
작성자 별 이미지
데이터를 분석하면서 우리가 염두에 두는 것은 숨겨진 패턴을 찾고, 의미 있는 인사이트를 추출하는 것입니다. 클러스터링 작업을 해결하는 강력한 알고리즘 중 하나가 데이터 이해를 혁신하는 K-Means 클러스터링 알고리즘인 ML 기반 학습의 새로운 범주, 즉 비지도 학습에 대해 살펴보겠습니다.
K-Means has become a useful algorithm in machine learning and data mining applications. In this article, we will deep dive into the workings of K-Means, its implementation using Python, and exploring its principles, applications, etc. So, let’s start the journey to unlock the secret patterns and harness the potential of the K-Means clustering algorithm.
K-Means 알고리즘은 비지도 학습 클래스에 속하는 클러스터링 문제를 해결하는 데 사용됩니다. 이 알고리즘의 도움으로 관측치 수를 K개의 클러스터로 그룹화할 수 있습니다.
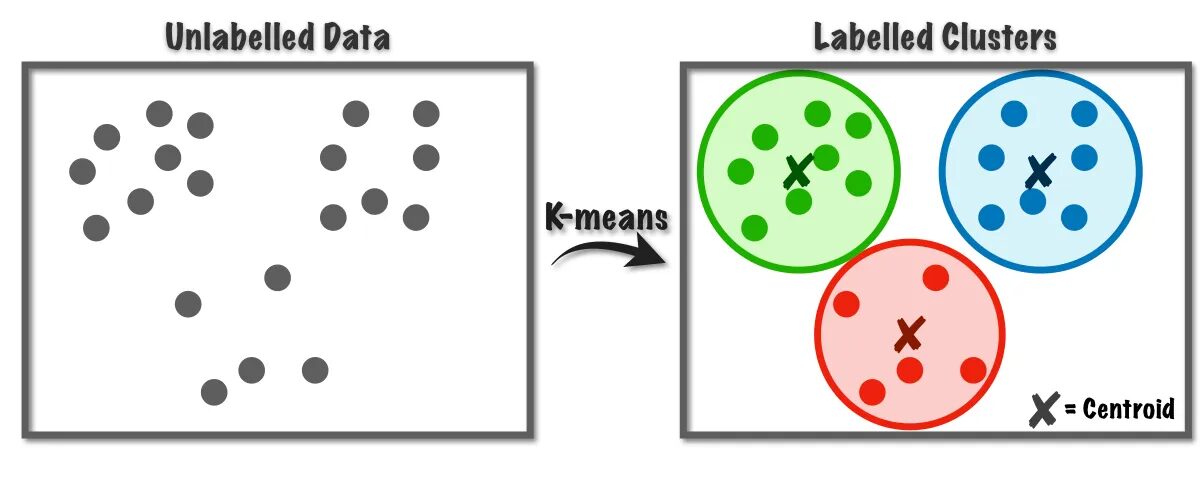
그림 1 K-평균 알고리즘 작동 | 이미지 출처: 데이터 과학을 향해
이 알고리즘은 내부적으로 벡터 양자화를 사용하는데, 이를 통해 데이터 세트의 각 관측값을 최소 거리를 가진 클러스터에 할당할 수 있으며, 이는 클러스터링 알고리즘의 프로토타입입니다. 이 클러스터링 알고리즘은 유사성 메트릭을 기반으로 K 클러스터로 데이터를 분할하기 위한 데이터 마이닝 및 기계 학습에 일반적으로 사용됩니다. 따라서 이 알고리즘에서는 관측값과 해당 중심 사이의 거리 제곱합을 최소화해야 하며, 이로 인해 결국 뚜렷하고 동질적인 클러스터가 생성됩니다.
K-평균 클러스터링의 응용
다음은 이 알고리즘의 표준 응용 프로그램 중 일부입니다. K-평균 알고리즘은 클러스터링 관련 문제를 해결하기 위해 산업계에서 일반적으로 사용되는 기술입니다.
- 고객 세분화: K-평균 클러스터링은 관심 분야에 따라 다양한 고객을 분류할 수 있습니다. 은행, 통신, 전자상거래, 스포츠, 광고, 판매 등에 적용할 수 있습니다.
- 문서 클러스터링: 이 기술에서는 문서 세트에서 유사한 문서를 모아 동일한 클러스터에 유사한 문서를 생성합니다.
- 추천 엔진: 때때로 K-평균 클러스터링을 사용하여 추천 시스템을 만들 수 있습니다. 예를 들어, 친구에게 노래를 추천하고 싶습니다. 그 사람이 좋아하는 노래를 살펴본 후 클러스터링을 이용하여 비슷한 노래를 찾고, 가장 유사한 노래를 추천할 수 있습니다.
