著者による画像
データ サイエンスと機械学習の世界に飛び込むと、基本的なスキルの 1 つはデータを読み取る技術です。すでにある程度の経験がある場合は、JSON (JavaScript Object Notation) に精通しているでしょう。JSON (JavaScript Object Notation) は、データの保存と交換の両方によく使用される形式です。
MongoDB のような NoSQL データベースがデータを JSON で保存することを好む方法や、REST API が同じ形式で応答することがよくあることを考えてください。
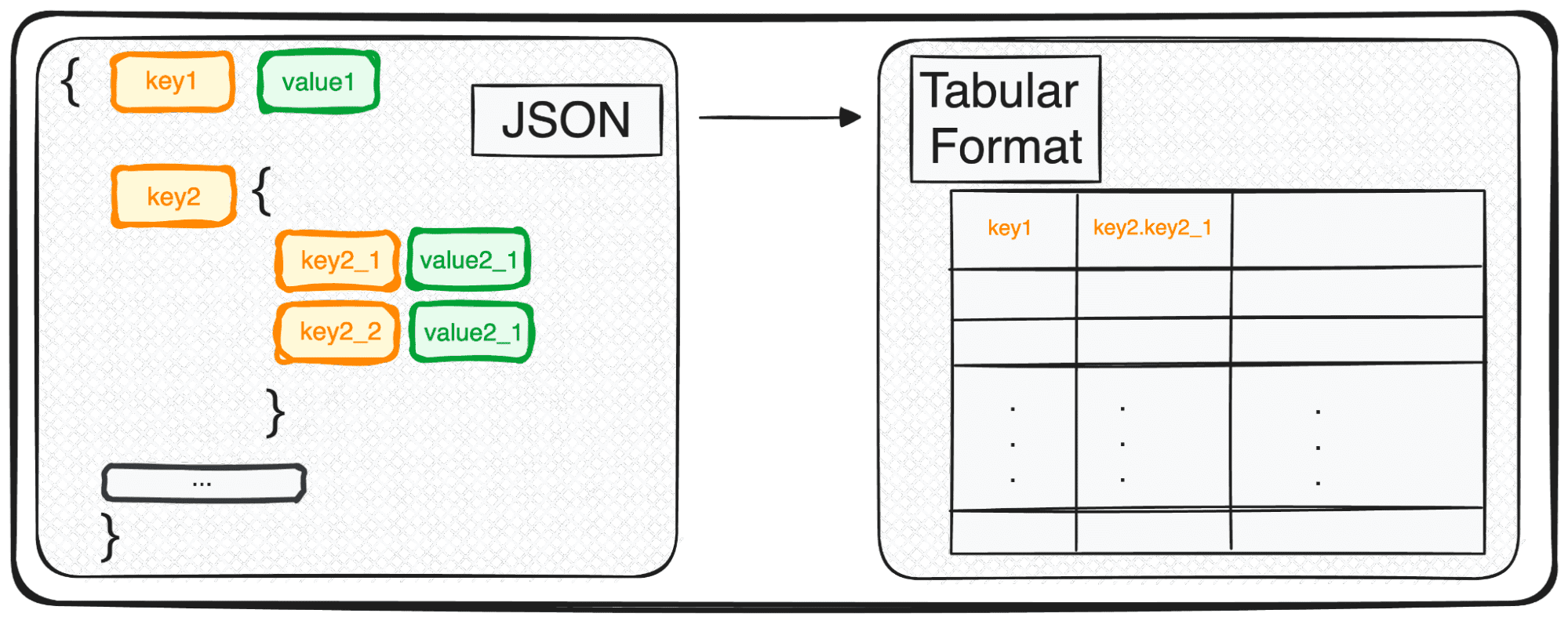
ただし、JSON は保存や交換には最適ですが、生の形式で詳細な分析を行うにはまだ準備ができていません。ここで、それをより分析しやすいもの、つまり表形式に変換します。
したがって、単一の JSON オブジェクトを扱っている場合でも、それらの楽しい配列を扱っている場合でも、Python の用語では、基本的に dict または dict のリストを扱っていることになります。
この変換がどのように展開し、データが分析に適した状態になるのかを一緒に探ってみましょう ????
