
Adobe Firefly からの画像
「私たちは多すぎました。私たちはあまりにも多くのお金とあまりにも多くの設備にアクセスできたので、少しずつ狂っていきました。」
フランシス・フォード・コッポラは、多額の費用を投じて行き場を失ったAI企業の比喩を言っているのではありませんが、そうかもしれません。 地獄の黙示録 GPT-4 と同様に、壮大ではありましたが、長く、困難で、費用がかかるプロジェクトでもありました。 LLM の開発は、あまりにも多くの資金とあまりにも多くの設備に引き寄せられてきたのではないかと思います。そして、「私たちは一般知能を発明したばかりだ」という誇大宣伝の中には、少々狂気を感じる人もいます。しかし今度は、オープンソース コミュニティが最も得意とすること、つまりはるかに少ない資金と設備を使用して無料の競合ソフトウェアを提供する番です。
OpenAI は 11 億ドル以上の資金を調達しており、GPT-3.5 ではトレーニングの実行ごとに 5 万ドルから 6 万ドルの費用がかかると推定されています。 OpenAI が明らかにしていないため、GPT-4 についてはほとんどわかっていませんが、GPT-3.5 よりも小さくないと考えて間違いないと思います。現在、世界的に GPU が不足していますが、話は変わりますが、それは最新の暗号通貨のせいではありません。ジェネレーティブ AI の新興企業は、自社製品の駆動に使用する LLM の IP を所有していないにもかかわらず、巨額の評価額で 100 億ドルを超えるシリーズ A ラウンドを獲得しています。 LLM の流行は絶好調で、資金が流れています。
Microsoft/OpenAI、Amazon、Google のような潤沢な企業だけが、数千億のパラメータ モデルをトレーニングする余裕があるのです。より大きなモデルがより優れたモデルであると見なされます。 GPT-3は何か問題がありましたか?より大きなバージョンが公開されるまで待ってください。大丈夫です。競争しようとしている中小企業は、はるかに多くの資金を調達するか、ChatGPT マーケットプレイスで商品統合を構築する必要がありました。研究予算はさらに限られており、学術界は傍観者に追いやられました。
幸いなことに、多くの賢明な人々とオープンソース プロジェクトは、これを制限ではなく課題として受け止めました。スタンフォード大学の研究者は、GPT-7 の 3.5 億パラメータ モデルに近いパフォーマンスを持つ 175 億パラメータ モデルである Alpaca をリリースしました。 OpenAI で使用されるサイズのトレーニング セットを構築するリソースが不足していたため、彼らは賢明にも、トレーニング済みのオープンソース LLM、LLaMA を利用し、代わりに一連の GPT-3.5 プロンプトと出力で微調整することを選択しました。基本的に、モデルは GPT-3.5 の動作を学習しました。これは、GPT-XNUMX の動作を再現するための非常に効果的な戦略であることが判明しました。
Alpaca はオープンソースの非営利 LLaMA モデルを使用しているため、コードとデータの両方で非営利使用のみがライセンスされており、OpenAI は競合製品を作成するための API の使用を明示的に禁止しています。これにより、Alpaca のプロンプトと出力に基づいて別のオープンソース LLM を微調整し、異なるライセンスの可能性を持つ 3.5 番目の GPT-XNUMX に似たモデルを作成するという、魅力的な見通しが生まれます。
