In 2021 および 2020での新機能について説明しました Amazonレッドシフト これにより、すべてのデータを分析し、豊富で強力な洞察を見つけることがより簡単に、より速く、より費用対効果が高くなります。 2022 年、Amazon Redshift チームが懸命に取り組んでいたことを喜んでご報告いたします。 お客様の要件から逆算して、すべてのデータをより簡単に、より速く、より費用対効果の高い方法で分析できるようにするための複数の新機能を発表しました。 この投稿では、これらの新機能の一部について説明します。
AWS では、データと分析について、私たちの戦略はお客様に 最新のデータアーキテクチャ これにより、データサイロから解放されます。 適切なジョブに適切なツールを使用するための専用のデータ、分析、機械学習 (ML)、および人工知能サービスを用意する。 また、誰もが分析を利用できるようにするために、オープンで管理された安全なフル マネージド サービスを提供します。 AWS の最新のデータ アーキテクチャ内で、クラウド データ ウェアハウスとしての Amazon Redshift は依然として重要なコンポーネントであり、テラバイトからペタバイトの構造化データと非構造化データの規模とパフォーマンスで複雑な SQL 分析を実行し、一般的なビジネス インテリジェンスを通じて洞察を広く利用できるようにします ( BI) と分析ツール。 お客様の要件から逆算して作業を続け、2022 年に Amazon Redshift で 40 を超える機能をリリースし、お客様の主要なデータ ウェアハウジングのユースケースを支援しました。
- セルフサービス分析
- 簡単なデータ取り込み
- データ共有とコラボレーション
- データサイエンスと機械学習
- 安全で信頼性の高い分析
- 最高の価格パフォーマンス分析
これらの分野における Amazon Redshift の新機能について、さらに深く掘り下げて説明しましょう。
セルフサービス分析
お客様からは、データと分析がユビキタスになりつつあり、組織内の誰もが分析を必要としているとの声が寄せられています。 発表しました AmazonRedshiftサーバーレス (プレビュー中) を 2021 年に導入し、データ ウェアハウス インフラストラクチャをプロビジョニングして管理する必要なく、分析を数秒で簡単に実行およびスケーリングできるようにします。 2022 年 XNUMX 月に、 Redshift サーバーレスの一般提供、そしてそれ以来、Peloton、Broadridge Financials、NextGen Healthcare を含む何千もの顧客が、迅速かつ簡単にデータを分析するために使用しています。 Amazon Redshift Serverless は、データ ウェアハウスの容量を自動的にプロビジョニングし、インテリジェントにスケーリングして、すべての分析に高いパフォーマンスを提供します。料金は、ワークロードの期間中に使用されたコンピューティングに対してのみ秒単位で課金されます。 GA以降、次のような機能を追加しました リソースのタグ付け、簡素化されたモニタリング、および追加の AWS リージョンでの可用性により、請求がさらに簡素化され、世界中のより多くのリージョンにリーチが拡大されます。
2021 年に、Amazon Redshift Query Editor V2 をリリースしました。これは、データ アナリスト、データ サイエンティスト、および開発者が Amazon Redshift データ ウェアハウスおよびデータ レイク内のデータを探索、分析、およびコラボレーションするための無料のウェブベース ツールです。 2022 年に、Query Editor V2 は次のような追加の拡張機能を取得しました。 ノートブックのサポート クエリの作成、整理、および注釈付けのコラボレーションを改善するため。 ユーザーアクセス ID プロバイダー (IdP) 資格情報 シングルサインオン用。 開発者の生産性を向上させるために複数のクエリを同時に実行する機能。
オートノミクスは、ML ベースの最適化を使用してお客様に自己学習および自己最適化データ ウェアハウスを提供するために積極的に取り組んでいるもう 2022 つの分野です。 XNUMX 年に、 自動化されたマテリアライズドビュー (AutoMV) を使用して、マテリアライズド ビューを自動的に作成および維持することにより、ユーザーの手間をかけずにクエリのパフォーマンスを向上させます (合計実行時間を短縮します)。 自動更新、増分更新、マテリアライズド ビューの自動クエリ リライトと組み合わせた AutoMV により、マテリアライズド ビューのメンテナンスが不要になり、パフォーマンスが自動的に向上します。 加えて 自動テーブル最適化 (ATO) スキーマ最適化機能と 自動ワークロード管理 ワークロードを最適化する (自動 WLM) 機能がさらに改善され、クエリのパフォーマンスが向上しました。
