あなたがビジネス アナリストであれば、顧客の行動を理解することはおそらく最も重要な関心事の XNUMX つです。 顧客の購入決定の背後にある理由とメカニズムを理解することで、収益の増加を促進できます。 しかし、顧客の喪失(一般に「顧客の喪失」と呼ばれます) 顧客解約)常にリスクを伴います。 顧客が離れていく理由を洞察することは、利益と収益を維持するためにも同様に重要です。
機械学習 (ML) は貴重な洞察を提供しますが、機械学習 (ML) が導入されるまでは、顧客離れ予測モデルを構築するには ML の専門家が必要でした。 Amazon SageMaker キャンバス.
SageMaker Canvas は、コードを XNUMX 行も記述することなく、多くのビジネス上の問題を解決できる ML モデルを作成できるローコード/ノーコードのマネージド サービスです。 また、データ サイエンティストであるかのように、高度なメトリクスを使用してモデルを評価することもできます。
この投稿では、ビジネス アナリストが SageMaker Canvas で作成された分類チャーン モデルを評価し、理解する方法を示します。 高度な指標 タブ。 メトリクスについて説明し、より良いモデルのパフォーマンスを得るためにデータを処理する手法を示します。
前提条件
この投稿で説明されているタスクのすべてまたは一部を実装したい場合は、SageMaker Canvas にアクセスできる AWS アカウントが必要です。 参照する Amazon SageMaker Canvasを使用して、コードなしの機械学習で顧客離れを予測する SageMaker Canvas、チャーン モデル、データセットに関する基本を説明します。
モデル性能評価の概要
一般的なガイドラインとして、モデルのパフォーマンスを評価する必要がある場合は、新しいデータを受け取ったときにモデルが何かをどの程度正確に予測するかを測定しようとします。 この予測はと呼ばれます 推論。 まず既存のデータを使用してモデルをトレーニングし、次にモデルにまだ見ていないデータの結果を予測するように依頼します。 モデルがこの結果をどの程度正確に予測するかは、モデルのパフォーマンスを理解するために注目するものです。
モデルが新しいデータを見ていない場合、予測が良いか悪いかをどうやって知ることができるでしょうか? そのアイデアは、結果がすでにわかっている履歴データを実際に使用し、これらの値をモデルの予測値と比較することです。 これは、過去のトレーニング データの一部を保存しておき、モデルがそれらの値に対して予測した内容と比較できるようにすることで可能になります。
顧客離れの例 (カテゴリ別分類問題) では、多くの属性 (各レコードに XNUMX つ) を持つ顧客を記述する履歴データセットから始めます。 属性の XNUMX つは Churn と呼ばれ、True または False で、顧客がサービスを離れたかどうかを示します。 モデルの精度を評価するには、このデータセットを分割し、一方の部分 (トレーニング データセット) を使用してモデルをトレーニングし、もう一方の部分 (テスト データセット) で結果を予測する (顧客をチャーンとして分類するかどうか) ようにモデルに依頼します。 次に、モデルの予測をテスト データセットに含まれるグラウンド トゥルースと比較します。
