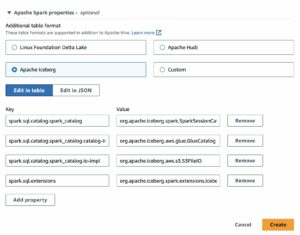
アパッチ・フディ は、データ レイクにデータベースとデータ ウェアハウスの機能をもたらすオープン テーブル形式です。 Apache Hudi は、データ エンジニアがクエリのパフォーマンスを維持しながらトランザクションで進化し続けるデータセットを管理するなど、複雑な課題を管理するのに役立ちます。 データ エンジニアは、ワークロードのストリーミングや効率的な増分データ パイプラインの作成に Apache Hudi を使用します。 Hudi が提供する テーブル, 取引, 効率的な更新/削除, 高度なインデックス, ストリーミング取り込みサービス、データ クラスタリング および 圧縮 最適化、および 同時実行制御、データをオープン ソース ファイル形式に保ちながら。 Hudi の高度なパフォーマンス最適化により、Apache Spark、Presto、Trino、Hive などの一般的なクエリ エンジンを使用して分析ワークロードが高速化されます。
AWS の多くの顧客は、Amazon S3 上に構築されたデータレイクに Apache Hudi を採用しました。 AWSグルーは、分析、機械学習 (ML)、アプリケーション開発のための複数のソースからのデータの検出、準備、移動、統合を容易にするサーバーレス データ統合サービスです。 AWS グルー クローラー は AWS Glue のコンポーネントであり、メタデータを手動で定義することなく、データ コンテンツからテーブル メタデータを自動的に作成できます。
AWS Glue クローラーが Apache Hudi テーブルをサポートするようになりましたの採用を簡素化します。 AWSGlueデータカタログ Hudi テーブルのカタログとして。 典型的な使用例の 3 つは、カタログ テーブル定義を持たない Hudi テーブルを登録することです。 もう 3 つの典型的な使用例は、Hive メタストアなどの他の Hudi カタログからの移行です。 他の Hudi カタログから移行する場合、AWS Glue クローラーを作成してスケジュールし、Hudi テーブル ファイルが配置されている XNUMX つ以上の Amazon SXNUMX パスを指定できます。 AWS Glue クローラーが通過できる Amazon SXNUMX パスの最大の深さを指定するオプションがあります。 実行するたびに、AWS Glue クローラーはスキーマとパーティションの情報を抽出し、スキーマとパーティションの変更で AWS Glue データカタログを更新します。 AWS Glue クローラーは、AWS 分析エンジンが直接使用できる AWS Glue データ カタログ内の最新のメタデータ ファイルの場所を更新します。
このリリースにより、AWS Glue クローラーを作成してスケジュールし、Hudi テーブルを AWS Glue データ カタログに登録できるようになります。 その後、Hudi テーブルが配置される 3 つまたは複数の Amazon S3 パスを指定できます。 クローラーが通過できる Amazon S3 パスの最大の深さを指定するオプションがあります。 クローラーが実行されるたびに、クローラーは各 SXNUMX パスを検査し、新しいテーブル、削除、スキーマの更新などのスキーマ情報を AWS Glue データ カタログにカタログします。 クローラーはパーティション情報を検査し、新しく追加されたパーティションを AWS Glue データ カタログに追加します。 クローラーは、AWS 分析エンジンが直接使用できる AWS Glue データ カタログ内の最新のメタデータ ファイルの場所も更新します。
この投稿では、Hudi テーブルをクロールするこの新しい機能がどのように機能するかを示します。
AWS Glue クローラーが Hudi テーブルでどのように動作するか
Hudi テーブルには XNUMX つのカテゴリがあり、それぞれに具体的な意味があります。
- コピーオンライト (CoW) – データは列指向形式 (Parquet) で保存され、更新ごとに書き込み中に新しいバージョンのファイルが作成されます。
- 読み取り時にマージ (MoR) – データは、列形式 (Parquet) と行ベース (Avro) 形式の組み合わせを使用して保存されます。 更新は行ベースで記録されます
deltaファイルは圧縮され、新しいバージョンのカラムナ ファイルが作成されます。
CoW データセットでは、レコードが更新されるたびに、そのレコードを含むファイルが更新された値で書き換えられます。 MoR データセットでは、更新があるたびに、Hudi は変更されたレコードの行のみを書き込みます。 MoR は、読み取りが少なく、書き込みまたは変更が多いワークロードに適しています。 CoW は、変更頻度が低いデータに対する読み取り負荷の高いワークロードに適しています。
Hudi には、データにアクセスするための XNUMX つのクエリ タイプが用意されています。
- スナップショットクエリ – 特定のコミットまたは圧縮アクションの時点でのテーブルの最新のスナップショットを参照するクエリ。 MoR テーブルの場合、スナップショット クエリは、クエリ時点での最新のファイル スライスのベース ファイルとデルタ ファイルをマージすることにより、テーブルの最新の状態を公開します。
- 増分クエリ – クエリでは、特定のコミットまたは圧縮以降にテーブルに書き込まれた新しいデータのみが参照されます。 これにより、変更ストリームが効果的に提供され、増分データ パイプラインが可能になります。
- 最適化されたクエリの読み取り – MoR テーブルの場合、クエリでは圧縮された最新のデータが参照されます。 CoW テーブルの場合、クエリはコミットされた最新のデータを参照します。
コピーオンライト テーブルの場合、クローラは ReadOptimized Serde を使用して AWS Glue データ カタログに単一のテーブルを作成します。 org.apache.hudi.hadoop.HoodieParquetInputFormat.
マージオンリードテーブルの場合、クローラは AWS Glue データカタログの同じテーブルの場所に XNUMX つのテーブルを作成します。
- 接尾辞付きのテーブル
_ro、ReadOptimized Serde を使用します。org.apache.hudi.hadoop.HoodieParquetInputFormat - 接尾辞付きのテーブル
_rtこれは、スナップショット クエリを可能にする RealTime Serde を使用します。org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
各クロール中、提供された Hudi パスごとに、クローラーは Amazon S3 リスト API 呼び出しを行い、 .hoodie フォルダーを検索し、その Hudi テーブル メタデータ フォルダーで最新のメタデータ ファイルを見つけます。
AWS Glue クローラーを使用して Hudi CoW テーブルをクロールする
このセクションでは、AWS Glue クローラーを使用して Hudi CoW をクロールする方法を説明します。
前提条件
このチュートリアルの前提条件は次のとおりです。
- インストールと設定 AWSコマンドラインインターフェイス(AWS CLI).
- S3 バケットがない場合は作成します。
- AWS Glue の IAM ロールを作成する お持ちでない場合。 必要です
s3:GetObjectfors3://your_s3_bucket/data/sample_hudi_cow_table/. - 次のコマンドを実行して、サンプルの Hudi テーブルを S3 バケットにコピーします。 (交換する
your_s3_bucketS3 バケット名に置き換えます。)
この手順ではサンプルデータをコピーする方法を説明しますが、AWS Glue を使用して任意の Hudi テーブルを簡単に作成できます。 詳細については、 AWS Glue for Apache Spark での Apache Hudi、Delta Lake、および Apache Iceberg のネイティブサポートの紹介、パート 2: AWS Glue Studio Visual Editor.
Hudi クローラーを作成する
この手順では、コンソールからクローラーを作成します。 Hudi クローラーを作成するには、次の手順を実行します。
- AWS Glue コンソールで、選択します Crawlers.
