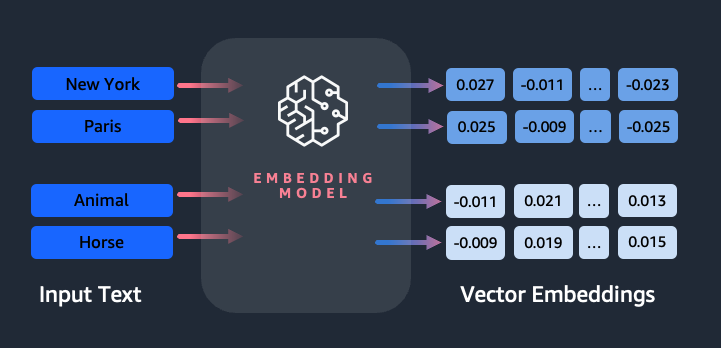
埋め込みは、自然言語処理 (NLP) と機械学習 (ML) において重要な役割を果たします。 テキストの埋め込み テキストを高次元ベクトル空間に存在する数値表現に変換するプロセスを指します。この手法は、データの意味とコンテキスト (意味的関係) の理解と、データ内の複雑な関係とパターン (構文的関係) の学習を可能にする ML アルゴリズムの使用によって実現されます。結果のベクトル表現は、情報検索、テキスト分類、自然言語処理などの幅広いアプリケーションに使用できます。
Amazon Titan テキスト埋め込み は、単一の単語、語句、または大きなドキュメントで構成される自然言語テキストを、意味的類似性に基づいた検索、パーソナライゼーション、クラスタリングなどのユースケースを強化するために使用できる数値表現に変換するテキスト埋め込みモデルです。
この投稿では、Amazon Titan Text Embeddings モデル、その機能、および使用例について説明します。
いくつかの重要な概念は次のとおりです。
- テキストの数値表現 (ベクトル) は、単語間の意味論と関係を捉えます。
- 豊富な埋め込みを使用してテキストの類似性を比較できます
- 多言語テキスト埋め込みにより、さまざまな言語の意味を識別できる
テキストの一部はどのようにベクトルに変換されるのでしょうか?
文をベクトルに変換する手法は複数あります。一般的な方法の 2 つは、WordXNUMXVec、GloVe、FastText などの単語埋め込みアルゴリズムを使用し、単語埋め込みを集約して文レベルのベクトル表現を形成する方法です。
もう 1 つの一般的なアプローチは、BERT や GPT などの大規模言語モデル (LLM) を使用することです。これにより、文全体にコンテキストに応じた埋め込みを提供できます。これらのモデルは、Transformers などの深層学習アーキテクチャに基づいており、文内の文脈情報や単語間の関係をより効果的にキャプチャできます。
なぜエンベディングモデルが必要なのでしょうか?
ベクトル埋め込みは、LLM が言語の意味論的な度合いを理解するための基礎であり、LLM が感情分析、固有表現認識、テキスト分類などの下流の NLP タスクで適切に実行できるようにします。
セマンティック検索に加えて、埋め込みを使用してプロンプトを拡張し、検索拡張生成 (RAG) を通じてより正確な結果を得ることができます。ただし、それらを使用するには、ベクトル機能を備えたデータベースに格納する必要があります。
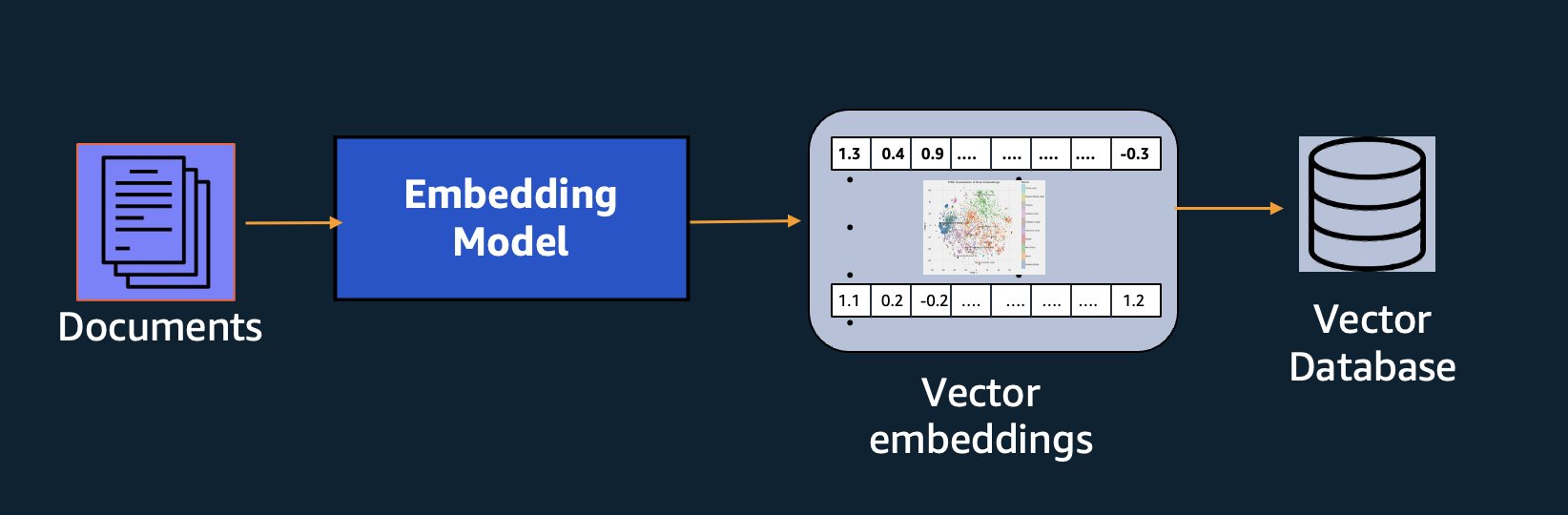
Amazon Titan Text Embeddings モデルは、RAG ユースケースを可能にするテキスト取得用に最適化されています。これにより、最初にテキスト データを数値表現またはベクトルに変換し、次にそれらのベクトルを使用してベクトル データベースから関連する文章を正確に検索できるため、独自のデータを他の基盤モデルと組み合わせて最大限に活用できます。
Amazon Titan Text Embeddings は、 アマゾンの岩盤、完全にサーバーレスのエクスペリエンスとして提供されます。 Amazon Bedrock REST 経由で使用できます。 API または AWS SDK。必須パラメータは、埋め込みを生成するテキストと、 modelID パラメータ。Amazon Titan Text Embeddings モデルの名前を表します。次のコードは、AWS SDK for Python (Boto3) を使用した例です。
