ほぼすべての顧客と同様に、あなたも可能な限り最高のパフォーマンスを実現しながら、支出を最小限に抑えたいと考えています。 つまり、コストパフォーマンスに注意を払う必要があります。 と Amazonレッドシフト、ケーキを持って食べることもできます! Amazon Redshift は、数百人の同時ユーザーをサポートするための同時実行スケーリングや、クエリ パフォーマンスを高速化するための強化された文字列エンコーディングなどの高度な技術を使用して、実際のワークロードで他のクラウド データ ウェアハウスと比較して、ユーザーあたりのコストを最大 4.9 倍削減し、最大 7.9 倍優れた価格パフォーマンスを実現します。 、 そして AmazonRedshiftサーバーレス パフォーマンスの強化。 価格パフォーマンスが重要な理由と、Amazon Redshift の価格パフォーマンスが、特定のレベルのワークロードパフォーマンス、つまりパフォーマンス ROI (投資収益率) を得るのにかかる費用の尺度であることを理解するために読み続けてください。
価格とパフォーマンスの両方が価格パフォーマンスの計算に含まれるため、価格パフォーマンスについては 1 つの考え方があります。 1 つ目の方法は、価格を一定に保つことです。XNUMX ドルを使えるとしたら、データ ウェアハウスからどの程度のパフォーマンスが得られるでしょうか? 価格パフォーマンスの優れたデータベースは、支出した XNUMX ドルごとに優れたパフォーマンスを提供します。 したがって、同じ価格の XNUMX つのデータ ウェアハウスを比較するときに価格を一定に保った場合、価格パフォーマンスの高いデータベースのほうがクエリをより速く実行できます。. 価格とパフォーマンスを考える 10 番目の方法は、パフォーマンスを一定に保つことです。ワークロードを 10 分で終了する必要がある場合、それにかかる費用はいくらでしょうか? 価格パフォーマンスに優れたデータベースでは、ワークロードを低コストで XNUMX 分で実行できます。 したがって、同じパフォーマンスを実現するサイズの XNUMX つのデータ ウェアハウスを比較するときにパフォーマンスを一定に保つ場合、価格パフォーマンスの高いデータベースの方がコストが低くなり、コストが節約されます。
最後に、価格パフォーマンスのもう XNUMX つの重要な側面は、予測可能性です。 データ ウェアハウス ユーザーの数が増加するにつれて、データ ウェアハウスのコストがどれくらいかかるかを把握することは、計画を立てる上で非常に重要です。 現在最高のコスト パフォーマンスを提供するだけでなく、ユーザーやワークロードが追加されたときに予測どおりに拡張し、最高のコスト パフォーマンスを提供する必要があります。 理想的なデータ ウェアハウスには次のものがあります。 リニアスケール- データ ウェアハウスをスケーリングしてクエリ スループットを XNUMX 倍にするには、理想的にはコストが XNUMX 倍 (またはそれ以下) になるはずです。
この投稿では、Amazon Redshift が主要な代替クラウド データ ウェアハウスと比較して、どのようにコスト パフォーマンスが大幅に優れているかを説明するために、パフォーマンスの結果を共有します。 これは、他のデータ ウェアハウスに費やすのと同じ金額を Amazon Redshift に費やした場合、Amazon Redshift を使用した方がパフォーマンスが向上することを意味します。 あるいは、同じパフォーマンスを実現するように Redshift クラスターのサイズを調整すると、これらの代替手段と比較してコストが低くなります。
実際のワークロードに対する価格パフォーマンス
