アマゾンアテナ は、データの分析を容易にするインタラクティブなクエリサービスです。 Amazon シンプル ストレージ サービス (Amazon S3) と、AWS、オンプレミス、または SQL または Python を使用する他のクラウド システムに存在するデータ ソース。 Athena は、オープンソースの Trino および Presto エンジン、および Apache Spark フレームワークに基づいて構築されており、プロビジョニングや構成の作業は必要ありません。 Athena はサーバーレスであるため、管理するインフラストラクチャはなく、実行したクエリに対してのみ料金が発生します。
アパッチ氷山 は、非常に大規模な分析データセット用のオープン テーブル形式です。 ファイルの大規模なコレクションをテーブルとして管理し、レコード レベルの挿入、更新、削除、タイム トラベル クエリなどの最新の分析データ レイク操作をサポートします。 Athena は、データに Apache Parquet 形式を使用する Apache Iceberg テーブルの読み取り、タイムトラベル、書き込み、DDL クエリをサポートしています。 AWSGlueデータカタログ メタストア用。
機能エンジニアリング 生データ (画像、テキスト ファイル、ビデオなど) を特定して変換し、欠落したデータを埋め戻し、XNUMX つ以上の意味のあるデータ要素を追加してコンテキストを提供し、機械学習 (ML) モデルがそこから学習できるようにするプロセスです。 データのラベル付けは、予測、コンピューター ビジョン、自然言語処理、音声認識などのさまざまなユースケースで必要です。
Athena の機能と組み合わせることで、Apache Iceberg は、データ サイエンティストがデータセット全体をコピーまたは再作成することなく新しいデータ特徴を作成できる簡素化されたワークフローを提供します。 他の特徴エンジニアリングサービスを使用せずに、Athena 上の標準 SQL を使用して特徴を作成できます。 データ サイエンティストは、データセットの準備とコピーに費やす時間を削減し、代わりにデータ特徴エンジニアリング、実験、大規模なデータ分析に集中できます。
この投稿では、Apache Iceberg オープン テーブル形式で Athena を使用する利点と、Athena によってデータ サイエンティストの一般的な特徴エンジニアリング タスクがどのように簡素化されるかについて説明します。 Athena が既存のテーブルを Apache Iceberg 形式に変換し、データセットを再作成またはコピーせずに列の追加、列の削除、テーブル内のデータの変更を行う方法を示します。また、これらの機能を使用して Apache Iceberg テーブルに新しい機能を作成する方法を示します。
ソリューションの概要
データ サイエンティストは一般に、大規模なデータセットを扱うことに慣れています。 データセットは通常、JSON、CSV、ORC、または アパッチパーケット フォーマット、または高速読み取りパフォーマンスを実現する同様の読み取りに最適化されたフォーマット。 データ サイエンティストは、新しいデータ特徴を作成し、そのようなデータ特徴を集約データや補助データでバックフィルすることがよくあります。 従来、このタスクは、Apache Parquet 形式の基になるデータを含むビューをテーブルの上部に作成することによって実行され、そのような列やデータは実行時に追加されるか、追加の列を持つ新しいテーブルを作成することによって実行されていました。 このワークフローは多くのユースケースに適していますが、実行時にデータを生成するか、データセットをコピーして変換する必要があるため、大規模なデータセットの場合は非効率的です。
アテナが導入しました ACID (原子性、一貫性、分離性、耐久性) トランザクション INSERT、UPDATE、DELETE、MERGE、およびタイムトラベル操作を追加する機能が構築されています。 Apache Iceberg テーブル。 これらの機能により、データ サイエンティストは、データセットのコピーや変換、ビューによる抽象化を気にせずに、新しいデータ特徴を作成したり、既存のデータ特徴を既存のデータセットにドロップしたりすることができます。 データ サイエンティストは、データセットのコピーや変換を回避して、特徴量エンジニアリングの作業に集中できます。
Athena Iceberg UPDATE オペレーションは、Apache Iceberg 位置削除ファイルと新しく更新された行を同じトランザクション内のデータ ファイルとして書き込みます。 単一の UPDATE ステートメントを使用してレコードを修正できます。
Athena エンジン バージョン 3 のリリースにより、Apache Iceberg テーブルの機能が強化され、次のような操作がサポートされます。 テーブルを選択として作成 (CTAS) Iceberg データのライフサイクル管理を合理化する MERGE コマンド。 CTAS を使用すると、Apache Paquet などの他の形式からテーブルを迅速かつ効率的に作成できます。 合併する Iceberg テーブルの行を条件付きで更新、削除、または挿入します。 単一のステートメントで、更新、削除、挿入のアクションを組み合わせることができます。
前提条件
Athena エンジン バージョン 3 を使用して Athena ワークグループをセットアップし、Apache Iceberg テーブルで CTAS および MERGE コマンドを使用します。 Athena ワークグループで既存の Athena エンジンをバージョン 3 にアップグレードするには、次の手順に従ってください。 Athena エンジン バージョン 3 にアップグレードして、クエリのパフォーマンスを向上させ、より多くの分析機能にアクセスします またはを参照してください Athena コンソールでのエンジンのバージョンの変更.
