編集者による画像
2023 年ということは、ほとんどの業界のほとんどの企業が、ビッグデータを利用して洞察を収集し、よりスマートな意思決定を推進していることを意味します。 最近では、これはそれほど驚くべきことではありません。大量のデータ セットを収集、分類、分析する機能は、次のような場合に非常に役立ちます。 データ主導のビジネス上の意思決定.
そして、ますます多くの組織がデジタル化を採用するにつれて、データ分析の有用性を把握し、信頼する能力は成長し続けるでしょう。
ただし、ビッグ データについては次の点があります。ビッグ データに依存する組織が増えるにつれて、ビッグ データを誤って使用する可能性が高くなります。 なぜ? ビッグデータとそれが提供する洞察は、組織がデータを正確に分析している場合にのみ役立ちます。
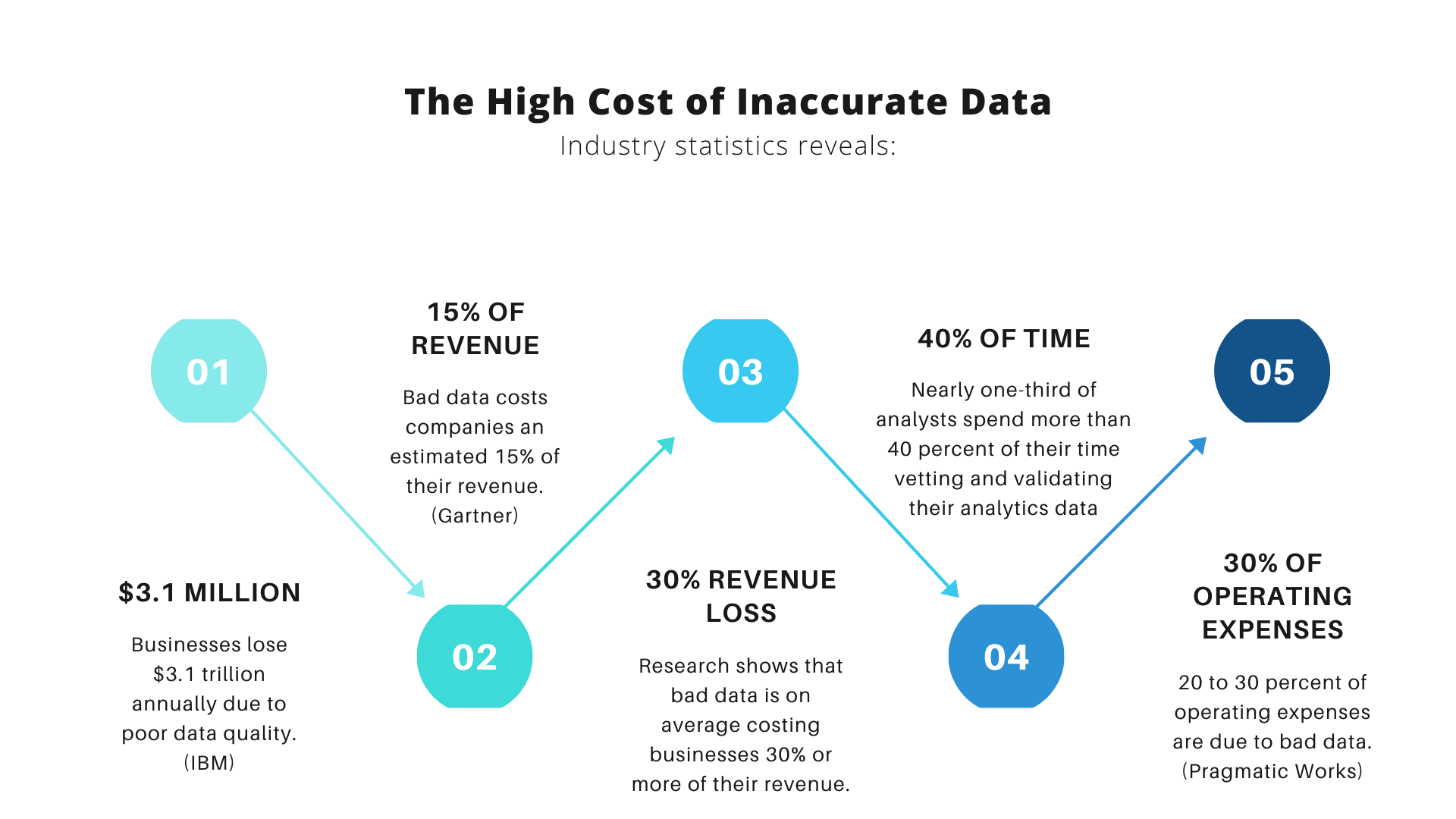
Image from
データラダー
そのために、データ分析の精度に影響を与えることが多いいくつかの一般的な間違いを回避していることを確認しましょう. これらの問題と、それらを回避する方法について学びましょう。
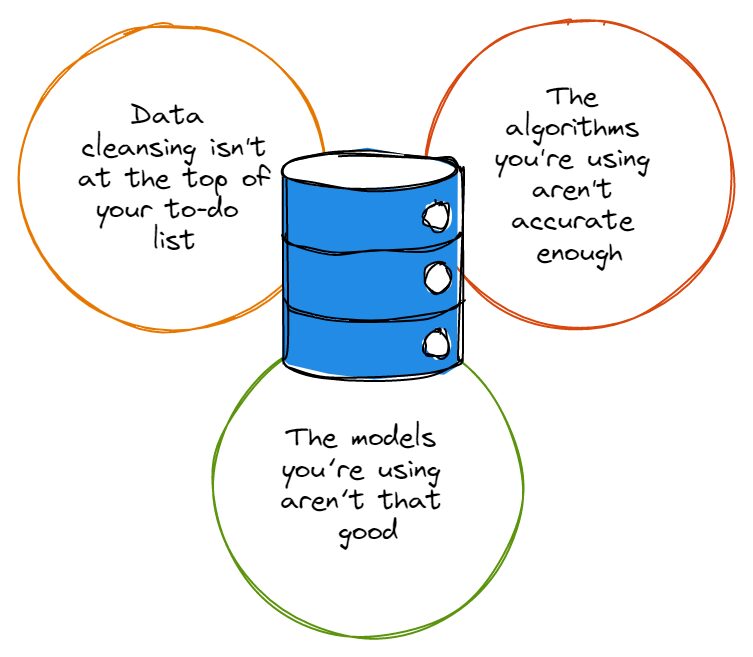
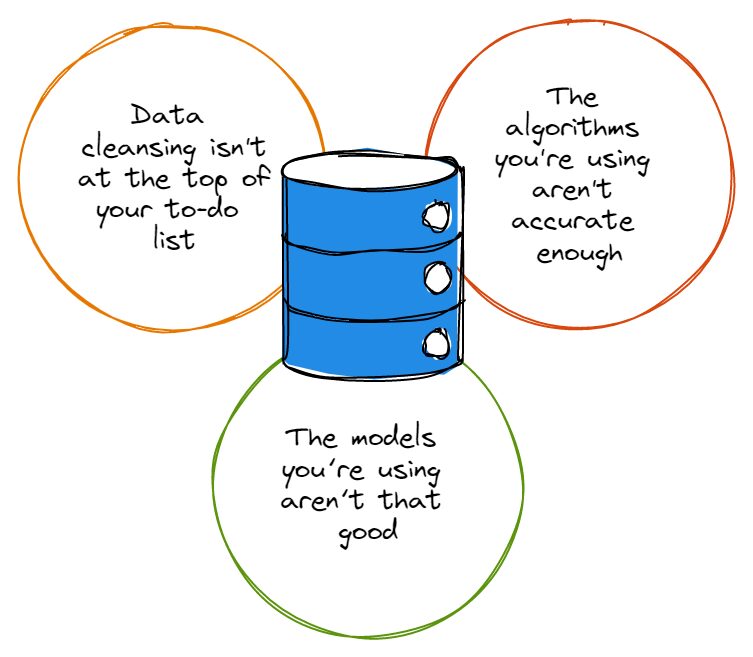
責任を追及する前に、ほとんどのデータ セットにはかなりの割合のエラーがあり、これらのエラーは、データを分析する際に誰にとっても何の役にも立たないことを認める必要があります。 タイプミス、変な命名規則、冗長性など、データセットのエラーはデータ分析の精度を乱します。
ですから、深く潜ることに興奮しすぎる前に データ分析のウサギの穴へ、最初にデータのクレンジングがやることリストの一番上にあり、データセットを常に適切にクレンジングしていることを確認する必要があります. 「ねえ、データクレンジングは時間がかかりすぎて面倒くさい」と言うかもしれませんが、私たちは同情してうなずきます。