이미 생각해 보신 응용 프로그램이 더 많이 있을 것입니다. 이 응용 프로그램은 아마도 이 기사 아래의 댓글 섹션에서 공유하실 것입니다.
이 섹션에서는 주로 데이터 과학 프로젝트에 사용되는 Python을 사용하여 데이터 세트 중 하나에 K-Means 알고리즘을 구현하기 시작합니다.
1. 필요한 라이브러리 및 종속성 가져오기
먼저 NumPy, Pandas, Seaborn, Marplotlib 등 K-평균 알고리즘을 구현하는 데 사용하는 Python 라이브러리를 가져옵니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. 데이터 세트 로드 및 분석
이 단계에서는 Pandas 데이터 프레임에 저장하여 학생 데이터 세트를 로드합니다. 데이터세트를 다운로드하려면 링크를 참조하세요. 여기에서 지금 확인해 보세요..
문제의 전체 파이프라인은 다음과 같습니다.

그림 2 프로젝트 파이프라인 | 작성자별 이미지
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. 데이터 세트의 산점도
이제 모델링 단계는 데이터를 시각화하는 것이므로 matplotlib를 사용하여 산점도를 그려 클러스터링 알고리즘이 어떻게 작동하는지 확인하고 다른 클러스터를 생성합니다.
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
출력:
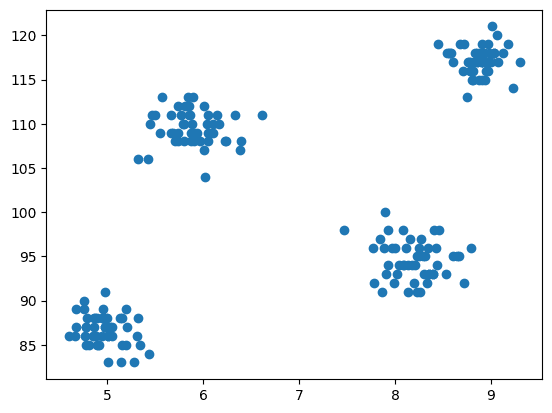
그림 3 산점도 | 작성자별 이미지
4. Scikit-learn의 클러스터 클래스에서 K-Means 가져오기
이제 K-Means 클러스터링을 구현해야 하므로 먼저 클러스터 클래스를 가져온 다음 KMeans를 해당 클래스의 모듈로 사용합니다.
from sklearn.cluster import KMeans5. Elbow Method를 이용한 K의 최적값 찾기
이번 단계에서는 알고리즘을 구현하면서 하이퍼파라미터 중 하나인 K의 최적값을 찾아보겠습니다. K 값은 데이터 세트에 대해 생성해야 하는 클러스터 수를 나타냅니다. 이 값을 직관적으로 찾는 것은 불가능하므로 최적의 값을 찾기 위해 WCSS(in-cluster-sum-of-squares)와 다양한 K 값 간의 플롯을 생성하고 해당 K를 선택해야 합니다. WCSS의 최소값을 제공합니다.
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
이제 K의 최적값을 찾기 위해 엘보우 플롯을 그려보겠습니다.
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
출력:
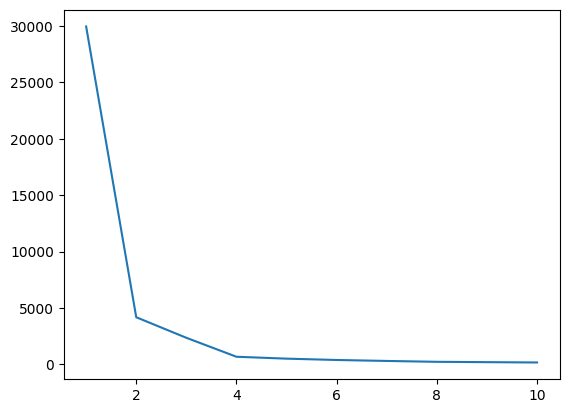
그림 4 엘보우 플롯 | 작성자별 이미지
위의 엘보우 플롯에서 K=4를 볼 수 있습니다. WCSS 값에 하락이 있습니다. 즉, 최적 값을 4로 사용하면 클러스터링이 좋은 성능을 제공할 것입니다.