ここにはもう一つの皮肉があります。主要な LLM はすべて、インターネット上で入手可能な著作権で保護されたテキストと画像を使ってトレーニングされており、権利所有者には一銭も支払っていないという点です。両社は、その使用が「変革的」であるとして、米国著作権法に基づく「フェアユース」の免除を主張している。しかし、無料データを使用して構築したモデルの出力に関しては、誰にも同じことをしてほしくないのです。権利者が賢明になるにつれてこの状況は変化し、ある時点で法廷に持ち込まれる可能性があると私は予想しています。
これは、CoPilot のような生成 AI for Code 製品について、ライセンスが遵守されていないという理由でコードがトレーニングに使用されることに反対する、制限付きライセンスのオープンソースの作成者が提起した問題とは別個の明確な論点です。個々のオープンソース作者にとっての問題は、著作権が存続していること、つまり実質的なコピーであることを示す必要があることと、損害が発生したことを示す必要があることです。そして、このモデルでは出力コードを入力 (作成者によるソース コードの行) にリンクすることが難しく、経済的損失がない (無料であるはずです) ため、訴訟を起こすのははるかに困難です。これは、ビジネスモデル全体が自分の作品のライセンス/販売にあり、実質的なコピーを示すことができるゲッティ イメージズのようなアグリゲーターに代表される営利目的のクリエイター (写真家など) とは異なります。
LLaMA のもう 1 つの興味深い点は、それが Meta から生まれたということです。当初は研究者のみに公開されていましたが、その後 BitTorrent 経由で世界に流出しました。 Meta は、クラウド サービスやソフトウェアを販売しようとしていないという点で、OpenAI、Microsoft、Google、Amazon とは根本的に異なるビジネスを行っており、そのためインセンティブも大きく異なります。同社は過去に自社のコンピューティング設計をオープンソース化しており (OpenCompute)、コミュニティがそれらを改善するのを見てきました。同社はオープンソースの価値を理解しています。
Meta は、オープンソース AI の最も重要な貢献者の 2 つとなる可能性があります。膨大なリソースを持っているだけでなく、優れた生成 AI テクノロジーが普及すれば、ソーシャル メディアで収益化できるコンテンツが増えるというメリットもあります。 Meta は、他にも XNUMX つのオープンソース AI モデル、ImageBind (多次元データ インデックス作成)、DINOvXNUMX (コンピューター ビジョン)、および Segment Anything をリリースしました。後者は画像内の固有のオブジェクトを識別し、非常に寛容な Apache ライセンスの下でリリースされます。
最後に、Google の内部文書「We Have No Moat, and Neither Does OpenAI」が漏洩した疑いもありました。この文書では、クローズド モデルと同等かそれよりも優れたパフォーマンスを発揮するはるかに小型で安価なモデルを生成するコミュニティのイノベーションを曖昧に扱っています。クローズドソースの対応物。私がそう言ったのは、記事の出典が Google 内部のものであることを確認する方法がないからだと言われています。ただし、次のような魅力的なグラフが含まれています。
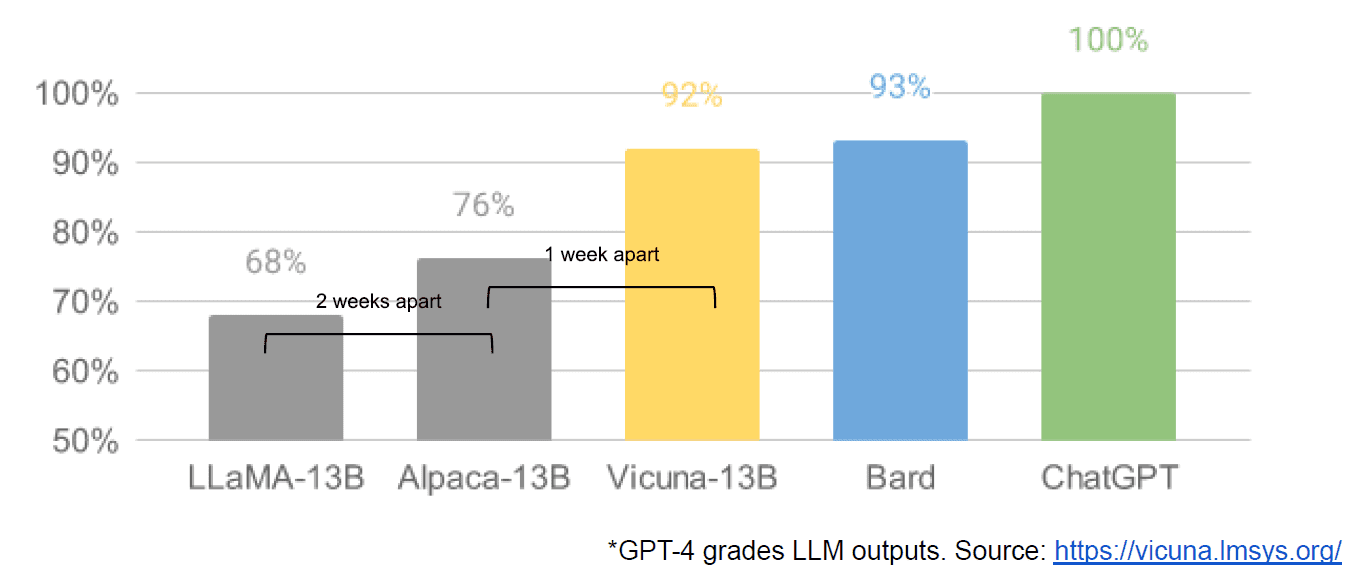
明確に言うと、縦軸は GPT-4 による LLM 出力のグレーディングです。
