これは、Taylor Names、Staff Machine Learning Engineer、Dev Gupta、Machine Learning Manager、およびArgie Angeleas、Ibottaのシニアプロダクトマネージャーによって共同執筆されたゲスト投稿です。 Ibottaは、デスクトップアプリとモバイルアプリを使用するユーザーが、レシートの送信、リンクされた小売業者のロイヤルティアカウント、支払い、購入確認を使用して、店舗、モバイルアプリ、オンライン購入でキャッシュバックを獲得できるようにするアメリカのテクノロジー企業です。
Ibottaは、ユーザーをより適切に維持し、関与させるために、パーソナライズされたプロモーションを推奨するよう努めています。 ただし、プロモーションとユーザー設定は常に進化しています。 多くの新しいユーザーと新しいプロモーションが存在するこの絶え間なく変化する環境は、典型的なコールドスタートの問題です。推論を引き出すのに十分な過去のユーザーとプロモーションのやり取りがありません。 強化学習(RL)は、累積報酬の概念を最大化するために、インテリジェントエージェントが環境内でどのように行動するかに関する機械学習(ML)の領域です。 RLは、未知の領域を探索することと現在の知識を活用することの間のバランスを見つけることに焦点を当てています。 多腕バンディット(MAB)は、探索と探索のトレードオフを例示する古典的な強化学習の問題です。短期的には報酬を最大化し(探索)、長期的には報酬を増やすことができる知識に対して短期的な報酬を犠牲にします(探索)。 )。 MABアルゴリズムは、ユーザーに最適な推奨事項を調査して活用します。
Ibottaは Amazon 機械学習ソリューション ラボ ユーザーとプロモーション情報が非常に動的である場合に、MABアルゴリズムを使用してユーザーエンゲージメントを高める。
次のユースケースで効果的であるため、コンテキストMABアルゴリズムを選択しました。
- ユーザーの状態(コンテキスト)に応じてパーソナライズされた推奨事項を作成する
- 新しいボーナスや新しい顧客などのコールドスタートの側面に対処する
- ユーザーの好みが時間とともに変化する推奨事項への対応
且つ
ボーナスの償還を増やすために、Ibottaは顧客にパーソナライズされたボーナスを送信したいと考えています。 ボーナスは、Ibottaの自己資金による現金インセンティブであり、コンテキストに応じた多腕バンディットモデルのアクションとして機能します。
盗賊モデルは、次のXNUMXつの機能セットを使用します。
- アクション機能 –これらは、ボーナスの種類やボーナスの平均額などのアクションを説明します
- 顧客の特徴 –これらは、過去数週間の償還、クリック、ビューなど、顧客の過去の好みとインタラクションを説明します
コンテキスト機能は、ユーザーのIbottaアプリとのインタラクションから生成された26週間のアクティビティメトリックを含む、過去のカスタマージャーニーから派生しています。
状況に応じた多腕バンディット
Banditは、意思決定者が潜在的に現在のコンテキスト情報に基づいてアクションを順次選択し、報酬信号を観察する、順次意思決定のためのフレームワークです。
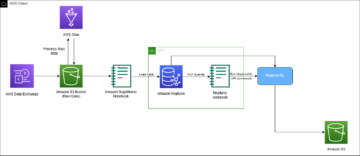
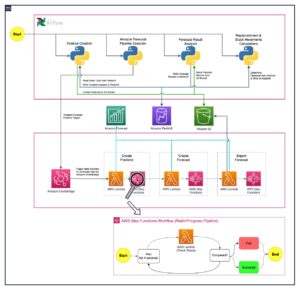
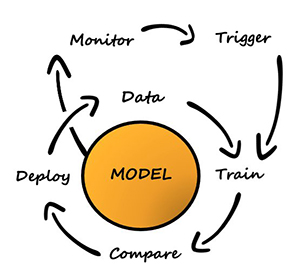
コンテキストマルチアームバンディットワークフローを設定します アマゾンセージメーカー ビルトインを使用して Vowpal Wabbit(VW) 容器。 SageMakerは、ML専用に構築された幅広い機能セットを統合することにより、データサイエンティストと開発者が高品質のMLモデルを迅速に準備、構築、トレーニング、デプロイするのを支援します。 モデルのトレーニングとテストは、オフラインの実験に基づいています。 盗賊は、ライブ環境ではなく、過去のやり取りからのフィードバックに基づいてユーザーの好みを学習します。 アルゴリズムは本番モードに切り替えることができ、SageMakerはサポートインフラストラクチャとして残ります。
