אגמי נתונים המופעלים על ידי AWS, הנתמכים על ידי זמינות ללא תחרות של שירות אחסון פשוט של אמזון (Amazon S3), יכול להתמודד עם קנה המידה, הזריזות והגמישות הנדרשים כדי לשלב גישות שונות של נתונים וניתוח. ככל שאגמי הנתונים גדלו בגודלם והתבגרו בשימוש, ניתן להשקיע כמות משמעותית של מאמץ כדי לשמור על התאמה של הנתונים לאירועים עסקיים. כדי להבטיח עדכון של קבצים באופן עקבי מבחינה עסקית, מספר הולך וגדל של לקוחות משתמשים בפורמטים של טבלאות עסקאות בקוד פתוח כגון אפאצ'י קרח, אפאצ'י הודי, ו Linux Foundation Delta Lake שעוזר לך לאחסן נתונים עם שיעורי דחיסה גבוהים, להתממש באופן טבעי עם האפליקציות והמסגרות שלך ולפשט את עיבוד הנתונים המצטבר באגמי נתונים שנבנו על Amazon S3. פורמטים אלו מאפשרים עסקאות ACID (אטומיות, עקביות, בידוד, עמידות), העלאות ומחיקות ותכונות מתקדמות כגון מסע בזמן ותצלומי מצב שהיו זמינים בעבר רק במחסני נתונים. כל פורמט אחסון מיישם את הפונקציונליות הזו בדרכים מעט שונות; להשוואה, עיין בחירת פורמט טבלה פתוחה עבור אגם הנתונים העסקאות שלך ב-AWS.
ב2023, AWS הודיעה על זמינות כללית עבור Apache Iceberg, Apache Hudi ו-Linux Foundation Delta Lake ב אמזון אתנה עבור אפאצ'י ספארק, אשר מסיר את הצורך בהתקנת מחבר נפרד או תלות קשורות וניהול גרסאות, ומפשטת את שלבי התצורה הנדרשים לשימוש במסגרות אלו.
בפוסט זה, אנו מראים לך כיצד להשתמש ב-Spark SQL ב אמזונה אתנה מחברות ועבודה עם פורמטים של שולחן Iceberg, Hudi ו- Delta Lake. אנו מדגימים פעולות נפוצות כגון יצירת מסדי נתונים וטבלאות, הכנסת נתונים לטבלאות, שאילתות נתונים והתבוננות בצילומי מצב של הטבלאות באמזון S3 באמצעות Spark SQL באתנה.
תנאים מוקדמים
השלם את התנאים המוקדמים הבאים:
הורד וייבא מחברות לדוגמה מאמזון S3
כדי לעקוב אחריהם, הורד את המחברות הנדונות בפוסט זה מהמיקומים הבאים:
לאחר הורדת המחברות, ייבא אותן לסביבת Athena Spark שלך על ידי ביצוע ה- כדי לייבא מחברת קטע ב ניהול קבצי מחברת.
נווט לקטע פתיחה ספציפי של פורמט טבלה
אם אתה מעוניין בפורמט טבלת אייסברג, נווט אל עבודה עם שולחנות Apache Iceberg סָעִיף.
אם אתה מעוניין בפורמט טבלת Hudi, נווט אל עבודה עם טבלאות Apache Hudi סָעִיף.
אם אתה מעוניין בפורמט טבלה של Delta Lake, נווט אל עבודה עם טבלאות Delta Lake של בסיס Linux סָעִיף.
עבודה עם שולחנות Apache Iceberg
בעת שימוש במחברות Spark ב- Athena, תוכל להריץ שאילתות SQL ישירות מבלי שתצטרך להשתמש ב- PySpark. אנו עושים זאת באמצעות קסמי תאים, שהם כותרות מיוחדות בתא מחברת שמשנות את התנהגות התא. עבור SQL, אנו יכולים להוסיף את %%sql magic, אשר יפרש את כל תוכן התא כמשפט SQL שיופעל על Athena.
בחלק זה, אנו מראים כיצד ניתן להשתמש ב-SQL ב-Apache Spark עבור Athena כדי ליצור, לנתח ולנהל טבלאות Apache Iceberg.
הגדר הפעלה של מחברת
על מנת להשתמש ב- Apache Iceberg באתנה, בזמן יצירה או עריכה של הפעלה, בחר את ה אפאצ'י קרח אפשרות על ידי הרחבת ה נכסי Apache Spark סָעִיף. זה יאכלס מראש את המאפיינים כפי שמוצג בצילום המסך הבא.
