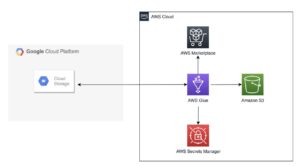
מודלים של שפה גדולה (LLMs) הופכים פופולריים יותר ויותר, כאשר מקרי שימוש חדשים נחקרים כל הזמן. באופן כללי, אתה יכול לבנות יישומים המופעלים על ידי LLMs על ידי שילוב הנדסה מהירה בקוד שלך. עם זאת, ישנם מקרים שבהם הנחיה של LLM קיים נופלת. זה המקום שבו כוונון עדין של הדגם יכול לעזור. הנדסה מהירה עוסקת בהנחיית הפלט של המודל על ידי יצירת הנחיות קלט, ואילו כוונון עדין עוסק באימון המודל על מערכי נתונים מותאמים אישית כדי להפוך אותו למתאים יותר למשימות או תחומים ספציפיים.
לפני שתוכל לכוונן מודל, עליך למצוא מערך נתונים ספציפי למשימה. מערך נתונים אחד שנמצא בשימוש נפוץ הוא מערך נתונים משותף של סריקה. קורפוס ה-Common Crawl מכיל פטה-בייט של נתונים, שנאספים באופן קבוע מאז 2008, ומכיל נתוני דפי אינטרנט גולמיים, תמציות מטא נתונים ותמציות טקסט. בנוסף לקביעה באיזה מערך נתונים יש להשתמש, נדרש ניקוי ועיבוד הנתונים לפי הצורך הספציפי של הכוונון.
לאחרונה עבדנו עם לקוח שרצה לעבד תת-קבוצה של מערך הנתונים העדכניים ביותר של הסריקה הרגילה ולאחר מכן לכוונן את ה-LLM שלו עם נתונים נקיים. הלקוח חיפש איך הם יכולים להשיג זאת בצורה החסכונית ביותר ב-AWS. לאחר דיון בדרישות, המלצנו להשתמש Amazon EMR ללא שרת כפלטפורמה שלהם לעיבוד מקדים של נתונים. EMR Serverless מתאים היטב לעיבוד נתונים בקנה מידה גדול ומבטל את הצורך בתחזוקת תשתית. מבחינת עלות, הוא גובה רק על סמך המשאבים ומשך הזמן המשמשים עבור כל עבודה. הלקוח הצליח לעבד מראש מאות TBs של נתונים תוך שבוע באמצעות EMR Serverless. לאחר שהם עיבדו מראש את הנתונים, הם השתמשו אמזון SageMaker כדי לכוונן את ה-LLM.
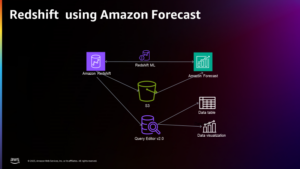
בפוסט זה, אנו מדריכים אותך דרך מקרה השימוש והארכיטקטורה שבה נעשה שימוש של הלקוח.
בסעיפים הבאים, אנו מציגים תחילה את מערך הנתונים הנפוצים של הסריקה וכיצד לחקור ולסנן את הנתונים הדרושים לנו. אמזונה אתנה גובה רק תשלום עבור גודל הנתונים שהוא סורק ומשמש לחקור ולסנן את הנתונים במהירות, תוך כדי עלות-תועלת. EMR Serverless מספק אפשרות חסכונית וללא תחזוקה לעיבוד נתוני Spark, ומשמשת לעיבוד הנתונים המסוננים. לאחר מכן, אנו משתמשים אמזון SageMaker JumpStart כדי לכוונן את דגם לאמה 2 עם מערך הנתונים המעובד מראש. SageMaker JumpStart מספקת סט של פתרונות למקרי השימוש הנפוצים ביותר שניתן לפרוס בכמה קליקים בלבד. אינך צריך לכתוב שום קוד כדי לכוונן LLM כגון Llama 2. לבסוף, אנו פורסים את המודל המכוונן באמצעות אמזון SageMaker והשוו את ההבדלים בפלט הטקסט עבור אותה שאלה בין דגמי ה-Llama 2 המקוריים והמכוונים העדינים.
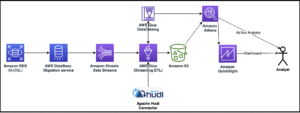
התרשים הבא ממחיש את הארכיטקטורה של פתרון זה.
לפני שאתה צולל עמוק לתוך פרטי הפתרון, השלם את השלבים המוקדמים הבאים:
Common Crawl הוא מערך נתונים של קורפוס פתוח המתקבל על ידי סריקה של למעלה מ-50 מיליארד דפי אינטרנט. הוא כולל כמויות אדירות של נתונים לא מובנים במספר שפות, החל משנת 2008 ועד לרמת פטה-בייט. זה מתעדכן כל הזמן.
באימון של GPT-3, מערך הנתונים של הסריקה הנפוצה מהווה 60% מנתוני ההדרכה שלו, כפי שמוצג בתרשים הבא (מקור: מודלים לשפה הם לומדים מעטים).
