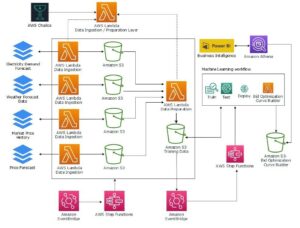
הטמעות ממלאות תפקיד מפתח בעיבוד שפה טבעית (NLP) ולמידת מכונה (ML). הטבעת טקסט מתייחס לתהליך של הפיכת טקסט לייצוגים מספריים השוכנים במרחב וקטורי ממדי גבוה. טכניקה זו מושגת באמצעות שימוש באלגוריתמי ML המאפשרים הבנת המשמעות וההקשר של נתונים (יחסים סמנטיים) ולמידה של קשרים ודפוסים מורכבים בתוך הנתונים (יחסים תחביריים). אתה יכול להשתמש בייצוגים הוקטוריים המתקבלים עבור מגוון רחב של יישומים, כגון אחזור מידע, סיווג טקסט, עיבוד שפה טבעית ועוד רבים אחרים.
הטבעות טקסט של אמזון טיטאן הוא מודל הטמעת טקסט הממיר טקסט בשפה טבעית - המורכב ממילים בודדות, ביטויים או אפילו מסמכים גדולים - לייצוגים מספריים שניתן להשתמש בהם כדי להשתמש במקרי שימוש כוחניים כגון חיפוש, התאמה אישית ואשכולות בהתבסס על דמיון סמנטי.
בפוסט זה, אנו דנים במודל Amazon Titan Text Embeddings, תכונותיו ומקרי שימוש לדוגמה.
כמה מושגי מפתח כוללים:
- ייצוג מספרי של טקסט (וקטורים) לוכד סמנטיקה ויחסים בין מילים
- ניתן להשתמש בהטבעות עשירות כדי להשוות דמיון טקסט
- הטבעת טקסט רב לשונית יכולה לזהות משמעות בשפות שונות
כיצד מומר פיסת טקסט לווקטור?
ישנן מספר טכניקות להמרת משפט לווקטור. שיטה פופולרית אחת היא שימוש באלגוריתמים להטמעת מילים, כגון Word2Vec, GloVe או FastText, ולאחר מכן צבירת הטמעות המילה ליצירת ייצוג וקטור ברמת המשפט.
גישה נפוצה נוספת היא להשתמש במודלים של שפה גדולה (LLMs), כמו BERT או GPT, שיכולים לספק הטבעות בהקשר של משפטים שלמים. מודלים אלו מבוססים על ארכיטקטורות למידה עמוקה כגון רובוטריקים, שיכולות ללכוד את המידע ההקשרי והקשרים בין מילים במשפט בצורה יעילה יותר.
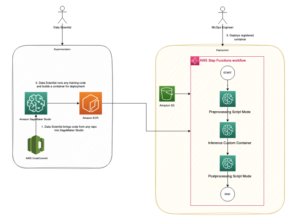
למה אנחנו צריכים דגם הטמעות?
הטמעות וקטוריות הן בסיסיות ללימודי LLM כדי להבין את הדרגות הסמנטיות של השפה, וגם מאפשרות ל-LLM לבצע ביצועים טובים במשימות NLP במורד הזרם כמו ניתוח סנטימנטים, זיהוי ישויות בשם וסיווג טקסט.
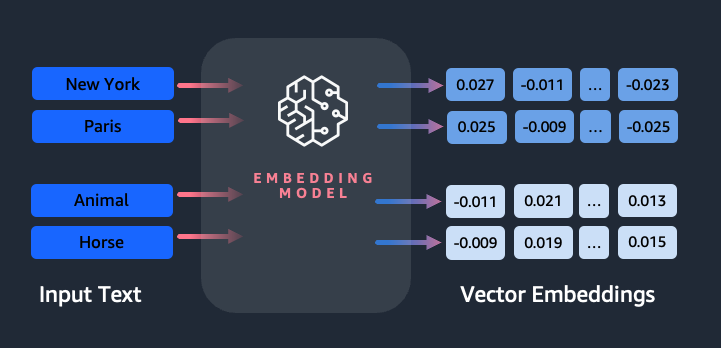
בנוסף לחיפוש סמנטי, אתה יכול להשתמש בהטמעות כדי להגדיל את ההנחיות שלך לקבלת תוצאות מדויקות יותר באמצעות Retrieval Augmented Generation (RAG) - אך כדי להשתמש בהן, תצטרך לאחסן אותן במסד נתונים עם יכולות וקטוריות.