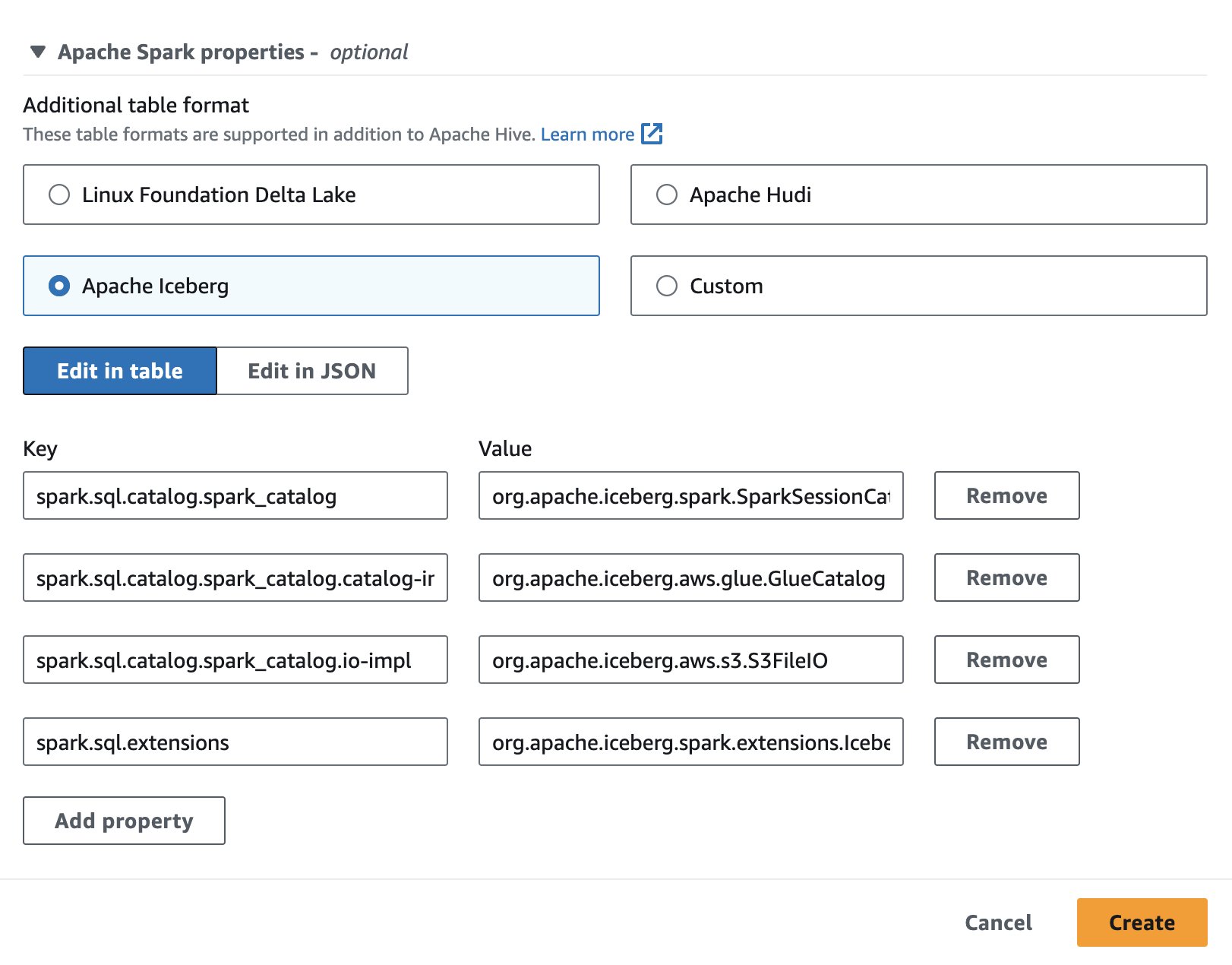
לשלבים, ראה עריכת פרטי הפגישה or יצירת מחברת משלך.
הקוד המשמש בסעיף זה זמין ב- SparkSQL_iceberg.ipynb קובץ לעקוב.
