編集者による画像
主要な取り組み
- t 検定は、データの XNUMX つの独立したサンプルの平均値に有意差があるかどうかを判断するために使用できる統計検定です。
- アイリス データセットと Python の Scipy ライブラリを使用して t 検定を適用する方法を説明します。
t 検定は、データの XNUMX つの独立したサンプルの平均値に有意差があるかどうかを判断するために使用できる統計検定です。 このチュートリアルでは、t 検定の最も基本的なバージョンを説明します。この場合、XNUMX つのサンプルの分散が等しいと仮定します。 t 検定の他の高度なバージョンには、t 検定の適応である Welch の t 検定が含まれており、XNUMX つのサンプルの分散が等しくなく、サンプル サイズが等しくない可能性がある場合に、より信頼性が高くなります。
t 統計量または t 値は次のように計算されます。
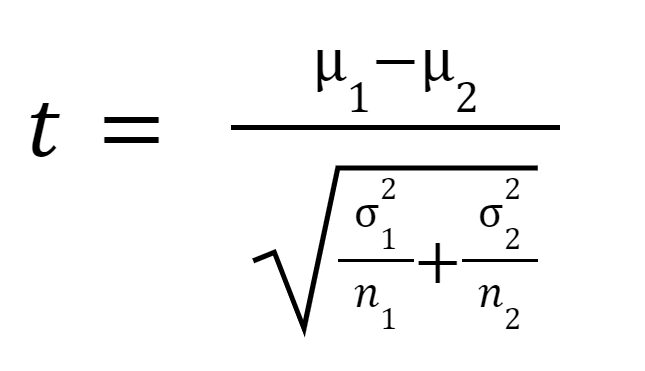
コラボレー
はサンプル 1 の平均、
はサンプル 2 の平均、
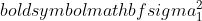 はサンプル 1 の分散、
はサンプル 1 の分散、 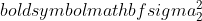 はサンプル 2 の分散、
はサンプル 2 の分散、 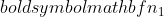 はサンプル 1 のサンプル サイズであり、
はサンプル 1 のサンプル サイズであり、 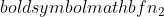 サンプル 2 のサンプル サイズです。
サンプル 2 のサンプル サイズです。
t 検定の使用法を説明するために、アイリス データセットを使用した簡単な例を示します。 花のがく片の長さなどの XNUMX つの独立したサンプルを観察するとします。この XNUMX つのサンプルが同じ個体群 (たとえば、同じ種の花または同様のがく片の特徴を持つ XNUMX つの種) から抽出されたものか、XNUMX つの異なる個体群から抽出されたものかを検討しているとします。
t 検定は、5 つのサンプルの算術平均の差を定量化します。 p 値は、帰無仮説 (サンプルが同じ母集団平均を持つ母集団から抽出されたという仮説) が真であると仮定して、観察された結果が得られる確率を定量化します。 選択したしきい値 (0.05% または XNUMX など) よりも大きい p 値は、観測が偶然に発生した可能性がそれほど高くないことを示します。 したがって、母集団平均が等しいという帰無仮説を受け入れます。 p 値がしきい値よりも小さい場合、母集団平均が等しいという帰無仮説に反する証拠があります。
T検定入力
t 検定を実行するために必要な入力またはパラメーターは次のとおりです。
- XNUMX つのアレイ a および b サンプル 1 とサンプル 2 のデータを含む
T検定の出力
t 検定は次を返します。
- 計算された t 統計量
- p値
必要なライブラリをインポートする
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
アイリス データセットの読み込み
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
サンプル平均とサンプル分散を計算する
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
t検定を実装する
stats.ttest_ind(a_1, b_1, equal_var = False)
出力
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
