סטודיו SageMaker של אמזון מספק פתרון מנוהל במלואו עבור מדעני נתונים לבנייה, אימון ופריסה אינטראקטיבית של מודלים של למידת מכונה (ML). משרות מחברת אמזון SageMaker לאפשר למדעני נתונים להפעיל את המחברות שלהם לפי דרישה או לפי לוח זמנים בכמה קליקים ב-SageMaker Studio. עם השקה זו, אתה יכול להריץ מחברות באופן פרוגרמטי כעבודות באמצעות ממשקי API המסופקים על ידי צינורות SageMaker של אמזון, תכונת תזמור זרימת העבודה של ML של אמזון SageMaker. יתר על כן, אתה יכול ליצור זרימת עבודה ML רב-שלבית עם מחברות תלויות מרובות באמצעות ממשקי API אלה.
SageMaker Pipelines הוא כלי תזמור מקורי של זרימת עבודה לבניית צינורות ML המנצלים את היתרונות של שילוב ישיר של SageMaker. כל צינור של SageMaker מורכב מ צעדים, המתאימות למשימות בודדות כגון עיבוד, הדרכה או עיבוד נתונים באמצעות אמזון EMR. עבודות מחברת SageMaker זמינות כעת כסוג צעד מובנה בצינורות SageMaker. אתה יכול להשתמש בשלב העבודה של מחברת זה כדי להפעיל בקלות מחברות כעבודות עם מספר שורות קוד בלבד באמצעות אמזון SageMaker Python SDK. בנוסף, אתה יכול לחבר מחברות תלויות מרובות יחד כדי ליצור זרימת עבודה בצורה של גרפים אציקליים מכוונים (DAGs). לאחר מכן תוכל להריץ את עבודות המחברות או ה-DAG הללו, ולנהל ולהמחיש אותן באמצעות SageMaker Studio.
מדעני נתונים משתמשים כיום ב-SageMaker Studio כדי לפתח באופן אינטראקטיבי את מחברות Jupyter שלהם ולאחר מכן להשתמש במשימות מחברת SageMaker כדי להפעיל את המחברות הללו כעבודות מתוזמנות. ניתן להריץ את המשימות הללו באופן מיידי או בלוח זמנים חוזר ללא צורך בעובדי נתונים כדי לשחזר קוד כמודולים של Python. כמה מקרי שימוש נפוצים לעשות זאת כוללים:
- הפעלת מחברות עם ריצה ארוכה ברקע
- מסקנות מודל הפועלות באופן קבוע להפקת דוחות
- התרחבות מהכנת מערכי נתונים קטנים לדוגמה לעבודה עם נתונים גדולים בקנה מידה פטה-בייט
- אימון מחדש ופריסה של מודלים בקצב מסוים
- תזמון עבודות לניטור איכות מודל או סחף נתונים
- בחינת מרחב הפרמטרים לדגמים טובים יותר
למרות שפונקציונליות זו הופכת את זה לפשוט עבור עובדי נתונים לבצע אוטומציה של מחברות עצמאיות, זרימות עבודה של ML מורכבות לרוב ממספר מחברות, שכל אחת מהן מבצעת משימה ספציפית עם תלות מורכבת. לדוגמה, מחברת שמנטרת סחיפה של נתוני מודל צריכה להיות שלב מקדים המאפשר חילוץ, טרנספורמציה וטעינה (ETL) ועיבוד של נתונים חדשים ואחר-שלב של רענון והדרכה של המודל למקרה שמבחינים בסחיפה משמעותית . יתר על כן, מדעני נתונים עשויים לרצות להפעיל את כל זרימת העבודה הזו בלוח זמנים חוזר כדי לעדכן את המודל על סמך נתונים חדשים. כדי לאפשר לך להפוך בקלות את המחברות שלך לאוטומטיות וליצור זרימות עבודה מורכבות כל כך, עבודות מחברת SageMaker זמינות כעת כשלב ב-SageMaker Pipelines. בפוסט זה, אנו מראים כיצד ניתן לפתור את מקרי השימוש הבאים עם כמה שורות קוד:
- הפעל באופן פרוגרמטי מחברת עצמאית באופן מיידי או על פי לוח זמנים חוזר
- צור זרימות עבודה מרובות שלבים של מחברות כ-DAG למטרות אינטגרציה מתמשכת ואספקה מתמשכת (CI/CD) שניתן לנהל באמצעות ממשק המשתמש של SageMaker Studio
סקירת פתרונות
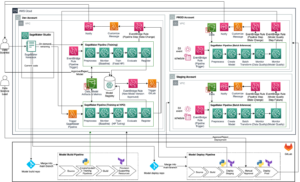
התרשים הבא ממחיש את ארכיטקטורת הפתרון שלנו. אתה יכול להשתמש ב-SageMaker Python SDK כדי להפעיל עבודת מחברת בודדת או זרימת עבודה. תכונה זו יוצרת עבודת אימון של SageMaker להפעלת המחברת.
