
著者による画像
データ サイエンスは学際的な分野であり、膨大な量のデータから洞察を抽出し、情報に基づいた意思決定を行うことに大きく依存しています。 データ サイエンティストのツールボックスの基本ツールの XNUMX つは、リレーショナル データベースを管理および操作するために設計されたプログラミング言語である SQL (構造化照会言語) です。
この記事では、SQL の最も強力な機能の XNUMX つである結合に焦点を当てます。
SQL 結合を使用すると、共通の列に基づいて複数のデータベース テーブルのデータを結合できます。 そうすることで、情報を結合し、関連するデータセット間に意味のある接続を作成できます。
いくつかある SQL 結合のタイプ:
- 内部結合
- 左外部結合
- 右外部結合
- 完全外部結合
- クロスジョイン
それぞれの種類について説明しましょう。
内部結合は、結合される両方のテーブルに一致する行のみを返します。 共有キーまたは列に基づいて XNUMX つのテーブルの行を結合し、一致しない行を破棄します。
これを次のように視覚化します。
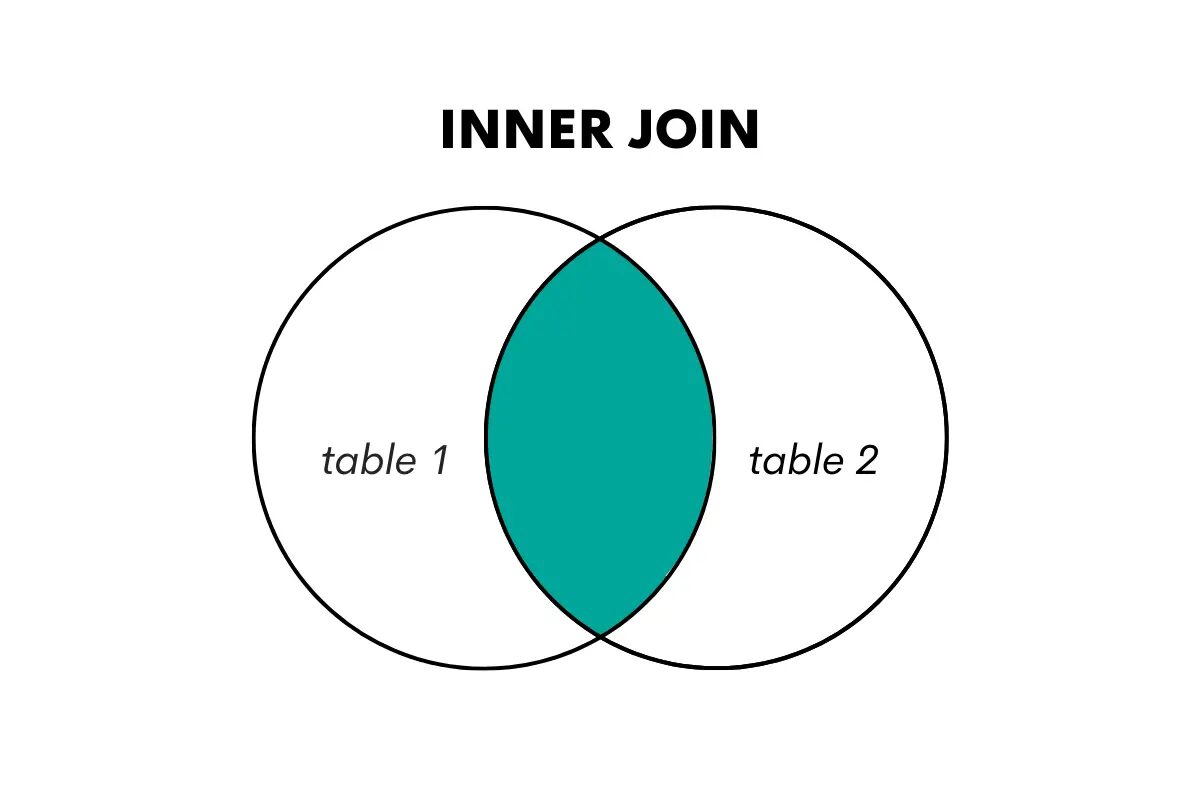
著者による画像
SQL では、このタイプの結合はキーワード JOIN または INNER JOIN を使用して実行されます。
左外部結合は、左側 (または最初) のテーブルからすべての行と、右側 (または XNUMX 番目) のテーブルから一致した行を返します。 一致するものがない場合は、右側のテーブルの列に対して NULL 値が返されます。
このように視覚化できます。
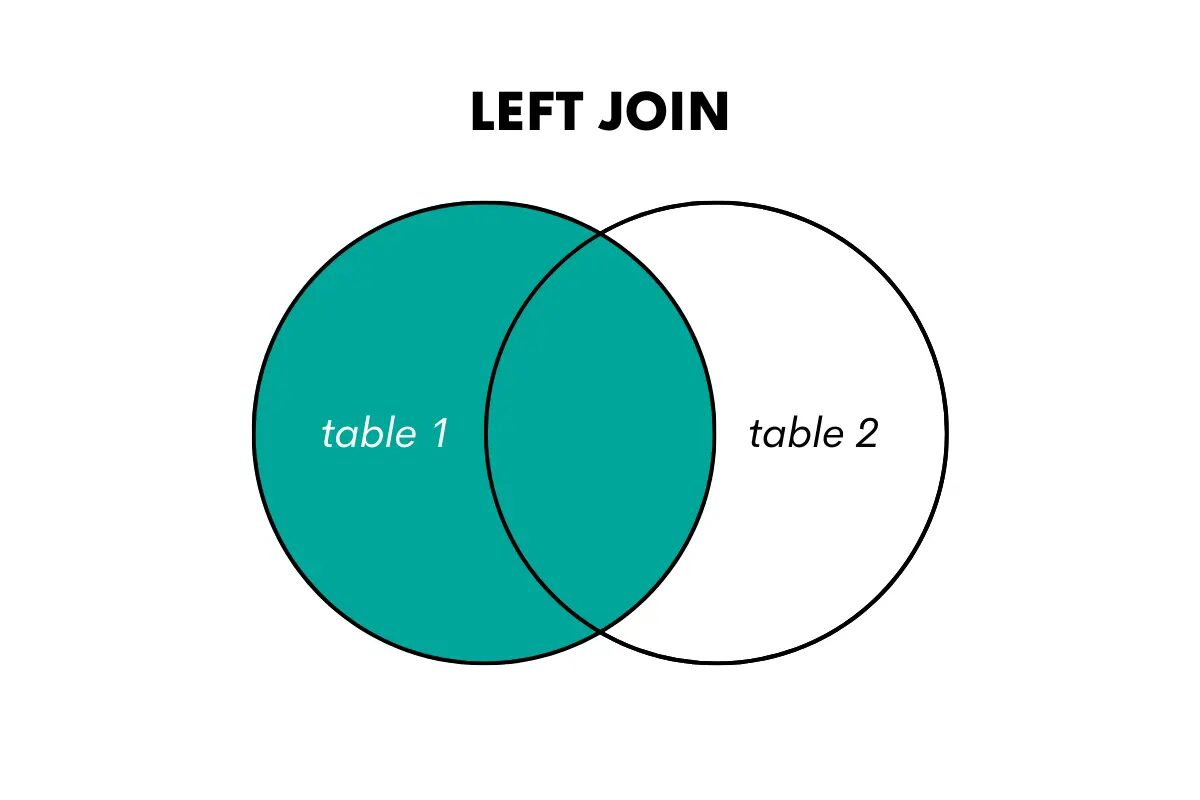
著者による画像
SQL でこの結合を使用する場合は、LEFT OUTER JOIN または LEFT JOIN キーワードを使用して実行できます。 について語った記事はこちら 左結合と左外部結合.