מודל Amazon Titan Text Embeddings מותאם לאחזור טקסט כדי לאפשר מקרי שימוש ב-RAG. היא מאפשרת לך להמיר תחילה את נתוני הטקסט שלך לייצוגים מספריים או לוקטורים, ולאחר מכן להשתמש בוקטורים אלה כדי לחפש במדויק קטעים רלוונטיים ממסד נתונים וקטורי, מה שמאפשר לך להפיק את המרב מהנתונים הקנייניים שלך בשילוב עם מודלים בסיסיים אחרים.
כי Amazon Titan Text Embeddings הוא מודל מנוהל על סלע אמזון, הוא מוצע כחוויה נטולת שרתים לחלוטין. אתה יכול להשתמש בו דרך Amazon Bedrock REST API או AWS SDK. הפרמטרים הנדרשים הם הטקסט שברצונך ליצור את ההטמעות שלו וה- modelID פרמטר, המייצג את שמו של דגם Amazon Titan Text Embeddings. הקוד הבא הוא דוגמה לשימוש ב-AWS SDK עבור Python (Boto3):
הפלט ייראה בערך כך:
עיין הגדרת Amazon Bedrock boto3 לפרטים נוספים כיצד להתקין את החבילות הנדרשות, התחבר לאמזון Bedrock והפעל דגמים.
תכונות של הטבעת טקסט של Amazon Titan
עם הטבעת טקסט של Amazon Titan, אתה יכול להזין עד 8,000 אסימונים, מה שהופך אותו למתאים היטב לעבודה עם מילים בודדות, ביטויים או מסמכים שלמים על סמך מקרה השימוש שלך. Amazon Titan מחזירה וקטורי פלט בגודל 1536, ומעניקה לו רמת דיוק גבוהה, תוך אופטימיזציה לתוצאות חסכוניות עם אחזור נמוך.
Amazon Titan Text Embeddings תומכת ביצירה ושאילתה של הטבעות עבור טקסט בלמעלה מ-25 שפות שונות. זה אומר שאתה יכול להחיל את המודל על מקרי השימוש שלך מבלי ליצור ולתחזק מודלים נפרדים עבור כל שפה שבה אתה רוצה לתמוך.
מודל הטמעות יחיד מאומן בשפות רבות מספק את היתרונות העיקריים הבאים:
- טווח רחב יותר - על ידי תמיכה ביותר מ-25 שפות מהקופסה, אתה יכול להרחיב את טווח ההגעה של היישומים שלך למשתמשים ולתוכן בשווקים בינלאומיים רבים.
- ביצוע עקבי - עם מודל מאוחד המכסה מספר שפות, אתה מקבל תוצאות עקביות בשפות במקום לבצע אופטימיזציה בנפרד לכל שפה. המודל מאומן בצורה הוליסטית כך שאתה מקבל את היתרון בין השפות.
- תמיכה בשאילתות רב לשוניות - Embeddings של אמזון Titan מאפשר לבצע שאילתות של הטבעות טקסט בכל אחת מהשפות הנתמכות. זה מספק גמישות לאחזור תוכן דומה מבחינה סמנטית בשפות מבלי להיות מוגבל לשפה אחת. אתה יכול לבנות יישומים המבצעים שאילתות ומנתחים נתונים רב לשוניים באמצעות אותו מרחב הטמעות מאוחד.
נכון לכתיבת שורות אלה, השפות הבאות נתמכות:
- ערבי
- הסיני (פשוט)
- סינית (מסורתית)
- צ'כיה
- הולנדי
- אנגלית
- צרפתית
- גרמנית
- עברית
- הינדי
- איטלקי
- יפני
- קנאדה
- קוריאני
- מליאלאם
- מרתי
- פולני
- פורטוגזי
- רוסי
- ספרדי
- שבדי
- טגלוג פיליפיני
- טמילית
- טלוגו
- תורכי
שימוש ב- Amazon Titan Text Embeddings עם LangChain
LangChain היא מסגרת קוד פתוח פופולרית לעבודה עם מודלים של בינה מלאכותית וטכנולוגיות תומכות. הוא כולל א לקוח BedrockEmbeddings שעוטף בנוחות את ה-Boto3 SDK בשכבת הפשטה. ה BedrockEmbeddings הלקוח מאפשר לך לעבוד עם טקסט והטבעות ישירות, מבלי לדעת את הפרטים של בקשת ה-JSON או מבני התגובה. להלן דוגמה פשוטה:
אתה יכול גם להשתמש ב-LangChain's BedrockEmbeddings לקוח לצד לקוח Amazon Bedrock LLM כדי לפשט את הטמעת RAG, חיפוש סמנטי ודפוסים אחרים הקשורים להטמעות.