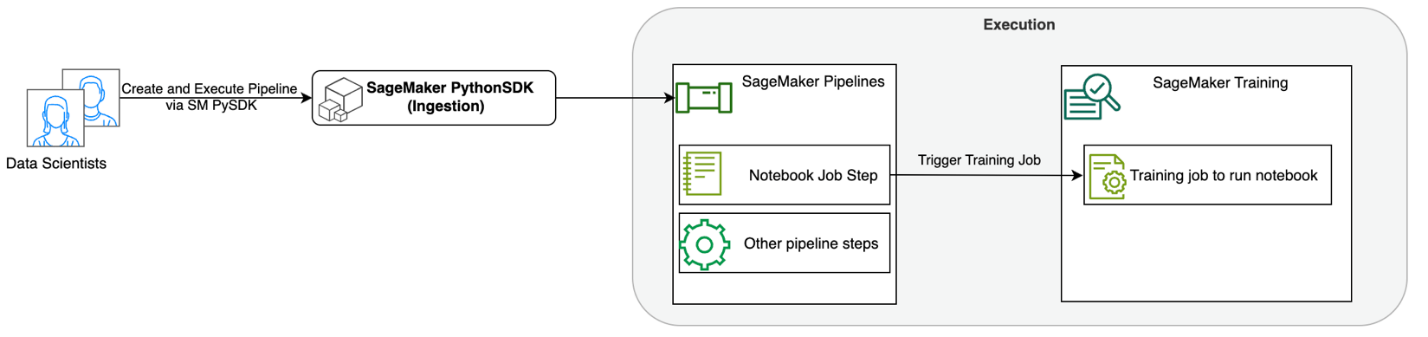
בסעיפים הבאים, אנו עוברים על מקרה שימוש לדוגמה ב-ML ומציגים את השלבים ליצירת זרימת עבודה של עבודות מחברת, העברת פרמטרים בין שלבי מחברת שונים, תזמון זרימת העבודה שלך וניטור שלו באמצעות SageMaker Studio.
עבור בעיית ה-ML שלנו בדוגמה זו, אנו בונים מודל לניתוח סנטימנטים, שהוא סוג של משימת סיווג טקסט. היישומים הנפוצים ביותר של ניתוח סנטימנטים כוללים ניטור מדיה חברתית, ניהול תמיכת לקוחות וניתוח משוב מלקוחות. מערך הנתונים המשמש בדוגמה זו הוא מערך הנתונים של Stanford Sentiment Treebank (SST2), המורכב מסקירות סרטים יחד עם מספר שלם (0 או 1) המציין את הסנטימנט החיובי או השלילי של הביקורת.
להלן דוגמה של א data.csv קובץ המתאים למערך הנתונים SST2, ומציג ערכים בשתי העמודות הראשונות שלו. שימו לב שלקובץ לא אמורה להיות כותרת כלשהי.
| הטור 1 | הטור 2 |
| 0 | להסתיר הפרשות חדשות מיחידות ההורים |
| 0 | אינו מכיל שנינות, רק סתימות עמל |
| 1 | שאוהב את הדמויות שלו ומתקשר משהו יפה למדי על הטבע האנושי |
| 0 | נשאר מרוצה לחלוטין להישאר זהה לאורך כל הדרך |
| 0 | על קלישאות נקמת-החנונים הכי גרועות שיוצרי הסרט יכלו לחפור |
| 0 | זה טרגי מדי מכדי לזכות לטיפול שטחי שכזה |
| 1 | מדגים שהבמאי של שוברי קופות בהוליווד כמו משחקי פטריוט עדיין יכול להמציא סרט קטן ואישי עם רעש רגשי. |
בדוגמה זו של ML, עלינו לבצע מספר משימות:
- בצע הנדסת תכונות כדי להכין מערך נתונים זה בפורמט שהמודל שלנו יכול להבין.
- הנדסה לאחר תכונות, הפעל שלב הדרכה המשתמש ברובוטריקים.
- הגדר מסקנות אצווה עם המודל המכוונן עדין כדי לעזור לחזות את הסנטימנט עבור ביקורות חדשות שיגיעו.
- הגדר שלב ניטור נתונים כדי שנוכל לעקוב באופן קבוע אחר הנתונים החדשים שלנו עבור כל סחיפה באיכות שעלולה לדרוש מאיתנו לאמן מחדש את משקלי הדגם.