幸いなことに、拡張分析などのソリューションに投資できます。 これにより、機械学習アルゴリズムを活用して、データ分析を実行する速度が加速されます (また、分析の精度も向上します)。
つまり、データ クレンジングを自動化および改善するためにどのようなソリューションを使用しても、実際のクレンジングを行う必要があります。そうしないと、正確なデータ分析の基礎となる適切な基盤が得られません。
データ セットの場合と同様に、ほとんどのアルゴリズムは XNUMX% 完璧というわけではありません。 それらのほとんどにはかなりの欠陥があり、使用するたびに思いどおりに機能しない. 多数の不完全なアルゴリズムは、分析に不可欠なデータを無視することさえあります。または、実際にはそれほど重要ではない間違った種類のデータに焦点を当てる可能性があります。
テクノロジーの最大の名前が 常にアルゴリズムを精査している それは、実際に完璧なアルゴリズムがほとんどないからです。 アルゴリズムが正確であればあるほど、プログラムが目標を達成し、必要な処理を行っているという保証が大きくなります。
さらに、組織に数人のデータ サイエンティストしかいない場合でも、それらのデータ サイエンティストがデータ分析プログラムのアルゴリズムを定期的に更新していることを確認する必要があります。合意されたスケジュールに従ってデータ分析アルゴリズムを更新します。
それよりもさらに良いのは、次の戦略を確立することです。 AI/ML ベースのアルゴリズムを活用、自動的に自分自身を更新できるはずです。
当然のことながら、データ分析チームと直接関わっていない多くのビジネス リーダーは、アルゴリズムとモデルが 同じものではない. あなたも知らなかったかもしれませんが、アルゴリズムはデータを分析するために使用する方法であることを思い出してください。 モデルは、アルゴリズムの出力を活用して作成される計算です。
アルゴリズムは XNUMX 日中データを処理できますが、その出力がその後の分析をチェックするように設計されたモデルを通過しない場合、有用または有用な洞察は得られません。