Amazon Redshift を使用すると、複雑な抽出、変換、ロード (ETL) ベースのレポートのバッチ処理から、リアルタイムのストリーミング分析から、低レイテンシーのビジネス インテリジェンス (BI) ダッシュボードまで、非常に多様なワークロードを強化できます。数百、さらには数千のユーザーに同時に XNUMX 秒未満の応答時間でサービスを提供する必要があります。 お客様の価格パフォーマンスを継続的に改善する方法の XNUMX つは、Redshift フリートからのソフトウェアおよびハードウェアのパフォーマンステレメトリーを常に確認し、Amazon Redshift のパフォーマンスをさらに向上できる機会とお客様のユースケースを探すことです。
フリート テレメトリによるパフォーマンス最適化の最近の例としては、次のようなものがあります。
- 文字列クエリの最適化 – Amazon Redshift が Redshift フリート内のさまざまなデータタイプをどのように処理したかを分析したところ、文字列を多く含むクエリを最適化すると、お客様のワークロードに大きなメリットがもたらされることがわかりました。 (これについては、この投稿の後半で詳しく説明します。)
- 自動化されたマテリアライズド ビュー – Amazon Redshift の顧客は、共通のサブクエリ パターンを持つ多くのクエリを実行することが多いことがわかりました。 たとえば、いくつかの異なるクエリが同じ結合条件を使用して同じ XNUMX つのテーブルを結合する場合があります。 Amazon Redshift は、マテリアライズド ビューを自動的に作成および維持し、機械学習されたクエリを使用してマテリアライズド ビューを使用するようにクエリを透過的に書き換えられるようになりました。 自動化されたマテリアライズド ビュー Amazon Redshift のオートノミクス機能。 自動マテリアライズド ビューを有効にすると、ユーザーの介入なしに、反復的なクエリのクエリ パフォーマンスを透過的に向上させることができます。 (自動マテリアライズド ビューは、この投稿で説明したどのベンチマーク結果にも使用されていないことに注意してください)。
- 同時実行性の高いワークロード – 増加しているユースケースは、Amazon Redshift を使用してダッシュボードのようなワークロードを提供することです。 これらのワークロードは、要求されるクエリ応答時間が XNUMX 桁秒以下であることが特徴で、数十から数百の同時ユーザーが、急激で予測不可能な使用パターンで同時にクエリを実行します。 この典型的な例は、Amazon Redshift を利用した BI ダッシュボードです。このダッシュボードでは、多くのユーザーが週を始める月曜の朝にトラフィックが急増します。
特に同時実行性の高いワークロードは非常に幅広い適用範囲を持っています。ほとんどのデータ ウェアハウス ワークロードは同時実行で動作し、数百、さらには数千のユーザーが Amazon Redshift で同時にクエリを実行することも珍しくありません。 Amazon Redshift は、クエリの応答時間を予測可能かつ高速に保つように設計されています。 Redshift Serverless は、クエリの応答時間を高速かつ予測可能に保つために、必要に応じてコンピューティングを追加および削除することでこれを自動的に実行します。 これは、XNUMX 人または XNUMX 人のユーザーがアクセスしているときに高速にロードされる Redshift サーバーレス ダッシュボードは、多くのユーザーが同時にロードしている場合でも引き続き高速にロードされることを意味します。
