著者による画像
ランダム フォレストなどの多くの高度な機械学習モデルや、XGBoost、CatBoost、LightGBM などの勾配ブースティング アルゴリズム (さらには オートエンコーダ!) 重要な共通要素に依存しています: 決定木!
決定木を理解しないと、前述の高度なバギングや勾配ブースティングのアルゴリズムを理解することは不可能です。これは、データ サイエンティストにとって恥ずべきことです。 それでは、Python で決定木を実装することによって、決定木の内部の仕組みを分かりやすく説明しましょう。
この記事では、
- 決定木がデータを分割する理由と方法
- 情報取得、および
- NumPy を使用して Python で決定木を実装する方法。
あなたはでコードを見つけることができます 私のGithub.
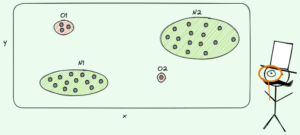
予測を行うために、決定木は以下に依存します 分裂 データセットを再帰的に小さな部分に分割します。

著者による画像
上の図では、分割の一例を見ることができます — 元のデータセットが XNUMX つの部分に分割されます。 次のステップでは、これらの両方の部分が再び分割されます。 これは、ある種の停止基準が満たされるまで続きます。たとえば、
- 分割の結果、パーツが空になった場合
- 特定の再帰深度に達した場合
- (以前の分割の後) データセットが少数の要素のみで構成されている場合、それ以上の分割は不要になります。
これらの分割をどのように見つけますか? そして、なぜ私たちは気にするのですか? 確認してみましょう。
動機
を解決したいと仮定しましょう バイナリ 分類問題 私たちが今自分自身を作成すること:
import numpy as np
np.random.seed(0) X = np.random.randn(100, 2) # features
y = ((X[:, 0] > 0) * (X[:, 1] < 0)) # labels (0 and 1)XNUMX 次元データは次のようになります。

著者による画像
ケースの約 75% が紫、約 25% が黄色の XNUMX つの異なるクラスがあることがわかります。 このデータを決定木にフィードすると 分類します、このツリーには当初、次のような考えがあります。
「XNUMX つの異なるラベルがありますが、これは私には面倒です。 データを XNUMX つの部分に分割して、この混乱を解消したいと考えています。これらの部分は、以前の完全なデータよりもきれいなはずです。」 — 意識を得た木
木もそうです。

著者による画像
ツリーは、ほぼに沿って分割することを決定します。 x-軸。 これにより、データの上部が完全に 掃除、 あなただけが見つけることを意味します 単一のクラス (この場合は紫)あります。
ただし下の部分はそのまま 乱雑な、ある意味で以前よりもさらに厄介です。 クラスの比率は、完全なデータセットでは約 75:25 でしたが、この小さな部分では約 50:50 であり、可能な限り混同されています。
注: ここでは、紫と黄色がきれいに分離されていてもかまいません。 ただ さまざまなラベルの生の量 XNUMXつの部分で数えます。

著者による画像
それでも、これはツリーの最初のステップとしては十分であり、継続します。 上部に別の分割を作成することはありませんが、 部分がなくなったら、下部に別の分割を作成してきれいにすることができます。

著者による画像
ほら、パーツごとに XNUMX つの色 (ラベル) しか見つからないため、XNUMX つの別々のパーツのそれぞれは完全にクリーンです。
現在、予測を行うのは非常に簡単です。新しいデータ ポイントが入ってきたら、どのデータ ポイントをチェックインするかだけです。 三部 それは嘘をつき、それに対応する色を与えます。 各部分が 。 簡単ですよね?

著者による画像
さて、私たちは話していました および 乱雑な しかし、これまでのところ、これらの単語は漠然とした考えを表しているにすぎません。 何かを実装するには、定義する方法を見つける必要があります 清浄度.
清潔への取り組み
たとえば、いくつかのラベルがあるとします。
y_1 = [0, 0, 0, 0, 0, 0, 0, 0] y_2 = [1, 0, 0, 0, 0, 0, 1, 0]
y_3 = [1, 0, 1, 1, 0, 0, 1, 0]直感的に、 y₁ は最もクリーンなラベルのセットであり、その後に y₂ その後 y₃. ここまでは順調ですが、この動作をどのように数値化できるのでしょうか? おそらく、頭に浮かぶ最も簡単なことは次のとおりです。
ゼロの数と XNUMX の数を数えるだけです。 それらの絶対差を計算します。 より良いものにするために、配列の長さで割って正規化します。
たとえば、 y₂ 合計で 8 つのエントリがあります — 6 が 2 つと XNUMX が XNUMX つです。 したがって、カスタム定義された 清潔度スコア |6 – 2| になります。 / 8 = 0.5。 の清潔度スコアを計算するのは簡単です。 y₁ および y₃ はそれぞれ 1.0 と 0.0 です。 ここで、一般式を見ることができます。