מערך נתונים חשוב נוסף שכדאי להזכיר הוא מערך נתונים של C4. C4, קיצור של Colossal Clean Crawled Corpus, הוא מערך נתונים שנגזר לאחר עיבוד של מערך הנתונים Common Crawl. במאמר LLaMA של Meta, הם תיארו את מערכי הנתונים שבהם נעשה שימוש, כאשר Common Crawl אחראי על 67% (המשתמשים ב-3.3 TB של נתונים) ו-C4 עבור 15% (המשתמשים ב-783 GB של נתונים). המאמר מדגיש את המשמעות של שילוב נתונים מעובדים מראש באופן שונה לשיפור ביצועי המודל. למרות שהנתונים המקוריים של C4 הם חלק מ-Common Crawl, Meta בחרה בגרסה המעובדת מחדש של נתונים אלה.
בסעיף זה, אנו מכסים דרכים נפוצות ליצירת אינטראקציה, סינון ועיבוד של מערך הנתונים הנפוצים של הסריקה.
מערך הנתונים הגולמי של Common Crawl כולל שלושה סוגים של קובצי נתונים: נתוני דפי אינטרנט גולמיים (WARC), מטא נתונים (WAT) וחילוץ טקסט (WET).
נתונים שנאספו לאחר 2013 מאוחסנים בפורמט WARC וכוללים מטא נתונים (WAT) ונתוני חילוץ טקסט (WET) מתאימים. מערך הנתונים ממוקם באמזון S3, מתעדכן על בסיס חודשי, וניתן לגשת אליו ישירות דרך AWS שוק.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzמערך הנתונים Common Crawl מספק גם טבלת אינדקס לסינון נתונים, הנקראת cc-index-table.
ה-cc-index-table הוא אינדקס של הנתונים הקיימים, המספק אינדקס מבוסס טבלה של קובצי WARC. זה מאפשר חיפוש קל של מידע, כגון איזה קובץ WARC מתאים לכתובת URL ספציפית.
לדוגמה, אתה יכול ליצור טבלת Athena למיפוי נתוני cc-index עם הקוד הבא:
הצהרות SQL הקודמות מדגימות כיצד ליצור טבלת Athena, להוסיף מחיצות ולהפעיל שאילתה.
סנן נתונים ממערך הנתונים של הסריקה הנפוצה
כפי שניתן לראות מהצהרת SQL של create table, ישנם מספר שדות שיכולים לסייע בסינון הנתונים. לדוגמה, אם ברצונך לקבל את ספירת המסמכים הסיניים במהלך תקופה מסוימת, הצהרת SQL יכולה להיות כדלקמן:
אם ברצונך לבצע עיבוד נוסף, תוכל לשמור את התוצאות בדלי S3 אחר.
נתח את הנתונים המסוננים
השמיים מאגר סריקה נפוץ של GitHub מספק מספר דוגמאות PySpark לעיבוד הנתונים הגולמיים.
בואו נסתכל על דוגמה של ריצה server_count.py (סקריפט לדוגמה מסופק על ידי ה-Common Crawl GitHub repo) על הנתונים שנמצאים ב s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
ראשית, אתה צריך סביבת Spark, כגון EMR Spark. לדוגמה, אתה יכול להשיק אמזון EMR על אשכול EC2 ב us-east-1 (כי מערך הנתונים נמצא ב us-east-1). שימוש ב-EMR על אשכול EC2 יכול לעזור לך לבצע בדיקות לפני הגשת עבודות לסביבת הייצור.
לאחר השקת EMR באשכול EC2, עליך לבצע התחברות SSH לצומת הראשי של האשכול. לאחר מכן, ארוז את סביבת Python ושלח את הסקריפט (עיין ב- תיעוד קונדה כדי להתקין מיניקונדה):
יכול לקחת זמן לעבד את כל ההפניות ב-warc.path. למטרות הדגמה, תוכל לשפר את זמן העיבוד באמצעות האסטרטגיות הבאות:
- הורד את הקובץ
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzלמחשב המקומי שלך, פתח אותו ואז העלה אותו ל-HDFS או Amazon S3. הסיבה לכך היא שקובץ ה-.gzip אינו ניתן לפיצול. אתה צריך לפתוח אותו כדי לעבד את הקובץ הזה במקביל. - שנה את
warc.pathקובץ, מחק את רוב השורות שלו, ושמור רק שתי שורות כדי לגרום לעבודה לפעול הרבה יותר מהר.
לאחר השלמת העבודה, תוכל לראות את התוצאה ב- s3://xxxx-common-crawl/output/, בפורמט פרקט.
הטמעת היגיון בעלות מותאם אישית
ה-Repo Common Crawl GitHub מספק גישה נפוצה לעיבוד קובצי WARC. בדרך כלל, אתה יכול להאריך את CCSparkJob לעקוף שיטה בודדת (process_record), וזה מספיק עבור מקרים רבים.
בואו נסתכל על דוגמה כדי לקבל את ביקורות IMDB על הסרטים האחרונים. ראשית, עליך לסנן קבצים באתר IMDB:
לאחר מכן תוכל לקבל רשימות קבצי WARC המכילות נתוני סקירת IMDB, ולשמור את שמות קבצי WARC כרשימה בקובץ טקסט.