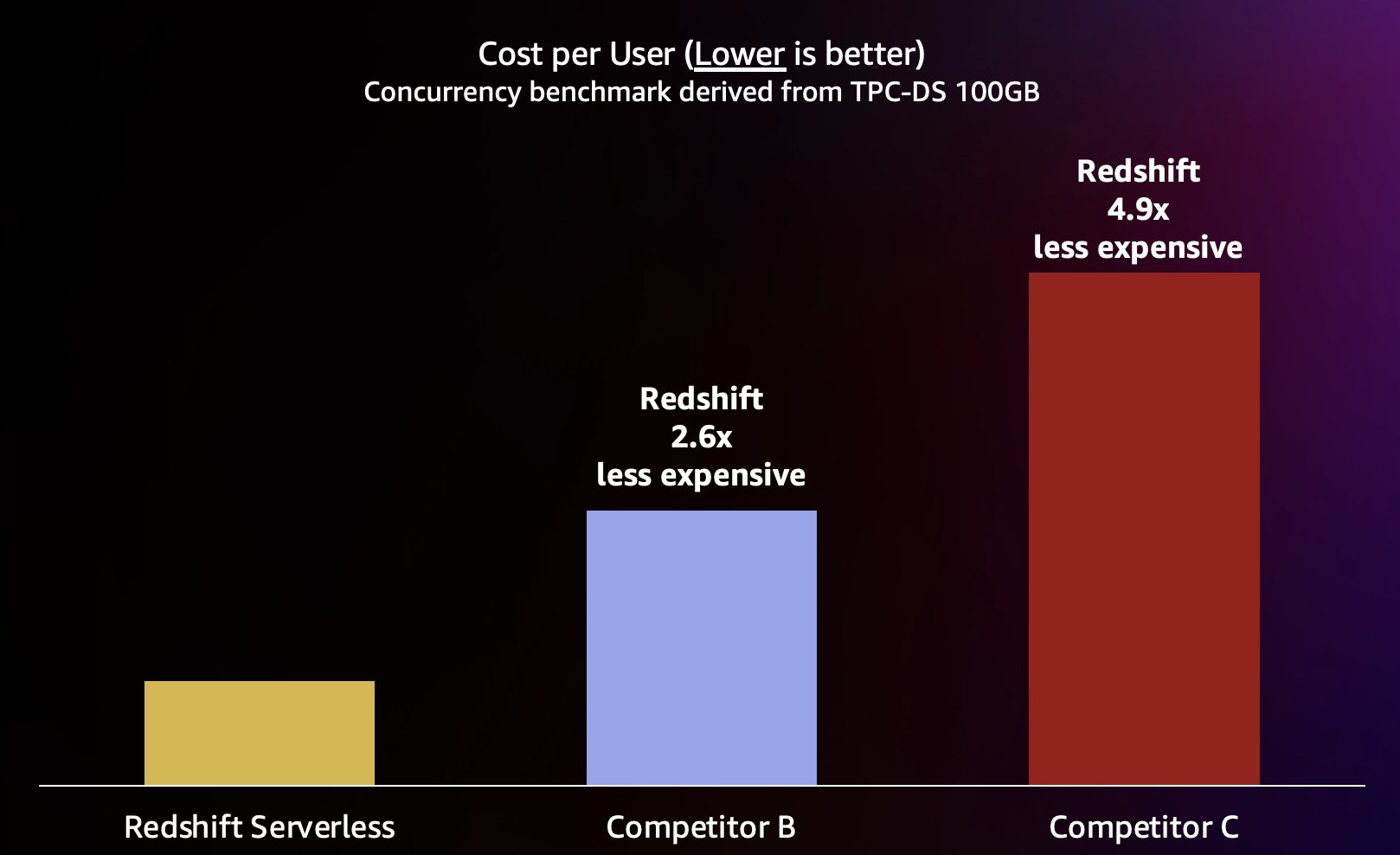
このタイプのワークロードをシミュレートするために、100 GB データ セットを使用した TPC-DS から派生したベンチマークを使用しました。 TPC-DS は、さまざまな典型的なデータ ウェアハウス クエリを含む業界標準のベンチマークです。 100 GB という比較的小規模なスケールでは、このベンチマークのクエリは Redshift Serverless 上で平均数秒で実行されます。これは、インタラクティブな BI ダッシュボードを読み込むユーザーが期待する速度を表しています。 このベンチマークでは 1 ~ 200 の同時テストを実行し、同時にダッシュボードをロードしようとする 1 ~ 200 人のユーザーをシミュレートしました。 また、自動的なスケールアウトもサポートする、いくつかの一般的な代替クラウド データ ウェアハウスに対してテストを繰り返しました (記事に詳しい方はこちら) Amazon Redshift は価格パフォーマンスのリーダーシップを維持します競合他社 A は自動スケールアップをサポートしていないため、含めませんでした)。 平均クエリ応答時間を測定しました。これは、ユーザーがクエリの完了 (またはダッシュボードの読み込み) を待つ時間を意味します。 結果を次のグラフに示します。
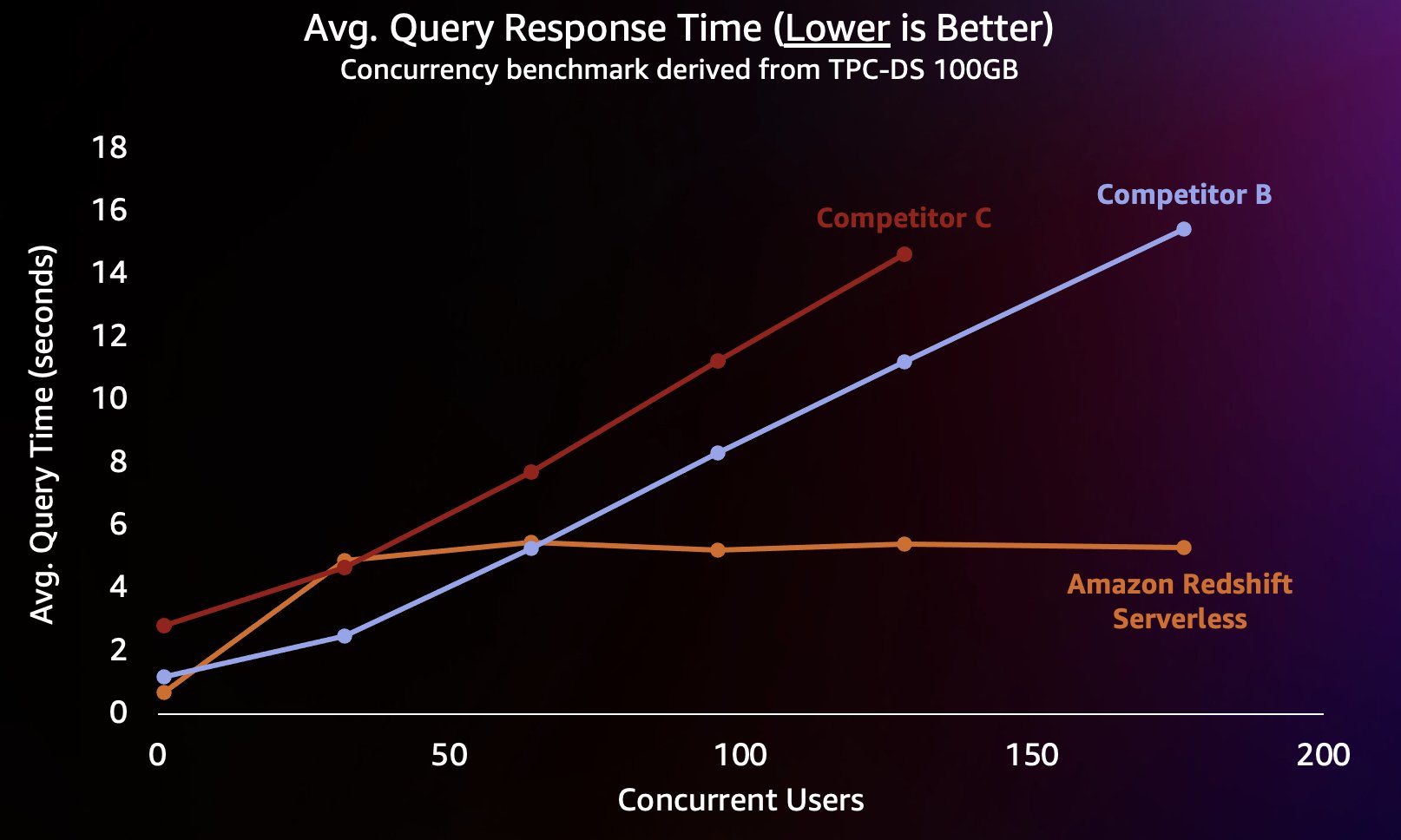
競合他社 B は、同時クエリ数が約 64 個になるまではうまく拡張できますが、その時点で追加のコンピューティングを提供できなくなり、クエリがキューに入り始め、クエリの応答時間の増加につながります。 競合他社 C は自動的にスケーリングできますが、Amazon Redshift や競合他社 B よりもクエリのスループットが低くなり、クエリのランタイムを低く保つことができません。 さらに、コンピューティングが不足した場合のクエリのキューイングはサポートされていないため、同時ユーザー数が約 128 人を超えて拡張することができません。 これを超えて追加のクエリを送信すると、システムによって拒否されます。
ここで、Redshift Serverless は、数百のユーザーが同時にクエリを実行している場合でも、クエリ応答時間を約 5 秒で比較的一定に保つことができます。 競合他社 B と競合他社 C の平均クエリ応答時間は、ウェアハウスの負荷が増加するにつれて確実に増加します。その結果、データ ウェアハウスがビジー状態になると、ユーザーはクエリが返されるまでより長く (最大 16 秒) 待たなければならなくなります。 これは、ユーザーがダッシュボードを更新しようとしている場合 (リロード時に複数の同時クエリを送信することもあります)、Amazon Redshift は、たとえダッシュボードが他の数十、数百ものものによって読み込まれている場合でも、ダッシュボードの読み込み時間をはるかに一貫した状態に保つことができることを意味します。ユーザーも同時に。
Amazon Redshift は短いクエリに対して非常に高いクエリ スループットを提供できるため (次の記事で説明したように) Amazon Redshift は価格パフォーマンスのリーダーシップを維持します)、より効率的にスケールアウトするときに、これらの高い同時実行性を処理することもできるため、コストが大幅に低くなります。 これを定量化するために、公開されているデータを使用して価格パフォーマンスを調べます。 オンデマンド価格設定 次のグラフに示すように、前のテストでの各倉庫の結果を示します。 使用することは注目に値します リザーブドインスタンス (RI)、特に全額前払いオプションで購入した 3 年間の RI は、プロビジョニングされたクラスターで Amazon Redshift を実行するコストが最も低く、オンデマンドまたは他の RI オプションと比較して相対的な価格パフォーマンスが最高になります。