出力は次のようになります。
参照する Amazon Bedrock boto3 のセットアップ 必要なパッケージのインストール、Amazon Bedrock への接続、モデルの呼び出し方法の詳細については、を参照してください。
Amazon Titan テキスト埋め込みの機能
Amazon Titan Text Embeddings を使用すると、最大 8,000 個のトークンを入力できるため、ユースケースに基づいて単一の単語、フレーズ、またはドキュメント全体を操作するのに適しています。 Amazon Titan は次元 1536 の出力ベクトルを返すため、高い精度が得られると同時に、低レイテンシーでコスト効率の高い結果が得られるように最適化されます。
Amazon Titan Text Embeddings は、25 を超える異なる言語でのテキストの埋め込みの作成とクエリをサポートしています。これは、サポートする言語ごとに個別のモデルを作成して維持する必要がなく、モデルをユースケースに適用できることを意味します。
単一のエンベディング モデルを多くの言語でトレーニングすると、次のような主な利点が得られます。
- リーチの拡大 – 25 を超える言語をすぐにサポートできるため、多くの国際市場のユーザーやコンテンツにアプリケーションの適用範囲を拡大できます。
- 一貫したパフォーマンス – 複数の言語をカバーする統合モデルにより、言語ごとに個別に最適化するのではなく、言語間で一貫した結果が得られます。モデルは総合的にトレーニングされるため、言語を超えて利点が得られます。
- 多言語クエリのサポート – Amazon Titan Text Embeddings を使用すると、サポートされている言語でテキスト埋め込みをクエリできます。これにより、単一言語に制限されることなく、言語間で意味的に類似したコンテンツを取得できる柔軟性が得られます。同じ統合された埋め込みスペースを使用して、多言語データのクエリと分析を行うアプリケーションを構築できます。
この記事の執筆時点では、次の言語がサポートされています。
- アラビア語
- 中国語(簡体字)
- 中国語(繁体字)
- チェコ語
- オランダ語
- 英語
- フランス語
- ドイツ語
- ヘブライ語
- ヒンディー語
- イタリア語
- 日本語
- カンナダ語
- 韓国語
- マラヤーラム語
- マラーティー語
- ポーランド語
- ポルトガル語
- ロシア語
- スペイン語
- スウェーデン語
- フィリピン語・タガログ語
- タミル語
- テルグ語
- トルコ語
LangChain での Amazon Titan テキスト埋め込みの使用
ラングチェーン は、生成 AI モデルとサポート テクノロジを操作するための人気のあるオープン ソース フレームワークです。それには、 BedrockEmbedding クライアント これは、Boto3 SDK を抽象化レイヤーで便利にラップします。の BedrockEmbeddings クライアントを使用すると、JSON リクエストまたはレスポンス構造の詳細を知らなくても、テキストと埋め込みを直接操作できます。以下は簡単な例です。
LangChain を使用することもできます BedrockEmbeddings Amazon Bedrock LLM クライアントと並行して使用すると、RAG、セマンティック検索、その他の埋め込み関連パターンの実装が簡素化されます。
埋め込みの使用例