探索/探索戦略を実装するために、次のアクションを実行する反復トレーニングおよび展開システムを構築しました。
- ユーザーコンテキストに基づくコンテキストバンディットモデルを使用したアクションを推奨します
- 時間の経過とともに暗黙のフィードバックをキャプチャします
- 増分相互作用データを使用してモデルを継続的にトレーニングします
クライアントアプリケーションのワークフローは次のとおりです。
- クライアントアプリケーションはコンテキストを選択します。コンテキストはSageMakerエンドポイントに送信され、アクションを取得します。
- SageMakerエンドポイントは、アクション、関連するボーナス償還確率、および
event_id. - このシミュレーターは履歴の相互作用を使用して生成されたため、モデルはそのコンテキストの真のクラスを認識しています。 エージェントが償還のあるアクションを選択した場合、報酬は1です。それ以外の場合、エージェントは0の報酬を取得します。
履歴データが利用可能で、次の形式の場合 <state, action, action probability, reward>、Ibottaは、ポリシーをオフラインで学習することにより、ライブモデルをウォームスタートできます。 それ以外の場合、Ibottaは1日目にランダムなポリシーを開始し、そこから盗賊ポリシーの学習を開始できます。
以下は、モデルをトレーニングするためのコードスニペットです。
モデルのパフォーマンス
利用されたインタラクションをトレーニングデータ(10,000インタラクション)と評価データ(5,300ホールドアウトインタラクション)としてランダムに分割します。
評価指標は平均報酬であり、1は推奨されるアクションが引き換えられたことを示し、0は推奨されるアクションが引き換えられなかったことを示します。
平均報酬は次のように決定できます。
平均報酬(償還率)=(償還を伴う推奨アクションの数)/(合計#推奨アクション)
次の表は、平均報酬結果を示しています。
| 平均報酬 | 均一なランダム推奨 | コンテキストMABベースの推奨事項 |
| トレーニング | 視聴者の38%が | 視聴者の38%が |
| ホイール試乗 | 視聴者の38%が | 視聴者の38%が |
次の図は、トレーニング中の増分パフォーマンス評価をプロットしています。ここで、x軸はモデルによって学習されたレコードの数であり、y軸は増分平均報酬です。 青い線は多腕バンディットを示しています。 オレンジ色の線はランダムな推奨事項を示します。

グラフは、予測された平均報酬が反復にわたって増加し、予測されたアクション報酬がアクションのランダムな割り当てよりも大幅に大きいことを示しています。
以前にトレーニングしたモデルをウォームスタートとして使用し、新しいデータを使用してモデルをバッチ再トレーニングできます。 この場合、モデルのパフォーマンスは初期トレーニングを通じてすでに収束しています。 次の図に示すように、新しいバッチの再トレーニングでは、パフォーマンスの大幅な向上は見られませんでした。
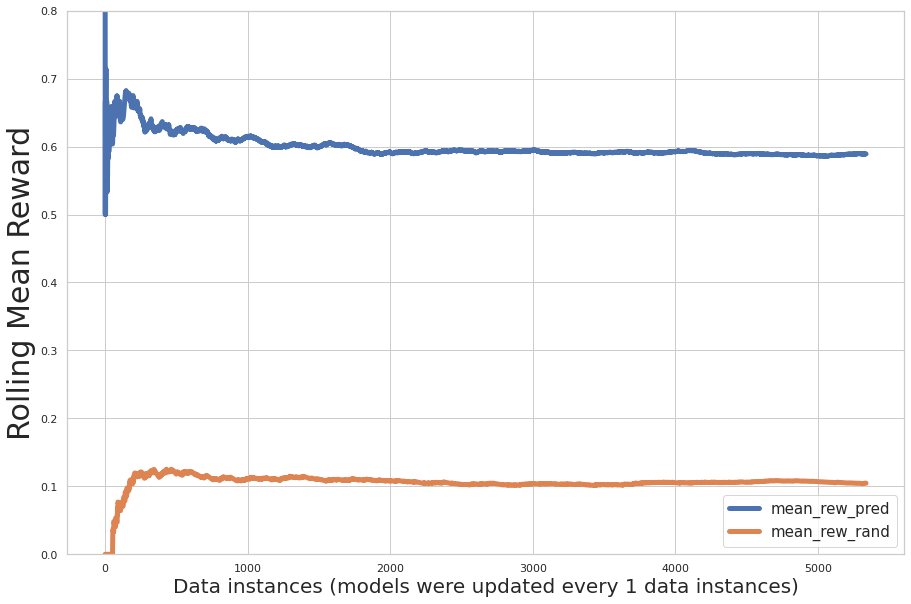
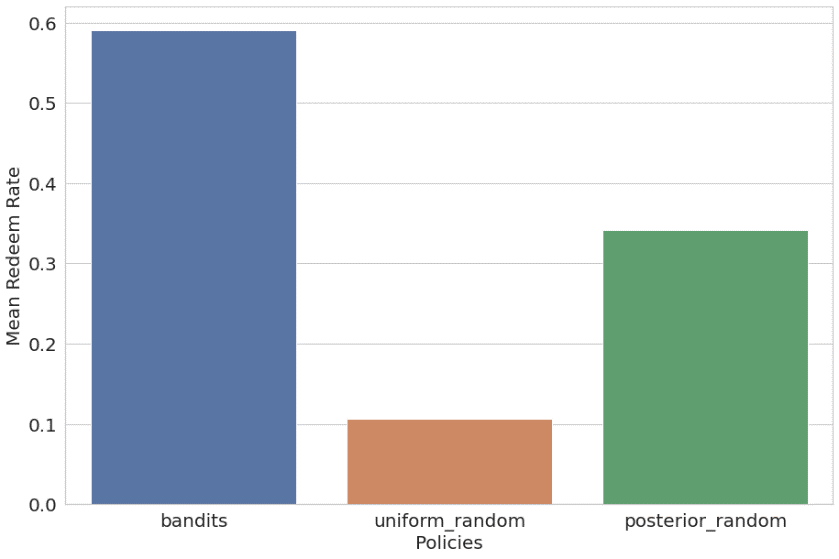
また、コンテキストバンディットを均一ランダムおよび事後ランダム(ウォームスタートとして過去のユーザー設定分布を使用したランダム推奨)ポリシーと比較しました。 結果は次のように一覧表示され、プロットされます。
- バンディット – 59.09%の平均報酬(56.44%のトレーニング)
- 均一ランダム – 10.69%の平均報酬(11.44%のトレーニング)
- 事後確率ランダム – 34.21%の平均報酬(34.82%のトレーニング)
コンテキストマルチアームバンディットアルゴリズムは、他のXNUMXつのポリシーを大幅に上回りました。
まとめ
