תמונה על ידי פריפיק
בינה מלאכותית לשיחה מתייחסת לסוכנים וירטואליים וצ'אטבוטים המחקים אינטראקציות אנושיות ויכולים לשלב בני אדם בשיחה. שימוש בבינה מלאכותית של שיחה הופך במהירות לדרך חיים - מלבקש מ-Alexa ועד "למצוא את המסעדה הקרובה ביותר” לבקש מסירי "ליצור תזכורת", עוזרים וירטואליים וצ'אטבוטים משמשים לעתים קרובות כדי לענות על שאלות של צרכנים, לפתור תלונות, לבצע הזמנות ועוד הרבה יותר.
פיתוח עוזרים וירטואליים אלה דורש מאמץ משמעותי. עם זאת, הבנה והתייחסות לאתגרים המרכזיים יכולים לייעל את תהליך הפיתוח. השתמשתי בניסיון ממקור ראשון שלי ביצירת צ'טבוט בוגר עבור פלטפורמת גיוס כנקודת התייחסות כדי להסביר את האתגרים המרכזיים והפתרונות המתאימים להם.
כדי לבנות צ'אטבוט של AI לשיחות, מפתחים יכולים להשתמש במסגרות כמו RASA, Lex של אמזון או Dialogflow של Google כדי לבנות צ'אטבוטים. רובם מעדיפים את RASA כשהם מתכננים שינויים מותאמים אישית או שהבוט נמצא בשלב בוגר מכיוון שהוא מסגרת קוד פתוח. גם מסגרות אחרות מתאימות כנקודת התחלה.
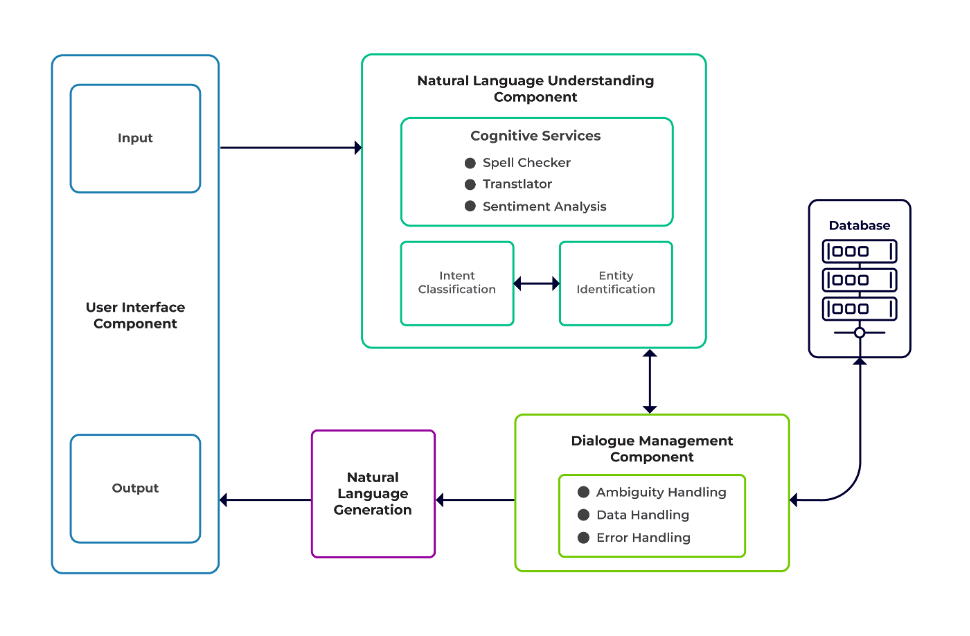
ניתן לסווג את האתגרים כשלושה מרכיבים עיקריים של צ'אט בוט.
הבנת שפה טבעית (NLU) היא היכולת של בוט להבין דיאלוג אנושי. הוא מבצע סיווג כוונות, מיצוי ישויות ואחזור תגובות.
מנהל דיאלוג אחראי על קבוצת פעולות שתבוצע בהתבסס על הסט הנוכחי והקודם של קלט המשתמש. זה לוקח כוונה וישויות כקלט (כחלק מהשיחה הקודמת) ומזהה את התגובה הבאה.
דור שפה טבעית (NLG) הוא תהליך של יצירת משפטים כתובים או מדוברים מנתונים נתונים. זה ממסגר את התגובה, אשר מוצגת לאחר מכן למשתמש.
