בפוסט היכרות עם הכלי TCO של ערכת ה-AWS ProServe Hadoop Migration Delivery, הצגנו את הכלי TCO של AWS ProServe Hadoop Migration Delivery Kit (HMDK) ואת היתרונות של העברת עומסי עבודה של Hadoop מקומיים אל אמזון EMR. בפוסט זה, אנו צוללים עמוק לתוך הכלי, עוברים על כל השלבים החל מהטמעת יומן, טרנספורמציה, הדמיה ותכנון ארכיטקטורה ועד לחישוב TCO.
סקירת פתרונות
בואו נבקר בקצרה בתכונות המפתח של הכלי HMDK TCO. הכלי מספק אוסף יומני YARN לחיבור Hadoop Resource Manager לאיסוף יומני YARN. מנתח עומסי עבודה של Hadoop מבוסס Python, הנקרא מנתח יומן YARN, בודק יישומי Hadoop. אמזון קוויקסייט לוחות מחוונים מציגים את התוצאות מהנתח. אותן תוצאות גם מאיצות את התכנון של מקרי EMR עתידיים. בנוסף, מחשבון TCO מייצר את הערכת ה-TCO של אשכול EMR אופטימלי כדי להקל על ההגירה.
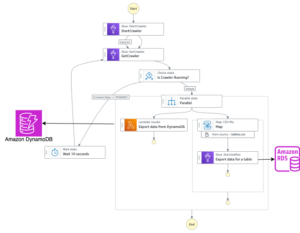
עכשיו בואו נראה איך הכלי עובד. התרשים הבא ממחיש את זרימת העבודה מקצה לקצה.

בסעיפים הבאים, נעבור על חמשת השלבים העיקריים של הכלי:
- אסוף יומני היסטוריית עבודות של YARN.
- הפוך את יומני היסטוריית העבודה מ-JSON ל-CSV.
- נתח את יומני היסטוריית העבודה.
- תכנן אשכול EMR להגירה.
- חשב את ה-TCO.
תנאים מוקדמים
לפני שתתחיל, הקפד להשלים את התנאים המוקדמים הבאים:
- שיבט את מאגר hadoop-migration-assessment-tco.
- התקן את Python 3 במחשב המקומי שלך.
- יש לך חשבון AWS עם הרשאה AWS למבדה, QuickSight (מהדורת Enterprise), ו AWS CloudFormation.
אסוף יומני היסטוריית עבודות של YARN
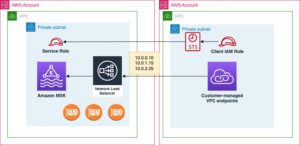
ראשית, אתה מפעיל את א אספן יומני YARN, start-collector.sh, במחשב המקומי שלך. שלב זה אוסף יומני Hadoop YARN ומניח את היומנים במחשב המקומי שלך. הסקריפט מחבר את המחשב המקומי שלך עם הצומת הראשי של Hadoop ומתקשר עם מנהל המשאבים. לאחר מכן הוא מאחזר את מידע היסטוריית העבודה (יומני YARN ממנהלי יישומים) על ידי קריאה ל-YARN ResourceManager היישום API.
לפני הפעלת אוסף היומנים של YARN, עליך להגדיר וליצור את החיבור (HTTP: 8088 או HTTPS: 8090; האחרון מומלץ) כדי לאמת את הנגישות של YARN ResourceManager ו-YARN Timeline Server מאופשר (נתמכים ב-Timeline Server v1 ואילך. ). ייתכן שיהיה עליך להגדיר את מרווחי האיסוף ומדיניות השמירה של יומני YARN. כדי להבטיח שאתה אוסף יומני YARN עוקבים, אתה יכול להשתמש ב-cron job כדי לתזמן את אוסף היומנים במרווח זמן מתאים. לדוגמה, עבור אשכול Hadoop עם 2,000 יישומים יומיים וההגדרה yarn.resourcemanager.max-completed-applications מוגדרת ל-1,000, תיאורטית, עליך להפעיל את אוסף היומנים לפחות פעמיים כדי לקבל את כל יומני ה-YARN. בנוסף, אנו ממליצים לאסוף לפחות 7 ימים של יומני YARN לניתוח עומסי עבודה הוליסטיים.