簡単なデータ取り込み
お客様からは、トランザクション データベース、データ ウェアハウス、データ レイク、ビッグ データ システムなどの複数のデータ ソースにデータが分散されているとの声が寄せられています。 彼らは、このデータをノーコード/ローコード、ゼロ ETL データ パイプラインと統合したり、このデータを移動せずにその場で分析したりできる柔軟性を望んでいます。 お客様から、現在のデータ パイプラインは複雑で、手動で、硬直的で、遅いため、データのビューが不完全で、一貫性がなく、陳腐であり、洞察が制限されているとの声が寄せられています。 お客様からより良い方法を求められており、データ パイプラインを簡素化および自動化するための多くの新機能を発表できることを嬉しく思います。
Amazon Aurora の Amazon Redshift とのゼロ ETL 統合 (プレビュー) ペタバイト規模のトランザクション データに対してほぼリアルタイムの分析と ML を実行できます。 複数のデータからトランザクション データを作成するためのノーコード ソリューションを提供します。 アマゾンオーロラ Aurora に書き込まれてから数秒以内に Amazon Redshift データ ウェアハウスでデータベースを利用できるようになり、複雑なデータ パイプラインを構築して維持する必要がなくなります。 この機能により、Aurora のお客様は、複雑な SQL 分析、組み込み ML、データ共有、複数のデータ ストアやデータ レイクへのフェデレーション アクセスなどの Amazon Redshift 機能にもアクセスできます。 この機能は、プレビューで利用できるようになりました AmazonAuroraMySQL-互換性のあるエディション バージョン 3 (MySQL 8.0 との互換性あり)、および次のことができます。 プレビューへのアクセスをリクエストする.
Amazon Redshift がサポートされるようになりました Amazon S3 からの自動コピー (プレビュー) からのデータの読み込みを簡素化する Amazon シンプル ストレージ サービス (Amazon S3) を Amazon Redshift に。 追加のツールやカスタム ソリューションを必要とせずに、継続的なファイル インジェスト ルール (コピー ジョブ) を設定して、Amazon S3 パスを追跡し、新しいファイルを自動的にロードできるようになりました。 コピー ジョブはシステム テーブルを介して監視でき、以前に読み込まれたファイルを自動的に追跡し、それらを取り込みプロセスから除外して、データの重複を防ぎます。 この機能はプレビューで利用できるようになりました。 プレビュー トラックを使用して新しいクラスターを作成することで、この機能を試すことができます。
顧客は、即時の、その瞬間の、リアルタイムの分析が必要であると言い続けており、喜んで発表します。 ストリーミング取り込みサポートの一般提供 Amazon Redshift で Amazon Kinesisデータストリーム および ApacheKafkaのAmazonマネージドストリーミング (アマゾン MSK)。 この機能により、ストリーミング データを Amazon Redshift に取り込む前に Amazon S3 でステージングする必要がなくなり、データ ウェアハウスに XNUMX 秒あたり数百メガバイトのストリーミング データを取り込みながら、秒単位の低レイテンシーを実現できます。 Amazon Redshift 内で SQL を使用して、複数の Kinesis データ ストリームまたは MSK トピックに接続してそこからデータを直接取り込み、ストリーム上に変換を使用して自動更新ストリーミング マテリアライズド ビューを作成し、ストリーミング データに直接アクセスし、リアルタイム データを履歴データと組み合わせることができます。より良い洞察のためのデータ。 たとえば、Adobe は、CRM やカスタマー サポート アプリケーションなどのさまざまなアプリケーションの Web およびアプリケーションのクリックストリームとセッション データをリアルタイムで取り込み、分析するために、Adobe Experience Platform の一部として Amazon Redshift ストリーミング インジェストを統合しました。