שימוש במארזים להטמעות
למרות ש-RAG הוא כיום מקרה השימוש הפופולרי ביותר לעבודה עם הטבעות, ישנם מקרי שימוש רבים אחרים בהם ניתן ליישם הטבעות. להלן כמה תרחישים נוספים שבהם אתה יכול להשתמש בהטמעות כדי לפתור בעיות ספציפיות, לבד או בשיתוף עם LLM:
- שאלה ותשובה - הטמעות יכולות לעזור לתמוך בממשקי שאלות ותשובות באמצעות דפוס RAG. יצירת הטמעות בשילוב עם מסד נתונים וקטורי מאפשרים לך למצוא התאמות קרובות בין שאלות ותוכן במאגר ידע.
- המלצות בהתאמה אישית - בדומה לשאלות ותשובות, אתה יכול להשתמש בהטבעות כדי למצוא יעדי נופש, מכללות, רכבים או מוצרים אחרים על סמך הקריטריונים שסיפק המשתמש. זה יכול ללבוש צורה של רשימה פשוטה של התאמות, או שאתה יכול להשתמש ב-LLM כדי לעבד כל המלצה ולהסביר כיצד היא עומדת בקריטריונים של המשתמש. אתה יכול גם להשתמש בגישה זו כדי ליצור "10 המאמרים הטובים ביותר" מותאמים אישית עבור משתמש בהתבסס על הצרכים הספציפיים שלו.
- ניהול נתונים – כאשר יש לך מקורות נתונים שאינם ממפים זה לזה בצורה נקייה, אבל יש לך תוכן טקסט המתאר את רשומת הנתונים, אתה יכול להשתמש בהטמעות כדי לזהות רשומות כפולות פוטנציאליות. לדוגמה, תוכל להשתמש בהטמעות כדי לזהות מועמדים כפולים שעשויים להשתמש בפורמט שונה, בקיצורים או אפילו בעלי שמות מתורגמים.
- רציונליזציה של תיק יישומים - כאשר מחפשים ליישר תיקי יישומים על פני חברת אם ורכישה, לא תמיד ברור היכן להתחיל למצוא חפיפה פוטנציאלית. האיכות של נתוני ניהול התצורה יכולה להוות גורם מגביל, וזה יכול להיות קשה לתאם בין צוותים כדי להבין את נוף היישומים. על ידי שימוש בהתאמה סמנטית עם הטבעות, אנו יכולים לבצע ניתוח מהיר בין תיקי יישומים כדי לזהות יישומים מועמדים בעלי פוטנציאל גבוה לרציונליזציה.
- קיבוץ תוכן - אתה יכול להשתמש בהטמעות כדי לעזור לקבץ תוכן דומה לקטגוריות שאולי לא ידעת מראש. לדוגמה, נניח שהיה לך אוסף של הודעות דוא"ל של לקוחות או ביקורות מוצרים מקוונים. אתה יכול ליצור הטבעות עבור כל פריט, ואז להפעיל את ההטמעות הללו k- פירושו אשכולות לזהות קבוצות הגיוניות של חששות לקוחות, שבחים או תלונות על המוצר, או נושאים אחרים. לאחר מכן תוכל ליצור סיכומים ממוקדים מהתוכן של קבוצות אלה באמצעות LLM.
דוגמה לחיפוש סמנטי
בשלנו דוגמה ב-GitHub, אנו מדגימים אפליקציית חיפוש הטמעות פשוטה עם Amazon Titan Text Embeddings, LangChain ו-Streamlit.
הדוגמה מתאימה את השאילתה של משתמש לערכים הקרובים ביותר במסד נתונים וקטור בזיכרון. לאחר מכן אנו מציגים את ההתאמות הללו ישירות בממשק המשתמש. זה יכול להיות שימושי אם אתה רוצה לפתור בעיות ביישום RAG, או להעריך ישירות מודל הטבעה.