לפרטים נוספים כיצד להגדיר ולתזמן את אוסף היומנים, עיין ב- ריפו של GitHub של אוסף יומני חוטים.
הפוך את יומני היסטוריית העבודה של YARN מ-JSON ל-CSV
לאחר השגת יומני YARN, אתה מפעיל מארגן יומני YARN, yarn-log-organizer.py, שהוא מנתח להפיכת יומנים מבוססי JSON לקובצי CSV. קובצי CSV פלט אלה הם הקלט עבור מנתח היומן YARN. למנתח יש גם יכולות אחרות, כולל מיון אירועים לפי זמן, הסרת הקדשות ומיזוג יומנים מרובים.
למידע נוסף על אופן השימוש במארגן יומן YARN, עיין ב- arn-log-organizer GitHub repo.
נתח את יומני היסטוריית העבודה של YARN
לאחר מכן, אתה מפעיל את מנתח היומנים של YARN כדי לנתח את יומני ה-YARN בפורמט CSV.
עם QuickSight, אתה יכול לדמיין נתוני יומן YARN ולבצע ניתוח מול מערכי הנתונים שנוצרו על ידי תבניות לוח מחוונים מובנות מראש ו-widget. הווידג'ט יוצר אוטומטית לוחות מחוונים של QuickSight בחשבון היעד של AWS, המוגדרים בתבנית CloudFormation.
התרשים הבא ממחיש את ארכיטקטורת HMDK TCO.

מנתח היומן של YARN מספק ארבע פונקציות מרכזיות:
- העלה יומני היסטוריית עבודות שעברו שינוי ב-YARN בפורמט CSV (לדוגמה,
cluster_yarn_logs_*.csv) כדי שירות אחסון פשוט של אמזון (אמזון S3) דליים. קובצי CSV אלה הם הפלטים ממארגן יומן YARN. - צור קובץ JSON מניפסט (לדוגמה,
yarn-log-manifest.json) עבור QuickSight והעלה אותו לדלי S3: - פרוס לוחות מחוונים של QuickSight באמצעות תבנית CloudFormation, שהיא בפורמט YAML. לאחר הפריסה, בחר בסמל הרענון עד שתראה את סטטוס הערימה כ
CREATE_COMPLETE. שלב זה יוצר מערכי נתונים על לוחות מחוונים של QuickSight בחשבון היעד שלך ב-AWS.
- בלוח המחוונים של QuickSight, אתה יכול למצוא תובנות של עומסי העבודה של Hadoop המנותחים מתרשימים שונים. תובנות אלו עוזרות לך לעצב מופעי EMR עתידיים להאצת הגירה, כפי שהוכח בשלב הבא.

תכנן אשכול EMR להגירה
התוצאות של מנתח היומן של YARN עוזרות לך להבין את עומסי העבודה בפועל של Hadoop על המערכת הקיימת. שלב זה מאיץ את עיצוב מופעי EMR עתידיים להגירה על ידי שימוש ב- תבנית אקסל. התבנית מכילה רשימת בדיקה לביצוע ניתוח עומס עבודה ותכנון קיבולת:
- האם היישומים הפועלים על האשכול נמצאים בשימוש הולם עם הקיבולת הנוכחית שלהם?
- האם האשכול תחת עומס בזמן מסוים או לא? אם כן, מתי הזמן?
- אילו סוגי יישומים ומנועים (כגון MR, TEZ או Spark) פועלים על האשכול, ומהו השימוש במשאבים עבור כל סוג?
- האם מחזורי ריצה של עבודות שונות (בזמן אמת, אצווה, אד-הוק) פועלים באשכול אחד?
- האם עבודות כלשהן פועלות באצוות רגילות, ואם כן, מהן מרווחי לוח הזמנים הללו? (לדוגמה, כל 10 דקות, שעה אחת, יום אחד.) האם יש לך עבודות שמשתמשות במשאבים רבים במהלך תקופה ארוכה?
- האם משרות כלשהן זקוקות לשיפור ביצועים?
- האם ארגונים או יחידים מסוימים מחזיקים במונופול על האשכול?
- האם עבודות פיתוח ותפעול מעורבות פועלות באשכול אחד?