高度なメトリクスの解釈
このセクションでは、モデルのパフォーマンスを理解するのに役立つ SageMaker Canvas の高度なメトリクスについて説明します。
混同行列
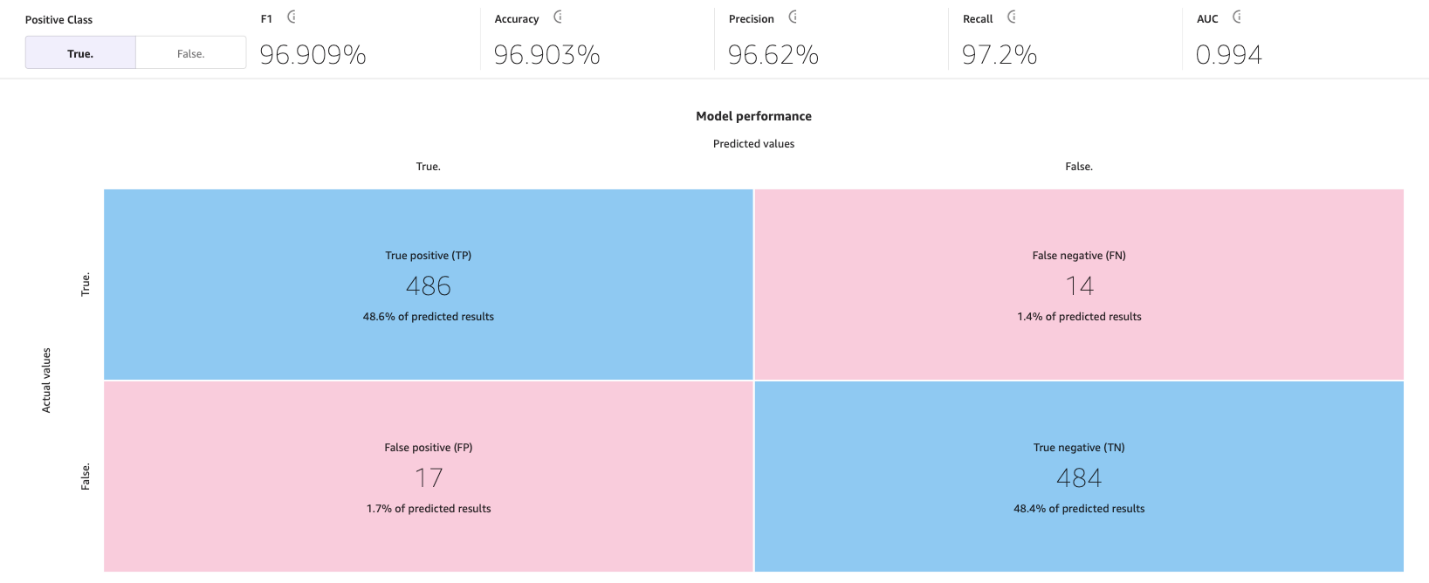
SageMaker Canvas は混同行列を使用して、モデルが予測を正しく生成するタイミングを視覚化するのに役立ちます。 混同マトリックスでは、予測値を実際の履歴 (既知の) 値と比較するように結果が整理されます。 次の例では、陽性ラベルと陰性ラベルを予測する XNUMX つのカテゴリの予測モデルに対して混同行列がどのように機能するかを説明します。
- 真陽性 – モデルは、真のラベルが陽性の場合に陽性を正しく予測しました
- 真陰性 – 真のラベルが陰性であった場合、モデルは陰性を正しく予測しました
- 偽陽性 – モデルは、真のラベルが陰性であるにもかかわらず、陽性を誤って予測しました
- 偽陰性 – 真のラベルが陽性であるにもかかわらず、モデルは誤って陰性を予測しました
次の画像は、XNUMX つのカテゴリの混同行列の例です。 チャーン モデルでは、実際の値はテスト データセットから取得され、予測値はモデルへの質問から取得されます。
正確さ
精度は、テスト セットのすべての行またはサンプルのうちの正しい予測の割合です。 これは、True として予測された真のサンプルと、正しく False として予測された偽サンプルを加えたものを、データセット内のサンプルの総数で割ったものです。
これは、モデルが何パーセント正しく予測したかを示すため、理解する必要がある最も重要なメトリクスの XNUMX つですが、場合によっては誤解を招く可能性があります。 例えば:
- クラスの不均衡 – データセット内のクラスが均等に分散されていない場合 (あるクラスのサンプル数が不均衡で、他のクラスのサンプル数が非常に少ない場合)、精度が誤解を招く可能性があります。 このような場合、各インスタンスの多数派クラスを単純に予測するモデルでも高い精度を達成できます。
- コスト重視の分類 – 一部のアプリケーションでは、クラスごとに誤分類のコストが異なる場合があります。 たとえば、薬物が症状を悪化させる可能性があるかどうかを予測する場合、偽陰性 (たとえば、実際には薬物が悪化するのに薬物が悪化しない可能性があると予測する) の方が、偽陽性 (たとえば、薬物が症状を悪化させる可能性があると予測する) よりもコストが高くなる可能性があります。実際にはそうでない場合)。
適合率、再現率、F1 スコア
精度は、すべての予測陽性 (TP + FP) のうちの真の陽性 (TP) の割合です。 実際に正しい肯定的な予測の割合を測定します。
リコールは、すべての実陽性 (TP + FN) のうちの真陽性 (TP) の割合です。 これは、モデルによって陽性と正しく予測された陽性インスタンスの割合を測定します。