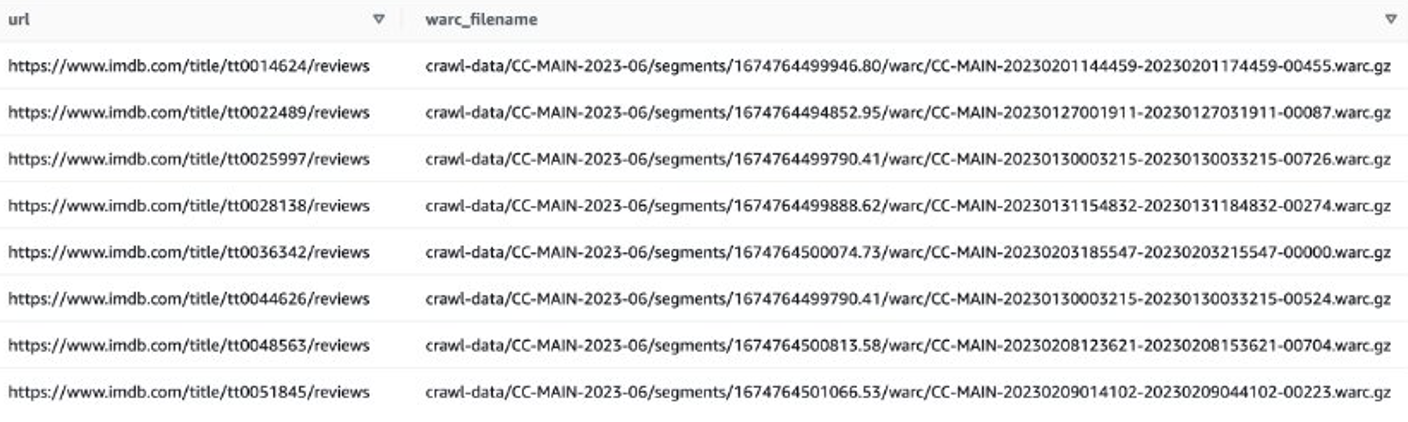
לחלופין, אתה יכול להשתמש ב-EMR Spark לקבל את רשימת הקבצים של WARC ולאחסן אותה באמזון S3. לדוגמה:
קובץ הפלט צריך להיראות דומה לזה s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
השלב הבא הוא לחלץ ביקורות משתמשים מקבצי WARC אלה. אתה יכול להאריך את CCSparkJob לעקוף את process_record() שיטה:
אתה יכול לשמור את הסקריפט הקודם בתור imdb_extractor.py, שבו תשתמש בשלבים הבאים. לאחר שהכנת את הנתונים והתסריטים, תוכל להשתמש ב-EMR Serverless כדי לעבד את הנתונים המסוננים.
EMR ללא שרת
EMR Serverless היא אפשרות פריסה ללא שרת להפעלת יישומי ניתוח נתונים גדולים באמצעות מסגרות קוד פתוח כמו Apache Spark ו-Hive מבלי להגדיר, לנהל ולהרחיב אשכולות או שרתים.
עם EMR Serverless, אתה יכול להפעיל עומסי עבודה אנליטיים בכל קנה מידה עם קנה מידה אוטומטי שמשנה את גודל המשאבים בשניות כדי לעמוד בנפחי הנתונים המשתנים ובדרישות העיבוד. EMR Serverless מרחיב את המשאבים באופן אוטומטי למעלה ולמטה כדי לספק את הכמות הנכונה של קיבולת עבור האפליקציה שלך, ואתה משלם רק על מה שאתה משתמש.
עיבוד מערך הנתונים Common Crawl הוא בדרך כלל משימת עיבוד חד פעמית, מה שהופך אותו למתאים לעומסי עבודה ללא שרת EMR.
צור אפליקציה ללא שרת EMR
אתה יכול ליצור אפליקציה ללא שרת EMR בקונסולת EMR Studio. השלם את השלבים הבאים:
- במסוף EMR Studio, בחר יישומים תחת ללא שרת בחלונית הניווט.
- בחרו צור יישום.

- ספק שם לאפליקציה ובחר גרסת אמזון EMR.

- אם נדרשת גישה למשאבי VPC, הוסף הגדרת רשת מותאמת אישית.

- בחרו צור יישום.
הסביבה ללא שרת Spark שלך תהיה מוכנה.
לפני שתוכל להגיש עבודה ל-EMR Spark Serverless, אתה עדיין צריך ליצור תפקיד ביצוע. מתייחס תחילת העבודה עם Amazon EMR Serverless לקבלת פרטים נוספים.
עבד נתוני סריקה נפוצים עם EMR Serverless
לאחר שהאפליקציה ללא שרת EMR Spark מוכנה, השלם את השלבים הבאים כדי לעבד את הנתונים:
- הכן סביבת Conda והעלה אותה לאמזון S3, שתשמש כסביבה ב-EMR Spark Serverless.
- העלה את הסקריפטים שיופעלו אל דלי S3. בדוגמה הבאה, ישנם שני סקריפטים:
- imbd_extractor.py - לוגיקה מותאמת אישית לחילוץ תוכן ממערך הנתונים. את התוכן ניתן למצוא מוקדם יותר בפוסט זה.
- cc-pyspark/sparkcc.py – מסגרת PySpark לדוגמה מה- ריפו סריקה נפוץ של GitHub, אשר יש צורך להיכלל.