לאחר שתשלים את רשימת הבדיקה, תהיה לך הבנה טובה יותר כיצד לעצב את הארכיטקטורה העתידית. לאופטימיזציה של עלות אפקטיביות של אשכול EMR, הטבלה הבאה מספקת הנחיות כלליות לבחירת הסוג המתאים של אשכול EMR ענן מחשוב אלסטי של אמזון משפחת (Amazon EC2).

כדי לבחור את סוג האשכול ואת משפחת המופעים המתאימים, עליך לבצע מספר סבבי ניתוח מול יומני YARN בהתבסס על קריטריונים שונים. בואו נסתכל על כמה מדדי מפתח.
ציר זמן
אתה יכול למצוא דפוסי עומס עבודה המבוססים על מספר יישומי Hadoop המופעלים בחלון זמן. לדוגמה, התרשימים היומיים או השעתיים "ספירת השיאים לפי שעת התחלה" מספקים את התובנות הבאות:
- בתרשימים של סדרות זמן יומיות, אתה משווה את מספר ריצות היישום בין ימי עבודה וחגים, ובין ימים קלנדריים. אם המספרים דומים, פירוש הדבר שהשימושים היומיומיים של האשכול ניתנים להשוואה. מצד שני, אם הסטייה גדולה, שיעור המשרות האד-הוק משמעותי. אתה גם יכול להבין את המשרות השבועיות או החודשיות האפשריות בימים מסוימים. במצב, אתה יכול בקלות לראות ימים ספציפיים בשבוע או בחודש עם ריכוז עומס עבודה גבוה.
- בתרשימים של סדרות זמן לפי שעה, אתה מבין עוד יותר כיצד יישומים מופעלים בחלונות לפי שעה. אתה יכול למצוא שעות שיא ושפל ביום.
משתמש
יומני YARN מכילים את מזהה המשתמש של כל אפליקציה. מידע זה עוזר לך להבין מי מגיש בקשה לתור. בהתבסס על הנתונים הסטטיסטיים של ריצות יישומים בודדים ומצטברים לכל תור ולכל משתמש, אתה יכול לקבוע את חלוקת עומס העבודה הקיימת לפי משתמש. בדרך כלל, למשתמשים באותו צוות יש תורים משותפים. לפעמים, למספר צוותים יש תורים משותפים. בעת עיצוב תורים למשתמשים, כעת יש לך תובנות שיעזרו לך לעצב ולהפיץ עומסי עבודה של יישומים מאוזנים יותר בין התורים מאשר בעבר.
סוגי יישומים
ניתן לפלח עומסי עבודה על סמך סוגי יישומים שונים (כגון Hive, Spark, Presto או HBase) ולהפעיל מנועים (כגון MR, Spark או Tez). עבור עומסי העבודה כבדי המחשוב כגון משרות MapReduce או Hive-on-MR, השתמש במופעים מותאמים ל-CPU. עבור עומסי עבודה עתירי זיכרון כגון עבודות Hive-on-TEZ, Presto ו-Spark, השתמש במופעים מותאמים לזיכרון.
זמן שחלף
אתה יכול לסווג יישומים לפי זמן ריצה. תבנית CloudFormation המוטבעת יוצרת אוטומטית שדה קבוצתי שעבר בלוח מחוונים של QuickSight. זה מאפשר תכונה מרכזית המאפשרת לך לצפות בעבודות ארוכות טווח באחד מארבעה תרשימים במרכזי המחוונים של QuickSight. לכן, תוכלו לעצב ארכיטקטורות עתידיות מותאמות עבור העבודות הגדולות הללו.
לוחות המחוונים המקבילים של QuickSight כוללים ארבעה תרשימים. אתה יכול להתעמק בכל תרשים, המשויך לקבוצה אחת.
| קְבוּצָה מספר |
זמן ריצה/זמן שחלף של עבודה |
| 1 | פחות מ -10 דקות |
| 2 | בין 10 דקות ל-30 דקות |
| 3 | בין 30 דקות לשעה |
| 4 | יותר משעה |
בתרשים של קבוצה 4, אתה יכול להתרכז בבדיקה מדוקדקת של משרות גדולות על סמך מדדים שונים, כולל משתמש, תור, סוג אפליקציה, ציר זמן, שימוש במשאבים וכו'. בהתבסס על שיקול זה, ייתכן שיש לך תורים ייעודיים באשכול או אשכול EMR ייעודי עבור עבודות גדולות. בינתיים, אתה יכול להגיש עבודות קטנות לתורים משותפים.