F1 スコアは、精度と再現率を組み合わせて、それらの間のトレードオフのバランスをとる単一のスコアを提供します。 これは、精度と再現率の調和平均として定義されます。
F1 スコア = 2 * (適合率 * 再現率) / (適合率 + 再現率)
F1 スコアの範囲は 0 ~ 1 で、スコアが高いほどパフォーマンスが優れていることを示します。 完全な F1 スコア 1 は、モデルが完全な精度と完全な再現率の両方を達成していることを示し、スコア 0 は、モデルの予測が完全に間違っていることを示します。
F1 スコアは、モデルのパフォーマンスのバランスのとれた評価を提供します。 精度と再現率が考慮され、陽性インスタンスを正しく分類し、偽陽性と偽陰性を回避するモデルの能力を反映する、より有益な評価指標が提供されます。
たとえば、医療診断、不正行為の検出、センチメント分析では、F1 が特に関連性があります。 医療診断では、特定の病気や状態の存在を正確に特定することが非常に重要であり、偽陰性または偽陽性は重大な結果をもたらす可能性があります。 F1 スコアでは、精度 (陽性症例を正確に識別する能力) と再現率 (すべての陽性症例を見つける能力) の両方が考慮され、疾患の検出におけるモデルのパフォーマンスのバランスの取れた評価が提供されます。 同様に、不正検出では、実際の不正ケースの数が不正でないケース (不均衡なクラス) に比べて比較的少ないため、真陰性の数が多いため、精度だけでは誤解を招く可能性があります。 F1 スコアは、精度と再現率の両方を考慮して、不正なケースと不正でないケースの両方を検出するモデルの能力の包括的な尺度を提供します。 また、感情分析では、データセットの不均衡がある場合、肯定的な感情クラスのインスタンスを分類する際のモデルのパフォーマンスが精度に正確に反映されない可能性があります。
AUC(曲線の下の領域)
AUC メトリクスは、すべての分類しきい値で陽性クラスと陰性クラスを区別するバイナリ分類モデルの能力を評価します。 あ しきい値 は、モデルが 0 つの可能なクラスの間で決定を行うために使用される値であり、サンプルがクラスの一部である確率を二分決定に変換します。 AUC を計算するために、真陽性率 (TPR) と偽陽性率 (FPR) がさまざまなしきい値設定にわたってプロットされます。 TPR はすべての実陽性のうちの真陽性の割合を測定し、FPR はすべての実陰性のうち偽陽性の割合を測定します。 受信者動作特性 (ROC) 曲線と呼ばれる結果の曲線は、さまざまなしきい値設定での TPR と FPR を視覚的に表現します。 AUC 値は 1 ~ 1 の範囲で、ROC 曲線の下の領域を表します。 AUC 値が高いほどパフォーマンスが優れていることを示し、完全な分類子は AUC XNUMX を達成します。
次のプロットは、TPR を Y 軸、FPR を X 軸とした ROC 曲線を示しています。 曲線がプロットの左上隅に近づくほど、モデルによるデータのカテゴリへの分類が向上します。

