OpenAI ChatGPT が 24 時間のニュース サイクルからすべての酸素を吸い上げている一方で、Google は、ビデオ、画像、およびテキスト入力が与えられたときにビデオを生成できる新しい AI モデルを静かに発表しました。 新しい Google Dreamix AI ビデオ エディターは、生成されたビデオを現実に近づけるようになりました。
GitHub で公開された調査によると、Dreamix はビデオとテキスト プロンプトに基づいてビデオを編集します。 結果として得られるビデオは、色、姿勢、オブジェクト サイズ、およびカメラ ポーズに対する忠実度を維持し、時間的に一貫したビデオになります。 現時点では、Dreamix はプロンプトだけからビデオを生成することはできませんが、既存の素材を使用して、テキスト プロンプトを使用してビデオを変更することはできます。
Google は Dreamix にビデオ拡散モデルを使用しています。このアプローチは、DALL-E2 やオープンソースの Stable Diffusion などの画像 AI で見られるほとんどのビデオ画像編集に適用され、成功しています。
このアプローチでは、入力ビデオを大幅に削減し、人工的なノイズを追加してから、ビデオ拡散モデルで処理します。次に、テキスト プロンプトを使用して、元のビデオの一部のプロパティを保持し、他のものを再レンダリングする新しいビデオを生成します。テキスト入力に。
ビデオ拡散モデルは、ビデオを扱う新しい時代の到来を告げる有望な未来を提供します。

たとえば、下のビデオでは、Dreamix は、「クマが踊ったり、アップビートな音楽に合わせてジャンプしたり、体全体を動かしたりしています」というプロンプトが表示されると、食べているサル (左) を踊るクマ (右) に変えます。
以下の別の例では、Dreamix は XNUMX つの写真をテンプレートとして使用し (イメージからビデオへのように)、オブジェクトはプロンプトを介してビデオ内でアニメーション化されます。 カメラの動きは、新しいシーンまたはその後のタイムラプス録画でも可能です。
別の例では、Dreamix は、水たまりにいるオランウータン (左) を、美しいバスルームで水浴びをしているオレンジ色の髪のオランウータンに変えます。
「拡散モデルは画像編集にうまく適用されていますが、ビデオ編集に適用された作品はほとんどありません。 一般的なビデオのテキストベースのモーションおよび外観編集を実行できる最初の拡散ベースの方法を提示します。」
