概要
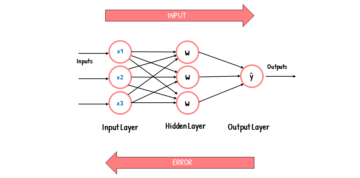
人工知能の未来に向けた大きな前進として、研究者らは画期的な自己回帰マルチモーダル モデルである Unified-IO 2 を発表しました。この革新的な反復は、画像、テキスト、音声、アクションなどの多様なデータ モダリティを理解して生成することにより、AI の境界を再定義します。共有セマンティック空間と単一のエンコーダ/デコーダ変換モデルにより、その比類のない機能が推進され、多面モデルのトレーニングの複雑さを克服します。

マルチモーダルな状況をナビゲートする: 統一されたアプローチ
Unified-IO 2 は、入力と出力を共有セマンティック空間にトークン化し、単一のエンコーダ/デコーダ変換モデルを通じて処理するという新しいアプローチを採用しています。この統一された方法論により他とは一線を画し、さまざまなモダリティの複雑さをシームレスにナビゲートできるようになります。画像やテキストの生成から音声やアクションの出力まで、無数のタスクを処理するモデルの能力は、その熟練度を示しています。
課題と解決策: アーキテクチャの強化
多様なモダリティを使用したトレーニングには課題があり、安定したモデル トレーニングのためのアーキテクチャの強化が提案されています。モデルは、さまざまなソースを組み込んだ、広範なマルチモーダル事前トレーニング コーパスに基づいて最初からトレーニングされます。デノイザーの目的をマルチモーダルに混合することで、複数のモダリティにわたる自己教師あり学習信号が容易になり、モデルの適応性が確保されます。
解き放たれた多用途性: ベンチマーク全体でのパフォーマンス
Unified-IO 2 は、画像の生成と理解、自然言語の理解、ビデオとオーディオの理解、さらにはロボット操作に至るまで、35 を超えるベンチマークで優れています。特に、General Robust Image Task (GRIT) ベンチマークにおける最先端のパフォーマンスは、以前のバージョンを 2.7 ポイント上回っています。自由形式の指示に従うモデルの能力は、その堅牢性を強調しています。
結果 Speak Louder: マルチタスクの驚異
GRIT ベンチマークにおける Unified-IO 2 のパフォーマンスは注目に値し、分類、ローカリゼーション、セグメンテーション、キーポイント推定における優れた能力を示しています。このモデルの多用途性は画像とテキストの生成、音声合成、アクション予測にまで及び、Unified-IO 2 を真のマルチタスクの驚異として位置付け、さまざまなドメインで競合他社を上回ります。
新しい領域を描く: ベンチマークを超えて
Unified-IO 2 の機能は、よく知られたベンチマークを超えて、テキストから画像への生成、テキストからオーディオへの生成、アクション生成などの新しい領域に参入しています。競合他社を上回るこのモデルは、多様なタスクにおける能力を強調し、複雑な課題に対処する際の多用途性と適応性を示しています。
以下について読むことができます – マルチモーダルモデルとは
視覚と言語の優位性: 全体的な理解
Unified-IO 2 はマルチタスクにとどまりません。視覚と言語のタスクに優れており、GRIT、VQA、ScienceQA などのベンチマークで最先端の結果を達成しています。そのパフォーマンスは、マルチモーダル データを総合的に理解している証拠であり、ビジョンと言語のジェネラリストとしての地位を確固たるものとしています。
私たちの言う
Unified-IO 2 の複雑さを詳しく調べると、このマルチモーダル モデルが単なる前進ではなく、AI の未来への飛躍であることが明らかになります。多様なタスクを処理する能力は、このモデルの熟練度を示しており、さまざまな領域で競合他社を上回る能力は、その適応性を示しています。 Unified-IO 2 は、AI がマルチモーダルな世界の複雑さをシームレスにナビゲートし、理解する未来を指し示すビーコンの役割を果たします。この注目すべき成果は新たな地平を開き、人工知能のさらなる探求と進歩を刺激します。
フォローをお願いします グーグルニュース AI、データサイエンス、その他の世界の最新のイノベーションを常に最新の状態に保つため ゲンアイ.
