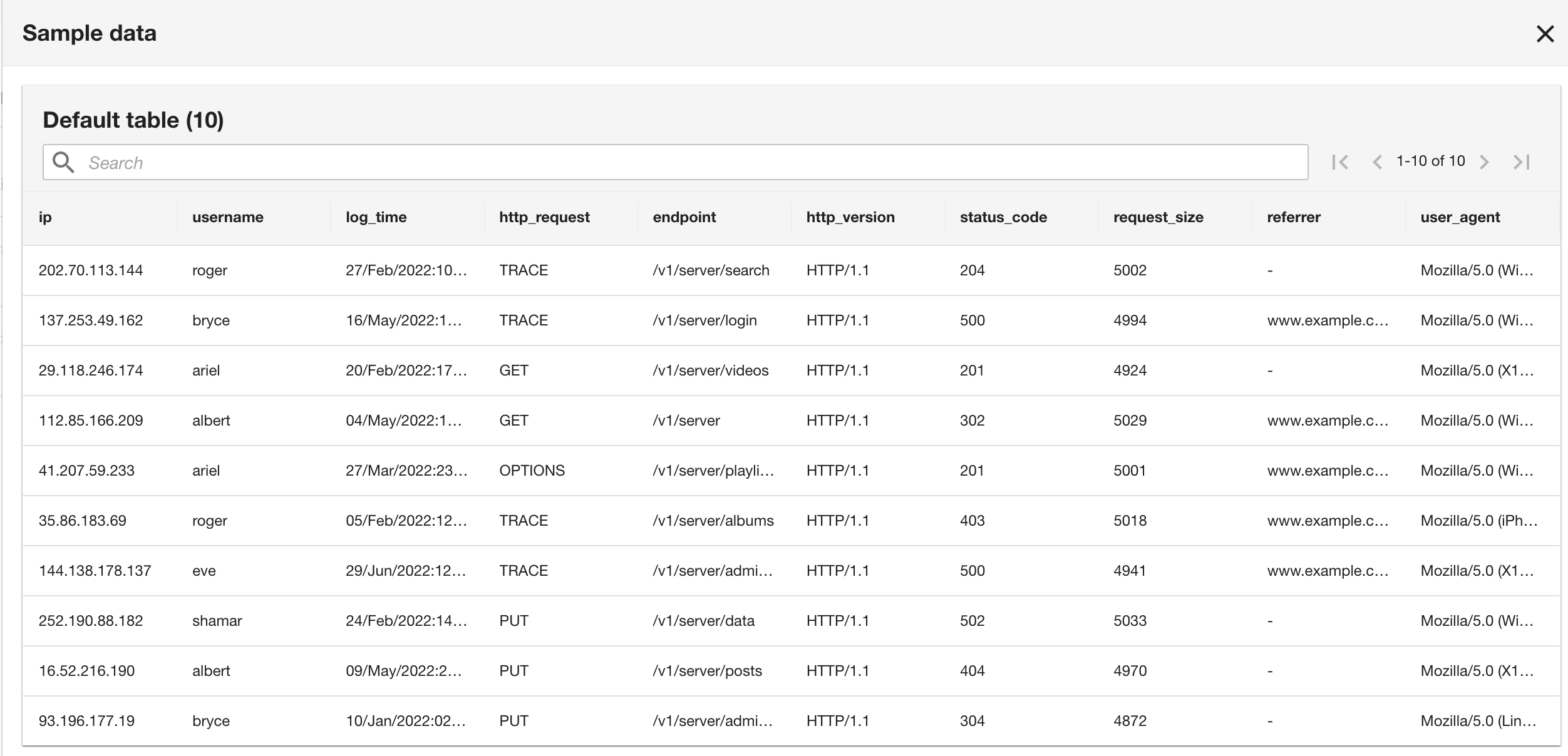
- 마지막 단계에서 구성을 검토하고 선택합니다. 문의하기.
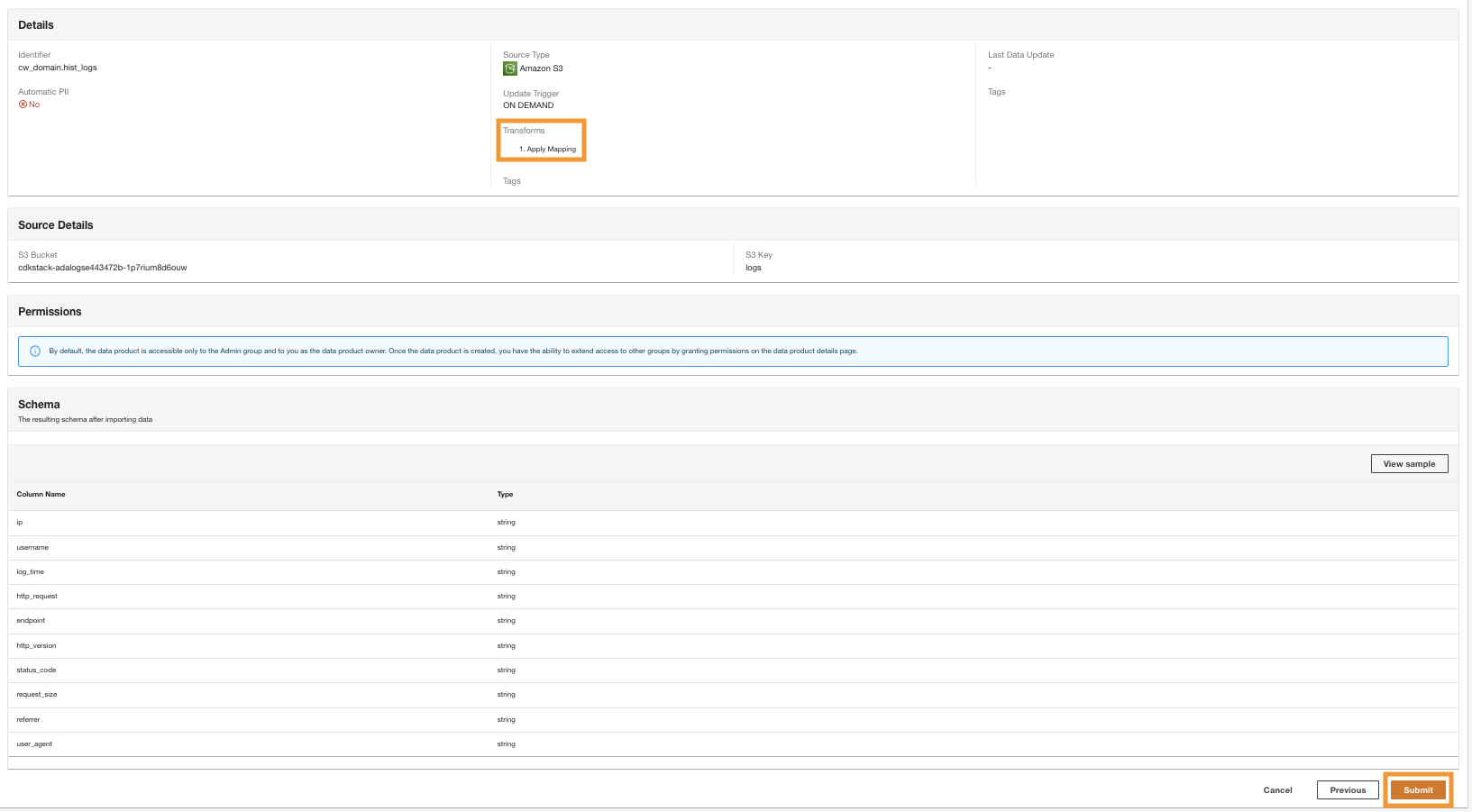
ADA는 Amazon S3 소스의 데이터 처리를 시작하고 백엔드 인프라를 생성하며 데이터 제품을 준비합니다. 이 프로세스는 데이터 크기에 따라 몇 분 정도 걸립니다.