Amazon ML Solutions Labは、Ibottaと協力して、SageMakerRLコンテナを使用したコンテキストバンディット強化学習推奨ソリューションを開発しました。
このソリューションは、オフラインテストに基づいて、ランダム(11倍のリフト)および非コンテキストRL(59倍のリフト)の推奨値よりも安定した増分償還率のリフトを示しました。 このソリューションにより、Ibottaは動的なユーザー中心のレコメンデーションエンジンを確立して、カスタマーエンゲージメントを最適化できます。 オフラインテストによると、ランダムな推奨と比較して、ソリューションは推奨の精度(平均報酬)をXNUMX%からXNUMX%に改善しました。 Ibottaは、このソリューションをよりパーソナライズされたユースケースに統合することを計画しています。
「Amazon ML Solutions Labは、Ibottaの機械学習チームと緊密に連携して、動的なボーナス推奨エンジンを構築し、償還を増やし、顧客エンゲージメントを最適化しました。 強化学習を活用して、絶えず変化する顧客の状態を学習して適応し、新しいボーナスを自動的にコールドスタートするレコメンデーションエンジンを作成しました。 2か月以内に、ML Solutions Labの科学者は、SageMakerRLコンテナを使用してコンテキストに応じた多腕バンディット強化学習ソリューションを開発しました。 コンテキストRLソリューションは、償還率の着実な増加を示し、ランダム推奨の11倍のボーナス償還率と、非コンテキストRLソリューションの59倍の上昇を達成しました。 推奨精度は、ランダム推奨を使用したXNUMX%からML Solutions Labソリューションを使用したXNUMX%に向上しました。 このソリューションの有効性と柔軟性を考慮して、このソリューションをより多くのIbottaパーソナライズのユースケースに統合し、すべての購入をユーザーに報いるという使命を推進する予定です。
–Ibottaのエンジニアリングおよびデータ担当シニアバイスプレジデントであるHeatherShannon氏。
著者について
 テイラーの名前 はIbottaのスタッフ機械学習エンジニアであり、コンテンツのパーソナライズとリアルタイムの需要予測に重点を置いています。 Ibottaに入社する前、テイラーはIoTとクリーンエネルギー分野で機械学習チームを率いていました。
テイラーの名前 はIbottaのスタッフ機械学習エンジニアであり、コンテンツのパーソナライズとリアルタイムの需要予測に重点を置いています。 Ibottaに入社する前、テイラーはIoTとクリーンエネルギー分野で機械学習チームを率いていました。
 デヴ・グプタ Ibotta Incのエンジニアリングマネージャーであり、機械学習チームを率いています。 IbottaのMLチームは、レコメンダー、予測、内部MLツールなどの高品質のMLソフトウェアを提供する任務を負っています。 Ibottaに入社する前、Devは機械学習のスタートアップであるPrediktoIncとTheHomeDepotで働いていました。 彼はフロリダ大学を卒業しました。
デヴ・グプタ Ibotta Incのエンジニアリングマネージャーであり、機械学習チームを率いています。 IbottaのMLチームは、レコメンダー、予測、内部MLツールなどの高品質のMLソフトウェアを提供する任務を負っています。 Ibottaに入社する前、Devは機械学習のスタートアップであるPrediktoIncとTheHomeDepotで働いていました。 彼はフロリダ大学を卒業しました。
 アージー・アンジェレアス Ibottaのシニアプロダクトマネージャーであり、機械学習とブラウザ拡張のチームを率いています。 Ibottaに入社する前は、ArgieはiReportsourceで製品ディレクターを務めていました。 Argieは、ライト州立大学でコンピューターサイエンスとエンジニアリングの博士号を取得しています。