お客様から、Amazon Redshift、BI および ETL (抽出、変換、ロード) ツール、および Salesforce や Marketo などのビジネス アプリケーション間のシンプルですぐに使える統合が必要であるとの声が寄せられています。 の一般提供を発表できることをうれしく思います。 Amazon Redshift 用の Informatica Data Loaderこれにより、Informatica Data Loader を使用して高速かつ大量のデータを Amazon Redshift に無料でロードできます。 Amazon Redshift コンソールで Informatica Data Loader オプションを選択するだけです。 Informatica Data Loader に入ると、Salesforce や Marketo などのソースに接続し、Amazon Redshift をターゲットとして選択して、データのロードを開始できます。
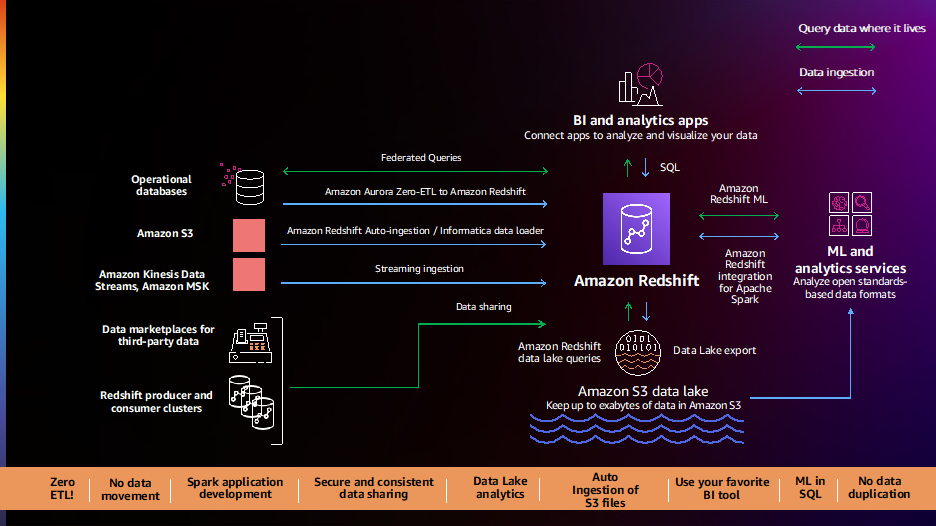
データ共有とコラボレーション
お客様は、ファーストパーティとサードパーティのすべてのデータを分析し、豊富なデータ駆動型の洞察を顧客、パートナー、およびサプライヤーが利用できるようにしたいという声を引き続きいただいています。 2021 年には、次のような新機能をリリースしました。 データ共有 および AWS データ交換の統合、すべてのデータを簡単に分析し、組織内外で共有できるようにします。
データ共有を使用している顧客の好例は、Orion です。 Orion は、資産管理、資産管理、投資管理プロバイダーなどの金融サービス業界の顧客向けに、リアルタイムのサービスとしてのデータ (DaaS) ソリューションを提供しています。 オンプレミスと AWS の両方に存在する主に SQL Server データベースである 2,500 を超えるデータ ソースがあります。 データは Kafka コネクタを使用して Amazon Redshift にストリーミングされます。 このすべてのデータを受信するプロデューサー クラスターがあり、データ共有を使用してコラボレーションのためにリアルタイムでデータを共有します。 これは、複数のクライアントにサービスを提供するマルチテナント アーキテクチャです。 データの機密性を考えると、データ共有はクラスター間のワークロードの分離を提供し、そのデータをエンド ユーザーに安全に共有する方法でもあります。
2022 年も引き続きこの分野に投資し、パフォーマンス、ガバナンス、開発者の生産性を向上させる新機能を追加して、データの共有とコラボレーションをより簡単、シンプル、迅速に行えるようにしました。
お客様が大規模なデータ共有構成を構築しているため、共有データの簡素化されたガバナンスとセキュリティを求める声がありました。 AWS Lake Formation による集中アクセス制御 Amazon Redshift データ共有用に、複数の Amazon Redshift データ ウェアハウス間でライブ データを共有できるようにします。 この機能により、Amazon Redshift は、Amazon Redshift データ共有の簡素化されたガバナンスをサポートするようになりました。 AWSレイクフォーメーション データまたはデータ共有のアクセス許可を一元管理するための単一の画面として。 Lake Formation API と AWSマネジメントコンソール、および Amazon Redshift データ共有を他の Amazon Redshift データ ウェアハウスで検出して使用できるようにします。
データサイエンスと機械学習
顧客は、ビジネスで何が起こっているか (記述的分析) から、なぜそれが起こっているのか (診断分析)、そして将来何が起こるかまで、データと分析システムが幅広い質問に答えてくれることを望んでいると私たちに言い続けています。 (予測分析)。 Amazon Redshift は、複雑な SQL 分析、データレイク分析、および Amazon Redshift ML お客様がデータを分析し、強力な洞察を発見できるようにします。 赤方偏移ML Amazon Redshift を アマゾンセージメーカーはフルマネージド ML サービスであり、使い慣れた SQL コマンドを使用して ML モデルを作成、トレーニング、デプロイできます。