6. K-Means 알고리즘을 K의 최적값에 맞춥니다.
K의 최적 값을 찾는 작업은 끝났습니다. 이제 모든 기능을 포함하는 전체 데이터 세트를 저장하는 X 배열을 생성하는 모델링을 수행하겠습니다. 비지도 문제이므로 여기서는 대상 벡터와 특징 벡터를 분리할 필요가 없습니다. 그런 다음 선택한 K 값을 사용하여 KMeans 클래스의 개체를 만든 다음 이를 제공된 데이터 세트에 맞춥니다. 마지막으로, 형성된 다양한 클러스터의 평균을 나타내는 y_means를 인쇄합니다.
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. 각 Category의 Cluster Assignment를 확인하세요.
데이터 세트의 모든 포인트가 어떤 클러스터에 속하는지 확인해 보겠습니다.
X[y_means == 3,1]
지금까지는 중심 초기화를 위해 K-Means++ 전략을 사용했습니다. 이제 K-Means++ 대신 임의의 중심을 초기화하고 동일한 프로세스를 따라 결과를 비교해 보겠습니다.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
몇 개의 값이 일치하는지 확인하세요.
sum(y_means == y_means_new)8. 클러스터 시각화
각 클러스터를 시각화하기 위해 축에 플롯하고 서로 다른 색상을 지정하여 4개의 클러스터가 형성된 것을 쉽게 볼 수 있습니다.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
출력:
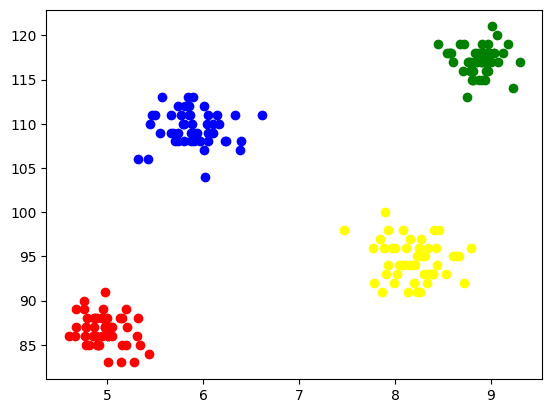
그림 5 형성된 클러스터의 시각화 | 작성자별 이미지
9. 3D 데이터의 K-평균
이전 데이터세트에는 2개의 열이 있으므로 2차원 문제가 발생합니다. 이제 3차원 문제에 대해 동일한 단계 세트를 활용하고 n차원 데이터에 대한 코드 재현성을 분석해 보겠습니다.
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
출력:
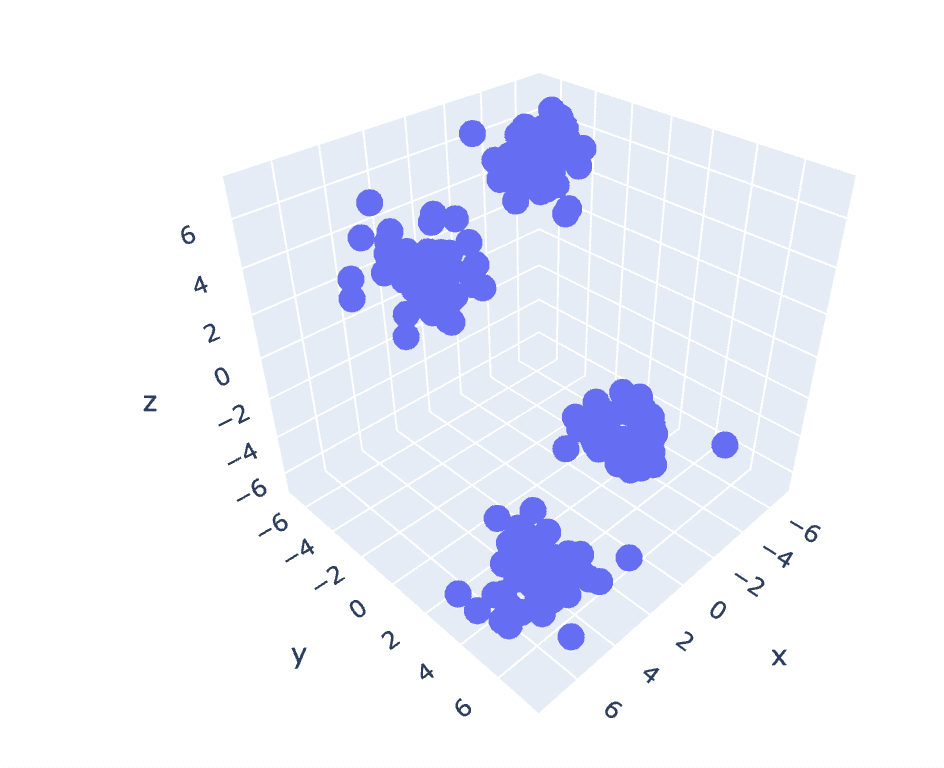
그림 6 3차원 데이터세트의 산점도 | 작성자별 이미지