テキストから画像を合成する Stable Diffusion は、オープンソースの生成 AI が独自のモデルよりも早く進歩できたもう 2 つの例です。そのプロジェクト (ControlNet) の最近の反復により、Dall-EXNUMX の機能を超えるまでに改善されました。これは世界中でさまざまな工夫が凝らされた結果、単一の機関が匹敵するのが難しい進歩のペースをもたらしました。それらの改造者の中には、安定した拡散をより高速にトレーニングし、より安価なハードウェアで実行できるようにする方法を考え出し、より多くの人による反復サイクルの短縮を可能にする人もいました。
こうして私たちは一周してきました。あまりにも多くのお金とあまりにも多くの設備を持っていないことが、一般の人々のコミュニティ全体による狡猾なレベルのイノベーションを引き起こしました。 AI開発者になるにはなんと素晴らしい時代だろう。
マシュー ロッジ AI For Code のスタートアップである Diffblue の CEO です。彼は、Anaconda や VMware などの企業で製品リーダーとして 25 年以上の多様な経験を持っています。ロッジは現在、Good Law Project の理事を務めており、英国王立写真協会の理事会の副委員長を務めています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :持っている
- :は
- :not
- :どこ
- $UP
- 9
- a
- できる
- 私たちについて
- アカデミー
- アクセス
- Adobe
- 進める
- アグリゲーター
- AI
- すべて
- 主張された
- 容疑者
- また
- Amazon
- an
- &
- 別の
- どれか
- 誰も
- 何でも
- アパッチ
- API
- です
- 引数
- 記事
- AS
- 想定される
- At
- 著者
- 著者
- 利用できます
- 軸
- BE
- なぜなら
- き
- さ
- 利点
- BEST
- より良いです
- より大きい
- BitTorrentの
- ボード
- 両言語で
- 予算
- ビルド
- 建物
- 束
- ビジネス
- ビジネスモデル
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 来ました
- 缶
- 機能
- 資本
- 場合
- 最高経営責任者(CEO)
- 椅子
- 挑戦する
- 変化する
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- 安い
- 選んだ
- サークル
- クレーム
- クリア
- 閉じる
- 閉まっている
- クラウド
- クラウドサービス
- コード
- 来ます
- 来ます
- 商品
- コミュニティ
- コミュニティ
- 企業
- 説得力のある
- 競争する
- 競合します
- 計算
- コンピュータ
- Computer Vision
- コンテンツ
- 貢献者
- 複写
- 著作権
- コスト
- 可能性
- 裁判所
- 作ります
- 作成
- クリエイター
- 暗号通貨
- 現在
- サイクル
- データ
- 配信する
- 副
- デザイン
- Developer
- 開発
- 死
- 異なります
- 難しい
- 明確な
- 異なる
- do
- ドキュメント
- ありません
- ドント
- e
- 経済
- 効果的な
- 有効にする
- end
- 全体
- EPIC
- 装置
- 本質的に
- 推定
- さらに
- 例
- 期待する
- 高価な
- 体験
- 遠く
- 速いです
- 考え出した
- 流れる
- 続いて
- フォード
- 無料版
- から
- フル
- 根本的に
- 資金調達
- ギア
- 生々しい
- 生成AI
- 良い
- でログイン
- GPU
- グラフ
- 素晴らしい
- 持っていました
- ハード
- Hardware
- 持ってる
- 持って
- he
- こちら
