データは、すべてのオンラインビジネスのライフラインであり、私たちがやり取りする方法です。
毎日、大まかに作成します 2.5キロバイト データの。 それは沢山。 しかし、驚くべきことはそれです そのデータの90% 構造化されていません。
特別な構造はありません。 したがって、データを理解するためには、非構造化データの処理方法を本当に理解する必要があります。
さらに面倒なことをせずに、非構造化データを深く掘り下げてみましょう。
非構造化データとは何ですか?
このデジタル世界のすべてはデータで構成されています。 データはXNUMXつの形式にすることができ、適切な構造に従うことも、従わないこともできます。
他の人が読みやすいように、シーケンスやスキーム、または特定の構造に配置されていない情報は、非構造化データと呼ばれます。
非構造化データには、簡単に認識できる構造や形式がありません。 非構造化データは、データや事実自由回答調査の回答のように高度にテキストベースですが、画像、音声、ビデオなどの非テキストの場合もあります。
続きを読む: PDFからデータを抽出するにはどうすればよいですか?
非構造化データの例は何ですか?
データについて考えるときは、繰り返しまたは認識可能なパターンがなく、非構造化データとなるあらゆる種類のデータを考えてください。 テキスト、非テキスト、人間、または機械で生成されたものにすることができます。 非構造化データの例を次に示します。
テキストデータ
電子メールまたは書面で入手できるデータは、テキストデータと呼ばれます。 非構造化データの例としては、テキストメッセージ、文書、単語、PDF、その他のファイルがあります。
マルチメディアメッセージ
非構造化データの XNUMX つのタイプはマルチメディア メッセージです。 マルチメディア データは、画像 (JPEG、PNG、GIF)、オーディオ、またはビデオ形式で構成されます。 マルチメディア メッセージは、同様のパターンを持たない複雑なコードが混在しています。
すべての画像、ビデオ、またはオーディオ ファイルは、パターンに従わない暗号化されたバイナリ コードである可能性があるため、非構造化データとなります。 ここには何が見えますか?

さて、実は赤い車のイメージです。

画像や写真を理解するには観察が必要であり、それらのデータは完全に構成されていないため、これは非構造化データと呼ばれます。
ウェブサイトのコンテンツ
すべてのWebサイトには、長い段落、散在し、まとまりのない形式で入手できる情報が満載です。 これは貴重な情報を含む一種のデータですが、それでも、データの適切な構成が必要であるため、価値がありません。
センサーデータ - IoT デバイス
モノのインターネットは、周囲の情報を収集し、そのデータをクラウドに送り返す物理デバイスです。 IoT デバイスは、構造化されていない可能性のある機密センサー データを送り返します。 センサー データを送信する IoT デバイスの例としては、交通監視デバイス、Alexa、Google Home などの音楽デバイスなどが挙げられます。
メール
電子メールは、通信するための主要なチャネルのXNUMXつとして企業によって広く使用されています。 電子メールは、半構造化または非構造化に分類できます。 詳細を理解するために電子メール情報をスクレイプする利用可能な多くの解析ツールがあります。
ビジネス文書
企業は、PDF、電子メール、請求書、注文など、さまざまな種類のドキュメントを扱います。 すべてのドキュメントは異なる構造を持っています。 そうするには PDFからデータを抽出する、およびその他の紙ベースのドキュメント、企業は使用できます インテリジェントドキュメント処理ソフトウェア ナノネットのように。
10,000 人以上のユーザーが Nanonets を使用して、98% 以上の精度で非構造化データを構造化データに変換しています。 試してみる?
構造化データと非構造化データの違いは何ですか?
