~からテーブルを抽出しようとしています PDFファイル そしてそれらをに変換します Excel フォーマット? 意図に基づいて、適切なメッセージを適切なユーザーに適切なタイミングで Nanonets PDF テーブル抽出ツール 無料で表形式のデータを抽出し、Excel に変換します。
概要
大企業の機能/業務は、スプレッドシート/Excel ファイルの使用と密接に結びついています。 Google スプレッドシートで整理された応募者のリストや個々の従業員のタスクの分離から、会社全体の財務および予算の予測に至るまで、企業は想像以上に表形式のフォームに依存しています。 ただし、データは統一された Excel 表現に落ち着きましたが、情報をさまざまな媒体からそのような形式に変換するには、他の作業に費やすことができる集中的な労働時間がかかる可能性があります。

コンピューター ビジョンとテキスト理解技術の進歩は、最終的にデータ抽出プロセスの再考につながりました。ディープ ラーニング技術を活用して、データを理解し、抽出し、数学的に計算可能な Excel 形式に整理するにはどうすればよいでしょうか?
この記事では、PDF データの自動抽出アプローチと CSV ファイルへの変換に関して過去 XNUMX 年間に達成された大きな進歩について説明し、このタスクを達成するための深層学習手法、チュートリアル、市場の既存のソリューションについて簡単に取り上げます。
コア抽出プロセスに入る前に、まず取得しようとしているデータの「種類」を理解する必要があります。 PDF には多数のデータ構造が存在しますが、その中で最も一般的でわかりやすいのは表形式とキーと値のペア (KVP) です。
表形式
表形式のデータは抽出するのが簡単に見えるかもしれませんが、PDF には固有の保存形式があるため、実際には困難な作業です。
多くの PDF では、テキストや表は機械でエンコードされた単語ではなくピクセルとして表示されます。 言い換えれば、これらは他の画像と同様、単なる白黒の非構造化ピクセルです。 したがって、表形式のデータを抽出するには、多くの場合、実際の単語を理解する前に表とテキストの検出が必要になります。
キーと値のペア
場合によっては、カテゴリ情報が表形式で明示的に表示されず、その代わりにキーと値として XNUMX つのリンクされたデータ項目である KVP として表示されることがあります。ここで、キーは値の一意の識別子です。 この例には、パスポートに記載されているデータが含まれます。 これらのデータは結果的に Excel ファイルのテーブルに変換できますが、元々は表示可能なテーブルではなく KVP として表示されていました。 したがって、そのようなデータの抽出ははるかに困難であり、追加の最先端の深層学習技術が必要になる可能性があります。
PDF から表を抽出し、画像や Excel に変換する無料のオンライン OCR が必要ですか? Nanonets をチェックして、カスタム OCR モデルを構築し、テーブルを抽出して Excel に無料で変換してください。
抽出とテーブル変換の背後にあるテクニック

Excel ファイルに直接インポートできる CSV ファイルへのデータ構造の変換は簡単ですが、前述の理由によりデータ抽出は本質的に困難な場合があります。 このセクションでは、人工知能と機械学習の概念、特に光学式文字認識 (OCR) のためのコンピューター ビジョンにおけるディープ ラーニングについて簡単に説明します。
人工知能と機械学習
人々はこの XNUMX つの用語を同じ意味で関連付けることがよくありますが、実際には意味の微妙な違いはありません。 人工知能は、決定がルールベースで実行されたか学習された設定で実行されたかにかかわらず、決定に基づいて実行するのに役立つ機械支援ソフトウェアを指す広義の用語です。
一方、機械学習は、入力と指定された結果を利用して、将来の意思決定/予測のための中間システムを「学習」するアプローチを具体的に説明します。 従来のコンピュータ ソフトウェアは、システムを介した入力が正確な結果を生み出すことができるように中間システムを設計することを目的としているため、このような設定は最初は奇妙に聞こえるかもしれません。 ただし、実行するタスクが複雑なために中間システムの設計が難しすぎる場合には、機械学習が成功することが証明されています。 アプリケーションの例には、画像分類、オブジェクト検出、そしてもちろん文字認識などの難しい画像関連のタスクが含まれます。
コンピュータービジョンの深層学習
ディープラーニングは機械学習のさらに特殊な分野であり、中間システムを近似するためにマルチパーセプトロン層またはニューラルネットワークを設計します。
ニューラル ネットワークは、生物学的ニューラル ネットワークにヒントを得たアーキテクチャであり、入力がネットワークに入力されると活性化関数として機能する複数のニューロン層で構成されます。 グラウンド トゥルースの予測に基づいて、ニューロンの重みがそれに応じて更新され、「正しい」アクティベーションのみが実行され、適切な決定が行われます。 このプロセスをバックプロパゲーションと呼ぶことがよくあります。
このアーキテクチャは 1970 年代初頭に提案されましたが、必要な計算量が多かったために開発は難航しましたが、GPU の計算能力の向上により最近になってようやく解決されました。