- 選択する クローラーを作成する.
- 名前 、 入る
hudi_cow_crawler。 選択してください Next. - データソースの構成、 選ぶ データソースを追加する.
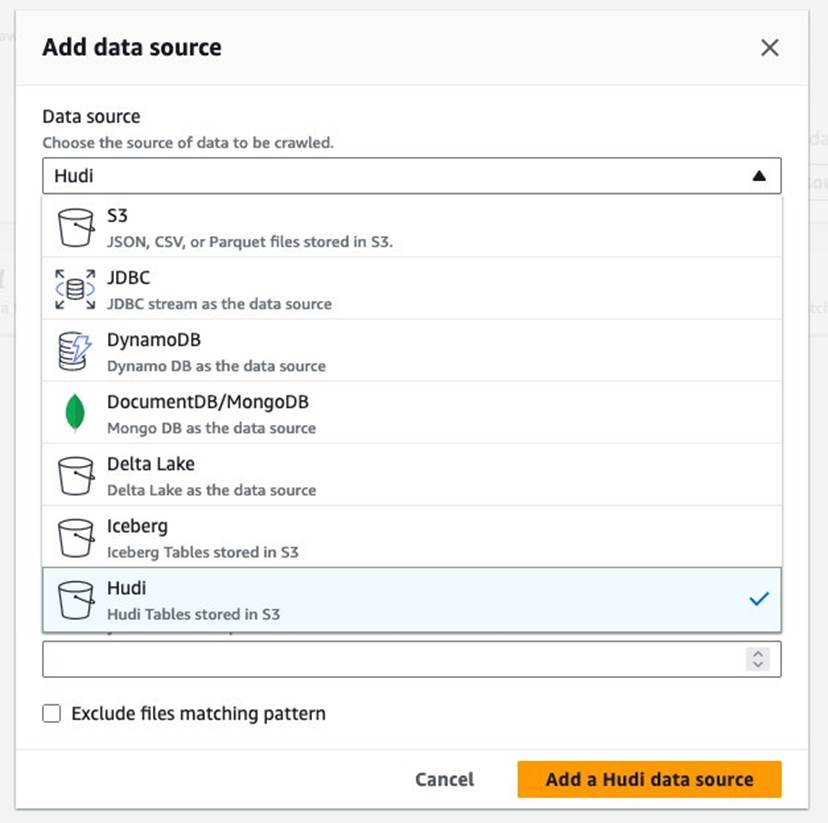
- 情報元、選択する フディ.
- hudi テーブルのパスを含める、 入る
s3://your_s3_bucket/data/sample_hudi_cow_table/。 (交換your_s3_bucketS3 バケット名に置き換えます。) - 選択する Hudi データソースを追加する.
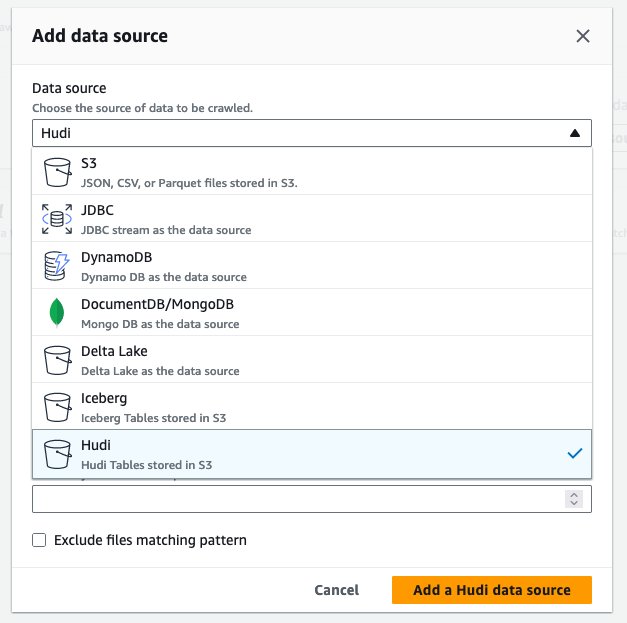
- 選択する Next.
- 既存の IAM ロール、IAM ロールを選択してから、 Next.
- 対象データベース、選択する データベースを追加する、 そうして データベースを追加する ダイアログが表示されます。 為に データベース名、 入る
hudi_crawler_blog、を選択します 創造する。 選択してください Next. - 選択する クローラーを作成する.
これで、新しい Hudi クローラーが正常に作成されました。 クローラーは、コンソール、または SDK または AWS CLI を使用してトリガーして実行できます。 StartCrawl API。 また、特定の時間にクローラーをトリガーするようにコンソールからスケジュールすることもできます。 この手順では、コンソールからクローラーを実行します。
- 選択する クローラーを実行する.
- クローラーが完了するまで待ちます。
クローラーが実行されると、AWS Glue コンソールで Hudi テーブル定義を確認できます。
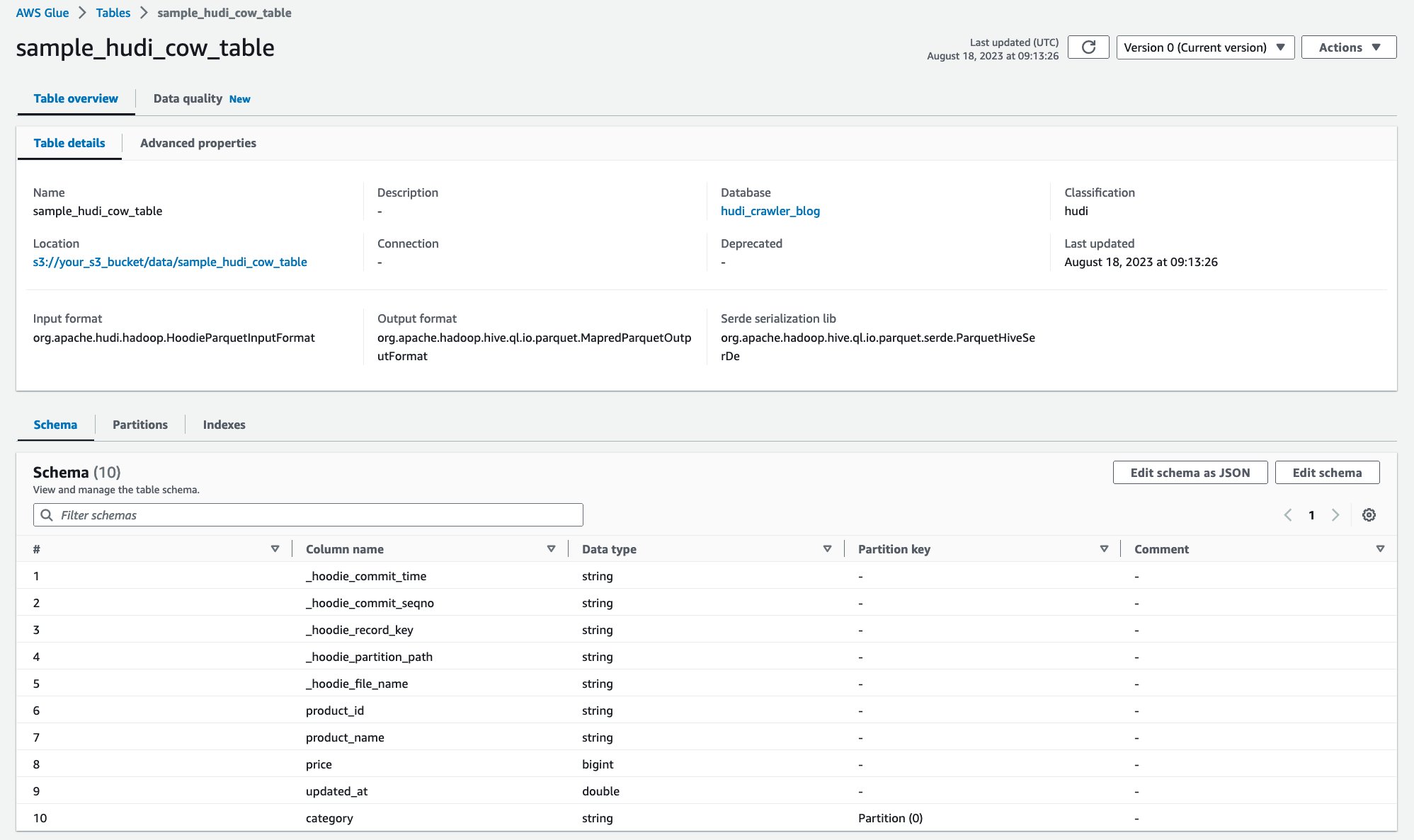
Amazon S3 上のデータを含む Hudi CoR テーブルを正常にクロールし、スキーマが設定された AWS Glue データ カタログ テーブルを作成しました。 AWS Glue データカタログでテーブル定義を作成すると、Amazon Athena などの AWS 分析サービスが Hudi テーブルにクエリを実行できるようになります。
Athena でクエリを開始するには、次の手順を実行します。
- Amazon Athena コンソールを開きます。
- 次のクエリを実行します。
次のスクリーンショットは、出力を示しています。
AWS Lake Formation データ権限を持つ AWS Glue クローラーを使用して Hudi MoR テーブルをクロールする
このセクションでは、AWS Glue を使用して Hudi MoR テーブルをクロールする方法を説明します。 今回は、IAM および Amazon S3 アクセス許可の代わりに、Amazon S3 データ ソースをクロールするために AWS Lake Formation データアクセス許可を使用します。 これはオプションですが、データレイクが AWS Lake Formation のアクセス許可によって管理されている場合、アクセス許可の設定が簡素化されます。
前提条件
このチュートリアルの前提条件は次のとおりです。
- インストールと設定 AWSコマンドラインインターフェイス(AWS CLI).
- S3 バケットがない場合は作成します。
- AWS Glue の IAM ロールを作成する お持ちでない場合。 必要です
lakeformation:GetDataAccess。 しかし、必要ありませんs3:GetObjectfors3://your_s3_bucket/data/sample_hudi_mor_table/ファイルにアクセスするために Lake Formation データ権限を使用しているためです。 - 次のコマンドを実行して、サンプルの Hudi テーブルを S3 バケットにコピーします。 (交換する