アージー・アンジェレアス Ibottaのシニアプロダクトマネージャーであり、機械学習とブラウザ拡張のチームを率いています。 Ibottaに入社する前は、ArgieはiReportsourceで製品ディレクターを務めていました。 Argieは、ライト州立大学でコンピューターサイエンスとエンジニアリングの博士号を取得しています。
 牙王 のシニアリサーチサイエンティストです Amazon 機械学習ソリューション ラボ、彼女は小売業界を率い、さまざまな業界のAWSのお客様と協力して、MLの問題を解決しています。 AWSに参加する前は、Anthemでデータサイエンスのシニアディレクターを務め、医療請求処理AIプラットフォームを主導していました。 彼女はシカゴ大学で統計学の修士号を取得しました。
牙王 のシニアリサーチサイエンティストです Amazon 機械学習ソリューション ラボ、彼女は小売業界を率い、さまざまな業界のAWSのお客様と協力して、MLの問題を解決しています。 AWSに参加する前は、Anthemでデータサイエンスのシニアディレクターを務め、医療請求処理AIプラットフォームを主導していました。 彼女はシカゴ大学で統計学の修士号を取得しました。
 シン・チェン のシニアマネージャーです Amazon 機械学習ソリューション ラボ、彼は中央米国、大中華圏、LATAM、および自動車バーティカルを率いています。 彼は、さまざまな業界のAWSのお客様が機械学習ソリューションを特定して構築し、組織の投資収益率が最も高い機械学習の機会に対応できるよう支援しています。 Xinは、ノートルダム大学でコンピューターサイエンスとエンジニアリングの博士号を取得しています。
シン・チェン のシニアマネージャーです Amazon 機械学習ソリューション ラボ、彼は中央米国、大中華圏、LATAM、および自動車バーティカルを率いています。 彼は、さまざまな業界のAWSのお客様が機械学習ソリューションを特定して構築し、組織の投資収益率が最も高い機械学習の機会に対応できるよう支援しています。 Xinは、ノートルダム大学でコンピューターサイエンスとエンジニアリングの博士号を取得しています。
 ラージビスワス のデータサイエンティストです Amazon 機械学習ソリューション ラボ。 彼は、AWSのお客様が、最も差し迫ったビジネス上の課題に対応するために、さまざまな業界でMLを活用したソリューションを開発するのを支援しています。 AWSに参加する前は、コロンビア大学のデータサイエンスの大学院生でした。
ラージビスワス のデータサイエンティストです Amazon 機械学習ソリューション ラボ。 彼は、AWSのお客様が、最も差し迫ったビジネス上の課題に対応するために、さまざまな業界でMLを活用したソリューションを開発するのを支援しています。 AWSに参加する前は、コロンビア大学のデータサイエンスの大学院生でした。
 梁星華 の応用科学者です Amazon 機械学習ソリューション ラボ、彼は製造業や自動車を含むさまざまな業界の顧客と協力し、AIとクラウドの採用を加速するのを支援しています。 Xinghuaは、カーネギーメロン大学で工学の博士号を取得しています。
梁星華 の応用科学者です Amazon 機械学習ソリューション ラボ、彼は製造業や自動車を含むさまざまな業界の顧客と協力し、AIとクラウドの採用を加速するのを支援しています。 Xinghuaは、カーネギーメロン大学で工学の博士号を取得しています。
 李劉 アマゾンカスタマーサービスの応用科学者です。 彼女は、ML / AIの力を利用して、Amazonのお客様のユーザーエクスペリエンスを最適化し、AWSのお客様がスケーラブルなクラウドソリューションを構築できるよう支援することに情熱を注いでいます。 彼女のAmazonでの科学研究は、メンバーシップエンゲージメント、オンラインレコメンデーションシステム、カスタマーエクスペリエンスの欠陥の特定と解決に及びます。 仕事以外では、イーは犬と一緒に旅行や自然探検を楽しんでいます。
