データの値は時間に敏感です。 リアルタイム処理により、データ主導の意思決定が正確になり、数時間または数日ではなく数秒または数分で実行可能になります。 変更データ キャプチャ (CDC) は、データベース内のデータに加えられた変更を特定してキャプチャし、それらの変更をリアルタイムでダウンストリーム システムに配信するプロセスを指します。 ソース データベースのトランザクションからすべての変更を取得し、それらをリアルタイムでターゲットに移動することで、システムの同期が維持され、リアルタイム分析のユース ケースとゼロ ダウンタイムのデータベース移行に役立ちます。 以下は、CDC のいくつかの利点です。
- ターゲット リポジトリへのデータ変更のインクリメンタル ロードまたはリアルタイム ストリーミングを有効にすることで、一括ロード更新や不便なバッチ ウィンドウの必要性がなくなります。
- 複数のシステムのデータが同期されていることを保証します。 これは、高速データ環境で時間に敏感な意思決定を行う場合に特に重要です。
カフカコネクト Apache Kafka のオープンソース コンポーネントであり、データベース、キー値ストア、検索インデックス、およびファイル システム間の単純なデータ統合のための集中型データ ハブとして機能します。 の AWSGlueスキーマレジストリ データ ストリーム スキーマを一元的に検出、制御、展開できます。 Kafka Connect と Schema Registry を統合して、コネクタからスキーマ情報を取得します。 Kafka Connect は、Kafka Connect で使用される内部データ型から Avro、Protobuf、または JSON スキーマとして表されるデータ型にデータを変換するメカニズムを提供します。 AvroConverter、ProtobufConverter、および JsonSchemaConverter は、データを Kafka に生成する Kafka コネクタ (ソース) によって生成されたスキーマを自動的に登録します。 Kafka からのデータを使用するコネクタ (シンク) は、各メッセージのデータに加えてスキーマ情報を受け取ります。 これにより、シンク コネクタはデータの構造を認識して、データ カタログ内のデータベース テーブル スキーマを維持するなどの機能を提供できます。
この投稿では、次を使用してエンドツーエンドの CDC を構築する方法を示しています。 アマゾンMSKコネクトは、Kafka Connect アプリケーションと AWS Glue Schema Registry をデプロイして実行する AWS マネージド サービスであり、データ ストリーム スキーマを一元的に検出、制御、進化させることができます。
ソリューションの概要
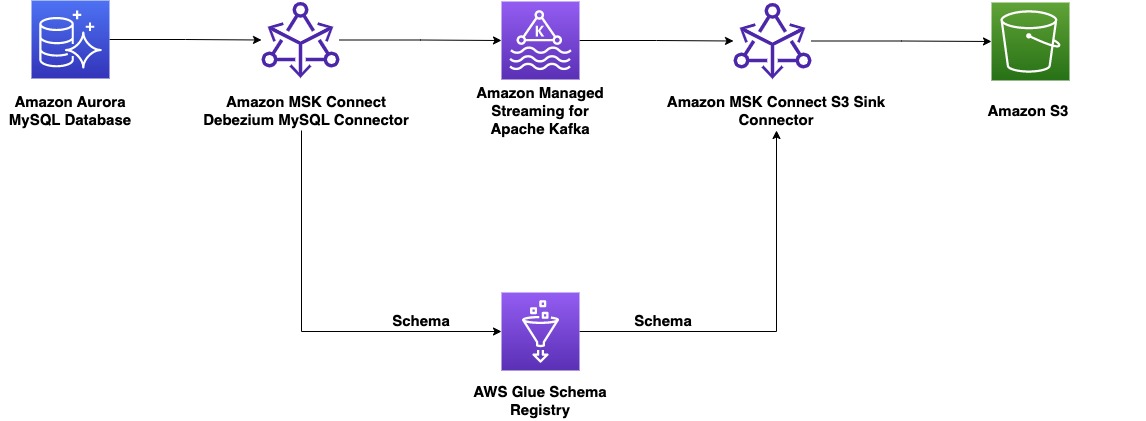
プロデューサー側では、この例では MySQL 互換の アマゾンオーロラ データベースをデータ ソースとして使用し、 デベジウム CDC を実行するための MySQL コネクタ。 Debezium コネクタはデータベースを継続的に監視し、行レベルの変更を Kafka トピックにプッシュします。 コネクターは、データベースからスキーマをフェッチして、レコードをバイナリー形式にシリアライズします。 スキーマがまだレジストリに存在しない場合は、スキーマが登録されます。 スキーマは存在するが、シリアライザーが新しいバージョンを使用している場合、スキーマ レジストリは 互換モード スキーマを更新する前のスキーマの。 このソリューションでは、 下位互換モード. 新しいバージョンのスキーマに下位互換性がない場合、スキーマ レジストリはエラーを返します。Kafka Connect を構成して、互換性のないメッセージを配信不能キューに送信できます。
消費者側では、 Amazon シンプル ストレージ サービス (Amazon S3) シンク コネクタ。レコードを逆シリアル化し、変更を Amazon S3 に保存します。 MSK Connect を使用して、Debezium コネクタと Amazon S3 シンクを構築してデプロイします。
スキーマの例
この投稿では、次のスキーマをテーブルの最初のバージョンとして使用します。
前提条件
MSK プロデューサーおよびコンシューマー コネクタを構成する前に、まずデータ ソース、MSK クラスター、および新しいスキーマ レジストリをセットアップする必要があります。 私たちは提供します AWS CloudFormation テンプレートを使用して、ソリューションに必要なサポート リソースを生成します。
- データ ソースとしての MySQL 互換の Aurora データベース。 CDC を実行するには、バイナリ ログを有効にします。 DB クラスターパラメータグループ.