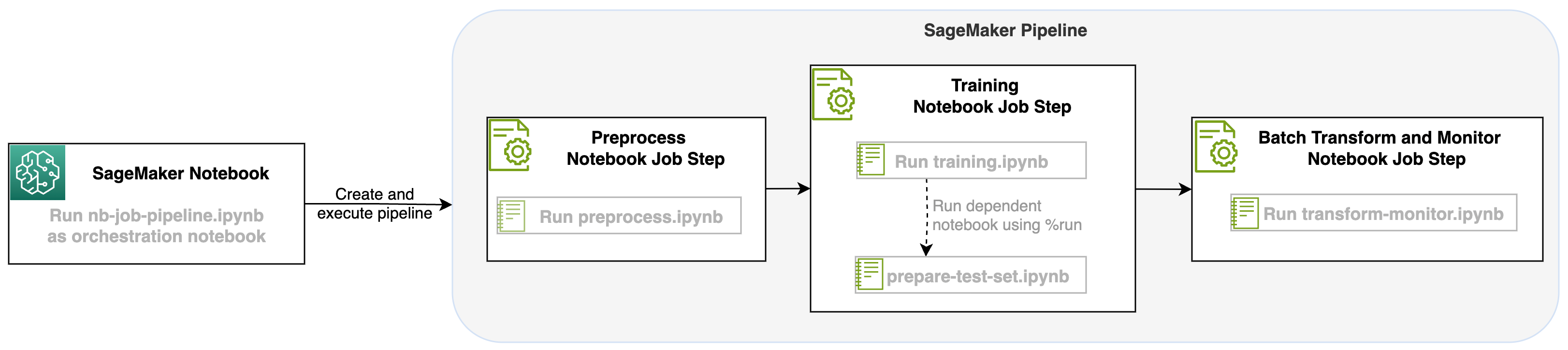
עם השקה זו של עבודת מחברת כשלב בצינורות של SageMaker, נוכל לתזמן את זרימת העבודה הזו, המורכבת משלושה שלבים נפרדים. כל שלב של זרימת העבודה מפותח במחברת אחרת, אשר מומרים לאחר מכן לשלבי עבודות מחברת עצמאיים ומחוברים כצינור:
- עיבוד מוקדם - הורד את מערך הנתונים הציבורי של SST2 מ שירות אחסון פשוט של אמזון (Amazon S3) וצור קובץ CSV להפעלת המחברת בשלב 2. מערך הנתונים SST2 הוא מערך נתונים לסיווג טקסט עם שתי תוויות (0 ו-1) ועמודת טקסט לקטגוריה.
- הדרכה - קח את קובץ ה-CSV המעוצב והפעל כוונון עדין עם BERT לסיווג טקסט תוך שימוש בספריות רובוטריקים. אנו משתמשים במחברת הכנת נתוני בדיקה כחלק משלב זה, המהווה תלות לשלב הכוונון וההסקת האצווה. כאשר הכוונון העדין הושלם, מחברת זו מופעלת באמצעות קסם הפעלה ומכינה מערך נתונים לבדיקה להסקת מסקנות לדוגמה עם המודל המכוונן.
- שינוי וניטור - בצע מסקנות אצווה והגדר איכות נתונים עם ניטור מודל כדי לקבל הצעת נתונים בסיסית.
הפעל את המחברות
הקוד לדוגמה עבור פתרון זה זמין ב- GitHub.
יצירת שלב עבודה של SageMaker מחברת דומה ליצירת שלבים אחרים של SageMaker Pipeline. בדוגמה של מחברת זו, אנו משתמשים ב- SageMaker Python SDK כדי לתזמן את זרימת העבודה. כדי ליצור שלב מחברת ב-SageMaker Pipelines, אתה יכול להגדיר את הפרמטרים הבאים:
- מחברת קלט – שם המחברת ששלב המחברת הזה יתזמר. כאן תוכל לעבור בנתיב המקומי למחברת הקלט. לחלופין, אם למחברת הזו יש מחברות אחרות שהיא פועלת, תוכל להעביר אותן ב-
AdditionalDependenciesפרמטר עבור שלב עבודת המחברת. - URI תמונה - תמונת ה-Docker מאחורי שלב העבודה של המחברת. זו יכולה להיות התמונות המוגדרות מראש ש-SageMaker כבר מספקת או תמונה מותאמת אישית שהגדרת ודחפת אליה מרשם מיכל אלסטי של אמזון (Amazon ECR). עיין בסעיף השיקולים בסוף פוסט זה לתמונות נתמכות.
- שם ליבה - שם הקרנל שבו אתה משתמש ב- SageMaker Studio. מפרט הליבה הזה רשום בתמונה שסיפקת.
- סוג מופע (אופציונלי) - ענן מחשוב אלסטי של אמזון סוג מופע (Amazon EC2) מאחורי עבודת המחברת שהגדרת ותפעל.
- פרמטרים (אופציונלי) – פרמטרים שתוכל להעביר שיהיו נגישים עבור המחברת שלך. ניתן להגדיר אותם בצמדי מפתח-ערך. בנוסף, ניתן לשנות פרמטרים אלה בין ריצות עבודות שונות של מחברת או ריצות צינור.
בדוגמה שלנו יש בסך הכל חמש מחברות:
- nb-job-pipeline.ipynb - זוהי המחברת הראשית שלנו שבה אנו מגדירים את הצינור ואת זרימת העבודה שלנו.
- preprocess.ipynb - מחברת זו היא השלב הראשון בזרימת העבודה שלנו ומכילה את הקוד שימשוך את מערך הנתונים הציבורי של AWS ויצור מתוכו קובץ CSV.