データセット
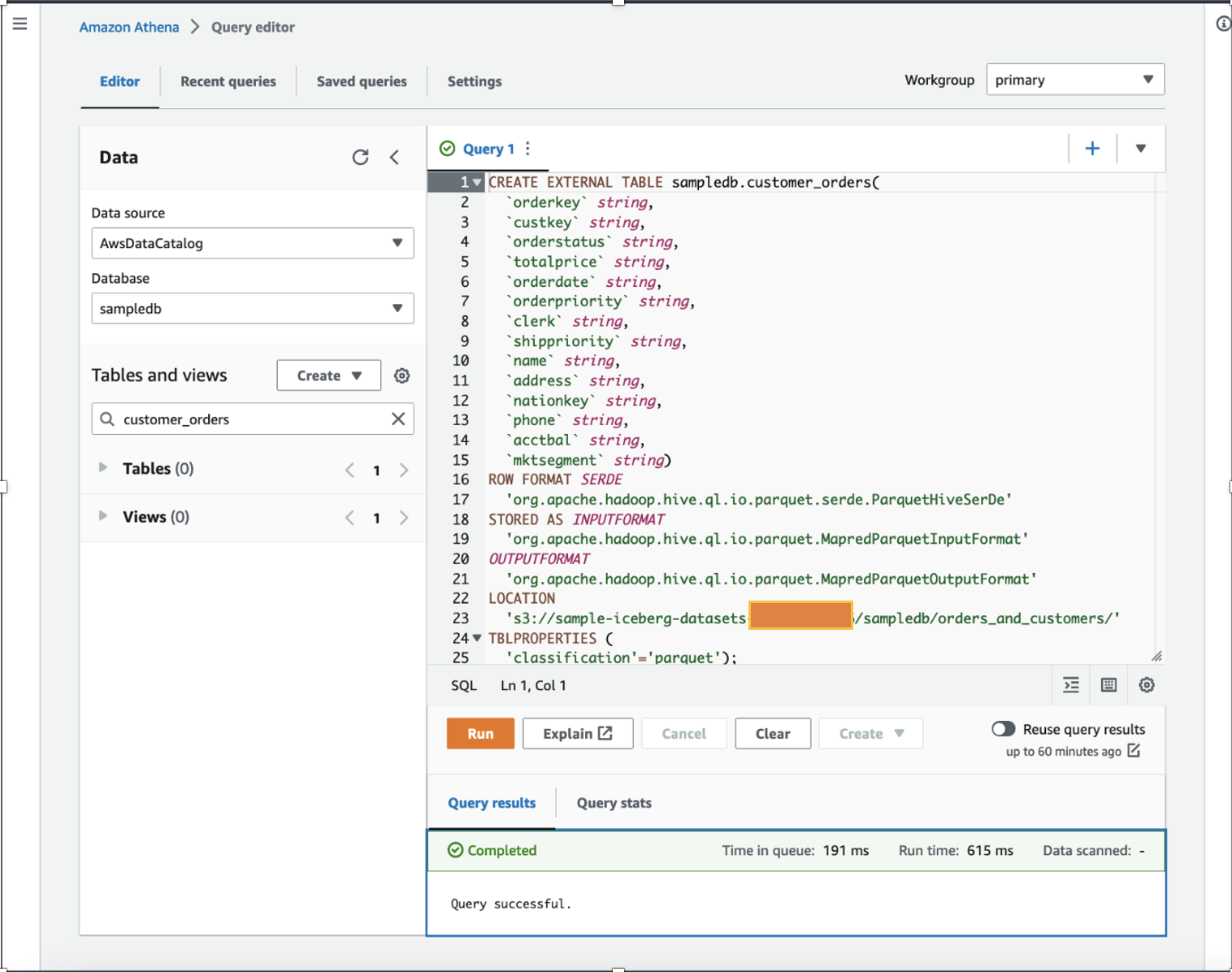
デモンストレーションのために、S3 バケットに保存された過去数年間のランダムに分散された架空の販売データの数百万レコードを含む Apache Parquet テーブルを使用します。 ダウンロード データセットをローカル コンピューターに解凍し、S3 バケットにアップロードします。 この投稿では、データセットを次の場所にアップロードしました s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
次の表は、テーブルのレイアウトを示しています。 customer_orders.
| 列名 | データ型 | Description |
| オーダーキー | 文字列 | 注文の注文番号 |
| 保管キー | 文字列 | 顧客識別番号 |
| 注文の状況 | 文字列 | 注文のステータス |
| 合計金額 | 文字列 | 注文の合計金額 |
| 注文日 | 文字列 | 注文日 |
| 注文優先 | 文字列 | 注文の優先順位 |
| 店員 | 文字列 | 注文を処理した店員の名前 |
| 配送優先度 | 文字列 | 発送優先です |
| 名 | 文字列 | 顧客名 |
| 住所 | 文字列 | お客様の住所 |
| 国家キー | 文字列 | 顧客の国キー |
| 電話 | 文字列 | お客様の電話番号 |
| アクトバル | 文字列 | お客様の口座残高 |
| mktsegment | 文字列 | 顧客市場セグメント |
特徴エンジニアリングを実行する
データサイエンティストとして、私たちは次のことを実行したいと考えています。 特徴エンジニアリング 既存のデータセット内の各顧客について計算された XNUMX 年間の合計購入額と XNUMX 年間の平均購入額を加算することにより、顧客注文データに基づいて計算します。 デモンストレーションの目的で、 customer_orders のテーブル sampledb 次の DDL コマンドに示すように、Athena を使用してデータベースを作成します。 (既存のデータセットのいずれかを使用して、この投稿で説明されている手順に従うことができます。) customer_orders データセットが生成され、S3 バケットの場所に保存されました s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ 寄木細工の形式で。 このテーブルは Apache Iceberg テーブルではありません。
![]()
クエリを実行してテーブル内のデータを検証します。
![]()
このテーブルに新しい機能を追加して、顧客の販売をより深く理解できるようにしたいと考えています。これにより、モデルのトレーニングが迅速化され、より貴重な洞察が得られるようになります。 データセットに新しい特徴を追加するには、 customer_orders Athena テーブルから Athena 上の Apache Iceberg テーブルへ。 発行A CTAS クエリ ステートメントを使用して、Apache Iceberg 形式で新しいテーブルを作成します。 customer_orders テーブル。 その際、各顧客の過去 XNUMX 年間 (データセットの最大年) の合計購入金額を取得する新しい機能が追加されます。