明確にするために、例を見てみましょう。 不正検出モデルについて考えてみましょう。 通常、これらのモデルは不均衡なデータセットからトレーニングされます。 これは、通常、データセット内のほとんどすべてのトランザクションが不正ではなく、不正としてラベル付けされるトランザクションはわずかであるという事実によるものです。 この場合、精度だけではモデルのパフォーマンスを適切に把握できない可能性があります。これは、不正ではないケースの多さに大きく影響され、誤解を招くほど高い精度スコアが得られる可能性があるためです。
この場合、AUC は、不正なトランザクションと不正でないトランザクションを区別するモデルの能力の包括的な評価を提供するため、モデルのパフォーマンスを評価するためのより良い指標となります。 これは、さまざまな分類しきい値での真陽性率と偽陽性率の間のトレードオフを考慮して、より微妙な評価を提供します。
F1 スコアと同様に、データセットの不均衡がある場合に特に役立ちます。 これは、TPR と FPR の間のトレードオフを測定し、モデルが分布に関係なく XNUMX つのクラスをどの程度区別できるかを示します。 これは、一方のクラスが他方のクラスよりも大幅に小さい場合でも、ROC 曲線は両方のクラスを同等に考慮することで、バランスの取れた方法でモデルのパフォーマンスを評価することを意味します。
追加の重要なトピック
ML モデルのパフォーマンスを評価および改善するために利用できる重要なツールは、高度なメトリクスだけではありません。 データ準備、特徴量エンジニアリング、および特徴量影響分析は、モデル構築に不可欠な手法です。 これらのアクティビティは、生データから有意義な洞察を抽出し、モデルのパフォーマンスを向上させ、より堅牢で洞察力に富んだ結果をもたらす上で重要な役割を果たします。
データの準備と特徴エンジニアリング
特徴エンジニアリングは、生データから新しい変数 (特徴) を選択、変換、作成するプロセスであり、ML モデルのパフォーマンスを向上させる上で重要な役割を果たします。 利用可能なデータから最も関連性の高い変数または特徴を選択するには、モデルの予測能力に寄与しない無関係または冗長な特徴を削除する必要があります。 データ特徴を適切な形式に変換するには、スケーリング、正規化、欠損値の処理が含まれます。 そして最後に、既存のデータからの新しい特徴の作成は、数学的変換、さまざまな特徴の結合または相互作用、またはドメイン固有の知識からの新しい特徴の作成を通じて行われます。
特徴の重要性分析
SageMaker Canvas は、データセット内の各列がモデルに与える影響を説明する特徴重要度分析を生成します。 予測を生成すると、列の影響を確認して、各予測に最も大きな影響を与える列を特定できます。 これにより、どの機能が最終モデルの一部に値するのか、どの機能を破棄する必要があるのかがわかります。 列の影響度は、他の列と比較して、予測を行う際にその列がどの程度の重みを持っているかを示すパーセンテージ スコアです。 列の影響が 25% の場合、Canvas は、その列については 25%、その他の列については 75% として予測を重み付けします。
モデルの精度を向上させるためのアプローチ
モデルの精度を向上させる方法は複数ありますが、データ サイエンティストと ML 実践者は通常、前述のツールとメトリクスを使用して、このセクションで説明する XNUMX つのアプローチのいずれかに従います。
モデル中心のアプローチ
このアプローチでは、データは常に同じままであり、望ましい結果を満たすようにモデルを反復的に改善するために使用されます。 このアプローチで使用されるツールには次のものがあります。
- 関連する複数の ML アルゴリズムを試す
- アルゴリズムとハイパーパラメータの調整と最適化
- さまざまなモデルアンサンブル手法
- 事前トレーニング済みモデルの使用 (SageMaker が提供するさまざまな 組み込みまたは事前トレーニングされたモデル ML 実践者を支援するため)
- AutoML。SageMaker Canvas が舞台裏で行うものです ( Amazon SageMakerオートパイロット)、上記のすべてを包含します。
データ中心のアプローチ
このアプローチでは、データの準備、データ品質の向上、およびパフォーマンスを向上させるためのデータの反復変更に重点が置かれています。
- モデルのトレーニングに使用されるデータセットの統計の調査。探索的データ分析 (EDA) とも呼ばれます。
- データ品質の向上 (データクリーニング、欠損値の補完、外れ値の検出と管理)
- 機能選択
- 機能エンジニアリング
- データ増強
Canvas を使用したモデルのパフォーマンスの向上
まずはデータ中心のアプローチから始めます。 モデルのプレビュー機能を使用して、初期 EDA を実行します。 これにより、データ拡張の実行に使用できるベースラインが提供され、新しいベースラインが生成され、最終的には標準のビルド機能を使用したモデル中心のアプローチで最適なモデルが取得されます。
私たちは、使用 合成データセット 通信携帯電話キャリアから。 このサンプル データセットには 5,000 のレコードが含まれており、各レコードは 21 の属性を使用して顧客プロファイルを記述します。 参照する Amazon SageMaker Canvasを使用して、コードなしの機械学習で顧客離れを予測する 詳しい説明については、
データ中心のアプローチによるモデルのプレビュー
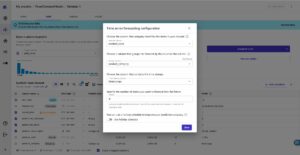
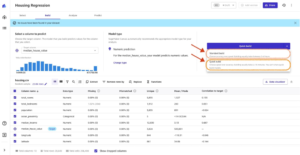
最初のステップとして、データセットを開き、「Churn?」として予測する列を選択し、選択してプレビュー モデルを生成します。 プレビューモデル.