右結合は左結合の逆です。 右のテーブルからすべての行を返し、左のテーブルから一致した行を返します。 一致するものがない場合は、左側のテーブルの列に対して NULL 値が返されます。
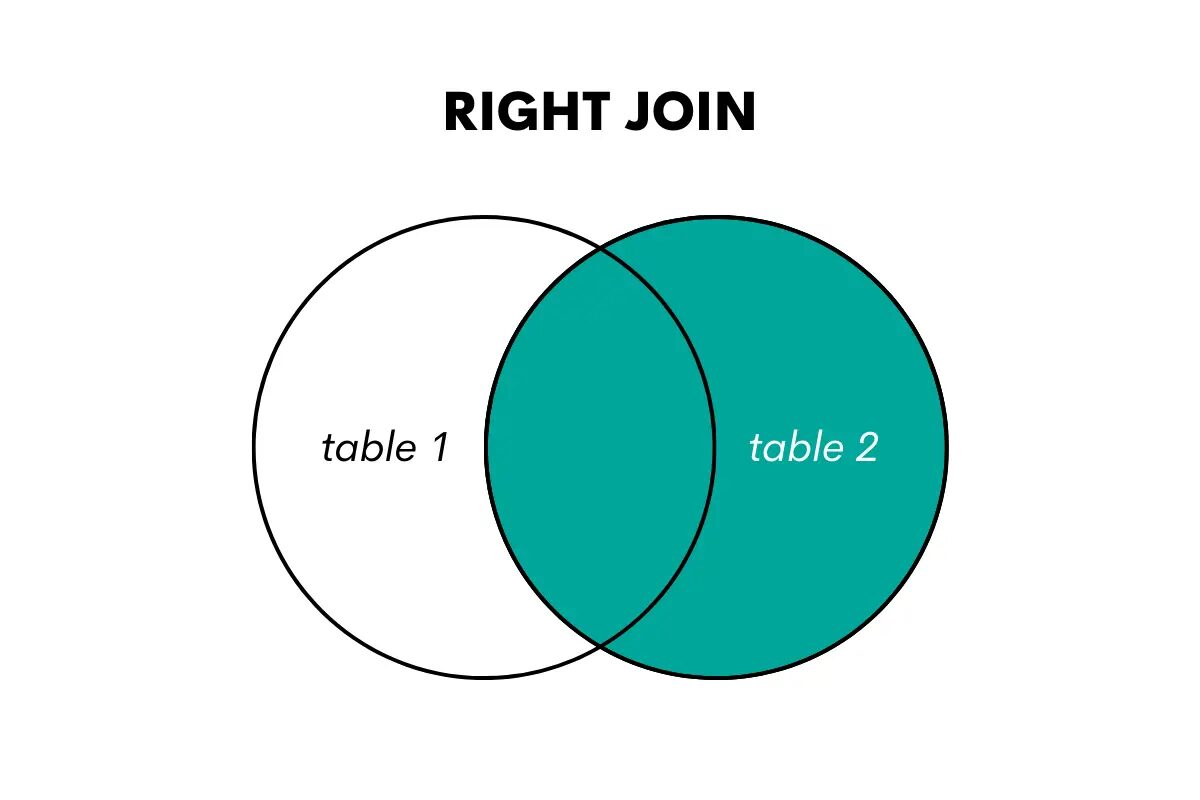
著者による画像
SQL では、この結合タイプはキーワード RIGHT OUTER JOIN または RIGHT JOIN を使用して実行されます。
完全外部結合では、両方のテーブルのすべての行が返され、可能な場合は行が一致し、一致しない行には NULL 値が埋められます。
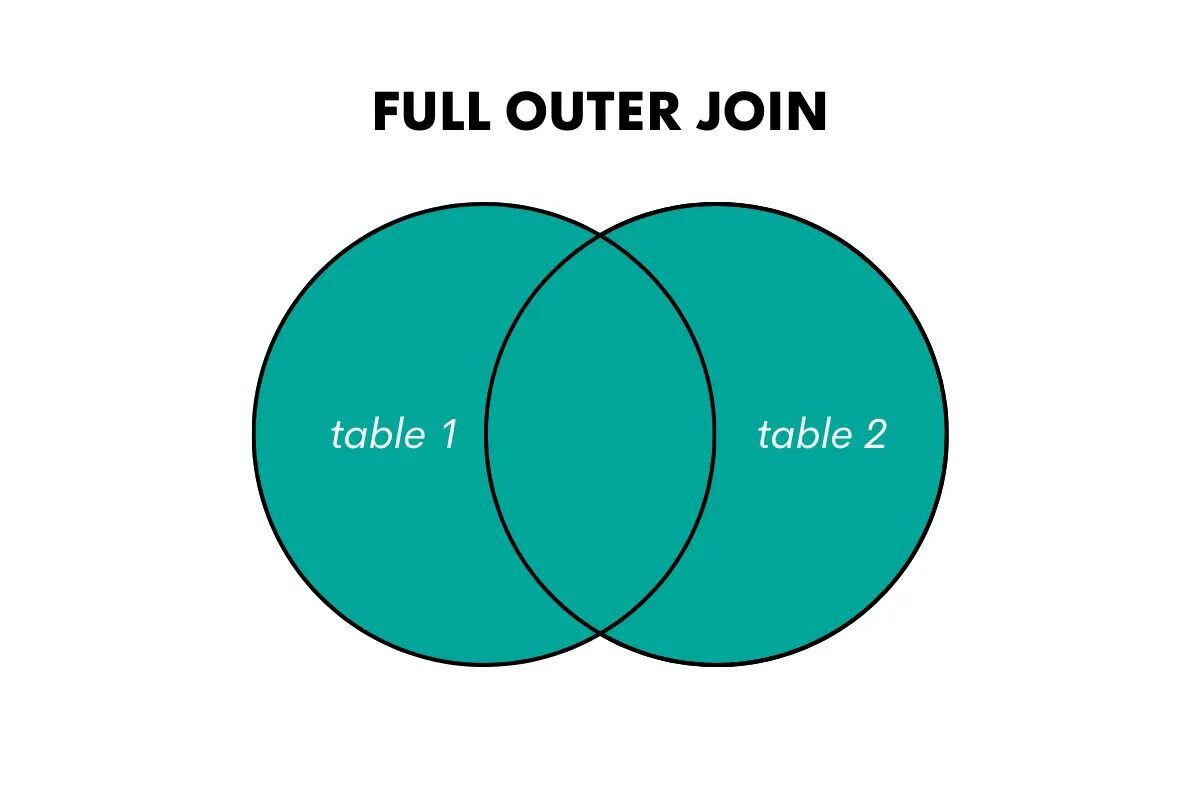
著者による画像
この結合の SQL のキーワードは、FULL OUTER JOIN または FULL JOIN です。
このタイプの結合では、XNUMX つのテーブルのすべての行と XNUMX 番目のテーブルのすべての行が結合されます。 言い換えれば、デカルト積、つまり XNUMX つのテーブルの行の可能なすべての組み合わせを返します。
わかりやすく視覚化したものがこちらです。
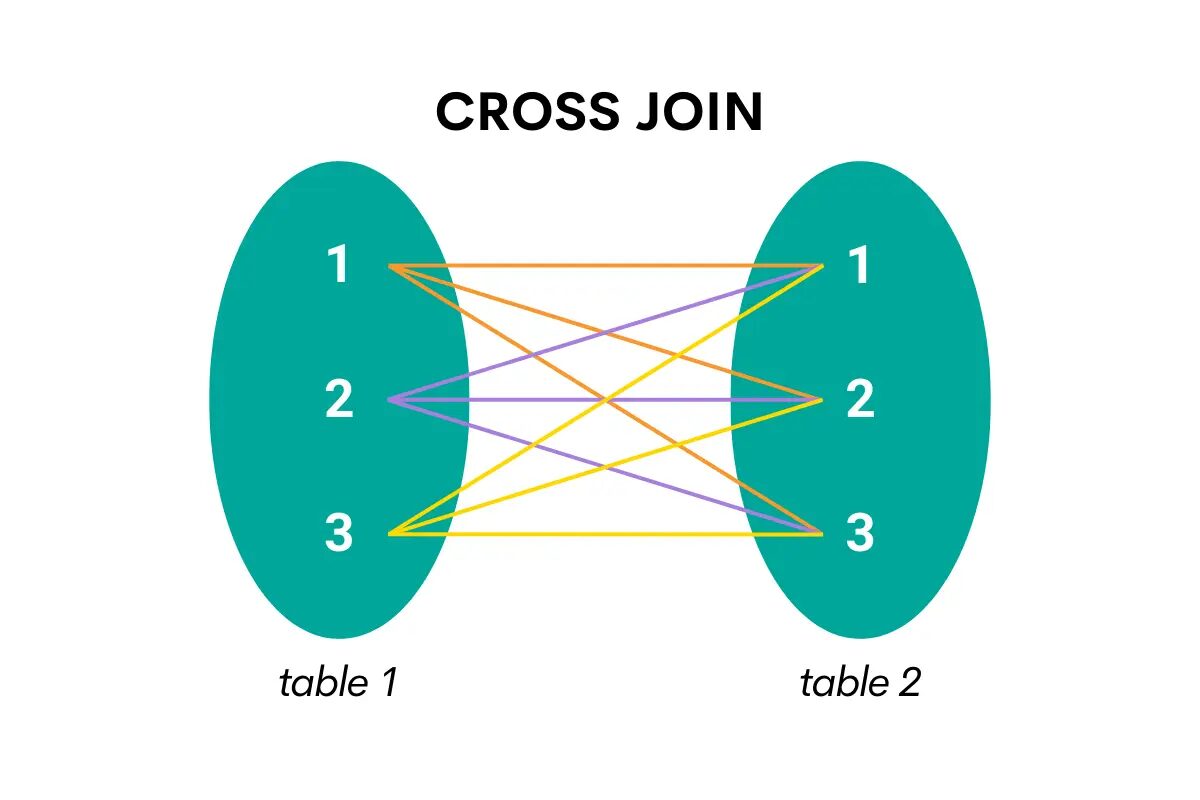
著者による画像
SQL でクロス結合する場合、キーワードは CROSS JOIN です。
SQL で結合を実行するには、結合するテーブル、照合に使用する列、および実行する結合の種類を指定する必要があります。 SQL でテーブルを結合するための基本的な構文は次のとおりです。
SELECT columns
FROM table1
JOIN table2
ON table1.column = table2.column;
この例では、JOIN の使用方法を示します。
FROM 句の最初 (または左側) のテーブルを参照します。 次に、JOIN を続けて XNUMX 番目 (または右側) のテーブルを参照します。
次に、ON 句の結合条件が続きます。 ここで、XNUMX つのテーブルを結合するために使用する列を指定します。 通常、これは XNUMX つのテーブルの主キーであり、XNUMX 番目のテーブルの外部キーである共有列です。