תמונה מתוכנת Talentica
מידע לא מספק
כאשר מפתחים מחליפים שאלות נפוצות או מערכות תמיכה אחרות בצ'אטבוט, הם מקבלים כמות הגונה של נתוני הדרכה. אבל אותו דבר לא קורה כשהם יוצרים את הבוט מאפס. במקרים כאלה, מפתחים מייצרים נתוני אימון באופן סינתטי.
מה לעשות?
מחולל נתונים מבוסס תבניות יכול ליצור כמות הגונה של שאילתות משתמשים להדרכה. ברגע שהצ'אט בוט מוכן, בעלי הפרויקט יכולים לחשוף אותו למספר מוגבל של משתמשים כדי לשפר את נתוני ההדרכה ולשדרג אותם לאורך תקופה.
בחירת דגמים לא מתאימה
נתוני בחירת מודל ונתוני הכשרה מתאימים הם חיוניים כדי לקבל את התוצאות הטובות ביותר של הכוונה ושל מיצוי הישות. מפתחים בדרך כלל מאמנים צ'אטבוטים בשפה ובדומיין ספציפיים, ורוב המודלים הזמינים שהוכשרו מראש הם לרוב ספציפיים לדומיין ומאומנים בשפה אחת.
יכולים להיות מקרים של שפות מעורבות גם שבהם אנשים הם פוליגלוטים. הם עשויים להזין שאילתות בשפה מעורבת. לדוגמה, באזור הנשלט על ידי צרפת, אנשים עשויים להשתמש בסוג של אנגלית שהוא שילוב של צרפתית ואנגלית כאחד.
מה לעשות?
שימוש במודלים מאומנים במספר שפות עשוי להפחית את הבעיה. מודל שהוכשר מראש כמו LaBSE (הטבעת משפטים של ברט אגנוסטית) יכול להיות מועיל במקרים כאלה. LaBSE מאומן ביותר מ-109 שפות במשימת דמיון במשפט. המודל כבר מכיר מילים דומות בשפה אחרת. בפרויקט שלנו זה עבד ממש טוב.
חילוץ ישות לא תקין
צ'אטבוטים דורשים מהישויות לזהות איזה סוג של נתונים המשתמש מחפש. ישויות אלה כוללות זמן, מקום, אדם, פריט, תאריך וכו'. עם זאת, בוטים עלולים להיכשל בזיהוי ישות משפה טבעית:
אותו הקשר אבל ישויות שונות. לדוגמה, בוטים יכולים לבלבל מקום כישות כאשר משתמש מקליד "שם סטודנטים מ- IIT Delhi" ולאחר מכן "שם סטודנטים מבנגלורו".
תרחישים שבהם הישויות צפויות בצורה שגויה עם ביטחון נמוך. לדוגמה, בוט יכול לזהות את IIT Delhi כעיר עם ביטחון נמוך.
מיצוי ישות חלקית על ידי מודל למידת מכונה. אם משתמש מקליד "סטודנטים מ- IIT Delhi", המודל יכול לזהות את "IIT" רק כישות במקום "IIT Delhi".
קלט של מילה אחת ללא הקשר יכול לבלבל את המודלים של למידת מכונה. לדוגמה, מילה כמו "רישיקש" יכולה להיות משמעותה גם בשם של אדם וגם של עיר.
מה לעשות?
הוספת דוגמאות נוספות לאימון יכולה להיות פתרון. אבל יש גבול שאחריו הוספת עוד לא תעזור. יתר על כן, זה תהליך אינסופי. פתרון אחר יכול להיות להגדיר דפוסי ביטוי רגולרי באמצעות מילים מוגדרות מראש כדי לעזור לחלץ ישויות עם קבוצה ידועה של ערכים אפשריים, כמו עיר, מדינה וכו'.
מודלים חולקים ביטחון נמוך יותר בכל פעם שהם לא בטוחים לגבי חיזוי הישות. מפתחים יכולים להשתמש בזה כטריגר לקרוא לרכיב מותאם אישית שיכול לתקן את הישות בעלת הביטחון העצמי נמוך. בואו ניקח בחשבון את הדוגמה לעיל. אם IIT דלהי חזויה כעיר עם ביטחון נמוך, אז המשתמש תמיד יכול לחפש אותה במסד הנתונים. לאחר שלא הצליח למצוא את הישות החזויה ב- עִיר הטבלה, המודל ימשיך לטבלאות אחרות ובסופו של דבר ימצא אותו ב- מכון טבלה, וכתוצאה מכך תיקון ישות.