- MSK クラスター。 ネットワーク接続を簡素化するために、Aurora データベースと MSK クラスターに同じ VPC を使用します。
- メッセージ キーとメッセージ値のスキーマを処理する XNUMX つのスキーマ レジストリ。
- データ シンクとして 3 つの SXNUMX バケット。
- このデモに必要な MSK Connect プラグインとワーカー構成。
- 1 アマゾン エラスティック コンピューティング クラウド データベース コマンドを実行する (Amazon EC2) インスタンス。
AWS アカウントでリソースをセットアップするには、Amazon MSK、MSK Connect、および AWS Glue Schema Registry をサポートする AWS リージョンで次の手順を完了します。
- 選択する 発射スタック:
- 選択する Next.
- スタック名、適切な名前を入力します。
- データベースのパスワードで、データベース ユーザーに必要なパスワードを入力します。
- その他の値はデフォルトのままにします。
- 選択する Next.
- 次のページで、 Next.
- 最後のページで詳細を確認し、選択します AWS CloudFormationがIAMリソースを作成する可能性があることを認めます.
- 選択する スタックを作成.
ソース コネクタと宛先コネクタのカスタム プラグイン
カスタム プラグインは、XNUMX つ以上のコネクタ、変換、またはコンバータの実装を含む一連の JAR ファイルです。 Amazon MSK は、コネクタが実行されている MSK Connect クラスターのワーカーにプラグインをインストールします。 このデモの一部として、ソース コネクタにはオープンソースを使用します Debezium MySQL コネクタ JAR、宛先コネクタには、認可された Confluent コミュニティを使用します Amazon S3 シンク コネクタ JAR. 両方のプラグインには、次のライブラリも追加されています。 Avro シリアライザーとデシリアライザー AWS Glue スキーマ レジストリの。 これらのカスタム プラグインは、前のステップでデプロイされた CloudFormation テンプレートの一部として既に作成されています。
MSK Connect の Debezium コネクタで AWS Glue Schema Registry を MSK プロデューサーとして使用する
まず、Debezium MySQL プラグインを使用してソース コネクタを展開し、 AmazonAuroraMySQL-互換性のあるエディション データベースを Amazon MSK に。 次の手順を完了します。
- Amazon MSK コンソールのナビゲーションペインで、 MSKコネクト、選択する コネクタ.
- 選択する コネクタを作成する.
- 選択する 既存のカスタム プラグインを使用 次に、名前が始まるカスタムプラグインを選択します
msk-blog-debezium-source-plugin. - 選択する Next.
- のような適切な名前を入力します
debezium-mysql-connectorおよびオプションの説明。 - Apache Kafka クラスター、選択する MSK クラスター CloudFormation テンプレートによって作成されたクラスターを選択します。
- In コネクタ構成、デフォルト値を削除し、次の構成キーと値のペアを適切な値とともに使用します。
- 名 – コネクタに使用される名前。
- データベース.ホスト名 – CloudFormation の出力 データベース エンドポイント.
- database.user および database.password – CloudFormation テンプレートで渡されるパラメーター。
- データベース.ヒストリー.kafka.ブートストラップ.サーバー – CloudFormation の出力 カフカ ブートストラップ.