Google の研究論文によると、Dreamix はビデオ拡散モデルを使用して、推論時に、元のビデオからの低解像度の時空間情報を、ガイド テキスト プロンプトに合わせて合成した新しい高解像度の情報と組み合わせます。」
Google によると、このアプローチを採用した理由は、「元の動画を忠実に再現するには、高解像度の情報の一部を保持する必要があるためです。元の動画のモデルを微調整する予備段階を追加することで、忠実度を大幅に高めることができます」と述べています。
以下は、Dreamix がどのように機能するかのビデオ概要です。
[埋め込まれたコンテンツ]
Dreamix ビデオ拡散モデルの仕組み
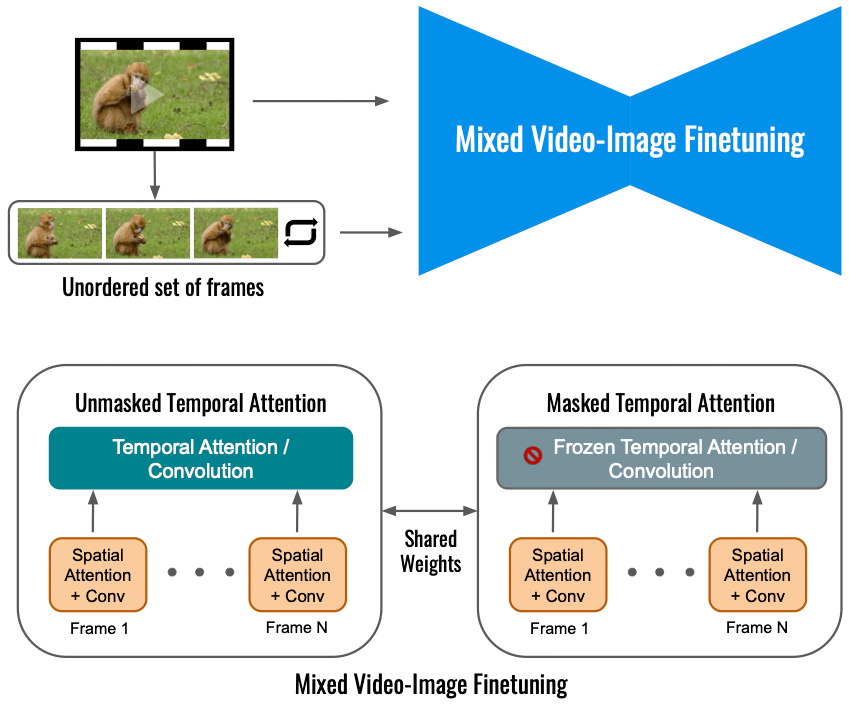
Google によると、入力ビデオだけで Dreamix のビデオ拡散モデルを微調整すると、モーションの変化の範囲が制限されます。 代わりに、元の目的 (左下) に加えて、フレームの順序付けられていないセットを微調整する混合目的を使用します。 これは、「マスクされた時間的注意」を使用して行われ、時間的注意と畳み込みが微調整されるのを防ぎます (右下)。 これにより、静止ビデオにモーションを追加できます。
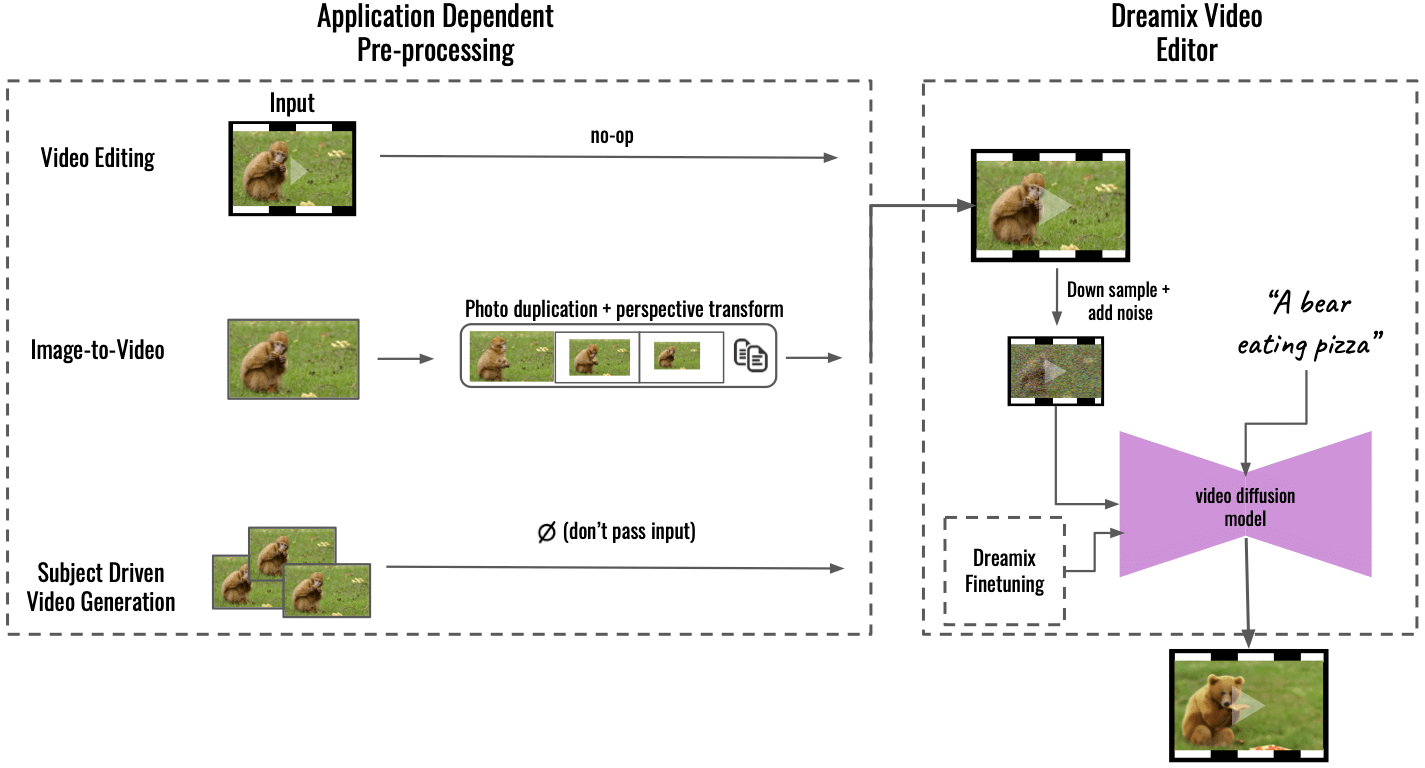
「私たちの方法は、アプリケーションに依存する前処理 (左) によって複数のアプリケーションをサポートし、入力コンテンツを統一されたビデオ形式に変換します。 画像からビデオへの変換では、入力画像が複製され、透視変換を使用して変換され、粗いビデオとカメラの動きが合成されます。 被写体主導のビデオ生成の場合、入力は省略されます。微調整のみが忠実度を処理します。 この粗いビデオは、一般的な「Dreamix ビデオ エディタ」(右) を使用して編集されます。最初にダウンサンプリングしてビデオを破損し、続いてノイズを追加します。 次に、微調整されたテキストガイド付きビデオ拡散モデルを適用し、ビデオを最終的な時空間解像度にアップスケールします」と Dream は書いています。 GitHubの.
以下の研究論文を読むことができます。
Google ドリームミックス- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://techstartups.com/2023/02/10/google-launches-ai-powered-video-editor-dreamix-to-create-edit-videos-and-animate-images/