לשם הפשטות, אנו משתמשים ב-in-memory FAISS מסד נתונים לאחסון וחיפוש וקטורי הטבעה. בתרחיש אמיתי בקנה מידה, סביר להניח שתרצה להשתמש במאגר נתונים מתמשך כמו מנוע וקטור עבור Amazon OpenSearch Serverless או pgvector הרחבה עבור PostgreSQL.
נסה כמה הנחיות מאפליקציית האינטרנט בשפות שונות, כגון הבאות:
- כיצד אוכל לפקח על השימוש שלי?
- איך אני יכול להתאים דגמים?
- באילו שפות תכנות אני יכול להשתמש?
- הערה mes données sont-elles sécurisées ?
- 私のデータはどのように保護されていますか?
- Quais fornecedores de modelos estão disponíveis por meio do Bedrock?
- ב-welchen Regionen האם Amazon Bedrock זמינה?
- 有哪些级别的支持?
שימו לב שלמרות שחומר המקור היה באנגלית, השאילתות בשפות אחרות הותאמו לערכים רלוונטיים.
סיכום
יכולות יצירת הטקסט של מודלים של בסיס מרגשות מאוד, אבל חשוב לזכור שהבנת טקסט, מציאת תוכן רלוונטי מגוף ידע ויצירת קשרים בין קטעים הם חיוניים להשגת הערך המלא של AI גנרטיבי. אנו נמשיך לראות מקרי שימוש חדשים ומעניינים להטמעות צצים במהלך השנים הבאות, ככל שהמודלים הללו ממשיכים להשתפר.
השלבים הבא
תוכל למצוא דוגמאות נוספות להטמעות כמחברות או יישומי הדגמה בסדנאות הבאות:
על הכותבים
 ג'ייסון סטהל הוא אדריכל פתרונות בכיר ב-AWS, המבוסס באזור ניו אינגלנד. הוא עובד עם לקוחות כדי להתאים את יכולות AWS לאתגרים העסקיים הגדולים ביותר שלהם. מחוץ לעבודה, הוא מבלה את זמנו בבניית דברים וצפייה בסרטי קומיקס עם משפחתו.
ג'ייסון סטהל הוא אדריכל פתרונות בכיר ב-AWS, המבוסס באזור ניו אינגלנד. הוא עובד עם לקוחות כדי להתאים את יכולות AWS לאתגרים העסקיים הגדולים ביותר שלהם. מחוץ לעבודה, הוא מבלה את זמנו בבניית דברים וצפייה בסרטי קומיקס עם משפחתו.
 ניטין אוזביוס הוא Sr. Enterprise Solutions Architect ב-AWS, מנוסה בהנדסת תוכנה, ארכיטקטורה ארגונית ו-AI/ML. הוא נלהב מאוד לחקור את האפשרויות של AI גנרטיבי. הוא משתף פעולה עם לקוחות כדי לעזור להם לבנות יישומים מעוצבים היטב בפלטפורמת AWS, ומוקדש לפתרון אתגרים טכנולוגיים וסיוע במסע הענן שלהם.
ניטין אוזביוס הוא Sr. Enterprise Solutions Architect ב-AWS, מנוסה בהנדסת תוכנה, ארכיטקטורה ארגונית ו-AI/ML. הוא נלהב מאוד לחקור את האפשרויות של AI גנרטיבי. הוא משתף פעולה עם לקוחות כדי לעזור להם לבנות יישומים מעוצבים היטב בפלטפורמת AWS, ומוקדש לפתרון אתגרים טכנולוגיים וסיוע במסע הענן שלהם.
 ראג' פאתאק הוא אדריכל פתרונות ראשי ויועץ טכני לחברות Fortune 50 גדולות ולמוסדות שירותים פיננסיים בינוניים (FSI) ברחבי קנדה וארצות הברית. הוא מתמחה ביישומי למידת מכונה כגון AI גנרטיבי, עיבוד שפה טבעית, עיבוד מסמכים חכם ו-MLOps.
ראג' פאתאק הוא אדריכל פתרונות ראשי ויועץ טכני לחברות Fortune 50 גדולות ולמוסדות שירותים פיננסיים בינוניים (FSI) ברחבי קנדה וארצות הברית. הוא מתמחה ביישומי למידת מכונה כגון AI גנרטיבי, עיבוד שפה טבעית, עיבוד מסמכים חכם ו-MLOps.