著者による画像
ここでは、 n₀ および n₁ はそれぞれゼロと XNUMX の数です。 n = n₀ + n₁ は配列の長さであり、 p₁ = n₁ / n 1 ラベルのシェアです。
この式の問題点は、 XNUMX つのクラスの場合に特に合わせた、しかし非常に多くの場合、多クラス分類に関心があります。 非常にうまく機能するXNUMXつの式は、 ジニ不純物測定:

著者による画像
または一般的なケース:

著者による画像
scikit-learn が非常にうまく機能する それをデフォルトの措置として採用した そのための DecisionTreeClassifier とに提供されます。

著者による画像
注: ジニ対策 乱雑 清潔さの代わりに。 例: リストに 1 つのクラスしか含まれていない場合 (= 非常にクリーンなデータ!)、合計のすべての項がゼロであるため、合計はゼロです。 最悪のケースは、すべてのクラスが正確な回数出現する場合です。この場合、Gini は 1–XNUMX/C コラボレー C クラス数です。
清潔さ/乱雑さの測定値が得られたので、それを使用して適切な分割を見つける方法を見てみましょう.
分割を見つける
たくさんのスプリットがありますが、どれが良いですか? 最初のデータセットを、ジニ不純物測定値と一緒にもう一度使用してみましょう。

著者による画像
ここではポイントをカウントしませんが、75% が紫で 25% が黄色であると仮定しましょう。 ジニの定義を使用すると、完全なデータセットの不純物は次のようになります。

著者による画像
に沿ってデータセットを分割すると、 x-軸、前に行ったように:

