著者による画像
機械学習を始める場合、ロジスティック回帰はツールボックスに最初に追加するアルゴリズムの 1 つです。これはシンプルで堅牢なアルゴリズムであり、バイナリ分類タスクによく使用されます。
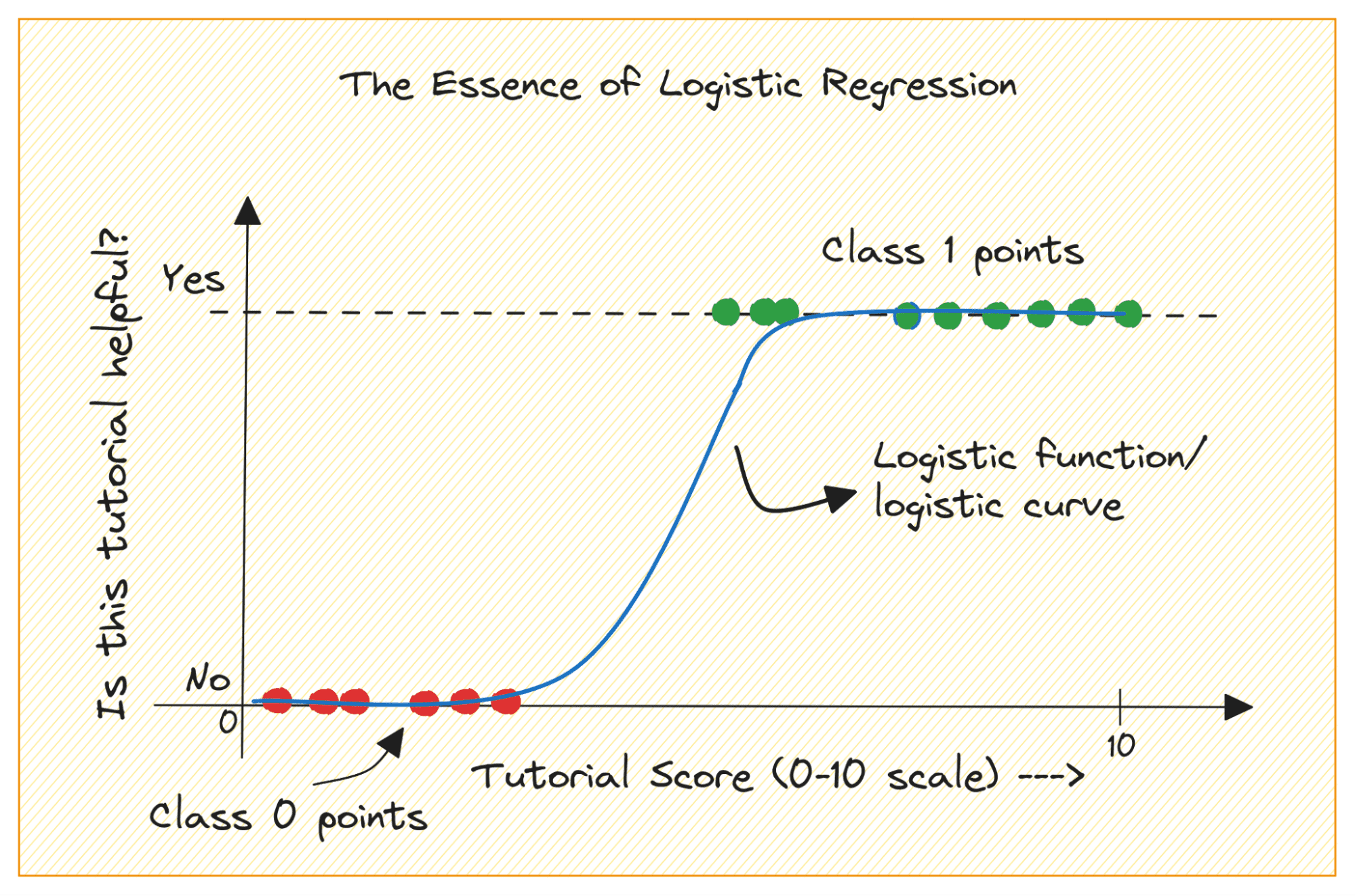
クラス 0 と 1 の二項分類問題を考えてみましょう。ロジスティック回帰では、ロジスティック関数またはシグモイド関数を入力データに近似し、クエリ データ ポイントがクラス 1 に属する確率を予測します。興味深いですね。
このチュートリアルでは、ロジスティック回帰について基礎から学びます。以下の内容をカバーします。
- ロジスティック (またはシグモイド) 関数
- 線形回帰からロジスティック回帰に移行する方法
- ロジスティック回帰の仕組み
最後に、単純なロジスティック回帰モデルを構築します。 電離層からのレーダーリターンを分類する.