RAG は現在、埋め込みを操作する最も一般的なユース ケースですが、埋め込みを適用できるユース ケースは他にもたくさんあります。以下に、エンベディングを単独で、または LLM と連携して使用して特定の問題を解決できる追加のシナリオをいくつか示します。
- 質問と答え – 埋め込みは、RAG パターンを通じて質問と回答のインターフェイスをサポートするのに役立ちます。エンベディング生成とベクトル データベースを組み合わせることにより、ナレッジ リポジトリ内の質問とコンテンツの間で厳密に一致するものを見つけることができます。
- パーソナライズされた推奨事項 – 質問と回答と同様に、埋め込みを使用して、ユーザーが指定した基準に基づいて休暇の目的地、大学、乗り物、またはその他の製品を検索できます。これは単純な一致リストの形式を取ることも、LLM を使用して各推奨事項を処理し、それがユーザーの基準をどのように満たしているかを説明することもできます。このアプローチを使用して、ユーザーの特定のニーズに基づいて、ユーザー向けのカスタムの「ベスト 10」記事を生成することもできます。
- データ管理 – データ ソースが相互に明確にマッピングされていないが、データ レコードを説明するテキスト コンテンツがある場合、埋め込みを使用して重複する可能性のあるレコードを特定できます。たとえば、埋め込みを使用して、異なる書式設定や略語が使用されている可能性がある、または名前が翻訳されている可能性がある重複した候補を識別できます。
- アプリケーションポートフォリオの合理化 – 親会社と買収先全体でアプリケーション ポートフォリオを調整しようとする場合、重複する可能性のあるものをどこから見つけ始めればよいのかが必ずしも明らかではありません。構成管理データの品質が制限要因となる可能性があり、アプリケーションの状況を理解するためにチーム間で調整することが困難になる場合があります。埋め込みとのセマンティック マッチングを使用することで、アプリケーション ポートフォリオ全体を迅速に分析して、合理化の可能性が高い候補アプリケーションを特定できます。
- コンテンツのグループ化 – 埋め込みを使用すると、類似したコンテンツを事前には分からないカテゴリに簡単にグループ化できます。たとえば、顧客からの電子メールやオンラインの製品レビューのコレクションがあるとします。アイテムごとに埋め込みを作成し、それらの埋め込みを実行できます。 k-クラスタリングを意味します 顧客の懸念、製品の賞賛や苦情、その他のテーマを論理的にグループ化して特定します。その後、LLM を使用して、それらのグループのコンテンツから焦点を絞った概要を生成できます。
セマンティック検索の例
GitHub 上の例では、Amazon Titan Text Embeddings、LangChain、Streamlit を使用した単純な埋め込み検索アプリケーションを示します。
この例では、ユーザーのクエリをメモリ内のベクトル データベース内の最も近いエントリと照合します。次に、それらの一致をユーザー インターフェイスに直接表示します。これは、RAG アプリケーションのトラブルシューティングを行う場合、または埋め込みモデルを直接評価する場合に役立ちます。
簡単にするために、インメモリを使用します。 フェイス 埋め込みベクトルを保存および検索するためのデータベース。実際の大規模なシナリオでは、次のような永続データ ストアを使用することになるでしょう。 Amazon OpenSearch サーバーレス用のベクトル エンジン または ベクター PostgreSQL の拡張機能。
Web アプリケーションからさまざまな言語で次のようなプロンプトをいくつか試してみます。
- 自分の使用状況を監視するにはどうすればよいですか?