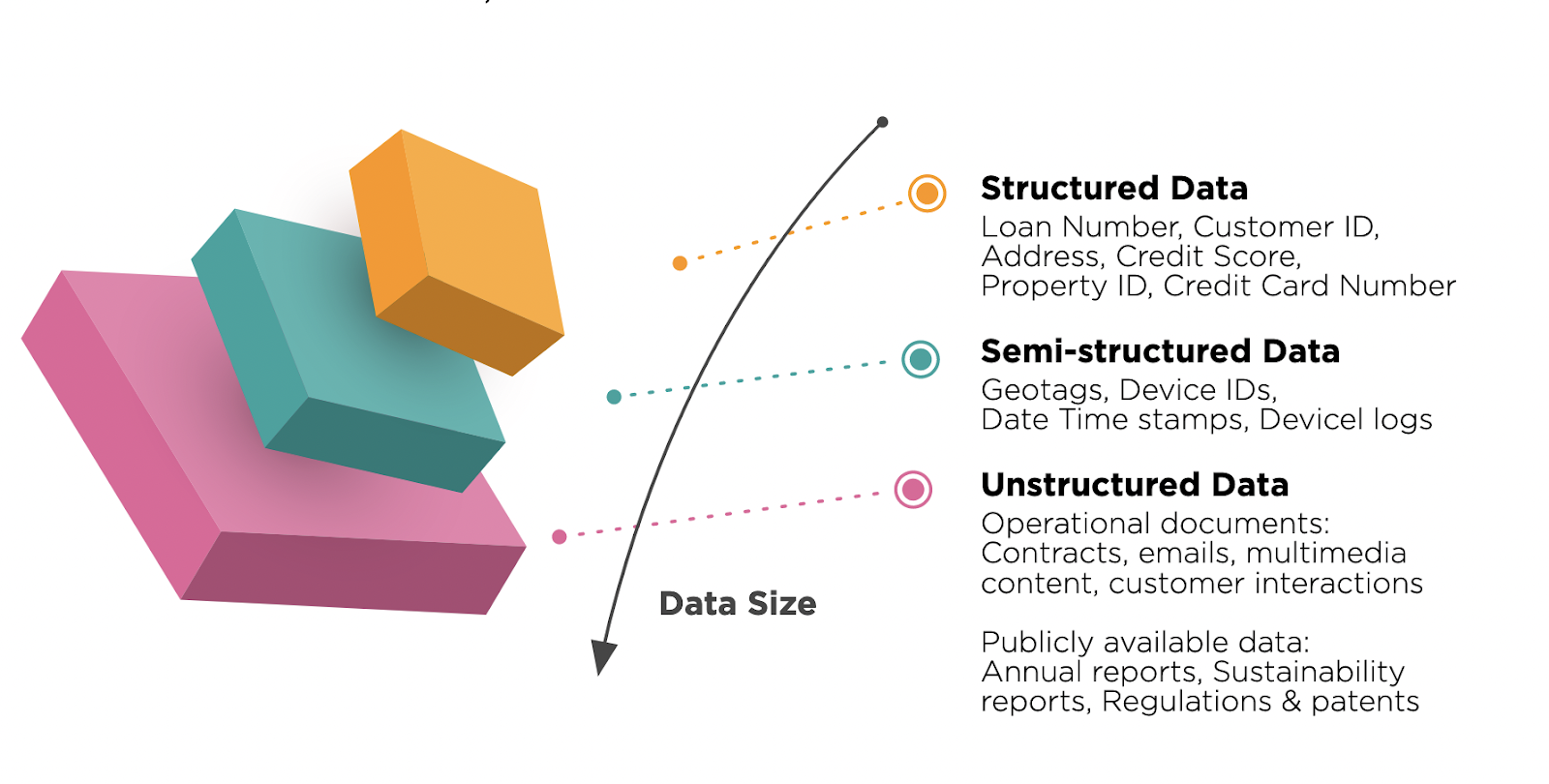
ビッグデータは、構造化データ、半構造化データ、および非構造化データで構成されます。 これらすべてのタイプのデータには、提供できるものがたくさんあります。 それらの違いを詳しく見ていきましょう。
構造化データは、特定のパターンに従い、認識しやすい別の種類のデータです。 この形式のデータはRDBMSで利用可能であり、多くのアプリケーションがあります。 構造化データと非構造化データの両方の説明の簡単な表があります。
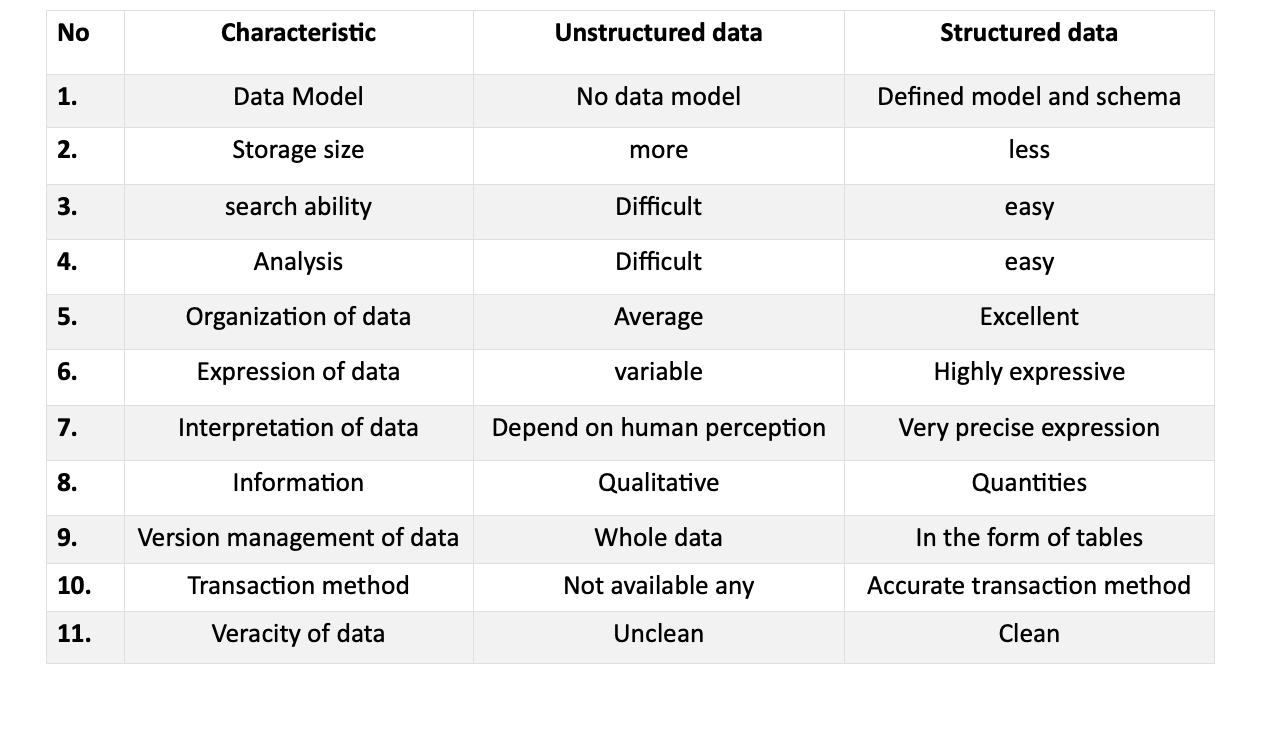
データ・モデル
- 非構造化データは多くの場合、大きな PDF、テキスト、またはマルチメディア ファイルの形式で提供されますが、構造化データは正確で組織化されています。
- 構造化データの定義されたモデルにより、研究とアクセスが簡単かつ信頼性が高くなります。
- 大きなファイルには大量のストレージ容量が必要となるため、ファイル サイズが調整可能であり、多くの場合は表形式であるため、構造化データがより望ましいものになります。
データ解析
- 分析により、データの関連性と正確性が判断されます。
- 整理され調整された構造化データとは異なり、非構造化データには信頼性の低い知識や曖昧な知識が含まれる可能性があります。
- 構造化データは、非構造化データと比較して分析が容易であるため、好まれます。
検索性
- 非構造化データの抽出は混乱する可能性があり、主要なポイントの検索に時間がかかります。
- 構造化データは、その構造により簡単に検索できます。
- 非構造化データは、そのサイズと形式により、理解や検索が難しい場合があります。
先見の明のある分析
- 非構造化データを集中的に分析すると、貴重な洞察が得られます。
- 短い最新の形式のデータは、長い段落よりも興味を引きます。
- 構造化データにより、情報の迅速な認証が可能になり、ユーザーの時間を節約できます。
非構造化データを扱う際の課題は何ですか?