プレビューモデル ペインには、プレビュー モデルの準備ができるまでの進行状況が表示されます。

モデルの準備が完了すると、SageMaker Canvas は特徴重要度分析を生成します。

最後に、完了すると、モデルへの影響を示す列のリストがペインに表示されます。 これらは、特徴が予測にどの程度関連しているかを理解するのに役立ちます。 列の影響度は、他の列と比較して、予測を行う際にその列がどの程度の重みを持っているかを示すパーセンテージ スコアです。 次の例では、Night Calls 列について、SageMaker Canvas は、その列については 4.04%、その他の列については 95.9% として予測を重み付けします。 値が大きいほど影響が大きくなります。
ご覧のとおり、プレビュー モデルの精度は 95.6% です。 データ中心のアプローチを使用してモデルのパフォーマンスを向上させてみましょう。 データの準備を実行し、特徴エンジニアリング手法を使用してパフォーマンスを向上させます。
次のスクリーンショットに示されているように、[電話] 列と [州] 列が予測に与える影響がはるかに小さいことがわかります。 したがって、この情報を次のフェーズであるデータ準備の入力として使用します。

SageMaker Canvas は、モデル構築のためにデータをクリーニング、変換、準備できる ML データ変換を提供します。 これらの変換はコードなしでデータセットで使用でき、モデルの構築前にデータに対して実行されたデータ準備の記録であるモデル レシピに追加されます。
使用するデータ変換はモデルの構築時に入力データを変更するだけであり、データセットや元のデータ ソースは変更しないことに注意してください。
SageMaker Canvas では、データの構築を準備するために次の変換を使用できます。
- 日時の抽出
- 列を削除
- 行をフィルタリングする
- 関数と演算子
- 行を管理する
- 列の名前を変更する
- 行を削除する
- 値を置換する
- 時系列データのリサンプリング
まずは、予測にほとんど影響を与えないことがわかった列を削除しましょう。
たとえば、このデータセットでは、電話番号は口座番号に相当します。他の口座の解約の可能性を予測するのには役に立たない、または有害ですらあります。 同様に、顧客の状態はモデルにあまり影響を与えません。 次の機能の選択を解除して、電話番号と州の列を削除しましょう。 列名.

ここで、追加のデータ変換と特徴エンジニアリングを実行してみましょう。
たとえば、以前の分析で、顧客への請求金額がチャーンに直接影響を与えることに気づきました。 したがって、日中、前夜、夜間、および国際線の料金、分数、および通話数を組み合わせて、顧客への合計料金を計算する新しい列を作成しましょう。 これを行うには、SageMaker Canvas のカスタム数式を使用します。

選ぶことから始めましょう 機能次に、数式テキストボックスに次のテキストを追加します。
(日中の通話数*日中の料金*日中の分数)+(前日の通話数*前日の料金*前日の分数)+(夜間通話数*夜間料金*夜間の分数)+(国際通話数*国際料金*国際時間分)
新しい列に名前 (たとえば、Total Charges) を付け、[請求額合計] を選択します。 Add プレビューが生成された後。 モデルのレシピは次のスクリーンショットのようになります。

このデータの準備が完了したら、新しいプレビュー モデルをトレーニングして、モデルが改善されたかどうかを確認します。 選ぶ プレビューモデル もう一度クリックすると、右下のペインに進行状況が表示されます。

トレーニングが終了すると、予測精度の再計算が開始され、新しい列の影響分析も作成されます。

そして最後に、プロセス全体が完了すると、前に表示したのと同じペインが新しいプレビュー モデルの精度で表示されます。 モデルの精度が 0.4% 増加していることがわかります (95.6% から 96%)。

ML ではモデルのトレーニングのプロセスに確率性が導入され、ビルドごとに異なる結果が生じる可能性があるため、前の画像の数値は実際の数値と異なる場合があります。
モデルを作成するためのモデル中心のアプローチ
Canvas には、モデルを構築するための XNUMX つのオプションがあります。
- 標準ビルド – 速度を犠牲にして精度を向上させる、最適化されたプロセスから最適なモデルを構築します。 Auto-ML を使用して、モデルの選択、ML ユースケースに関連するさまざまなアルゴリズムの試行、ハイパーパラメーターの調整、モデルの説明可能性レポートの作成など、ML のさまざまなタスクを自動化します。
- クイックビルド – 標準的なビルドと比較してほんのわずかな時間でシンプルなモデルを構築しますが、精度は速度と引き換えになります。 クイック モデルは、データ変更がモデルの精度に及ぼす影響をより迅速に理解するために反復処理を行う場合に役立ちます。
引き続き、標準的なビルド アプローチを使用してみましょう。
標準ビルド
前に見たように、標準ビルドでは、精度を最大化するために最適化されたプロセスから最適なモデルが構築されます。

チャーン モデルの構築プロセスには約 45 分かかります。 この間、Canvas は何百もの候補パイプラインをテストし、最適なモデルを選択します。 次のスクリーンショットでは、予想されるビルド時間と進行状況を確認できます。
標準のビルド プロセスを使用すると、ML モデルのモデル精度は 96.903% に向上し、大幅な改善となりました。

高度なメトリクスを調べる
を使用してモデルを調べてみましょう 高度な指標 タブ。 に 得点 タブを選択 高度な指標.