- ハイ
- 非常に
- ホルダー
- 認定条件
- How To
- しかしながら
- HTTPS
- 巨大な
- 誇大広告
- i
- 識別する
- if
- 画像
- 重要
- 改善します
- 改善されました
- in
- インセンティブ
- 個人
- 革新的手法
- INSANE
- インスピレーションある
- を取得する必要がある者
- 機関
- 統合
- 興味深い
- 内部
- インターネット
- 発明された
- IP
- アイロニー
- IT
- 繰り返し
- ITS
- ただ
- KDナゲット
- 知っている
- 着陸
- 最新の
- 法律
- 層
- リーダーシップ
- 学んだ
- 左
- less
- レベル
- ライセンス
- ライセンス供与
- ライセンシング
- ような
- ライン
- LINK
- 少し
- ラマ
- 長い
- 見
- 探して
- 失う
- 損失
- たくさん
- 主要な
- make
- 作成
- 多くの
- 市場
- 大規模な
- 一致
- 五月..
- メディア
- Meta
- Microsoft
- モデル
- 収益化する
- お金
- 他には?
- 最も
- ずっと
- 必要
- どちらでもありません
- いいえ
- 非営利
- 今
- オブジェクト
- オブジェクト
- of
- on
- ONE
- の
- 開いた
- オープンソース
- オープンソースプロジェクト
- OpenAI
- or
- 一般
- 元々
- その他
- でる
- 出力
- が
- 自分の
- 平和
- パラメーター
- 過去
- 支払う
- のワークプ
- 実行する
- パフォーマンス
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- の可能性
- 電力
- 問題
- プロダクト
- 製品
- プロジェクト
- プロジェクト(実績作品)
- 所有権
- 見通し
- 上げる
- 隆起した
- むしろ
- 本当に
- 最近
- リリース
- で表さ
- 研究
- 研究者
- リソース
- 結果として
- 権利
- ラウンド
- ロイヤル
- ラン
- s
- 安全な
- 同じ
- 言う
- 見て
- セグメント
- 売る
- 別
- シリーズ
- シリーズA
- 仕える
- サービス
- セッションに
- 不足
- 表示する
- から
- サイズ
- より小さい
- スマート
- So
- 社会
- ソーシャルメディア
- 社会
- ソフトウェア
- 一部
- 何か
- ソース
- ソースコード
- 過ごす
- 安定した
- スタンフォード
- ベンチャー
- スタートアップ
- 戦略
- そのような
- 示唆する
- 想定
- 超越
- 取る
- 撮影
- 取り
- テクノロジー
- より
- それ
- ソース
- 世界
- アプリ環境に合わせて
- それら
- その後
- そこ。
- 彼ら
- もの
- 考える
- 三番
- この
- それらの
- 三
- 時間
- 〜へ
- あまりに
- 取った
- トレーニング
- 訓練された
- トレーニング
- 順番
- ターン
- 下
- 理解する
- ユニーク
- 異なり、
- まで
- us
- つかいます
- 中古
- 使用されます
- 評価
- 値
- 確認する
- バージョン
- 垂直
- 非常に
- 、
- 詳しく見る
- ビジョン
- ヴイエムウェア
- vs
- wait
- 欲しいです
- ました
- 仕方..
- we
- 行ってきました
- した
- この試験は
- いつ
- which
- 誰
- 全体
- その
- 意志
- WISE
- 仕事
- 世界
- 間違った
- 貴社
- ゼファーネット