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
출력:

그림 7 엘보우 플롯 | 작성자별 이미지
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
출력:
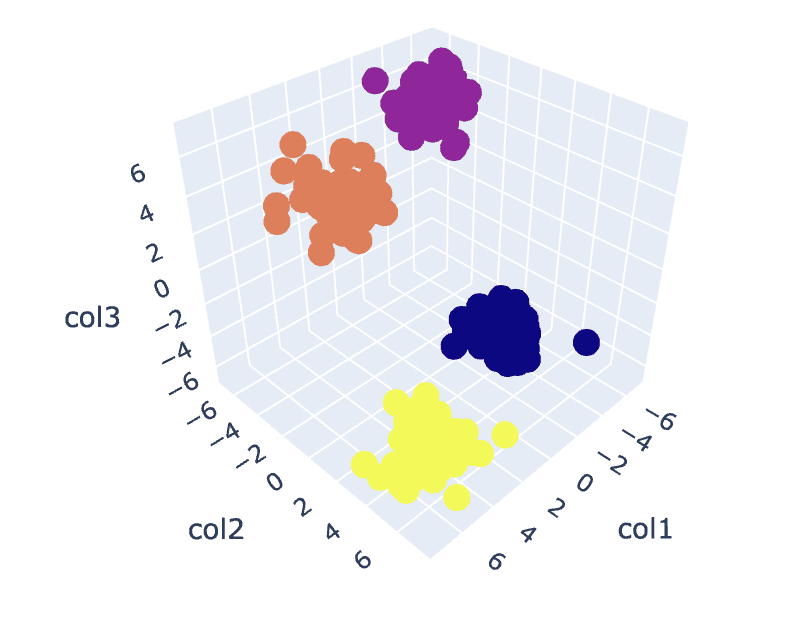
그림 8. 클러스터 시각화 | 작성자별 이미지
You can find the complete code here – Colab 노트북
이것으로 우리의 논의가 끝났습니다. 우리는 K-Means의 작동, 구현 및 적용에 대해 논의했습니다. 결론적으로, 클러스터링 작업을 구현하는 것은 데이터 세트의 관찰을 그룹화하는 간단하고 직관적인 접근 방식을 제공하는 비지도 학습 클래스에서 널리 사용되는 알고리즘입니다. 이 알고리즘의 주요 강점은 알고리즘을 구현하는 사용자의 도움을 받아 선택된 유사성 측정항목을 기반으로 관찰 결과를 여러 세트로 나누는 것입니다.
그러나 첫 번째 단계에서 중심을 선택하면 알고리즘이 다르게 동작하여 로컬 또는 전역 최적값으로 수렴됩니다. 따라서 알고리즘을 구현할 클러스터 수를 선택하고 데이터 전처리, 이상값 처리 등의 작업이 좋은 결과를 얻는 데 중요합니다. 하지만 이 알고리즘의 한계 뒤에 있는 이면을 살펴보면 K-Means는 다양한 분야의 탐색적 데이터 분석 및 패턴 인식에 유용한 기술입니다.
아리안 가르그 비텍입니다. 전기 공학 학생, 현재 학부 마지막 학년입니다. 그의 관심은 웹 개발 및 기계 학습 분야에 있습니다. 그는 이러한 관심을 추구해 왔으며 이러한 방향으로 더 많은 일을 하고자 합니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoData.Network 수직 생성 Ai. 자신에게 권한을 부여하십시오. 여기에서 액세스하십시오.
- PlatoAiStream. 웹3 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 플라톤ESG. 자동차 / EV, 탄소, 클린테크, 에너지, 환경, 태양광, 폐기물 관리. 여기에서 액세스하십시오.
- BlockOffsets. 환경 오프셋 소유권 현대화. 여기에서 액세스하십시오.