- モデルをカスタマイズするにはどうすればよいですか?
- どのプログラミング言語を使用できますか?
- コメントを送信してください。
- 私のデータはどのように保護されていますか?
- Bedrock のモデルを開発する場所はありますか?
- ウェルヒェン地域では Amazon Bedrock が最適ですか?
- いくつかのサポートがありますか?
ソース資料が英語であっても、他の言語のクエリが関連するエントリと一致することに注意してください。
まとめ
基礎モデルのテキスト生成機能は非常に魅力的ですが、生成 AI の価値を最大限に発揮するには、テキストを理解し、知識体系から関連するコンテンツを見つけ、文章間の接続を作成することが重要であることを覚えておくことが重要です。これらのモデルが改善され続けるにつれて、今後数年間にわたって、埋め込みの新しくて興味深い使用例が出現し続けるでしょう。
次のステップ
次のワークショップでは、ノートブックまたはデモ アプリケーションとして埋め込みの追加の例を見つけることができます。
著者について
 ジェイソン・ステール は、ニューイングランド地域に拠点を置く AWS のシニア ソリューション アーキテクトです。 彼は顧客と協力して、AWS の機能をビジネスの最大の課題に合わせて調整しています。 仕事以外では、ものを作ったり、家族と一緒に漫画映画を観たりして時間を過ごしています。
ジェイソン・ステール は、ニューイングランド地域に拠点を置く AWS のシニア ソリューション アーキテクトです。 彼は顧客と協力して、AWS の機能をビジネスの最大の課題に合わせて調整しています。 仕事以外では、ものを作ったり、家族と一緒に漫画映画を観たりして時間を過ごしています。
 ニティン・エウセビウス AWS のシニア エンタープライズ ソリューション アーキテクトであり、ソフトウェア エンジニアリング、エンタープライズ アーキテクチャ、AI/ML の経験があります。彼は生成 AI の可能性を探求することに深い情熱を持っています。彼は顧客と協力して、AWS プラットフォーム上で適切に設計されたアプリケーションを構築できるよう支援し、テクノロジーの課題を解決し、クラウドへの移行を支援することに専念しています。
ニティン・エウセビウス AWS のシニア エンタープライズ ソリューション アーキテクトであり、ソフトウェア エンジニアリング、エンタープライズ アーキテクチャ、AI/ML の経験があります。彼は生成 AI の可能性を探求することに深い情熱を持っています。彼は顧客と協力して、AWS プラットフォーム上で適切に設計されたアプリケーションを構築できるよう支援し、テクノロジーの課題を解決し、クラウドへの移行を支援することに専念しています。
 ラジ・パタク は、カナダと米国のフォーチュン 50 に名を連ねる大企業および中堅金融サービス機関 (FSI) のプリンシパル ソリューション アーキテクトおよびテクニカル アドバイザーです。彼は、生成 AI、自然言語処理、インテリジェント文書処理、MLOps などの機械学習アプリケーションを専門としています。
ラジ・パタク は、カナダと米国のフォーチュン 50 に名を連ねる大企業および中堅金融サービス機関 (FSI) のプリンシパル ソリューション アーキテクトおよびテクニカル アドバイザーです。彼は、生成 AI、自然言語処理、インテリジェント文書処理、MLOps などの機械学習アプリケーションを専門としています。
 マニカヌジャ テックリード – ジェネレーティブ AI スペシャリストであり、書籍「Applied Machine Learning and High Performance Computing on AWS」の著者であり、女性製造教育財団理事会のメンバーでもあります。 彼女は、コンピューター ビジョン、自然言語処理、生成 AI などのさまざまなドメインで機械学習 (ML) プロジェクトを主導しています。 彼女は、顧客が大規模な機械学習モデルを構築、トレーニング、デプロイできるよう支援します。 彼女は、re:Invent、Women in Manufacturing West、YouTube ウェビナー、GHC 23 などの社内外のカンファレンスで講演しています。自由時間には、ビーチに沿って長距離を走るのが好きです。