DynamoDB 데이터 제품 생성
마지막으로 DynamoDB 데이터 제품을 생성합니다. 다음 단계를 완료하세요.
- ADA 콘솔에서 새 데이터 제품을 생성합니다.
- 이름을 입력하세요(
lookup) 및 선택 아마존 DynamoDB.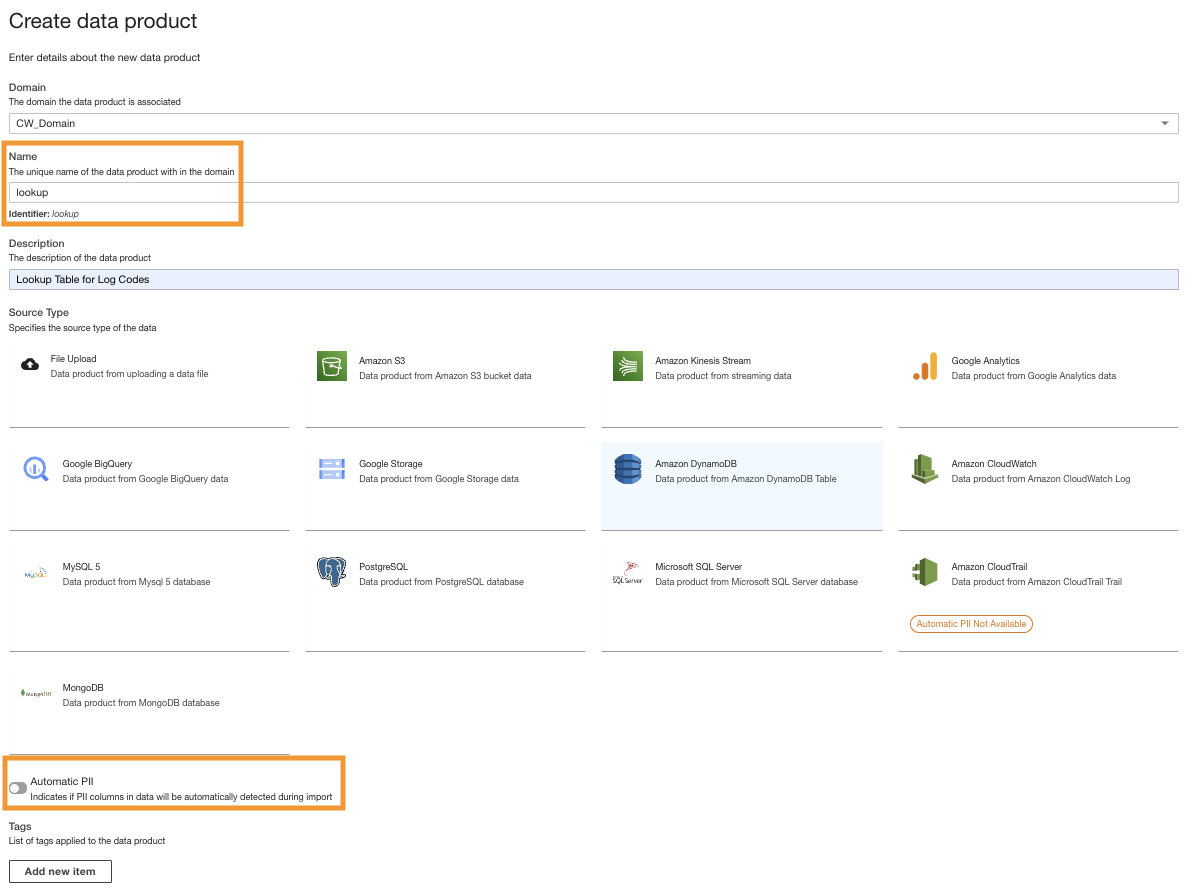
- 입력
Cdk.DynamoDBTable출력 변수 DynamoDB 테이블 ARN.
이 테이블에는 이 데모에서 조회 테이블로 사용될 주요 속성이 포함되어 있습니다. 조회 데이터의 경우 HTTP 코드와 코드에 대한 길고 짧은 설명을 사용하고 있습니다. 대안으로 PostgreSQL, MySQL 또는 CSV 파일 소스를 사용할 수도 있습니다.
- 럭셔리 업데이트 트리거, 고르다 온디맨드.
조회는 주로 쿼리하는 동안 참조 목적으로 사용되며 조회 데이터에 대한 모든 업데이트는 주문형 트리거를 사용하여 ADA에서 업데이트될 수 있으므로 업데이트는 주문형입니다.
- 왼쪽 메뉴에서 다음 보기.
ADA는 기본 DynamoDB 스키마에서 스키마를 읽고 선택적 변환을 위한 열 이름과 유형을 제공합니다. 열 유형이 CloudWatch 로그 그룹 및 Amazon S3 CSV 데이터 원본의 유형과 일치하므로 기본 스키마 선택을 진행하겠습니다. 데이터 소스 전체에서 일관된 데이터 유형을 사용하면 열 필드를 사용하여 테이블을 조인하여 레코드를 가져오는 쿼리를 작성할 수 있습니다. 예를 들어, 열 key DynamoDB 스키마의 status_code Amazon S3 및 CloudWatch 데이터 제품에서. 열 이름을 사용하여 세 테이블을 조인할 수 있는 쿼리를 작성할 수 있습니다. key. 다음 섹션에 예가 나와 있습니다.
- 왼쪽 메뉴에서 현재 스키마로 계속.