したがって、Amazon Redshift は、より高い同時実行でより優れたパフォーマンスを提供できるだけでなく、大幅に低いコストでそれを実現できます。 価格パフォーマンス チャートの各データ ポイントは、指定された同時実行数でベンチマークを実行するコストに相当します。 価格パフォーマンスは線形であるため、任意の同時実行でベンチマークを実行するコストを同時実行数 (このグラフの同時ユーザー数) で割ることで、この特定のベンチマークで新しいユーザーを追加するたびにどれくらいのコストがかかるかを知ることができます。
前述の結果は簡単に再現できます。 ベンチマークで使用されたすべてのクエリは、 GitHubリポジトリ パフォーマンスは、データ ウェアハウスを起動し、Amazon Redshift で同時実行スケーリング (または他のウェアハウスの対応する自動スケーリング機能) を有効にし、すぐに使用できるデータをロードし (手動チューニングやデータベース固有のセットアップは不要)、その後、各データ ウェアハウスで 1 ~ 200 の同時実行数 (32 段階) でのクエリの同時ストリーム。 同じ GitHub リポジトリは、事前に生成された (および変更されていない) TPC-DS データを参照します。 Amazon シンプル ストレージ サービス 公式 TPC-DS データ生成キットを使用して、さまざまなスケールで (Amazon S3) を実行します。
文字列を多く使用するワークロードの最適化
前述したように、Amazon Redshift チームは、お客様にさらに優れたコストパフォーマンスを提供するための新しい機会を継続的に探しています。 パフォーマンスを大幅に向上させるために最近開始した改善の XNUMX つは、文字列データに対するクエリのパフォーマンスを高速化する最適化です。 たとえば、次のようなクエリを使用して、ニューヨーク市にある小売店から得られた総収益を確認するとします。 SELECT sum(price) FROM sales WHERE city = ‘New York’。 このクエリは文字列データに述語を適用しています (city = ‘New York’)。 ご想像のとおり、文字列データ処理はデータ ウェアハウス アプリケーションで広く使用されています。
顧客のワークロードが文字列にアクセスする頻度を定量化するために、Amazon Redshift が管理する数万の顧客クラスターのフリート テレメトリを使用して、文字列データ型の使用状況の詳細な分析を実施しました。 分析の結果、クラスターの 90% では文字列列が全列の少なくとも 30% を構成し、クラスターの 50% では文字列列が全列の少なくとも 50% を構成していることがわかりました。 さらに、Amazon Redshift クラウド データ ウェアハウス プラットフォームで実行されるすべてのクエリの大部分は、少なくとも XNUMX つの文字列列にアクセスします。 もう XNUMX つの重要な要素は、文字列データはカーディナリティが低いことが非常に多く、列に含まれる一意の値のセットが比較的小さいことを意味します。 たとえば、 orders 売上データを表すテーブルには数十億行が含まれる場合があります。 order_status そのテーブル内の列には、数十億の行にわたって少数の一意の値しか含まれていない可能性があります。 pending, in process, completed.
