現代の世界では、ほとんどの企業がビッグデータと分析の力に依存して、成長、戦略的投資、および顧客エンゲージメントを促進しています。 ビッグデータは、ターゲットを絞った広告、パーソナライズされたマーケティング、製品の推奨、洞察の生成、価格の最適化、センチメント分析、予測分析などの基本的な要素です。
多くの場合、データは複数のソースから収集され、オンプレミスまたはクラウド上のデータ レイクで変換、保存、処理されます。 データの最初の取り込みは比較的簡単で、社内で開発されたカスタム スクリプトまたは従来の ETL (Extract Transform Load) ツールを使用して実現できますが、企業が次のことを行う必要があるため、問題はすぐに法外に複雑になり、解決するのに費用がかかります。
- データのライフサイクル全体を管理 – ハウスキーピングとコンプライアンスの目的で
- ストレージを最適化 – 関連コストを削減
- アーキテクチャの簡素化 – コンピューティング インフラストラクチャの再利用による
- 強力な状態管理により、データを段階的に処理
- 重複する作業なしに、バッチ データとストリーム データに同じポリシーを適用
- 最小限の労力でオンプレミスとクラウド間を移行
それはどこです アパッチゴブリン、オープンソースのデータ管理および統合システムが登場します。Apache Gobblin は、ビジネスのニーズに応じて全体または部分的に使用できる比類のない機能を提供します。
このセクションでは、前述の課題に対処するのに役立つ Apache Gobblin のさまざまな機能について詳しく説明します。
完全なデータ ライフサイクルの管理
Apache Gobblin は、データセットでのデータ ライフサイクル操作の完全なスイートをサポートするデータ パイプラインを構築するためのさまざまな機能を提供します。
- データの取り込み – データベース、Rest API、FTP/SFTP サーバー、ファイラー、Salesforce や Dynamics などの CRM など、複数のソースからシンクまで。