צור מסד נתונים וטבלת אייסברג
ראשית, אנו יוצרים מסד נתונים בקטלוג הנתונים של AWS Glue Data. עם ה-SQL הבא, נוכל ליצור מסד נתונים בשם icebergdb:
לאחר מכן, במסד הנתונים icebergdb, אנו יוצרים שולחן אייסברג בשם noaa_iceberg מצביע על מיקום באמזון S3 שבו נטען את הנתונים. הפעל את ההצהרה הבאה והחלף את המיקום s3://<your-S3-bucket>/<prefix>/ עם דלי S3 והקידומת שלך:
הכנס נתונים לטבלה
כדי לאכלס את noaa_iceberg שולחן אייסברג, אנו מכניסים נתונים משולחן הפרקט sparkblogdb.noaa_pq שנוצרה כחלק מהדרישות המוקדמות. אתה יכול לעשות זאת באמצעות an להכניס לתוך הצהרה בספארק:
לחלופין, ניתן להשתמש צור טבלה כבחירה עם הסעיף USING iceberg כדי ליצור טבלת Iceberg ולהכניס נתונים מטבלת מקור בשלב אחד:
שאילתה בטבלת אייסברג
כעת, כשהנתונים מוכנסים לטבלת Iceberg, אנו יכולים להתחיל לנתח אותם. בואו נריץ Spark SQL כדי למצוא את הטמפרטורה המינימלית שנרשמה לפי שנה עבור ה- 'SEATTLE TACOMA AIRPORT, WA US' מיקום:
אנחנו מקבלים את הפלט הבא.
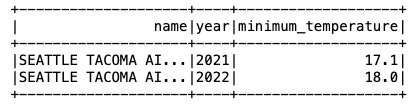
עדכן נתונים בטבלת Iceberg
בואו נסתכל כיצד לעדכן נתונים בטבלה שלנו. אנחנו רוצים לעדכן את שם התחנה 'SEATTLE TACOMA AIRPORT, WA US' ל 'Sea-Tac'. באמצעות Spark SQL, נוכל להריץ קובץ עדכון הצהרה נגד שולחן הקרח:
לאחר מכן נוכל להריץ את שאילתת ה-SELECT הקודמת כדי למצוא את הטמפרטורה המינימלית שנרשמה עבור 'Sea-Tac' מיקום:
אנו מקבלים את התפוקה הבאה.

קבצי נתונים קומפקטיים
פורמטים של טבלה פתוחים כמו Iceberg פועלים על ידי יצירת שינויים בדלתא באחסון הקבצים, ומעקב אחר גרסאות השורות דרך קובצי מניפסט. יותר קובצי נתונים מובילים ליותר מטא נתונים המאוחסנים בקובצי מניפסט, וקבצי נתונים קטנים גורמים לרוב לכמות מיותרת של מטא נתונים, וכתוצאה מכך שאילתות פחות יעילות ועלויות גישה גבוהות יותר של Amazon S3. הפעלת אייסברג'ס rewrite_data_files ההליך ב-Spark for Athena יגבש קבצי נתונים, תוך שילוב של קבצי שינוי דלתא קטנים רבים לקבוצה קטנה יותר של קבצי Parquet המותאמים לקריאה. דחיסה של קבצים מאיצה את פעולת הקריאה בעת שאילתה. כדי להפעיל דחיסה על הטבלה שלנו, הפעל את ה-Spark SQL הבא:
rewrite_data_files מציע אפשרויות כדי לציין את אסטרטגיית המיון שלך, שיכולה לעזור לארגן מחדש ולצמצם נתונים.
רשימת תמונות טבלה
כל פעולת כתיבה, עדכון, מחיקה, העלאה ודחיסה בטבלת Iceberg יוצרת תמונת מצב חדשה של טבלה תוך שמירה על הנתונים והמטא-נתונים הישנים לבידוד תמונת מצב ומסע בזמן. כדי לרשום את התמונות של טבלת Iceberg, הפעל את הצהרת Spark SQL הבאה:
פג תוקפם של תמונות ישנות
תמונות מצב שפג תוקפן מומלץ באופן קבוע כדי למחוק קבצי נתונים שאינם נחוצים עוד, וכדי לשמור על גודל המטא נתונים של הטבלה. זה לעולם לא יסיר קבצים שעדיין נדרשים על ידי תמונת מצב שלא פג. ב-Spark for Athena, הפעל את ה-SQL הבא כדי לפוג את תוקפם של תמונות מצב של הטבלה icebergdb.noaa_iceberg שישנים יותר מחותמת זמן מסוימת:
שים לב שערך חותמת הזמן מצוין כמחרוזת בפורמט yyyy-MM-dd HH:mm:ss.fff. הפלט ייתן ספירה של מספר הנתונים והמטא נתונים שנמחקו.
שחרר את הטבלה ואת מסד הנתונים
אתה יכול להריץ את ה-Spark SQL הבא כדי לנקות את טבלאות Iceberg והנתונים הקשורים באמזון S3 מתרגיל זה:
הפעל את ה-Spark SQL הבא כדי להסיר את מסד הנתונים icebergdb:
למידע נוסף על כל הפעולות שתוכל לבצע על שולחנות אייסברג באמצעות Spark for Athena, עיין שאילתות ניצוץ ו נהלי ניצוץ בתיעוד אייסברג.