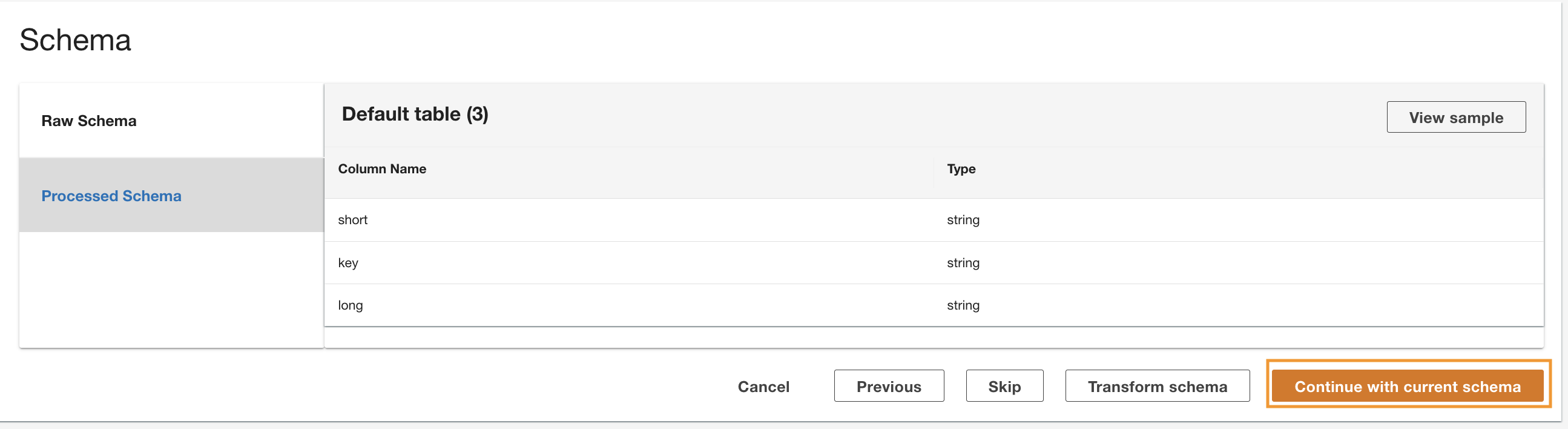
- 구성을 검토하고 선택 문의하기.
ADA는 DynamoDB 테이블 데이터 원본의 데이터를 처리하고 데이터 제품을 준비합니다. 데이터 크기에 따라 이 프로세스는 몇 분 정도 걸립니다.
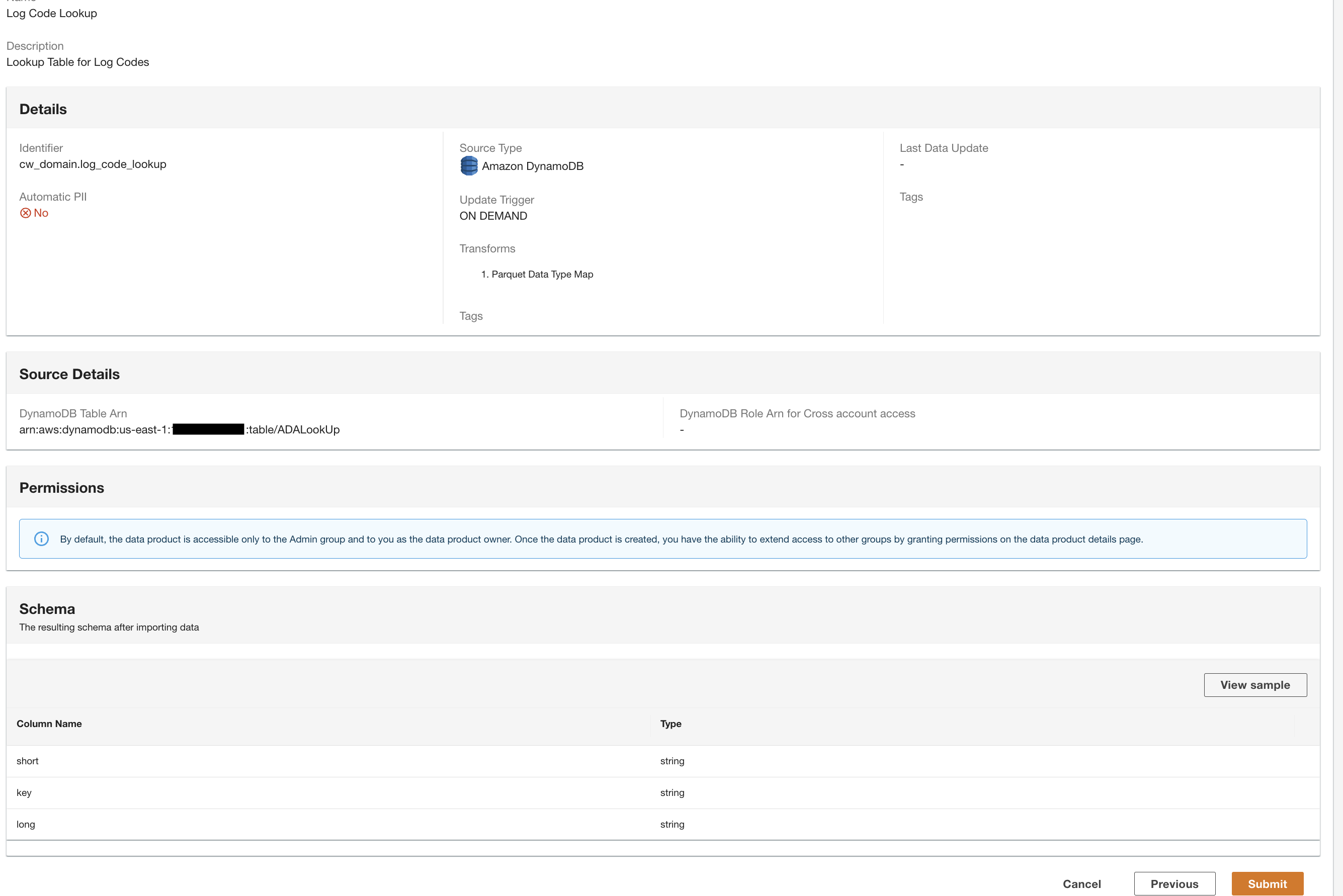
이제 우리는 ADA에서 처리한 세 가지 데이터 제품을 모두 보유하고 있으며 쿼리를 실행할 수 있습니다.

쿼리 워크벤치를 사용하여 데이터 쿼리
ADA를 사용하면 데이터 소스를 추상화하고 SQL(구조적 쿼리 언어)을 사용하여 액세스할 수 있도록 하면서 데이터 제품에 대해 쿼리를 실행할 수 있습니다. 관계형 데이터베이스의 테이블에 대해 쿼리하는 것처럼 쿼리를 작성하고 테이블을 조인할 수 있습니다. 우리는 두 가지 사용자 시나리오를 통해 ADA의 쿼리 기능을 보여줍니다. 두 시나리오 모두에서 애플리케이션 로그 데이터 세트를 오류 코드 조회 테이블에 조인합니다. 첫 번째 사용 사례에서는 현재 애플리케이션 로그를 쿼리하여 해당 HTTP 상태 코드와 함께 가장 많이 액세스된 상위 10개 애플리케이션 엔드포인트를 식별합니다.