次の CTAS クエリでは、という名前の新しい列が追加されます。 one_year_sales_aggregate デフォルト値として 0.0 データ型の double が追加され、 table_type に設定されています ICEBERG:
![]()
次のクエリを発行して、Apache Iceberg テーブルのデータと新しい列を確認します。 one_year_sales_aggregate としての値 0.0:
![]()
新しい機能の値を入力したいと考えています one_year_sales_aggregate データセット内でデータを取得し、過去 XNUMX 年間 (データセットの最大年) の購入に基づいて各顧客の合計購入金額を取得します。 Athena を使用して Apache Iceberg テーブルに MERGE クエリ ステートメントを発行し、 one_year_sales_aggregate 機能:
![]()
次のクエリを発行して、過去 XNUMX 年間の各顧客の合計支出の更新値を検証します。
![]()
各顧客による過去 XNUMX 年間の平均購入金額を計算して保存するために、既存の Apache Iceberg テーブルに別の機能を追加することにしました。 ALTER クエリ ステートメントを発行して、機能の既存のテーブルに新しい列を追加します。 one_year_sales_average:
![]()
この新しい機能に値を設定する前に、機能のデフォルト値を設定できます。 one_year_sales_average 〜へ 0.0。 Athena で同じ Apache Iceberg テーブルを使用して、UPDATE クエリ ステートメントを発行して、新機能の値を次のように設定します。 0.0:
![]()
次のクエリを発行して、過去 XNUMX 年間の各顧客の平均支出の更新値が次のように設定されていることを確認します。 0.0:
![]()
次に、新しい機能の値を入力します。 one_year_sales_average データセット内でデータを取得し、過去 XNUMX 年間 (データセットの最大年) の購入に基づいて各顧客の平均購入金額を取得します。 Athena エンジンを使用して Athena 上の既存の Apache Iceberg テーブルに MERGE クエリ ステートメントを発行し、機能の値を設定します。 one_year_sales_average:
![]()
次のクエリを発行して、各顧客の平均支出の更新された値を確認します。
![]()
追加のデータ特徴がデータセットに追加されると、データサイエンティストは通常、Amazon Sagemaker または同等のツールセットを使用して ML モデルのトレーニングと推論を行います。
まとめ
この投稿では、Athena と Apache Iceberg を使用して特徴量エンジニアリングを実行する方法を説明しました。 また、CTAS クエリを使用して Apache Parquet 形式の既存のデータセットから Athena 上に Apache Iceberg テーブルを作成すること、ALTER クエリを使用して Athena 上の既存の Apache Iceberg テーブルに新機能を追加すること、UPDATE および MERGE クエリ ステートメントを使用して既存の列の特徴値。