- training.ipynb - מחברת זו היא השלב השני בזרימת העבודה שלנו ומכילה קוד לקחת את ה-CSV מהשלב הקודם ולבצע הדרכה מקומית וכיוונון עדין. לצעד זה יש גם תלות ב-
prepare-test-set.ipynbמחברת כדי להוריד מערך בדיקה להסקת מסקנות עם המודל המכוונן. - prepare-test-set.ipynb - מחברת זו יוצרת מערך בדיקה שבו מחברת ההדרכה שלנו תשתמש בשלב השני של הצינור ותשתמש בהסקת מסקנות לדוגמה עם המודל המכוונן.
- transform-monitor.ipynb - מחברת זו היא השלב השלישי בזרימת העבודה שלנו והיא לוקחת את מודל BERT הבסיסי ומריצה עבודת טרנספורמציה של SageMaker, תוך הגדרת איכות נתונים עם ניטור מודלים.
לאחר מכן, אנו עוברים על המחברת הראשית nb-job-pipeline.ipynb, המשלב את כל מחברות המשנה לצינור ומפעיל את זרימת העבודה מקצה לקצה. שים לב שלמרות שהדוגמה הבאה מפעילה את המחברת פעם אחת בלבד, תוכל גם לתזמן את הצינור להפעיל את המחברת שוב ושוב. מתייחס תיעוד SageMaker להוראות מפורטות.
עבור שלב עבודת המחברת הראשון שלנו, אנו מעבירים פרמטר עם דלי S3 ברירת מחדל. אנחנו יכולים להשתמש בדלי הזה כדי לזרוק כל חפץ שנרצה זמין עבור שלבי הצינור האחרים שלנו. למחברת הראשונה (preprocess.ipynb), אנו מושכים את מערך הרכבות הציבורי של AWS SST2 ויוצרים ממנו קובץ CSV אימון שאנו דוחפים לדלי S3 הזה. ראה את הקוד הבא:
לאחר מכן נוכל להמיר מחברת זו ב-a NotebookJobStep עם הקוד הבא במחברת הראשית שלנו:
כעת, כשיש לנו קובץ CSV לדוגמה, אנו יכולים להתחיל לאמן את המודל שלנו במחברת ההדרכה שלנו. מחברת ההדרכה שלנו קולטת את אותו פרמטר עם דלי S3 ומושכת את מערך ההדרכה ממיקום זה. לאחר מכן אנו מבצעים כוונון עדין באמצעות אובייקט המאמן של Transformers עם קטע הקוד הבא:
לאחר כוונון עדין, אנו רוצים להריץ מסקנות אצווה כדי לראות כיצד המודל מתפקד. זה נעשה באמצעות מחברת נפרדת (prepare-test-set.ipynb) באותו נתיב מקומי שיוצר מערך נתונים לבדיקה כדי לבצע הסקה לגבי השימוש במודל המאומן שלנו. נוכל להפעיל את המחברת הנוספת במחברת ההדרכה שלנו עם תא הקסם הבא:
אנו מגדירים את התלות הנוספת הזו במחברת ב- AdditionalDependencies פרמטר בשלב עבודת המחברת השני שלנו:
כמו כן, עלינו לציין ששלב עבודת מחברת ההדרכה (שלב 2) תלוי בשלב עבודת המחברת מראש (שלב 1) באמצעות add_depends_on קריאת API באופן הבא:
הצעד האחרון שלנו, יקח את מודל BERT להפעיל טרנספורמציה של SageMaker Batch, תוך הגדרת לכידת נתונים ואיכות באמצעות SageMaker Model Monitor. שים לב שזה שונה משימוש במובנה לשנות or ללכוד צעדים דרך צינורות. המחברת שלנו עבור שלב זה תפעיל את אותם ממשקי API, אך יתבצע מעקב כשלב עבודה של מחברת. שלב זה תלוי ב-Training Job Step שהגדרנו קודם לכן, אז אנחנו גם מצלמים את זה עם הדגל תלוי_on.
לאחר שהשלבים השונים של זרימת העבודה שלנו הוגדרו, נוכל ליצור ולהפעיל את הצינור מקצה לקצה:
פיקוח על פעולות הצינור
אתה יכול לעקוב ולנטר את פעולות השלבים של המחברת באמצעות SageMaker Pipelines DAG, כפי שניתן לראות בצילום המסך הבא.