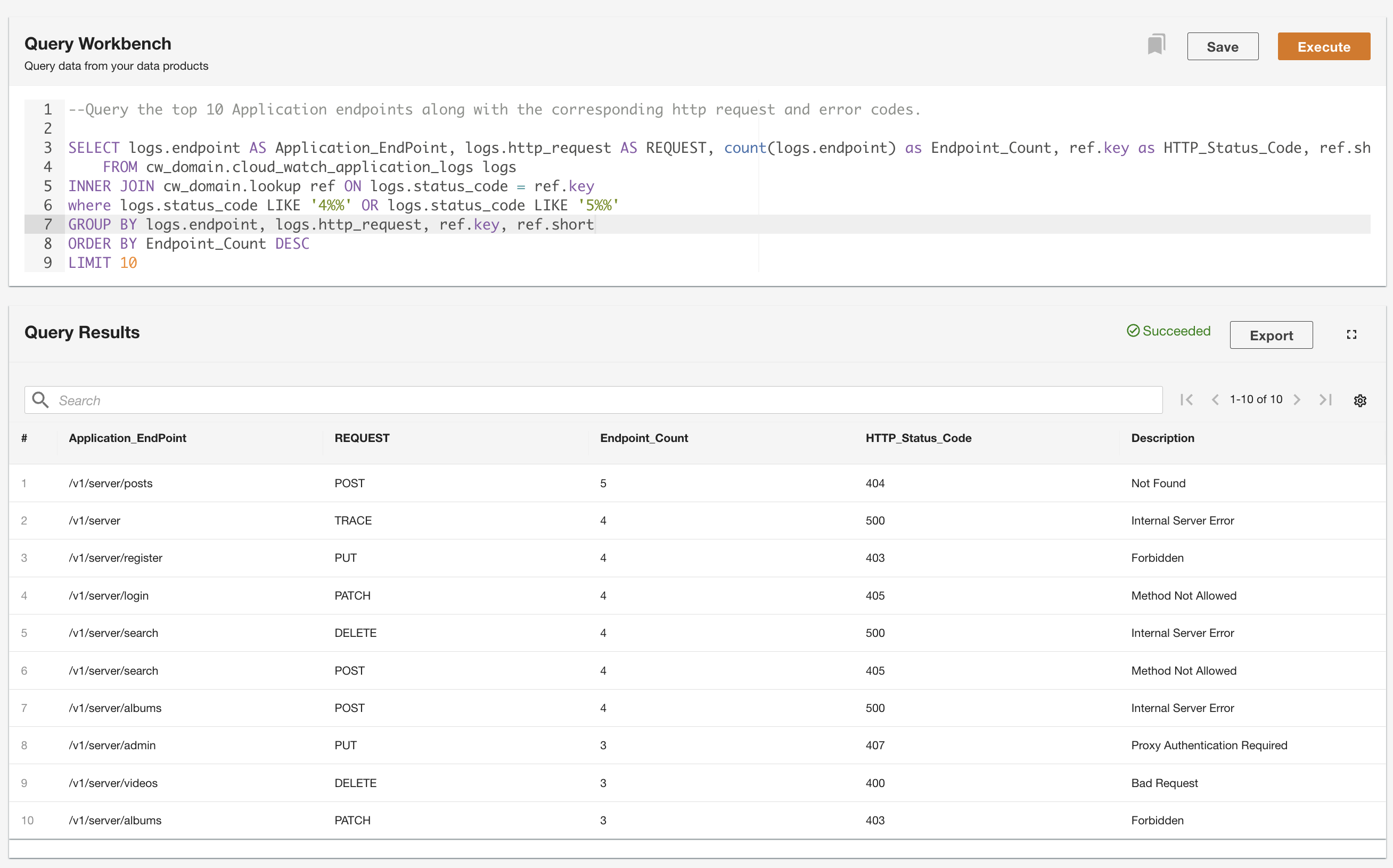
두 번째 예에서는 엔드포인트 호출 패턴을 이해하기 위해 기록 로그 테이블을 쿼리하여 오류가 가장 많은 상위 10개 애플리케이션 엔드포인트를 가져옵니다.
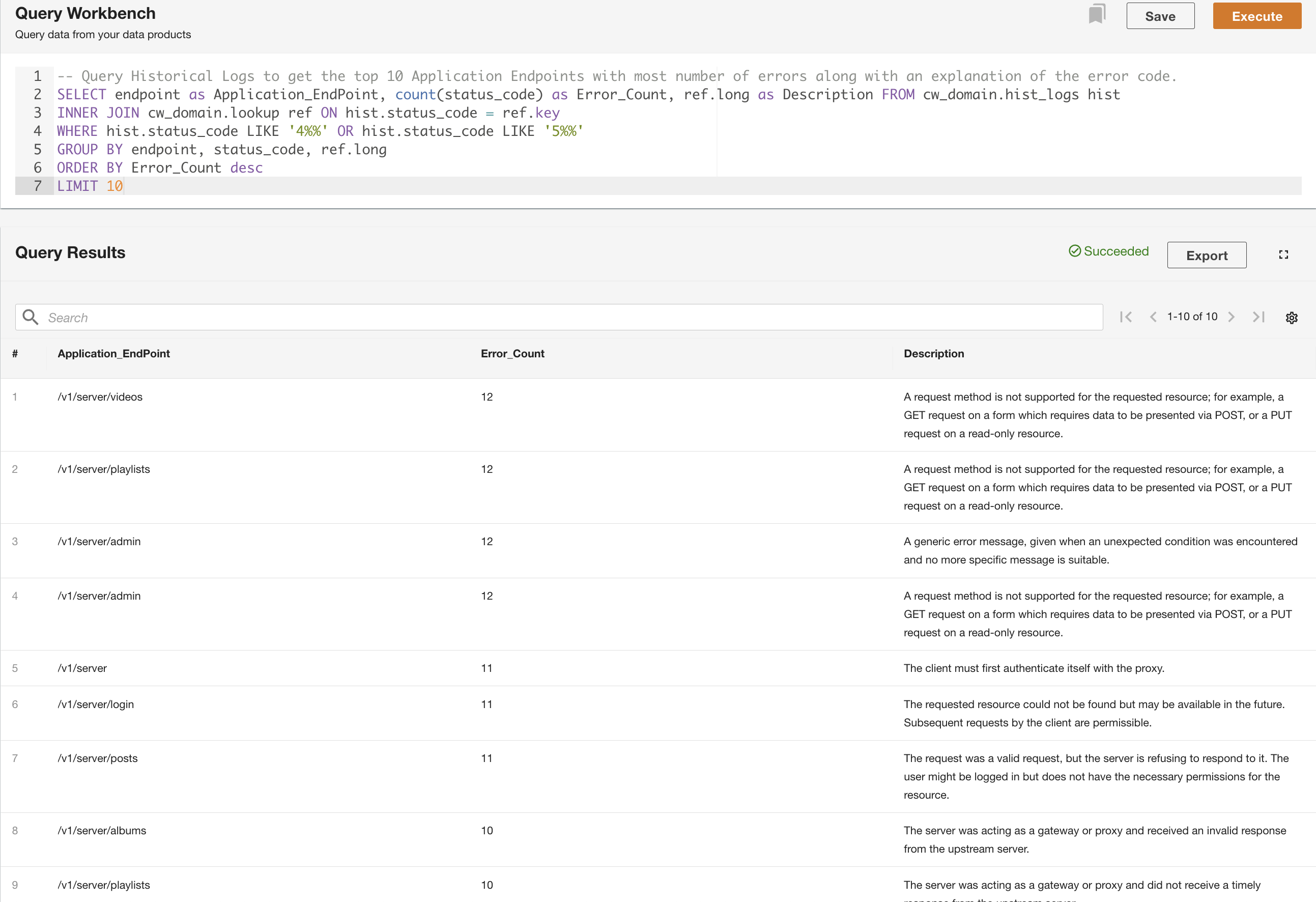
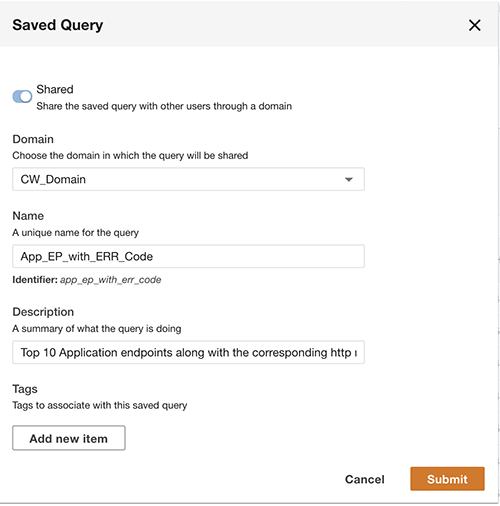
쿼리 외에도 선택적으로 쿼리를 저장하고 저장된 쿼리를 동일한 도메인의 다른 사용자와 공유할 수 있습니다. 공유 쿼리는 쿼리 워크벤치에서 직접 액세스할 수 있습니다. 쿼리 결과는 CSV 형식으로 내보낼 수도 있습니다.