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2024/01/unified-io-2-a-giant-leap-in-multimodal-ai-evolution/
- :は
- :not
- :どこ
- 視聴者の38%が
- 7
- a
- 能力
- 私たちについて
- 達成
- 達成する
- 越えて
- Action
- アドバンス
- AI
- 許可
- an
- および
- 離れて
- アプローチ
- 建築の
- です
- 人工の
- 人工知能
- AS
- At
- オーディオ
- ビーコン
- になる
- ベンチマーク
- ベンチマーク
- 越えて
- 境界
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 缶
- 機能
- 機能
- 容量
- 課題
- 競合他社
- 複雑な
- 複雑さ
- 理解する
- データ
- データサイエンス
- 掘り下げる
- 実証
- 異なる
- そうではありません
- ドメイン
- 支配
- ドライブ
- 従業員
- 強化
- 確保する
- 入る
- さらに
- 明らか
- 進化
- 探査
- 伸ばす
- 拡張する
- 広範囲
- 促進する
- おなじみの
- フォワード
- から
- さらに
- 未来
- AIの未来
- 生成
- 世代
- 巨大な
- でログイン
- 画期的な
- ハンドル
- ハンドリング
- 持ってる
- ハイ
- 包括的な
- 地平
- HTTPS
- 画像
- 画像生成
- in
- 含めて
- 組み込む
- イノベーション
- 入力
- インスピレーション
- 説明書
- インテリジェンス
- に
- 複雑さ
- IT
- 繰り返し
- ITS
- ただ
- 風景
- 言語
- 最新の
- 主要な
- 跳躍
- 学習
- ような
- ローカライゼーション
- 大声で
- 操作
- マーキング
- 驚異
- 最大幅
- 方法論
- 混合
- モダリティ
- モデル
- 多面
- の試合に
- 無数の
- ナチュラル
- 自然言語
- 自然言語理解
- ナビゲートします
- ナビゲーション
- 新作
- ニューホライズン
- 特に
- 小説
- 目的
- of
- on
- 開きます
- 私たちの
- 優れたパフォーマンス
- 出力
- outputs
- が
- 克服する
- パフォーマンス
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- 位置
- ポジショニング
- 前任者
- 予測
- プレゼント
- 処理されました
- 提案された
- 腕前
- 読む
- 顕著
- 研究者
- 結果
- 革新的な
- 堅牢な
- 丈夫
- 科学
- スクラッチ
- シームレス
- シームレス
- セグメンテーション
- セット
- shared
- 展示の
- 信号
- 重要
- 単数
- 固まる
- ソリューション
- ソース
- スペース
- 緊張
- 話す
- 安定した
- スタンド
- 最先端の
- 滞在
- 手順
- Force Stop
- ストライド
- そのような
- 凌駕する
- 合成
- 仕事
- タスク
- 地域
- 遺言
- 클라우드 기반 AI/ML및 고성능 컴퓨팅을 통한 디지털 트윈의 기초 – Edward Hsu, Rescale CPO 많은 엔지니어링 중심 기업에게 클라우드는 R&D디지털 전환의 첫 단계일 뿐입니다. 클라우드 자원을 활용해 엔지니어링 팀의 제약을 해결하는 단계를 넘어, 시뮬레이션 운영을 통합하고 최적화하며, 궁극적으로는 모델 기반의 협업과 의사 결정을 지원하여 신제품을 결정할 때 데이터 기반 엔지니어링을 적용하고자 합니다. Rescale은 이러한 혁신을 돕기 위해 컴퓨팅 추천 엔진, 통합 데이터 패브릭, 메타데이터 관리 등을 개발하고 있습니다. 이번 자리를 빌려 비즈니스 경쟁력 제고를 위한 디지털 트윈 및 디지털 스레드 전략 개발 방법에 대한 인사이트를 나누고자 합니다.
- テキスト生成
- それ
- 未来
- 世界
- この
- 介して
- 〜へ
- トークン化
- に向かって
- 訓練された
- トレーニング
- トランス
- true
- アンダースコア
- 理解する
- 統一
- 解き放たれました
- 圧倒的な
- 発表
- 更新しました
- us
- さまざまな
- 汎用性
- ビデオ
- ビジョン
- we
- 世界
- ゼファーネット