次のように考えてみてください。データを処理する高度なアルゴリズムを持っていても、それに対して示す洞察がない場合、それらのアルゴリズムを使用する前よりも優れたデータ駆動型の意思決定を行うことはできません。 それは、ユーザー調査を製品ロードマップに組み込みたいと考えているのに、市場調査業界などの事実を無視しているようなものです。 76.4億ドルを生み出した 2021 年の収益は 100 年から 2008% 増加しています。
あなたの意図は称賛に値するかもしれませんが、最新のツールと知識を利用して、それらの洞察を収集したり、そのユーザー調査をロードマップに組み込んだりする必要があります。
残念なことに、最適化されていないモデルは、アルゴリズムがどれほど洗練されていても、アルゴリズムの出力を台無しにする確実な方法です。 したがって、複雑すぎず単純すぎないモデルを作成するには、ビジネス エグゼクティブや技術リーダーがデータ分析の専門家とより密接に連携することが不可欠です。
また、扱うデータの量に応じて、ビジネス リーダーは、処理する必要があるデータの量と種類に最適なモデルを決定する前に、いくつかの異なるモデルを検討することを選択する場合があります。
結局のところ、データ分析が一貫して間違っていないことを確認したい場合は、次のことも忘れないでください。 偏見の犠牲になることはありません. 残念ながら、バイアスは、データ分析の精度を維持する上で克服しなければならない最大のハードルの XNUMX つです。
収集されるデータの種類に影響を与えているか、ビジネス リーダーがデータを解釈する方法に影響を与えているかにかかわらず、偏見はさまざまであり、特定するのが難しいことがよくあります。正確なデータ分析。
データは強力です。適切に活用すれば、ビジネス リーダーとその組織は、製品の開発方法と顧客への提供方法を変革できる非常に有用な洞察を得ることができます。 データ分析が正確であり、この記事で概説した簡単に回避できる間違いに悩まされないように、できる限りのことを行っていることを確認してください.