- Distcp-NG を介して、Hadoop 分散ファイル システムに特化した機能を備えた複数のデータ レイク間でデータをレプリケートします。
- データのパージ – 時間ベース、最新の K、バージョン管理、またはポリシーの組み合わせなどの保持ポリシーを使用します。
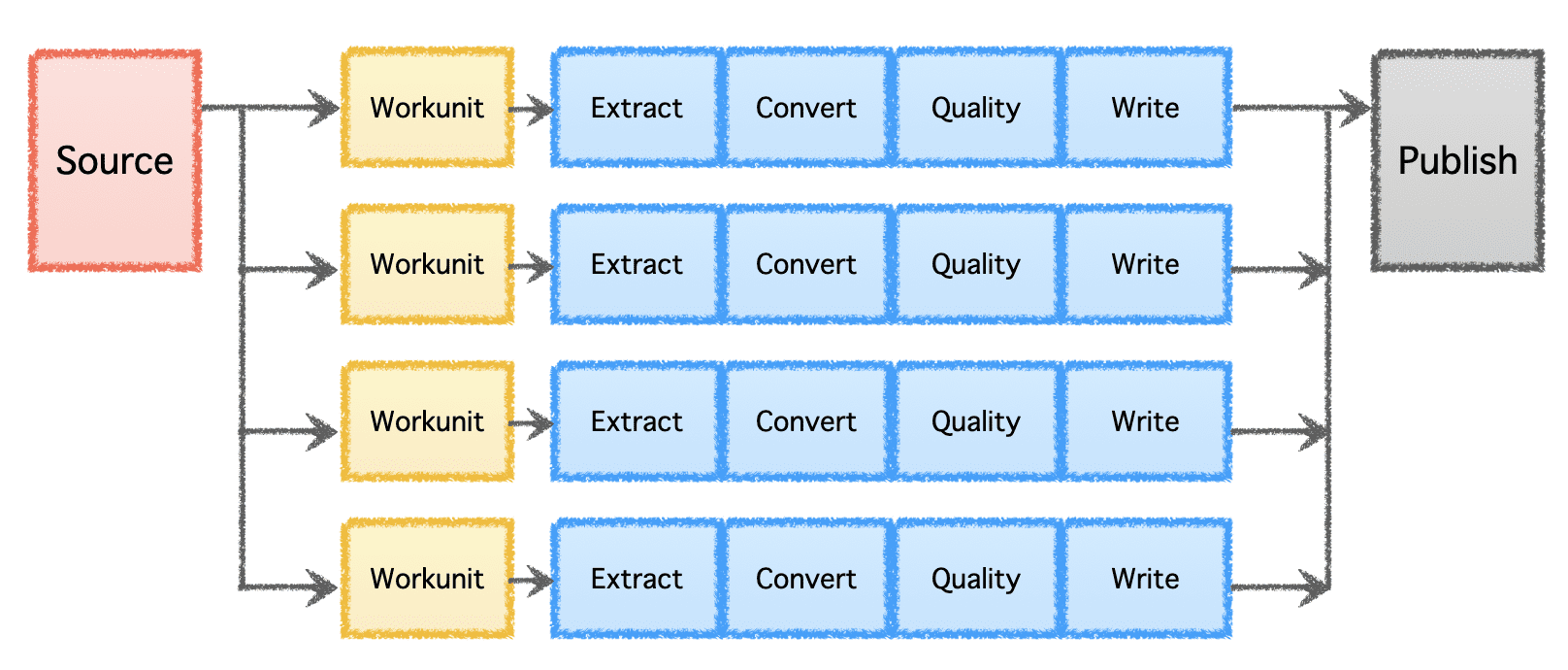
Gobblin の論理パイプラインは、作業の配分を決定し、「ワークユニット」を作成する「ソース」で構成されています。 これらの「ワークユニット」は、抽出、変換、品質チェック、宛先へのデータの書き込みを含む「タスク」として実行するために取得されます。 最後のステップである「データの公開」では、パイプラインが正常に実行されたことを検証し、宛先がサポートしている場合は、出力データをアトミックにコミットします。
著者による画像
ストレージを最適化する
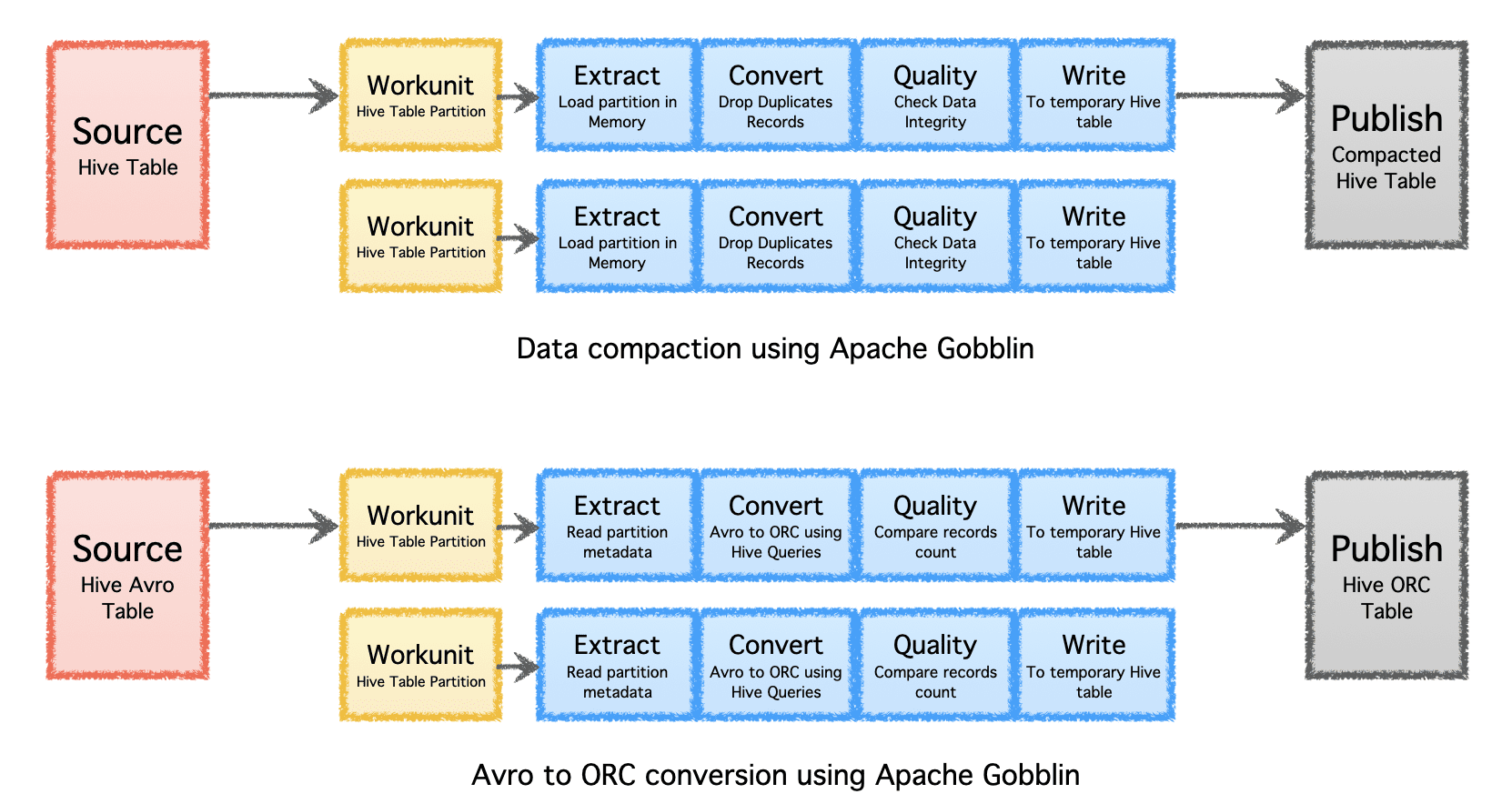
Apache Gobblin は、圧縮またはフォーマット変換による取り込みまたは複製後のデータの後処理を通じて、データに必要なストレージの量を削減するのに役立ちます。
- 圧縮 – レコードのすべてのフィールドまたはキー フィールドに基づいてデータを後処理して重複排除し、同じキーを持つ最新のタイムスタンプを持つレコードを XNUMX つだけ保持するようにデータをトリミングします。
- Avro から ORC へ - 一般的な行ベースの Avro 形式を超最適化された列ベースの ORC 形式に変換する特殊な形式変換メカニズムとして。
著者による画像
アーキテクチャを簡素化
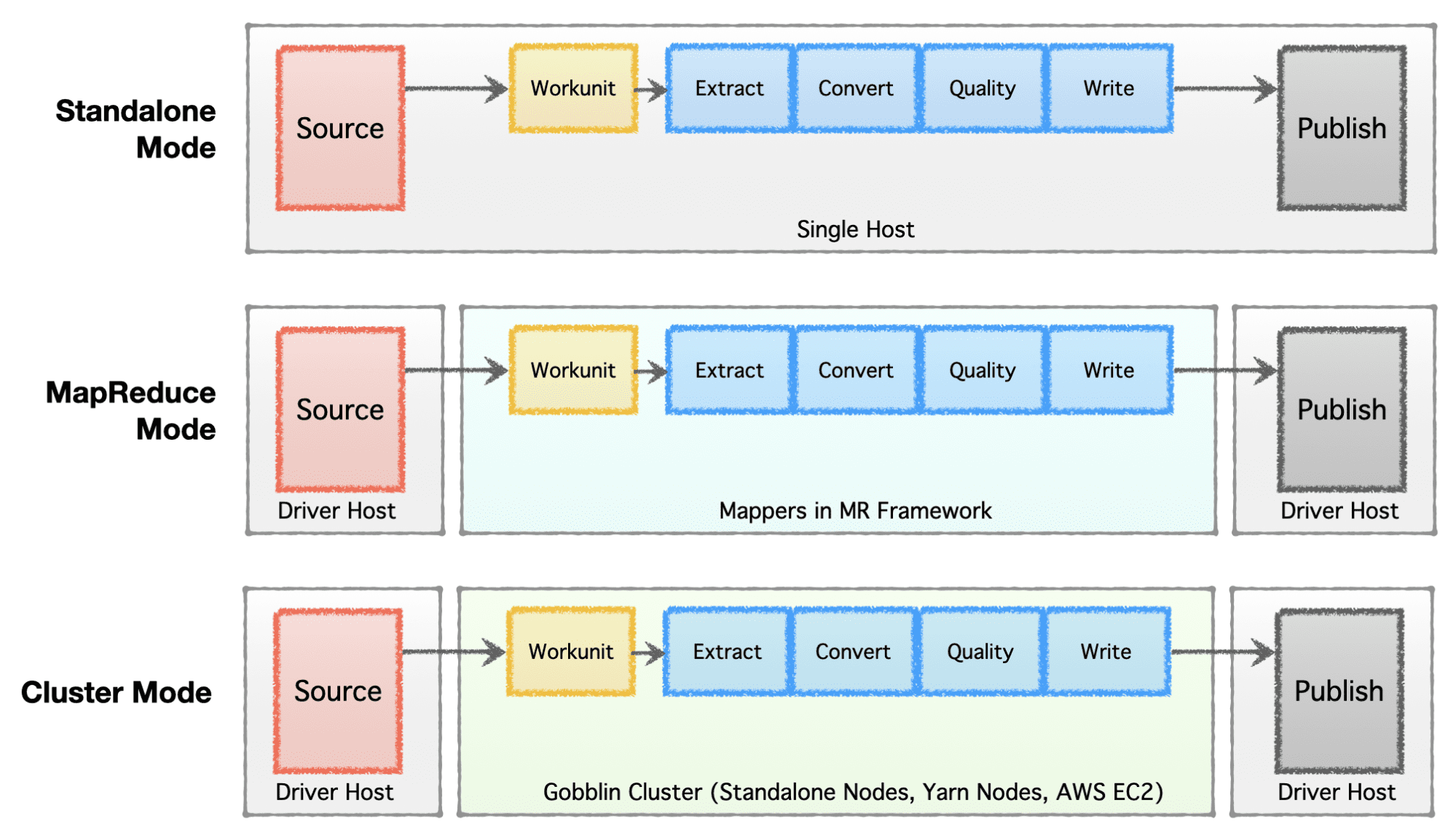
企業の段階 (スタートアップからエンタープライズまで)、規模の要件、およびそれぞれのアーキテクチャに応じて、企業はデータ インフラストラクチャをセットアップまたは進化させることを好みます。 Apache Gobblin は非常に柔軟で、複数の実行モデルをサポートしています。
