Pandas は、Python を使用したデータ操作と分析のための強力で広く使用されているオープンソース ライブラリです。 その主な機能の XNUMX つは、groupby 関数を使用してデータをグループ化する機能です。DataFrame を XNUMX つ以上の列に基づいてグループに分割し、それぞれにさまざまな集計関数を適用します。

Image from
Unsplash
groupby 関数は、大規模なデータセットをすばやく要約して分析できるため、非常に強力です。 たとえば、データセットを特定の列でグループ化し、各グループの残りの列の平均、合計、または数を計算できます。 複数の列でグループ化して、データをより詳細に理解することもできます。 さらに、複雑なデータ分析タスクのための非常に強力なツールとなるカスタム集計関数を適用できます。
このチュートリアルでは、Pandas で groupby 関数を使用して、さまざまな種類のデータをグループ化し、さまざまな集計操作を実行する方法を学習します。 このチュートリアルの終わりまでに、この関数を使用して、さまざまな方法でデータを分析および要約できるようになります。
概念は、よく実践すると内面化されます。これが次に行うことです。つまり、Pandas の groupby 関数を実際に使用します。 を使用することをお勧めします ジュピターノート このチュートリアルでは、各ステップで出力を確認できるため、.
サンプル データの生成
次のライブラリをインポートします。
- Pandas: データフレームを作成して group by を適用するには
- Random – ランダムなデータを生成します
- Pprint – 辞書を印刷する
import pandas as pd
import random
import pprint
次に、空のデータフレームを初期化し、以下に示すように各列に値を入力します。
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
おまけのヒント – 同じタスクを行うためのよりクリーンな方法は、すべての変数と値の辞書を作成し、後でそれをデータフレームに変換することです。