マニカヌジャ テックリード – ジェネレーティブ AI スペシャリストであり、書籍「Applied Machine Learning and High Performance Computing on AWS」の著者であり、女性製造教育財団理事会のメンバーでもあります。 彼女は、コンピューター ビジョン、自然言語処理、生成 AI などのさまざまなドメインで機械学習 (ML) プロジェクトを主導しています。 彼女は、顧客が大規模な機械学習モデルを構築、トレーニング、デプロイできるよう支援します。 彼女は、re:Invent、Women in Manufacturing West、YouTube ウェビナー、GHC 23 などの社内外のカンファレンスで講演しています。自由時間には、ビーチに沿って長距離を走るのが好きです。
 マークロイ AWS のプリンシパル機械学習アーキテクトとして、顧客の AI/ML ソリューションの設計と構築を支援しています。 Mark の仕事は、コンピュータ ビジョン、ディープ ラーニング、企業全体での ML のスケーリングに主な関心を持っており、幅広い ML ユースケースをカバーしています。 彼は、保険、金融サービス、メディアとエンターテイメント、ヘルスケア、公益事業、製造など、多くの業界の企業を支援してきました。 Mark は、ML スペシャリティ認定を含む 25 つの AWS 認定を取得しています。 AWS に入社する前、Mark は 19 年以上にわたってアーキテクト、開発者、テクノロジーのリーダーとして活躍し、その中には金融サービスでの XNUMX 年間の勤務も含まれます。
マークロイ AWS のプリンシパル機械学習アーキテクトとして、顧客の AI/ML ソリューションの設計と構築を支援しています。 Mark の仕事は、コンピュータ ビジョン、ディープ ラーニング、企業全体での ML のスケーリングに主な関心を持っており、幅広い ML ユースケースをカバーしています。 彼は、保険、金融サービス、メディアとエンターテイメント、ヘルスケア、公益事業、製造など、多くの業界の企業を支援してきました。 Mark は、ML スペシャリティ認定を含む 25 つの AWS 認定を取得しています。 AWS に入社する前、Mark は 19 年以上にわたってアーキテクト、開発者、テクノロジーのリーダーとして活躍し、その中には金融サービスでの XNUMX 年間の勤務も含まれます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :持っている
- :は
- :not
- :どこ
- $UP
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- 私たちについて
- 抽象化
- 同意
- 精度
- 正確な
- 正確にデジタル化
- 達成
- 達成する
- 買収
- 越えて
- 添加
- NEW
- 利点
- 顧問
- 先んじて
- AI
- AIモデル
- AI / ML
- アルゴリズム
- 整列する
- すべて
- 許す
- 許可
- ことができます
- 沿って
- 並んで
- また
- 常に
- Amazon
- Amazon Webサービス
- an
- 分析
- 分析します
- および
- 回答
- どれか
- 申し込み
- 適用された
- 申し込む
- アプローチ
- 建築
- アーキテクチャ
- です
- AREA
- 物品
- AS
- 支援する
- At
- 増強
- 増強された
- 著者
- 利用できます
- AWS
- ベース
- BE
- (ダグラス・ビーチ)
- さ
- 利点
- の間に
- ボード
- 取締役会
- ボディ
- 本
- ボックス
- ビルド
- 建物
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- カナダ
- 候補者
- 候補