- a
- できる
- 従った
- AI
- AIビデオ
- AI電源
- すべて
- ことができます
- 一人で
- &
- 別の
- 適用された
- 申し込む
- アプローチ
- 人工の
- 注意
- ベース
- くま
- 美しい
- なぜなら
- さ
- 以下
- ボディ
- 後押し
- ボトム
- もたらす
- カメラ
- これ
- 変化する
- AI言語モデルを活用してコードのデバッグからデータの異常検出まで、
- クローザー
- カラー
- 組み合わせる
- 整合性のある
- コンテンツ
- 作成
- サイクル
- ダンシング
- 夢
- エディタ
- 埋め込まれた
- 時代
- 例
- 既存の
- 少数の
- 忠実
- ファイナル
- 名
- 続いて
- 形式でアーカイブしたプロジェクトを保存します.
- から
- 未来
- 生成する
- 生成された
- 世代
- GIF
- GitHubの
- 与えられた
- でログイン
- ヘア
- 重く
- 高解像度の
- 認定条件
- しかしながら
- HTTPS
- 画像
- 画像
- in
- 情報
- を取得する必要がある者
- IT
- 起動
- 制限
- 維持
- 材料
- マックス
- 方法
- 混合
- モデル
- 修正する
- 瞬間
- 最も
- モーション
- 動作
- 移動する
- の試合に
- 音楽を聴く際のスピーカーとして
- 新作
- ニュース
- ノイズ
- オブジェクト
- 客観
- オファー
- オープンソース
- OpenAI
- オレンジ
- オリジナル
- その他
- 概要
- 酸素
- 紙素材
- 実行する
- 視点
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プール
- 可能
- 現在
- 予防
- 処理
- 有望
- プロパティ
- 公表
- 静かに
- 読む
- 現実
- 録音
- 縮小
- 必要
- 研究
- 解像度
- 結果として
- 保持
- 前記
- シーン
- セッションに
- 著しく
- サイズ
- So
- 一部
- 安定した
- ステージ
- それに続きます
- 首尾よく
- そのような
- サポート
- 取る
- template
- 時間
- 〜へ
- 変換
- 変換
- 発表
- つかいます
- 、
- ビデオ
- 動画
- 水
- which
- ワーキング
- 作品
- ユーチューブ
- ゼファーネット











