데이터 과학 파이프라인을 최적화하는 15가지 Python 스니펫
데이터 사이언스 주기를 지원하는 빠른 Python 솔루션입니다.
By 루카스 소아레스, K1 Digital 머신러닝 엔지니어

님이 촬영 한 사진 카를로스 무자 on Unsplash
스니펫이 데이터 과학에 중요한 이유
일상 생활에서 csv 파일 로드에서 데이터 시각화에 이르기까지 동일한 상황을 많이 처리해야 합니다. 그래서 프로세스를 간소화하기 위해 csv 파일 로드에서 데이터 시각화에 이르기까지 다양한 상황에서 유용한 코드 스니펫을 저장하는 습관을 만들었습니다.
이 게시물에서는 데이터 분석 파이프라인의 다양한 측면에 도움이 되는 15개의 코드 스니펫을 공유합니다.
1. glob 및 list comprehension으로 여러 파일 로드
import glob
import pandas as pd
csv_files = glob.glob("path/to/folder/with/csvs/*.csv")
dfs = [pd.read_csv(filename) for filename in csv_files]2. 열 테이블에서 고유한 값 가져오기
import pandas as pd
df = pd.read_csv("path/to/csv/file.csv")
df["Item_Identifier"].unique()array(['FDA15', 'DRC01', 'FDN15', ..., 'NCF55', 'NCW30', 'NCW05'], dtype=object)3. Pandas 데이터 프레임을 나란히 표시
from IPython.display import display_html
from itertools import chain,cycledef display_side_by_side(*args,titles=cycle([''])): # source: https://stackoverflow.com/questions/38783027/jupyter-notebook-display-two-pandas-tables-side-by-side html_str='' for df,title in zip(args, chain(titles,cycle(['</br>'])) ): html_str+='<th style="text-align:center"><td style="vertical-align:top">' html_str+="<br>" html_str+=f'<h2>{title}</h2>' html_str+=df.to_html().replace('table','table style="display:inline"') html_str+='</td></th>' display_html(html_str,raw=True)
df1 = pd.read_csv("file.csv")
df2 = pd.read_csv("file2")
display_side_by_side(df1.head(),df2.head(), titles=['Sales','Advertising'])
### Output
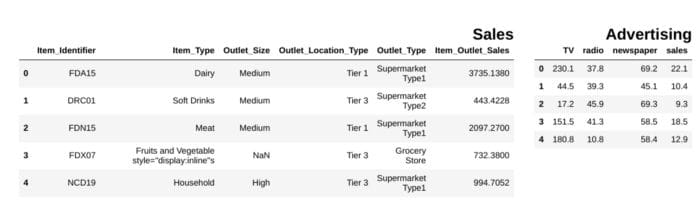
작성자의 이미지
4. pandas 데이터 프레임에서 모든 NaN 제거
df = pd.DataFrame(dict(a=[1,2,3,None]))
df
df.dropna(inplace=True)
df

5. DataFrame 열의 NaN 항목 수 표시
def findNaNCols(df): for col in df: print(f"Column: {col}") num_NaNs = df[col].isnull().sum() print(f"Number of NaNs: {num_NaNs}")
df = pd.DataFrame(dict(a=[1,2,3,None],b=[None,None,5,6]))
findNaNCols(df)# OutputColumn: a
Number of NaNs: 1
Column: b
Number of NaNs: 26. 열 변환 .apply 및 람다 함수
df = pd.DataFrame(dict(a=[10,20,30,40,50]))
square = lambda x: x**2
df["a"]=df["a"].apply(square)
df