非構造化データは非常に長い形式で提供されるため、非構造化データの抽出が必要になります。 非構造化データを扱う際に、作業スタッフは多くの課題に直面します。 まず、このタイプのデータは他の形式のバルクテキストで利用できるため、このデータを処理するには時間がかかりすぎます。 第XNUMXに、データが大きなファイルで利用できる場合、おそらく非構造化データが示すように、ストレージを大量に消費します。 構造化データの品質は、非常に正確で表形式で表示されるため、データの抽出が非常に簡単です。
妥協した関連性
非構造化データには、価値がなく、非常に不正確で無関係な多くの情報が含まれていることがわかります。 データの正確性は可能な限り最善の方法で維持する必要があります。そのため、非構造化データ抽出が直面する最大の課題は、関連性のある正確なデータの品質を維持することです。
Storage
20世紀の世界のデジタル化の時代以来、データの成功は、より少ないストレージとより多くの情報を占有することによってもたらされます。 以前は、データは多くの大きなファイルに保存されていましたが、非構造化データはストレージを大量に消費しているため、これらすべての変更に対処することが課題になっています。
非構造化データの処理には時間がかかります。 データの緊急性に関しては、非構造化データから情報を抽出するのに時間がかかりすぎました。 そのため、データに時間がかかりすぎ、緊急にデータからすべての知識を抽出することは非常に困難です。
デジタル化が始まって以来、非構造化データ抽出の課題に対処するために多くのツールが登場しました。 時間を節約するために、AI で強化された非構造化データ抽出 データ抽出ツール Nanonets のようなサービスは、データに完全かつ完全に関連する情報を提供するため、非常に信頼できます。 データは作業スタッフやアナリストにとって重要な時間節約ツールであるため、データの関連性は非常に重要です。 これらのデータ戦略を使用すると、データから貴重な情報を簡単に解釈できます。
Nanonets を使用して非構造化データを洞察に変換するにはどうすればよいでしょうか?