このページには、F1 スコア、精度、適合率、再現率、F1 スコア、および AUC の混同行列が高度な指標と併せて表示されます。

予測を生成する
メトリクスが良好に見えるようになったので、インタラクティブな予測を実行できます。 予測する タブで、バッチまたは単一 (リアルタイム) 予測のいずれかで。
XNUMXつのオプションがあります。
- このモデルを使用して、バッチまたは単一の予測を実行します。
- モデルを送信する Amazon Sagemaker スタジオ データサイエンティストと共有するため
クリーンアップ
将来の発生を避けるため セッション料金、SageMakerCanvasからログアウトします。

まとめ
SageMaker Canvas は、コーディングや専門的なデータ サイエンスや ML の専門知識を必要とせずに、モデルの構築と精度の評価を可能にし、モデルのパフォーマンスを向上させる強力なツールを提供します。 顧客離れモデルの作成の例で見てきたように、これらのツールを、高度なメトリクスを使用したデータ中心のアプローチとモデル中心のアプローチの両方と組み合わせることで、ビジネス アナリストは予測モデルを作成して評価できます。 ビジュアル インターフェイスを使用すると、正確な ML 予測を自分で生成することもできます。 参考資料に目を通して、これらの概念のうちのどれだけが他のタイプの ML 問題に適用できるかを確認することをお勧めします。
参考文献
著者について
 マルコス 米国フロリダに拠点を置く AWS シニア機械学習ソリューションアーキテクトです。 その役割において、彼は米国の新興企業のクラウド戦略を指導および支援し、高リスクの問題に対処し、機械学習ワークロードを最適化する方法についてのガイダンスを提供する責任を負っています。 彼は、クラウド ソリューション開発、機械学習、ソフトウェア開発、データセンター インフラストラクチャなどのテクノロジーに関して 25 年以上の経験を持っています。
マルコス 米国フロリダに拠点を置く AWS シニア機械学習ソリューションアーキテクトです。 その役割において、彼は米国の新興企業のクラウド戦略を指導および支援し、高リスクの問題に対処し、機械学習ワークロードを最適化する方法についてのガイダンスを提供する責任を負っています。 彼は、クラウド ソリューション開発、機械学習、ソフトウェア開発、データセンター インフラストラクチャなどのテクノロジーに関して 25 年以上の経験を持っています。
 インドラジット AWS エンタープライズ シニア ソリューション アーキテクトです。 彼の役割は、顧客がクラウド導入を通じてビジネス成果を達成できるよう支援することです。 彼は、マイクロサービス、サーバーレス、API、およびイベント駆動型パターンに基づいて最新のアプリケーション アーキテクチャを設計しています。 彼は、DataOps と MLOps のプラクティスとソリューションの導入を通じて、顧客と協力してデータ分析と機械学習の目標を実現しています。 Indrajit は、サミットや ASEAN ワークショップなどの AWS 公開イベントで定期的に講演し、いくつかの AWS ブログ投稿を公開し、AWS でのデータと機械学習に焦点を当てた顧客向けの技術ワークショップを開発しました。
インドラジット AWS エンタープライズ シニア ソリューション アーキテクトです。 彼の役割は、顧客がクラウド導入を通じてビジネス成果を達成できるよう支援することです。 彼は、マイクロサービス、サーバーレス、API、およびイベント駆動型パターンに基づいて最新のアプリケーション アーキテクチャを設計しています。 彼は、DataOps と MLOps のプラクティスとソリューションの導入を通じて、顧客と協力してデータ分析と機械学習の目標を実現しています。 Indrajit は、サミットや ASEAN ワークショップなどの AWS 公開イベントで定期的に講演し、いくつかの AWS ブログ投稿を公開し、AWS でのデータと機械学習に焦点を当てた顧客向けの技術ワークショップを開発しました。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://aws.amazon.com/blogs/machine-learning/is-your-model-good-a-deep-dive-into-amazon-sagemaker-canvas-advanced-metrics/
- :持っている
- :は
- :not
- :どこ
- 000
- 1
- 100
- 1239
- 25
- 420
- a
- 能力
- 私たちについて
- 豊富
- アクセス
- 精度
- 正確な
- 正確にデジタル化
- 達成する
- 達成
- 達成する
- 越えて
- 活動
- 実際の
- 実際に
- 加えます
- 追加されました
- NEW
- 住所
- 十分に
- 養子縁組
- 高度な
- 後
- 再び
- に対して