深層学習の強力なモデリング結果により、ほぼすべてのコンピューター ビジョン タスク (つまり、コンピューターに画像を理解させるタスク) が完全にまたは少なくとも部分的に深層学習によって支援されます。 コンピューター ビジョン タスクに使用される特定の種類のニューラル ネットワークの XNUMX つは、畳み込みニューラル ネットワーク (CNN) です。これには、画像をスライドさせて特徴を抽出する従来の畳み込みカーネルが導入されています。 従来のネットワーク層と組み合わせることで、現在の研究は、OCR の驚異的な精度は言うまでもなく、画像内のオブジェクトの分類と検出において最先端の結果を達成しました。
OCR
従来、文書から文字を抽出して機械エンコードされたテキストに変換するプロセスは、ルールベースのスキャンによって行われてきました。 これは、さまざまなフォント、スタイル、さらには手書き文字にさえ適応できる前述の深層学習手法にすぐに取って代わられました。
さらに、長期短期記憶などの指定されたネットワーク アーキテクチャの助けを借りて、文字の前後 (たとえば、「d」と「o」の後、 「g」は「z」よりもはるかに可能性の高い文字です)。
パイプライン
深層学習テクノロジーを簡単に理解した上で、表データを PDF から Excel ファイルに変換するパイプラインを紹介します。
- OCR経由でPDF上のすべての単語を検出します
- PDF 上のすべての境界ボックスを検出する
- 明示的な境界ボックスと PDF に基づいて、データをリストや辞書などのデータ構造に変換します
- リストと辞書を Excel 処理用の CSV ファイルにエクスポートします。
PDF から表を抽出し、画像や Excel に変換する無料のオンライン OCR が必要ですか? Nanonets をチェックして、カスタム OCR モデルを構築し、テーブルを抽出して Excel に無料で変換してください。
チュートリアル
このチュートリアルは、OCR 変換と CSV エクスポートの XNUMX つのコンポーネントで構成されています。 簡単に言うと、PDF から表を Excel および表に変換するプロセスでは、まず PDF から単語と表を適切に抽出し、次にエクスポートする手順が必要です。
チュートリアルは主に Python で行われ、Google API と Python が PDF 変換およびエクスポート用に提供するいくつかの組み込みライブラリを利用します。
チュートリアル パート 1 – OCR 変換
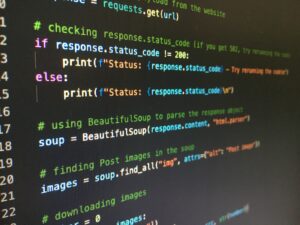
最初に OCR を実行するには、PDF を画像形式に変換する必要がある場合があります。 これは、以下をインストールすることで pdf2image ライブラリを介して実現できます。
pip install pdf2imageパスから変換する方法とバイトから変換する XNUMX つの方法を以下に示します。
from pdf2image import convert_from_path, convert_from_bytes
from pdf2image.exceptions import ( PDFInfoNotInstalledError, PDFPageCountError, PDFSyntaxError
) images = convert_from_path('example.pdf')
images = convert_from_bytes(open('example.pdf','rb').read())コードの詳細については、の公式ドキュメントを参照してください。 https://pypi.org/project/pdf2image/
その後、OCR を取得するために Google Vision API を参照できます。 Google や Amazon などの大企業は、その膨大な顧客ベースにより大規模なクラウドソーシングの恩恵を受けています。 したがって、個人的な OCR をトレーニングする代わりに、そのサービスを使用すると、精度がはるかに高くなる可能性があります。
Google Vision API全体のセットアップは簡単です。公式ガイダンスを参照してください。 https://cloud.google.com/vision/docs/quickstart-client-libraries 詳細なセットアップ手順については。
以下は、OCR検索のコードです。
def detect_document(path): """Detects document features in an image.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.document_text_detection(image=image) for page in response.full_text_annotation.pages: for block in page.blocks: print('nBlock confidence: {}n'.format(block.confidence)) for paragraph in block.paragraphs: print('Paragraph confidence: {}'.format( paragraph.confidence)) for word in paragraph.words: word_text = ''.join([ symbol.text for symbol in word.symbols ]) print('Word text: {} (confidence: {})'.format( word_text, word.confidence)) for symbol in word.symbols: print('tSymbol: {} (confidence: {})'.format( symbol.text, symbol.confidence)) if response.error.message: raise Exception( '{}nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message))document_text_detectionは、主にPDFに表示される非常に凝縮されたテキストに特化した、彼らが提供した関数のXNUMXつであることに注意してください。 