著者による画像
上部のジニ不純物は 0.0 です そして下の部分

著者による画像
平均して、0.0 つの部分のジニ不純物は (0.5 + 2) / 0.25 = 0.375 であり、以前のデータセット全体の XNUMX よりも優れています。 いわゆる言葉で表現することもできます。 情報獲得:
この分割の情報ゲインは 0.375 – 0.25 = 0.125 です。
そのように簡単です。 情報利得が高ければ高いほど (つまり、ジニ不純物が低ければ低いほど)、良い結果が得られます。
注: 別の同様に適切な初期分割は、y 軸に沿ったものです。
心に留めておくべき重要なことは、 パーツのジニ不純物をパーツのサイズで量る. たとえば、
- パート 1 は 50 個のデータポイントで構成され、ジニ不純物が 0.0 であり、
- パート 2 は 450 のデータポイントで構成され、ジニ不純物は 0.5 です。
その場合、ジニ不純物の平均値は (0.0 + 0.5) / 2 = 0.25 ではなく、50 / (50 + 450) * 0.0 + 450 / (50 + 450) * 0.5 = になります。 0.45.
では、どうすれば最適な分割を見つけることができるでしょうか? シンプルだが冷静な答えは次のとおりです。
すべての分割を試して、情報利得が最も高いものを選択してください。 基本的に強引なアプローチです。
より正確に言うと、標準の決定木は次を使用します。 座標軸に沿って分割しますすなわち、 xᵢ = c いくつかの機能のために i およびしきい値 c. これは、
- 分割データの一部は、すべてのデータ ポイントで構成されます x xᵢcおよび
- すべてのポイントの他の部分 x xᵢ ≥ c.
これらの単純な分割ルールは実際には十分に優れていることが証明されていますが、もちろんこのロジックを拡張して他の分割を作成することもできます (つまり、次のような対角線 xᵢ + 2xⱼ = 3、 例えば)。
よし、これで準備が整いました!
ここで決定木を実装します。 ノードで構成されているため、 Node クラスファースト。
from dataclasses import dataclass @dataclass
class Node: feature: int = None # feature for the split value: float = None # split threshold OR final prediction left: np.array = None # store one part of the data right: np.array = None # store the other part of the dataノードは、分割に使用する機能を認識しています (feature) と分割値 (value). value 決定木の最終予測のストレージとしても使用されます。 二分木を構築するので、各ノードは、その左と右の子を、 left および right .
それでは、実際のデシジョン ツリーの実装を行いましょう。 私はそれをscikit-learn互換にしているので、いくつかのクラスを使用しています sklearn.base . よくわからない場合は、私の記事をチェックしてください scikit-learn 互換モデルの構築方法.
実装しよう!
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin class DecisionTreeClassifier(BaseEstimator, ClassifierMixin): def __init__(self): self.root = Node() @staticmethod def _gini(y): """Gini impurity.""" counts = np.bincount(y) p = counts / counts.sum() return (p * (1 - p)).sum() def _split(self, X, y): """Bruteforce search over all features and splitting points.""" best_information_gain = float("-inf") best_feature = None best_split = None for feature in range(X.shape[1]): split_candidates = np.unique(X[:, feature]) for split in split_candidates: left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] information_gain = self._gini(y) - ( len(X_left) / len(X) * self._gini(y_left) + len(X_right) / len(X) * self._gini(y_right) ) if information_gain > best_information_gain: best_information_gain = information_gain best_feature = feature best_split = split return best_feature, best_split def _build_tree(self, X, y): """The heavy lifting.""" feature, split = self._split(X, y) left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] if len(X_left) == 0 or len(X_right) == 0: return Node(value=np.argmax(np.bincount(y))) else: return Node( feature, split, self._build_tree(X_left, y_left), self._build_tree(X_right, y_right), ) def _find_path(self, x, node): """Given a data point x, walk from the root to the corresponding leaf node. Output its value.""" if node.feature == None: return node.value else: if x[node.feature] node.value: return self._find_path(x, node.left) else: return self._find_path(x, node.right) def fit(self, X, y): self.root = self._build_tree(X, y) return self def predict(self, X): return np.array([self._find_path(x, self.root) for x in X])以上です! scikit-learn で好きなことをすべて今すぐ実行できます。
dt = DecisionTreeClassifier().fit(X, y)
print(dt.score(X, y)) # accuracy # Output
# 1.0ツリーは正則化されていないため、過剰適合が多く、完全なトレイン スコアです。 目に見えないデータでは精度が低下します。 ツリーがどのように見えるかを確認することもできます
print(dt.root) # Output (prettified manually):
# Node(
# feature=1,
# value=-0.14963454032767076,
# left=Node(
# feature=0,
# value=0.04575851730144607,
# left=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# ),
# right=Node(
# feature=None,
# value=1,
# left=None,
# right=None
# )
# ),
# right=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# )
# )イメージとしては、次のようになります。