ロジスティック回帰について詳しく学ぶ前に、ロジスティック関数がどのように機能するかを確認しましょう。ロジスティック (またはシグモイド関数) は次のように与えられます。

シグモイド関数をプロットすると、次のようになります。
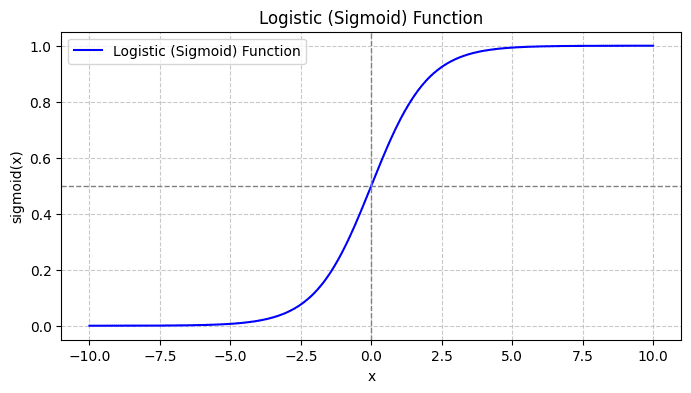
プロットから、次のことがわかります。
- x = 0 の場合、σ(x) は 0.5 の値になります。
- x が +∞ に近づくと、σ(x) は 1 に近づきます。
- x が -∞ に近づくと、σ(x) は 0 に近づきます。
したがって、すべての実数入力に対して、シグモイド関数はそれらを押しつぶして [0, 1] の範囲内の値をとります。
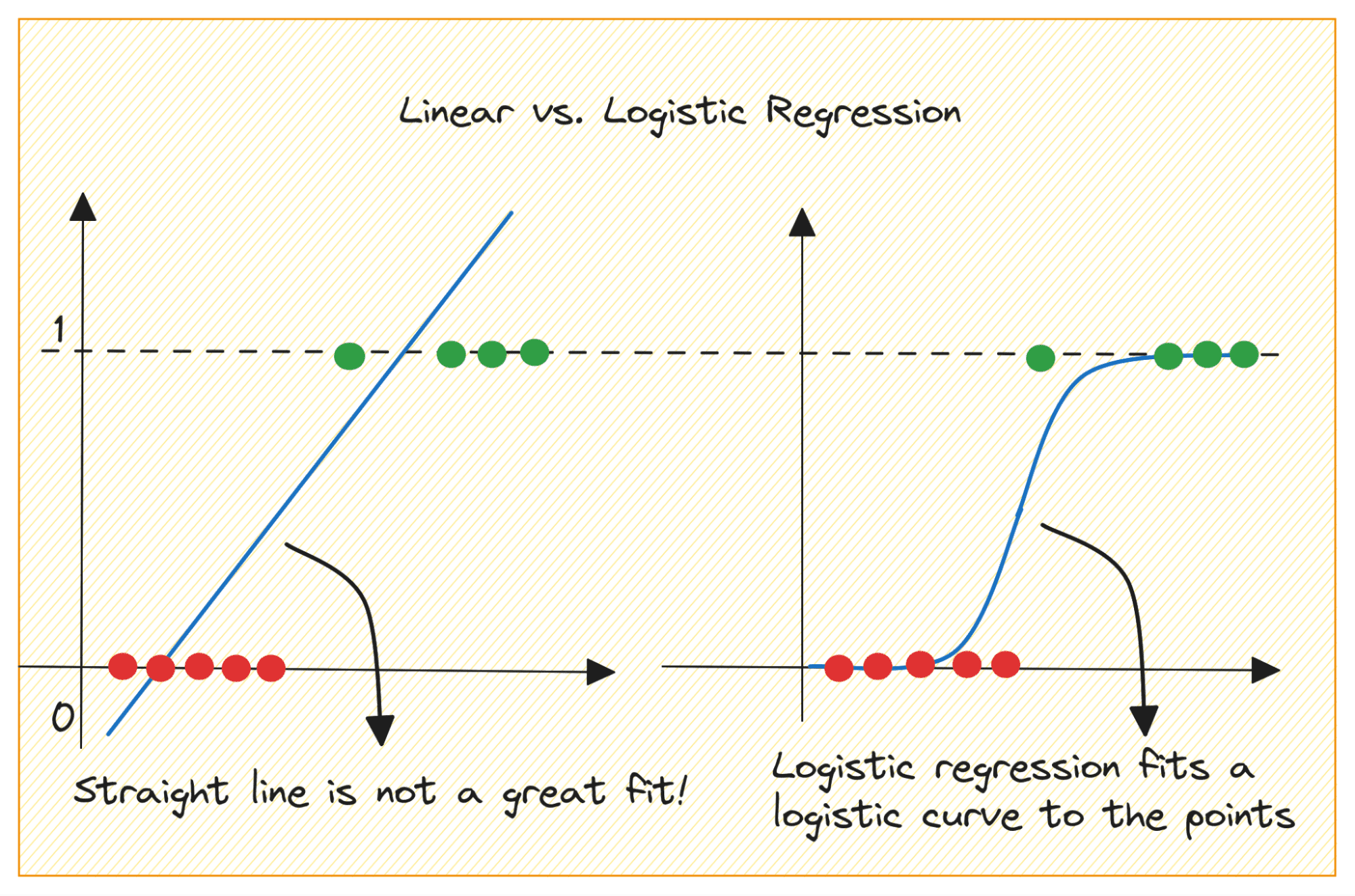
まず、二項分類問題に線形回帰を使用できない理由について説明します。
バイナリ分類問題では、出力はカテゴリラベル (0 または 1) です。線形回帰は、0 未満または 1 より大きい連続値の出力を予測するため、当面の問題にとっては意味がありません。
また、出力ラベルが 2 つのカテゴリのいずれかに属する場合、直線が最適ではない可能性があります。
著者による画像
では、線形回帰からロジスティック回帰にどのように移行するのでしょうか?線形回帰では、予測出力は次のように求められます。
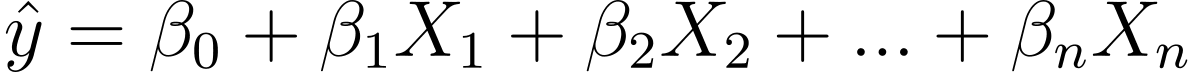
ここで、β は係数、X_is は予測子 (または特徴) です。
一般性を失わずに、X_0 = 1 と仮定します。

したがって、より簡潔な表現が可能になります。
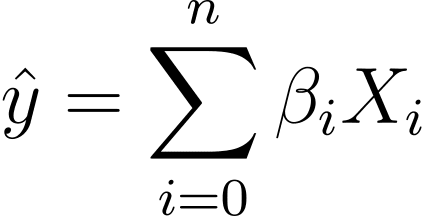
ロジスティック回帰では、[0,1] 区間の予測確率 p_i が必要です。ロジスティック関数が入力を押しつぶして、[0,1] 区間の値を取ることがわかっています。
したがって、この式をロジスティック関数に代入すると、予測確率は次のようになります。
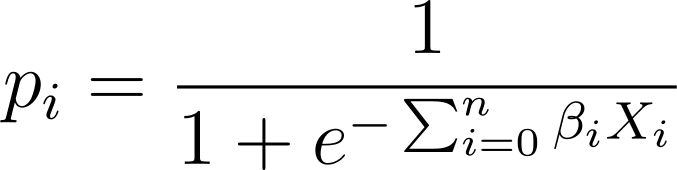
では、与えられたデータセットに最適なロジスティック曲線を見つけるにはどうすればよいでしょうか?これに答えるために、最尤推定を理解しましょう。
最尤推定 (MLE) 尤度関数を最大化することでロジスティック回帰モデルのパラメーターを推定するために使用されます。ロジスティック回帰における MLE のプロセスと、勾配降下法を使用した最適化のためのコスト関数の定式化方法を詳しく見てみましょう。
最尤推定の分解