- 機能
- キャプチャー
- キャプチャ
- 場合
- 例
- カテゴリ
- 認証
- 認定
- 課題
- 分類
- クライアント
- 閉じる
- クラウド
- クラスタリング
- コード
- コレクション
- 大学
- 組み合わせ
- コマンドと
- 企業
- 会社
- 比較します
- 不満
- 複雑な
- コンピュータ
- Computer Vision
- コンピューティング
- コンセプト
- 懸念事項
- 会議
- お問合せ
- 接続
- Connections
- 整合性のある
- コンテンツ
- コンテキスト
- 文脈上の
- 続ける
- 便利に
- 変換
- 変換
- 協力
- 調整する
- コスト効率の良い
- 可能性
- カバーする
- カバー
- 作ります
- 作成
- 基準
- 重大な
- 現在
- カスタム
- 顧客
- Customers
- カスタマイズ
- データ
- データベース
- de
- 専用の
- 深いです
- 深い学習
- 深く
- 定義します
- 度
- デモ
- 実証します
- 展開します
- 説明する
- 設計
- 目的地
- 細部
- Developer
- 異なります
- 難しい
- 次元
- 直接に
- 取締役
- 話し合います
- ディスプレイ
- do
- ドキュメント
- ドキュメント
- ドメイン
- ドント
- 各
- 教育
- 効果的に
- どちら
- メール
- 埋め込み
- 出てくる
- enable
- 可能
- エンジン
- エンジニアリング
- イングランド
- 英語
- Enterprise
- エンタープライズ・ソリューション
- エンターテインメント
- 全体
- 完全に
- エンティティ
- エーテル(ETH)
- 評価する
- さらに
- 例
- 例
- エキサイティング
- 詳細
- 体験
- 経験豊かな
- 説明する
- 探る
- 外部
- 容易にする
- 要因
- 家族
- 特徴
- 少数の
- ファイナンシャル
- 金融業務
- もう完成させ、ワークスペースに掲示しましたか?
- 発見
- 名
- 柔軟性
- 焦点を当て
- フォロー中
- フォーム
- フォーチュン
- Foundation
- フレームワーク
- 無料版
- から
- フル
- 基本的な
- 生成する
- 世代
- 生々しい
- 生成AI
- 取得する
- 受け
- 与え
- グローブ
- Go
- 最大
- 持っていました
- 持ってる
- he
- ヘルスケア
- 助けます
- 助けました
- 助け
- ことができます
- 彼女の
- ハイ
- ハイパフォーマンス・コンピューティング
- 彼の
- 保持している
- 認定条件
- How To
- HTML
- HTTPS
- i
- 識別する
- if
- 実装
- import
- 重要
- 改善します
- in
- その他の
- include
- 含ま
- 含めて
- 産業
- 情報
- install
- を取得する必要がある者
- 機関
- 保険
- インテリジェント-
- インテリジェントなドキュメント処理
- 関心
- 興味深い
- インタフェース
- インターフェース
- 内部
- 世界全体
- に
- IT
- ITS
- 参加
- 旅
- JPG
- JSON
- キー
- 知っている
- 知っている
- 知識
- 風景
- 言語
- ESL, ビジネスESL <br> 中国語/フランス語、その他
- 大
- 層
- つながる
- リーダー
- リード
- 学習
- う
- ような
- 可能性が高い
- 好き
- 制限する
- リスト
- LLM
- 論理的な
- 長い
- 見て
- 探して
- 機械
- 機械学習
- 維持する
- make
- 作成
- マネージド
- 管理
- 製造業
- 多くの
- 地図
- マーク
- マークス
- マーケット
- マッチ
- マッチ
- マッチング
- 材料
- me
- 意味
- 手段
- メディア
- メンバー
- 方法
- かもしれない
- ML
- MLアルゴリズム
- MLOps
- モデル
- モニター
- 他には?