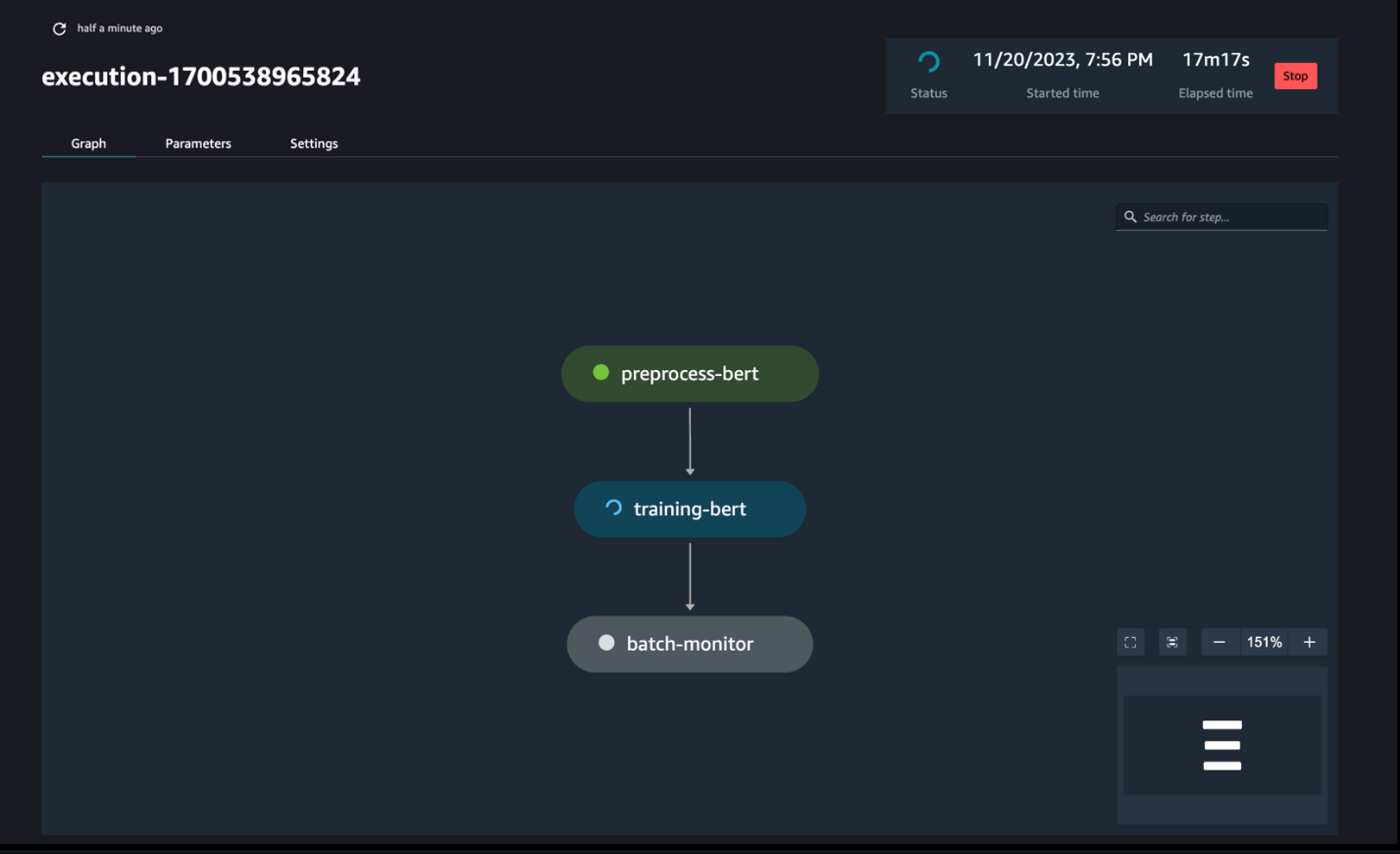
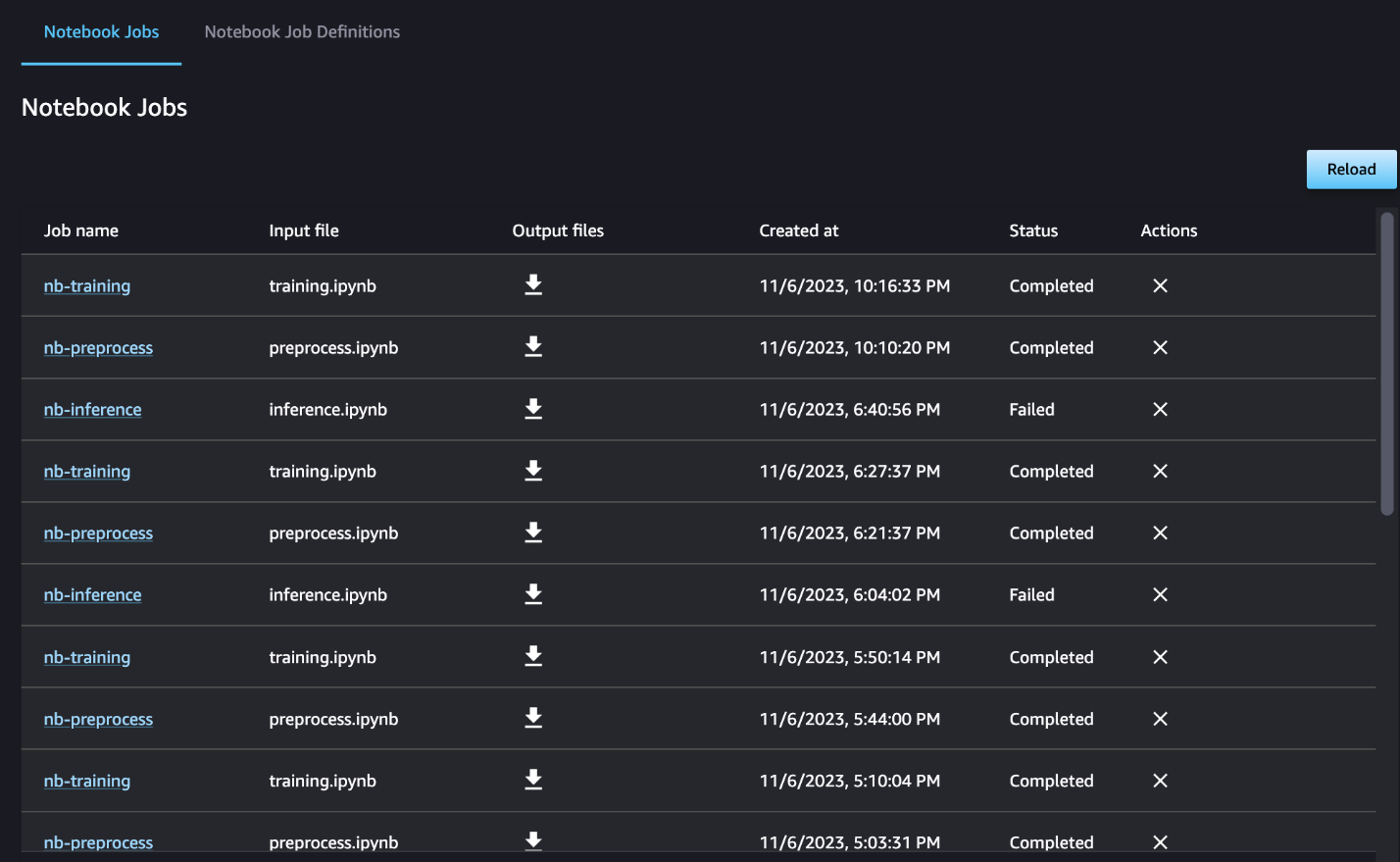
ניתן גם לפקח באופן אופציונלי על ריצות המחברת הבודדות בלוח המחוונים של עבודת המחברת ולהחליף את קבצי הפלט שנוצרו דרך ממשק המשתמש של SageMaker Studio. בעת שימוש בפונקציונליות זו מחוץ ל-SageMaker Studio, אתה יכול להגדיר את המשתמשים שיכולים לעקוב אחר מצב הריצה בלוח המחוונים של העבודה של המחברת באמצעות תגים. לפרטים נוספים על תגים שיש לכלול, ראה הצג את עבודות המחברת שלך והורד את הפלטים בלוח המחוונים של ממשק המשתמש של Studio.
עבור דוגמה זו, אנו פלט את עבודות המחברת שהתקבלו לספרייה בשם outputs בנתיב המקומי שלך עם קוד הפעלת הצינור שלך. כפי שמוצג בצילום המסך הבא, כאן אתה יכול לראות את הפלט של מחברת הקלט שלך וגם את כל הפרמטרים שהגדרת עבור אותו שלב.
לנקות את
אם עקבת אחר הדוגמה שלנו, הקפד למחוק את הצינור שנוצר, עבודות המחברת ואת נתוני ה-s3 שהורדו על ידי המחברות לדוגמה.
שיקולים