Nanonets は、AI、ML、NLP 技術を採用し、ユーザーが非構造化データから洞察を得るのを支援するプラットフォームです。これを達成する方法に関する簡単なステップバイステップのガイドは次のとおりです。
- データ収集: 非構造化データを収集します。 これは、画像、テキスト ファイル、PDF、ビデオ、またはオーディオ ファイルの形式である可能性があります。
- ナノネットにアップロードする: アカウントを使用して、非構造化データを Nanonets プラットフォームにアップロードします。 あなたはできる ここであなたのものを作成してください。 これは、直接行うことも、アプリに存在する API を介して行うこともできます。
- モデルの選択またはトレーニング: 次に、アップロードするドキュメントに基づいて、OCR モデルを選択します。 Nanonets は、さまざまな種類のドキュメントに対して事前トレーニングされたモデルを提供します。 。データの種類と目的に合ったモデルを選択してください。事前トレーニングされたモデルがニーズに合わない場合は、データを使用してカスタム OCR モデルをトレーニングできます。
- モデルをデータに適用する: モデルの準備ができたら、それをドキュメントに適用します。 モデルはドキュメントからデータを抽出し、テーブル、Excel、CSV などの読みやすい構造化形式に変換します。
- レビューと調整: モデルの解析結果を確認します。精度が十分でない場合は、結果がニーズを満たすまで、Nanonets のドラッグ アンド ドロップ プラットフォームを使用してモデルを微調整できます。
- 洞察を抽出する: 最後に、構造化データを使用して洞察を導き出します。 データをエクスポートし、データ分析を実行して洞察を得ることができます。
具体的な手順は、特定のタイプの非構造化データと、導き出したい洞察に応じて異なる場合があることに注意してください。 Nanonets は、自動化されたワークフロー、強力な OCR ソフトウェア、コード不要のユーザー インターフェイスを使用してプロセスを自動化できます。
私たちはデジタル化によりビジネスの成長と意思決定が簡素化される変革の時代に生きています。非構造化データの抽出は、時間を節約し、高速に実行できるため、さまざまなプロセスを合理化します。
非構造化データ(本質的には生の素材)は、簡単に保存できるように貴重な情報を抽出するために処理されます。 表形式なのでアクセシビリティが向上します。 データ クエリは、曖昧さのない、ユーザー フレンドリーで適切に構造化された形式に編成されているため、読みやすくなっています。 さまざまなデータ抽出ツールが用意されており、それぞれがシステムの効率化や環境改善に貢献します。
非構造化データの抽出は、データの信頼性を維持するために、業界全体で非常に重要です。 たとえば、銀行部門はビジネスの成長のためにこれらのツールを活用しています。