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
データフレームは次のようになります。 このコードを実行すると、ランダム サンプルを使用しているため、一部の値が一致しません。
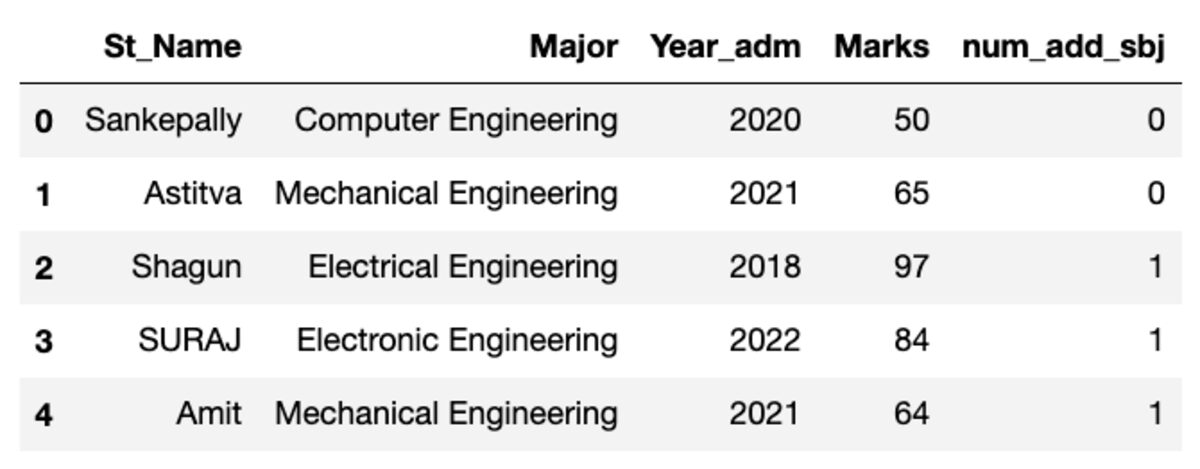
グループを作る
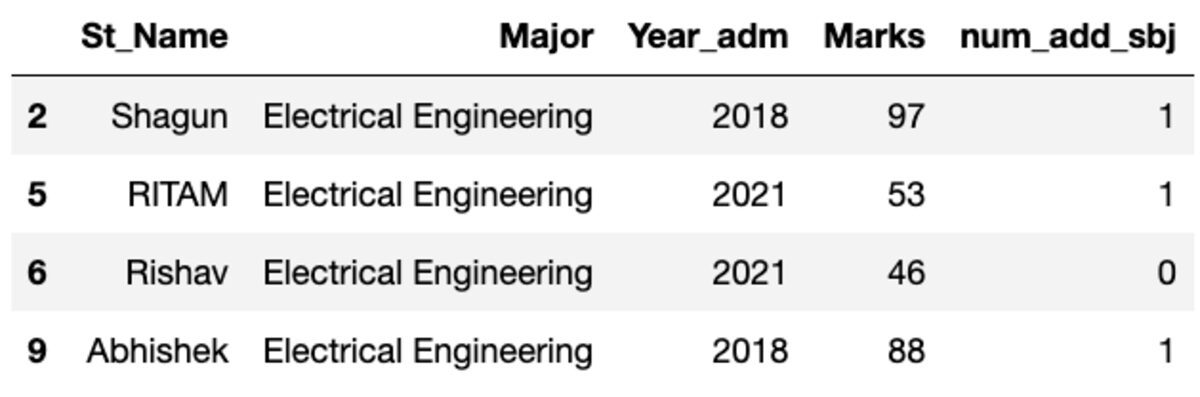
データを「主な」件名でグループ化し、グループ フィルターを適用して、このグループに分類されるレコードの数を確認しましょう。
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
というわけで、XNUMX名の学生が電気工学専攻に所属しています。
複数の列 (この場合はメジャーと num_add_sbj) でグループ化することもできます。
groups = df.groupby(['Major', 'num_add_sbj'])