- スタンドアロン モード – ベア メタル ボックスでスタンドアロン プロセスとして実行します。つまり、単純なユース ケースおよび要求の少ない状況向けの単一ホストです。
- MapReduce モード – ペタバイト規模の範囲のデータセットを処理するビッグ データ ケースの Hadoop インフラストラクチャで MapReduce ジョブとして実行します。
- クラスター モード: スタンドアロン – 一連のベア メタル マシンまたはホスト上で Apache Helix および Apache Zookeeper に支えられたクラスターとして実行し、Hadoop MR フレームワークから独立して大規模な処理を処理します。
- クラスター モード: Yarn – Hadoop MR フレームワークを使用せずに、ネイティブ Yarn でクラスターとして実行します。
- クラスター モード: AWS – Amazon のパブリック クラウド サービスでクラスターとして実行します。 AWS でホストされるインフラストラクチャ用の AWS。
著者による画像
データを段階的に処理する
複数のデータ パイプラインと大容量を伴う大規模なデータは、バッチで時間をかけて処理する必要があります。 そのため、データ パイプラインが前回中断したところから再開して先に進むことができるように、チェックポイントが必要です。 Apache Gobblin は、ロー ウォーターマークとハイ ウォーターマークをサポートし、HDFS、AWS S3、MySQL などのステート ストアを介して、より透過的に堅牢な状態管理セマンティクスをサポートします。
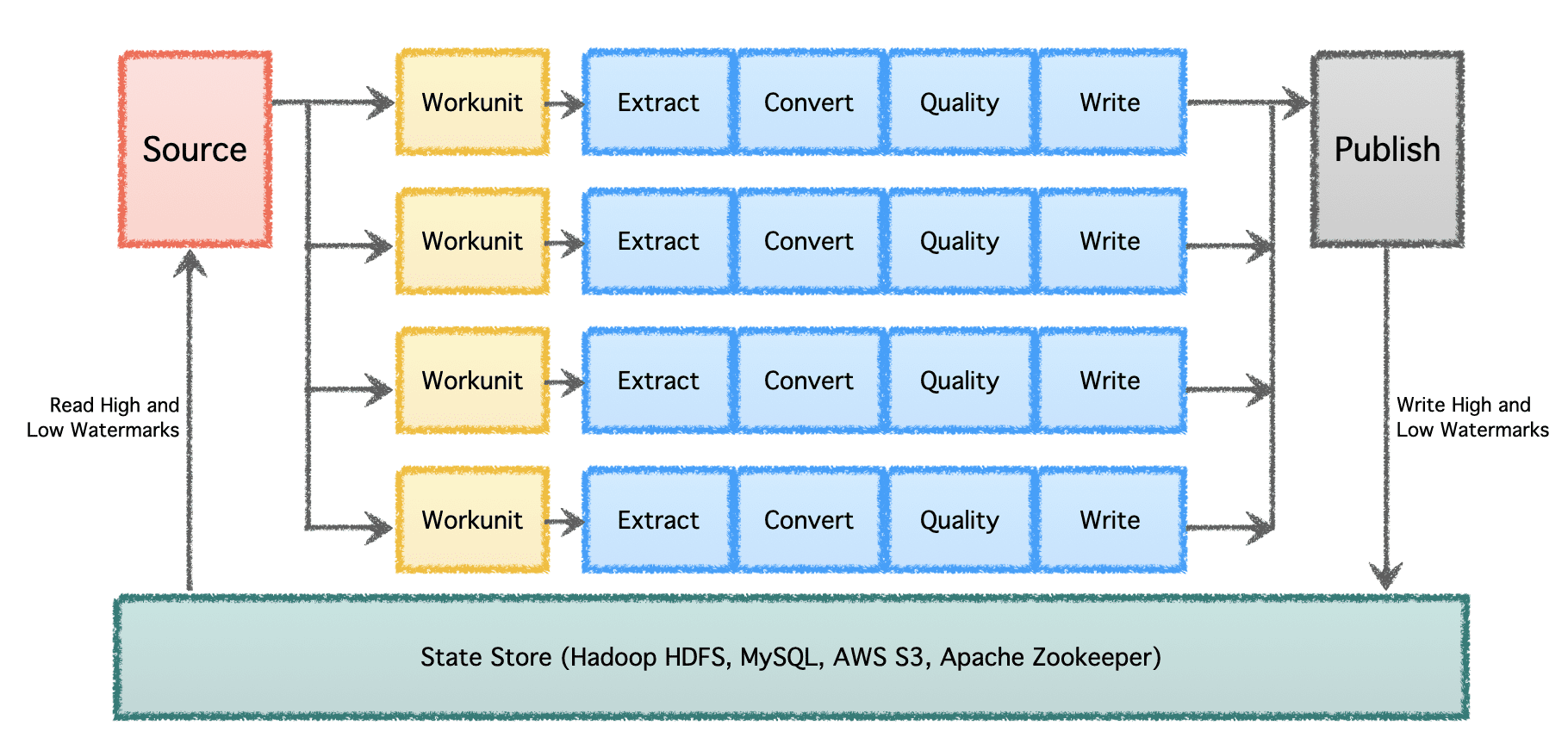
著者による画像
バッチ データとストリーム データに対する同じポリシー