your_s3_bucketS3 バケット名に置き換えます。)
処理手順に加えて、次の手順を実行して、IAM ベースのアクセス制御の代わりに Lake Formation アクセス許可を使用してカタログ リソースを制御するように AWS Glue データ カタログ設定を更新します。
- データ レイク管理者として Lake Formation コンソールにサインインします。
- Lake Formation コンソールに初めてアクセスする場合は、 自分自身をデータ レイク管理者として追加します。
- 管理部門、選択する データカタログ設定.
- 新しく作成されたデータベースとテーブルのデフォルトの権限、選択を解除します 新しいデータベースにはIAMアクセス制御のみを使用する および 新しいデータベースの新しいテーブルには IAM アクセス制御のみを使用する.
- クロスアカウントのバージョン設定、選択する Version 3.
- 選択する Save.
次のステップは、S3 バケットを Lake Formation データ レイクの場所に登録することです。
- Lake Formation コンソールで、 データレイクの場所、選択して 登録場所.
- AmazonS3パス、 入る
s3://your_s3_bucket/。 (交換するyour_s3_bucketS3 バケット名に置き換えます。) - 選択する 登録場所.
次に、Glue クローラー ロールにデータの場所へのアクセスを付与し、クローラーが Lake Formation 権限を使用してデータにアクセスし、その場所にテーブルを作成できるようにします。
- Lake Formation コンソールで、 データの場所 選択して グラント.
- IAMユーザーとロール、クローラーに使用した IAM ロールを選択します。
- ストレージの場所、 入る
s3://your_s3_bucket/data/。 (交換するyour_s3_bucketS3 バケット名に置き換えます。) - 選択する グラント.
次に、データベースの下にテーブルを作成するためのクローラの役割を付与します。 hudi_crawler_blog:
- Lake Formation コンソールで、 データレイクの許可.
- 選択する グラント.
- プリンシパル、選択する IAMユーザーとロールをクリックして、クローラーの役割を選択します。
- LF タグまたはカタログ リソース、選択する 名前付きデータカタログリソース.
- データベース、データベースを選択します
hudi_crawler_blog. - データベースのアクセス許可選択 テーブルを作成.
- 選択する グラント.
Lake Formation データ権限を持つ Hudi クローラーを作成する
Hudi クローラーを作成するには、次の手順を実行します。
- AWS Glue コンソールで、選択します Crawlers.
- 選択する クローラーを作成する.
- 名前 、 入る
hudi_mor_crawler。 選択してください Next. - データソースの構成、 選ぶ データソースを追加する.
- 情報元、選択する フディ.
- hudi テーブルのパスを含める、 入る
s3://your_s3_bucket/data/sample_hudi_mor_table/。 (交換するyour_s3_bucketS3 バケット名に置き換えます。) - 選択する Hudi データソースを追加する.
- 選択する Next.