お客様からも、Amazon Redshift と Apache Spark の統合を改善してほしいという要望がありましたので、発表できることを嬉しく思います。 Apache Spark の Amazon Redshift 統合 Spark ベースのアプリケーションがデータ ウェアハウスに簡単にアクセスできるようにします。 現在、AWS アナリティクスと ML サービスを使用している開発者は、 アマゾンEMR, AWSグルー、および SageMaker は、Amazon Redshift データ ウェアハウスから読み書きする Apache Spark アプリケーションを簡単に構築できます。 Amazon EMR と AWS Glue は Redshift-Spark コネクタをパッケージ化するため、Spark ベースのアプリケーションからデータ ウェアハウスに簡単に接続できます。 関連するデータのみが Amazon Redshift データ ウェアハウスから消費する Spark アプリケーションに移動されるように、並べ替え、集計、制限、結合、スカラー関数などの操作にいくつかのプッシュダウン機能を使用できます。 を利用することで、アプリケーションをより安全にすることもできます AWS IDおよびアクセス管理 (IAM) Amazon Redshift に接続するための認証情報。
安全で信頼性の高い分析
データ ウェアハウスは、高可用性、信頼性、およびセキュリティを必要とするミッション クリティカルなシステムであるというお客様からの声が引き続き寄せられています。 この分野では、2022 年に多くの新機能をリリースしました。
Amazon Redshift がサポートされるようになりました マルチ AZ 配置 (プレビュー中) RA3 インスタンスベースのクラスター用。これにより、データ ウェアハウスを複数の AWS アベイラビリティー ゾーンで同時に実行し、予期しないアベイラビリティー ゾーン全体の障害シナリオでの継続的な運用を可能にします。 Redshift サーバーレスでは、マルチ AZ のサポートが既に利用可能です。 Amazon Redshift のマルチ AZ 配置では、アベイラビリティ ゾーンで障害が発生した場合に、ユーザーの介入なしで復旧できます。 Amazon Redshift マルチ AZ データ ウェアハウスは、XNUMX つのエンドポイントを持つ単一のデータ ウェアハウスとしてアクセスされ、ワークロード処理を複数のアベイラビリティー ゾーンに自動的に分散することでパフォーマンスを最大化するのに役立ちます。 予期しない停止時にビジネスの継続性を維持するためにアプリケーションを変更する必要はありません。
2022 年には、ロールベースのアクセス制御、行レベルのセキュリティ、データ マスキング (プレビュー段階) などの機能をリリースして、アクセスの管理と、個人を特定できる情報 (PII ) クレジット カード番号など。
あなたが使用することができます ロールベースのアクセス制御(RBAC) エンド ユーザーの職務と権限に基づいて、エンド ユーザーによるデータへのアクセスを広範または詳細なレベルで制御します。 RBAC を使用すると、SQL を使用してロールを作成し、詳細なアクセス許可のコレクションをロールに付与して、そのロールをエンド ユーザーに割り当てることができます。 ロールには、オブジェクト レベル、列レベル、およびシステム レベルのアクセス許可を付与できます。 さらに、RBAC は、DBA、オペレーター、セキュリティ管理者、またはカスタマイズされた役割のためのすぐに使えるシステム役割を導入します。
行レベルのセキュリティ(RLS) テーブル内の行へのきめ細かなアクセスの設計と実装を簡素化します。 RLS を使用すると、ユーザーのジョブ ロールまたは SQL の権限に基づいて、テーブル内の行のサブセットへのアクセスを制限できます。
Amazon Redshift のサポート 動的データ マスキング (DDM)現在プレビューで利用できる を使用すると、Amazon Redshift データ ウェアハウスで社会保障番号、クレジット カード番号、電話番号などの PII を簡単に保護できます。 動的データ マスキングを使用すると、クエリ時に Amazon Redshift が機密データをユーザーに返す方法を決定する単純な SQL ベースのマスキング ポリシーを通じて、データへのアクセスを制御できます。 マスキング ポリシーを作成して、一貫性があり、フォーマットが保持され、元に戻せないマスキング データ値を定義できます。 テーブル内の特定の列または列のリストにマスキング ポリシーを適用できます。 また、マスクされたデータの表示方法を柔軟に選択できます。 たとえば、データを完全に非表示にしたり、部分的な実数値をワイルドカード文字に置き換えたり、SQL 式、Python、または AWSラムダ ユーザー定義関数。 さらに、他の列に基づいて条件付きマスキング ポリシーを適用できます。これにより、XNUMX つ以上の異なる列の値に基づいてテーブルの列データが選択的に保護されます。