説明したように、バイナリ結果が 1 つ以上の予測変数 (または特徴) の関数として発生する確率をモデル化します。
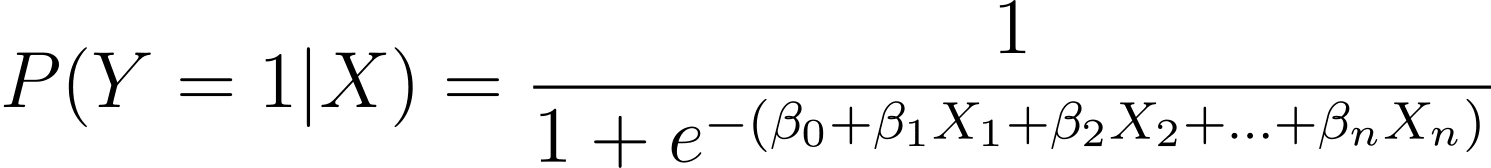
ここで、β はモデルのパラメーターまたは係数です。 X_1、X_2、…、X_n は予測変数です。
MLE は、観測データの尤度を最大化する β の値を見つけることを目的としています。 L(β) として示される尤度関数は、ロジスティック回帰モデルの下で、指定された予測値に対して指定された結果が観察される確率を表します。
対数尤度関数の定式化
最適化プロセスを簡素化するには、対数尤度関数を使用するのが一般的です。確率の積を対数確率の合計に変換するためです。
ロジスティック回帰の対数尤度関数は次のように求められます。
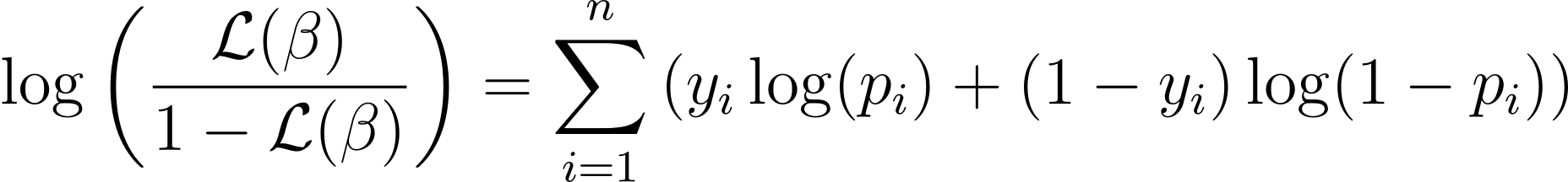
対数尤度の本質を理解したので、最適なモデル パラメーターを見つけるためのロジスティック回帰とその後の勾配降下法のコスト関数の定式化に進みましょう。
ロジスティック回帰のコスト関数
ロジスティック回帰モデルを最適化するには、対数尤度を最大化する必要があります。したがって、トレーニング中に最小化するコスト関数として負の対数尤度を使用できます。負の対数尤度はロジスティック損失と呼ばれることが多く、次のように定義されます。
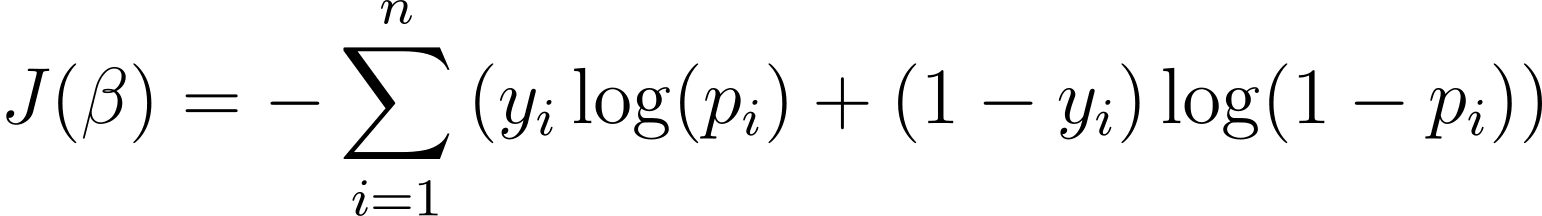
したがって、学習アルゴリズムの目標は、? の値を見つけることです。このコスト関数を最小化します。勾配降下法は、このコスト関数の最小値を見つけるために一般的に使用される最適化アルゴリズムです。
ロジスティック回帰における勾配降下法
勾配降下 β に対するコスト関数の勾配と逆方向にモデル パラメーター β を更新する反復最適化アルゴリズムです。勾配降下法を使用したロジスティック回帰のステップ t+1 の更新ルールは次のとおりです。
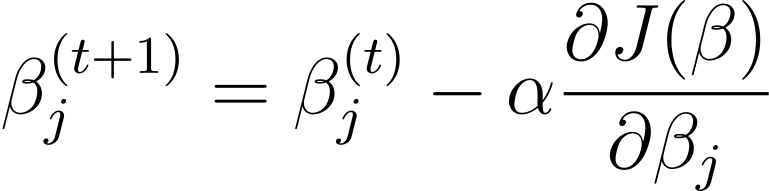
ここで、α は学習率です。
偏導関数は連鎖則を使用して計算できます。勾配降下法は、ロジスティック損失を最小限に抑えることを目的として、収束するまでパラメータを繰り返し更新します。収束するにつれて、観測データの尤度を最大化する最適な β 値が見つかります。
ロジスティック回帰の仕組みがわかったので、scikit-learn ライブラリを使用して予測モデルを構築しましょう。
私たちは UCI 機械学習リポジトリの電離層データセット このチュートリアルのために。データセットは 34 個の数値特徴で構成されます。出力はバイナリで、「良好」または「不良」のいずれかです (「g」または「b」で示されます)。出力ラベル「良好」は、電離層内の何らかの構造を検出したレーダー反射を指します。