注: 主キーは、テーブル内の各レコードの一意の識別子です。 外部キーは XNUMX つのテーブル間のリンクを確立します。つまり、外部キーは、最初のテーブルを参照する XNUMX 番目のテーブルの列です。 それが何を意味するかを例で示します。
LEFT JOIN、RIGHT JOIN、または FULL JOIN を使用する場合は、JOIN の代わりにこれらのキーワードを使用するだけです。コード内のその他の部分はすべてまったく同じです。
CROSS JOIN の場合は少し異なります。 その性質上、両方のテーブルのすべての行の組み合わせを結合します。 そのため ON 句は必要なく、構文は次のようになります。
SELECT columns
FROM table1
CROSS JOIN table2;
つまり、XNUMX つのテーブルを FROM で参照し、XNUMX 番目のテーブルを CROSS JOIN で参照するだけです。
あるいは、FROM で両方のテーブルを参照し、カンマで区切ることもできます。これは CROSS JOIN の短縮形です。
SELECT columns
FROM table1, table2;テーブルを結合する特定の方法が XNUMX つあり、それはテーブルをそれ自体と結合することです。 これは、テーブルへの自己結合とも呼ばれます。
前述の結合タイプは自己結合にも使用できるため、これは厳密には別のタイプの結合というわけではありません。
自己結合の構文は、前に示したものと似ています。 主な違いは、FROM と JOIN で同じテーブルが参照されることです。
SELECT columns
FROM table1 t1
JOIN table1 t2
ON t1.column = t2.column;
また、テーブルを区別するために、テーブルに XNUMX つの別名を与える必要があります。 ここで行っていることは、テーブルをそれ自体と結合し、それを XNUMX つのテーブルとして扱うことです。
ここではこれについて触れておきたかっただけですが、これ以上詳しくは説明しません。 自己参加に興味がある場合は、この図解ガイドを参照してください。 SQLでの自己結合.