- key.converter.region と value.converter.region – あなたの地域。
これらの設定の一部は一般的なものであり、すべてのコネクタに対して指定する必要があります。 例えば:
- connector.class は、コネクタの Java クラスです。
- tasks.max は、このコネクタ用に作成するタスクの最大数です
いくつかの設定 (database.*, transforms.*) は、Debezium MySQL コネクタに固有のものです。 参照する Debezium MySQL ソース コネクタの構成プロパティ 。
いくつかの設定 (key.converter.* & value.converter.*) スキーマ レジストリに固有のものです。 私たちは、 AWSKafkaAvroConverter AWS Glue スキーマ レジストリ ライブラリ フォーマットコンバーターとして。 構成するには AWSKafkaAvroConverter、文字列定数プロパティの値を使用します AWSSchemaRegistryConstants クラス:
key.converter&value.converterソース コネクタ用に Kafka に書き込まれる、またはシンク コネクタ用に Kafka から読み取られるデータの形式を制御します。 を使用しておりますAWSKafkaAvroConverterアブロフォーマット用。key.converter.registry.name&value.converter.registry.name使用するスキーマ レジストリを定義します。key.converter.compatibility&value.converter.compatibility互換性モデルを定義します。
参照する AWS Glue Schema Registry で Kafka Connect を使用する 。
- 次に、構成します コネクタ容量. 私たちは選ぶことができます Provisioned 他のプロパティをデフォルトのままにします
- ワーカー構成、名前で始まるカスタムワーカー構成を選択します
msk-gsr-blogCloudFormation テンプレートの一部として作成されます。 - アクセス許可には、Live モジュールで提供された AWS IDおよびアクセス管理 CloudFormation テンプレートによって生成された (IAM) ロール
MSKConnectRole. - 選択する Next.
- セキュリティで、デフォルトを選択します。
- 選択する Next.
- ログ配信選択 Amazon CloudWatch Logs に配信する CloudFormation テンプレートによって作成されたログ グループを参照します (
msk-connector-logs). - 選択する Next.
- 設定を確認して選択します コネクタを作成する.
数分後、コネクタは実行中の状態に変わります。
MSK コンシューマとして MSK Connect で実行されている Confluent S3 シンク コネクタで AWS Glue Schema Registry を使用する
Confluent S3 シンク プラグインを使用してシンク コネクタをデプロイし、Amazon MSK から Amazon S3 にデータをストリーミングします。 次の手順を完了します。
-
- Amazon MSK コンソールのナビゲーションペインで、 MSKコネクト、選択する コネクタ.
- 選択する コネクタを作成する.
- 選択する 既存のカスタム プラグインを使用 名前で始まるカスタムプラグインを選択します
msk-blog-S3sink-plugin. - 選択する Next.
- のような適切な名前を入力します
s3-sink-connectorおよびオプションの説明。 - Apache Kafka クラスター、選択する MSK クラスター CloudFormation テンプレートによって作成されたクラスターを選択します。
- In コネクタ構成、提供されたデフォルト値を削除し、適切な値で次の構成キーと値のペアを使用します。
-
- 名 – コネクタに使用されているものと同じ名前。
- s3.バケット.名 – CloudFormation の出力 バケット名.
- s3.region、key.converter.region、および value.converter.region – あなたの地域。
-
- 次に、構成します コネクタ容量. 私たちは選ぶことができます Provisioned 他のプロパティをデフォルトのままにします
- ワーカー構成、名前で始まるカスタムワーカー構成を選択します
msk-gsr-blogCloudFormation テンプレートの一部として作成されます。 - アクセス許可、CloudFormation テンプレートによって生成された IAM ロールを使用します
MSKConnectRole. - 選択する Next.
- セキュリティで、デフォルトを選択します。
- 選択する Next.
- ログ配信選択 Amazon CloudWatch Logs に配信する CloudFormation テンプレートによって作成されたログ グループを参照します。
msk-connector-logs. - 選択する Next.
- 設定を確認して選択します コネクタを作成する.
数分後、コネクタが実行されます。
エンド ツー エンドの CDC ログ ストリームをテストする
Debezium と S3 シンク コネクタの両方が稼働中になったので、次の手順を実行して、エンド ツー エンドの CDC をテストします。
- Amazon EC2 コンソールで、 セキュリティグループ ページで見やすくするために変数を解析したりすることができます。
- セキュリティグループを選択
ClientInstanceSecurityGroup選択して インバウンドルールを編集する. - ローカル ネットワークからの SSH 接続を許可するインバウンド ルールを追加します。
- ソフトウェア設定ページで、下図のように インスタンス ページで、インスタンスを選択します
ClientInstance選択して お問合せ. - ソフトウェア設定ページで、下図のように EC2インスタンス接続 タブを選択 お問合せ.