- 출처: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- :있다
- :이다
- :아니
- :어디
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- 위의
- 광고
- 후
- 연산
- 알고리즘
- All
- 이미
- am
- an
- 분석하다
- 분석
- 분석하다
- 분석하는
- 및
- 어플리케이션
- 적용된
- 접근
- 있군요
- 배열
- 기사
- AS
- At
- 축
- b
- 은행
- 기반으로
- BE
- 가
- 뒤에
- 이하
- 사이에
- 파란색
- 건물
- 비자 면제 프로그램에 해당하는 국가의 시민권을 가지고 있지만
- by
- CAN
- 케이스
- 가지 경우
- 범주
- 검사
- 왼쪽 메뉴에서
- 수업
- 클럽
- 클러스터
- 클러스터링
- 암호
- 열
- 제공
- 댓글
- 일반적으로
- 비교
- 완전한
- 완료
- 결론
- 동
- 만들
- 결정적인
- 현재
- 고객
- 고객
- 데이터
- 데이터 분석
- 데이터 마이닝
- 데이터 과학
- 데이터 세트
- 깊은
- 심해 잠수
- 개발
- 다른
- 찍어
- 사용법
- 논의 된
- 토론
- 거리
- 뚜렷한
- do
- 문서
- 서류
- 한
- 다운로드
- 무승부
- e
- 전자 상거래
- 마다
- 심한
- 용이하게
- 전기 공학
- 엔지니어링
- 엔진
- 엔터 버튼
- 등
- 있을뿐만 아니라
- 예
- 탐색 적 데이터 분석
- 탐색
- 급행
- 추출물
- 특색
- 특징
- 들
- Fields
- 무화과
- 최후의
- 최종적으로
- Find
- 발견
- 먼저,
- 맞게
- 수행원
- 럭셔리
- 형성
- 친구
- 에
- 주기
- 제공
- 글로벌
- 가는
- 좋은
- 구글
- 초록색
- 그룹
- 처리
- 마구
- 있다
- 데
- he
- 도움
- 도움이
- 여기에서 지금 확인해 보세요.
- 숨겨진
- 그의
- 방법
- HTTPS
- i
- if
- 영상
- 구현
- 이행
- 구현
- import
- in
- 포함
- 표시
- 산업
- 관성
- 통찰력
- 를 받아야 하는 미국 여행자
- 관심
- 이해
- 내부로
- 으로
- 직관적인
- IT
- 그
- 여행
- JPG
- 너 겟츠
- 라벨
- 배우기
- 도서관
- 거짓
- 한계
- LINK
- 링크드인
- 명부
- 하중
- 지방의
- 보기
- 기계
- 기계 학습
- 본관
- 주로
- 확인
- .
- 경기
- 매트플롯립
- 의미있는
- 방법
- 통계
- 신경
- 최저한의
- 채굴
- 모델
- 모델링
- 모듈
- 배우기
- 가장
- 여러
- 절대로 필요한 것
- 필요한
- 필요
- 신제품
- 아니
- 지금
- 번호
- numpy
- 대상
- 관찰
- 획득
- of
- on
- ONE
- 사람
- 최적의
- or
- 기타
- 우리의
- 팬더
- 패스
- 무늬
- 패턴
- 성능
- 사람
- 관로
- 플라톤
- 플라톤 데이터 인텔리전스
- 플라토데이터
- 전철기
- 가능한
- 가능성
- 강한
- 너무 이른
- 원칙
- 인쇄
- 아마
- 문제
- 문제
- 방법
- 프로젝트
- 프로젝트
- 프로토 타입
- 제공
- 제공
- Python
- 닥치는대로의
- 인식
- 권하다
- 추천
- 빨간색
- 연구
- 결과
- 결과
- 혁명을 일으키다
- s
- 판매
- 같은
- 과학
- Seaborn
- 비밀
- 섹션
- 참조
- 분절
- 분할
- 선택된
- 선택
- 선택
- 별도의
- 세트
- 설정
- 셰이프
- 공유
- 표시
- 측면
- 의미
- 비슷한
- 단순, 간단, 편리
- So
- 풀다
- 해결
- 일부
- 스포츠
- 사각형
- 표준
- 스타트
- 단계
- 단계
- 저장
- 상점
- 전략
- 힘
- 학생
- 확인
- 인조
- 시스템은
- 목표
- 작업
- 기술
- 통신
- 그
- XNUMXD덴탈의
- 그들의
- 그들
- 그때
- 그곳에.
- 따라서
- Bowman의
- 맡은 일
- 이
- 생각
- 을 통하여
- 에
- 시도
- 이해
- 해방
- 잠금을 해제
- 비지도 학습
- us
- 사용
- 익숙한
- 사용자
- 사용
- 사용
- 활용
- 가치
- 마케팅은:
- 여러
- 심상
- vs
- 필요
- we
- 웹
- 웹 개발
- 어느
- 동안
- 누구
- 크게
- 의지
- 과
- 작업
- 일하는
- 작업장
- 일
- X
- year
- 노랑
- 당신
- 너의
- 제퍼 넷