出力
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
出力
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)観測
「equal-var」パラメーターに「true」または「false」を使用しても、t 検定の結果はそれほど変わらないことがわかります。 また、サンプル配列 a_1 と b_1 の順序を交換すると、負の t 検定値が得られますが、予想どおり、t 検定値の大きさは変化しません。 計算された p 値はしきい値の 0.05 よりもかなり大きいため、サンプル 1 とサンプル 2 の平均値の差が有意であるという帰無仮説を棄却できます。 これは、サンプル 1 とサンプル 2 のがく片の長さが同じ母集団データから抽出されたことを示しています。
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
サンプル平均とサンプル分散を計算する
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
t検定を実装する
stats.ttest_ind(a_1, b_1, equal_var = False)
出力
stats.ttest_ind(a_1, b_1, equal_var = False)観測
サイズが等しくないサンプルを使用しても、t 統計量と p 値が大幅に変化しないことがわかります。
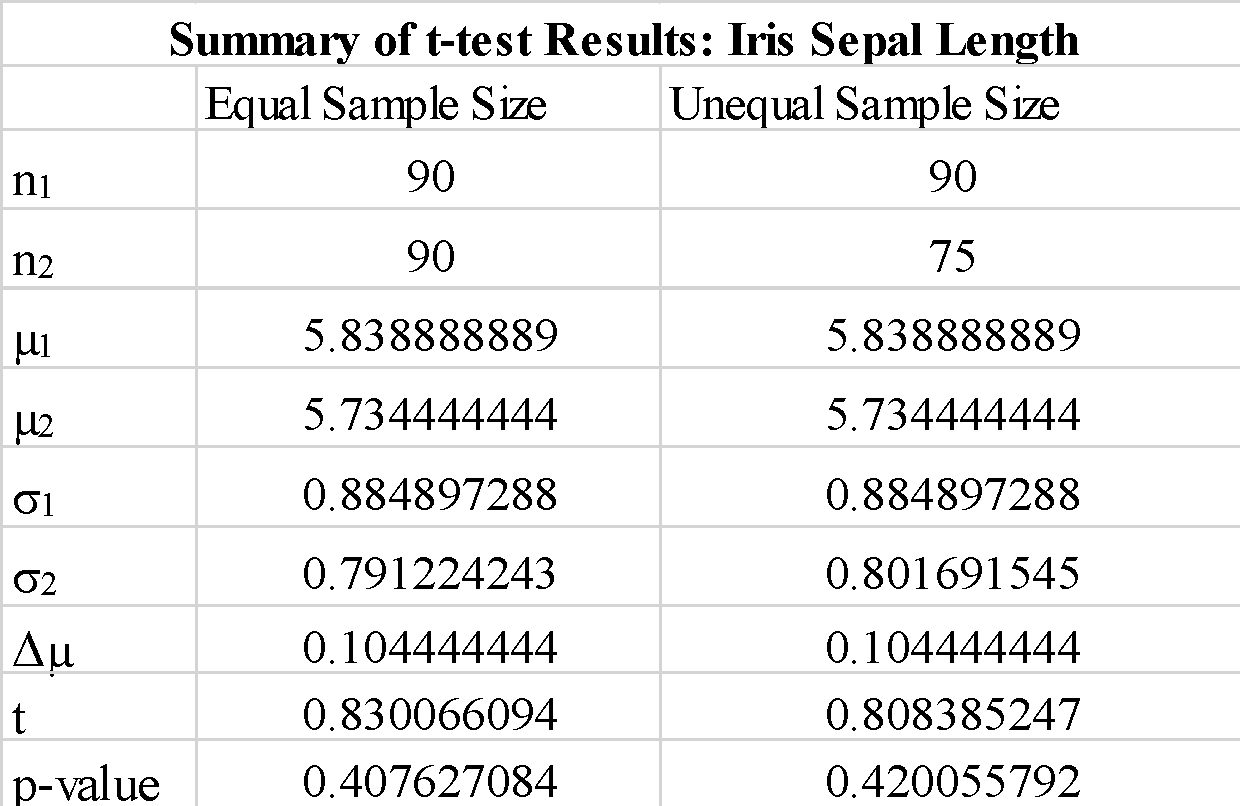
要約すると、Python で scipy ライブラリを使用して単純な t 検定を実装する方法を示しました。
ベンジャミン・O・タヨ は、物理学者、データサイエンス教育者、ライターであり、DataScienceHubの所有者でもあります。 以前、ベンジャミンはセントラルオクラホマ大学、グランドキャニオン大学、およびピッツバーグ州立大学で工学と物理学を教えていました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- 同意
- 高度な
- に対して
- および
- 適用された
- 基本
- ベンジャミン
- の間に
- 計算された
- 中央の
- チャンス
- 変化する
- 特性
- 選ばれた
- 考えると
- 可能性
- データ
- データサイエンス
- データセット
- 決定する
- 違い
- 異なります
- 描かれた
- エンジニアリング
- 証拠
- 例
- 予想される
- 花
- フォロー中
- 次
- から
- 認定条件
- HTTPS
- 実装
- import
- in
- include
- 独立しました
- を示し
- KDナゲット
- より大きい
- 図書館
- matplotlib
- 手段
- 他には?
- 最も
- 必要
- 負
- numpy
- 観察する
- 入手
- 発生した
- オクラホマ州
- 注文
- その他
- 所有者
- パラメーター
- パラメータ
- 実行
- 物理学
- ピッツバーグ
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 人口
- 人口
- 前に
- 確率
- Python
- 信頼性のある
- 結果
- 収益
- 同じ
- 科学
- 表示する
- 示す
- 作品
- 重要
- 著しく
- 同様の
- 簡単な拡張で
- から
- サイズ
- サイズ
- より小さい
- So
- 都道府県
- 統計的
- 統計情報
- 概要
- ティーチング
- test
- したがって、
- しきい値
- 〜へ
- true
- チュートリアル
- つかいます
- 値
- バージョン
- かどうか
- which
- 意志
- 作家
- 収量
- ゼファーネット