- 現在の作業ディレクトリが
/home/ec2-userそして、それはファイルを持っていますcreate_table.sql,alter_table.sql,initial_insert.sql,insert_data_with_new_column.sql. - 次のコマンドを実行して、MySQL データベースにテーブルを作成します (CloudFormation テンプレートの出力からデータベースのホスト名を指定します)。
- パスワードの入力を求められたら、CloudFormation テンプレート パラメーターからパスワードを入力します。
- 次のコマンドを使用して、いくつかのサンプル データをテーブルに挿入します。
- パスワードの入力を求められたら、CloudFormation テンプレート パラメーターからパスワードを入力します。
- AWS Glue コンソールで、選択します スキーマレジストリ ナビゲーションペインで、を選択します スキーマ.
- MFAデバイスに移動する
db1.sampledatabase.moviesバージョン 1 を使用して、movies テーブル用に作成された新しいスキーマを確認します。
Kafka トピックのパーティションごとに個別の S3 フォルダーが作成され、トピックのデータがそのフォルダーに書き込まれます。
- Amazon S3 コンソールで、Kafka トピックのフォルダーにある Parquet 形式で書き込まれたデータを確認します。
スキーマの進化
最初のスキーマが定義された後、アプリケーションは時間の経過とともにそれを進化させる必要がある場合があります。 これが発生した場合、下流のコンシューマーが古いスキーマと新しいスキーマの両方でエンコードされたデータをシームレスに処理できることが重要です。 互換モードを使用すると、時間の経過とともにスキーマがどのように進化できるか、またはできないかを制御できます。 これらのモードは、アプリケーションがデータを生成および消費する間の契約を形成します。 AWS Glue Schema Registry で利用可能なさまざまな互換性モードの詳細については、次を参照してください。 AWSGlueスキーマレジストリ. この例では、コンシューマーが現在と以前のスキーマ バージョンの両方を読み取れるようにするために、後方互換性を使用しています。 次の手順を完了します。
- 次のコマンドを実行して、テーブルに新しい列を追加します。
- 次のコマンドを実行して、テーブルに新しいデータを挿入します。
- AWS Glue コンソールで、選択します スキーマレジストリ ナビゲーションペインで、を選択します スキーマ.
- スキーマに移動します
db1.sampledatabase.moviesバージョン 2 を使用して、追加した国列を含む、movies テーブル movies 用に作成されたスキーマの新しいバージョンを確認します。
- Amazon S3 コンソールで、Kafka トピックのフォルダーに Parquet 形式で書き込まれたデータを確認します。
クリーンアップ
AWS アカウントへの不要な請求を防ぐために、この投稿で使用した AWS リソースを削除してください。
- Amazon S3 コンソールで、CloudFormation テンプレートによって作成された S3 バケットに移動します。
- すべてのファイルとフォルダーを選択し、 削除.
- 指示に従って完全に削除を入力し、選択します オブジェクトを削除する.
- AWS CloudFormationコンソールで、作成したスタックを削除します。
- スタックステータスがに変わるのを待ちます DELETE_COMPLETE.
まとめ
この投稿では、Amazon MSK、MSK Connect、および AWS Glue Schema Registry を使用して CDC ログ ストリームを構築し、ビジネス ニーズの変化に応じてデータ ストリームのスキーマを進化させる方法を示しました。 このアーキテクチャ パターンを、さまざまな Kafka コネクタを持つ他のデータ ソースに適用できます。 詳細については、 MSK コネクトの例.
