DALL-E で生成された画像
データ分析処理がビジネスの成功と失敗の決定的な違いとなる時代には、そのニーズをサポートできるツール スタックが必要です。テクノロジーの進歩により、私たちが必要とするこれらすべてのデータ ツール、つまり DuckDB と MotherDuck が進歩しました。
ダックDB は、オープンソースのインプロセス SQL オンライン分析処理 (OLAP) データベース管理システムです。データベース システムは、データ サイズに関係なく、データ分析クエリを迅速に処理できるように設計されています。このシステムには、データ分析プロセスを効果的に改善するインメモリ処理と OLAP システムが実装されています。
DuckDB は、データ分析 (テーブル結合、データ集計など) を伴う表形式データの保存と処理、およびワークフローに通常テーブルの大幅な変更が含まれる場合に最適です。一方、DuckDB は、大量のデータ アクティビティや 1 つのデータベース内での複数の同時プロセスには適していません。
マザーダック は、クラウド上のマネージド DuckDB サービスです。 DuckDB コミュニティによって保守されている間は、無料で使用でき、オープンソースです。これは、一般の人々が使用できるクラウド サービス プラットフォームを作成するために DuckDB Lab と提携して構築されたサービスです。
DuckDB と Motherduck を組み合わせることで、あらゆるシナリオですぐに使用できる分析エンジンを作成できます。どうやってそれを行うのでしょうか?それでは始めましょう。
ネイティブの MotherDuck UI を使用して、サービスがどのように機能するか、そして DuckDB がデータ分析のための強力なツールである理由の例を示します。 MotherDuck アカウントをまだ取得していない場合は、Web サイトに登録して取得してください。
MotherDuck アカウントの登録に成功すると、MotherDuck UI が表示されます。 UI に慣れてみると、Jupyter Notebook を使用したことがある場合は、UI がそれに似ていることがわかるでしょう。
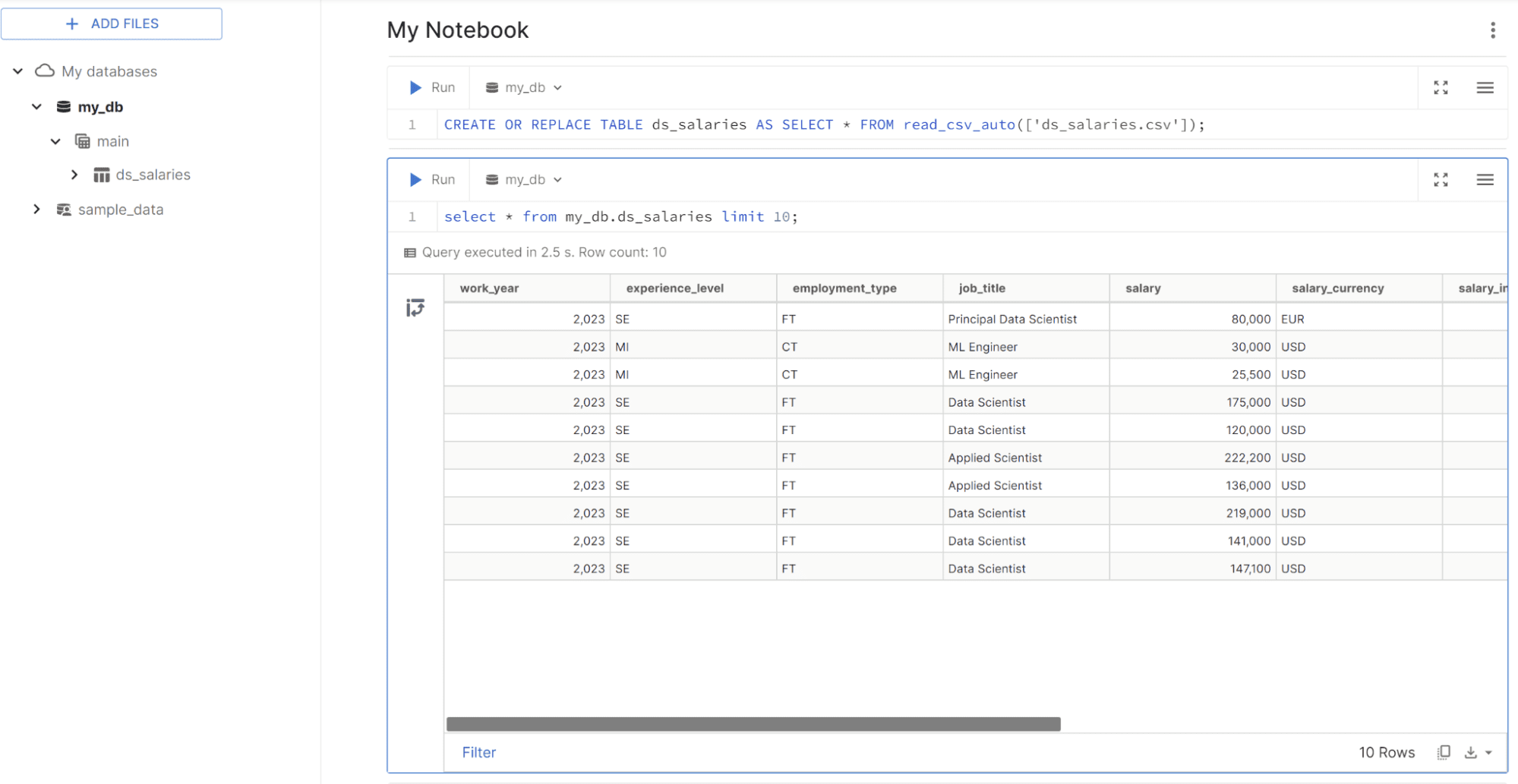
DS Salary データを使用して MotherDuck UI で DBduck の機能を実験してみます。 Kaggle。 [ファイルの追加] ボタンを使用してデータをアップロードすると、実行するクエリを含む新しいセルが表示されます。クエリは次のようになります。
CREATE OR REPLACE TABLE ds_salaries AS SELECT * FROM read_csv_auto(['ds_salaries.csv']);
テーブルを作成したら、次のコードを使用してデータをクエリしてみます。
select * from my_db.ds_salaries limit 10;
ご覧のとおり、MotherDuck は Notebook でデータ分析を行うのとほぼ同じですが、SQL クエリを使用します。 MotherDuck でデータ分析を行うためのクエリを試してみましょう。
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
セル内でクエリを実行できます。テーブルの結果は以下の画像と同様に表示されます。