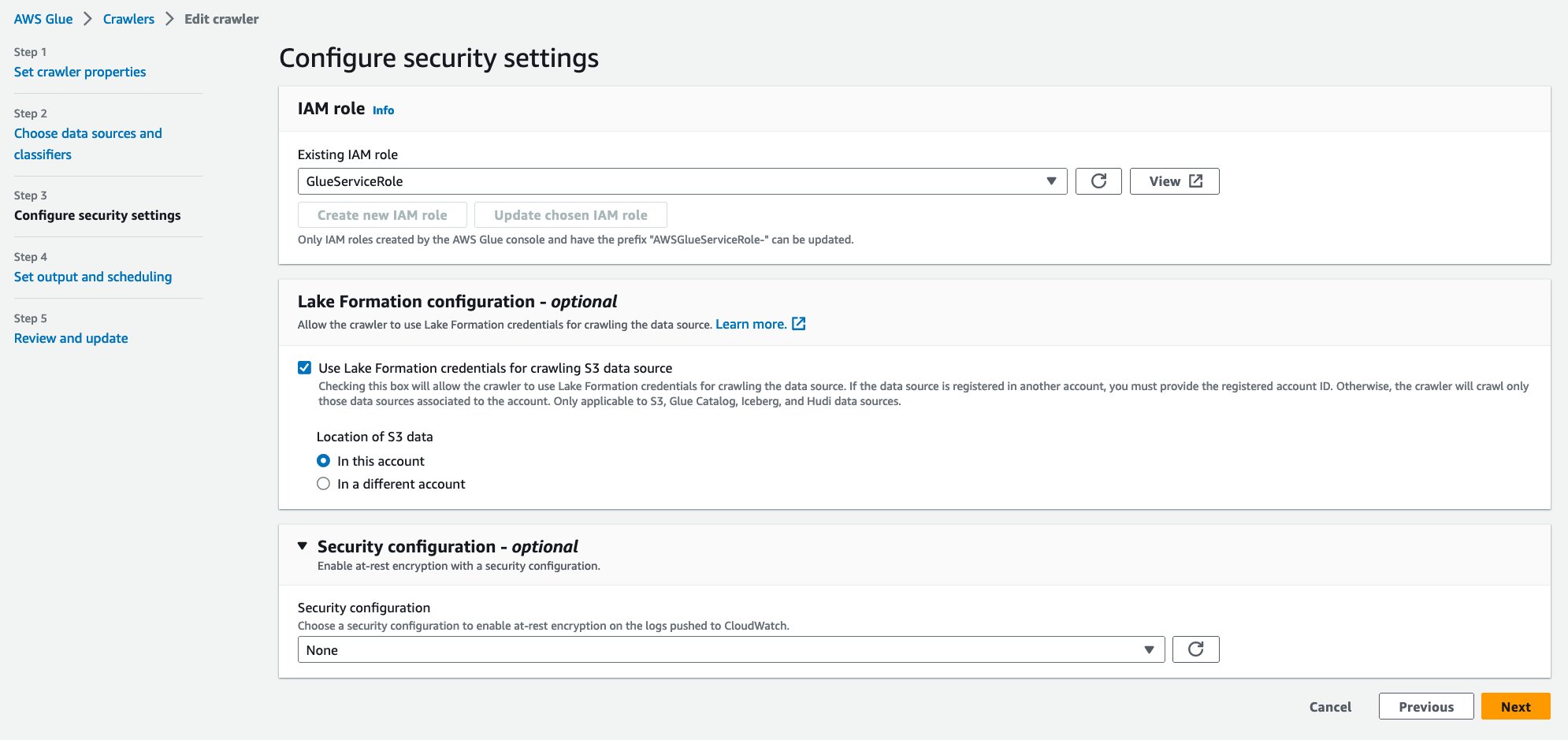
- 既存の IAM ロール、IAM ロールを選択します。
- Lake Formation 構成 – オプション選択 S3 データ ソースのクロールに Lake Formation 資格情報を使用する.
- 選択する Next.
- 対象データベース、選択する
hudi_crawler_blog。 選択してください Next. - 選択する クローラーを作成する.
これで、新しい Hudi クローラーが正常に作成されました。 クローラーは、Amazon S3 ファイルをクロールするために Lake Formation 認証情報を使用します。 新しいクローラーを実行してみましょう。
- 選択する クローラーを実行する.
- クローラーが完了するまで待ちます。
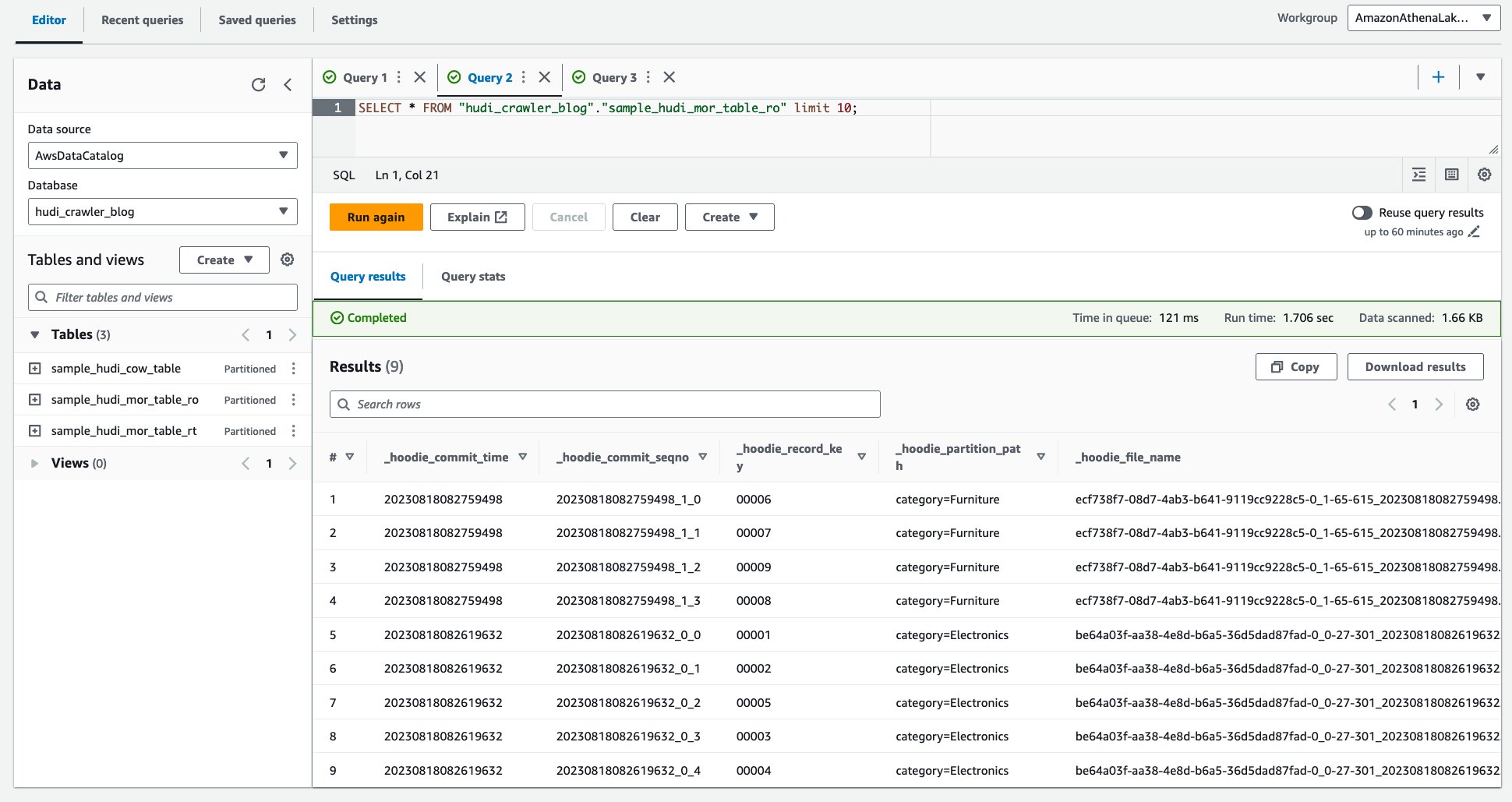
クローラーが実行されると、AWS Glue コンソールに Hudi テーブル定義の XNUMX つのテーブルが表示されます。
sample_hudi_mor_table_ro(最適化されたテーブルの読み取り)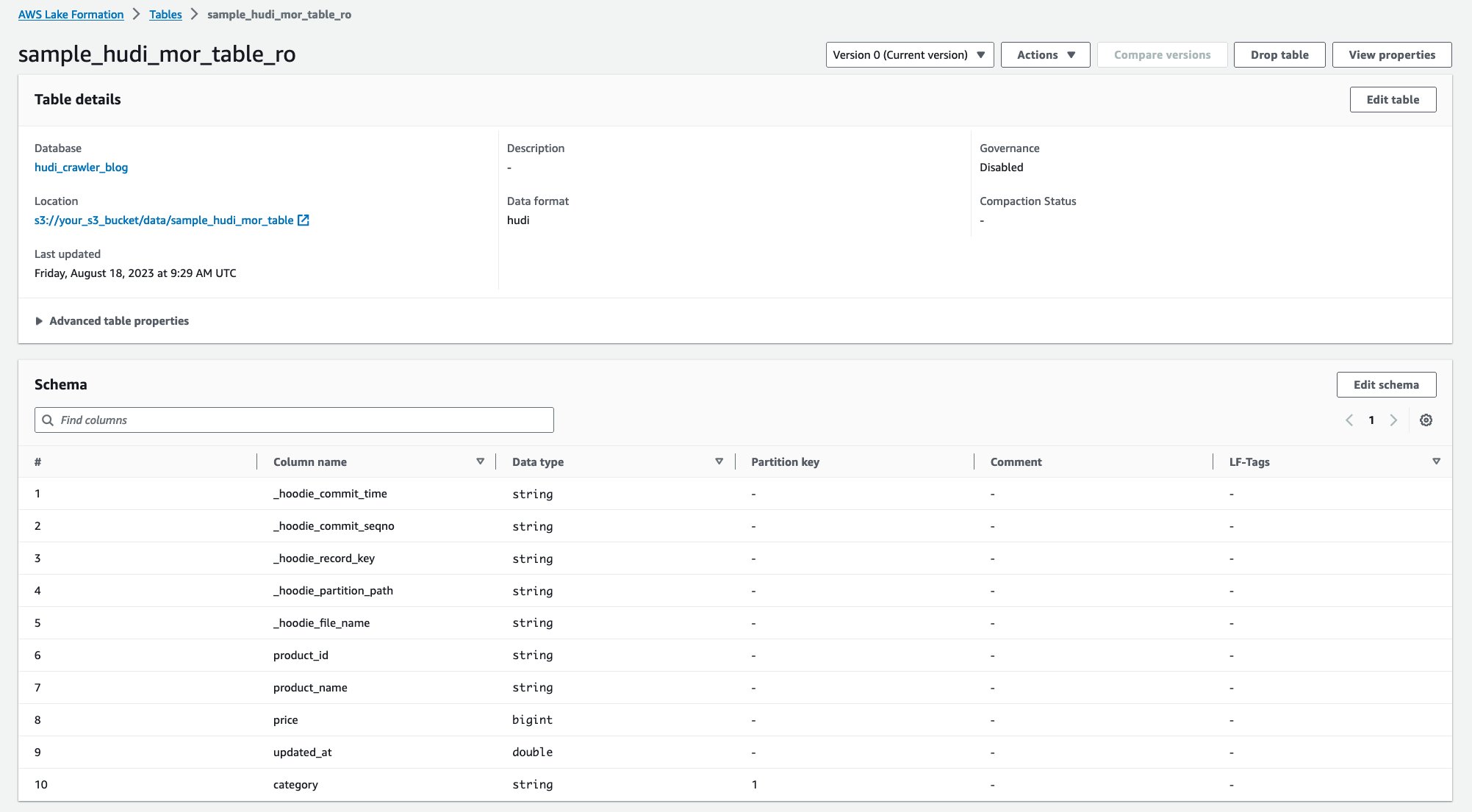