この記事の執筆時点では、Amazon Redshift のほとんどの文字列列は次の方法で圧縮されています。 LZO or ZSTD アルゴリズム。 これらは優れた汎用圧縮アルゴリズムですが、カーディナリティの低い文字列データを利用するように設計されていません。 特に、データを操作する前に解凍する必要があり、ハードウェア メモリ帯域幅の使用効率が低くなります。 カーディナリティの低いデータの場合、より最適化できる別のタイプのエンコードがあります。 バイトディクト。 このエンコードでは、辞書エンコード スキームが使用されており、データベース エンジンは圧縮データを最初に解凍する必要がなく、圧縮データに対して直接操作できます。
文字列の多いワークロードの価格パフォーマンスをさらに向上させるために、Amazon Redshift は現在、BYTEDICT としてエンコードされたカーディナリティの低い文字列列のスキャンと述語評価を 5 ~ 63 倍高速化する追加のパフォーマンス強化を導入しています (結果を参照)次のセクションを参照)、LZO や ZSTD などの代替圧縮エンコーディングと比較します。 Amazon Redshift は、軽量で CPU 効率が高く、BYTEDICT でエンコードされたカーディナリティの低い文字列列に対するスキャンをベクトル化することで、このパフォーマンスの向上を実現します。 これらの文字列処理の最適化により、最新のハードウェアが提供するメモリ帯域幅が効果的に利用され、文字列データのリアルタイム分析が可能になります。 これらの新しく導入されたパフォーマンス機能は、カーディナリティの低い文字列列 (最大数百の一意の文字列値) に最適です。
有効にすることで、この新しい高性能文字列の機能強化の恩恵を自動的に受けられます。 自動テーブル最適化 Amazon Redshift データウェアハウス内にあります。 テーブルで自動テーブル最適化が有効になっていない場合は、 Amazon Redshift アドバイザー Amazon Redshift コンソールで、文字列列の BYTEDICT エンコードへの適合性を確認します。 BYTEDICT エンコードを使用したカーディナリティの低い文字列列を持つ新しいテーブルを定義することもできます。 Amazon Redshift の文字列の拡張機能は、次のすべての AWS リージョンで利用できるようになりました。 Amazon Redshiftが利用可能になりました.
業績
文字列の強化によるパフォーマンスへの影響を測定するために、カーディナリティの低い文字列データで構成される 10 TB (テラバイト) データセットを生成しました。 Amazon Redshift フリート テレメトリからの文字列の長さの 25、50、および 75 パーセンタイルに対応する、短、中、長の文字列を使用して 90 つのバージョンのデータを生成しました。 このデータを Amazon Redshift に 50 回ロードし、1 回の場合は LZO 圧縮を使用し、もう XNUMX 回の場合は BYTEDICT 圧縮を使用してエンコードしました。 最後に、多くの行 (テーブルの XNUMX%)、中程度の行 (テーブルの XNUMX%)、および少数の行 (テーブルの XNUMX%) を返す、スキャンを多用するクエリのパフォーマンスを、これらの低パフォーマンスよりも測定しました。 -カーディナリティ文字列データセット。 パフォーマンス結果を次のグラフにまとめます。

この内部ベンチマークでは、高い割合の行に一致する述語を含むクエリでは、LZO と比較して新しいベクトル化 BYTEDICT エンコーディングで 5 ~ 30 倍の改善が見られましたが、低い割合の行に一致する述語によるクエリでは 10 ~ 63 倍の改善が見られました。
Redshiftサーバーレスの価格パフォーマンス
この投稿で示した高同時実行パフォーマンスの結果に加えて、TPC-DS 由来のクラウド データ ウェアハウス ベンチマークも使用して、Redshift Serverless の価格パフォーマンスを、より大きな 3 TB データセットを使用する他のデータ ウェアハウスと比較しました。 私たちは同様の価格設定のデータ ウェアハウスを選択しました。この場合、公開されているオンデマンド価格を使用すると、10 時間あたり 32 ドルの 3% 以内です。 これらの結果は、Amazon Redshift RAXNUMX インスタンスと同様に、Redshift Serverless が他の主要なクラウド データ ウェアハウスと比較して優れた価格パフォーマンスを実現していることを示しています。 いつものように、これらの結果は、SQL スクリプトを使用して複製できます。 GitHubリポジトリ.