Tableau에서 ADA 데이터 제품 시각화
ADA는 다음과 같은 기능을 제공합니다. 잇다 데이터를 시각화하고 ADA 데이터 제품에서 보고서를 생성하기 위한 타사 BI 도구. 이 데모에서는 Tableau와 ADA의 기본 통합을 사용하여 이전에 구성한 세 가지 데이터 제품의 데이터를 시각화합니다. Tableau의 Athena 커넥터를 사용하고 다음 단계를 따르세요. Tableau 구성을 사용하면 Tableau에서 ADA를 데이터 원본으로 구성할 수 있습니다. Tableau와 ADA 간에 성공적인 연결이 설정된 후 Tableau는 Tableau 카탈로그 아래에 세 가지 데이터 제품을 채웁니다. cw_domain.
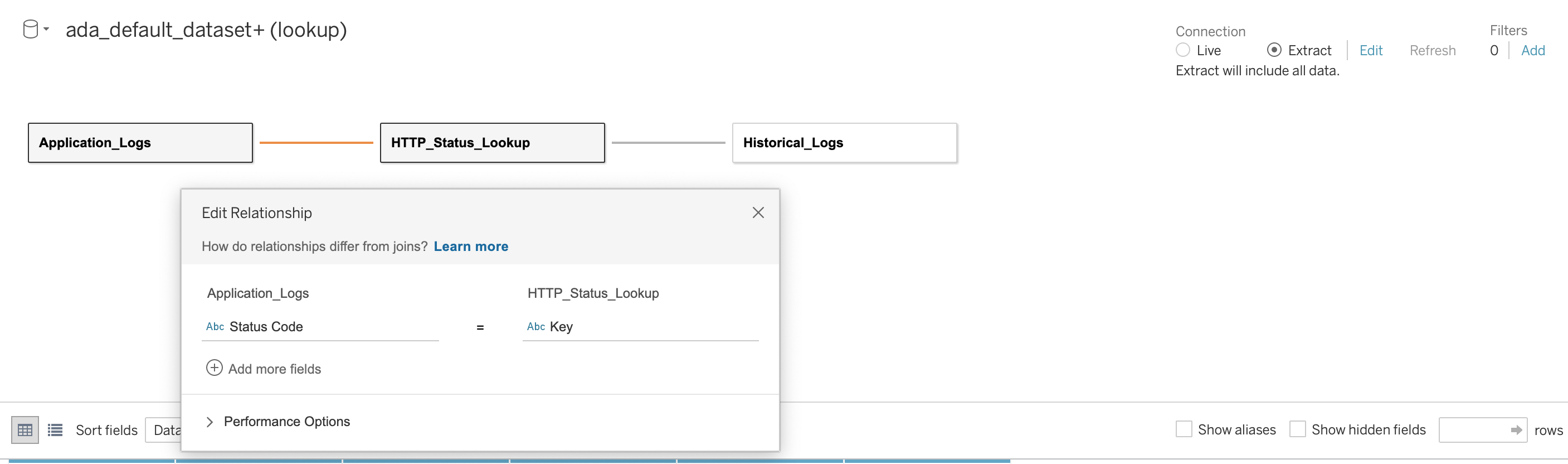
그런 다음 다음 스크린샷과 같이 HTTP 상태 코드를 조인 열로 사용하여 세 데이터베이스 간에 관계를 설정합니다. Tableau를 사용하면 데이터 원본을 온라인 및 오프라인 모드로 작업할 수 있습니다. 온라인 모드에서 Tableau는 ADA에 연결하고 데이터 제품을 실시간으로 쿼리합니다. 오프라인 모드에서는 다음을 사용할 수 있습니다. 발췌 ADA에서 데이터를 추출하고 Tableau로 데이터를 가져오는 옵션입니다. 이 데모에서는 쿼리 응답성을 높이기 위해 데이터를 Tableau로 가져옵니다. 그런 다음 Tableau 통합 문서를 저장합니다. 데이터베이스를 선택하여 데이터 소스의 데이터를 검사할 수 있습니다. 지금 업데이트.
Tableau에 데이터 원본 구성이 있으면 ADA 데이터 제품에 대한 사용자 지정 보고서, 차트 및 시각화를 만들 수 있습니다. 시각화에 대한 두 가지 사용 사례를 고려해 보겠습니다.