- שלח את עבודת PySpark ל-EMR Serverless Spark. הגדר את הפרמטרים הבאים כדי להפעיל דוגמה זו בסביבה שלך:
- מזהה אפליקציה - מזהה היישום של היישום ללא שרת EMR שלך.
- ביצוע-תפקיד-ארן - תפקיד הביצוע ללא שרת EMR שלך. כדי ליצור אותו, עיין ב צור תפקיד זמן ריצה של עבודה.
- מיקום קובץ WARC - המיקום של קבצי ה-WARC שלך.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtמכיל את רשימת קבצי ה-WARC המסוננת, שהשגת קודם לכן בפוסט זה. - spark.sql.warehouse.dir - מיקום המחסן המוגדר כברירת מחדל (השתמש בספריית S3 שלך).
- spark.archives – מיקום S3 של סביבת קונדה המוכנה.
- spark.submit.pyFiles – הסקריפט של PySpark שהוכן sparkcc.py.
ראה את הקוד הבא:
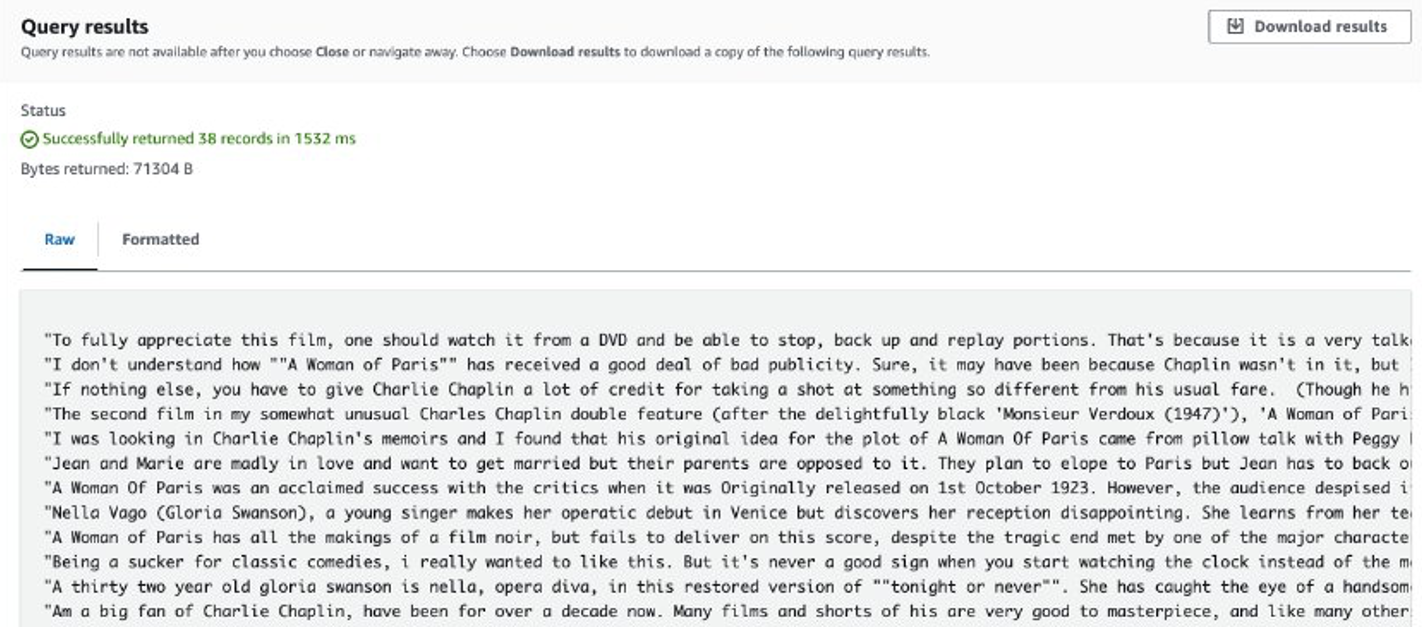
לאחר השלמת העבודה, הביקורות שחולצו מאוחסנות באמזון S3. כדי לבדוק את התוכן, אתה יכול להשתמש ב- Amazon S3 Select, כפי שמוצג בצילום המסך הבא.
שיקולים
להלן הנקודות שיש לקחת בחשבון כאשר מתמודדים עם כמויות אדירות של נתונים עם קוד מותאם אישית:
- ייתכן שחלק מספריות Python של צד שלישי לא יהיו זמינות ב-Conda. במקרים כאלה, אתה יכול לעבור לסביבה וירטואלית של Python כדי לבנות את סביבת זמן הריצה של PySpark.
- אם יש כמות עצומה של נתונים לעיבוד, נסה ליצור ולהשתמש במספר יישומי EMR Serverless Spark כדי להקביל אותם. כל אפליקציה עוסקת בתת-קבוצה של רשימות קבצים.
- אתה עלול להיתקל בבעיית האטה עם Amazon S3 בעת סינון או עיבוד נתוני הסריקה הנפוצה. הסיבה לכך היא שדלי S3 המאחסן את הנתונים נגיש לציבור, ומשתמשים אחרים עשויים לגשת לנתונים בו-זמנית. כדי להקל על בעיה זו, אתה יכול להוסיף מנגנון ניסיון חוזר או לסנכרן נתונים ספציפיים מ-Common Crawl S3 לדלי משלך.