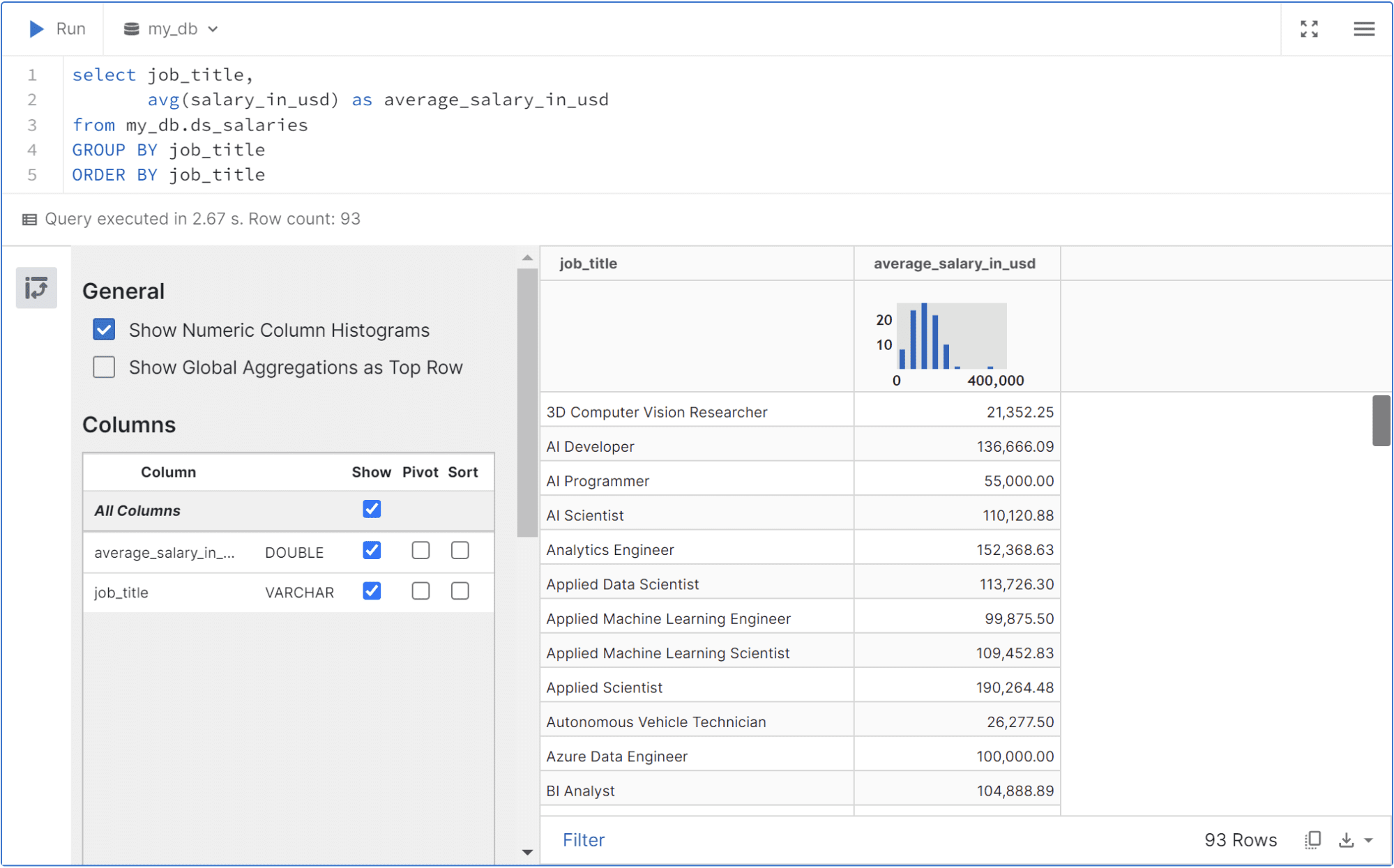
UI で使用できる選択ボタンを使用して、データをフィルターで除外したり、テーブルをピボットしたり、結果をダウンロードしたりできます。
MotherDuck を使用すると、ユーザーは Notebook 上の Python 経由でデータベースにアクセスできます。次のコードを使用して DuckDB パッケージをインストールする必要があります。
pip install duckdb==v0.9.2
MotherDuck がサポートする現在のバージョンは DuckDB 0.9.2 です。そのため、そのバージョンをインストールしました。
インストールが成功したら、DuckDB を Motherduck に接続する必要があります。接続を認証するにはいくつかの方法がありますが、ここではサービス トークンを使用します。このトークンは MotherDuck 設定で取得されます。
import duckdb
token = "insert token here"
# initiate the MotherDuck connection
con = duckdb.connect(f'md:?motherduck_token={token}')
データベース名を設定しなかった場合、MotherDuck はデフォルトのデータベース (my_db) を使用してアクセスします。次に、以前に Notebook で実行したのと同じクエリを使用してみましょう。
q = """
select job_title,
avg(salary_in_usd) as average_salary_in_usd
from my_db.ds_salaries
GROUP BY job_title
ORDER BY job_title
"""
con.sql(q).show()
以下の表のような出力が表示されます。
┌─────────────────────────────────────┬───────────────────────┐
│ job_title │ average_salary_in_usd │
│ varchar │ double │
├─────────────────────────────────────┼───────────────────────┤
│ 3D Computer Vision Researcher │ 21352.25 │
│ AI Developer │ 136666.0909090909 │
│ AI Programmer │ 55000.0 │
│ AI Scientist │ 110120.875 │
│ Analytics Engineer │ 152368.63106796116 │
│ Applied Data Scientist │ 113726.3 │
│ Applied Machine Learning Engineer │ 99875.5 │
│ Applied Machine Learning Scientist │ 109452.83333333333 │
│ Applied Scientist │ 190264.4827586207 │
│ Autonomous Vehicle Technician │ 26277.5 │
│ · │ · │
│ · │ · │
│ · │ · │
│ Principal Data Engineer │ 192500.0 │