סיווג כוונה שגוי
לכל הודעת משתמש יש כוונה כלשהי הקשורה אליה. מכיוון שהכוונות נובעות מהדרך הבאה של פעולות של בוט, סיווג נכון של שאילתות משתמשים עם כוונה הוא חיוני. עם זאת, מפתחים חייבים לזהות כוונות עם מינימום בלבול בין כוונות. אחרת, יכולים להיות מקרים עם בלבול. לדוגמה, "תראה לי משרות פתוחות" לעומת. "הראה לי מועמדים לתפקיד פתוח".
מה לעשות?
ישנן שתי דרכים להבדיל בין שאילתות מבלבלות. ראשית, מפתח יכול להציג כוונת משנה. שנית, מודלים יכולים לטפל בשאילתות על סמך ישויות שזוהו.
צ'אט בוט ספציפי לתחום צריך להיות מערכת סגורה שבה הוא צריך לזהות בבירור למה הוא מסוגל ומה לא. מפתחים חייבים לבצע את הפיתוח בשלבים תוך תכנון של צ'אטבוטים ספציפיים לדומיין. בכל שלב, הם יכולים לזהות את התכונות הלא נתמכות של הצ'אטבוט (דרך כוונה לא נתמכת).
הם יכולים גם לזהות את מה שהצ'אטבוט לא יכול להתמודד בכוונה "מחוץ לתחום". אבל יכולים להיות מקרים שבהם הבוט מבולבל בגלל כוונה שאינה נתמכת ומחוץ לטווח. עבור תרחישים כאלה, מנגנון החזרה צריך להיות במקום שבו, אם ביטחון הכוונה הוא מתחת לסף, המודל יכול לעבוד בחן עם כוונה חילופין לטפל במקרים של בלבול.
ברגע שהבוט מזהה את כוונת ההודעה של משתמש, עליו לשלוח תגובה בחזרה. בוט מחליט את התגובה על סמך קבוצה מסוימת של כללים וסיפורים מוגדרים. לדוגמה, כלל יכול להיות פשוט כמו מוחלט "בוקר טוב" כאשר המשתמש מברך "היי". עם זאת, לרוב, שיחות עם צ'אטבוטים מהוות אינטראקציה המשך, והתגובות שלהם תלויות בהקשר הכולל של השיחה.
מה לעשות?
כדי להתמודד עם זה, צ'אטבוטים מוזנים בדוגמאות שיחה אמיתיות הנקראות סיפורים. עם זאת, משתמשים לא תמיד מקיימים אינטראקציה כמתוכנן. צ'אט בוט בוגר צריך לטפל בכל הסטיות הללו בחן. מעצבים ומפתחים יכולים להבטיח זאת אם הם לא רק יתמקדו בדרך מאושרת בזמן כתיבת סיפורים אלא גם יעבדו בשבילים אומללים.
מעורבות המשתמשים בצ'אטבוטים מסתמכת במידה רבה על תגובות הצ'אטבוטים. משתמשים עלולים לאבד עניין אם התגובות רובוטיות מדי או מוכרות מדי. לדוגמה, ייתכן שמשתמש לא יאהב תשובה כמו "הקלדת שאילתה שגויה" עבור קלט שגוי למרות שהתגובה נכונה. התשובה כאן לא תואמת את הדמות של עוזר.
מה לעשות?
הצ'אטבוט משמש כעוזר וצריך להיות בעל אישיות וטון דיבור ספציפיים. הם צריכים להיות מסבירי פנים וצנועים, והמפתחים צריכים לעצב שיחות והתבטאויות בהתאם. התגובות לא אמורות להישמע רובוטיות או מכניות. לדוגמה, הבוט יכול לומר, "מצטער, נראה שאין לי פרטים. תוכל בבקשה להקליד מחדש את השאילתה שלך?" לטפל בקלט שגוי.
צ'אטבוטים מבוססי LLM (Large Language Model) כמו ChatGPT ו-Bard הם חידושים משנים משחקים ושיפרו את היכולות של AIs לשיחה. הם לא רק טובים בניהול שיחות פתוחות דמויות אנושיות, אלא יכולים לבצע משימות שונות כמו סיכום טקסט, כתיבת פסקאות וכו', שניתן להשיג מוקדם יותר רק על ידי מודלים ספציפיים.
אחד האתגרים עם מערכות צ'טבוט מסורתיות הוא לקטלג כל משפט לכוונות ולהחליט על התגובה בהתאם. גישה זו אינה מעשית. תגובות כמו "סליחה, לא הצלחתי להשיג אותך" מרגיזים לעתים קרובות. מערכות צ'אט בוט חסרות כוונות הן הדרך קדימה, וחברות LLM יכולות להפוך את זה למציאות.