sample_hudi_mor_table_rt(リアルタイムタイムテーブル)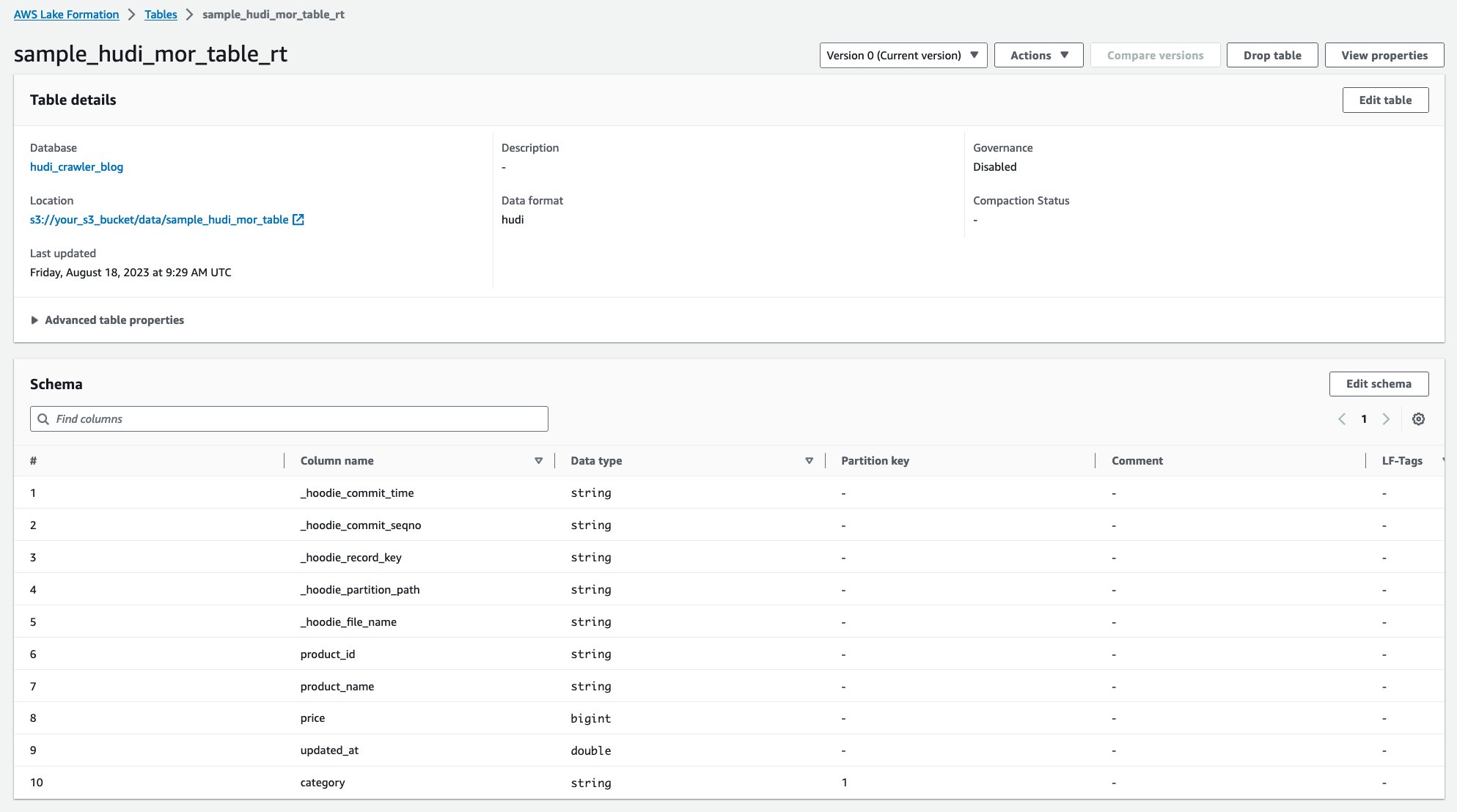
データ レイク バケットを Lake Formation に登録し、Lake Formation 権限を使用してデータ レイクへのクロール アクセスを有効にしました。 Amazon S3 上のデータを含む Hudi MoR テーブルを正常にクロールし、スキーマが設定された AWS Glue データ カタログ テーブルを作成しました。 AWS Glue データカタログでテーブル定義を作成すると、Amazon Athena などの AWS 分析サービスが Hudi テーブルにクエリを実行できるようになります。
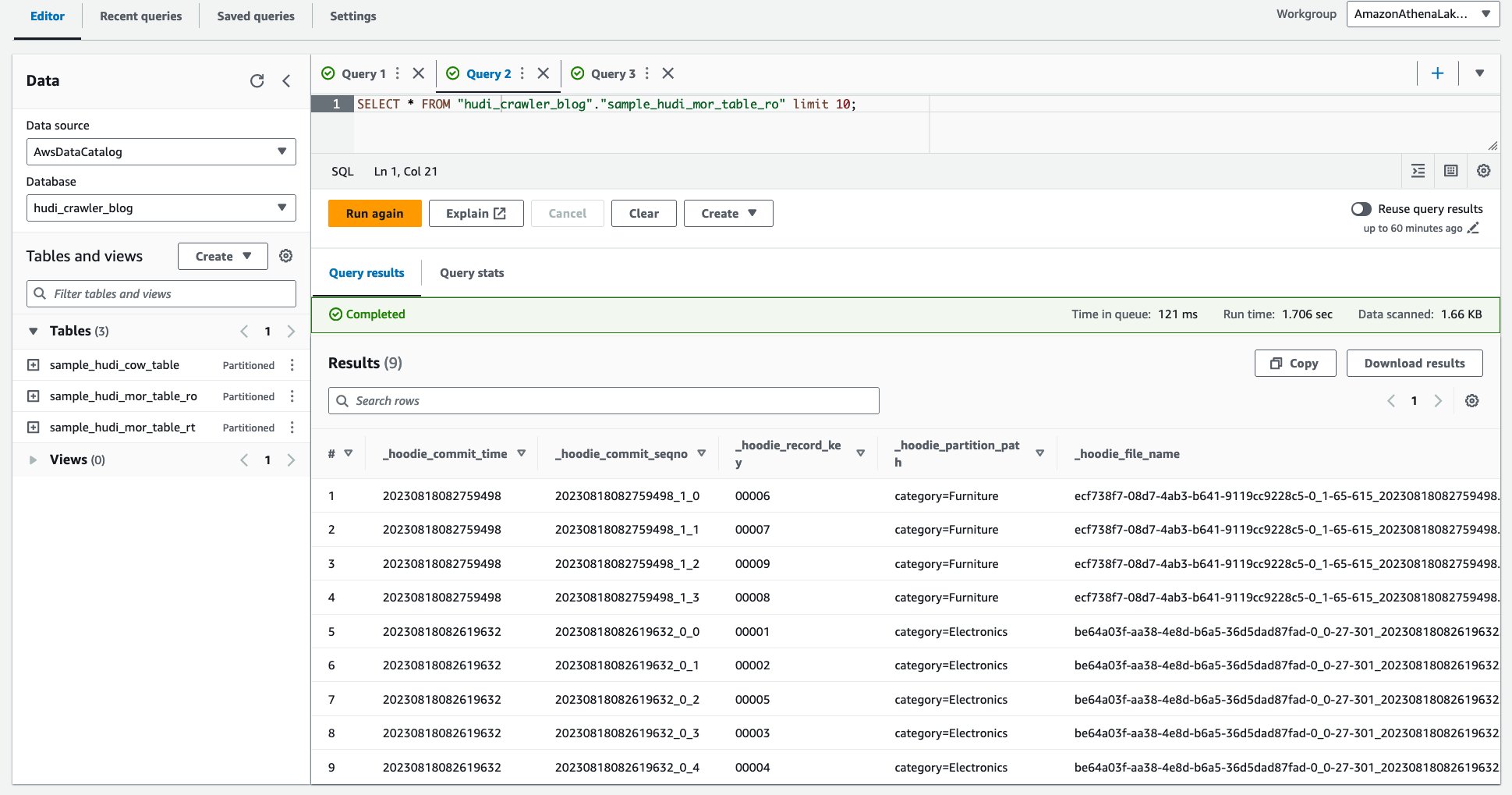
Athena でクエリを開始するには、次の手順を実行します。
- Amazon Athena コンソールを開きます。
- 次のクエリを実行します。
次のスクリーンショットは、出力を示しています。
- 次のクエリを実行します。
次のスクリーンショットは、出力を示しています。
AWS Lake Formation 権限を使用したきめ細かいアクセス制御