ナフラ・デイビス ソフトウェア開発者およびテクニカルライターです。 テクニカルライティングに専念する前に、彼女は、とりわけ興味深いことに、Samsung、Time Warner、Netflix、Sonyなどのクライアントを持つInc.5,000の体験型ブランディング組織でリードプログラマーを務めることができました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/03/3-mistakes-could-affecting-accuracy-data-analytics.html?utm_source=rss&utm_medium=rss&utm_campaign=3-mistakes-that-could-be-affecting-the-accuracy-of-your-data-analytics
- :は
- 000
- 2021
- 2023
- a
- 能力
- 能力
- できる
- 私たちについて
- 加速する
- 成し遂げる
- 精度
- 正確な
- 正確にデジタル化
- 実際に
- 立派な
- 認める
- 影響を及ぼす
- 影響
- アルゴリズム
- アルゴリズム
- すべて
- 常に
- 間で
- 分析
- 分析論
- 分析します
- 分析する
- および
- 誰も
- です
- 記事
- AS
- At
- 増強された
- 自動化する
- 自動的に
- 利用できます
- 回避
- ベース
- BE
- なぜなら
- になる
- さ
- 恩恵
- BEST
- より良いです
- バイアス
- ビッグ
- ビッグデータ
- より大きい
- 最大の
- ボトム
- ブランド設定
- ビルド
- 束
- ビジネス
- ビジネス
- by
- 缶
- 場合
- チャンス
- チェック
- 選択する
- クライアント
- 閉じる
- 密接に
- Codecademy
- 収集
- 来ます
- コマンドと
- 複雑な
- 計算
- 続ける
- 表記
- 可能性
- カップル
- 作ります
- 作成した
- クランチ
- Customers
- データ
- データ分析
- データ分析
- データセット
- データ駆動型の
- 中
- 日
- 決定
- 深いです
- 配信する
- によっては
- 設計
- 開発する
- Developer
- 異なります
- 難しい
- デジタル化
- 直接に
- すること
- ダウン
- 運転
- 簡単に
- どちら
- 受け入れる
- 従事する
- 従事して
- 確保
- エラー
- 本質的な
- 確立する
- 確立
- さらに
- あらゆる
- すべてのもの
- 例
- 興奮した
- 幹部
- 経験の
- 専門家
- フェア
- 秋
- 恩恵
- 少数の
- 名
- 欠陥
- フォーカス
- フォロー中
- Foundation
- から
- フル
- 取得する
- Go
- 目標
- 行く
- 助成金
- 把握
- 大きい
- 最大
- 成長する
- 成長
- 保証
- ハンドル
- 持ってる
- 頭
- 助けます
- 保持している
- 認定条件
- HTML
- HTTP
- HTTPS
- ハードル
- 識別する
- とてつもなく
- 重要
- 改善します
- 向上させる
- in
- (株)
- include
- 間違って
- 増える
- 産業
- 産業を変えます
- 影響する
- 洞察
- 意図
- 投資する
- 問題
- IT
- JPG
- KDナゲット
- 種類
- 知識
- つながる
- リーダー
- LEARN
- 学習
- レバレッジ
- 活用
- ような
- LINE
- リスト
- 長い
- たくさん
- 機械
- 機械学習
- make
- 作成
- マネージド
- 市場
- 市場調査
- 問題
- 手段
- メソッド
- ミス
- モデル
- モダン
- 他には?
- 最も
- 名
- 命名
- 必要
- どちらでもありません
- Netflix
- 数
- of
- オファー
- on
- ONE
- 注文
- 組織
- 組織
- その他
- 概説
- 出力
- 克服する
- パーセント
- 完璧
- 実行する
- ピューリサーチ
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 可能
- 電力
- 強力な
- プロダクト
- 製品
- プログラマー
- プログラム
- 適切な
- 正しく
- ウサギ
- レート
- RE
- 読む
- 実現する
- 定期的に
- 覚えています
- 表します
- 研究
- 収入
- ロードマップ
- s
- 同じ
- サムスン
- スケジュール
- 科学者たち
- 秘密
- 役立つ
- セット
- 落ち着く
- シェアする
- すべき
- 表示する
- 簡単な拡張で
- 単に
- から
- 賢い
- So
- ソフトウェア
- 溶液
- ソリューション
- 一部
- Sony
- 洗練された
- まだ
- 戦略
- それに続きます
- そのような
- 苦しみ
- 驚き
- チーム
- テク
- 技術的
- それ
- アプリ環境に合わせて
- それら
- 自分自身
- したがって、
- ボーマン
- もの
- 物事
- 介して
- 時間
- 時間がかかる
- 〜へ
- あまりに
- 豊富なツール群
- top
- 最適化の適用
- 微調整
- 理解しやすい
- 不幸な
- アップデイト
- 更新版
- 更新
- 使用可能な
- つかいます
- ユーザー
- Ve
- 被害者
- ボリューム
- 欲しい
- ワーナー
- 仕方..
- この試験は
- かどうか
- which
- 誰
- 意志
- 仕事
- ワーキング
- やりがいのある
- 作家
- 書き込み
- 間違った
- あなたの
- ゼファーネット