また、次の機能強化も発表しました。 監査ログ、とのネイティブ統合 Microsoft Azure Active Directory、およびサポート デフォルトのIAMロール 追加のリージョンで、セキュリティ管理をさらに簡素化します。
最高の価格パフォーマンス分析
お客様は、コストを低く抑えながら、あらゆる規模で高いパフォーマンスを提供する、高速で費用対効果の高いデータ ウェアハウスが必要であるという声を引き続きいただいています。 初日から 2012 年の Amazon Redshift のリリース、データ駆動型のアプローチを採用し、フリート テレメトリを使用して、あらゆる規模で最高の価格パフォーマンスを提供するクラウド データ ウェアハウス サービスを構築しました。 何年にもわたって、私たちは進化してきました Amazon Redshift のアーキテクチャ などの機能をリリースしました Redshift マネージド ストレージ (RMS) ストレージとコンピューティングを分離するため、 AmazonRedshiftスペクトラム データレイククエリの場合、 自動テーブル最適化 物理スキーマの最適化のために、 自動ワークロード管理 ワークロードに優先順位を付け、適切なコンピューティングとメモリを割り当てます。 クラスターのサイズ変更 コンピューティングとストレージを垂直方向にスケーリングする 並行性スケーリング 計算を動的にスケールアウトまたはスケールインします。 パフォーマンスベンチマーク Amazon Redshift の価格性能比のリーダーシップを引き続き示します。
2022 年には、 書き込み操作の並行スケーリング COPY、INSERT、UPDATE、および DELETE のように、事実上無制限の同時ユーザーとクエリをサポートします。 また、軽量で CPU 効率が高く、辞書でエンコードされた文字列列に対するベクトル化されたスキャンにより、文字列ベースのデータ処理のパフォーマンスが向上しました。これにより、データベース エンジンは圧縮されたデータを直接操作できます。
次のような SQL 演算子のサポートも追加しました。 MERGE (挿入または更新のための単一の演算子); CONNECY_BY (階層クエリの場合); GROUPING SETS、ROLLUP、CUBE (多次元レポート用); また、SUPER データ型のサイズを 16 MB に増やして、レガシー データ ウェアハウスから Amazon Redshift への移行を容易にしました。
まとめ
お客様は、データと分析が引き続き最優先事項であり、この時期にデータからより多くのビジネス価値を費用対効果の高い方法で抽出する必要性が過去のどの時期よりも顕著であると私たちに話し続けています。 クラウド データ ウェアハウスとしての Amazon Redshift を使用すると、テラバイトからペタバイトの構造化データと非構造化データのスケールとパフォーマンスで複雑な SQL 分析を実行し、一般的な BI および分析ツールを通じて洞察を広く利用できるようになります。
40 年に 2022 を超える機能をリリースし、イノベーションのペースは加速し続けていますが、まだ初日であり、これらの機能が組織にとってより多くの価値を引き出すのにどのように役立つかについて、皆様からのご連絡をお待ちしております。 これらの新機能をお試しいただき、さらにご意見がありましたら、AWS アカウント チームを通じてご連絡ください。
著者,
 マナン・ゴエル AWS の Amazon Redshift を含む AWS 分析サービスの製品市場開拓リーダーです。 彼は 25 年以上の経験があり、データベース、データ ウェアハウジング、ビジネス インテリジェンス、および分析に精通しています。 マナンは、デューク大学で MBA を取得し、電子通信工学の学士号を取得しています。
マナン・ゴエル AWS の Amazon Redshift を含む AWS 分析サービスの製品市場開拓リーダーです。 彼は 25 年以上の経験があり、データベース、データ ウェアハウジング、ビジネス インテリジェンス、および分析に精通しています。 マナンは、デューク大学で MBA を取得し、電子通信工学の学士号を取得しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- 能力
- 私たちについて
- 加速する
- アクセス
- データへのアクセス
- アクセス
- アクセス可能な
- 達成する
- 越えて
- アクティブ
- 積極的に
- 追加されました
- 添加
- NEW
- さらに
- Adobe
- すべて
- ことができます
- 既に
- Amazon
- アマゾンEMR
- アナリスト
- 分析論
- 分析します
- 分析する
- および
- アナウンス
- 発表の
- 別の
- 回答