CTAS クエリを使用してテーブルを迅速かつ効率的に作成し、MERGE クエリ ステートメントを使用して XNUMX ステップでテーブルを同期し、Athena と Apache Iceberg を使用して機能を変換する際のデータの準備と更新タスクを簡素化することをお勧めします。 コメントやフィードバックがある場合は、コメントセクションに残してください。
著者について
![]() ヴィヴェーク・ゴータム は、AWS プロフェッショナル サービスでデータレイクを専門とするデータ アーキテクトです。 彼は、AWS 上でデータ製品、分析プラットフォーム、ソリューションを構築する企業顧客と協力しています。 最新のデータ プラットフォームを構築および設計していないときは、Vivek はグルメ愛好家であり、新しい旅行先を探索したり、ハイキングに出かけたりすることも好きです。
ヴィヴェーク・ゴータム は、AWS プロフェッショナル サービスでデータレイクを専門とするデータ アーキテクトです。 彼は、AWS 上でデータ製品、分析プラットフォーム、ソリューションを構築する企業顧客と協力しています。 最新のデータ プラットフォームを構築および設計していないときは、Vivek はグルメ愛好家であり、新しい旅行先を探索したり、ハイキングに出かけたりすることも好きです。
![]() ミハイル・ヴェインシュタイン アマゾン ウェブ サービスのソリューション アーキテクトです。 Mikhail は、ヘルスケアおよびライフ サイエンスの顧客と協力して、患者の転帰を改善するソリューションを構築しています。 Mikhail は、データ分析サービスを専門としています。
ミハイル・ヴェインシュタイン アマゾン ウェブ サービスのソリューション アーキテクトです。 Mikhail は、ヘルスケアおよびライフ サイエンスの顧客と協力して、患者の転帰を改善するソリューションを構築しています。 Mikhail は、データ分析サービスを専門としています。
![]() ナレシュゴータム AWS のデータ分析および AI/ML のリーダーであり、20 年の経験があります。顧客が高可用性、高パフォーマンス、および費用対効果の高いデータ分析および AI/ML ソリューションを設計して、データ主導の意思決定で顧客を支援することを楽しんでいます。 . 余暇には、瞑想と料理を楽しんでいます。
ナレシュゴータム AWS のデータ分析および AI/ML のリーダーであり、20 年の経験があります。顧客が高可用性、高パフォーマンス、および費用対効果の高いデータ分析および AI/ML ソリューションを設計して、データ主導の意思決定で顧客を支援することを楽しんでいます。 . 余暇には、瞑想と料理を楽しんでいます。
![]() ハルシャ・タディパルティ は、AWS の分析担当プリンシパル ソリューション アーキテクトのスペシャリストです。 彼は、データベースと分析における複雑な顧客の問題を解決し、成功を収めることを楽しんでいます。 仕事以外では、可能な限り家族と過ごしたり、映画を見たり、旅行したりするのが大好きです。