独自の Amazon Redshift を試してみることをお勧めします。 概念実証 Amazon Redshift がデータ分析のニーズをどのように満たすかを確認する最良の方法として、ワークロードを確認してください。
ワークロードに最適なコストパフォーマンスを見つけてください
この投稿で使用されているベンチマークは、業界標準の TPC-DS ベンチマークから派生したもので、次の特徴があります。
- スキーマとデータは TPC-DS から変更されずに使用されます。
- クエリは、TPC-DS キットのデフォルトのランダム シードを使用して生成されたクエリ パラメーターを持つ公式 TPC-DS キットを使用して生成されます。 ウェアハウスがデフォルトの TPC-DS クエリの SQL 言語をサポートしていない場合、TPC 承認のクエリ バリアントがウェアハウスに使用されます。
- テストには 99 個の TPC-DS SELECT クエリが含まれます。 これには、メンテナンスとスループットの手順は含まれません。
- 単一の 3TB 同時実行テストでは、XNUMX 回の電力実行が実行され、データ ウェアハウスごとに最良の実行が採用されました。
- TPC-DS クエリの価格パフォーマンスは、時間あたりのコスト (USD) にベンチマークの実行時間 (時間単位) を掛けたものとして計算されます。これは、ベンチマークの実行コストに相当します。 最新の公開されたオンデマンド価格は、前述したようにリザーブド インスタンスの価格ではなく、すべてのデータ ウェアハウスに使用されます。
これをクラウド データ ウェアハウス ベンチマークと呼んでいます。当社のスクリプト、クエリ、データを使用して、前述のベンチマーク結果を簡単に再現できます。 GitHubリポジトリ。 この投稿で説明されているように、これは TPC-DS ベンチマークから導出されたものであり、テストの結果は公式仕様に準拠していないため、公開されている TPC-DS の結果と比較することはできません。
まとめ
Amazon Redshift は、さまざまなワークロードに対して業界最高のコストパフォーマンスを提供することに尽力しています。 Redshift Serverless は、最高 (最低) の価格パフォーマンスで直線的に拡張し、一貫したクエリ応答時間を維持しながら数百人の同時ユーザーをサポートします。 この投稿で説明したテスト結果に基づくと、Amazon Redshift は、最も近い競合他社 (競合 B) と比較して、同じレベルの同時実行で最大 2.6 倍優れた価格パフォーマンスを示します。 前述したように、3 年間全額前払いオプションでリザーブドインスタンスを使用すると、Amazon Redshift の実行コストが最も低くなり、この投稿で使用したオンデマンドインスタンスの価格と比較して、相対的なコストパフォーマンスがさらに向上します。 継続的なパフォーマンス向上に対する当社のアプローチには、顧客のユースケースとそれに関連するスケーラビリティのボトルネックを理解するという顧客のこだわりと、パフォーマンスを大幅に最適化する機会を特定するための継続的なフリートデータ分析を組み合わせた独自の組み合わせが含まれます。
各ワークロードには独自の特性があるため、始めたばかりの場合は、 概念実証 これは、Amazon Redshift がどのようにコストを削減しながらパフォーマンスを向上させるかを理解する最良の方法です。 独自の概念実証を実行する場合は、クエリ スループット (XNUMX 時間あたりのクエリ数)、応答時間、価格パフォーマンスなどの適切な指標に焦点を当てることが重要です。 独自に概念実証を実行するか、または 助けを借りて AWS または システムインテグレーションおよびコンサルティングパートナー.