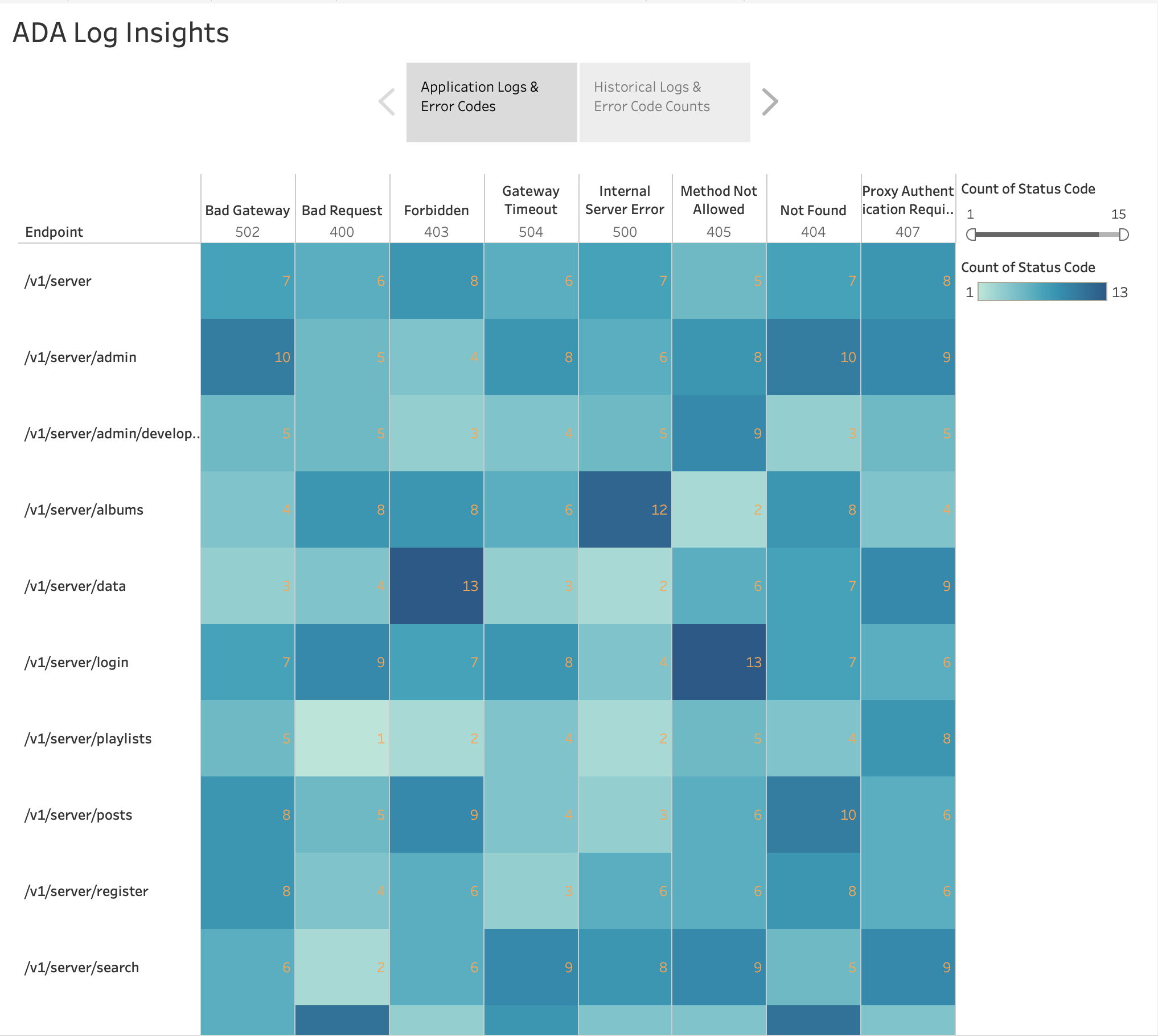
다음 그림과 같이 Tableau의 기본 제공 기능을 사용하여 응용 프로그램 끝점별 HTTP 오류 빈도를 시각화했습니다. 열지도 차트. 4xx 및 5xx 범위의 오류 코드만 포함하도록 HTTP 상태 코드를 필터링했습니다.
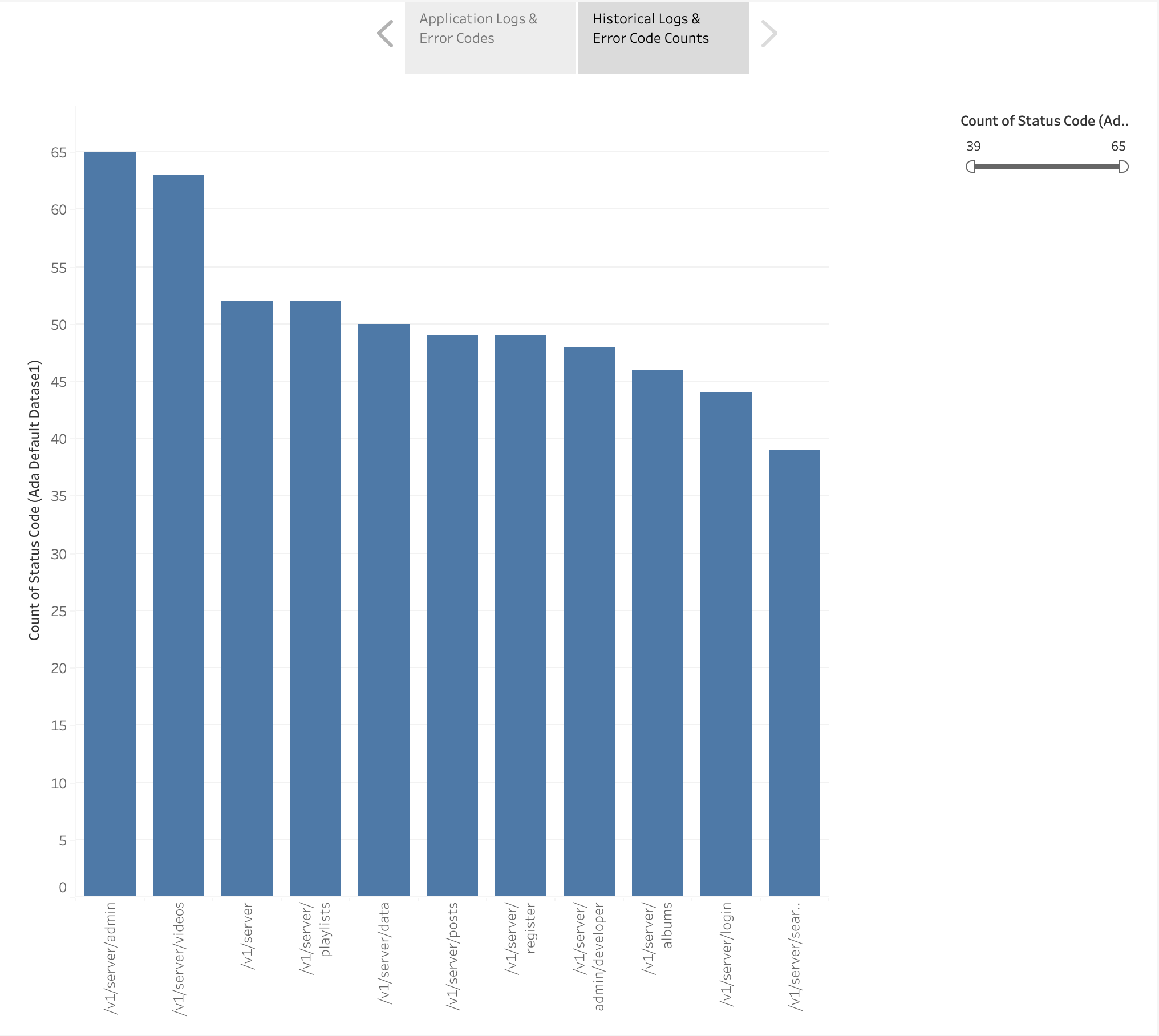
또한 HTTP 오류 코드 수에 따라 정렬된 기록 로그의 애플리케이션 엔드포인트를 설명하는 막대형 차트도 만들었습니다. 이 차트에서 우리는 /v1/server/admin 엔드포인트가 가장 많은 HTTP 오류 상태 코드를 생성했습니다.