ハルシャ・タディパルティ は、AWS の分析担当プリンシパル ソリューション アーキテクトのスペシャリストです。 彼は、データベースと分析における複雑な顧客の問題を解決し、成功を収めることを楽しんでいます。 仕事以外では、可能な限り家族と過ごしたり、映画を見たり、旅行したりするのが大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- EVMファイナンス。 分散型金融のための統一インターフェイス。 こちらからアクセスしてください。
- クォンタムメディアグループ。 IR/PR増幅。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :持っている
- :は
- :not
- :どこ
- $UP
- 10
- 100
- 12
- 17
- 20
- 20年
- 23
- 27
- 7
- a
- 私たちについて
- 加速する
- アクセス
- 熟達した
- 行動
- 加えます
- 追加されました
- 追加
- NEW
- 住所
- AI / ML
- また
- しかし
- Amazon
- アマゾンアテナ
- アマゾンセージメーカー
- Amazon Webサービス
- 量
- an
- 分析的
- 分析的
- 分析論
- 分析します
- 分析する
- および
- 別の
- どれか
- アパッチ
- Apache Spark
- です
- AS
- At
- 利用できます
- 平均
- 避ける
- AWS
- AWSプロフェッショナルサービス
- ベース
- BE
- なぜなら
- き
- 利点
- ビルド
- 建物
- 内蔵
- by
- 計算された
- 缶
- 機能
- 例
- 分類
- クラウド
- コレクション
- コラム
- コラム
- 組み合わせる
- 注釈
- コマンドと
- 複雑な
- 計算
- コンピュータ
- Computer Vision
- 含まれています
- コンテキスト
- 変換
- 料理
- 複写
- 補正
- コスト効率の良い
- 作ります
- 作成した
- 作成
- 顧客
- Customers
- データ
- データ分析
- データレイク
- データサイエンス
- データサイエンティスト
- データ駆動型の
- データベース
- データベースを追加しました
- データセット
- 日付
- 決めます
- 意思決定
- より深い
- デフォルト
- 配信する
- 提供します
- 実証します
- 実証
- 設計
- 目的地
- 配布
- すること
- Drop
- 耐久性
- 各
- 簡単に
- 効率的な
- 効率良く
- 努力
- どちら
- 要素は
- エンパワー
- enable
- 奨励する
- エンジン
- エンジニアリング
- エンジン
- 強化された
- Enterprise
- 企業顧客
- 熱狂者
- 全体
- 同等の
- エーテル(ETH)
- 既存の
- 体験
- 探る
- 外部
- false
- 家族
- スピーディー
- 速いです
- 特徴
- 特徴
- フィードバック
- フォーカス
- フォロー中
- フード
- 形式でアーカイブしたプロジェクトを保存します.