ここで、私が述べたすべてが実際にどのように機能するかを説明します。 使います SQL JOIN 面接の質問 StrataScratch から、SQL におけるそれぞれの異なるタイプの結合を紹介します。
1. JOIN の例
Microsoft によるこの質問 各プロジェクトをリスト化し、従業員ごとにプロジェクトの予算を計算してもらいたいと考えています。
高額なプロジェクト
「プロジェクトと各プロジェクトにマッピングされた従業員のリストが与えられた場合、各従業員に割り当てられたプロジェクト予算の額を計算します。 出力には、プロジェクトのタイトルと、最も近い整数に四捨五入されたプロジェクトの予算が含まれる必要があります。 従業員あたりの予算が最も高いプロジェクトからリストを並べてください。」
且つ
質問には XNUMX つの表が示されています。
ms_projects
| ID: | int型 |
| タイトル: | varchar |
| バジェット: | int型 |
ms_emp_projects
| emp_id: | int型 |
| プロジェクトID: | int型 |
さて、テーブルの列ID ms_projects テーブルの主キーです。 テーブル内に同じ列が見つかります ms_emp_projects名前は異なりますが、project_id です。 これはテーブルの外部キーであり、最初のテーブルを参照します。
これら XNUMX つの列を使用して、ソリューション内のテーブルを結合します。
Code
SELECT title AS project, ROUND((budget/COUNT(emp_id)::FLOAT)::NUMERIC, 0) AS budget_emp_ratio
FROM ms_projects a
JOIN ms_emp_projects b ON a.id = b.project_id
GROUP BY title, budget
ORDER BY budget_emp_ratio DESC;
JOIN を使用して XNUMX つのテーブルを結合しました。 テーブル ms_projects は FROM で参照されますが、 ms_emp_projects JOIN の後に参照されます。 両方のテーブルにエイリアスを付けたので、後でテーブルの長い名前を使用しなくても済みます。
次に、テーブルを結合する列を指定する必要があります。 どの列が XNUMX つのテーブルの主キーであり、別のテーブルの外部キーであるかについてはすでに述べたので、ここではそれらを使用します。
プロジェクト ID が同じであるすべてのデータを取得したいので、これら XNUMX つの列を等しくします。 各列の前にテーブルのエイリアスも使用しました。
両方のテーブルのデータにアクセスできるようになったので、SELECT で列をリストできます。 最初の列はプロジェクト名で、XNUMX 番目の列は計算されます。
この計算では、COUNT() 関数を使用して、プロジェクトごとに従業員の数をカウントします。 次に、各プロジェクトの予算を従業員の数で割ります。 また、結果を XNUMX 進数値に変換し、小数点以下 XNUMX 桁に四捨五入します。
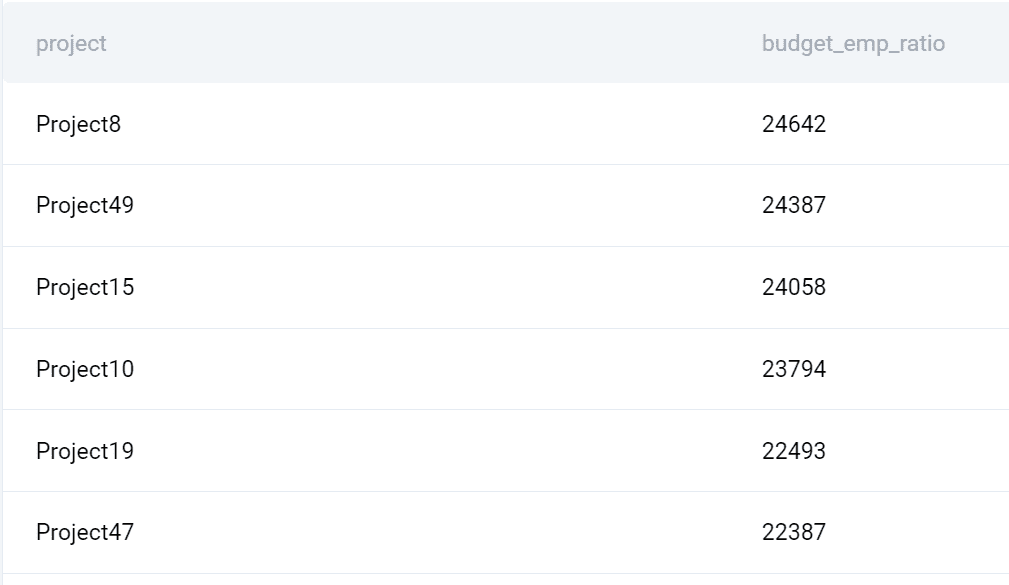
出力
クエリが返す内容は次のとおりです。
2. 左結合の例
この結合を練習してみましょう Airbnbの面接での質問。 各都市の注文数、顧客数、注文の合計コストを調べたいと考えています。
お客様の注文と詳細
「各都市の注文数、顧客数、注文の合計コストを調べます。 少なくとも 5 件の注文を行った都市のみを含め、注文していない場合でも各都市のすべての顧客をカウントします。
各計算を対応する都市名とともに出力します。」
且つ
テーブルが与えられます お客様に および 受注.