科学研究では、非構造化データ抽出ツールは、人間が生成したものであるか機械が生成したものであるかに関係なく、データをより正確な形式に凝縮し、貴重な洞察を提供します。
さまざまな業界の企業が、ビジネス文書を理解し、分析に追加のインテリジェンス層を追加するために、非構造化データ抽出技術を使用しています。 以下の図は、さまざまな業界での非構造化データの使用の出現を示しています。
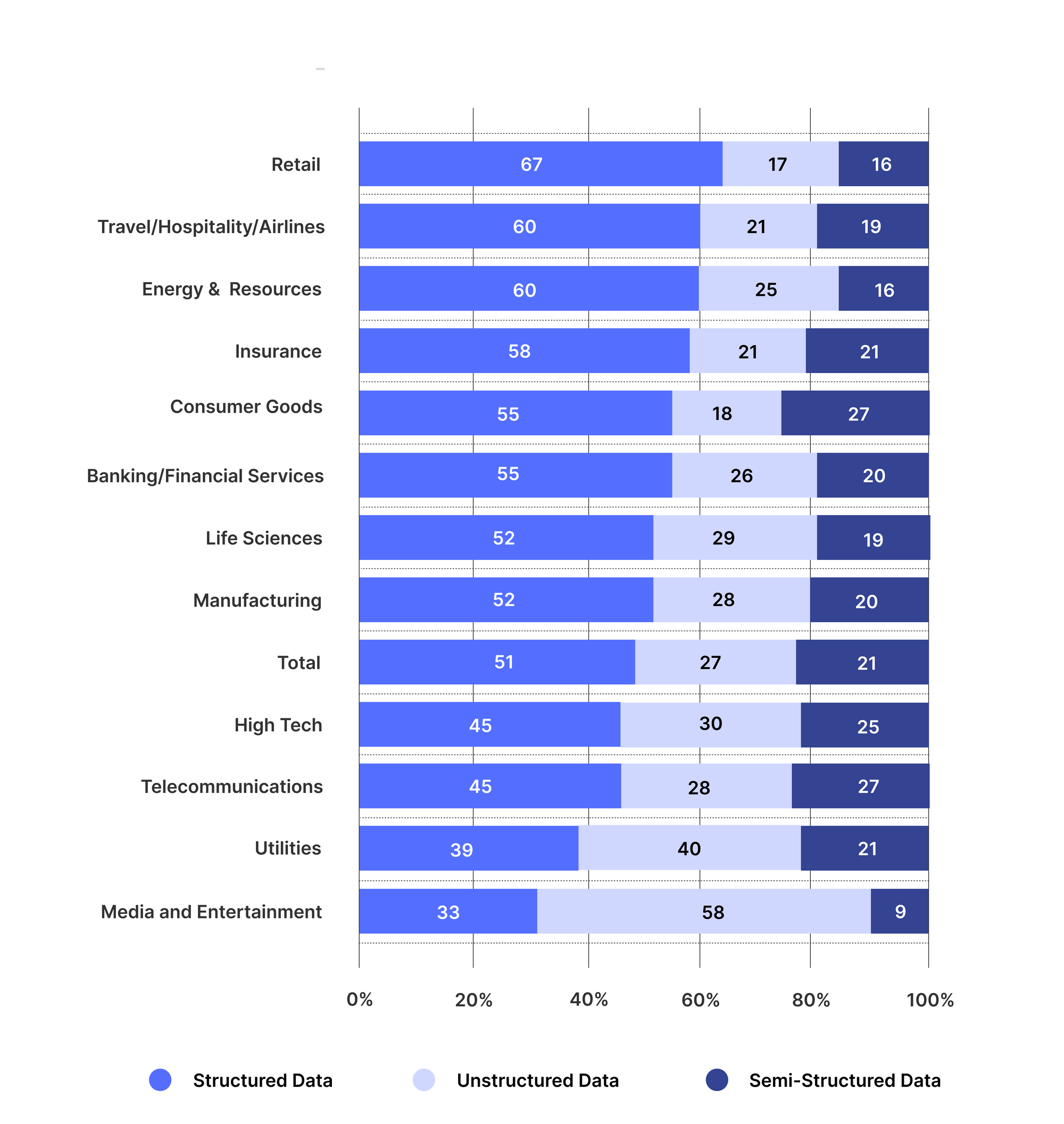
[ソース: TCS研究]
これは、さまざまな業界が非構造化データの抽出と生産性の向上のためにNanonetsなどのインテリジェントなドキュメント処理プラットフォームをどのように使用しているかの例です。
銀行
銀行は使用します IDPプラットフォーム クレーム、顧客フォーム、KYCドキュメント、通話記録、財務報告などの非構造化データソースから洞察を抽出します。
続きを読む: 銀行のRPA & バンキングオートメーション
保険
保険は厳しく規制されている業界です。 保険金請求手続きのあらゆる段階で書類確認と本人確認を行う必要があります。 保険会社は、自動化された文書処理プラットフォームを使用して、ルールベースの請求プロセス、リスク管理、その他の機能を自動化します。 保険請求プロセスには、大量の非構造化データが含まれています。 非構造化データの抽出 Nanonets のような AI 強化プラットフォームを使用すると、画像、PDF、ビデオ、オーディオなどから選択的にデータを抽出できるため、保険請求プロセスが簡単になります。
続きを読む: 保険の自動化, 保険OCR, 保険におけるRPA
健康
卓越した患者体験を提供することは、より良いサービスを提供し、患者の待ち時間を短縮し、スタッフが過労にならないようにすることを中心に展開されます。 使用する IDPプラットフォーム 顧客データの声、患者調査、EHR、顧客の苦情、規制Webサイト、文献レビューなどの非構造化データソースから洞察を抽出することは、ヘルスケアがより良い患者体験を保証するのに役立ちます。
不動産
不動産会社は、顧客、建築業者、テナント、ベンダー、競合他社、不動産所有者など、同時に複数の人と取引します。 自動ドキュメント処理ソフトウェアを使用すると、不動産会社が言及された利害関係者の豊富なプロファイルを作成し、賃貸借、契約、不動産評価書などの非構造化データソースからのデータ抽出を合理化するのに役立ちます。
まとめ
データは新しいオイルです。 非構造化データの抽出をマスターするビジネスは、エンタープライズデータの可能性を最大限に引き出すことができます。 ナノネットを使用すると、企業はドキュメント処理を自動化でき、あらゆる種類のドキュメントからデータをスマートに抽出できます。
ナノネット オンラインOCR&OCR API 多くの興味深いものがあります ユースケース t帽子はあなたの業績を最適化し、コストを節約し、成長を後押しすることができます。 詳細 Nanonetsのユースケースを製品にどのように適用できるか。
よくある質問
非構造化データを使用する利点は何ですか?