│ Principal Data Scientist │ 198171.125 │
│ Principal Machine Learning Engineer │ 190000.0 │
│ Product Data Analyst │ 56497.2 │
│ Product Data Scientist │ 8000.0 │
│ Research Engineer │ 163108.37837837837 │
│ Research Scientist │ 161214.19512195123 │
│ Software Data Engineer │ 62510.0 │
│ Staff Data Analyst │ 15000.0 │
│ Staff Data Scientist │ 105000.0 │
├─────────────────────────────────────┴───────────────────────┤
│ 93 rows (20 shown) 2 columns │
└─────────────────────────────────────────────────────────────┘
上記のクエリでは、次のコードを使用してそれらを Pandas DataFrame に処理できます。
import pandas as pd
df = con.sql(q).fetchdf()
最後に、次のクエリを使用して、別のデータセットをデータベースにロードできます。
con.sql("CREATE TABLE mytable AS SELECT * FROM '~/filepath.csv'")
上記のクエリは、データが CSV ファイルであることを前提としています。その他のオプションには、S3 または MotherDuck データベースへのローカル DuckDB が含まれます。
DuckDB は、データ分析専用に開発されたオープンソース データベース システムです。このシステムは、データ処理を迅速かつ効率的に処理できるように設計されています。 MotherDuck は、DuckDB 用のオープンソースのマネージド クラウドベース サービスです。
DuckDB と MotherDuck を組み合わせることで、データをクラウドに置き、DuckDB で迅速に処理することで、ラップトップを個人用分析エンジンに変えることができます。
コーネリアス・ユダ・ウィジャヤ は、データ サイエンス アシスタント マネージャー兼データ ライターです。 Allianz Indonesia でフルタイムで働いている間、彼はソーシャル メディアやライティング メディアを通じて Python とデータのヒントを共有するのが大好きです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/turn-your-laptop-into-a-personal-analytics-engine-with-duckdb-and-motherduck?utm_source=rss&utm_medium=rss&utm_campaign=turn-your-laptop-into-a-personal-analytics-engine-with-duckdb-and-motherduck
- :持っている
- :は
- :not
- :どこ
- 10
- 125
- 15000
- 20
- 25
- 3d
- 7
- 8
- 8000
- 9
- a
- 上記の.