כוונן את Llama 2 עם SageMaker
לאחר הכנת הנתונים, אתה יכול לכוונן עדין דגם של Lama 2 איתו. אתה יכול לעשות זאת באמצעות SageMaker JumpStart, מבלי לכתוב שום קוד. למידע נוסף, עיין ב כוונן את Llama 2 ליצירת טקסט ב- Amazon SageMaker JumpStart.
בתרחיש זה, אתה מבצע כוונון עדין של התאמת תחום. עם מערך נתונים זה, הקלט מורכב מקובץ CSV, JSON או TXT. אתה צריך לשים את כל נתוני הביקורת בקובץ TXT. לשם כך, אתה יכול להגיש עבודת Spark פשוטה ל-EMR Spark Serverless. ראה את קטע הקוד לדוגמה הבא:
לאחר הכנת נתוני האימון, הזן את מיקום הנתונים עבור סט נתוני אימון, ואז לבחור רכבת.
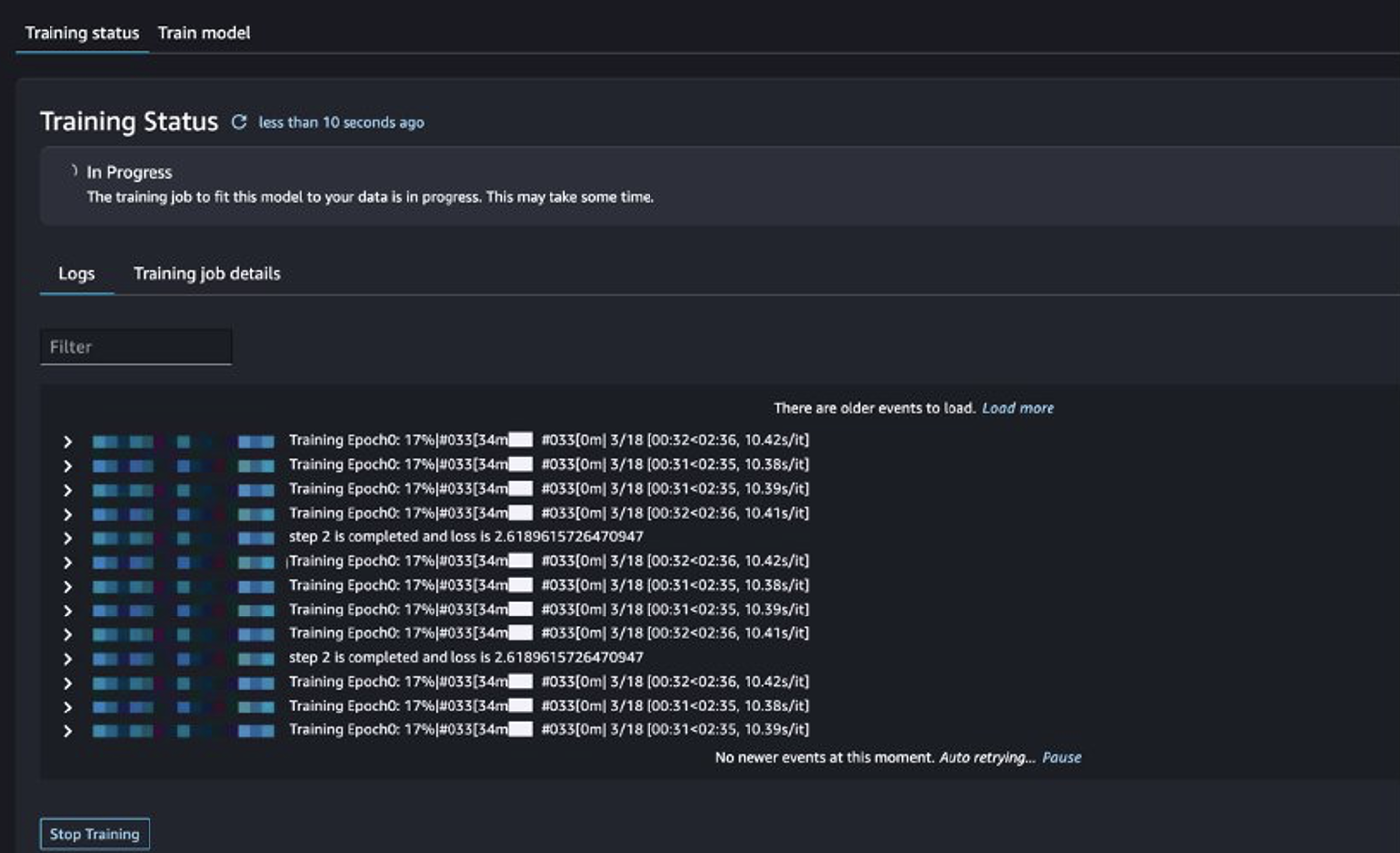
אתה יכול לעקוב אחר מצב עבודת ההדרכה.
הערך את המודל המכוונן
לאחר סיום האימון, בחר לפרוס ב- SageMaker JumpStart כדי לפרוס את הדגם המכוונן שלך.

לאחר פריסת המודל בהצלחה, בחר פתח מחברת, שמפנה אותך למחברת Jupyter מוכנה שבה תוכל להריץ את קוד Python שלך.