XNUMX つの列を持つグループに適用できるすべての集計関数は、複数の列を持つグループに適用できることに注意してください。 チュートリアルの残りの部分では、例として XNUMX つの列を使用して、さまざまな種類の集計に焦点を当てましょう。
「メジャー」列で groupby を使用してグループを作成しましょう。
groups = df.groupby('Major')直接関数の適用
各メジャーの平均点を求めたいとしましょう。 あなたならどうしますか?
- マーク列を選択
- 平均関数を適用
- 丸め関数を適用して、小数点以下 XNUMX 桁に四捨五入します (オプション)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
集計
同じ結果を得る別の方法は、以下に示すように集計関数を使用することです。
groups['Marks'].aggregate('mean').round(2)
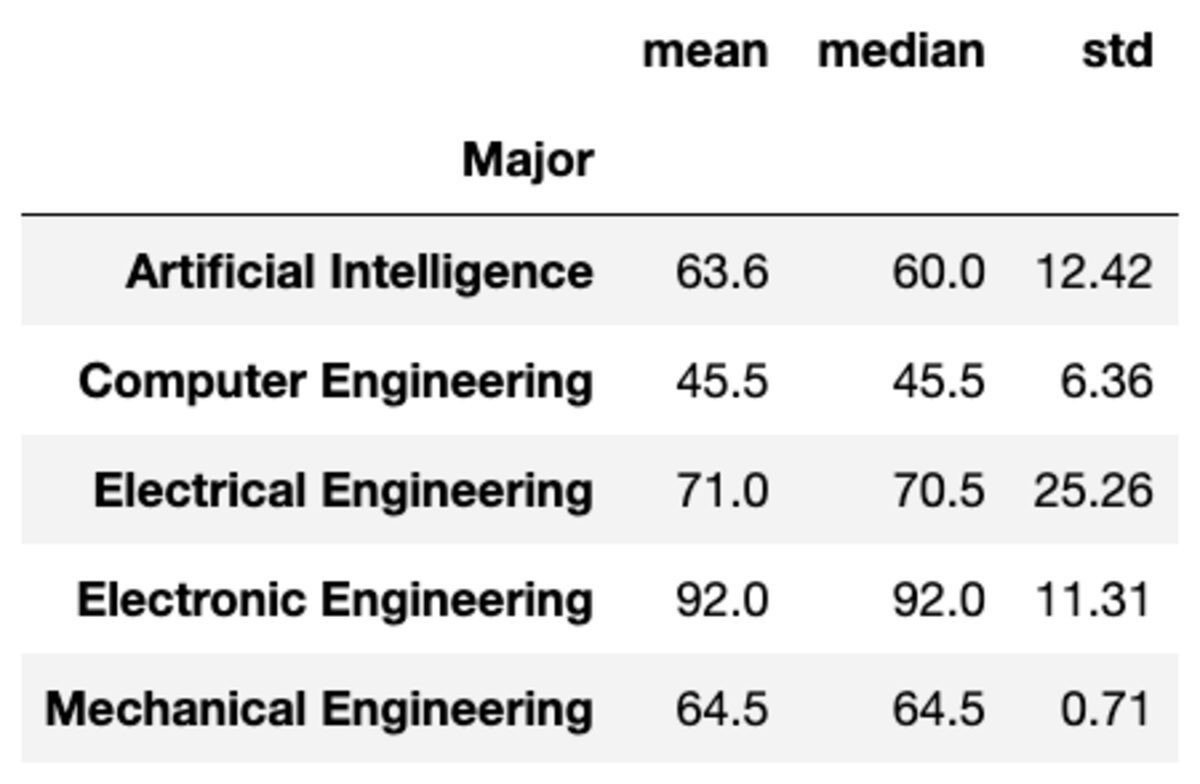
関数を文字列のリストとして渡すことで、複数の集計をグループに適用することもできます。