ステップ 1 – データセットのロード
まず、データセットをダウンロードし、pandas データフレームに読み込みます。
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)ステップ 2 – データセットの探索
データフレームの最初の数行を見てみましょう。
# Display the first few rows of the DataFrame
df.head()
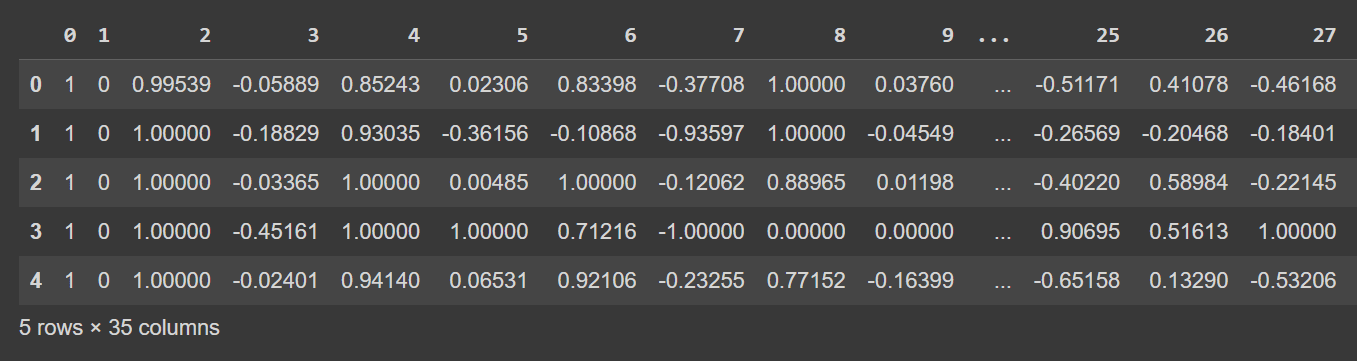
df.head() の切り詰められた出力
データセットに関する情報、つまり非 null 値の数と各列のデータ型を取得しましょう。
# Get information about the dataset
print(df.info())
 df.info() の切り詰められた出力
df.info() の切り詰められた出力
すべての数値特徴があるため、次の関数を使用して記述的な統計を取得することもできます。 describe() データフレーム上のメソッド:
# Get descriptive statistics of the dataset
print(df.describe())
df.describe() の切り詰められた出力
現在、列名はラベルを含めて 0 ~ 34 です。データセットでは列にわかりやすい名前が提供されていないため、必要に応じて、次のように列の名前を属性 1 から属性 34 として参照するだけです。
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
注: このステップは完全にオプションです。必要に応じて、デフォルトの列名を使用して続行できます。
# Display the first few rows of the DataFrame
df.head()
df.head() の切り捨てられた出力 [列の名前変更後]
ステップ 3 – クラスラベルの名前変更とクラス分布の視覚化
出力クラス ラベルは 'g' と 'b' であるため、それらをそれぞれ 1 と 0 にマップする必要があります。を使用してそれを行うことができます map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
クラス ラベルの分布も視覚化してみましょう。
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