Hudi テーブルにきめ細かいアクセス制御を適用するには、AWS Lake Formation のアクセス許可を利用できます。 Lake Formation のアクセス許可を使用すると、特定のテーブル、列、または行へのアクセスを制限し、きめ細かいアクセス制御で Amazon Athena を通じて Hudi テーブルにクエリを実行できます。 Hudi MoR テーブルの Lake Formation 権限を構成しましょう。
前提条件
このチュートリアルの前提条件は次のとおりです。
- 前のセクションを完了してください AWS Lake Formation データ権限を持つ AWS Glue クローラーを使用して Hudi MoR テーブルをクロールする.
- AWS 管理ポリシーを持つ IAM ユーザー DataAnalyst を作成します。 AmazonAthenaフルアクセス.
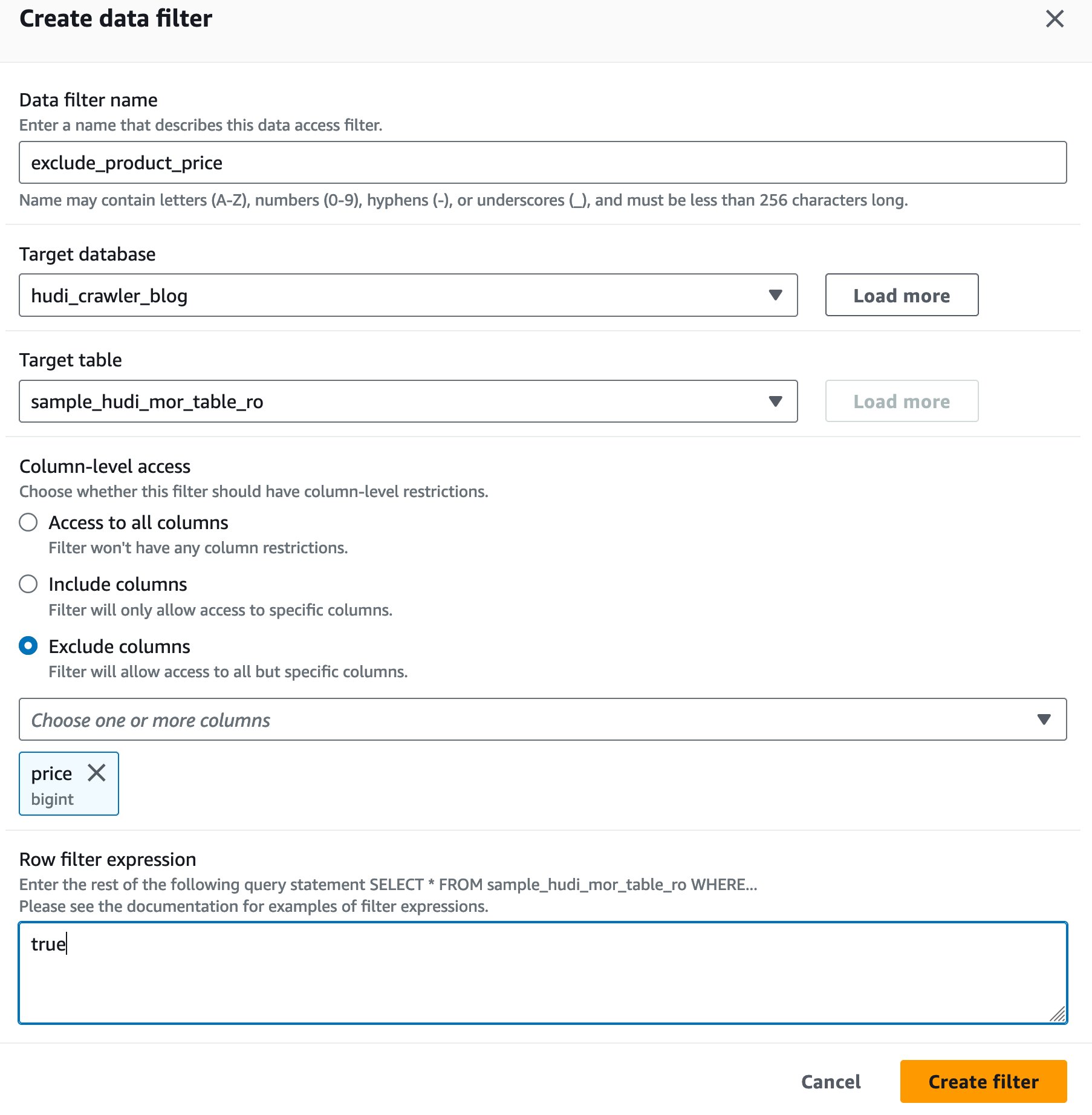
Lake Formation データ セル フィルターを作成する
まず、MoR 読み取り最適化テーブルのフィルターを設定しましょう。
- データ レイク管理者として Lake Formation コンソールにサインインします。
- 選択する データフィルター.