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
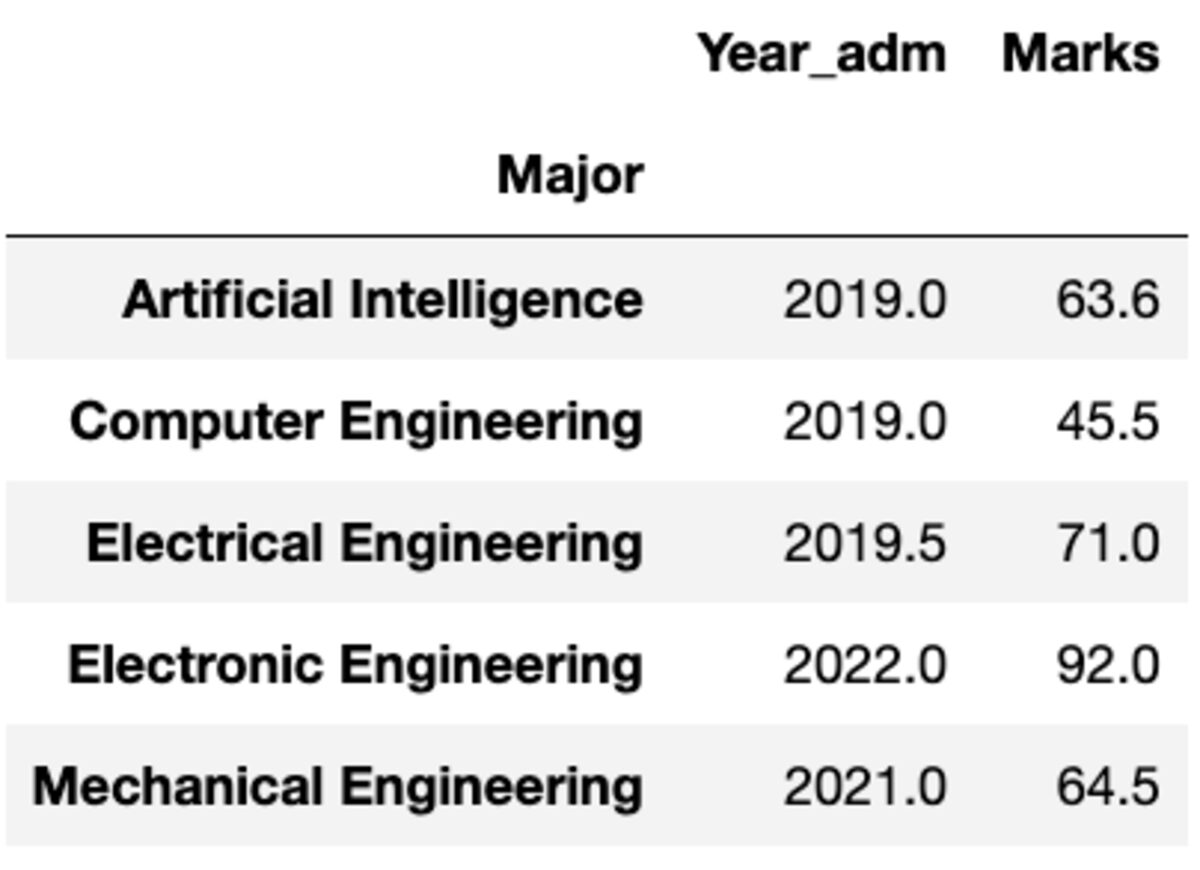
しかし、別の関数を別の列に適用する必要がある場合はどうでしょう。 心配しないで。 {column: function} ペアを渡すことによってもそれを行うことができます。
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
変換
groupby() を使用して簡単に実現できる特定の列に対してカスタム変換を実行する必要がある場合があります。 sklearn の前処理モジュールで使用できるものと同様の標準スカラーを定義しましょう。 transform メソッドを呼び出してカスタム関数を渡すことで、すべての列を変換できます。
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
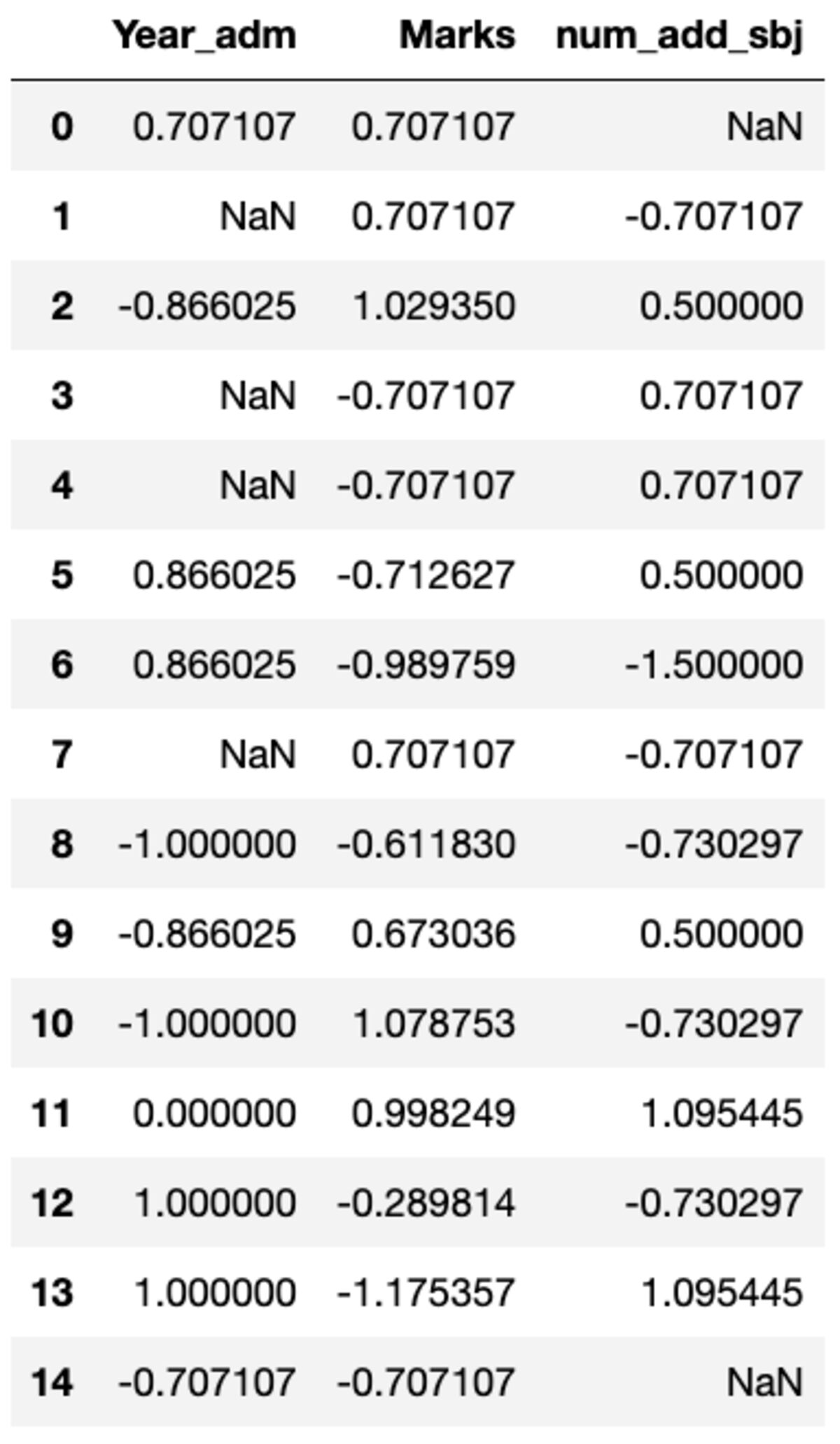