お客さま
| ID: | int型 |
| ファーストネーム: | varchar |
| 苗字: | varchar |
| 街: | varchar |
| 住所: | varchar |
| 電話番号: | varchar |
受注
| ID: | int型 |
| cust_id: | int型 |
| 注文日: | 日付時刻 |
| 注文詳細: | varchar |
| 合計注文コスト: | int型 |
共有列はテーブルの ID です お客さま およびテーブルからの cust_id 受注。 これらの列を使用してテーブルを結合します。
Code
LEFT JOIN を使用してこの質問を解決する方法を次に示します。
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM customers c
LEFT JOIN orders o ON c.id = o.cust_id
GROUP BY c.city
HAVING COUNT(o.id) >=5;
表を参考にさせていただきます お客さま FROM (これは左側のテーブルです) で LEFT JOIN します。 受注 顧客 ID 列に表示されます。
これで、都市を選択し、COUNT() を使用して都市ごとの注文数と顧客数を取得し、SUM() を使用して都市ごとの合計注文コストを計算できるようになりました。
これらすべての計算を都市ごとに取得するために、出力を都市ごとにグループ化します。
質問には追加のリクエストが 5 つあります。「少なくとも XNUMX 件の注文を行った都市のみを含める…」これを達成するために、HAVING を使用して XNUMX 件以上の注文を行った都市のみを表示します。
問題は、なぜ使用したのかということです 左結合します そうではない 登録? ヒントは次の質問にあります。「…注文していない場合でも、各都市のすべての顧客を数えます。」 すべての顧客が注文を行っていない可能性があります。 これは、テーブルのすべての顧客を表示したいことを意味します お客さまこれは LEFT JOIN の定義に完全に適合します。
JOIN を使用していたら、注文をしなかった顧客を見逃していたため、結果は間違っていたでしょう。
注: SQL の結合の複雑さは、構文ではなくセマンティクスに反映されます。 ご覧のとおり、各結合は同じ方法で記述されますが、キーワードのみが異なります。 ただし、各結合の動作は異なるため、データに応じて異なる結果が出力される可能性があります。 そのため、各結合が何を行うのかを完全に理解し、必要なものを正確に返す結合を選択することが重要です。
出力
次に、出力を見てみましょう。

3. 右結合の例
RIGHT JOIN は LEFT JOIN の鏡像です。 だからこそ、RIGHT JOIN を使用すれば、前の問題を簡単に解決できたはずです。 その方法を説明しましょう。
且つ
テーブルは同じままです。 別の種類の結合を使用します。
Code
SELECT c.city, COUNT(DISTINCT o.id) AS orders_per_city, COUNT(DISTINCT c.id) AS customers_per_city, SUM(o.total_order_cost) AS orders_cost_per_city
FROM orders o
RIGHT JOIN customers c ON o.cust_id = c.id GROUP BY c.city
HAVING COUNT(o.id) >=5;
変更点は次のとおりです。 RIGHT JOINを使用しているので、テーブルの順序を入れ替えました。 さて、テーブル 受注 左がテーブルになります お客さま 正しいもの。 加入条件はそのままです。 テーブルの順序を反映するために列の順序を切り替えただけですが、そうする必要はありません。
テーブルの順序を入れ替えて RIGHT JOIN を使用すると、たとえ注文がなかったとしても、すべての顧客が再び出力されます。
クエリの残りの部分は前の例と同じです。 出力についても同様です。
注: 実際には、 正しい参加 比較的まれに使用されます。 SQL ユーザーにとっては LEFT JOIN の方が自然であるため、より頻繁に使用されます。 RIGHT JOIN で実行できることはすべて、LEFT JOIN でも実行できます。 そのため、RIGHT JOIN が優先される特定の状況はありません。
出力
4. FULL JOIN の例
SalesforceとTeslaの質問 2020 年に発売された製品企業の数と、前年に発売された製品企業の数との純差を数えてほしいと考えています。
新製品
「企業ごとに年ごとに発売された製品の表が与えられます。 2020 年に発売された製品企業の数と、前年に発売された製品企業の数との純差を数えるクエリを作成します。 企業名と2020年に発売された純製品の前年比純差額を出力します。」