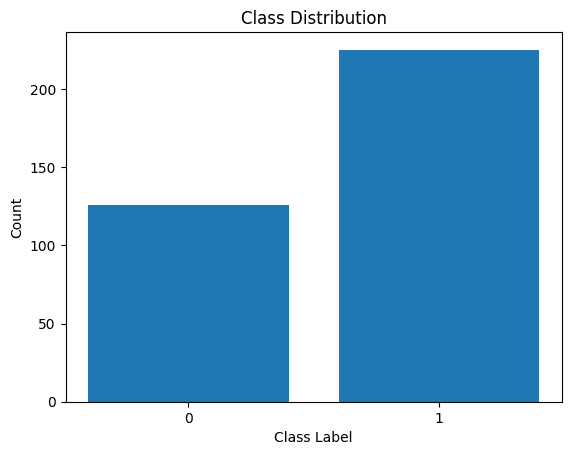
クラスラベルの分布
分布に不均衡があることがわかります。クラス 1 よりもクラス 0 に属するレコードの方が多いです。このクラスの不均衡は、ロジスティック回帰モデルを構築するときに処理します。
ステップ 5 – データセットの前処理
次のように特徴を収集してラベルを出力しましょう。
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
データセットをトレーニング セットとテスト セットに分割した後、データセットを前処理する必要があります。
多数の数値特徴があり、それぞれのスケールが異なる可能性がある場合、数値特徴を前処理する必要があります。一般的な方法は、ゼロ平均と単位分散の分布に従うようにそれらを変換することです。
StandardScaler scikit-learn の前処理モジュールがこれを達成するのに役立ちます。
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])ステップ 6 – ロジスティック回帰モデルの構築
これで、ロジスティック回帰分類器をインスタンス化できるようになりました。の LogisticRegression クラスはscikit-learnのlinear_modelモジュールの一部です。
を設定していることに注意してください。 class_weight パラメータを「バランス」に設定します。これはクラスの不均衡を説明するのに役立ちます。各クラスに重みを割り当てることで、クラス内のレコード数に反比例します。
クラスをインスタンス化した後、モデルをトレーニング データセットに適合させることができます。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)ステップ 7 – ロジスティック回帰モデルの評価
あなたは呼び出すことができます predict() モデルの予測を取得するメソッド。
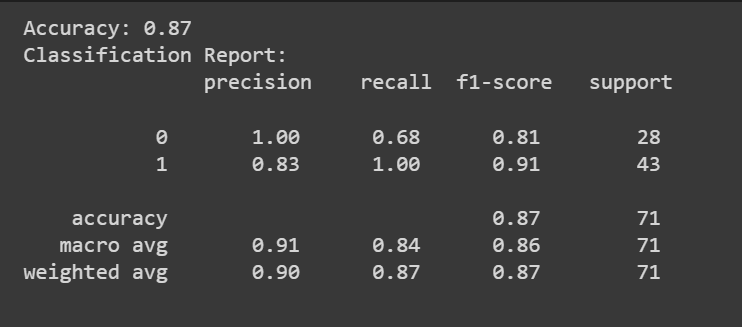
精度スコアに加えて、適合率、再現率、F1 スコアなどの指標を含む分類レポートも取得できます。
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
おめでとうございます。最初のロジスティック回帰モデルのコーディングが完了しました。
このチュートリアルでは、理論と数学からロジスティック回帰分類器のコーディングまで、ロジスティック回帰について詳しく学びました。