今日のほとんどのデータ パイプラインは、バッチ データ用に XNUMX 回、ニアライン データまたはストリーミング データ用に XNUMX 回、XNUMX 回書き込む必要があります。 労力が XNUMX 倍になり、さまざまな種類のパイプラインに適用されるポリシーとアルゴリズムに矛盾が生じます。 Apache Gobblin は、Gobblin Cluster モード、Gobblin on AWS モード、または Gobblin on Yarn モードで使用されている場合、ユーザーがパイプラインを一度作成し、バッチ データとストリーム データの両方で実行できるようにすることで、これを解決します。
オンプレミスとクラウドの間で移行する
単一のボックス、ノードのクラスター、またはクラウドでオンプレミスで実行できる多目的モードにより、Apache Gobblin はオンプレミスとクラウドに展開して使用できます。 そのため、ユーザーはデータ パイプラインを一度作成すれば、特定のニーズに基づいて、オンプレミスとクラウドの間で簡単に Gobblin の展開と共にそれらを移行できます。
その非常に柔軟なアーキテクチャ、強力な機能、およびサポートおよび処理できるデータ ボリュームの極端なスケールにより、Apache Gobblin は、 大手テクノロジー企業 これは、今日のビッグ データ インフラストラクチャの展開に欠かせないものです。
Apache Gobblin とその使用方法の詳細については、次の Web サイトを参照してください。 https://gobblin.apache.org
アブヒシェク・ティワリ LinkedIn のシニア マネージャーであり、同社のビッグ データ パイプライン組織を率いています。 また、Apache Software Foundation の Apache Gobblin の副社長であり、British Computer Society のフェローでもあります。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- 達成
- アドレッシング
- 広告
- 後
- 援助
- アルゴリズム
- すべて
- 許可
- 量
- 分析
- 分析論
- および
- アパッチ