להלן כמה שיקולים חשובים עבור תכונה זו:
- אילוצי SDK - ניתן ליצור את שלב עבודת המחברת רק באמצעות ה-SageMaker Python SDK.
- אילוצי תמונה -שלב העבודה של המחברת תומך בתמונות הבאות:
סיכום
עם ההשקה הזו, עובדי נתונים יכולים כעת להפעיל את המחברות שלהם באופן פרוגרמטי עם כמה שורות קוד באמצעות SageMaker Python SDK. בנוסף, אתה יכול ליצור זרימות עבודה מורכבות מרובות שלבים באמצעות המחברות שלך, ולצמצם משמעותית את הזמן הדרוש לעבור ממחברת לצינור CI/CD. לאחר יצירת הצינור, אתה יכול להשתמש ב-SageMaker Studio כדי להציג ולהפעיל DAGs עבור הצינורות שלך ולנהל ולהשוות את הריצות. בין אם אתה מתזמן תהליכי עבודה ML מקצה לקצה או חלק מהם, אנו ממליצים לך לנסות זרימות עבודה מבוססות מחברת.
על המחברים
 אנצ'יט גופטה הוא מנהל מוצר בכיר ב-Amazon SageMaker Studio. היא מתמקדת בהפעלת תהליכי עבודה אינטראקטיביים של מדע נתונים והנדסת נתונים מתוך SageMaker Studio IDE. בזמנה הפנוי היא נהנית לבשל, לשחק משחקי לוח/קלפים ולקרוא.