אתה יכול להשתמש בתמונה Data Science 2.0 ובליבת Python 3 עבור המחברת.
לאחר מכן, תוכל להעריך את הדגם המכוון ואת הדגם המקורי במחברת זו.
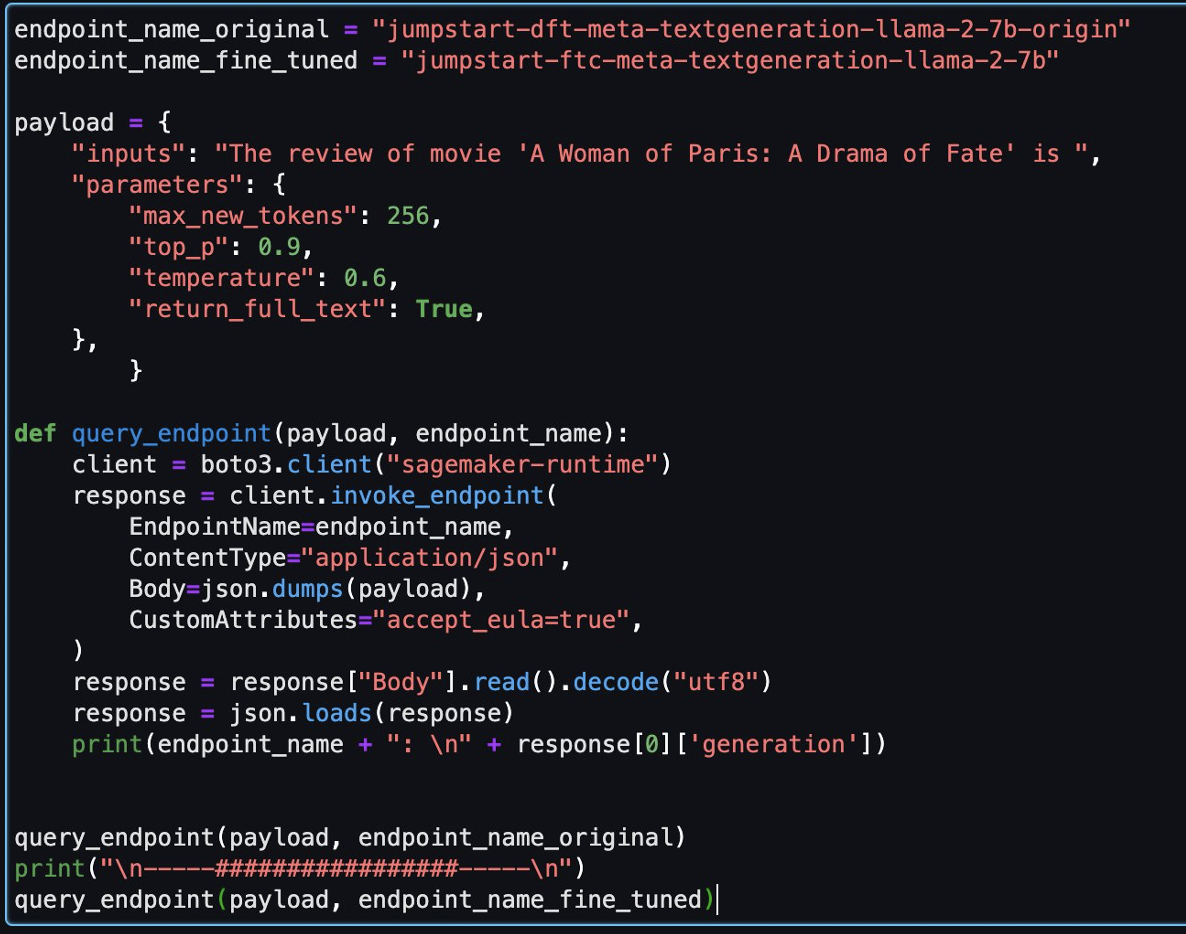
להלן שתי תגובות שהוחזרו על ידי הדגם המקורי והדגם המכוונן עדין עבור אותה שאלה.

סיפקנו לשתי הדוגמניות את אותו המשפט: "הביקורת של הסרט 'אישה מפריז: דרמה של גורל' היא" ונתנו להם להשלים את המשפט.
הדגם המקורי מוציא משפטים חסרי משמעות:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
לעומת זאת, התפוקות של הדגם המכוונן דומות יותר לביקורת סרטים:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
ברור שהמודל המכוונן מתפקד טוב יותר בתרחיש הספציפי הזה.
לנקות את
לאחר שתסיים את התרגיל הזה, השלם את השלבים הבאים כדי לנקות את המשאבים שלך:
- מחק את דלי S3 שמאחסן את מערך הנתונים הנוקה.
- עצור את הסביבה ללא שרת EMR.
- מחק את נקודת הקצה של SageMaker המארח את מודל LLM.
- מחק את הדומיין של SageMaker שמפעיל את המחברות שלך.
היישום שיצרת אמור להפסיק אוטומטית לאחר 15 דקות של חוסר פעילות כברירת מחדל.
בדרך כלל, אינך צריך לנקות את סביבת Athena מכיוון שאין חיובים כאשר אינך משתמש בה.