 מני חנוג'ה היא מובילה טכנולוגית – מומחי בינה מלאכותית, מחברת הספר – Applied Machine Learning and High Performance Computing on AWS, וחברה במועצת המנהלים של קרן החינוך לנשים בייצור. היא מובילה פרויקטים של למידת מכונה (ML) בתחומים שונים כמו ראייה ממוחשבת, עיבוד שפה טבעית ובינה מלאכותית גנרטיבית. היא עוזרת ללקוחות לבנות, לאמן ולפרוס מודלים גדולים של למידת מכונה בקנה מידה. היא מדברת בכנסים פנימיים וחיצוניים כגון re:Invent, Women in Manufacturing West, סמינרים מקוונים ביוטיוב ו-GHC 23. בזמנה הפנוי היא אוהבת לצאת לריצות ארוכות לאורך החוף.
מני חנוג'ה היא מובילה טכנולוגית – מומחי בינה מלאכותית, מחברת הספר – Applied Machine Learning and High Performance Computing on AWS, וחברה במועצת המנהלים של קרן החינוך לנשים בייצור. היא מובילה פרויקטים של למידת מכונה (ML) בתחומים שונים כמו ראייה ממוחשבת, עיבוד שפה טבעית ובינה מלאכותית גנרטיבית. היא עוזרת ללקוחות לבנות, לאמן ולפרוס מודלים גדולים של למידת מכונה בקנה מידה. היא מדברת בכנסים פנימיים וחיצוניים כגון re:Invent, Women in Manufacturing West, סמינרים מקוונים ביוטיוב ו-GHC 23. בזמנה הפנוי היא אוהבת לצאת לריצות ארוכות לאורך החוף.
 מארק רוי הוא ארכיטקט למידת מכונה ראשי עבור AWS, שעוזר ללקוחות לתכנן ולבנות פתרונות AI/ML. עבודתו של מארק מכסה מגוון רחב של מקרי שימוש ב-ML, עם עניין עיקרי בראייה ממוחשבת, למידה עמוקה והרחבת ML ברחבי הארגון. הוא עזר לחברות בתעשיות רבות, כולל ביטוח, שירותים פיננסיים, מדיה ובידור, שירותי בריאות, שירותים וייצור. מארק מחזיק בשש הסמכות AWS, כולל הסמכת ML Specialty. לפני שהצטרף ל-AWS, מארק היה אדריכל, מפתח ומוביל טכנולוגיה במשך למעלה מ-25 שנים, כולל 19 שנים בשירותים פיננסיים.
מארק רוי הוא ארכיטקט למידת מכונה ראשי עבור AWS, שעוזר ללקוחות לתכנן ולבנות פתרונות AI/ML. עבודתו של מארק מכסה מגוון רחב של מקרי שימוש ב-ML, עם עניין עיקרי בראייה ממוחשבת, למידה עמוקה והרחבת ML ברחבי הארגון. הוא עזר לחברות בתעשיות רבות, כולל ביטוח, שירותים פיננסיים, מדיה ובידור, שירותי בריאות, שירותים וייצור. מארק מחזיק בשש הסמכות AWS, כולל הסמכת ML Specialty. לפני שהצטרף ל-AWS, מארק היה אדריכל, מפתח ומוביל טכנולוגיה במשך למעלה מ-25 שנים, כולל 19 שנים בשירותים פיננסיים.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- אודות
- הפשטה
- לְקַבֵּל
- דיוק
- מדויק
- במדויק
- הושג
- השגתי
- רכישה
- לרוחב
- תוספת
- נוסף
- יתרון
- יועץ
- קדימה
- AI
- דגמי AI
- AI / ML
- אלגוריתמים
- ליישר
- תעשיות
- להתיר
- מאפשר
- מאפשר
- לאורך
- בַּצַד
- גם
- תמיד
- אמזון בעברית
- אמזון שירותי אינטרנט
- an
- אנליזה
- לנתח
- ו
- לענות
- כל
- בקשה
- יישומים