- アパッチ
- Apache Spark
- API
- 申し込み
- 申し込む
- アプローチ
- 建築
- AREA
- エリア
- 人工の
- 人工知能
- 資産
- 資産管理
- 監査
- オーロラ
- 著者
- オート
- 自動化する
- オートマチック
- 自動的に
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- AWS
- AWSグルー
- Azure
- ベース
- 基礎
- になる
- さ
- BEST
- より良いです
- の間に
- ビッグ
- ビッグデータ
- 請求
- ブレーク
- 広い
- ブロードリッジ
- ビルド
- 建物
- 内蔵
- ビジネス
- ビジネスアプリケーション
- 事業継続性
- ビジネス・インテリジェンス
- 機能
- 容量
- カード
- 場合
- 例
- 変更
- 文字
- 選択する
- 選択する
- クライアント
- クラウド
- クラスタ
- 協力します
- 環境、テクノロジーを推奨
- コレクション
- コラム
- コラム
- 組み合わせる
- 組み合わせた
- 注釈
- 通信部
- 互換性
- 完全に
- 複雑な
- コンポーネント
- 計算
- 同時
- お問合せ
- 整合性のある
- 領事
- 消費
- 続ける
- 継続します
- 続ける
- 連続的な
- コントロール
- コスト効率の良い
- コスト
- カバー
- 作ります
- 作成
- Credentials
- クレジット
- クレジットカード
- Applied Deposits
- CRM
- 電流プローブ
- カスタム
- 顧客
- カスタマーサービス
- Customers
- カスタマイズ
- データ
- データ交換
- データレイク
- データ処理
- データ共有
- データウェアハウス
- データウェアハウス
- データ駆動型の
- データベース
- データベースを追加しました
- 中
- より深い
- 配信する
- 実証します
- 展開します
- 展開
- 設計
- 決定する
- Developer
- 開発者
- 異なります
- 直接に
- 発見する
- 発見
- 話し合います
- 配布
- 配布する
- デューク
- デューク大学
- 間に
- ダイナミック
- 容易
- 簡単に
- エディタ
- 努力
- 電子
- 排除
- 排除
- enable
- 可能
- 有効にする
- エンドポイント
- エンジン
- エンジニアリング
- エーテル(ETH)
- 誰も
- 進化
- 例
- 交換
- 興奮した
- 詳細
- 体験
- 探る
- 表現
- エキス
- 不良解析
- おなじみの
- スピーディー
- 速いです
- 特徴
- 特徴
- File
- ファイナンシャル
- 金融業務
- 財務
- もう完成させ、ワークスペースに掲示しましたか?
- 艦隊
- 柔軟性
- 形成
- フォワード
- 無料版
- から
- 完全に
- 機能
- さらに
- 未来
- 取得する
- GIF
- 与える
- 与えられた
- 与える
- 与え
- ガラス
- 市場に行きます
- ガバナンス
- 助成金
- 付与された
- 素晴らしい
- 起こる
- ハッピー
- ハード
- 持って
- ヘルスケア
- 耳
- 助けます
- ことができます
- 隠す
- ハイ
- 歴史的
- 保持している
- 認定条件
- How To
- HTML
- HTTPS
- 何百
- IAM
- アイデンティティ
- 実装
- 改善します
- 改善されました
- 改善
- in
- 含めて
- 増加した
- 産業を変えます
- 情報
- インフラ関連事業
- 革新的手法
- インサート
- 洞察
- 統合する
- 統合された
- 統合する
- 統合
- インテリジェンス
- 介入
- 導入
- 紹介します
- 投資する
- 投資
- 招待
- 分離
- IT
- ジョブ
- Jobs > Create New Job
- join
- 7月
- カフカ
- キープ
- 保管
- キー
- Kinesisデータストリーム
- 湖
- 大規模
- レイテンシ
- 起動する
- 打ち上げ
- リーダー
- リーダーシップ
- 学習
- Legacy
- レベル
- 軽量
- LIMIT
- リスト
- ライブ
- ライブデータ
- 負荷
- ローダ
- ローディング
- 見て
- ロー
- 機械
- 機械学習
- 製
- 維持する
- メンテナンス
- make
- 作成
- 管理します
- マネージド
- 管理
- マニュアル
- Marketo
- mask
- 最大化します
- メモリ
- 移動します
- ML
- モデル
- モダン
- 修正する
- 監視対象
- モニタリング
- 他には?