סיכום
בפוסט זה, הצגנו את מערך הנתונים הנפוצים של סריקה וכיצד להשתמש ב-EMR Serverless לעיבוד הנתונים עבור כוונון עדין של LLM. לאחר מכן הדגמנו כיצד להשתמש ב- SageMaker JumpStart כדי לכוונן את ה-LLM ולפרוס אותו ללא כל קוד. למקרי שימוש נוספים של EMR Serverless, עיין ב Amazon EMR ללא שרת. למידע נוסף על אירוח וכוונון דגמים ב-Amazon SageMaker JumpStart, עיין ב- תיעוד Sagemaker JumpStart.
על הכותבים
 שיג'יאן טאנג הוא ארכיטקט פתרונות מומחה ב-Analytics בשירותי האינטרנט של אמזון.
שיג'יאן טאנג הוא ארכיטקט פתרונות מומחה ב-Analytics בשירותי האינטרנט של אמזון.
 מתיו ליאם הוא מנהל ארכיטקטורת פתרונות בכיר בשירותי האינטרנט של אמזון.
מתיו ליאם הוא מנהל ארכיטקטורת פתרונות בכיר בשירותי האינטרנט של אמזון.
 דיילי שו הוא ארכיטקט פתרונות מומחה ב-Analytics בשירותי האינטרנט של אמזון.
דיילי שו הוא ארכיטקט פתרונות מומחה ב-Analytics בשירותי האינטרנט של אמזון.
 יואנג'ון שיאו הוא ארכיטקט פתרונות בכיר בחברת Amazon Web Services.
יואנג'ון שיאו הוא ארכיטקט פתרונות בכיר בחברת Amazon Web Services.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- יכול
- אודות
- גישה
- נצפה
- נגיש
- חשבונאות
- חשבונות
- להשיג
- להפעיל
- להוסיף
- תוספת
- אפריקה
- לאחר
- תעשיות
- מאפשר
- גם
- מדהים
- אמזון בעברית
- אמזון EMR
- אמזון SageMaker
- אמזון SageMaker JumpStart
- אמזון שירותי אינטרנט
- כמות
- כמויות
- an
- ניתוח
- ו
- אחר
- כל
- אַפָּשׁ
- אפאצ 'י ספארק
- בקשה
- יישומים
- גישה
- ארכיטקטורה
- ARE
- AS
- At
- אוסטרלי
- מכני עם סלילה אוטומטית
- באופן אוטומטי
- זמין
- AWS
- רקע
- מבוסס
- בסיס
- BE
- יפה
- כי
- התהוות
- לפני
- להתחיל
- להיות
- מוטב
- בֵּין
- גָדוֹל
- נתונים גדולים
- B
- גוּף
- שניהם
- לִבנוֹת
- by
- נקרא
- CAN
- יכול לקבל
- קיבולת
- לשאת
- מקרה
- מקרים
- משתנה
- אופי
- חיובים
- לבדוק
- סינית
- בחרו
- בכיתה
- לְנַקוֹת
- לקוחות
- אשכול
- קוד
- COM
- Common
- בדרך כלל
- לְהַשְׁווֹת
- להשלים
- תצורה
- לשקול
- מורכב
- קונסול
- תמיד
- להכיל
- מכיל
- תוכן
- ברציפות
- לעומת זאת
- תוֹאֵם
- מתכתב
- עלות
- עלות תועלת
- יכול
- לספור
- לכסות
- לִיצוֹר
- נוצר
- מנהג
- לקוח
- אישית
- נתונים
- ניתוח נתונים
- עיבוד נתונים
- מדע נתונים
- מערכי נתונים
- דייויס
- התמודדות
- דילים
- עמוק
- בְּרִירַת מֶחדָל
- לְהַגדִיר
- הַדגָמָה
- להפגין
- מופגן
- לפרוס
- פרס
- פריסה
- נגזר
- למרות
- פרטים
- קביעה
- תרשים
- ההבדלים
- באופן שונה
- מְכוּוָן
- ישירות
- דנים
- צלילה
- do
- מסמכים
- תחום
- תחומים
- דונלד
- לא
- מטה
- דרמה
- נהג
- משך
- בְּמַהֲלָך
- כל אחד
- מוקדם יותר
- קל
- מבטל
- מדגיש
- פְּגִישָׁה
- הנדסה
- שיפור
- זן
- סביבה
- Ether (ETH)
- להעריך
- דוגמה
- דוגמאות
- הוצאת להורג
- תרגיל
- קיימים
- קיים
- לחקור
- חקר
- להאריך
- חיצוני
- תמצית
- הוֹצָאָה
- תמציות
- פולס
- שקר
- מהר יותר
- גורל
- מומלצים
- מעטים
- שדות
- שלח
- קבצים
- לסנן
- סינון
- בסופו של דבר
- גימור
- ראשון
- הבא
- כדלקמן
- בעד
- פוּרמָט
- מצא
- מסגרת
- מסגרות
- החל מ-
- נוסף
- כללי
- בדרך כלל
- יצירת
- דור
- לקבל
- Git
- GitHub
- מנחה
- יש
- לעזור
- כוורת
- אירוח
- מארחים
- איך
- איך
- אולם
- HTML
- HTTPS
- מאות
- i
- IAM
- ID
- if
- מדגים
- תמונה
- לייבא
- חשוב
- לשפר
- in
- כלול
- כולל
- שילוב
- גדל
- מדד
- מידע
- תשתית
- קלט
- תשומות
- להתקין
- אינטראקציה
- אל תוך
- מבוא
- הציג
- סוגיה
- IT
- שֶׁלָה
- שקע
- עבודה
- מקומות תעסוקה
- ג'סון
- מחברת צדק
- רק
- שמור
- מפתח
- שפה
- שפות
- בקנה מידה גדול
- האחרון
- לשגר
- השקה
- עוֹפֶרֶת
- לתת
- רמה
- ספריות
- כמו
- להגביל
- קווים
- רשימה
- רשימות
- לאמה
- LLM
- מקומי
- ממוקם
- מיקום
- הגיון
- התחבר
- נראה
- הסתכלות
- בדיקה
- מכונה
- תחזוקה
- לעשות
- עשייה
- מנהל
- ניהול
- רב
- מַפָּה
- מסיבי
- מאי..