- アクセス
- 取得する
- 取得
- アクティビティ
- 加えます
- 進める
- アドバンス
- 凝集
- AI
- すべて
- アリアンツ
- ことができます
- 既に
- また
- an
- 分析
- アナリスト
- 分析的
- 分析的
- 分析論
- および
- 別の
- どれか
- 適用された
- です
- AS
- アシスタント
- と仮定する
- At
- 認証
- 自律的
- 自律車両
- 利用できます
- BE
- 以下
- の間に
- 内蔵
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- (Comma Separated Values) ボタンをクリックして、各々のジョブ実行の詳細(開始/停止時間、変数値など)のCSVファイルをダウンロードします。
- by
- 缶
- セル
- 変更
- クラウド
- コード
- コラム
- 組み合わせ
- 結合
- コミュニティ
- コンピュータ
- Computer Vision
- 同時
- お問合せ
- 接続
- 可能性
- 作ります
- 重大な
- 電流プローブ
- データ
- データ分析
- データアナリスト
- データ分析
- データエンジニア
- データ処理
- データサイエンス
- データサイエンティスト
- データベース
- デフォルト
- 設計
- 発展した
- Developer
- DID
- 違い
- do
- すること
- ダウンロード
- 効果的に
- 効率良く
- エンジン
- エンジニア
- 等
- エーテル(ETH)
- EVER
- あらゆる
- 例
- 実行します
- 実験
- 慣れる
- 少数の
- File
- filter
- フォロー中
- 無料版
- から
- 生成された
- 取得する
- 与える
- グループ
- ハンド
- ハンドル
- ハンドリング
- 持って
- he
- 助けました
- こちら
- 認定条件
- HTTPS
- if
- 画像
- 実装する
- 改善します
- in
- include
- インドネシア
- 開始する
- install
- インストール
- に
- 関与
- 関与
- IT
- join
- ジュピターノート
- KDナゲット
- ラボ
- ノートパソコン
- ノートパソコン
- 学習
- ような
- LIMIT
- 負荷
- ローカル
- 見て
- のように見える
- で
- 機械
- 機械学習
- マネージド
- 管理
- マネジメントシステム
- マネージャー
- メディア
- ずっと
- の試合に
- 名
- すなわち
- ネイティブ
- 必要
- ニーズ
- 新作
- 次の
- ノート
- of
- on
- ONE
- オンライン
- オープンソース
- オプション
- or
- 注文
- その他
- 私たちの
- でる
- 出力
- パッケージ
- パンダ
- パートナー
- 完璧
- 個人的な
- 枢軸
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- お願いします
- 電力
- 強力な
- かなり
- 前に
- 校長
- プロセス
- ラボレーション
- 処理
- プロダクト
- プログラマー
- 公共
- Python
- クエリ
- すぐに
- すぐに
- 実現する
- 関係なく
- 登録
- replace
- 研究
- 研究者
- 結果
- 給与
- 同じ
- シナリオ
- 科学
- 科学者
- select
- 選択
- サービス
- セッションに
- 設定
- シェアする
- すべき
- 示す
- 重要
- 同様の
- 同様に
- サイズ
- 社会
- ソーシャルメディア
- ソフトウェア
- 特に
- SQL
- スタック
- スタッフ
- 成功した
- 首尾よく
- 適当
- サポート
- サポート
- 素早く
- システム
- テーブル
- 撮影
- テクノロジー
- それ
- それら
- そこ。
- ボーマン
- この
- 時間
- ヒント
- 〜へ
- トークン
- ツール
- 豊富なツール群
- 試します
- 順番
- ui
- つかいます
- ユーザー
- 通常
- 自動車
- バージョン
- 、
- ビジョン
- ました
- 方法
- we
- ウェブサイト
- いつ
- which
- while
- なぜ
- 意志
- ワークフロー
- ワーキング
- 作品
- でしょう
- 作家
- 書き込み
- 貴社
- あなたの
- あなた自身
- ゼファーネット