「NaN」は、標準偏差がゼロのグループを表すことに注意してください。
フィルタ
平均的な学生の「マーク」が 60 未満の「専攻」など、どの「専攻」が成績が悪いかを確認したい場合があります。これには、内部に関数を含むグループにフィルター メソッドを適用する必要があります。 以下のコードは ラムダ関数 フィルタリングされた結果を達成します。
groups.filter(lambda x: x['Marks'].mean() 60)

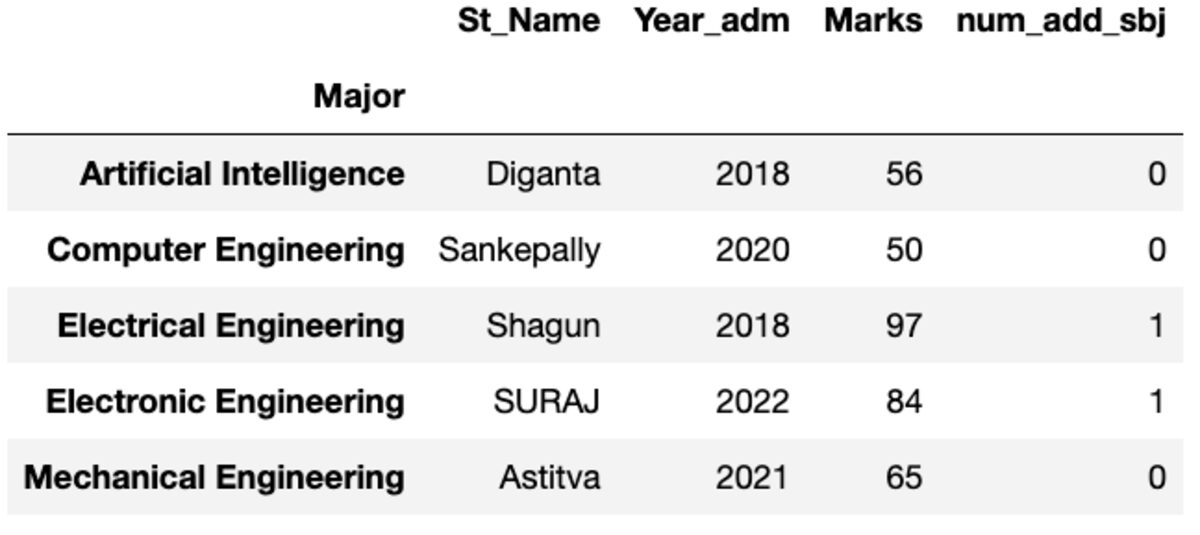
名
インデックスでソートされた最初のインスタンスを提供します。
groups.first()
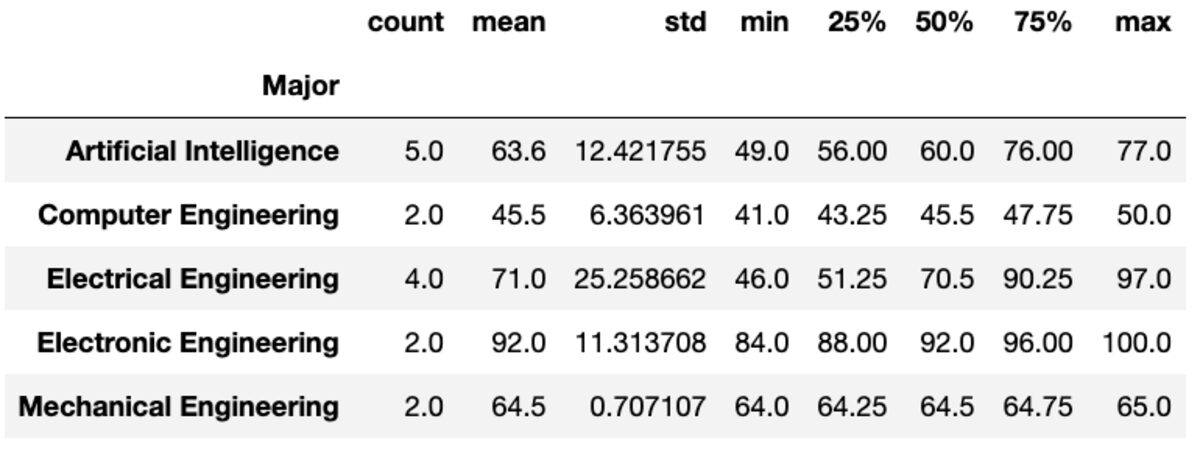
説明する
「describe」メソッドは、指定された列のカウント、平均、標準、最小、最大などの基本的な統計を返します。
groups['Marks'].describe()
サイズ
サイズは、その名前が示すように、各グループのサイズをレコード数で返します。