עבודה עם טבלאות Apache Hudi
לאחר מכן, אנו מראים כיצד ניתן להשתמש ב-SQL ב-Spark עבור Athena כדי ליצור, לנתח ולנהל טבלאות Apache Hudi.
הגדר הפעלה של מחברת
על מנת להשתמש ב- Apache Hudi באתנה, בזמן יצירה או עריכה של הפעלה, בחר את ה אפאצ'י הודי אפשרות על ידי הרחבת ה נכסי Apache Spark סָעִיף.
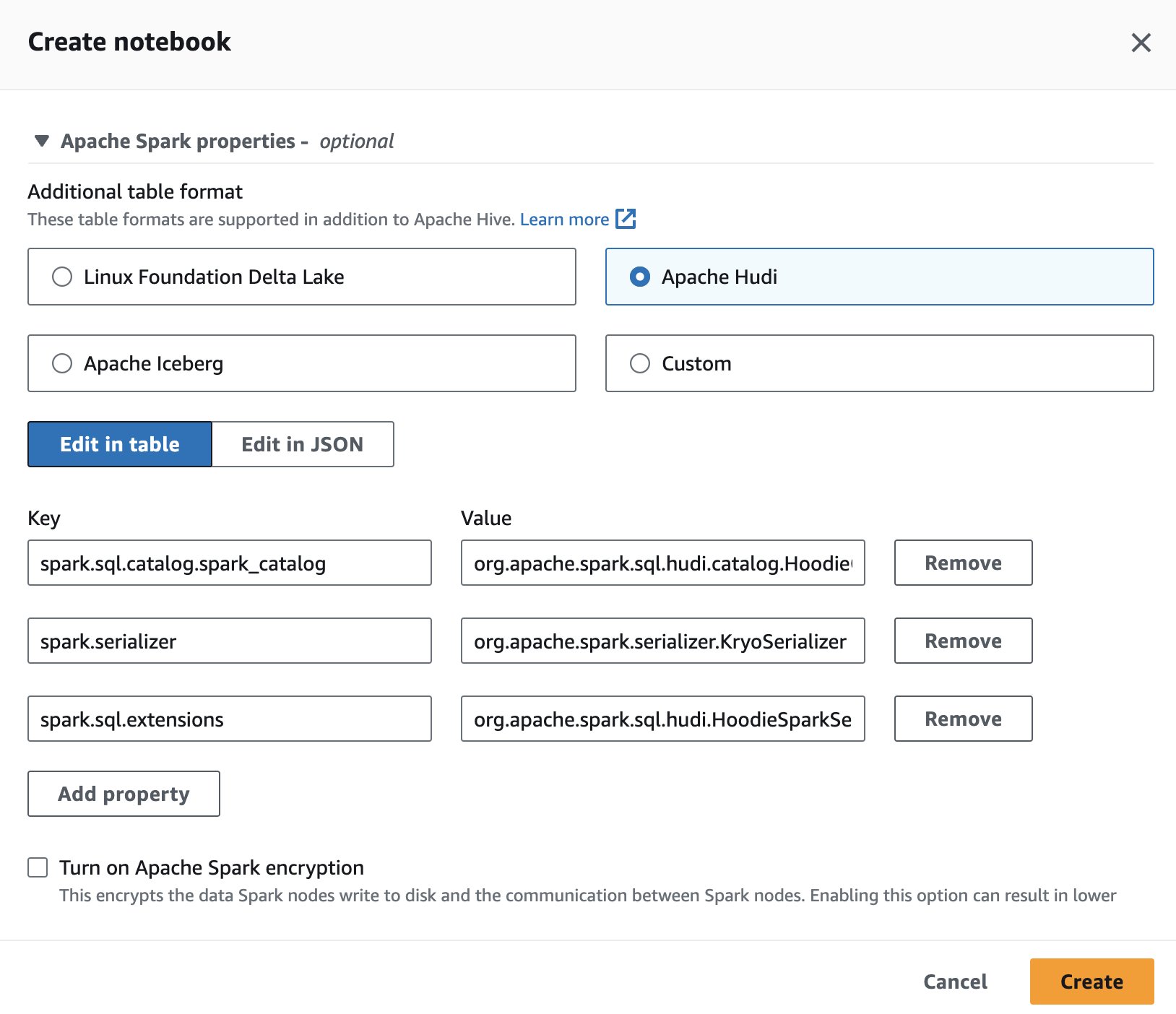
לשלבים, ראה עריכת פרטי הפגישה or יצירת מחברת משלך.