Amazon Redshift の最新の開発状況を常に把握するには、次に従ってください。 Amazon Redshift の新機能 フィード。
著者について
 ステファン・グロモル Amazon Redshift チームのシニア パフォーマンス エンジニアであり、Redshift パフォーマンスの測定と改善を担当しています。 余暇には、料理をしたり、XNUMX 人の息子と遊んだり、薪を割ったりすることを楽しんでいます。
ステファン・グロモル Amazon Redshift チームのシニア パフォーマンス エンジニアであり、Redshift パフォーマンスの測定と改善を担当しています。 余暇には、料理をしたり、XNUMX 人の息子と遊んだり、薪を割ったりすることを楽しんでいます。
 ラヴィ・アニミ Amazon Redshift チームのシニアプロダクト管理リーダーであり、パフォーマンス、空間分析、ストリーミング取り込み、移行戦略など、Amazon Redshift クラウド データ ウェアハウス サービスのいくつかの機能領域を管理しています。 彼は、リレーショナル データベース、多次元データベース、IoT テクノロジ、ストレージおよびコンピューティング インフラストラクチャ サービスの経験があり、最近では AI/ディープ ラーニング、コンピュータ ビジョン、ロボティクスを使用するスタートアップの創設者としても活躍しています。
ラヴィ・アニミ Amazon Redshift チームのシニアプロダクト管理リーダーであり、パフォーマンス、空間分析、ストリーミング取り込み、移行戦略など、Amazon Redshift クラウド データ ウェアハウス サービスのいくつかの機能領域を管理しています。 彼は、リレーショナル データベース、多次元データベース、IoT テクノロジ、ストレージおよびコンピューティング インフラストラクチャ サービスの経験があり、最近では AI/ディープ ラーニング、コンピュータ ビジョン、ロボティクスを使用するスタートアップの創設者としても活躍しています。
 アーメル・シャー Amazon Redshift サービス チームのシニア エンジニアです。
アーメル・シャー Amazon Redshift サービス チームのシニア エンジニアです。
 サンケット・ハセ Amazon Redshift Service チームのソフトウェア開発マネージャーです。
サンケット・ハセ Amazon Redshift Service チームのソフトウェア開発マネージャーです。
 オレスティス・ポリクロニウ Amazon Redshift サービス チームの主任エンジニアです。
オレスティス・ポリクロニウ Amazon Redshift サービス チームの主任エンジニアです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :持っている
- :は
- :not
- :どこ
- $UP
- 10
- 100
- 16
- 32
- 7
- 9
- a
- できる
- 私たちについて
- 加速する
- アクセス
- アクセス
- 達成する
- 越えて
- 追加されました
- 追加
- 添加
- NEW
- 高度な
- 利点
- 与えられた
- に対して
- アルゴリズム
- すべて
- ことができます
- また
- 代替案
- 選択肢
- しかし
- 常に
- Amazon
- Amazon Webサービス
- 量
- an
- 分析
- 分析論
- 分析する
- および
- 別の
- どれか
- 適用
- アプローチ
- です
- エリア
- 周りに
- AS
- 側面
- 関連する
- At
- 注意
- オート
- 自動化
- オートマチック
- 自動的に
- 利用できます
- 平均
- AWS
- b
- 帯域幅
- ベース
- BE
- なぜなら
- 始まる
- さ
- ベンチマーク
- ベンチマーク
- 恩恵
- BEST
- より良いです
- の間に
- 越えて
- 億
- 両言語で
- ボトルネック
- ボックス
- 持って来る
- 広い
- ビジネス
- ビジネス・インテリジェンス
- 忙しい
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- CAKE
- 計算された
- 計算
- コール
- 缶
- 機能
- 場合
- 例
- 特性
- 特徴付けられた
- チャート
- チョッピング
- 選んだ
- 市町村
- クラウド
- クラスタ
- コラム
- コラム
- 組み合わせ
- コミットした
- コマンドと
- 匹敵します
- 比較します
- 比べ
- 比較
- 競合他社
- 競合他社
- 複雑な
- 従う
- 計算
- コンピュータ
- Computer Vision
- コンセプト
- 同時
- 条件
- 実施
- 整合性のある
- 領事
- 定数
- 絶えず
- 構成します
- コンサルティング
- 含む
- 継続的に
- 続ける
- 続ける
- 連続的な
- 連続的に
- 料理
- 対応する
- 費用
- コスト
- 結合しました
- 作ります
- 重大な
- 顧客
- Customers
- ダッシュボード
- ダッシュボード
- データ
- データ分析
- データ分析
- データ処理
- データセット
- データウェアハウス
- データウェアハウス
- データ駆動型の
- データベース
- データベースを追加しました
- データセット
- 日付
- 決定
- デフォルト
- 定義します
- 配信する
- 配信する
- 提供します
- 派生
- 記載された
- 設計
- 希望
- 詳細
- 詳細な
- 開発
- 進展
- 異なります
- 直接に
- 話し合います
- 議論する
- 多様性
- 分割
- do
- ありません
- そうではありません
- ドント
- ドリブン
- 各
- 前
- 簡単に
- 食べる
- 効果的な
- 効率的な
- 効率良く
- 使用可能
- 有効にする
- 奨励する
- エンジン
- エンジニア
- 強化された
- 強化
- 強化
- 入力します
- 同等の
- 特に
- エーテル(ETH)
- 評価
- さらに
- すべてのもの
- 例
- 例
- 期待する
- 体験
- エキス
- 要因
- おなじみの
- 遠く
- スピーディー
- 速いです
- 特徴
- 少数の
- 最後に
- もう完成させ、ワークスペースに掲示しましたか?