- מנגנון
- לִפְגוֹשׁ
- פוגשת
- אזכור
- meta
- מידע נוסף
- שיטה
- דקות
- להקל
- מודל
- מודלים
- אחת לחודש
- יותר
- רוב
- סרט
- סרטים
- הרבה
- מספר
- שם
- שמות
- ניווט
- הכרחי
- צורך
- רשת
- חדש
- הבא
- לא
- צומת
- מחברה
- מחשבים ניידים
- מושג
- אוֹקְטוֹבֶּר
- of
- on
- ONE
- רק
- לפתוח
- קוד פתוח
- אפשרות
- or
- מְקוֹרִי
- אחר
- הַחוּצָה
- המתואר
- תפוקה
- פלטים
- יותר
- לעקוף
- שֶׁלוֹ
- חבילה
- חבילה
- זגוגית
- מאמר
- מקביל
- פרמטרים
- פריז
- חלק
- נתיב
- שבילים
- תשלום
- אֲנָשִׁים
- ביצועים
- הופעות
- מבצע
- תקופה
- פטיבה
- פיטר
- צלם
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- עלילה
- נקודות
- פופולרי
- הודעה
- מופעל
- מראש
- קודם
- להכין
- מוּכָן
- יְסוֹדִי
- תהליך
- מעובד
- תהליך
- הפקה
- הנחיות
- לספק
- ובלבד
- מספק
- מתן
- בפומבי
- למטרות
- גם
- פיתון
- שאלה
- שאלה
- מהירות
- חי
- נתונים גולמיים
- הגעה
- חומר עיוני
- מוכן
- לאחרונה
- לאחרונה
- מוּמלָץ
- שיא
- להתייחס
- אזכור
- באופן קבוע
- קשר
- שוחרר
- לתקן
- להחליף
- בקשות
- נדרש
- דרישות
- משאבים
- תגובה
- תגובות
- תוצאה
- תוצאות
- סקירה
- חוות דעת של לקוחותינו
- תקין
- תפקיד
- רורי
- הפעלה
- ריצה
- פועל
- בעל חכמים
- אותו
- שמור
- סולם
- מאזניים
- דרוג
- סריקות
- תרחיש
- מדע
- תסריט
- סקריפטים
- שניות
- סעיף
- סעיפים
- לִרְאוֹת
- קטע
- בחר
- עצמי
- לחצני מצוקה לפנסיונרים
- משפט
- ללא שרת
- שרתים
- שירותים
- סט
- הצבה
- כמה
- היא
- קצר
- צריך
- הראה
- משמעות
- דומה
- since
- יחיד
- אתר
- מידה
- האט
- קטע
- So
- פִּתָרוֹן
- פתרונות
- מרק
- מָקוֹר
- לעורר
- מומחה
- ספציפי
- SQL
- ssh
- החל
- החל
- הצהרה
- הצהרות
- מצב
- שלב
- צעדים
- עוד
- עצור
- חנות
- מאוחסן
- חנויות
- סיפור
- פשוט
- אסטרטגיות
- מחרוזת
- סטודיו
- להגיש
- מגיש
- בהצלחה
- כזה
- מספיק
- מַתְאִים
- מתג
- סינכרון.
- שולחן
- לקחת
- יעד
- המשימות
- משימות
- tensorflow
- מונחים
- בדיקות
- טֶקסט
- דור טקסט
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- שם.
- אלה
- הֵם
- צד שלישי
- זֶה
- שְׁלוֹשָׁה
- דרך
- זמן
- חותם
- ל
- לעקוב
- הדרכה
- נוסע
- נָכוֹן
- לנסות
- שתיים
- סוגים
- תחת
- לא מובנה
- מְעוּדכָּן
- כתובת האתר
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמש
- ביקורות משתמשים
- משתמשים
- באמצעות
- ניצול
- גרסה
- וירטואלי
- כרכים
- ללכת
- רוצה
- רציתי
- מחסן
- היה
- דֶרֶך..
- דרכים
- we
- אינטרנט
- שירותי אינטרנט
- שבוע
- טוֹב
- מה
- מתי
- ואילו
- אשר
- בזמן
- מי
- חיות בר
- יצטרך
- ויליאם
- עם
- בתוך
- לְלֹא
- אשה
- עבד
- ראוי
- לכתוב
- כתיבה
- תְשׁוּאָה
- אתה
- זפירנט