- 選択する 新しいフィルターを作成する.
- データフィルター名、 入る
exclude_product_price. - 対象データベース、データベースを選択します
hudi_crawler_blog. - 対象表、テーブルを選択してください
sample_hudi_mor_table_ro. - 列レベル アクセス、選択 列を除外するをクリックし、列の価格を選択します。
- 行フィルター式、 入る
true. - 選択する フィルターを作成.
DataAnalyst ユーザーに Lake Formation 権限を付与します。
次の手順を実行して、Lake Formation のアクセス許可を付与します。 DataAnalyst user
- Lake Formation コンソールで、 データレイクの許可.
- 選択する グラント.
- プリンシパル、選択する IAMユーザーとロール、ユーザーを選択します
DataAnalyst. - LF タグまたはカタログ リソース、選択する 名前付きデータカタログリソース.
- データベース、データベースを選択します
hudi_crawler_blog. - テーブル – オプション、テーブルを選択してください
sample_hudi_mor_table_ro. - データフィルター – オプション、 選択する
exclude_product_price. - データ フィルターのアクセス許可選択 選択.
- 選択する グラント.
データベースに対する Lake Formation 権限を付与しました hudi_crawler_blog そしてテーブル sample_hudi_mor_table_ro、列を除く price DataAnalyst ユーザーへ。 次に、Athena を使用してデータへのユーザー アクセスを検証してみましょう。
- DataAnalyst ユーザーとして Athena コンソールにサインインします。
- クエリ エディターで、次のクエリを実行します。
次のスクリーンショットは、出力を示しています。
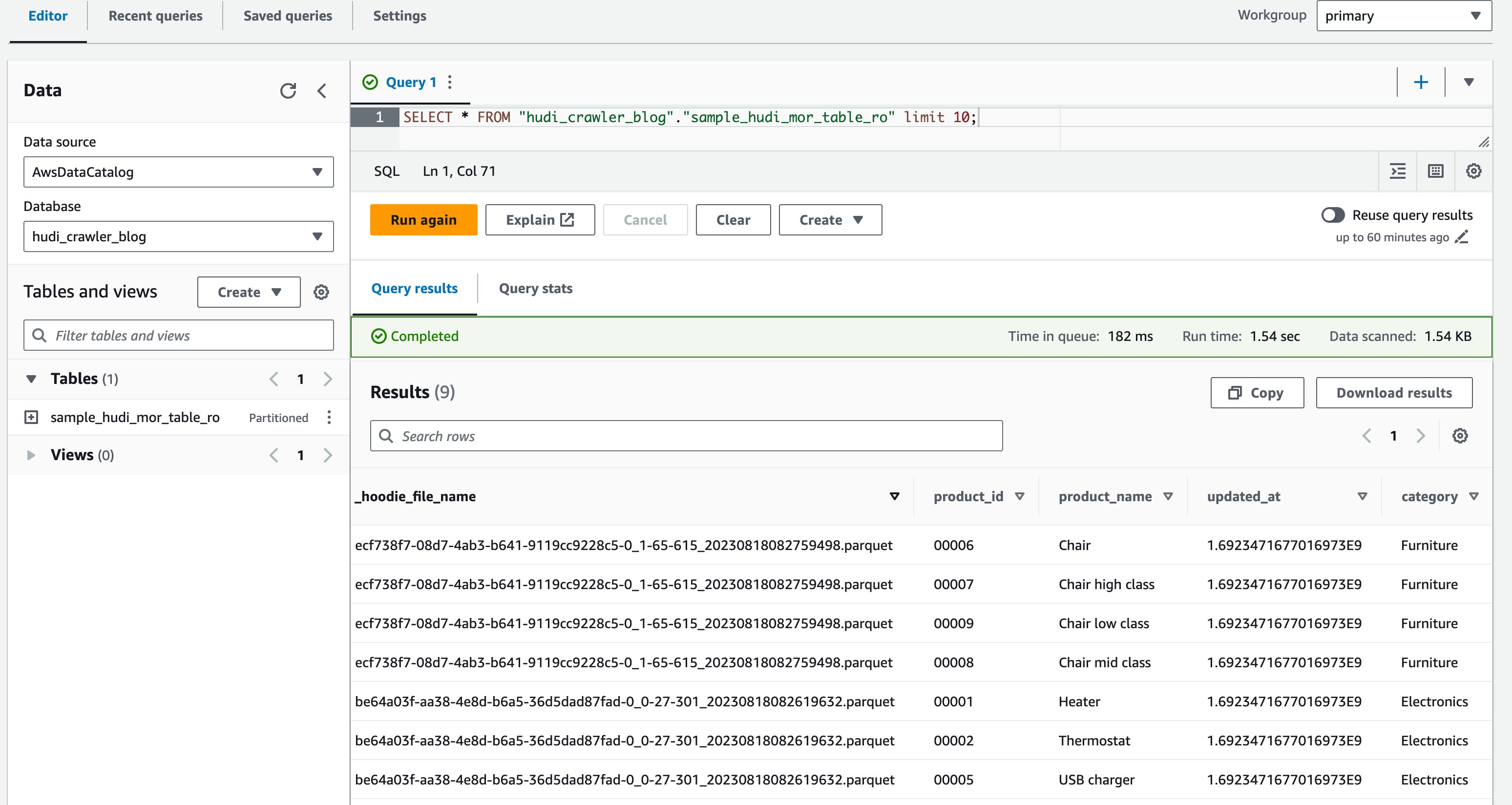
これで、列が price は表示されていませんが、他の列は product_id, product_name, update_at, category 示されています。
クリーンアップ
AWS アカウントへの不要な料金を回避するには、次の AWS リソースを削除します。
- AWS Glue データベースを削除する
hudi_crawler_blog. - AWS Glue クローラーを削除する
hudi_cow_crawlerおよびhudi_mor_crawler. - 以下の Amazon S3 ファイルを削除します
s3://your_s3_bucket/data/sample_hudi_cow_table/およびs3://your_s3_bucket/data/sample_hudi_mor_table/.