הקוד המשמש בסעיף זה אמור להיות זמין ב- SparkSQL_hudi.ipynb קובץ לעקוב.
צור מסד נתונים וטבלת Hudi
ראשית, אנו יוצרים מסד נתונים בשם hudidb זה יאוחסן בקטלוג נתוני הדבק של AWS ואחריו יצירת טבלת Hudi:
אנו יוצרים טבלת Hudi המצביעה על מיקום באמזון S3 בו נטען את הנתונים. שימו לב שהטבלה היא של העתק על כתיבה סוּג. זה מוגדר על ידי type= 'cow' בטבלה DDL. הגדרנו תחנה ותאריך כמפתחות ראשיים מרובים ו-preCombinedField כשנה. כמו כן, השולחן מחולק לפי שנה. הפעל את ההצהרה הבאה והחלף את המיקום s3://<your-S3-bucket>/<prefix>/ עם דלי S3 והקידומת שלך:
הכנס נתונים לטבלה
כמו עם אייסברג, אנחנו משתמשים ב- להכניס לתוך הצהרה כדי לאכלס את הטבלה על ידי קריאת נתונים מה- sparkblogdb.noaa_pq טבלה שנוצרה בפוסט הקודם:
שאל את טבלת ההודי
כעת לאחר יצירת הטבלה, הבה נריץ שאילתה כדי למצוא את הטמפרטורה המקסימלית שנרשמה עבור 'SEATTLE TACOMA AIRPORT, WA US' מיקום:
עדכן נתונים בטבלת Hudi
בואו נשנה את שם התחנה 'SEATTLE TACOMA AIRPORT, WA US' ל 'Sea–Tac'. אנחנו יכולים להריץ הצהרת UPDATE על Spark עבור Athena עדכון הרישומים של ה noaa_hudi שולחן:
אנו מריצים את שאילתת ה-SELECT הקודמת כדי למצוא את הטמפרטורה המקסימלית שנרשמה עבור 'Sea-Tac' מיקום:
הפעל שאילתות מסע בזמן
אנו יכולים להשתמש בשאילתות מסע בזמן ב-SQL על Athena כדי לנתח תצלומי מצב של נתונים מהעבר. לדוגמה:
שאילתה זו בודקת את נתוני הטמפרטורה של נמל התעופה בסיאטל נכון לזמן מסוים בעבר. סעיף חותמת הזמן מאפשר לנו לנסוע אחורה מבלי לשנות את הנתונים הנוכחיים. שים לב שערך חותמת הזמן מצוין כמחרוזת בפורמט yyyy-MM-dd HH:mm:ss.fff.
מטב את מהירות השאילתה באמצעות אשכולות
כדי לשפר את ביצועי השאילתה, אתה יכול לבצע קיבוץ בטבלאות Hudi באמצעות SQL ב-Spark עבור Athena:
שולחנות קומפקטיים
דחיסה הוא שירות טבלאות המופעל על ידי Hudi במיוחד בטבלאות מיזוג בזמן קריאה (MOR) כדי למזג עדכונים מקובצי יומן רישום מבוססי שורות לקובץ הבסיס המתאים המבוסס על עמודים מעת לעת כדי לייצר גרסה חדשה של קובץ הבסיס. דחיסה אינה חלה על טבלאות Copy On Write (COW) והיא חלה רק על טבלאות MOR. אתה יכול להריץ את השאילתה הבאה ב-Spark עבור Athena כדי לבצע דחיסה בטבלאות MOR:
שחרר את הטבלה ואת מסד הנתונים
הפעל את ה-Spark SQL הבא כדי להסיר את טבלת Hudi שיצרת והנתונים המשויכים ממיקום Amazon S3:
הפעל את ה-Spark SQL הבא כדי להסיר את מסד הנתונים hudidb:
כדי ללמוד על כל הפעולות שתוכל לבצע בטבלאות Hudi באמצעות Spark for Athena, עיין SQL DDL ו נהלים בתיעוד ההודי.
עבודה עם טבלאות Delta Lake של בסיס Linux
לאחר מכן, אנו מראים כיצד ניתן להשתמש ב-SQL ב-Spark עבור Athena כדי ליצור, לנתח ולנהל טבלאות Delta Lake.
הגדר הפעלה של מחברת
על מנת להשתמש ב-Delta Lake ב-Spark for Athena, בזמן יצירה או עריכה של הפעלה, בחר Linux Foundation Delta Lake על ידי הרחבת ה- נכסי Apache Spark סָעִיף.