非構造化データは理解、解釈、直接使用することが困難ですが、それだけではありません。 以下に示すように、非構造化データを使用することには多くの利点があります。
固定フォーマットなし
非構造化データは、すべての形式とサイズのデータをサポートします。 適切なシーケンスを持たないあらゆる種類のデータは、非構造化データとして分類できます。 データの種類の範囲を広げると便利な場合があります。
スキーマなし
上で説明したように、非構造化データには固定シーケンスがなく、固定スキーマもありません。 これが、ほとんどの部品で非構造化データの抽出を困難にしている理由です。
柔軟性
非構造化データには構造がないため、任意の形式にすることができます。 これにより、構造的に流動的になります。
ポータブルでスケーラブル
非構造化データは、半構造化データや構造化データと比較して、移植性と拡張性が高くなっています。
多くのビジネスアプリケーション
企業の80%、企業データが構造化されていないことを考えると、このデータには多くのアプリケーションがあります。 非構造化エンタープライズデータは、さまざまなビジネス分析のユースケースに使用されます。 たとえば、プレゼンテーション、会社のビデオ、顧客プロファイルの理解などです。
非構造化データを構造化データに変換するにはどうすればよいですか?
大きくてかさばるデータを処理するときは、多忙な作業になる可能性があります。 時間を節約し、データの独創性と正確性を維持するために、必要な情報だけが残る程度にデータを短縮する必要があります。 非構造化データの抽出にはさまざまな方法があり、その重要性は上記のすべての情報によって非常に示されています。 構造化データと非構造化データの違いは、データに関する重要な手がかりを与えます。 次の手順を使用して、非構造化データを構造化データに変換できます。
ステップ1:明確な目標を念頭に置く
一連の測定可能な目標がなければ、プロジェクトを開始することはできません。 取得したい洞察の最終目標を明確に把握することで、次のステップを完了するのが容易になります。
ステップ2:データソースを完成させる
データはいたるところにあります。 ただし、変換を開始するには、非構造化データを描画するためのデータソースを特定する必要があります。 データ抽出戦略は、データソースごとに異なります。 ナノネットを使用すると、ユーザーはGmail、ドロップボックス、Outlook、デスクトップなどの複数のソースからデータを収集できます。
データは、大きなpdfファイル、画像、およびその他のテキスト形式から抽出できます。
ステップ3:データの標準化
XNUMX番目のステップは、非構造化データ抽出をどうするかを知ることです。 アナリストは、非構造化データの最終結果について考えている必要があります。
データを選択した場合、次のステップはデータの結果を確定することです。 データが可変形式の場合、分析を実行する前に、アナリストはデータを標準化する必要があります。 この特定のステップには、次のステップのためにデータ形式をクリーンアップして標準化することが含まれます。
ステップ 4: データ抽出テクノロジーの選択:
データソースとデータの標準化方法を理解した後、これらの手順を実装するために使用するソフトウェアを完成させることが重要です。 NanonetsのようなIDPプラットフォームは、組織が接続し、データを抽出し、さらに分析するためにデータを標準化するのに役立ちます。
データはさまざまなソフトウェアによって取得されます。次のステップは、データがソフトウェアに転送されるテクノロジーを見つけることです。 この目的のために、合理的なデータベース管理システム(RDBMS)が使用されます。 このソフトウェアとテクノロジーは、テクノロジーを簡単に使用するのに役立ちます。
ステップ5:データストレージシステムを選択する
データ ストレージ システムは、探しているテクノロジの種類に基づいて選択され、高可用性、高速性、その他の機能を備えている必要があります。 これらすべての機能とリアルタイム ストレージ容量により、高ストレージ システムが実現されます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://nanonets.com/blog/unstructured-data-extraction/
- :持っている
- :は
- :not
- :どこ
- 1
- 12
- 24
- 50
- 7
- a
- 私たちについて
- それについて
- 上記の.