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
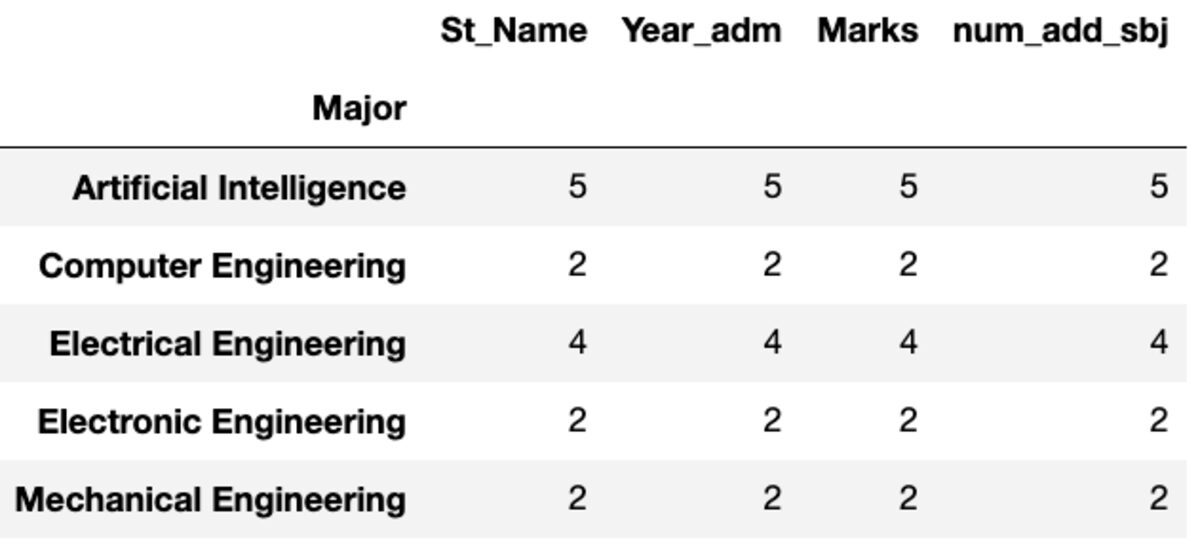
dtype: int64カウントとヌニーク
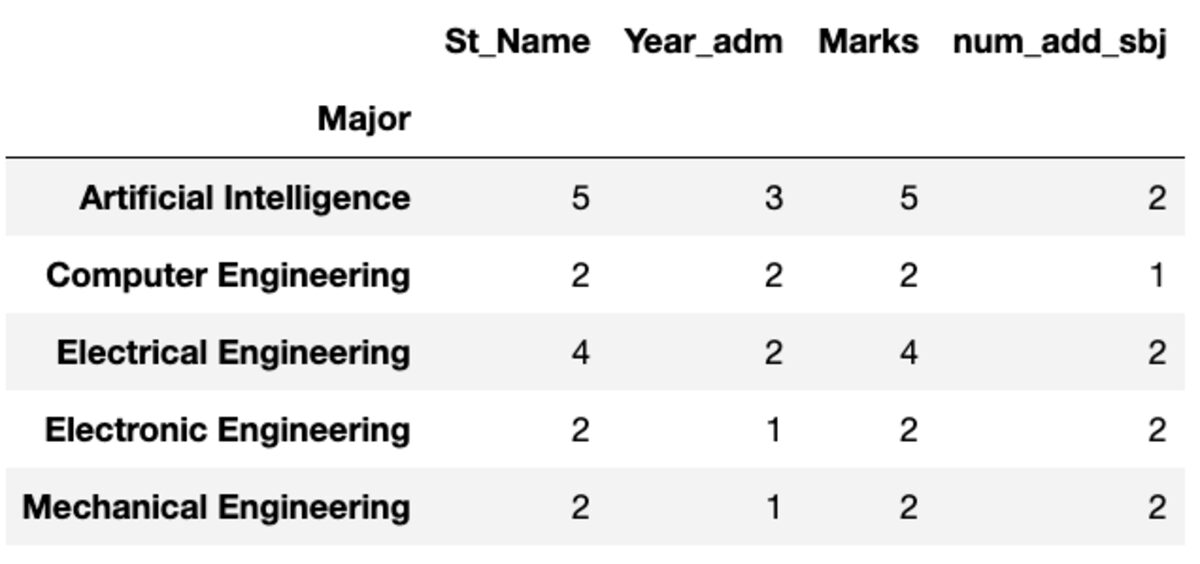
「Count」はすべての値を返しますが、「Nunique」はそのグループ内の一意の値のみを返します。
groups.count()
groups.nunique()
リネーム
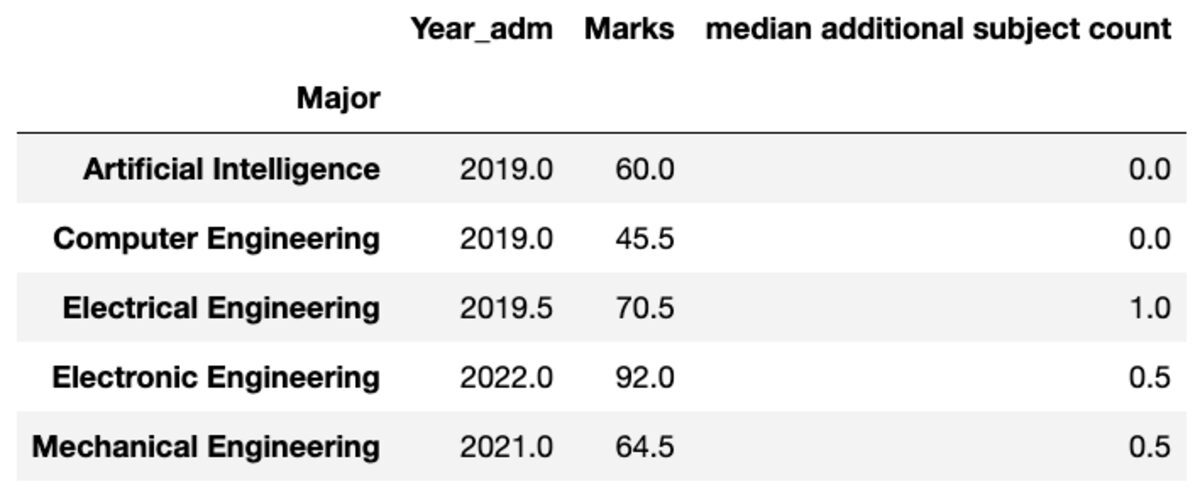
好みに応じて、集計された列の名前を変更することもできます。
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- groupby の目的を明確にしてください。 データを XNUMX つの列でグループ化して、別の列の平均を取得しようとしていますか? または、データを複数の列でグループ化して、各グループの行数を取得しようとしていますか?