정리
샘플 애플리케이션 인프라 정리는 XNUMX단계 프로세스로 이루어집니다. 먼저 이 데모의 목적을 위해 프로비저닝된 인프라를 제거하려면 터미널에서 다음 명령을 실행합니다.
다음 질문에 y를 입력하면 AWS CDK가 데모용으로 배포된 리소스를 삭제합니다.
또는 CdkStack 스택으로 이동하고 다음을 선택하여 AWS CloudFormation 콘솔을 통해 리소스를 제거할 수 있습니다. ..
두 번째 단계는 ADA를 제거하는 것입니다. 지침은 다음을 참조하세요. 솔루션 제거.
결론
이 게시물에서는 ADA 솔루션을 사용하여 두 개의 서로 다른 데이터 소스에 저장된 애플리케이션 로그에서 통찰력을 얻는 방법을 시연했습니다. AWS 계정에 ADA를 설치하고 AWS CDK를 사용하여 데모 구성 요소를 배포하는 방법을 시연했습니다. 우리는 ADA에서 데이터 제품을 생성하고 ADA에 내장된 데이터 커넥터를 사용하여 해당 데이터 소스로 데이터 제품을 구성했습니다. 표준 SQL 쿼리를 사용하여 데이터 제품을 쿼리하고 로그 데이터에 대한 통찰력을 생성하는 방법을 시연했습니다. 또한 타사 BI 제품인 Tableau Desktop 클라이언트를 ADA에 연결하고 데이터 제품에 대한 시각화를 구축하는 방법을 시연했습니다.
ADA는 다양한 데이터 세트를 수집, 변환, 관리 및 쿼리하는 프로세스를 자동화하고 데이터의 수명 주기 관리를 단순화합니다. ADA의 사전 구축된 커넥터를 사용하면 다양한 데이터 소스에서 데이터를 수집할 수 있습니다. AWS 제품 및 서비스에 대한 기본 지식을 갖춘 소프트웨어 팀은 몇 시간 내에 운영 데이터 분석 플랫폼을 설정하고 데이터에 대한 안전한 액세스를 제공할 수 있습니다. 그런 다음 직관적인 독립형 웹 사용자 인터페이스를 사용하여 데이터를 쉽고 빠르게 쿼리할 수 있습니다.
지금 ADA를 사용해 데이터를 쉽게 관리하고 통찰력을 얻으세요.
저자 소개
 아파라지탄 바이디야나단 AWS의 수석 엔터프라이즈 솔루션 아키텍트입니다. 그는 엔터프라이즈 고객이 AWS 클라우드에서 워크로드를 마이그레이션하고 현대화하도록 지원합니다. 엔터프라이즈, 대규모 및 분산 소프트웨어 시스템을 설계하고 개발한 경력이 23년 이상인 클라우드 설계자입니다. 그는 데이터 및 기능 엔지니어링 도메인에 중점을 둔 기계 학습 및 데이터 분석을 전문으로 합니다. 그는 야심 찬 마라톤 선수이며 취미로는 하이킹, 자전거 타기, 아내 및 두 아들과 시간 보내기 등이 있습니다.
아파라지탄 바이디야나단 AWS의 수석 엔터프라이즈 솔루션 아키텍트입니다. 그는 엔터프라이즈 고객이 AWS 클라우드에서 워크로드를 마이그레이션하고 현대화하도록 지원합니다. 엔터프라이즈, 대규모 및 분산 소프트웨어 시스템을 설계하고 개발한 경력이 23년 이상인 클라우드 설계자입니다. 그는 데이터 및 기능 엔지니어링 도메인에 중점을 둔 기계 학습 및 데이터 분석을 전문으로 합니다. 그는 야심 찬 마라톤 선수이며 취미로는 하이킹, 자전거 타기, 아내 및 두 아들과 시간 보내기 등이 있습니다.
 라심 라만 는 호주 시드니에 본사를 둔 소프트웨어 개발자로, 소프트웨어 개발 및 아키텍처 분야에서 10년 이상의 경력을 갖고 있습니다. 그는 주로 일반적인 고객 사용 사례와 비즈니스 문제를 위한 대규모 오픈 소스 AWS 솔루션을 구축하는 일을 하고 있습니다. 여가 시간에는 스포츠를 즐기고 친구 및 가족과 함께 시간을 보냅니다.
라심 라만 는 호주 시드니에 본사를 둔 소프트웨어 개발자로, 소프트웨어 개발 및 아키텍처 분야에서 10년 이상의 경력을 갖고 있습니다. 그는 주로 일반적인 고객 사용 사례와 비즈니스 문제를 위한 대규모 오픈 소스 AWS 솔루션을 구축하는 일을 하고 있습니다. 여가 시간에는 스포츠를 즐기고 친구 및 가족과 함께 시간을 보냅니다.
 하피즈 사둘라 Amazon Web Services의 수석 기술 제품 관리자입니다. Hafiz는 일반적인 비즈니스 문제와 사용 사례를 해결하여 고객을 지원하도록 설계된 AWS 솔루션에 중점을 둡니다.
하피즈 사둘라 Amazon Web Services의 수석 기술 제품 관리자입니다. Hafiz는 일반적인 비즈니스 문제와 사용 사례를 해결하여 고객을 지원하도록 설계된 AWS 솔루션에 중점을 둡니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- PlatoHealth. 생명 공학 및 임상 시험 인텔리전스. 여기에서 액세스하십시오.
- 차트프라임. ChartPrime으로 트레이딩 게임을 향상시키십시오. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :있다
- :이다
- :아니
- :어디
- $UP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- 능력
- 할 수 있는
- 소개
- ACCESS
- 액세스
- 얻기 쉬운
- 계정
- 가로질러
- 행위
- ADA
- 더하다
- 또한
- 추가
- 주소 지정
- 관리자
- 후
- 반대
- All
- 수
- 수
- 따라
- 또한
- 대안
- 아마존
- Amazon Web Services
- 중
- an
- 분석
- 애널리스트
- 분석
- 분석하다
- 및
- 다른
- 어떤
- 아파치
- API를
- API
- 어플리케이션
- 어플리케이션
- 적용된
- 신청
- 적용
- 아키텍처
- 있군요
- AS
- 열망하는
- At
- 속성
- 호주
- 인증
- 허가
- 자동화
- 오토마타
- 자동적으로
- 가능
- AWS
- AWS 클라우드 포메이션
- 뒤로
- 백엔드
- 바
- 기반으로
- 기본
- BE
- 때문에
- 된
- 전에
- 주문품
- 사이에
- 두
- 보물상자
- 빌드
- 건물
- 내장
- 사업
- 비즈니스 인텔리전스
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- 전화
- CAN
- 능력
- 케이스
- 가지 경우
- 목록
- CD
- 이전 단계로 돌아가기
- 거래차트
- 차트
- 왼쪽 메뉴에서
- 선택
- 클라이언트
- 클라우드
- 암호
- 코드
- 수집
- 단
- 열
- 공통의
- 완전한
- 구성 요소들
- 구성
- 구성
- 연결하기
- 연결
- 연결
- 커넥트
- 고려
- 일관된
- 콘솔에서
- 이 포함되어 있습니다
- 계속
- 상관 관계
- 상관 관계
- 동
- 대응
- 비용
- 만들
- 만든
- 생성
- 만들기
- 신임장
- Current
- 관습
- 고객
- 고객
- 계기반
- 데이터
- 데이터 분석
- 데이터 처리
- 데이터베이스
- 데이터베이스
- 데이터 세트
- 태만
- 수요
- Rescale과 함께 비즈니스를 가속화하는 방법에 대해 알아보세요.