לשלבים, ראה עריכת פרטי הפגישה or יצירת מחברת משלך.
הקוד המשמש בסעיף זה אמור להיות זמין ב- SparkSQL_delta.ipynb קובץ לעקוב.
צור מסד נתונים וטבלת Delta Lake
בסעיף זה, אנו יוצרים מסד נתונים בקטלוג הנתונים של AWS Glue Data. באמצעות SQL הבא, נוכל ליצור מסד נתונים בשם deltalakedb:
לאחר מכן, במסד הנתונים deltalakedb, אנו יוצרים שולחן Delta Lake בשם noaa_delta מצביע על מיקום באמזון S3 שבו נטען את הנתונים. הפעל את ההצהרה הבאה והחלף את המיקום s3://<your-S3-bucket>/<prefix>/ עם דלי S3 והקידומת שלך:
הכנס נתונים לטבלה
אנו משתמשים ב- להכניס לתוך הצהרה כדי לאכלס את הטבלה על ידי קריאת נתונים מה- sparkblogdb.noaa_pq טבלה שנוצרה בפוסט הקודם:
אתה יכול גם להשתמש ב-CREATE TABLE AS SELECT כדי ליצור טבלת Delta Lake ולהוסיף נתונים מטבלת מקור בשאילתה אחת.
שאילתה בטבלה של אגם דלתא
כעת, כשהנתונים מוכנסים לטבלת Delta Lake, אנו יכולים להתחיל לנתח אותם. בואו נריץ Spark SQL כדי למצוא את הטמפרטורה המינימלית שנרשמה עבור 'SEATTLE TACOMA AIRPORT, WA US' מיקום:
עדכן נתונים בטבלת אגם דלתא
בואו נשנה את שם התחנה 'SEATTLE TACOMA AIRPORT, WA US' ל 'Sea–Tac'. אנחנו יכולים להפעיל א עדכון הצהרה על Spark עבור אתנה לעדכן את הרשומות של noaa_delta שולחן:
נוכל להריץ את שאילתת ה-SELECT הקודמת כדי למצוא את הטמפרטורה המינימלית שנרשמה עבור 'Sea-Tac' מיקום, והתוצאה צריכה להיות זהה לקודם:
קבצי נתונים קומפקטיים
ב-Spark for Athena, אתה יכול להריץ את OPTIMIZE על טבלת Delta Lake, מה שידחוס את הקבצים הקטנים לקבצים גדולים יותר, כך שהשאילתות לא יועמדו על ידי תקורה של קבצים קטנים. כדי לבצע את פעולת הדחיסה, הפעל את השאילתה הבאה:
עיין אופטימיזציות בתיעוד של Delta Lake לאפשרויות שונות הזמינות בזמן הפעלת OPTIMIZE.
הסר קבצים שכבר לא מתייחסים אליהם על ידי טבלת Delta Lake
אתה יכול להסיר קבצים המאוחסנים ב-Amazon S3 שכבר לא מתייחסים אליהם על ידי טבלת Delta Lake והם ישנים יותר מסף השמירה על ידי הפעלת הפקודה VACCUM בטבלה באמצעות Spark for Athena:
עיין הסר קבצים שכבר לא מתייחסים אליהם על ידי טבלת דלתא בתיעוד של אגם Delta לאפשרויות הזמינות עם VACUUM.
שחרר את הטבלה ואת מסד הנתונים
הפעל את ה-Spark SQL הבא כדי להסיר את טבלת Delta Lake שיצרת:
הפעל את ה-Spark SQL הבא כדי להסיר את מסד הנתונים deltalakedb:
הפעלת DROP TABLE DDL בטבלת Delta Lake ובבסיס הנתונים מוחקת את המטא נתונים עבור אובייקטים אלה, אך אינה מוחקת אוטומטית את קבצי הנתונים באמזון S3. אתה יכול להפעיל את קוד Python הבא בתא של המחברת כדי למחוק את הנתונים ממיקום S3:
למידע נוסף על הצהרות SQL שאתה יכול להפעיל על טבלת Delta Lake באמצעות Spark for Athena, עיין ב- QuickStart בתיעוד אגם דלתא.