PDFの単語がやや不足している場合は、他のテキスト検出機能を使用して、野生の画像に焦点を当てた方がよい場合があります。 Google APIの使用に関するその他のコードは、次の場所で取得できます。 https://cloud.google.com/vision; コードに精通している場合は、他の言語(Javaなど)のコードを参照することもできます。
アマゾンとマイクロソフトからの他のOCRサービス/ APIもあり、いつでも使用できます パイテッセラクト 特定の目的のためにモデルをトレーニングするためのライブラリ。
チュートリアル パート 2 – CSV エクスポート
Python からの CSV エクスポートは、プロセス全体の最後の部分であり、おそらくより単純な部分です。 Python では、データがリストとして保存される場合、次のようになります。
# field names fields = ['FirstName', 'Surname', 'Year', 'CGPA'] # data rows rows = [ ['Nikhil', 'John', '2', '9.0'], ['Sam', 'Cheng', '2', '9.1'], ['Adi', 'Travolta', '2', '9.3'], ['Lorenzo', 'Thomas', '1', '9.5'], ['Stuart', 'Ali', '3', '7.8'], ['Saz', 'TY', '2', '9.1']] 次のように CSV ライターを使用して CSV に単純に入力できます。
with open('people.csv', 'w') as f: write = csv.writer(f) write.writerow(fields) write.writerows(rows)コードを実行すると、ディレクトリ内に people.csv ファイルが作成され、Excel で直接開いてさらに処理できます。
f = open… を使用することもできます。 行の書き込みの間に多くの処理がある場合は、f.close() が続きます。
PDF から表を抽出し、画像や Excel に変換する無料のオンライン OCR が必要ですか? Nanonets をチェックして、カスタム OCR モデルを構築し、テーブルを抽出して Excel に無料で変換してください。
市場のソリューション
現在、データ変換プロセスを自動パイプラインに変換したいと考えている企業が増えています。 したがって、現在では多くの企業 (Google、Amazon など) がそのようなタスクを実行するための API を提供しています。 ここでは、OCR とテーブル検出を提供するいくつかの一般的なソリューションとその長所と短所をリストします。
*補足:実際の画像などのタスクを対象とした複数のOCRサービスがあります。 現在、PDFドキュメントの読み取りのみに重点を置いているため、これらのサービスはスキップしました。
- Google API — データ抽出における Google の無敵の結果は、検索エンジンからの大規模なデータセットのクラウドソーシングによるものです。 個人利用には無料トライアルを提供していますが、通話がビジネス規模に達するとすぐに料金が高騰します。
- ディープリーダー — Deep Reader は、2019 年の ACCV Conference で発表された研究成果です。これは、複数の最先端のネットワーク アーキテクチャを利用して、ドキュメント マッチング、テキスト検索、画像のノイズ除去などのタスクを実行します。 データを体系的に取得および保存できるようにするテーブルやキーと値のペアの抽出などの追加機能があります。
- ナノネット — 高度に熟練した深層学習チームを擁する Nanonets PDF OCR は、テンプレートやルールに完全に依存しません。 したがって、Nanonet は特定の種類の PDF で機能するだけでなく、テキスト検索のためにあらゆる種類のドキュメントに適用することもできます。 表の抽出などのタスクも組み込まれており、あらゆる種類の文書から柔軟かつ高精度に検索できます。
ナノネット — シンプルかつエレガント
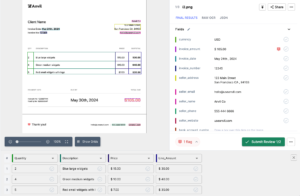
Nanonets のハイライトの XNUMX つは、サービスがもたらすシンプルさです。 プログラミングの知識がなくてもこれらのサービスを選択でき、最先端のテクノロジーを使用して表形式のデータを簡単に抽出できます。 以下は、表を PDF から Excel に変換するために Nanonets にアクセスすることがいかに簡単であるかを簡単に示しています。
ステップ 1
nanonets.comにアクセスし、登録/ログインします。