- 보여
- 시연
- 의존
- 배포
- 배포
- 전개
- 배치하다
- 설명
- 설계
- 설계
- 바탕 화면
- 상세한
- 세부설명
- 개발자
- 개발
- 개발
- 진단
- 다른
- 직접
- 사용
- 발견
- 디스플레이
- 분산
- 몇몇의
- 하지 않습니다
- 도메인
- 도메인
- 말라
- 떨어 뜨린
- ...동안
- 마다
- 이전
- 용이하게
- 편집
- 중
- 이메일
- 사용 가능
- 수
- 종점
- 엔드 포인트
- 엔지니어링
- 확인
- 엔터 버튼
- Enterprise
- 기업 고객
- 기업 솔루션
- 오류
- 오류
- 세우다
- 확립 된
- 에테르 (ETH)
- 예
- 현존하는
- 경험
- 설명
- 설명
- 추출물
- 데이터 추출
- 익숙한
- 가족
- 특색
- 를
- 들
- Fields
- 그림
- 입양 부모로서의 귀하의 적합성을 결정하기 위해 미국 이민국에
- 파일
- 최후의
- 재원
- 먼저,
- 융통성있는
- 초점
- 집중
- 수행원
- 럭셔리
- 체재
- 사
- 진동수
- 친구
- 에
- 기능
- 이득
- 생성
- 생성
- 얻을
- 점점
- 통치
- 그룹
- 여러 떼
- 있다
- 데
- he
- 도움
- 강조
- 하이킹
- 그의
- 역사적인
- 취미
- 호스팅
- 진료 시간
- 방법
- How To
- 그러나
- HTML
- HTTP
- HTTPS
- IAM
- 같은
- 확인
- 통합 인증
- if
- import
- in
- 포함
- 포함
- 포함
- 정보
- 인프라
- 처음에는
- 통찰력
- 설치
- 설치
- 명령
- 통합 된
- 완성
- 인텔리전스
- 대화형
- 관심있는
- 인터페이스
- 으로
- 직관적인
- 호출
- 참여
- 발행물
- IT
- 어울리다
- 가입
- 조인
- JPG
- JSON
- 다만
- 유지
- 키
- 지식
- 언어
- 넓은
- 대규모
- 성
- 후에
- 진수
- 배우기
- 도서관
- 라이센스
- wifecycwe
- 처럼
- 제한
- 라인
- 명부
- 살고있다
- 기록
- 로깅
- 긴
- 보기
- 조회
- 기계
- 기계 학습
- 확인
- 유튜브 영상을 만드는 것은
- 관리
- 구축
- 매니저
- .
- 지도
- 매핑
- 마라톤
- 마케팅
- 문제
- 의미있는
- 메시지
- MFA
- 수도
- 이전
- 분
- 모드
- 현대화
- 배우기
- 가장
- 대개
- 모질라
- 다중 요소 인증
- MySQL의
- name
- 이름
- 이름
- 출신
- 이동
- 탐색
- 카테고리
- 필요
- 필요
- 요구
- 신제품
- 새로운
- 다음 것
- 번호
- of
- 제공
- 오프라인
- 낡은
- on
- 온디맨드
- ONE
- 온라인
- 만
- 열 수
- 오픈 소스
- 운영
- 선택권
- or
- 주문
- 기타
- 기타
- 아웃
- 출력
- 개요
- 페이지
- 빵
- 비밀번호
- 통로
- 무늬
- 수행
- 권한
- 몸소
- 전화
- pii
- 관로
- 장소
- 평원
- 계획
- 플랫폼
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 정책
- 포털
- 게시하다
- Postgresql
- powered
- Prepare
- 준비하다
- 전제 조건
- 제시
- 선물
- 시사
- 너무 이른
- 주로
- 교장
- 이전에
- 문제
- 진행
- 방법
- 처리
- 프로세스
- 처리
- 생산
- 프로덕트
- 제품 관리자
- 제품
- 제품 및 서비스
- 프로그램
- 프로젝트
- 제공
- 제공
- 공급자
- 제공
- 목적
- 목적
- Python
- 쿼리
- 문제
- 빨리
- 범위
- 읽기
- 준비
- 받다
- 기록
- 참조
- 지방
- 관계
- 관련된
- 제거
- 반복
- 보고서
- 의뢰
- 필수
- 제품 자료
- 그
- 반응
- 결과
- 유지
- 리뷰
- 승마
- 역할
- 뿌리
- 통치
- 달리기
- 러너
- 달리는
- 판매
- 같은
- 찜하기
- 규모
- 시나리오
- 예약
- 범위
- 검색
- 둘째
- 섹션
- 안전해야합니다.
- 보안
- 참조
- 선택된
- 선택
- 보내다
- 전송
- 별도의
- 서브
- 서버리스
- 서비스
- 서비스
- 세트
- 설정
- 공유
- 공유
- 짧은
- 표시
- 쇼
- 단순, 간단, 편리
- 단순화
- 단순화
- 크기
- 기술
- So
- 소프트웨어
- 소프트웨어 개발
- 해결책
- 솔루션
- 출처
- 지우면 좋을거같음 . SM
- 전문가
- 전문적으로
- 구체적인
- 지정
- 지출
- 스포츠
- SQL
- 스택
- 독립
- 표준
- 스타트
- 시작
- Status
- 단계
- 단계
- 저장
- 저장
- 끈
- 구조화
- 성공한
- 성공적으로
- 이러한
- 지원
- 확인
- 시드니
- 시스템은
- 테이블
- Tableau
- 받아
- 소요
- 팀
- 팀
- 테크니컬
- 기술 능력
- 단말기
- 그
- XNUMXD덴탈의
- 소스
- 그들의
- 그때
- 그곳에.
- Bowman의
- 타사
- 이
- 세
- 을 통하여
- 시간
- 에
- 오늘
- 검색을
- 상단
- 최고 10
- 금액
- 변환
- 변환
- 변환
- 변환
- 변화
- 변환
- 방아쇠를 당긴
- 두
- 유형
- 유형
- 아래에
- 밑에 있는
- 이해
- 업데이트
- 업데이트
- ...에
- URI
- us
- 사용
- 유스 케이스
- 익숙한
- 사용자
- 시간을 아껴주는 인터페이스
- 사용자
- 사용
- 마케팅은:
- 변수
- 종류
- 버전
- 를 통해
- 관측
- 필요
- 방법..
- we
- 웹
- 웹 서비스
- 잘
- 언제
- 어느
- 동안
- 넓은
- 넓은 범위
- 아내
- 의지
- 과
- 이내
- 없이
- 작업
- 워크플로우
- 일
- 겠지
- 쓰다
- 년
- 당신
- 너의
- 제퍼 넷