סיכום
פוסט זה הדגים כיצד להשתמש ב-Spark SQL במחברות של Athena כדי ליצור מסדי נתונים וטבלאות, להכניס ולשאול נתונים ולבצע פעולות נפוצות כמו עדכונים, דחיסות ומסע בזמן בטבלאות Hudi, Delta Lake ו-Iceberg. פורמטים פתוחים של טבלה מוסיפים עסקאות ACID, העלאות ומחיקות לאגמי נתונים, ומתגברים על מגבלות של אחסון אובייקטים גולמיים. על ידי הסרת הצורך להתקין מחברים נפרדים, האינטגרציה המובנית של Spark on Athena מפחיתה את שלבי התצורה ואת תקורה הניהולית בעת שימוש במסגרות פופולריות אלה לבניית אגמי נתונים אמינים ב-Amazon S3. למידע נוסף על בחירת פורמט טבלה פתוחה עבור עומסי העבודה של אגם הנתונים שלך, עיין ב בחירת פורמט טבלה פתוחה עבור אגם הנתונים העסקאות שלך ב-AWS.
על הכותבים
![]() פאתיק שאה הוא אדריכל Sr. Analytics באמזון אתנה. הוא הצטרף ל-AWS ב-2015 ומאז הוא מתמקד בתחום ניתוח הנתונים הגדולים, ועוזר ללקוחות לבנות פתרונות מדרגיים וחזקים באמצעות שירותי ניתוח של AWS.
פאתיק שאה הוא אדריכל Sr. Analytics באמזון אתנה. הוא הצטרף ל-AWS ב-2015 ומאז הוא מתמקד בתחום ניתוח הנתונים הגדולים, ועוזר ללקוחות לבנות פתרונות מדרגיים וחזקים באמצעות שירותי ניתוח של AWS.
![]() ראג' דבנת' הוא מנהל מוצר ב-AWS באמזון אתנה. הוא נלהב לבנות מוצרים שלקוחות אוהבים ולעזור ללקוחות להפיק ערך מהנתונים שלהם. הרקע שלו הוא באספקת פתרונות עבור שווקי קצה מרובים, כגון פיננסים, קמעונאות, מבנים חכמים, אוטומציה ביתית ומערכות תקשורת נתונים.
ראג' דבנת' הוא מנהל מוצר ב-AWS באמזון אתנה. הוא נלהב לבנות מוצרים שלקוחות אוהבים ולעזור ללקוחות להפיק ערך מהנתונים שלהם. הרקע שלו הוא באספקת פתרונות עבור שווקי קצה מרובים, כגון פיננסים, קמעונאות, מבנים חכמים, אוטומציה ביתית ומערכות תקשורת נתונים.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- אודות
- גישה
- להוסיף
- מתקדם
- נגד
- נמל תעופה
- תעשיות
- לאורך
- גם
- אמזון בעברית
- אמזונה אתנה
- אמזון שירותי אינטרנט
- כמות
- an
- ניתוח
- לנתח
- ניתוח
- ו
- הודיע
- אַפָּשׁ
- אפאצ 'י ספארק
- ישים
- יישומים
- חל
- גישות
- ARE
- סביב
- AS
- המשויך
- At
- באופן אוטומטי
- אוטומציה
- זמינות
- זמין
- AWS
- דבק AWS
- בחזרה
- רקע
- בסיס
- BE
- היה
- התנהגות
- גָדוֹל
- נתונים גדולים
- לִבנוֹת
- בִּניָן
- נבנה
- מובנה
- עסקים
- אבל
- by
- שיחה
- נקרא
- CAN
- קטלוג
- לגרום
- תא
- שינוי
- שינויים
- בדיקות
- לְנַקוֹת
- קוד
- לשלב
- שילוב
- Common
- תקשורת
- מערכות תקשורת
- קומפקטי
- השוואה
- תְצוּרָה
- עִקבִי
- תוכן
- תוֹאֵם
- עלויות
- לספור
- לִיצוֹר
- נוצר
- יוצר
- יוצרים
- יצירה
- נוֹכְחִי
- לקוחות
- נתונים
- ניתוח נתונים
- אגם דאטה
- עיבוד נתונים
- מחסני נתונים
- מסד נתונים
- מאגרי מידע
- תַאֲרִיך
- מוגדר
- אספקה
- דלתא
- להפגין
- מופגן
- תלות
- אחר
- ישירות
- נָדוֹן
- do
- תיעוד
- לא
- להורדה
- ירידה
- עמידות
- כל אחד
- מוקדם יותר
- עריכה