今日は、JSON を数秒で表形式に簡単に解析できる魔法のコマンドについて説明します。
そしてそれは…PD.json_normalize()
それでは、さまざまな種類の JSON でどのように動作するかを見てみましょう。
操作できる最初のタイプの JSON は、いくつかのキーと値を持つ単一レベルの JSON です。最初の単純な JSON を次のように定義します。
著者によるコード
そこで、これらの JSON を操作する必要性をシミュレートしてみましょう。 JSON 形式ではできることがあまりないことは誰もが知っています。これらの JSON を読み取り可能で変更可能な形式に変換する必要があります。つまり、Pandas DataFrame です。
1.1 単純な JSON 構造の処理
まず、パンダ ライブラリをインポートする必要があります。その後、次のようにコマンド pd.json_normalize() を使用できます。
import pandas as pd
pd.json_normalize(json_string)
このコマンドを 1 つのレコードを持つ JSON に適用すると、最も基本的なテーブルが得られます。ただし、データがもう少し複雑で、JSON のリストを表す場合でも、同じコマンドをさらに複雑にすることなく使用でき、出力は複数のレコードを含むテーブルに対応します。

著者による画像
簡単…ですよね?
次に当然の疑問は、値の一部が欠落している場合に何が起こるかということです。
1.2 NULL 値の処理
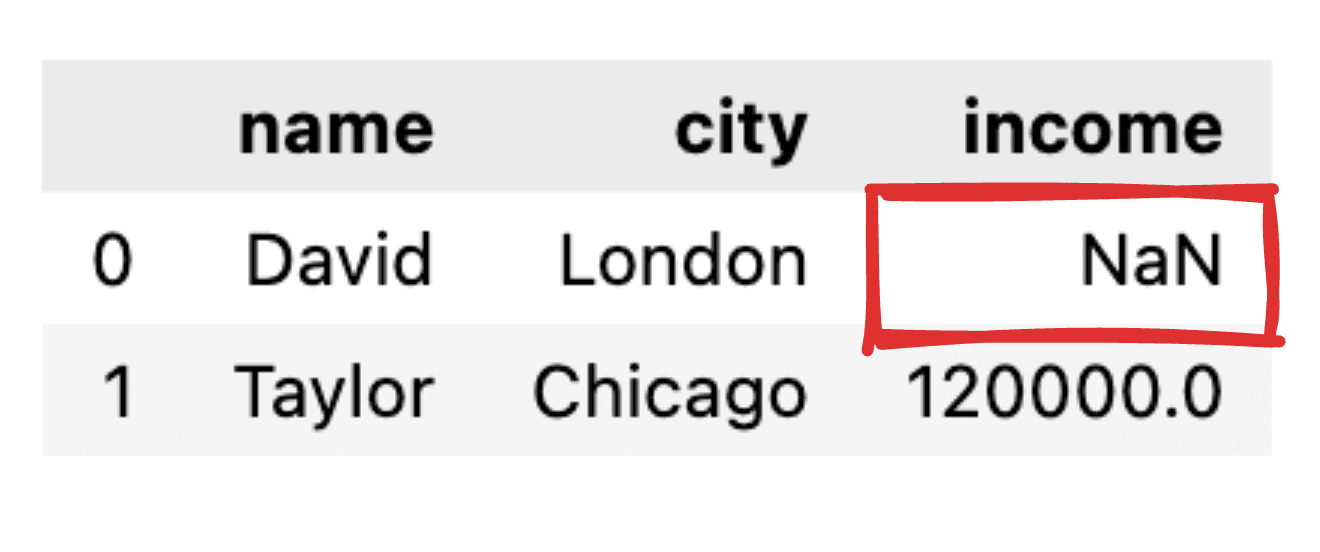
たとえば、David の収入レコードが欠落しているなど、一部の値が通知されていないと想像してください。 JSON を単純な pandas データフレームに変換すると、対応する値は NaN として表示されます。
著者による画像
一部のフィールドのみを取得したい場合はどうすればよいでしょうか?