אנצ'יט גופטה הוא מנהל מוצר בכיר ב-Amazon SageMaker Studio. היא מתמקדת בהפעלת תהליכי עבודה אינטראקטיביים של מדע נתונים והנדסת נתונים מתוך SageMaker Studio IDE. בזמנה הפנוי היא נהנית לבשל, לשחק משחקי לוח/קלפים ולקרוא.
 רם וג'יראג'ו הוא אדריכל ML עם צוות שירות SageMaker. הוא מתמקד בסיוע ללקוחות לבנות ולמטב את פתרונות ה-AI/ML שלהם ב-Amazon SageMaker. בזמנו הפנוי הוא אוהב לטייל ולכתוב.
רם וג'יראג'ו הוא אדריכל ML עם צוות שירות SageMaker. הוא מתמקד בסיוע ללקוחות לבנות ולמטב את פתרונות ה-AI/ML שלהם ב-Amazon SageMaker. בזמנו הפנוי הוא אוהב לטייל ולכתוב.
 אדוארד סאן הוא SDE בכיר שעובד עבור SageMaker Studio בשירותי האינטרנט של Amazon. הוא מתמקד בבניית פתרון ML אינטראקטיבי ובפישוט חווית הלקוח כדי לשלב את SageMaker Studio עם טכנולוגיות פופולריות בהנדסת נתונים ואקוסיסטם ML. בזמנו הפנוי, אדוארד מעריץ גדול של קמפינג, טיולים ודיג ונהנה מהזמן לבלות עם משפחתו.
אדוארד סאן הוא SDE בכיר שעובד עבור SageMaker Studio בשירותי האינטרנט של Amazon. הוא מתמקד בבניית פתרון ML אינטראקטיבי ובפישוט חווית הלקוח כדי לשלב את SageMaker Studio עם טכנולוגיות פופולריות בהנדסת נתונים ואקוסיסטם ML. בזמנו הפנוי, אדוארד מעריץ גדול של קמפינג, טיולים ודיג ונהנה מהזמן לבלות עם משפחתו.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :יש ל
- :הוא
- :איפה
- $ למעלה
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- אודות
- נגיש
- מחזורי
- נוסף
- בנוסף
- יתרון
- לאחר
- AI / ML
- תעשיות
- מאפשר
- לאורך
- כְּבָר
- גם
- למרות
- אמזון בעברית
- אמזון
- אמזון SageMaker
- סטודיו SageMaker של אמזון
- אמזון שירותי אינטרנט
- an
- אנליזה
- ניתוח
- ו
- כל
- API
- ממשקי API
- יישומים
- ארכיטקטורה
- ARE
- AS
- At
- אוטומטי
- זמין
- AWS
- בסיס
- מבוסס
- Baseline
- BE
- יפה
- היה
- מאחור
- להיות
- מוטב
- בֵּין
- גָדוֹל
- לִבנוֹת
- בִּניָן
- מובנה
- אבל
- by
- שיחה
- נקרא
- קמפינג
- CAN
- ללכוד
- מקרה
- מקרים
- תא
- תווים
- מיון
- קוד
- טור
- עמודות
- משלב
- איך
- Common
- לְהַשְׁווֹת
- להשלים
- מורכב
- מורכב
- מורכב
- לחשב
- לנהל
- מחובר
- שיקולים
- מורכב
- מכולה
- מכיל
- רציף
- להמיר
- הומר
- בישול
- תוֹאֵם
- יכול
- לִיצוֹר
- נוצר
- יוצר
- יוצרים
- כיום
- מנהג
- לקוח
- חווית לקוח
- שירות לקוחות
- לקוחות
- DAG
- לוח מחוונים
- נתונים
- ניטור נתונים
- הכנת נתונים
- עיבוד נתונים
- איכות נתונים
- מדע נתונים
- מערכי נתונים
- בְּרִירַת מֶחדָל
- לְהַגדִיר
- מוגדר
- מסירה
- דרישה
- תלות
- תלות
- תלוי
- תלוי
- לפרוס
- פריסה
- מְפוֹרָט
- פרטים
- לפתח
- מפותח
- אחר
- ישיר
- מְכוּוָן
- מְנַהֵל
- מובהק
- סַוָר
- עושה
- עשה
- מטה
- להורדה
- שפך
- כל אחד
- בקלות
- המערכת האקולוגית
- אדוארד
- לאפשר
- מה שמאפשר
- לעודד
- סוף
- מקצה לקצה
- הנדסה
- שלם
- תקופה
- Ether (ETH)
- דוגמה
- לבצע
- הוצאת להורג
- ניסיון
- נוסף
- תמצית
- משפחה
- אוהד
- רחוק
- מאפיין
- מָשׁוֹב
- מעטים
- שלח
- קבצים
- סרט צילום
- יוצרי סרטים
- ראשון
- דיג
- חמש