- アルゴリズム
- すべて
- ことができます
- 一人で
- 既に
- また
- 常に
- Amazon
- アマゾンセージメーカー
- Amazon SageMaker キャンバス
- Amazon Webサービス
- 量
- an
- 分析
- アナリスト
- アナリスト
- 分析論
- および
- どれか
- API
- 申し込み
- 申し込む
- アプローチ
- アプローチ
- です
- AREA
- 周りに
- 整えられた
- AS
- アセアン
- 評価する
- 評価
- 支援する
- At
- 属性
- 自動化する
- 利用できます
- 避ける
- AWS
- 軸
- 悪い
- バランス
- ベース
- ベースライン
- の基礎
- BE
- なぜなら
- き
- 始まる
- 背後に
- 舞台裏で
- さ
- BEST
- より良いです
- の間に
- ブログ
- ブログの投稿
- 両言語で
- ビルド
- 建物
- 構築します
- ビジネス
- 焙煎が極度に未発達や過発達のコーヒーにて、クロロゲン酸の味わいへの影響は強くなり、金属を思わせる味わいと乾いたマウスフィールを感じさせます。
- by
- 計算する
- 呼ばれます
- コール
- 缶
- 候補者
- キャンバス
- キャプチャー
- これ
- 場合
- 例
- カテゴリ
- センター
- 変更
- 特性
- チャージ
- 荷担した
- 課金
- 選択する
- 選択する
- class
- クラス
- 分類
- 分類します
- クリーニング
- クローザー
- クラウド
- クラウドの採用
- コード
- コーディング
- コラム
- コラム
- 組み合わせ
- 結合
- 来ます
- 一般に
- 比較します
- 比べ
- コンプリート
- 完全に
- 包括的な
- コンセプト
- 条件
- 混乱
- 結果
- 考えると
- 考慮する
- 含まれている
- 含まれています
- 続ける
- 貢献する
- 変換
- コーナー
- 正しい
- 費用
- 高額で
- カバー
- 作ります
- 作成した
- 作成
- 創造
- 重大な
- 曲線
- カスタム
- 顧客
- 顧客行動
- Customers
- データ
- データ分析
- データ分析
- データセンター
- データの準備
- データ品質
- データサイエンス
- データサイエンティスト
- データセット
- 中
- 取引
- 決定
- 決定
- 深いです
- ディープダイブ
- 定義済みの
- 説明する
- 記載された
- 説明
- 値する
- デザイン
- 希望
- 検出
- 発展した
- 開発
- 診断
- 異なる
- 異なります
- 区別する
- 直接
- 話し合います
- 議論する
- 病気
- 見分けます
- 配布
- ディストリビューション
- 分割された
- do
- ありません
- そうではありません
- 行われ
- 落ちる
- 薬
- 原因
- 間に
- 各
- 前
- どちら
- 権限を与え
- enable
- 使用可能
- 可能
- 包含する
- 奨励する
- エンジニアリング
- 強化
- Enterprise
- 平等に
- 同等の
- 特に
- 本質的な
- エーテル(ETH)
- 評価する
- 評価します
- 評価
- 前夜
- さらに
- 均等に
- イベント
- あらゆる
- 例
- 交換した
- 既存の
- 予想される
- 体験
- 専門知識
- 専門家
- 説明する
- 説明可能
- 説明
- 探索的データ分析
- 探る
- f1
- 容易にする
- 実際
- false
- 特徴
- 特徴
- 少数の
- ファイナル
- 最後に
- もう完成させ、ワークスペースに掲示しましたか?
- 名
- フロリダ
- フォーカス
- 焦点を当て
- フォロー中
- 形式でアーカイブしたプロジェクトを保存します.
- 式
- 発見
- 分数
- 詐欺
- 不正検出
- 不正な
- から
- フル
- 機能性
- 未来
- 獲得
- 生成する
- 生成された
- 生成
- 生成
- 受け
- 与える
- Go
- 目標
- 良い
- 陸上
- 成長性
- ガイダンス
- ハンドリング
- 持ってる
- he
- 重く
- 助けます
- ことができます
- ハイ
- リスクが高い
- より高い
- 彼の
- 歴史的
- 認定条件
- How To
- しかしながら
- HTML
- HTTPS
- 何百
- ハイパーパラメータ調整
- アイデア
- 識別する
- 識別する
- 識別
- if
- 画像
- 画像
- 影響
- 実装する
- 重要性
- 重要
- 改善します
- 改善されました
- 改善
- 改善
- in
- その他の
- include
- 含ま
- 含めて
- 間違って
- 増加した
- 示す
- を示し
- 示します
- 影響を受け
- 情報
- 有益な
- インフラ関連事業
- 初期
- 洞察力のある
- 洞察
- 相互作用
- 相互作用的
- インタフェース
- に
- 紹介します