1.3 関心のある列のみを選択する
いくつかの特定のフィールドを表形式の pandas DataFrame に変換したいだけの場合、 json_normalize() コマンドでは変換するフィールドを選択できません。
したがって、JSON の小さな前処理を実行して、対象の列のみをフィルターする必要があります。
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
それでは、より高度な JSON 構造に移りましょう。
複数レベルの JSON を扱う場合、異なるレベル内に JSON が入れ子になっていることがわかります。手順は前と同じですが、この場合、変換するレベルの数を選択できます。デフォルトでは、コマンドは常にすべてのレベルを展開し、すべてのネストされたレベルの連結名を含む新しい列を生成します。
そこで、次の JSON を正規化するとします。
著者によるコード
フィールド スキルの下に 3 つの列がある次のテーブルが得られます。
- スキル.python
- スキル.SQL
- スキル.GCP
フィールドの役割の下の 4 列
- 役割.プロジェクトマネージャー
- 役割.データエンジニア
- 役割.データサイエンティスト
- 役割.データアナリスト

著者による画像
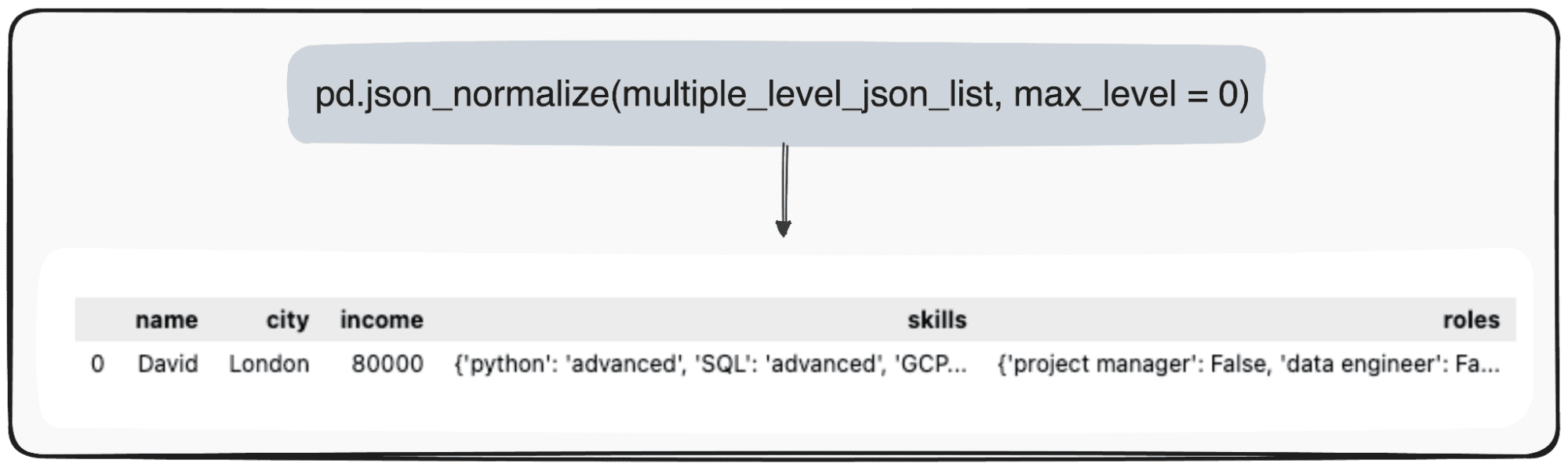
ただし、トップレベルを変更したいだけだと想像してください。これを行うには、パラメータ max_level を 0 (拡張したい max_level) に具体的に定義します。
pd.json_normalize(mutliple_level_json_list, max_level = 0)
保留中の値は、pandas DataFrame 内の JSON 内に維持されます。
著者による画像
私たちが見つけることができる最後のケースは、JSON フィールド内にネストされたリストがあることです。したがって、最初に使用する JSON を定義します。
著者によるコード
Python の Pandas を使用すると、このデータを効果的に管理できます。 pd.json_normalize() 関数は、このコンテキストで特に役立ちます。ネストされたリストを含む JSON データを、分析に適した構造化形式にフラット化できます。この関数を JSON データに適用すると、フィールドの一部としてネストされたリストを組み込んだ正規化されたテーブルが生成されます。
さらに、Pandas は、このプロセスをさらに改良する機能を提供します。 pd.json_normalize() の Record_path パラメーターを利用することで、ネストされたリストを具体的に正規化するように関数に指示できます。
このアクションにより、リストの内容専用の専用テーブルが作成されます。デフォルトでは、このプロセスはリスト内の要素のみを展開します。ただし、各レコードに関連付けられた ID を保持するなど、追加のコンテキストでこのテーブルを充実させるには、meta パラメーターを使用できます。

著者による画像
要約すると、Python の Pandas ライブラリを使用して JSON データを CSV ファイルに変換するのは簡単かつ効果的です。
JSON は依然として、最新のデータ ストレージと交換、特に NoSQL データベースと REST API で最も一般的な形式です。ただし、生の形式でデータを扱う場合、分析上でいくつかの重要な課題が生じます。
Pandas の pd.json_normalize() の重要な役割は、このような形式を処理し、データを pandas DataFrame に変換する優れた方法として浮上します。
このガイドがお役に立てば幸いです。次回 JSON を扱うときは、より効果的な方法で処理できるようになります。
対応する Jupyter Notebook を確認できます。 以下の GitHub リポジトリ。
ジョセップ・フェレール バルセロナ出身の分析エンジニアです。 彼は物理工学を卒業し、現在は人間の移動に適用されるデータ サイエンス分野で働いています。 彼は、データ サイエンスとテクノロジーに焦点を当てた非常勤のコンテンツ クリエイターです。 あなたは彼に連絡することができます LinkedIn, Twitter or M.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :は
- :not
- :どこ
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- 私たちについて
- Action
- NEW
- 高度な
- すべて
- 許す
- ことができます
- 既に