- アクセス
- 接近性
- 精度
- 正確な
- 達成する
- 越えて
- 実際に
- 加えます
- 調節可能
- 調整
- 利点
- 出現
- AI
- アレクサ
- すべて
- 許す
- ことができます
- 沿って
- また
- 全部
- 曖昧さ
- 間で
- an
- 分析
- アナリスト
- アナリスト
- 分析論
- &
- 別の
- どれか
- API
- アプリ
- 申し込む
- です
- 周りに
- 整えられた
- AS
- At
- 魅力
- オーディオ
- 認証
- 信頼性
- 自動化する
- 自動化
- 賃貸条件の詳細・契約費用のお見積り等について
- 利用できます
- バック
- バンキング
- 銀行部門
- 銀行
- ベース
- BE
- なぜなら
- になる
- になる
- さ
- 以下
- BEST
- より良いです
- の間に
- ビッグ
- 最大の
- ブースト
- 両言語で
- ボックス
- ビルダー
- ビジネス
- 業績
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- コール
- 呼ばれます
- 缶
- 容量
- 自動車
- 例
- 世紀
- 挑戦する
- 課題
- 変更
- チャンネル
- チェック
- 選択する
- クレーム
- 分類された
- クリーニング
- クリア
- 閉じる
- クラウド
- コード
- 収集する
- 集める
- COM
- 来ます
- 来ます
- 伝える
- 企業
- 会社
- 比べ
- 競合他社
- 不満
- 完全に
- 複雑な
- 構成
- 含む
- 結論
- お問合せ
- 含まれています
- 契約
- 変換
- 変換
- コスト
- 可能性
- 作ります
- 重大な
- カスタム
- 顧客
- 顧客データ
- Customers
- データ
- データ分析
- データストレージ
- データベース
- 中
- 取引
- 意思決定
- 深いです
- ディープダイブ
- 定義済みの
- デスクトップ
- 詳細
- 細部
- 決定する
- デバイス
- Devices
- 違い
- の違い
- 異なります
- 難しい
- デジタル
- デジタルワールド
- デジタル化
- 直接に
- 議論する
- do
- ドキュメント
- ドキュメント
- ありません
- 行われ
- ドロー
- Drop
- 原因
- 各
- 緩和する
- 容易
- 簡単に
- 簡単に
- 効率
- どちら
- メール
- 従業員
- では使用できません
- end
- 強化
- 強化
- 十分な
- 確保
- 確保する
- Enterprise
- 企業
- 環境の
- 時代
- 本質的に
- 不動産
- 等
- エーテル(ETH)
- EVER
- あらゆる
- 例
- 例
- Excel
- 例外的
- 詳細
- 体験
- export
- 余分な
- エキス
- 抽出
- 直面して
- 事実
- スピーディー
- 特徴
- フィギュア
- File
- 埋め
- ファイナル
- 確定する
- 最後に
- ファイナンシャル
- もう完成させ、ワークスペースに掲示しましたか?
- 企業
- 名
- 固定の
- 流体
- 焦点を当て
- フォロー中
- 次
- フォーブス
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- フォーム
- から
- フル
- 機能
- さらに
- 集める
- 生成する
- 取得する
- GIF
- 与える
- Gmailの
- 目標
- 目標
- でログイン
- Googleホーム
- 成長性
- ガイド
- ハード
- 持ってる
- 持って
- 健康
- ヘルスケア
- 重く
- 助けます
- ことができます
- こちら
- ハイ
- 非常に
- ホーム
- 地平線
- 認定条件
- How To
- HTTP
- HTTPS
- 人間
- アイデア
- 識別する
- アイデンティティ
- 身元確認
- if
- 画像
- 画像
- 実装
- 重要
- 改善
- in
- 不正確
- 産業
- 産業を変えます
- 情報
- 洞察
- 機関
- 保険
- インテリジェンス
- インテリジェント-
- インテリジェントなドキュメント処理
- 対話
- 関心
- 興味深い
- インタフェース
- インターネット
- モノのインターネット
- に
- IOT
- IoTデバイス
- 無関係に
- IT
- ITS
- 種類
- 知っている
- 知識
- KYC
- 大
- 層
- 左
- less
- ような
- レポート
- 生活
- 長い
- 見て
- 探して
- たくさん
- 維持する
- 主要な
- make
- 作る
- 作成
- 管理
- マネジメントシステム
- 多くの
- 材料
- 大会
- 言及した
- メッセージ
- 方法
- メソッド
- かもしれない
- ML
- モデル
- モニタリング
- 他には?