LLMs יכולים בקלות להשיג תוצאות מתקדמות בזיהוי ישויות כלליות, תוך חסימת זיהוי ישויות ספציפיות לתחום. גישה מעורבת לשימוש ב-LLMs עם כל מסגרת צ'אטבוט יכולה לעורר מערכת צ'טבוט בוגרת וחזקה יותר.
עם ההתקדמות העדכנית ביותר והמחקר המתמשך בתחום הבינה המלאכותית של שיחה, הצ'אטבוטים משתפרים מיום ליום. תחומים כמו טיפול במשימות מורכבות עם כוונות מרובות, כמו "הזמנת טיסה למומבאי ותארגן מונית לדאדר", זוכים לתשומת לב רבה.
בקרוב יתקיימו שיחות מותאמות אישית על סמך המאפיינים של המשתמש כדי לשמור על מעורבות המשתמש. לדוגמה, אם בוט מגלה שהמשתמש אינו מרוצה, הוא מפנה את השיחה לסוכן אמיתי. בנוסף, עם נתוני צ'אטבוט הולכים וגדלים, טכניקות למידה עמוקה כמו ChatGPT יכולות ליצור באופן אוטומטי תגובות לשאילתות באמצעות בסיס ידע.
סומאן סאורב הוא מדען נתונים בחברת Talentica Software, חברה לפיתוח מוצרי תוכנה. הוא בוגר של NIT Agartala עם למעלה מ-8 שנות ניסיון בתכנון והטמעה של פתרונות בינה מלאכותית מהפכנית תוך שימוש ב-NLP, בינה מלאכותית בשיחה ובינה מלאכותית.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :יש ל
- :הוא
- :לֹא
- :איפה
- 8
- a
- יכולת
- אודות
- מֵעַל
- לפיכך
- להשיג
- הושג
- לרוחב
- פעולות
- מוסיף
- בנוסף
- כתובת
- פְּנִיָה
- התקדמות
- לאחר
- סוֹכֵן
- סוכנים
- AI
- צ 'אט AI
- Alexa
- תעשיות
- כְּבָר
- גם
- בוגר
- תמיד
- כמות
- an
- ו
- אחר
- לענות
- כל
- גישה
- ARE
- אזורים
- AS
- לשאול
- עוזר
- עוזרים
- המשויך
- At
- תשומת לב
- באופן אוטומטי
- זמין
- לְהִמָנַע
- בחזרה
- בסיס
- מבוסס
- BE
- התהוות
- ישויות
- להלן
- הטוב ביותר
- מוטב
- בוט
- שניהם
- בוטים
- לִבנוֹת
- אבל
- by
- שיחה
- נקרא
- CAN
- לא יכול
- יכולות
- מסוגל
- מקרים
- סיווג
- מסוים
- האתגרים
- שינויים
- מאפיינים
- chatbot
- chatbots
- ChatGPT
- עִיר
- מיון
- מְסוּוָג
- בבירור
- סגור
- חברה
- תלונות
- מורכב
- רְכִיב
- רכיבים
- לִהַבִין
- אמון
- מבולבל
- מבלבל
- בלבול
- לשקול
- הקשר
- רציף
- שיחה
- שיחה
- AI שיחה
- שיחות
- לתקן
- צורה נכונה
- תוֹאֵם
- יכול
- מדינה
- קורס
- לִיצוֹר
- יוצרים
- מכריע
- נוֹכְחִי
- מנהג
- נתונים
- מדען נתונים
- מסד נתונים
- תַאֲרִיך
- יְוֹם
- הגון
- מחליטים
- עמוק
- למידה עמוקה
- לְהַגדִיר
- מוגדר
- דלהי
- לסמוך
- לגזור
- עיצוב
- מעצבים
- תכנון
- פרטים
- מפתח
- מפתחים
- צעצועי התפתחות
- זרימת דיאלוג
- דיאלוג
- אחר
- להבחין
- do
- לא
- תחום
- לא
- כל אחד
- מוקדם יותר
- בקלות
- מאמץ
- הטבעה
- אין סופי
- לעסוק
- מאורס
- התעסקות
- אנגלית
- להגביר את
- זן
- ישויות
- ישות
- וכו '
- אֲפִילוּ
- בסופו של דבר
- הולך וגובר
- כל
- כל יום
- דוגמה
- דוגמאות
- ניסיון
- להסביר
- תמצית
- הוֹצָאָה
- FAIL
- אי
- מוכר
- מהר
- תכונות
- הפד
- ממצאים
- טיסה
- להתמקד
- בעד
- קדימה
- מסגרת
- מסגרות
- צרפתית
- החל מ-
- כללי
- ליצור
- יצירת
- דור
- גנרטטיבית
- AI Generative
- גנרטור
- לקבל
- מקבל
- נתן
- טוב
- גוגל
- אַחֲרָיוּת
- לטפל
- טיפול
- לקרות
- שמח
- יש
- יש
- he
- בִּכְבֵדוּת
- לעזור
- מועיל
- כאן
- איך
- איך
- אולם
- HTTPS
- בן אנוש
- צנוע
- i
- מזוהה
- מזהה
- לזהות
- if
- יישום
- משופר
- in
- לכלול
- חידושים
- קלט
- תשומות
- לעורר
- למשל
- במקום
- התכוון
- כוונה
- אינטראקציה
- אינטראקציה
- יחסי גומלין
- אינטרס
- אל תוך
- מבוא
- IT
- jpg
- רק
- KDnuggets
- שמור
- מפתח
- סוג
- ידע
- ידוע
- יודע
- שפה
- שפות
- גָדוֹל
- האחרון
- למידה
- החיים
- כמו
- להגביל
- מוגבל
- לינקדין
- להפסיד
- נמוך
- להוריד
- מכונה
- למידת מכונה
- גדול
- לעשות
- עשייה
- להתאים
- בוגר
- מאי..