- יישומית
- החל
- גישה
- ארכיטקטורה
- ארכיטקטורות
- ARE
- AREA
- מאמרים
- AS
- סיוע
- At
- לְהַגדִיל
- מוגבר
- מחבר
- זמין
- AWS
- מבוסס
- BE
- חוף
- להיות
- הטבות
- בֵּין
- לוּחַ
- דירקטוריון
- גוּף
- ספר
- אריזה מקורית
- לִבנוֹת
- בִּניָן
- עסקים
- אבל
- by
- CAN
- קנדה
- מועמד
- מועמדים
- יכולות
- ללכוד
- לוכדת
- מקרה
- מקרים
- קטגוריות
- תעודה
- אישורים
- האתגרים
- מיון
- לקוחות
- סְגוֹר
- ענן
- קיבוץ
- קוד
- אוסף
- מכללות
- שילוב
- Common
- חברות
- חברה
- לְהַשְׁווֹת
- תלונות
- מורכב
- המחשב
- ראייה ממוחשבת
- מחשוב
- מושגים
- דאגות
- כנסים
- תְצוּרָה
- לְחַבֵּר
- הקשר
- חיבורי
- עִקבִי
- תוכן
- הקשר
- קשר
- להמשיך
- בנוחות
- להמיר
- הומר
- שיתוף פעולה
- תיאום
- עלות תועלת
- יכול
- כיסוי
- מכסה
- לִיצוֹר
- יוצרים
- הקריטריונים
- מכריע
- כיום
- מנהג
- לקוח
- לקוחות
- אישית
- נתונים
- מסד נתונים
- de
- מוקדש
- עמוק
- למידה עמוקה
- באופן מעמיק
- לְהַגדִיר
- תואר
- הַדגָמָה
- להפגין
- לפרוס
- מתאר
- עיצוב
- יעדים
- פרטים
- מפתח
- אחר
- קשה
- מֵמַד
- ישירות
- דירקטורים
- לדון
- לְהַצִיג
- do
- מסמך
- מסמכים
- תחומים
- לא
- כל אחד
- חינוך
- יעילות
- או
- מיילים
- הטבעה
- לצאת
- לאפשר
- מאפשר
- מנוע
- הנדסה
- אַנְגלִיָה
- אנגלית
- מִפְעָל
- פתרונות ארגוניים
- בידור
- שלם
- לַחֲלוּטִין
- ישות
- Ether (ETH)
- להעריך
- אֲפִילוּ
- דוגמה
- דוגמאות
- מרגש
- לְהַרְחִיב
- ניסיון
- מנוסה
- להסביר
- היכרות
- הארכה
- חיצוני
- לְהַקֵל
- גורם
- משפחה
- תכונות
- מעטים
- כספי
- שירותים פיננסיים
- מציאת
- ראשון
- גמישות
- מרוכז
- הבא
- בעד
- טופס
- הון עתק
- קרן
- מסגרת
- חופשי
- החל מ-
- מלא
- יסודי
- ליצור
- דור
- גנרטטיבית
- AI Generative
- לקבל
- מקבל
- נתינה
- כפפה
- Go
- הגדול ביותר
- היה
- יש
- he
- בריאות
- לעזור
- עזר
- עזרה
- עוזר
- לה
- גָבוֹהַ
- מחשוב עתיר ביצועים
- שֶׁלוֹ
- מחזיק
- איך
- איך
- HTML
- HTTPS
- i
- לזהות
- if
- יישום
- לייבא
- חשוב
- לשפר
- in
- באחר
- לכלול
- כולל
- כולל
- תעשיות
- מידע
- קלט
- להתקין
- במקום
- מוסדות
- ביטוח
- אינטליגנטי
- עיבוד מסמכים חכם
- אינטרס
- מעניין
- מִמְשָׁק
- ממשקים
- פנימי
- ברמה בינלאומית
- אל תוך
- IT
- שֶׁלָה
- הצטרפות
- מסע
- jpg
- ג'סון
- מפתח
- לדעת
- יודע
- ידע
- נוף
- שפה
- שפות
- גָדוֹל
- שכבה
- עוֹפֶרֶת
- מנהיג
- מוביל
- למידה
- לתת
- כמו
- סביר
- אוהב
- מגביל
- רשימה
- LLM
- הגיוני
- ארוך
- נראה
- הסתכלות
- מכונה
- למידת מכונה
- לתחזק
- לעשות
- עשייה
- הצליח
- ניהול
- ייצור
- רב
- מַפָּה
- סימן
- של מארק
- שוקי
- מתאים
- גפרורים
- תואם
- חוֹמֶר
- me
- משמעות
- אומר
- מדיה
- חבר
- שיטה
- יכול
- ML