著者による画像
この記事では、決定木がどのように機能するかを詳しく見てきました。 私たちは漠然とした直感的なアイデアから始め、それらを数式とアルゴリズムに変えました。 最終的に、決定木をゼロから実装することができました。
ただし注意が必要です。決定木はまだ正則化できません。 通常、次のようなパラメータを指定します
- 最大深度
- 葉の大きさ
- 最小限の情報取得
他の多くの中で。 幸いなことに、これらのことを実装するのはそれほど難しくないので、これはあなたにとって完璧な宿題になります. たとえば、次のように指定すると leaf_size=10 パラメータとして、10 個を超えるサンプルを含むノードは分割されません。 また、この実装は 効率的ではありません. 通常、データセットの一部をノードに格納するのではなく、代わりにインデックスのみを格納します。 したがって、(潜在的に大きい) データセットはメモリ内に XNUMX 回だけ存在します。
良いことは、この意思決定ツリー テンプレートを使用して夢中になれることです。 あなたはできる:
- 対角分割を実装する、つまり xᵢ + 2xⱼ = 3 ただの代わりに xᵢ = 3、
- リーフ内で発生するロジックを変更します。つまり、単に多数決を行う代わりに、各リーフ内でロジスティック回帰を実行できます。 線形ツリー
- 分割手順を変更します。つまり、ブルートフォースを行う代わりに、ランダムな組み合わせをいくつか試して、最適なものを選択します。 エクストラツリー分類器
- 等です。
ロバート・キューブラー博士 Publicis Mediaのデータサイエンティストであり、Towards DataScienceの著者です。
元の。 許可を得て転載。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/02/understanding-implementing-decision-tree.html?utm_source=rss&utm_medium=rss&utm_campaign=understanding-by-implementing-decision-tree
- 1
- 10
- 100
- 11
- 28
- 7
- 9
- a
- できる
- 私たちについて
- 上記の.
- 絶対の
- 精度
- 高度な
- 後
- アルゴリズム
- すべて
- 量
- および
- 別の
- 回答
- 現れる
- アプローチ
- 約
- 周りに
- 配列
- 記事
- 著者
- 平均
- ベース
- 基本的に
- なぜなら
- さ
- BEST
- より良いです
- 後押し
- ボトム
- 強引な
- ビルド
- これ
- 場合
- 例
- 一定
- チェック
- 子供達
- 選択する
- class
- クラス
- 分類
- コード
- カラー
- 組み合わせ
- コマンドと
- 互換性のあります
- コンプリート
- 完全に
- 計算
- 意識
- 続ける
- 調整する
- 対応する
- ここから
- 作ります
- 重大な
- データ
- データサイエンス
- データサイエンティスト
- データセット
- 決定
- 決定木
- デフォルト
- 深さ
- 詳細
- 違い
- 異なります
- 難しい
- そうではありません
- すること
- 各
- 最も簡単
- 効果
- 要素は
- 十分な
- 全体
- 平等に
- エーテル(ETH)
- さらに
- 例
- 表現します
- 伸ばす
- おなじみの
- ファッション
- 特徴
- 特徴
- 少数の
- ファイナル
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- フロート
- 続いて
- フォロー中
- 強
- 式
- から
- さらに
- 利得
- 取得する
- ジニ
- 与える
- 与えられた
- 与える
- Go
- 行く
- 良い
- 起こります
- こちら
- より高い
- 最高
- 宿題
- 認定条件
- HTML
- HTTPS
- アイデア
- 考え
- 実装する
- 実装
- 実装
- import
- 重要
- 不可能
- in
- 索引
- 情報
- 初期
- 当初
- を取得する必要がある者
- 興味がある
- 直観的な
- IT
- KDナゲット
- キープ
- 種類
- 知っている
- ラベル
- ラベル
- 大
- 学習
- 長さ
- フェイスリフト
- ライン
- リスト
- LOOKS
- たくさん
- 愛
- 機械
- 機械学習
- 大多数
- make
- 作る
- 作成
- 手動で
- 多くの
- 問題
- 手段
- だけど
- メディア
- メモリ
- マインド
- 最小限の
- 混合
- モデル
- 他には?
- 必要
- ニーズ
- 新作
- 次の
- ノード
- 数
- 番号
- numpy
- ONE
- 注文
- オリジナル
- その他
- その他
- パラメーター
- パラメータ
- 部
- 部品
- 完璧
- 許可
- 選ぶ
- 画像
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- ポイント
- ポイント
- :
- 練習
- 予測
- 予測
- 前
- 問題
- 実績のある
- 置きます
- Python
- ランダム
- 比
- 達した
- 再帰的
- 回帰
- 表す
- それぞれ
- 結果
- return
- ROBERT
- ルート
- ルール
- ラン
- 科学
- 科学者
- scikit-学ぶ
- を検索
- 自己
- センス
- 別
- セッションに
- シェアする
- すべき
- 簡単な拡張で
- から
- サイズ
- より小さい
- So
- これまでのところ
- 解決する
- 一部
- split
- 分割
- 標準
- 開始
- 手順
- 停止
- ストレージ利用料
- 店舗
- 保存され
- そのような
- テーラード
- 会話
- template
- 条件
- 情報
- アプリ環境に合わせて
- もの
- 物事
- 三
- しきい値
- 介して
- <font style="vertical-align: inherit;">回数</font>
- 〜へ
- 一緒に
- あまりに
- top
- トータル
- に向かって
- トレーニング
- 樹木類
- オン
- わかる
- 理解する
- us
- つかいます
- 通常
- 値
- 投票
- which
- while
- 意志
- 以内
- Word
- 言葉
- 仕事
- 仕組み
- 作品
- 最悪
- でしょう
- X
- XGブースト
- あなたの
- ゼファーネット
- ゼロ