- フレームワーク
- 無料版
- から
- 一般に
- 生成された
- 取得する
- Go
- グループ
- Hadoopの
- 持ってる
- he
- ヘルスケア
- 助けます
- 助け
- ハイパフォーマンス
- 非常に
- ハイキング
- 彼の
- 歴史的に
- ハイブ
- 認定条件
- How To
- HTML
- HTTPS
- 識別
- 識別
- if
- 画像
- 改善します
- in
- 含めて
- 増える
- 非効率的な
- インフラ関連事業
- インサート
- 洞察
- を取得する必要がある者
- 説明書
- 相互作用的
- に
- 導入
- 分離
- 問題
- IT
- JPG
- JSON
- ラベリング
- 湖
- 言語
- 大
- 姓
- レイアウト
- リーダー
- LEARN
- 学習
- コメントを残す
- 生活
- 生命科学
- wifecycwe
- LIMIT
- ローカル
- 場所
- で
- 機械
- 機械学習
- make
- 作る
- 管理します
- 管理
- 管理する
- 多くの
- 市場
- マッチ
- マックス
- 意味のある
- 瞑想
- 言及した
- マージ
- 百万
- 行方不明
- ML
- モデル
- モダン
- 修正する
- 他には?
- 動画
- 名
- 名前付き
- 国
- ナチュラル
- 自然言語
- 自然言語処理
- 必要
- 必要
- 新作
- 新機能
- 新しい特徴
- 新しく
- いいえ
- 数
- of
- 頻繁に
- on
- ONE
- の
- 開いた
- オープンソース
- 操作
- 業務執行統括
- or
- 受注
- その他
- 私たちの
- 成果
- 外側
- 過去
- 支払う
- 実行する
- パフォーマンス
- 電話
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- 位置
- 可能
- ポスト
- 準備中
- ブランド
- 校長
- 問題
- プロセス
- 処理されました
- 処理
- 製品
- プロ
- 提供します
- 購入
- 購入
- 目的
- Python
- クエリ
- すぐに
- Raw
- 生データ
- 読む
- 認識
- 記録
- 記録
- 減らします
- リリース
- の提出が必要です
- 結果
- レビュー
- 行
- ラン
- ランニング
- セージメーカー
- セールス
- 同じ
- 規模
- 科学
- 科学
- 科学者
- 科学者たち
- セクション
- サーバレス
- サービス
- サービス
- セッションに
- いくつかの
- 示す
- 作品
- 同様の
- 簡単な拡張で
- 簡略化されました
- 簡素化する
- So
- ソリューション
- 解決
- ソース
- スパーク
- 専門家
- 専門にする
- スピーチ
- 音声認識
- 過ごす
- 費やした
- SQL
- 標準
- ステートメント
- 文
- 手順
- ステップ
- ストレージ利用料
- 店舗
- 保存され
- 流線
- 文字列
- 成功した
- そのような
- サポート
- サポート
- システム
- テーブル
- 仕事
- タスク
- それ
- マージ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- ボーマン
- この
- 時間
- タイムトラベル
- 〜へ
- top
- トータル
- トレーニング
- トレーニング
- トランザクション
- トランザクションの
- 変換
- 変換
- 旅行
- type
- 根本的な
- 理解する
- アップデイト
- 更新しました
- 更新版
- アップグレード
- アップロード
- つかいます
- 通常
- 検証
- 貴重な
- 値
- 価値観
- さまざまな
- 確認する
- バージョン
- 非常に
- 、
- 動画
- 詳しく見る
- ビジョン
- 欲しいです
- ました
- よく見る
- we
- ウェブ
- Webサービス
- した
- いつ
- たびに
- which
- while
- 誰
- 無し
- 仕事
- ワークフロー
- ワークグループ
- ワーキング
- 作品
- でしょう
- 書きます
- 年
- 年
- 貴社
- あなたの
- ゼファーネット
- 〒