- 移動する
- の試合に
- MySQL
- ネイティブ
- 必要
- 必要とされる
- ニーズ
- 新作
- 新しい特徴
- 数
- 番号
- オファー
- ONE
- 開いた
- 操作する
- 操作
- 業務執行統括
- オペレータ
- 演算子
- 最適化
- オプション
- 組織
- 組織
- その他
- 停電
- 外側
- 自分の
- 平和
- パッケージ
- ペイン
- 部
- パートナー
- 過去
- 支払う
- ペトトン
- パフォーマンス
- パーミッション
- 個人的に
- 電話
- 物理的な
- 敬虔な
- 場所
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 喜んだ
- ポリシー
- 方針
- 人気
- ポスト
- 強力な
- 予測分析
- 防ぐ
- プレビュー
- 前に
- ブランド
- 主に
- 優先順位をつける
- 優先順位
- プロセス
- 処理
- プロデューサー
- プロダクト
- 生産性
- 保護
- 提供します
- プロバイダー
- プロバイダ
- は、大阪で
- 準備
- Python
- 質問
- すぐに
- 範囲
- リーチ
- 読む
- リアル
- への
- リアルタイムデータ
- 受け取り
- 回復する
- 減らします
- 地域
- 関連した
- 信頼性
- 信頼性のある
- 残っている
- replace
- レポート
- 各種レポート作成
- 要件
- 制限する
- 結果として
- 収益
- レビュー
- 書き換え
- 富裕層
- 堅い
- 職種
- 役割
- 巻き上げる
- ルール
- ラン
- ランニング
- セージメーカー
- salesforce
- 規模
- 秤
- スケーリング
- シナリオ
- 科学
- 科学者たち
- 二番
- 秒
- 安全に
- しっかりと
- セキュリティ
- 敏感な
- 感度
- サーバレス
- 仕える
- サービス
- サービス
- セッション
- セッションに
- セット
- いくつかの
- シェアする
- shared
- シェアリング
- 表示する
- 簡単な拡張で
- 簡略化されました
- 簡素化する
- 単に
- 同時に
- から
- 座っている
- サイズ
- 遅く
- So
- 社会
- 溶液
- ソリューション
- 一部
- ソース
- スパーク
- 特定の
- SQL
- ステージ
- ストレージ利用料
- 店舗
- 戦略
- ストリーミング配信
- ストリーミング
- ストリーム
- 構造化された
- 構造化データと非構造化データ
- そのような
- スーパー
- サプライヤー
- サポート
- サポート
- システム
- テーブル
- ターゲット
- チーム
- 未来
- アプリ環境に合わせて
- サードパーティ
- 数千
- 介して
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- ツール
- 豊富なツール群
- top
- トピック
- トータル
- touch
- 追跡する
- トレーニング
- トランザクションの
- 最適化の適用
- 変換
- 遍在する
- 思いがけない
- 大学
- 無限の
- アンロック
- アップデイト
- 更新版
- us
- つかいます
- ユーザー
- users
- 活用
- 値
- 価値観
- さまざまな
- バージョン
- 詳しく見る
- ビュー
- 事実上
- 倉庫
- 倉庫保管
- 富
- ウェルスマネジメント
- ウェブ
- ウェブベースの
- この試験は
- 何ですか
- which
- while
- 誰
- ワイド
- 広い範囲
- 広く
- 意志
- 以内
- 無し
- 仕事
- 働いていました
- ワーキング
- 書きます
- 書かれた
- 年
- 年
- あなたの
- ゼファーネット
- ゾーン