- 仕上げ
- 名
- 艦隊
- フォーカス
- フォロー中
- 発見
- AIとMoku
- から
- 機能的な
- さらに
- 一般的用途
- 生成された
- 世代
- 取得する
- 受け
- GitHubの
- 与える
- 行く
- 良い
- 成長
- 育ちます
- ハンドル
- Hardware
- 持ってる
- 持って
- he
- ハイ
- より高い
- 彼の
- 開催
- 時間
- HOURS
- 認定条件
- HTML
- HTTP
- HTTPS
- 百
- 何百
- 理想
- 理想的には
- 識別する
- if
- 説明します
- 絵
- 影響
- 重要
- 重要な側面
- 改善します
- 改善されました
- 改善
- 改善
- 改善
- in
- include
- 含ま
- 含めて
- 増える
- 増加した
- 増加
- を示し
- 業界の
- インフラ関連事業
- インスタンス
- 統合
- インテリジェンス
- 相互作用的
- 内部
- 介入
- に
- 導入
- 導入
- 投資
- 関与
- IOT
- IT
- ITS
- join
- JPG
- ただ
- キープ
- キット
- 知っている
- 大
- より大きい
- 後で
- 最新の
- 最新の開発
- 打ち上げ
- 発射
- リーダー
- 主要な
- 学習
- 最低
- less
- レベル
- 軽量
- ような
- 少し
- 負荷
- ローディング
- 負荷
- 位置して
- 長い
- より長いです
- 見て
- 探して
- ロー
- 下側
- 最低
- 維持する
- 保守
- メンテナンス
- 大多数
- make
- マネージド
- 管理
- マネージャー
- 管理する
- マニュアル
- 多くの
- 一致
- 事態
- 五月..
- 意味
- 手段
- だけど
- 測定された
- 計測
- ミディアム
- 大会
- メモリ
- 言及した
- かもしれない
- 移行
- 分
- モダン
- 月曜日
- お金
- 他には?
- さらに
- 最も
- ずっと
- すなわち
- 必要
- 必要とされる
- ニーズ
- 新作
- ニューヨーク
- ニューヨーク市
- 新しく
- 次の
- いいえ
- 注意
- 注意
- 注記
- 今
- 数
- of
- 公式
- 頻繁に
- on
- オンデマンド
- ONE
- の
- 操作する
- 運営
- 機会
- 最適な
- 最適化
- 最適化
- オプション
- オプション
- or
- その他
- 私たちの
- でる
- が
- 自分の
- パラメータ
- 特定の
- パターン
- パターン
- 支払う
- 支払い
- 以下のために
- 割合
- パフォーマンス
- 計画
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 再生
- ポイント
- 人気
- 可能
- ポスト
- 電力
- 予測可能な
- PLM platform.
- を防止
- ブランド
- 価格設定
- 校長
- 処理されました
- 処理
- プロダクト
- 製品管理
- 証明
- 概念実証
- 提供します
- 公然と
- 公表
- 購入した
- クエリ
- すぐに
- ランダム
- 読む
- 現実の世界
- への
- 受け取ります
- 最近
- 最近
- 提言
- リファレンス
- 地域
- 拒否されました..
- 相対
- 相対的に
- 除去
- 繰り返される
- 反復的な
- 複製された
- レポート
- 代表者
- 表します
- 必要とする
- 予約済み
- 応答
- 責任
- 結果として
- 結果
- 小売
- return
- 収入
- レビュー
- 右
- ロボット工学
- ROI
- ラン
- ランニング
- runs
- セールス
- 同じ
- Save
- 見ました
- スケーラビリティ
- 規模
- 秤
- スケーリング
- スキャン
- スキーム
- スクリプト
- 二番
- 秒
- セクション
- シード
- シニア
- 役立つ
- サーバレス
- サービス
- サービス
- セッションに
- いくつかの
- シェアする
- ショート
- すべき
- 表示する
- 示す
- 重要
- 著しく
- 同様に
- 簡単な拡張で
- 同時に
- サイズ
- 大きさの
- 小さい
- So
- ソフトウェア
- ソフトウェア開発
- 空間の
- 仕様
- 指定の
- スピード
- 過ごす
- 費やした
- スパイク
- SQL
- start
- 開始
- スタートアップ
- 滞在
- 着実に
- ステップ
- ストレージ利用料
- 店舗
- 簡単な
- 作戦
- 流れ
- ストリーミング
- 文字列
- 提出する
- そのような
- 適合性
- サポート
- 支援する
- テーブル
- 取る
- 撮影
- チーム
- テクニック
- テクノロジー
- 言う
- 十
- test
- テスト
- より
- それ
- アプリ環境に合わせて
- その後
- そこ。
- したがって、
- ボーマン
- 彼ら
- 考える
- この
- それらの
- 数千
- 三
- スループット
- 時間
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- 今日
- トータル
- トラフィック
- 最適化の適用
- 透明に
- 試します
- しよう
- Twice
- 2
- type
- 典型的な
- 遍在する
- できません
- アンコモン
- わかる
- ユニーク
- 予測できない
- まで
- us
- 使用法
- USD
- つかいます
- 使用事例
- 中古
- ユーザー
- users
- 使用されます
- 価値観
- 多様
- さまざまな
- 非常に
- ビュー
- 事実上
- ビジョン
- wait
- 欲しいです
- 倉庫
- ました
- 仕方..
- 方法
- we
- ウェブ
- Webサービス
- 週間
- WELL
- した
- この試験は
- いつ
- 一方
- which
- while
- なぜ
- ワイド
- 意志
- 以内
- 無し
- 価値
- でしょう
- 書き込み
- 書いた
- ヨーク
- 貴社
- あなたの
- ゼファーネット