- 常に
- an
- 分析
- アナリスト
- 分析的
- 分析論
- および
- どれか
- API
- 現れる
- 適用された
- 適用
- です
- 配列
- 宝品
- AS
- 関連する
- バルセロナ
- 基本
- BE
- ビット
- 両言語で
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- 機能
- 場合
- 課題
- チェック
- 選択する
- 市町村
- コラム
- コマンドと
- 複雑な
- 合併症
- 接触
- コンテンツ
- 中身
- コンテキスト
- 変換
- 変換
- マッチ
- 対応する
- クリエイター
- 現在
- データ
- データアナリスト
- データエンジニア
- データサイエンス
- データサイエンティスト
- データストレージ
- データベースを追加しました
- デイビッド
- 取引
- 専用の
- デフォルト
- 定義します
- 定義
- 楽しい
- DICT
- 異なります
- 直接
- do
- ありません
- 各
- 簡単に
- 簡単に
- 効果的な
- 効果的に
- 要素は
- 出てくる
- 出会い
- エンジニア
- エンジニアリング
- 豊かにする
- 本質的に
- 交換
- 交換
- 排他的に
- 詳細
- 体験
- 説明
- 探る
- おなじみの
- 少数の
- フィールド
- フィールズ
- filter
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- 焦点を当て
- フォロー中
- 次
- フォーム
- 形式でアーカイブしたプロジェクトを保存します.
- 優しい
- から
- function
- 基本的な
- さらに
- GCP
- 生成する
- 取得する
- GitHubの
- Go
- 素晴らしい
- ガイド
- ハンドル
- ハンドリング
- 起こります
- 持ってる
- 持って
- he
- 彼に
- 希望
- 認定条件
- しかしながら
- HTTPS
- 人間
- i
- 私は
- ID
- if
- 絵
- import
- 重要
- in
- 綿密な
- include
- 含めて
- 所得
- 組み込む
- 情報に基づく
- 関心
- に
- ISN
- IT
- ITS
- JavaScriptを
- JSON
- ジュピターノート
- ただ
- KDナゲット
- キー
- キー
- 知っている
- 姓
- 学習
- レベル
- レベル
- 図書館
- ような
- リスト
- 少し
- ll
- 愛
- 機械
- 機械学習
- マジック
- 維持
- 作成
- 管理します
- マネージャー
- 多くの
- 手段
- Meta
- 行方不明
- モビリティ
- モダン
- MongoDBの
- 他には?
- 最も
- ずっと
- の試合に
- 名
- ナチュラル
- 必要
- 入れ子になりました
- 新作
- 次の
- いいえ
- 特に
- ノート
- オブジェクト
- 入手する
- of
- オファー
- 頻繁に
- on
- ONE
- の
- or
- 私たちの
- 自分自身
- 出力
- パンダ
- パラメーター
- 部
- 特に
- ペンディング
- 完璧
- 実行
- 物理学
- 極めて重要な
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人気
- プレゼント
- 多分
- 手続き
- プロセス
- 生産する
- プロジェクト
- Python
- 質問
- 非常に
- Raw
- RE
- リーディング
- 準備
- 記録
- 記録
- リファイン
- 反応します
- REST
- 結果
- 保持
- 右
- 職種
- s
- 同じ
- 科学
- 科学技術
- 科学者
- 秒
- 選択
- すべき
- 簡単な拡張で
- シミュレートする
- スキル
- 小さい
- So
- 一部
- 何か
- 特定の
- 特に
- SQL
- まだ
- ストレージ利用料
- 店舗
- 構造
- 構造化された
- そのような
- 適当
- 概要
- T
- テーブル
- テクノロジー
- 条件
- それ
- 世界
- アプリ環境に合わせて
- それら
- その後
- ボーマン
- この
- それらの
- 時間
- 〜へ
- 一緒に
- top
- 最適化の適用
- 変換
- 変換
- type
- 下
- us
- つかいます
- 便利
- 活用
- 値
- 価値観
- 欲しいです
- ました
- 仕方..
- we
- この試験は
- いつ
- かどうか
- which
- while
- 意志
- 以内
- 仕事
- ワーキング
- 作品
- 世界
- でしょう
- 貴社
- ゼファーネット