且つ
この質問では、次の列を含む XNUMX つのテーブルが提供されます。
car_launches
| 年: | int型 |
| 会社名: | varchar |
| 商品名: | varchar |
テーブルが XNUMX つしかない場合、一体どうやってテーブルを結合するのでしょうか? うーん、それも見てみよう!
Code
このクエリは少し複雑なので、徐々に明らかにしていきます。
SELECT company_name, product_name AS brand_2020
FROM car_launches
WHERE YEAR = 2020;
最初の SELECT ステートメントは、2020 年の会社と製品名を検索します。このクエリは後でサブクエリに変換されます。
この質問は、2020 年と 2019 年の違いを見つけることを求めています。そこで、2019 年を除いて同じクエリを作成しましょう。
SELECT company_name, product_name AS brand_2019
FROM car_launches
WHERE YEAR = 2019;
これらのクエリをサブクエリにし、FULL OUTER JOIN を使用して結合します。
SELECT *
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name;
サブクエリはテーブルとして扱うことができるため、結合することができます。 最初のサブクエリにエイリアスを付け、それを FROM 句に配置しました。 次に、FULL OUTER JOIN を使用して、会社名列の XNUMX 番目のサブクエリと結合します。
このタイプの SQL 結合を使用すると、2020 年のすべての企業と製品が 2019 年のすべての企業と製品とマージされます。
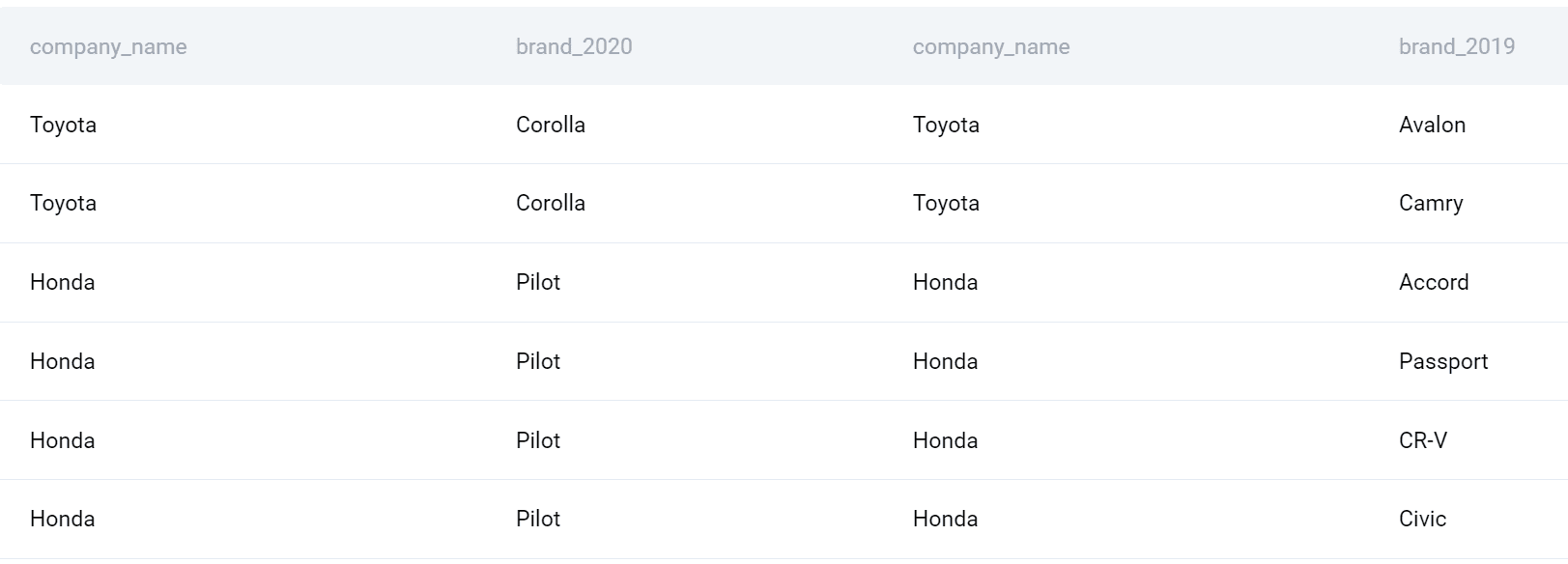
これでクエリを完成させることができます。 会社名を選択しましょう。 また、COUNT() 関数を使用して各年に発売された製品の数を見つけ、それを減算して差を求めます。 最後に、出力を会社ごとにグループ化し、さらに会社ごとにアルファベット順に並べ替えます。
これがクエリ全体です。
SELECT a.company_name, (COUNT(DISTINCT a.brand_2020)-COUNT(DISTINCT b.brand_2019)) AS net_products
FROM (SELECT company_name, product_name AS brand_2020 FROM car_launches WHERE YEAR = 2020) a
FULL OUTER JOIN (SELECT company_name, product_name AS brand_2019 FROM car_launches WHERE YEAR = 2019) b ON a.company_name = b.company_name
GROUP BY a.company_name
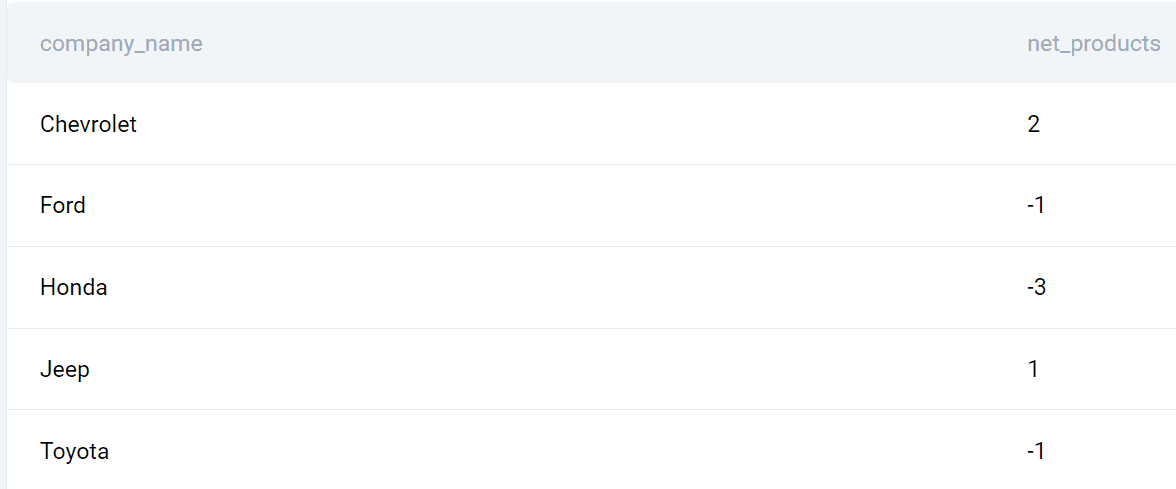
ORDER BY company_name;出力
企業のリストと、2020年と2019年に発売された製品の違いは次のとおりです。
5. クロスジョインの例
デロイトによるこの質問 は、CROSS JOIN がどのように機能するかを示すのに最適です。
最大 XNUMX つの数字
「数値の単一列が与えられた場合、数値のペア (x,y) と (y,x) が XNUMX つの異なる順列であると仮定して、XNUMX つの数値の考えられるすべての順列を検討します。 次に、順列ごとに、XNUMX つの数値の最大値を見つけます。
XNUMX つの列を出力します: 最初の数値、XNUMX 番目の数値、および XNUMX つの数値の最大値。
この質問では、数値のペア (x,y) と (y,x) が XNUMX つの異なる順列であると仮定して、XNUMX つの数値の考えられるすべての順列を見つけることが求められています。 次に、各順列の数値の最大値を見つける必要があります。
且つ
この質問により、XNUMX つの列を持つ XNUMX つのテーブルが得られます。
デロイト_ナンバーズ
| 数: | int型 |
Code
このコードは CROSS JOIN の例ですが、自己結合の例でもあります。
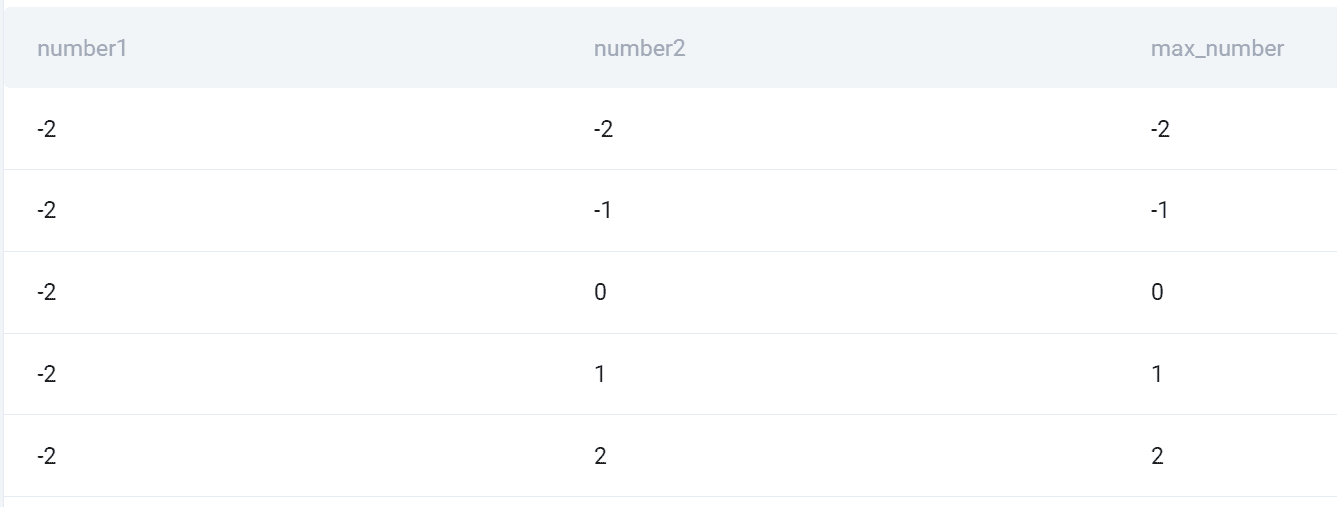
SELECT dn1.number AS number1, dn2.number AS number2, CASE WHEN dn1.number > dn2.number THEN dn1.number ELSE dn2.number END AS max_number