李劉 アマゾンカスタマーサービスの応用科学者です。 彼女は、ML / AIの力を利用して、Amazonのお客様のユーザーエクスペリエンスを最適化し、AWSのお客様がスケーラブルなクラウドソリューションを構築できるよう支援することに情熱を注いでいます。 彼女のAmazonでの科学研究は、メンバーシップエンゲージメント、オンラインレコメンデーションシステム、カスタマーエクスペリエンスの欠陥の特定と解決に及びます。 仕事以外では、イーは犬と一緒に旅行や自然探検を楽しんでいます。
- "
- &
- 000
- 10
- 100
- 11
- 7
- 9
- 私たちについて
- 加速する
- 従った
- 越えて
- Action
- 行動
- アクティビティ
- NEW
- 住所
- 養子縁組
- エージェント
- AI
- アルゴリズム
- アルゴリズム
- 既に
- Amazon
- アメリカ
- 量
- アプリ
- 申し込み
- アプリ
- AREA
- 自動車
- 利用できます
- 平均
- AWS
- ボーナス
- ブラウザ
- ビルド
- 内蔵
- ビジネス
- 機能
- カーネギーメロン
- 例
- 現金
- 課題
- 変化する
- シカゴ
- 中国
- クラシック
- クラウド
- コード
- 会社
- 比べ
- コンピュータサイエンス
- コンテナ
- コンテンツ
- 電流プローブ
- 顧客満足体験
- 顧客サービス
- Customers
- データ
- データサイエンス
- データサイエンティスト
- 中
- 決定を下す人
- 需要
- 実証
- 展開します
- 展開
- デベロッパー
- 開発する
- 発展した
- 開発者
- 異なります
- 取締役
- ディストリビューション
- ダイナミック
- 効果的な
- エンドポイント
- エネルギー
- 婚約
- エンジン
- エンジニア
- エンジニアリング
- 環境
- 確立する
- 進化
- 体験
- 探査
- 特徴
- フィードバック
- フィギュア
- 柔軟性
- フロリダ
- 焦点を当てて
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- フレームワーク
- さらに
- 卒業生
- ゲスト
- ゲストのポスト
- 高さ
- 助けます
- ことができます
- 非常に
- 歴史的
- ホーム
- 認定条件
- HTTPS
- 識別
- 識別する
- 実装する
- 含めて
- 増える
- 産業
- 産業を変えます
- 情報
- インフラ関連事業
- 統合する
- インテリジェント-
- 相互作用
- IOT
- 知識
- ラボ
- 主要な
- リード
- LEARN
- 学んだ
- 学習
- ツェッペリン
- 活用
- LINE
- リストされた
- 長い
- 忠誠心
- 機械
- 機械学習
- 作成
- マネージャー
- 製造業
- マスターの
- 医療の
- メトリック
- ミッション
- ML
- モバイル
- モバイルアプリ
- モデル
- ヶ月
- 他には?
- 最も
- 名
- 自然
- 概念
- 数
- オンライン
- オンライン購入
- 機会
- 注文
- その他
- さもないと
- 支払い
- パフォーマンス
- 個人化
- プラットフォーム
- ポリシー
- 方針
- 電力
- 社長
- 問題
- 問題
- プロダクト
- 生産
- プロモーション
- 提供
- 購入
- 購入
- すぐに
- 価格表
- への
- 推奨する
- 記録
- 研究
- 結果
- 小売
- 小売業者
- 収益
- 報酬
- ド電源のデ
- 科学
- 科学者
- 科学者たち
- 選択
- サービス
- セッションに
- 重要
- ソフトウェア
- 溶液
- ソリューション
- 解決する
- スペース
- split
- start
- 開始
- スタートアップ
- 都道府県
- 統計
- 戦略
- 学生
- 支援する
- サポート
- スイッチ
- チーム
- テクノロジー
- test
- テスト
- 介して
- 一緒に
- 豊富なツール群
- トレーニング
- 列車
- 大学
- us
- つかいます
- users
- さまざまな
- Verification
- 副会長
- weekly
- 以内
- 仕事
- 働いていました
- ワーキング
- 作品