次のステップとして、選択した適切なデータセットのロジスティック回帰モデルを構築してみてください。
電離層データセットは、 クリエイティブ・コモンズ 表示 4.0 国際 (CC BY 4.0) ライセンス:
シギリート、V.、ウィング、S.、ハットン、L.、およびベイカー、K.. (1989)。電離層。 UCI 機械学習リポジトリ。 https://doi.org/10.24432/C5W01B。
バラ プリヤ C インド出身の開発者兼テクニカル ライターです。 彼女は、数学、プログラミング、データ サイエンス、コンテンツ作成が交わる場所で働くのが好きです。 彼女の興味と専門分野には、DevOps、データ サイエンス、自然言語処理が含まれます。 彼女は読書、執筆、コーディング、コーヒーが好きです。 現在、彼女はチュートリアル、ハウツー ガイド、意見記事などを作成して、学習し、開発者コミュニティと知識を共有することに取り組んでいます。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :は
- :not
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- 私たちについて
- 精度
- 達成する
- 加えます
- 添加
- 後
- 目指して
- アルゴリズム
- アルゴリズム
- すべて
- また
- an
- および
- 回答
- アプローチ
- です
- エリア
- AS
- 引き受けます
- At
- オーサリング
- b
- ベイカー
- バランスのとれた
- バー
- BE
- なぜなら
- 所属
- BEST
- ブレーク
- ビルド
- 建物
- by
- コール
- 缶
- カテゴリ
- チェーン
- 選択
- class
- クラス
- 分類
- コード化
- コーディング
- 収集する
- コラム
- コラム
- コマンドと
- 一般に
- コモンズ
- コミュニティ
- 含む
- 特徴
- コンテンツ
- コンテンツ作成
- 変換
- 費用
- カバーする
- 作ります
- 創造
- 現在
- 曲線
- データ
- データポイント
- データサイエンス
- データセット
- デフォルト
- 定義済みの
- デリバティブ
- 詳細
- 検出された
- Developer
- DevOps
- 異なります
- 方向
- 話し合います
- 議論する
- ディスプレイ
- ディストリビューション
- do
- ありません
- ダウン
- ダウンロード
- 間に
- 各
- 本質
- 推定
- 評価します
- 専門知識
- 探る
- 表現
- 特徴
- 少数の
- もう完成させ、ワークスペースに掲示しましたか?