著者について
 カリヤン・ジャナキ アマゾン ウェブ サービスのシニア ビッグデータおよび分析スペシャリストです。 彼は、顧客が AWS で高度にスケーラブルでパフォーマンスが高く、安全なクラウドベースのソリューションを設計および構築するのを支援しています。
カリヤン・ジャナキ アマゾン ウェブ サービスのシニア ビッグデータおよび分析スペシャリストです。 彼は、顧客が AWS で高度にスケーラブルでパフォーマンスが高く、安全なクラウドベースのソリューションを設計および構築するのを支援しています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :は
- $UP
- 1
- 10
- 11
- 7
- 8
- a
- できる
- 私たちについて
- アクセス
- 正確な
- 認める
- 追加されました
- 添加
- すべて
- 許可
- ことができます
- 既に
- Amazon
- Amazon EC2
- Amazon Webサービス
- 分析論
- &
- アパッチ
- アパッチカフカ
- 申し込む
- 適切な
- 建築
- です
- AS
- オーロラ
- 自動的に
- 利用できます
- AWS
- AWS CloudFormation
- AWSグルー
- BE
- 利点
- の間に
- ビッグ
- ビッグデータ
- ブートストラップ
- ビルド
- ビジネス
- by
- 缶
- 機能
- キャプチャー
- キャプチャ
- 例
- カタログ
- CDC
- 集中型の
- 変化する
- 変更
- 課金
- チェック
- 小切手
- 選択する
- class
- クラスタ
- コラム
- コミュニティ
- 互換性
- 互換性のあります
- コンプリート
- コンポーネント
- 計算
- ジャンクション
- お問合せ
- 接続
- 領事
- 定数
- 消費する
- consumer
- 消費者
- 連続的に
- 縮小することはできません。
- コントロール
- 国
- 作ります
- 作成した
- 重大な
- 電流プローブ
- カスタム
- Customers
- データ
- データ統合
- データ駆動型の
- データベース
- データベースを追加しました
- 日
- 決定
- デフォルト
- デフォルト
- 定義済みの
- 配信する
- デモ
- 実証
- 実証
- 展開します
- 展開
- 説明
- デスティネーション
- 詳細な
- 細部
- 異なります
- 発見する
- そうではありません
- Drop
- 各
- 排除
- 有効にする
- 端から端まで
- 確保
- 確実に
- 入力します
- 環境
- エラー
- 特に
- エーテル(ETH)
- あらゆる
- 進化
- 例
- 既存の
- 存在
- 少数の
- フィールズ
- File
- ファイナル
- 名
- フォロー中
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- から
- 生成する
- 生成された
- グループ
- グループの
- ハンドル
- ハンドリング
- 起こります
- 持ってる
- 助けます
- ことができます
- 非常に
- history
- host
- HOURS
- 認定条件
- How To
- HTML
- HTTP
- HTTPS
- ハブ
- IAM
- 識別
- アイデンティティ
- 実装
- 重要
- in
- 含めて
- インデックス
- 情報
- 初期
- install
- を取得する必要がある者
- 統合する
- 統合
- 内部
- IT
- Java
- JPG
- JSON
- カフカ
- キー
- 知っている
- コメントを残す
- ライブラリ
- ライセンス供与
- ような
- 負荷
- ローディング
- ローカル
- 長い
- 製
- 作る
- 作成
- マネージド
- マスター
- マックス
- メカニズム
- メッセージ
- メッセージ
- かもしれない
- 分
- モード
- モニター
- 他には?
- 動画
- 移動する
- の試合に
- MySQL
- 名
- ナビゲート
- ナビゲーション
- 必要
- 必要とされる
- ニーズ
- ネットワーク
- 新作
- 次の
- 数
- of
- 古い
- on
- ONE
- オープンソース
- その他
- 出力
- ページ
- 足
- ペイン
- パラメーター
- パラメータ
- 部
- 渡された
- パスワード
- パターン
- 実行する
- 永久に
- 選ぶ
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プラグイン
- プラグイン
- ポスト
- 防ぐ
- 前
- プロセス
- 処理
- 作り出す
- プロデューサー
- プロパティ
- 提供します
- 提供
- は、大阪で
- 読む
- リアル
- への
- 受け取ります
- 記録
- 記録
- 指し
- 地域
- 登録
- 登録された
- レジストリ
- 倉庫
- で表さ
- リソース
- 収益
- 職種
- ルール
- ラン
- ランニング
- 同じ
- ド電源のデ
- シームレス
- を検索
- 秒
- 安全に
- セキュリティ
- シニア
- 敏感な
- 別
- サービス
- サービス
- セッションに
- 設定
- すべき
- 簡単な拡張で
- 簡素化する
- 溶液
- ソリューション
- 一部
- ソース
- ソース
- 専門家
- 特定の
- 指定の
- スタック
- 起動
- Status:
- 手順
- ステップ
- ストレージ利用料
- 店舗
- 店舗
- 流れ
- ストリーミング
- ストリーム
- 構造
- 適当
- 支援する
- サポート
- 同期。
- システム
- テーブル
- ターゲット
- タスク
- template
- test
- それ
- ソース
- それら
- ボーマン
- 時間
- 時間に敏感
- 役職
- 〜へ
- トピック
- 取引
- 順番
- 下
- 不要な
- 更新
- つかいます
- ユーザー
- 値
- 価値観
- バージョン
- ウェブ
- Webサービス
- which
- 意志
- ウィンドウズ
- ワーカー
- 労働者
- ワーキング
- 作品
- 書かれた
- あなたの
- ゼファーネット