- API
- 適用された
- 建築
- 関連する
- 著者
- AWS
- 支持された
- ベース
- になる
- の間に
- ビッグ
- ビッグデータ
- ボックス
- 英国の
- ビジネス
- ビジネス
- 機能
- 例
- 課題
- 点検
- クラウド
- クラスタ
- 組み合わせ
- 企業
- 会社
- 複雑な
- コンプライアンス
- コンピュータ
- コンピューティング
- 定数
- 構築する
- 続ける
- 変換
- 変換
- 作成します。
- カスタム
- 顧客
- 顧客エンゲージメント
- データ
- データインフラストラクチャ
- データ管理
- データベースを追加しました
- データセット
- によっては
- 展開
- 展開
- 配備
- デスティネーション
- 細部
- 決定する
- 発展した
- 異なります
- 配布
- ディストリビューション
- ダイナミクス
- 簡単に
- 努力
- 婚約
- Enterprise
- エーテル(ETH)
- 進化
- 実行
- 高価な
- エキス
- 抽出
- 極端な
- 特徴
- 仲間
- フィールズ
- File
- ファイナル
- フレキシブル
- 形式でアーカイブしたプロジェクトを保存します.
- 発見
- Foundation
- フレームワーク
- から
- ガソリンタンク
- フル
- 世代
- 成長性
- Hadoopの
- ハンドル
- 助けます
- ハイ
- 非常に
- host
- 主催
- 認定条件
- How To
- HTTPS
- in
- include
- 独立しました
- インフラ
- インフラ
- 初期
- 洞察
- 統合
- 紹介します
- インベストメント
- IT
- ジョブ
- KDナゲット
- キープ
- キー
- 大
- 姓
- 最新の
- 主要な
- 負荷
- ロー
- マシン
- 管理
- マネージャー
- マーケティング
- メカニズム
- 金属
- 移動します
- モード
- モデル
- モダン
- モード
- 他には?
- 最も
- の試合に