まとめ
この投稿では、AWS Glue クローラーが Hudi テーブルに対してどのように機能するかを示しました。 Hudi クローラーのサポートにより、AWS Glue データ カタログをプライマリ Hudi テーブル カタログとして使用することにすぐに移行できます。 AWS Glue、AWS Glue データカタログ、Lake Formation のきめ細かなアクセス制御を使用して、AWS 分析エンジンでサポートされているテーブルと形式のきめ細かいアクセス制御を使用して、AWS 上の Hudi を使用してサーバーレス トランザクション データ レイクの構築を開始できます。
著者について
 関山典隆 AWS Glue チームのプリンシパル ビッグ データ アーキテクトです。 彼は日本の東京を拠点に活動しています。 彼は、顧客を支援するソフトウェア アーティファクトの構築を担当しています。 余暇には、ロードバイクでサイクリングを楽しんでいます。
関山典隆 AWS Glue チームのプリンシパル ビッグ データ アーキテクトです。 彼は日本の東京を拠点に活動しています。 彼は、顧客を支援するソフトウェア アーティファクトの構築を担当しています。 余暇には、ロードバイクでサイクリングを楽しんでいます。
 カイル・ドゥオン は、AWS Glue および Lake Formation チームのソフトウェア開発エンジニアです。 彼はビッグデータテクノロジーと分散システムの構築に情熱を注いでいます。
カイル・ドゥオン は、AWS Glue および Lake Formation チームのソフトウェア開発エンジニアです。 彼はビッグデータテクノロジーと分散システムの構築に情熱を注いでいます。
 サンディープ・アドワンカー AWS のシニア テクニカル プロダクト マネージャーです。 カリフォルニア ベイ エリアに拠点を置く彼は、世界中の顧客と協力して、ビジネス要件と技術要件を製品に変換し、顧客がデータの管理、保護、およびアクセスの方法を改善できるようにしています。
サンディープ・アドワンカー AWS のシニア テクニカル プロダクト マネージャーです。 カリフォルニア ベイ エリアに拠点を置く彼は、世界中の顧客と協力して、ビジネス要件と技術要件を製品に変換し、顧客がデータの管理、保護、およびアクセスの方法を改善できるようにしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :持っている
- :は
- :not
- :どこ
- $UP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- できる
- 私たちについて
- アクセス
- データへのアクセス
- アクセス
- Action
- 加えます
- 追加されました
- 添加
- 採択
- 養子縁組
- 高度な
- 後
- すべて
- 許す
- 許可
- ことができます
- また
- Amazon
- アマゾンアテナ
- Amazon Webサービス
- an
- 分析的
- 分析論
- および
- 別の
- どれか
- アパッチ
- Apache Spark
- API
- 登場する
- 申し込み
- アプリケーション開発
- 申し込む
- です
- AREA
- 周りに
- AS
- At
- 自動的に
- 避ける
- AWS
- AWSグルー
- AWSレイクフォーメーション
- ベース
- ベース
- ベイ
- BE
- なぜなら
- き
- 恩恵
- より良いです
- ビッグ
- ビッグデータ
- もたらす
- 建物
- 内蔵
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- カリフォルニア州
- コール
- 缶
- 機能
- 機能
- 場合
- カタログ
- カタログ
- カテゴリ
- セル
- 課題
- 変化する
- 変更
- 変更
- 課金
- 選択する
- コラム
- コラム
- 組み合わせ
- コミット
- コミットした
- コンプリート
- 複雑な
- コンポーネント
- 領事
- 含まれています
- コンテンツ
- 連続的に
- コントロール
- controls
- 可能性
- クローラー
- 作ります
- 作成した
- 作成します。
- Credentials
- Customers
- データ
- データ統合
- データレイク
- データウェアハウス
- データベース
- データベースを追加しました
- データセット
- 定義
- 定義
- デルタ
- 実証
- 実証
- 深さ
- 開発
- 直接に
- 発見する
- 配布
- 分散システム
- do
- ありません
- 間に
- 各
- 容易
- 簡単に
- エディタ
- 効果的に
- 効率的な
- enable
- 使用可能
- エンジニア
- エンジニア
- エンジン
- 入力します
- エーテル(ETH)
- 進化
- 除外
- エキス
- 速いです
- より少ない
- File
- filter
- フィルター
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- 初回
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- 形成
- 頻繁に
- から
- 与えられた
- 世界
- Go
- 助成金
- 付与された
- ガイド
- Hadoopの
- 持ってる
- he
- 助けます
- ことができます
- 彼の
- ハイブ
- 認定条件
- How To
- HTML
- HTTPS
- IAM
- if
- 意義
- 改善します
- in
- 含めて
- インクリメンタル
- 情報
- を取得する必要がある者
- 統合する
- 統合
- インタフェース
- に
- 導入
- IT
- 日本
- JPG
- 保管
- 湖
- 湖
- 最新の
- 起動する
- LEARN
- 学習
- less
- LIMIT
- LINE
- リスト
- 位置して
- 場所
- 場所
- ログインして
- 機械
- 機械学習
- 保守
- make
- 作る
- 管理します
- マネージド
- マネージャー
- 管理する
- マニュアル
- マージ
- 移行中
- 移行
- ML
- 他には?
- 最も
- の試合に
- 名
- ネイティブ
- 必要
- 必要とされる
- 新作
- 新しく
- 次の
- 今
- of
- on
- ONE
- の
- 開いた
- オープンソース
- 最適化
- オプション
- or
- その他
- 私たちの
- 出力
- 部
- 情熱的な
- path
- パス
- パフォーマンス
- 許可
- パーミッション
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人気
- 人口
- ポスト
- 準備
- 前提条件
- 前
- ブランド
- 主要な
- 校長
- 処理
- プロダクト
- プロダクトマネージャー
- 製品
- 提供します
- 提供
- は、大阪で
- クエリ
- すぐに
- 読む
- リアル
- への
- リアルタイム
- 最近
- 記録
- 登録
- 登録された
- replace
- 要件
- リソース
- 責任
- 制限する
- ロード
- 職種
- 行
- ラン
- 同じ
- スケジュール
- 予定の
- SDDK
- セクション
- 安全に
- select
- シニア
- サーバレス
- サービス
- サービス
- セッションに
- 設定
- 示す
- 作品
- 簡素化する
- から
- スライス
- Snapshot
- So
- ソフトウェア
- ソフトウェア開発
- ソース
- ソース
- スパーク
- 特定の
- start
- 都道府県
- 手順
- ステップ
- 保存され
- ストリーミング
- ストリーム
- 研究
- 首尾よく
- そのような
- サポート
- サポート
- 同期。
- システム
- テーブル
- チーム
- 技術的
- テクノロジー
- それ
- アプリ環境に合わせて
- その後
- そこ。
- 彼ら
- この
- 三
- 介して
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- 東京
- top
- トランザクションの
- 取引
- 翻訳する
- トラバース
- トリガー
- トリガ
- チュートリアル
- 2
- 典型的な
- 下
- 不要な
- アップデイト
- 更新しました
- 更新版
- つかいます
- 使用事例
- 中古
- ユーザー
- users
- 使用されます
- 検証
- 検証済み
- 価値観
- バージョン
- ビジュアル
- 倉庫
- we
- ウェブ
- Webサービス
- WELL
- いつ
- which
- while
- 誰
- 意志
- 無し
- 仕事
- 作品
- 書きます
- 書かれた
- 貴社
- あなたの
- あなた自身
- ゼファーネット