FROM deloitte_numbers AS dn1
CROSS JOIN deloitte_numbers AS dn2;
FROM でテーブルを参照し、別名を XNUMX つ付けます。 次に、CROSS JOIN の後にそれを参照し、テーブルに別の別名を与えることで、それ自体と CROSS JOIN します。
これでテーブルがXNUMXつあるのでXNUMXつを使えるようになります。 各テーブルから列番号を選択します。 次に、CASE ステートメントを使用して、XNUMX つの数値の最大値を表示する条件を設定します。
ここで CROSS JOIN が使用されるのはなぜですか? これは、すべてのテーブルのすべての行のすべての組み合わせを表示する SQL 結合の一種であることに注意してください。 まさにそれが質問の内容です!
出力
以下は、すべての組み合わせと XNUMX つの大きい方の番号のスナップショットです。
SQL 結合の使用方法がわかったので、問題はその知識をデータ サイエンスでどのように活用するかです。
SQL 結合は、データ探索、データ クリーニング、特徴エンジニアリングなどのデータ サイエンス タスクにおいて重要な役割を果たします。
SQL 結合を活用する方法の例をいくつか示します。
- データの結合: テーブルを結合すると、さまざまなデータ ソースをまとめて、複数のデータセット間の関係や相関関係を分析できるようになります。 たとえば、顧客テーブルをトランザクション テーブルと結合すると、顧客の行動や購入パターンについての洞察が得られます。
- データ検証: 結合を使用して、データの品質と整合性を検証できます。 異なるテーブルのデータを比較することで、不一致、欠損値、外れ値を特定できます。 これはデータのクリーニングに役立ち、分析に使用されるデータが正確で信頼できるものであることが保証されます。
- 機能エンジニアリング: 結合は、機械学習モデルの新しい機能を作成するのに役立ちます。 関連するテーブルを結合することで、意味のある情報を抽出し、データ内の重要な関係を捉える特徴を生成できます。 これにより、モデルの予測能力を強化できます。
- 集計と分析: 結合を使用すると、複数のテーブルにわたって複雑な集計と分析を実行できます。 さまざまなソースからのデータを組み合わせることで、データを包括的に把握し、貴重な洞察を得ることができます。 たとえば、売上テーブルを製品テーブルと結合すると、製品カテゴリまたは地域ごとの売上実績を分析するのに役立ちます。
すでに述べたように、結合の複雑さは構文には現れません。 構文が比較的単純であることがわかりました。
結合のベスト プラクティスもそれを反映しています。結合のベスト プラクティスはコーディング自体ではなく、結合が何を行うのか、どのように実行されるのかを考慮しているからです。
SQL の結合を最大限に活用するには、次のベスト プラクティスを考慮してください。
- データを理解する: データ内の構造と関係をよく理解してください。 これは、適切な結合の種類を選択し、一致する適切な列を選択するのに役立ちます。
- インデックスを使用する: テーブルが大きい場合、または頻繁に結合される場合は、結合に使用される列にインデックスを追加することを検討してください。 インデックスによりクエリのパフォーマンスが大幅に向上します。
- パフォーマンスに注意してください: 大きなテーブルや複数のテーブルを結合すると、計算コストが高くなる可能性があります。 データをフィルタリングし、適切な結合タイプを使用し、一時テーブルまたはサブクエリの使用を考慮して、クエリを最適化します。
- テストと検証: 結合結果が正しいことを確認するために、常に検証してください。 健全性チェックを実行し、結合されたデータが期待およびビジネス ロジックと一致していることを確認します。
SQL 結合は、データ サイエンティストが複数のソースからのデータを結合して分析できるようにする基本的な概念です。 さまざまな種類の SQL 結合を理解し、その構文をマスターし、効果的に活用することで、データ サイエンティストは貴重な洞察を引き出し、データ品質を検証し、データ主導の意思決定を推進できます。
その方法を XNUMX つの例で説明しました。 データ サイエンス プロジェクトで SQL と結合の力を活用し、より良い結果を達成できるかどうかは、あなた次第です。
ネイト・ロシディ データサイエンティストであり、製品戦略に携わっています。 彼はまた、分析を教える非常勤教授であり、 ストラタスクラッチ、データサイエンティストがトップ企業からの実際の面接の質問で面接の準備をするのを支援するプラットフォーム。 彼とつながる Twitter:StrataScratch or LinkedIn.