ステップ 2
登録後、「開始するために選択」領域に移動します。ここで、事前に作成されたすべてのエクストラクタが作成され、表形式のデータを抽出するために設計されたエクストラクタの「テーブル」タブをクリックします。

ステップ 3
数秒後、データ抽出ページがポップアップし、準備ができたことを示します。 抽出のためにファイルをアップロードします。

ステップ 4
処理後、Nanonets は、空のスペースもスキップして、すべての表情報を正確に適切に抽出できます。

PDF から表を抽出し、画像や Excel に変換する無料のオンライン OCR が必要ですか? Nanonets をチェックして、カスタム OCR モデルを構築し、テーブルを抽出して Excel に無料で変換してください。
まとめ
この記事では、PDF から表を抽出して変換し、さらに Excel で開くために CSV ファイルにエクスポートするプロセスについていくつかの洞察を提供します。 XNUMX つのチュートリアルは、このような自動化されたプロセスがどれほど便利かを理解するための入り口として機能することを期待しています。
- '
- "
- 2019
- 7
- 9
- アクセス
- NEW
- 目指す
- すべて
- 許可
- Amazon
- API
- API
- 建築
- AREA
- 記事
- 人工知能
- 人工知能と機械学習
- 自動化
- ブラック
- ビルド
- ビジネス
- ビジネス
- 文字認識
- 分類
- クラウド
- コード
- コマンドと
- 企業
- 会社
- コンピュータソフトウェア
- Computer Vision
- コンピューター
- 講演
- 信頼
- コンテンツ
- 変換
- 法人
- クラウドソーシング
- 電流プローブ
- データ
- 深い学習
- 設計
- 検出
- 開発
- ドキュメント
- 早い
- エッジ(Edge)
- 社員
- Excel
- export
- 抽出
- 特徴
- FRBは
- フィールズ
- ファイナンシャル
- 名
- 形式でアーカイブしたプロジェクトを保存します.
- 無料版
- function
- 未来
- 良い
- でログイン
- GPU
- こちら
- ハイ
- 特徴
- 認定条件
- HTTPS
- 画像
- info
- 情報
- 洞察
- インテリジェンス
- IT
- Java
- キー
- 労働
- ESL, ビジネスESL <br> 中国語/フランス語、その他
- 大
- 学習
- ツェッペリン
- 活用します
- 図書館
- リスト
- リスト
- 機械学習
- 主要な
- 作成
- 市場
- ミディアム
- Microsoft
- 名
- ネットワーク
- ネットワーク
- ニューラル
- ニューラルネットワーク
- ニューラルネットワーク
- オブジェクト検出
- OCR
- 提供
- オファー
- 公式
- オンライン
- 開いた
- 光学式文字認識
- その他
- のワークプ
- 人気
- 電力
- 予測
- ブランド
- プログラミング
- Python
- 上げる
- リーダー
- リーディング
- 理由は
- 参加申し込み
- 研究
- 応答
- 結果
- ラン
- 規模
- スキャニング
- を検索
- 検索エンジン
- サービス
- 設定
- 簡単な拡張で
- So
- ソフトウェア
- ソリューション
- 成功した
- テクニック
- テクノロジー
- トレーニング
- チュートリアル
- チュートリアル
- us
- 値
- ビジョン
- W
- 以内
- 言葉
- 仕事
- 作家
- 書き込み
- 年