- 発見
- 発見
- 名
- フィット
- 次
- FRAME
- から
- function
- 取得する
- 受け
- 与えられた
- Go
- 目標
- でログイン
- 大きい
- 陸上
- ガイド
- ハンド
- ハンドル
- 持ってる
- 助けます
- ことができます
- 彼女の
- 認定条件
- HTTPS
- ICS
- if
- 不均衡
- import
- in
- include
- index
- インド
- 索引
- 情報
- 入力
- 関心
- 興味深い
- 交差点
- に
- IT
- ただ
- KDナゲット
- 知っている
- 知識
- ラベル
- ラベル
- 言語
- LEARN
- 学んだ
- 学習
- less
- う
- 図書館
- ライセンス
- ライセンス供与
- ような
- 尤度
- 好き
- LINE
- ローディング
- ログ
- 見て
- のように見える
- 損失
- 機械
- 機械学習
- make
- 多くの
- 地図
- math
- matplotlib
- 最大化します
- 最大化
- 五月..
- 意味する
- 方法
- メトリック
- 最小限に抑えます
- 最小
- モデル
- モジュール
- 他には?
- 名
- ナチュラル
- 自然言語
- 自然言語処理
- 必要
- 負
- 次の
- 数
- 観測された
- of
- 頻繁に
- on
- ONE
- 意見
- 反対
- 最適な
- 最適化
- 最適化
- or
- 結果
- 成果
- 出力
- outputs
- パンダ
- パラメーター
- パラメータ
- 部
- ピース
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- ポイント
- :
- 精度
- 予測
- 予測
- 予測的
- Predictor
- 予測
- 好む
- 確率
- 問題
- 進む
- プロセス
- 処理
- 製品
- プログラミング
- 提供します
- 純粋に
- Python
- レーダー
- 範囲
- レート
- 読む
- リーディング
- リアル
- 記録
- 言及
- 指し
- 回帰
- レポート
- 倉庫
- 表し
- 要求
- 尊重
- それぞれ
- 収益
- レビュー
- 堅牢な
- ルール
- s
- 科学
- scikit-学ぶ
- スコア
- センス
- セッションに
- セット
- シェアリング
- 彼女
- 示す
- 簡単な拡張で
- 簡素化する
- So
- 一部
- split
- 開始
- 統計
- 手順
- ストレート
- 構造
- 続いて
- そのような
- 適当
- 合計
- 取る
- 取り
- ターゲット
- タスク
- 技術的
- test
- テスト
- より
- それ
- それら
- 理論
- そこ。
- したがって、
- 彼ら
- この
- 介して
- 〜へ
- ツールボックス
- トレーニング
- 訓練された
- トレーニング
- 最適化の適用
- トランスフォーム
- 試します
- チュートリアル
- チュートリアル
- 2
- 下
- わかる
- 単位
- アップデイト
- 更新版
- URL
- us
- 米国のアカウント
- つかいます
- 中古
- 値
- 価値観
- 視覚化する
- we
- いつ
- which
- なぜ
- Wikipedia
- 意志
- 翼
- 仕事
- ワーキング
- 作品
- でしょう
- 作家
- 書き込み
- X
- はい
- 貴社
- あなたの
- ゼファーネット
- ゼロ