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/08/sql-data-science-understanding-leveraging-joins.html?utm_source=rss&utm_medium=rss&utm_campaign=sql-for-data-science-understanding-and-leveraging-joins
- :は
- :not
- :どこ
- $UP
- 1
- 11
- 12
- 13
- 2019
- 2020
- 7
- 8
- a
- 私たちについて
- アクセス
- データへのアクセス
- 正確な
- 達成する
- 越えて
- 追加
- 付属
- 後
- 再び
- 凝集
- 整列
- すべて
- 割り当てられました
- 許す
- 許可
- ことができます
- 沿って
- 既に
- また
- 常に
- 量
- 金額
- an
- 分析
- 分析論
- 分析します
- および
- 別の
- どれか
- 何でも
- 適切な
- です
- 記事
- AS
- At
- b
- ベース
- 基本
- BE
- なぜなら
- になる
- き
- さ
- BEST
- ベストプラクティス
- より良いです
- の間に
- 両言語で
- 持って来る
- 予算
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 計算する
- 計算された
- 呼ばれます
- 缶
- キャプチャー
- 場合
- カテゴリー
- 変更
- 変更
- 小切手
- 選択する
- 都市
- 市町村
- クリーニング
- コード
- コーディング
- コラム
- コラム
- COM
- 組み合わせ
- 組み合わせる
- 組み合わせ
- 結合
- comes
- コマンドと
- 企業
- 会社
- 比べ
- 比較
- 複雑な
- 複雑さ
- 複雑な
- 包括的な
- コンセプト
- 心配
- 条件
- お問合せ
- Connections
- 検討
- 考えると
- 変換
- 対応する
- 費用
- 作ります
- 作成
- Cross
- 重大な
- 顧客
- 顧客行動
- Customers
- データ
- データ品質
- データサイエンス
- データサイエンティスト
- データ駆動型の
- データベース
- データベースを追加しました
- データセット
- 意思決定
- 決定
- 定義
- によっては
- 設計
- 詳細
- DID
- 違い
- 異なります
- 明確な
- 見分けます
- do
- ありません
- そうではありません
- すること
- 行われ
- ドライブ
- e
- 各
- 前
- 容易
- 簡単に
- 効果的に
- ほかに
- 従業員
- 社員
- 力を与える
- enable
- 有効にする
- end
- エンジニアリング
- 高めます
- 確保
- 確実に
- 等しい
- 確立する
- さらに
- すべてのもの
- 正確に
- 例
- 例
- 期待
- 高価な
- 説明する
- 探査
- 余分な
- エキス
- 特徴
- 特徴
- 少数の
- フィールド
- 充填
- フィルタリング
- 確定する
- 最後に
- もう完成させ、ワークスペースに掲示しましたか?
- 発見
- 名
- 五
- フロート
- フォーカス
- フォロー中
- 次
- 外国の
- 発見
- AIとMoku
- 頻繁に
- から
- フロント
- フル
- 完全に
- function
- 基本的な
- さらに
- 利得
- 生成する
- 取得する
- 与える
- 与えられた
- 与える
- 与え
- ゴエス
- 行く
- 徐々に
- 素晴らしい
- グループ
- ガイド
- ハーネス
- 持ってる
- 持って
- he
- 重く
- 助けます
- 助け
- ことができます
- こちら
- より高い
- 最高
- 彼に
- 認定条件
- How To
- しかしながら
- HTTPS
- i
- 私は
- ID
- 識別子
- 識別する
- if
- 画像
- 重要
- 改善します
- in
- その他の
- include
- インデックス
- 情報
- 情報に基づく
- 洞察
- を取得する必要がある者
- インストルメンタル
- 整合性
- 興味がある
- インタビュー
- 面接の質問
- 記事執筆
- に
- IT
- ITS
- 自体
- join
- 参加した
- 参加
- ジョイン
- JPG
- ただ
- KDナゲット
- キー
- キーワード
- 知っている
- 知識
- 言語
- 大
- 後で
- 打ち上げ
- 起動
- 学習
- 最低
- 左
- 活用
- ような
- LINK
- リスト
- 少し
- ロジック
- 長い
- 見て
- LOOKS
- 機械
- 機械学習
- 製
- メイン
- make
- 作成
- 管理する
- 操作する
- マスタリング
- 一致
- マッチ
- マッチング
- me
- 意味のある
- 手段
- 言及した
- マージ
- マージ
- かもしれない
- ミラー
- ミラーイメージ
- 逃した
- 行方不明
- モデル
- 他には?
- 最も
- ずっと
- の試合に
- my
- 名
- 名
- ナチュラル
- 自然
- 必要
- 必要
- 必要とされる
- net
- 新作
- 新しい特徴
- いいえ
- 今
- 数
- 番号
- of
- 頻繁に
- on
- ONE
- の
- 反対
- 最適化
- or
- 注文
- 受注
- その他
- 私たちの
- でる
- 出力
- 足
- パターン
- 以下のために
- 実行する
- パフォーマンス
- 実行
- 実行する
- 場所
- 場所
- プラットフォーム
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイ
- お願いします
- 可能
- 電力
- 強力な
- 練習
- プラクティス
- 優先
- 準備
- 前
- 主要な
- 問題
- プロダクト
- 製品
- 東京大学大学院海洋学研究室教授
- プログラミング
- プロジェクト
- プロジェクト(実績作品)
- 提供します
- は、大阪で
- 購買
- 品質
- クエリ
- 質問
- 質問
- まれに
- リアル
- 記録
- リファレンス
- 参照
- 反映する
- 反映
- 地域
- 関連する
- の関係
- 相対的に
- リリース
- 関連した
- 信頼性のある
- 覚えています
- 要求
- REST
- 結果
- 結果
- return
- 収益
- 明らかにする
- 右
- 職種
- 円形
- s
- セールス
- salesforce
- 同じ
- 見ました
- 科学
- 科学者
- 科学者たち
- 二番
- と思われる
- 自己
- 別
- セッションに
- いくつかの
- shared
- 速記
- すべき
- 表示する
- ショーケース
- 示されました
- 表示
- 作品
- 著しく
- 同様の
- 単に
- 状況
- Snapshot
- So
- 溶液
- 解決する
- ソース
- 特定の
- SQL
- ステートメント
- 滞在
- 簡単な
- 戦略
- 構造
- 構造化された
- そのような
- 切り替え
- 構文
- T1
- テーブル
- トーク
- タスク
- ティーチング
- 一時的
- test
- それ
- アプリ環境に合わせて
- それら
- その後
- そこ。
- したがって、
- ボーマン
- 彼ら
- この
- 三
- 時間
- 役職
- 〜へ
- 一緒に
- ツールボックス
- 豊富なツール群
- top
- トータル
- トランザクション
- 治療
- 治療
- オン
- 2
- type
- わかる
- 理解する
- ユニーク
- アンロック
- us
- つかいます
- 中古
- users
- 使用されます
- 通常
- 活用する
- 検証
- 貴重な
- 価値観
- さまざまな
- 広大な
- 確認する
- 詳しく見る
- 可視化
- vs
- 欲しいです
- wanted
- 欲しい
- 望んでいる
- 仕方..
- we
- この試験は
- いつ
- which
- while
- 全体
- なぜ
- 意志
- 以内
- 言葉
- 作品
- 書きます
- 書かれた
- 間違った
- X
- 年
- 貴社
- あなたの
- あなた自身
- ゼファーネット
- ゼロ