- データ フレームのインデックス付けを理解する: groupby 関数は、インデックスを使用してデータをグループ化します。 列ごとにデータをグループ化する場合は、列がインデックスとして設定されていることを確認するか、.set_index() を使用できます。
- 適切な集計関数を使用する: mean()、sum()、count()、min()、max()などのさまざまな集計関数で使用できます
- as_index パラメータを使用します。 False に設定すると、このパラメーターは、グループ化された列をインデックスではなく通常の列として使用するように pandas に指示します。
groupby() を他の pandas 関数 (pivot_table()、crosstab()、cut() など) と組み合わせて使用して、データからより多くの洞察を抽出することもできます。
groupby 関数は、XNUMX つ以上の列に基づいてデータの行をグループ化し、グループに対して集計計算を実行できるため、データの分析と操作のための強力なツールです。 このチュートリアルでは、コード例を使用して groupby 関数を使用するさまざまな方法を示しました。 それに付随するさまざまなオプションと、それらがデータ分析にどのように役立つかについての理解を提供してくれることを願っています.
ヴィディ・チュー スケーラブルな機械学習システムを構築するために、製品、科学、エンジニアリングの交差点で働く AI ストラテジストであり、デジタル トランスフォーメーションのリーダーです。 彼女は受賞歴のあるイノベーション リーダーであり、作家であり、国際的な講演者でもあります。 彼女は、機械学習を民主化し、誰もがこの変革に参加できるよう専門用語を打ち破ることを使命としています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- 能力
- できる
- 達成する
- 達成
- NEW
- さらに
- 凝集
- AI
- すべて
- ことができます
- 分析
- 分析します
- および
- 別の
- 適用された
- 申し込む
- 適用
- 適切な
- 人工の
- 人工知能
- 著者
- 利用できます
- 平均
- 受賞歴のある
- ベース
- 基本
- 以下
- バイオテクノロジー
- ブレーク
- ビルド
- 計算する
- 呼び出し
- 場合
- チェック
- クリア
- コード
- コラム
- コラム
- 来ます
- 複雑な
- コンピュータ
- コンピューター工学
- 作ります
- 作成
- カスタム
- データ
- データ分析
- データセット
- 民主化する
- 実証
- 偏差
- 異なります
- デジタル
- 直接
- ドント
- 各
- 簡単に
- 効果的に
- 電気工学
- エレクトロニック
- エンジニアリング
- 等
- 誰も
- 例
- 例
- エキス
- 秋
- 特徴
- 埋める
- filter
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- フォーカス
- フォロー中
- FRAME
- から
- function
- 機能
- 生成する
- 取得する
- 与えられた
- 与える
- 行く
- グループ
- グループの
- 実践的な
- 助けます
- 希望
- 認定条件
- How To
- HTML
- HTTPS
- import
- in
- 信じられないほど
- index
- 革新的手法
- 洞察
- を取得する必要がある者
- インテリジェンス
- 世界全体
- 交差点
- IT
- 専門用語
- KDナゲット
- キー
- 大
- リーダー
- LEARN
- 学習
- ライブラリ
- 図書館
- リスト
- LOOKS
- 機械
- 機械学習
- 主要な
- make
- 操作
- 多くの
- 一致
- マックス
- 機械的な
- 機械工学
- ミディアム
- 方法
- ミッション
- モジュール
- 他には?
- の試合に
- 名
- 名
- 必要
- 次の
- 数
- ONE
- オープンソース
- 業務執行統括
- オプション
- その他
- パンダ
- パラメーター
- 部
- 特定の
- 通過
- 実行する
- 場所
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- 強力な
- 印刷物
- プロダクト
- は、大阪で
- 目的
- Python
- すぐに
- ランダム
- 推奨される
- 記録
- レギュラー
- 残り
- 表し
- 必要
- REST
- 結果
- 結果
- return
- 収益
- リチャード
- 円形
- ランニング
- 同じ
- ド電源のデ
- 科学
- セッションに
- すべき
- 示す
- 同様の
- サイズ
- 一部
- スピーカー
- 特定の
- 標準
- 統計
- 手順
- 戦略家
- 学生
- 生徒
- テーマ
- 提案する
- まとめる
- システム
- 仕事
- タスク
- 伝える
- 条件
- 先端
- 〜へ
- ツール
- 最適化の適用
- 変換
- 変換
- チュートリアル
- 理解する
- ユニーク
- つかいます
- 価値観
- さまざまな
- 方法
- この試験は
- which
- 意志
- ワーキング
- でしょう
- X
- 年
- あなたの
- ゼファーネット
- ゼロ