- 最も
- ずっと
- マルチメディア
- の試合に
- 音楽を聴く際のスピーカーとして
- 必要
- 必要
- ニーズ
- 新作
- 次の
- NLP
- いいえ
- 今
- 客観
- 入手する
- OCR
- OCRソフトウェア
- of
- 提供
- 頻繁に
- 油
- on
- かつて
- ONE
- オンライン
- オンラインビジネス
- の
- 操作
- 最適化
- or
- 注文
- 受注
- 組織
- 組織
- 整理
- 独創
- その他
- その他
- 結果
- Outlook
- 所有者
- 紙ベース
- 論文
- 特定の
- 部品
- 過去
- 患者
- パターン
- のワークプ
- 実行する
- パフォーマンス
- 物理的な
- ピクチャー
- プラットフォーム
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- 可能
- 潜在的な
- 強力な
- 正確な
- 優先
- 現在
- プレゼンテーション
- プレゼント
- 主要な
- 多分
- プロセス
- ラボレーション
- 処理
- プロダクト
- 生産性
- 対応プロファイル
- プロジェクト
- 適切な
- 財産
- 提供
- は、大阪で
- 提供
- 目的
- 品質
- クエリ
- より速い
- 五十億
- 合理的
- Raw
- RE
- 読む
- 準備
- リアル
- 不動産
- への
- 本当に
- 認識する
- 記録
- レッド
- 縮小
- レギュラー
- 規制
- レギュレータ
- 関連性
- 関連した
- 信頼性のある
- 残っている
- 家賃
- レポート
- 必要とする
- の提出が必要です
- 研究
- 回答
- 結果
- 結果
- 明らかにする
- レビュー
- 富裕層
- リスク
- リスク管理
- 大体
- s
- 同じ
- Save
- 節約
- ド電源のデ
- 散在する
- スキーム
- 科学研究
- を検索
- 二番
- セクター
- 見て
- 選択
- 選択
- 選択的
- 送信
- 送信
- 送る
- センス
- 敏感な
- シーケンス
- サービス
- セッションに
- ショート
- 短縮
- すべき
- 示す
- 作品
- 意義
- 重要
- 同様の
- 簡略化されました
- サイズ
- サイズ
- So
- ソフトウェア
- 一部
- ソース
- ソース
- 特定の
- スタッフ
- ステークホルダー
- 標準化
- start
- 手順
- ステップ
- まだ
- ストレージ利用料
- 簡単な
- 作戦
- 流線
- 合理化された
- 構造
- 構造化された
- 構造化データと非構造化データ
- 勉強
- 成功
- そのような
- スーツ
- サポート
- 驚くべき
- 周囲の
- Survey
- テーブル
- 取る
- 取り
- 取得
- 仕事
- テクニック
- テクノロジー
- 条件
- より
- それ
- 情報
- 世界
- アプリ環境に合わせて
- それら
- そこ。
- したがって、
- ボーマン
- 彼ら
- もの
- 物事
- 考える
- 三番
- この
- 全体
- 時間
- 時間がかかる
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- あまりに
- 取った
- ツール
- 豊富なツール群
- トラフィック
- トレーニング
- 転送
- 変形させる
- 試します
- 2
- type
- わかる
- 理解する
- 異なり、
- アンロック
- まで
- 最新
- アップロード
- 緊急
- つかいます
- 中古
- ユーザー
- ユーザーインターフェース
- 「DeckleBenchは非常に使いやすく最適なソリューションを簡単に見つけることができるため、稼働率が向上しコストも削減した。当社の旧システムは良かったが改善は期待していなかった。
- users
- 利用
- 貴重な
- 貴重な情報
- 評価
- 多様
- さまざまな
- ベンダー
- Verification
- 非常に
- 、
- ビデオ
- 動画
- ボイス
- wait
- 欲しいです
- ました
- 仕方..
- we
- ウェブサイト
- この試験は
- 何ですか
- いつ
- かどうか
- which
- while
- なぜ
- 広く
- 意志
- 無し
- Word
- ワークフロー
- ワーキング
- 世界
- でしょう
- 書かれた
- 貴社
- あなたの
- ゼファーネット