- me
- אומר
- מֵכָנִי
- מנגנון
- הודעה
- יכול
- מינימלי
- לערבב
- מעורב
- מודל
- מודלים
- יותר
- יתר על כן
- רוב
- הרבה
- מספר
- מומבאי
- צריך
- my
- שם
- שם
- טבעי
- שפה טבעית
- הבא
- NLG
- NLP
- nlu
- לא
- מספר
- of
- לעתים קרובות
- on
- פעם
- רק
- לפתוח
- קוד פתוח
- or
- אחר
- אַחֶרֶת
- שלנו
- יותר
- מקיף
- בעלי
- חלק
- נתיב
- שבילים
- דפוסי
- אֲנָשִׁים
- לבצע
- ביצעתי
- מבצע
- תקופה
- אדם
- אישית
- שלב
- שלבים
- מקום
- תכנית
- תכנון
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- אנא
- נקודה
- עמדה
- להחזיק
- אפשרי
- מעשי
- חזה
- נבואה
- לְהַעֲדִיף
- מוצג
- קודם
- בעיה
- להמשיך
- תהליך
- המוצר
- פיתוח מוצר
- פּרוֹיֶקט
- שאילתות
- שאלות
- R
- טאבולה
- מוכן
- ממשי
- מציאות
- בֶּאֱמֶת
- הכרה
- גיוס
- להפחית
- הפניה
- מתייחס
- באזור
- לסמוך
- תזכורת
- להחליף
- לדרוש
- דורש
- מחקר
- לפתור
- תגובה
- תגובות
- אחראי
- וכתוצאה מכך
- תוצאות
- מהפכני
- חָסוֹן
- כלל
- כללי
- אותו
- לומר
- תרחישים
- מַדְעָן
- לגרד
- חיפוש
- חיפוש
- נראה
- מבחר
- לשלוח
- משפט
- משמש
- סט
- שיתוף
- צריך
- דומה
- פָּשׁוּט
- since
- יחיד
- Siri
- תוכנה
- פִּתָרוֹן
- פתרונות
- כמה
- קול
- ספציפי
- דיבר
- התמחות
- החל
- מדינה-of-the-art
- סיפורים
- לייעל
- סטודנטים
- ניכר
- כזה
- מַתְאִים
- תמיכה
- מערכות תמיכה
- בטוח
- באופן סינתטי
- מערכת
- מערכות
- T
- שולחן
- לקחת
- לוקח
- המשימות
- משימות
- טכניקות
- טֶקסט
- מֵאֲשֶׁר
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- שם.
- אלה
- הֵם
- זֶה
- אם כי?
- שְׁלוֹשָׁה
- סף
- זמן
- ל
- צליל
- טון דיבור
- גַם
- מסורתי
- רכבת
- מְאוּמָן
- הדרכה
- להפעיל
- שתיים
- סוג
- סוגים
- הבנה
- שדרוג
- להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- באמצעות
- בְּדֶרֶך כְּלַל
- ערכים
- באמצעות
- וירטואלי
- קול
- vs
- W
- דֶרֶך..
- דרכים
- בברכה
- טוֹב
- מה
- מתי
- בכל פעם
- אשר
- בזמן
- יצטרך
- עם
- Word
- מילים
- תיק עבודות
- עבד
- היה
- כתיבה
- כתוב
- טעות
- שנים
- אתה
- זפירנט