- מרוכז
- מתמקד
- בעקבות
- הבא
- כדלקמן
- בעד
- טופס
- פוּרמָט
- החל מ-
- לגמרי
- פונקציונלי
- יתר על כן
- משחקים
- ליצור
- גרפים
- יש
- he
- לעזור
- עזרה
- לה
- כאן
- טיולים
- שֶׁלוֹ
- הוליווד
- איך
- HTML
- http
- HTTPS
- בן אנוש
- if
- מדגים
- תמונה
- תמונות
- מיד
- לייבא
- חשוב
- in
- לכלול
- עצמאי
- מצביע על
- בנפרד
- קלט
- למשל
- הוראות
- לשלב
- השתלבות
- אינטראקטיבי
- אל תוך
- IT
- שֶׁלָה
- עבודה
- מקומות תעסוקה
- jpg
- רק
- תווית
- תוויות
- אחרון
- לשגר
- למידה
- ספריות
- קו
- קווים
- לִטעוֹן
- מקומי
- מיקום
- ארוך
- אוהב
- מכונה
- למידת מכונה
- קסם
- ראשי
- עושה
- לנהל
- הצליח
- ניהול
- מנהל
- מדיה
- לִזכּוֹת
- יכול
- ML
- מודל
- מודלים
- שונים
- מודולים
- צג
- ניטור
- צגים
- יותר
- רוב
- המהלך
- סרט
- מספר
- צריך
- שם
- יליד
- צורך
- נחוץ
- שלילי
- חדש
- לא
- הערות
- מחברה
- מחשבים ניידים
- עַכשָׁיו
- אובייקט
- of
- לעתים קרובות
- on
- ONE
- רק
- מטב
- or
- תזמור
- אחר
- שלנו
- הַחוּצָה
- תפוקה
- פלטים
- בחוץ
- זוגות
- פרמטר
- פרמטרים
- חלק
- לעבור
- חולף
- נתיב
- לבצע
- ביצוע
- אישי
- צינור
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- משחק
- פופולרי
- חיובי
- הודעה
- לחזות
- הכנה
- להכין
- מכין
- העריכה
- קודם
- קוֹדֶם
- בעיה
- תהליך
- המוצר
- מנהל מוצר
- לספק
- ובלבד
- מספק
- ציבורי
- מושך
- למטרות
- דחוף
- דחף
- פיתון
- איכות
- מהר
- R
- במקום
- חומר עיוני
- קריאה
- חוזר
- הפחתה
- רפקטור
- להתייחס
- רשום
- באופן קבוע
- להשאר
- שוב ושוב
- לדרוש
- וכתוצאה מכך
- סקירה
- חוות דעת של לקוחותינו
- הפעלה
- ריצה
- פועל
- בעל חכמים
- צינורות SageMaker
- אותו
- מרוצה
- לוח זמנים
- מתוכנן
- עבודות מתוזמנות
- תזמון
- מדע
- מדענים
- Sdk
- שְׁנִיָה
- סעיף
- סעיפים
- לִרְאוֹת
- לראות
- לחצני מצוקה לפנסיונרים
- רגש
- נפרד
- שרות
- שירותים
- מושב
- סט
- הצבה
- כמה
- מְעוּצָב
- היא
- צריך
- לְהַצִיג
- ראווה
- הראה
- הופעות
- משמעותי
- באופן משמעותי
- דומה
- פָּשׁוּט
- מפשט
- יחיד
- קטן
- קטן יותר
- קטע
- So
- חֶברָתִי
- מדיה חברתית
- פִּתָרוֹן
- פתרונות
- לפתור
- כמה
- משהו
- מֶרחָב
- ספציפי
- הוצאה
- עצמאי
- סטנפורד
- התחלה
- מצב
- שלב
- צעדים
- עוד
- אחסון
- פשוט
- סטודיו
- כזה
- שמש
- תמיכה
- נתמך
- תומך
- בטוח
- לקחת
- לוקח
- המשימות
- משימות
- נבחרת
- טכנולוגיות
- מבחן
- טֶקסט
- סיווג טקסט
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- אלה
- שְׁלִישִׁי
- זֶה
- אלה
- שְׁלוֹשָׁה
- דרך
- זמן
- ל
- יַחַד
- גַם
- כלי
- סה"כ
- לעקוב
- רכבת
- מְאוּמָן
- הדרכה
- לשנות
- רוֹבּוֹטרִיקִים
- נסיעה
- להפעיל
- תור
- שתיים
- סוג
- ui
- להבין
- עדכון
- us
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמשים
- שימושים
- באמצעות
- ניצול
- ערכים
- שונים
- באמצעות
- לצפיה
- לחזות
- ללכת
- רוצה
- we
- אינטרנט
- שירותי אינטרנט
- מתי
- אם
- אשר
- בזמן
- מי
- יצטרך
- עם
- בתוך
- לְלֹא
- עובדים
- זרימת עבודה
- זרימות עבודה
- עובד
- גרוע
- כתיבה
- אתה
- זפירנט