- 最も
- 一番人気
- 動画
- の試合に
- my
- 名
- 名前付き
- 名
- ナチュラル
- 自然言語
- 自然言語処理
- 必要
- 必要
- ニーズ
- 新作
- 次の
- NLP
- ノートPC
- 明白
- of
- 提供
- on
- ONE
- オンライン
- 開いた
- オープンソース
- 最適化
- 最適化
- or
- 注文
- その他
- その他
- 私たちの
- でる
- 出力
- 外側
- が
- 自分の
- パッケージ
- 対になった
- パラメーター
- パラメータ
- 親会社
- 通路
- 情熱的な
- パターン
- パターン
- 以下のために
- 実行する
- パフォーマンス
- 個人化
- フレーズ
- ピース
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイ
- お願いします
- 人気
- BY
- ポートフォリオ
- ポートフォリオ
- の可能性
- ポスト
- Postgresql
- 潜在的な
- 電力
- 主要な
- 校長
- 印刷物
- 事前の
- 問題
- プロセス
- 処理
- プロダクト
- 商品レビュー
- 製品
- プログラミング
- プログラミング言語
- プロジェクト(実績作品)
- プロンプト
- 所有権
- 提供します
- 提供
- は、大阪で
- Python
- 品質
- クエリ
- クエリー
- 質問
- 質問
- クイック
- ぼろ
- 範囲
- RE
- リーチ
- 現実の世界
- 認識
- おすすめ
- 提言
- 記録
- 記録
- 指し
- の関係
- 関連した
- 覚えています
- 倉庫
- 表現
- 表し
- 要求
- の提出が必要です
- 応答
- REST
- 制限されました
- 結果として
- 結果
- 検索
- 収益
- レビュー
- 職種
- ラン
- runs
- s
- 同じ
- 言う
- 規模
- スケーリング
- シナリオ
- シナリオ
- SDDK
- を検索
- セマンティック
- 意味論
- シニア
- 文
- 感情
- 別
- サーバレス
- サービス
- 彼女
- 同様の
- 簡単な拡張で
- 単純
- 簡略化されました
- 簡素化する
- SIX
- So
- ソフトウェア
- ソフトウェア工学
- ソリューション
- 解決する
- 解決
- 一部
- 何か
- ソース
- ソース
- スペース
- スピークス
- 専門家
- 専門にする
- 専門
- 特定の
- start
- 開始
- 米国
- 店舗
- 構造
- そのような
- サポート
- サポート
- 支援する
- サポート
- 取る
- タスク
- チーム
- テク
- 技術的
- 技術
- テクニック
- テクノロジー
- テクノロジー
- 言う
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- テキスト分類
- テキスト生成
- それ
- ソース
- アプリ環境に合わせて
- それら
- テーマ
- その後
- そこ。
- ボーマン
- 物事
- この
- それらの
- しかし?
- 介して
- 時間
- タイタン
- 〜へ
- トークン
- 伝統的な
- トレーニング
- 訓練された
- トランスフォーマー
- 変換
- わかる
- 理解する
- 統一
- ユナイテッド
- 米国
- 使用法
- つかいます
- 使用事例
- 中古
- 便利
- ユーザー
- ユーザーインターフェース
- users
- 公益事業
- 休暇
- 値
- さまざまな
- 車
- 非常に
- 、
- ビジョン
- 欲しいです
- ました
- 見ている
- we
- ウェブ
- ウェブアプリケーション
- Webサービス
- ウェビナー
- WELL
- した
- ウェスト
- いつ
- which
- while
- ワイド
- 広い範囲
- 意志
- 以内
- 無し
- レディース
- Word
- 言葉
- 仕事
- ワーキング
- 作品
- ワークショップ
- でしょう
- 書きます
- 書き込み
- 年
- 貴社
- あなたの
- ユーチューブ
- ゼファーネット