- אלגוריתמים של ML
- MLOps
- מודל
- מודלים
- צג
- יותר
- רוב
- הכי פופולארי
- סרטים
- מספר
- my
- שם
- שם
- שמות
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- צורך
- צורך
- צרכי
- חדש
- הבא
- NLP
- מחשבים ניידים
- ברור
- of
- מוצע
- on
- ONE
- באינטרנט
- לפתוח
- קוד פתוח
- אופטימיזציה
- מיטוב
- or
- להזמין
- אחר
- אחרים
- שלנו
- הַחוּצָה
- תפוקה
- בחוץ
- יותר
- שֶׁלוֹ
- חבילות
- מְזוּוָג
- פרמטר
- פרמטרים
- חברת אם
- קטעים
- לוהט
- תבנית
- דפוסי
- עבור
- לבצע
- ביצועים
- התאמה אישית
- ביטויים
- לְחַבֵּר
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- לְשַׂחֵק
- אנא
- פופולרי
- על ידי
- תיק עבודות
- תיקים
- אפשרויות
- הודעה
- פוסטגרסל
- פוטנציאל
- כּוֹחַ
- יְסוֹדִי
- מנהל
- קופונים להדפסה
- קודם
- בעיות
- תהליך
- תהליך
- המוצר
- סקירות מוצרים
- מוצרים
- תכנות
- שפות תכנות
- פרויקטים
- הנחיות
- קניינית
- לספק
- ובלבד
- מספק
- פיתון
- איכות
- שאילתות
- שאלה
- שאלה
- שאלות
- מָהִיר
- סמרטוט
- רכס
- RE
- לְהַגִיעַ
- עולם אמיתי
- הכרה
- המלצה
- המלצות
- שיא
- רשום
- מתייחס
- מערכות יחסים
- רלוונטי
- לזכור
- מאגר
- נציגות
- מייצג
- לבקש
- נדרש
- תגובה
- REST
- מוגבל
- וכתוצאה מכך
- תוצאות
- שליפה
- החזרות
- חוות דעת של לקוחותינו
- תפקיד
- הפעלה
- פועל
- s
- אותו
- לומר
- סולם
- דרוג
- תרחיש
- תרחישים
- Sdk
- חיפוש
- לִרְאוֹת
- סמנטי
- סמנטיקה
- לחצני מצוקה לפנסיונרים
- משפט
- רגש
- נפרד
- ללא שרת
- שירותים
- היא
- דומה
- פָּשׁוּט
- פשטות
- פשוט
- לפשט
- יחיד
- שישה
- So
- תוכנה
- הנדסת תוכנה
- פתרונות
- לפתור
- פותר
- כמה
- משהו
- מָקוֹר
- מקורות
- מֶרחָב
- מדבר
- מומחים
- מתמחה
- התמחות
- ספציפי
- התחלה
- החל
- הברית
- חנות
- מבנים
- כזה
- תמיכה
- נתמך
- מסייע
- תומך
- לקחת
- משימות
- צוותי
- טק
- טכני
- טכניקה
- טכניקות
- טכנולוגיות
- טכנולוגיה
- לספר
- טֶקסט
- סיווג טקסט
- דור טקסט
- זֶה
- השמיים
- המקור
- שֶׁלָהֶם
- אותם
- נושאים
- אז
- שם.
- אלה
- דברים
- זֶה
- אלה
- אם כי?
- דרך
- זמן
- עֲנָק
- ל
- מטבעות
- מסורתי
- רכבת
- מְאוּמָן
- רוֹבּוֹטרִיקִים
- הפיכה
- להבין
- הבנה
- מאוחד
- מאוחד
- ארצות הברית
- נוֹהָג
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- מועיל
- משתמש
- ממשק משתמש
- משתמשים
- באמצעות
- כלי עזר
- חופשה
- ערך
- שונים
- כלי רכב
- מאוד
- באמצעות
- חזון
- רוצה
- היה
- צופה
- we
- אינטרנט
- אפליקציית רשת
- שירותי אינטרנט
- סמינרים
- טוֹב
- היו
- מערב
- מתי
- אשר
- בזמן
- רָחָב
- טווח רחב
- יצטרך
- עם
- בתוך
- לְלֹא
- נשים
- Word
- מילים
- תיק עבודות
- עובד
- עובד
- סדנות
- היה
- לכתוב
- כתיבה
- שנים
- אתה
- YouTube
- זפירנט