- יעיל
- מאמץ
- מוּעֳסָק
- לאפשר
- סוף
- לְהַבטִיחַ
- שלם
- סביבה
- Ether (ETH)
- אירועים
- דוגמה
- תרגיל
- הרחבת
- תמצית
- תכונות
- שלח
- קבצים
- לממן
- ראשון
- גמישות
- התמקדות
- לעקוב
- בעקבות
- הבא
- בעד
- פוּרמָט
- קרן
- מסגרות
- החל מ-
- פונקציונלי
- כללי
- לקבל
- לתת
- קְבוּצָה
- גדל
- מְגוּדָל
- לטפל
- יש
- יש
- he
- כותרות
- לעזור
- עזרה
- hh
- גָבוֹהַ
- גבוה יותר
- שֶׁלוֹ
- עמוד הבית
- בית אוטומציה
- איך
- איך
- HTML
- http
- HTTPS
- תמונה
- מיישמים
- לייבא
- לשפר
- in
- מצטבר
- להתקין
- השתלבות
- מעוניין
- מִמְשָׁק
- אל תוך
- בדידות
- IT
- הצטרף
- jpg
- שמור
- שמירה
- מפתחות
- אגם
- אגמים
- גדול יותר
- רוחב
- מוביל
- לִלמוֹד
- פחות
- מאפשר לי
- כמו
- מגבלות
- לינוקס
- בסיס לינוקס
- רשימה
- לִטעוֹן
- מיקום
- מקומות
- היכנס
- עוד
- נראה
- הסתכלות
- אהבה
- קסם
- לנהל
- ניהול
- מנהל
- דרך
- רב
- שוקי
- מקסימום
- מקסימום
- למזג
- מידע נוסף
- דקות
- מינימום
- יותר
- מספר
- שם
- במקור
- נווט
- צורך
- נחוץ
- לעולם לא
- חדש
- לא
- הערות
- מחברה
- מחשבים ניידים
- מספר
- אובייקט
- אחסון אובייקטים
- אובייקטים
- of
- המיוחדות שלנו
- לעתים קרובות
- זקן
- מבוגר
- on
- ONE
- רק
- OP
- לפתוח
- קוד פתוח
- מבצע
- תפעול
- מטב
- אפשרות
- אפשרויות
- or
- להזמין
- שלנו
- תפוקה
- התגברות
- שֶׁלוֹ
- חלק
- לוהט
- עבר
- לבצע
- ביצועים
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- פופולרי
- הודעה
- תנאים מוקדמים
- קודם
- קוֹדֶם
- יְסוֹדִי
- הליך
- תהליך
- לייצר
- המוצר
- מנהל מוצר
- מוצרים
- נכסים
- פיתון
- שאילתות
- תעריפים
- חי
- חומר עיוני
- קריאה
- מוּמלָץ
- מוקלט
- רשום
- מפחית
- להתייחס
- הפניה
- אָמִין
- להסיר
- מסיר
- הסרת
- להחליף
- נדרש
- תוצאה
- וכתוצאה מכך
- קמעוני
- שייר
- חָסוֹן
- הפעלה
- ריצה
- אותו
- להרחבה
- סולם
- סיאטל
- שְׁנִיָה
- סעיף
- לִרְאוֹת
- בחר
- בחירה
- נפרד
- שרות
- שירותים
- מושב
- סט
- צריך
- לְהַצִיג
- הראה
- הופעות
- משמעותי
- פָּשׁוּט
- מפשט
- לפשט
- since
- מידה
- מעט שונה
- SLP
- קטן
- קטן יותר
- חכם
- תמונת בזק
- So
- פתרונות
- מָקוֹר
- מֶרחָב
- לעורר
- מיוחד
- ספציפי
- במיוחד
- מפורט
- מְהִירוּת
- מהירויות
- בילה
- SQL
- התחלה
- הצהרה
- הצהרות
- תחנה
- שלב
- צעדים
- עוד
- אחסון
- חנות
- מאוחסן
- אִסטרָטֶגִיָה
- מחרוזת
- כזה
- נתמך
- מערכת
- מערכות
- שולחן
- טקומה
- מֵאֲשֶׁר
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- אלה
- זֶה
- סף
- דרך
- זמן
- זמן הנסיעה
- חותם
- ל
- מעקב
- טרנזקציות
- עסקות
- נסיעות
- סוג
- ללא תחרות
- עדכון
- מְעוּדכָּן
- עדכונים
- us
- נוֹהָג
- להשתמש
- מְשׁוּמָשׁ
- באמצעות
- חלל
- ערך
- גרסה
- גירסאות
- רוצה
- היה
- דרכים
- we
- אינטרנט
- שירותי אינטרנט
- היו
- מתי
- אשר
- בזמן
- יצטרך
- עם
- לְלֹא
- תיק עבודות
- לכתוב
- שנה
- אתה
- זפירנט