- 持っている必要があります
- MySQL
- ネイティブ
- 必要とされる
- ニーズ
- 最新
- ノード
- 提供すること
- ONE
- オープンソース
- 業務執行統括
- 組織
- 概説
- 部品
- カスタマイズ
- ピックアップ
- パイプライン
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポリシー
- 人気
- 電力
- 強力な
- 予測分析
- 好む
- 社長
- 前に
- ブランド
- 問題
- プロセス
- プロダクト
- 生産
- は、大阪で
- 公共
- パブリッククラウド
- パブリッシュ
- 品質
- すぐに
- 測距
- 提言
- 記録
- 記録
- 減らします
- 相対的に
- レプリケーション
- 要件
- それらの
- REST
- 履歴書
- 保持
- 堅牢な
- ラン
- salesforce
- 同じ
- 規模
- スケーリング
- スクリプト
- セクション
- 意味論
- シニア
- 感情
- セッションに
- 重要
- 簡単な拡張で
- 状況
- So
- 社会
- ソフトウェア
- 解決する
- 解決する
- ソース
- ソース
- 専門の
- 特定の
- ステージ
- スタンドアロン
- スタートアップ
- 都道府県
- 手順
- ストレージ利用料
- 店舗
- 保存され
- 戦略的
- 流れ
- ストリーミング
- 成功した
- スイート
- サポート
- サポート
- 対象となります
- タスク
- テクノロジー
- アプリ環境に合わせて
- したがって、
- 介して
- 時間
- タイムスタンプ
- 〜へ
- 今日
- 豊富なツール群
- 伝統的な
- 最適化の適用
- 変換
- 根本的な
- 圧倒的な
- つかいます
- users
- さまざまな
- 多才な
- 、
- 副会長
- ボリューム
- ボリューム
- which
- while
- 意志
- 無し
- 仕事
- 世界
- 書きます
- 書き込み
- 書かれた
- ゼファーネット