- 概要
- 問題
- IT
- ITS
- JPG
- ただ
- キー
- 知っている
- 知識
- 既知の
- ラベル
- ラベル
- つながる
- 主要な
- 学習
- コメントを残す
- 左
- less
- ような
- 尤度
- LINE
- リスト
- 少し
- ログ
- 見て
- 損失
- ロー
- 下側
- 機械
- 機械学習
- 大多数
- make
- 作成
- マネージド
- 管理
- 方法
- 多くの
- 数学的
- マトリックス
- 最大化します
- 五月..
- 意味する
- 意味のある
- 手段
- だけど
- 措置
- メカニズム
- 医療の
- 大会
- メソッド
- メトリック
- メトリック
- マイクロサービス
- かもしれない
- 分
- 誤解を招く
- 行方不明
- ML
- MLOps
- モバイル
- 携帯電話
- モデル
- モダン
- 修正する
- 他には?
- 最も
- ずっと
- の試合に
- 名
- 必要
- 必要とされる
- 負
- ネガ
- 新作
- 新しい特徴
- 次の
- 夜
- 知らせ..
- 今
- 数
- 番号
- 観察する
- 入手する
- of
- オファー
- on
- ONE
- もの
- の
- 開いた
- オペレーティング
- 最適化
- 最適化
- オプション
- or
- 組織
- オリジナル
- その他
- その他
- 私たちの
- でる
- 結果
- 成果
- が
- 自分の
- ページ
- ペイン
- 部
- 特に
- パターン
- 割合
- 完璧
- 実行する
- パフォーマンス
- 実行
- 相
- 電話
- プラトン
- プラトンデータインテリジェンス
- プラトデータ
- プレイ
- 演劇
- さらに
- ポーズ
- 正の
- 可能
- ポスト
- 投稿
- 電力
- 強力な
- プラクティス
- 精度
- 予測する
- 予測
- 予測
- 予測
- 予測
- 予測
- 準備
- 準備
- プレゼンス
- プレビュー
- 前
- 確率
- 多分
- 問題
- 問題
- プロセス
- プロフィール
- 利益
- 進捗
- 割合
- 提供します
- は、大阪で
- 提供
- 公共
- 公表
- 購入
- 品質
- クイック
- すぐに
- レート
- Raw
- 生データ
- 準備
- への
- 実現する
- 理由は
- レシピ
- 記録
- 記録
- リファレンス
- 言及
- 反映する
- 反映
- 関係なく
- 定期的に
- 関係
- 相対的に
- 関連した
- 残っている
- 削除します
- 除去
- レポート
- 表現
- 表し
- 責任
- 結果として
- 結果
- 収入
- 収入の伸び
- 右
- リスク
- 堅牢な
- 職種
- ラン
- セージメーカー
- 同じ
- サンプル データセット
- 見ました
- スケーリング
- シーン
- 科学
- 科学者
- 科学者たち
- スコア
- スコア
- セクション
- 見て
- 見て
- 選択
- 選択
- 感情
- シリーズ
- サーバレス
- サービス
- サービス
- セッションに
- 設定
- 設定
- いくつかの
- シェアする
- すべき
- 表示する
- 示す
- 作品
- 重要
- 著しく
- 同様に
- 簡単な拡張で
- 単に
- より小さい
- So
- ソフトウェア
- ソフトウェア開発
- 溶液
- ソリューション
- 解決する
- 一部
- 何か
- ソース
- スピークス
- 専門の
- 特定の
- スピード
- split
- 標準
- start
- スタートアップ
- 都道府県
- 統計
- 手順
- 戦略
- そのような
- 適当
- サミット
- 取り
- 取得
- タスク
- 技術的
- テクニック
- テクノロジー
- 電気通信
- 言う
- test
- テスト
- より
- それ
- エリア
- 基礎
- アプリ環境に合わせて
- それら
- その後
- そこ。
- したがって、
- ボーマン
- 彼ら
- 物事
- 考える
- この
- それらの
- しきい値
- 介して
- 時間
- 時系列
- 〜へ
- 豊富なツール群
- top
- トータル
- に向かって
- tp
- TPR
- トレーニング
- 訓練された
- トレーニング
- 取引
- 最適化の適用
- 変換
- 変換
- 変換
- トランスフォーム
- true
- 真実
- 試します
- 2
- 下
- わかる
- 理解する
- まで
- us
- つかいます
- 使用事例
- 中古
- 使用されます
- 通常
- 貴重な
- 値
- 価値観
- さまざまな
- 非常に
- ました
- we
- ウェブ
- Webサービス
- 重さ
- 重量
- WELL
- した
- この試験は
- いつ
- which
- while
- 全体
- なぜ
- 意志
- 無し
- 作品
- ワークショップ
- でしょう
- 書き込み
- 間違った
- X
- 年
- 貴社
- あなたの
- ゼファーネット