7. 2개의 DataFrame 열을 사전으로 변환
df = pd.DataFrame(dict(a=["a","b","c"],b=[1,2,3]))
df_dictionary = dict(zip(df["a"],df["b"]))
df_dictionary{'a': 1, 'b': 2, 'c': 3}8. 열에 조건부 분포 그리드 그리기
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd df = pd.DataFrame(dict(a=np.random.randint(0,100,100),b=np.arange(0,100,1)))
plt.figure(figsize=(15,7))
plt.subplot(1,2,1)
df["b"][df["a"]>50].hist(color="green",label="bigger than 50")
plt.legend()
plt.subplot(1,2,2)
df["b"][df["a"]<50].hist(color="orange",label="smaller than 50")
plt.legend()
plt.show()
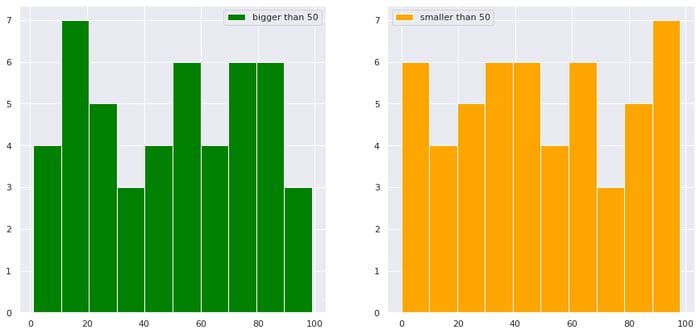
작성자의 이미지
9. pandas의 다른 열 값에 대해 t-테스트 실행
from scipy.stats import ttest_rel data = np.arange(0,1000,1)
data_plus_noise = np.arange(0,1000,1) + np.random.normal(0,1,1000)
df = pd.DataFrame(dict(data=data, data_plus_noise=data_plus_noise))
print(ttest_rel(df["data"],df["data_plus_noise"]))# Output
Ttest_relResult(statistic=-1.2717454718006775, pvalue=0.20375954602300195)10. 주어진 열에 데이터 프레임 병합
df1 = pd.DataFrame(dict(a=[1,2,3],b=[10,20,30],col_to_merge=["a","b","c"]))
df2 = pd.DataFrame(dict(d=[10,20,100],col_to_merge=["a","b","c"]))
df_merged = df1.merge(df2, on='col_to_merge')
df_merged

11. sklearn으로 pandas 열의 값 정규화
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scores = scaler.fit_transform(df["a"].values.reshape(-1,1))12. 팬더의 특정 열에 NaN 삭제
df.dropna(subset=["col_to_remove_NaNs_from"],inplace=True)13. 조건부로 데이터 프레임의 하위 집합 선택 및 or 성명서
df = pd.DataFrame(dict(result=["Pass","Fail","Pass","Fail","Distinction","Distinction"]))
pass_index = (df["result"]=="Pass") | (df["result"]=="Distinction")
df_pass = df[pass_index]
df_pass

14. 기본 파이 차트
import matplotlib.pyplot as plt df = pd.DataFrame(dict(a=[10,20,50,10,10],b=["A","B","C","D","E"]))
labels = df["b"]
sizes = df["a"]
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()

15. 다음을 사용하여 백분율 문자열을 숫자 값으로 변경 .apply()
def change_to_numerical(x): try: x = int(x.strip("%")[:2]) except: x = int(x.strip("%")[:1]) return x df = pd.DataFrame(dict(a=["A","B","C"],col_with_percentage=["10%","70%","20%"]))
df["col_with_percentage"] = df["col_with_percentage"].apply(change_to_numerical)
df

결론
코드 스니펫은 매우 가치가 있다고 생각합니다. 코드를 다시 작성하는 것은 정말 시간 낭비일 수 있으므로 데이터 분석 프로세스를 간소화하는 데 필요한 모든 간단한 솔루션이 포함된 완벽한 툴킷을 갖추는 것이 큰 도움이 될 수 있습니다.
이 게시물이 마음에 들면 나와 연결하십시오. 트위터, 링크드인 그리고 나를 따라와 중급. 감사합니다. 다음에 뵙겠습니다! 🙂
더 많은 콘텐츠 plainenglish.io
바이오 : 루카스 소아레스 광범위한 문제에 대한 딥 러닝 응용 프로그램을 연구하는 AI 엔지니어입니다.
실물. 허가를 받아 다시 게시했습니다.
관련 :
| 지난 30 일 동안의 주요 기사 | |||||
|---|---|---|---|---|---|
|
|
||||
출처: https://www.kdnuggets.com/2021/08/15-python-snippets-optimize-data-science-pipeline.html
더보기 너 겟츠


주요 뉴스, 26월 1일 – XNUMX월 XNUMX일: GitHub Copilot 오픈 소스 대안; "생산적 데이터 과학"을 왜 그리고 어떻게 배워야 합니까?
소스 노드 : 997661
타임 스탬프 : 2년 2021월 XNUMX일


주요 뉴스, 13월 19-XNUMX일: 데이터 엔지니어링 기술이 없는 데이터 과학자는 가혹한 진실에 직면할 것입니다. 기계 및 딥 러닝 개요서 공개
소스 노드 : 1094099
타임 스탬프 : 20년 2021월 XNUMX일