משאבים
בהתבסס על דפוסי צריכת משאבים (CPU, זיכרון), אתה בוחר את הגודל והמשפחה הנכונים של מופעי EC2 לביצועים ולעלות אפקטיבית. עבור יישומים עתירי מחשוב, אנו ממליצים על מופעים של משפחות מותאמות ל-CPU. עבור יישומים עתירי זיכרון, מומלצות משפחות המופעים המותאמות לזיכרון.
בנוסף, בהתבסס על אופי עומסי העבודה של האפליקציה וניצול המשאבים לאורך זמן, תוכל לבחור באשכול EMR מתמשך או חולף, אמזון EMR ב-EKS, או Amazon EMR ללא שרת.
לאחר ניתוח יומני YARN לפי מדדים שונים, אתה מוכן לתכנן ארכיטקטורות EMR עתידיות. הטבלה הבאה מפרטת דוגמאות של אשכולות EMR מוצעים. תוכל למצוא פרטים נוספים ב- Repo GitHub optimized-tco-calculator.

חשב TCO
לבסוף, במחשב המקומי שלך, הפעל את tco-input-generator.py כדי לצבור יומני היסטוריית עבודות של YARN על בסיס שעתי לפני השימוש בתבנית Excel כדי לחשב את ה-TCO המאופטימלי. שלב זה הוא קריטי מכיוון שהתוצאות מדמות את עומסי העבודה של Hadoop במקרי EMR עתידיים.
התנאי המקדים של סימולציית TCO הוא הפעלה tco-input-generator.py, אשר יוצר יומנים מצטברים לפי שעה. לאחר מכן, אתה פותח קובץ תבנית Excel כדי לאפשר פקודות מאקרו ולספק את הקלט שלך בתאים ירוקים לחישוב ה-TCO. לגבי נתוני הקלט, אתה מזין את גודל הנתונים בפועל ללא שכפול, ואת מפרטי החומרה (vCore, mem) של הצומת הראשי של Hadoop וצמתי הנתונים. עליך גם לבחור ולהעלות יומנים מצטברים שעתיים שנוצרו בעבר. לאחר הגדרת משתני סימולציית ה-TCO, כגון אזור, סוג EC2, זמינות גבוהה של Amazon EMR, אפקט מנוע, הנחה של Amazon EC2 ו- Amazon EBS (EDP), הנחת נפח של Amazon S3, שער מטבע מקומי ויחס תמחור משימה/ליבת EMR EC2 ומחיר/שעה, סימולטור ה-TCO מחשב אוטומטית את העלות האופטימלית של מקרי EMR עתידיים באמזון EC2. צילומי המסך הבאים מציגים דוגמה לתוצאות HMDK TCO.

למידע נוסף והנחיות של חישובי HMDK TCO, עיין ב Repo GitHub optimized-tco-calculator.
לנקות את
לאחר שתסיים את כל השלבים ותסיים את הבדיקה, בצע את השלבים הבאים כדי למחוק משאבים כדי למנוע הוצאות:
- במסוף AWS CloudFormation, בחר את הערימה שיצרת.
- בחרו מחק.
- בחרו מחק ערימה.
- רענן את הדף עד שתראה את הסטטוס
DELETE_COMPLETE. - בקונסולת Amazon S3, מחק את דלי S3 שיצרת.
סיכום
הכלי AWS ProServe HMDK TCO מפחית באופן משמעותי את מאמצי תכנון ההגירה, שהם המשימות הגוזלות זמן ומאתגרות של הערכת עומסי העבודה של Hadoop. עם הכלי HMDK TCO, ההערכה נמשכת בדרך כלל 2-3 שבועות. אתה יכול גם לקבוע את ה-TCO המחושב של ארכיטקטורות EMR עתידיות. עם הכלי HMDK TCO, אתה יכול להבין במהירות את עומסי העבודה ודפוסי השימוש שלך במשאבים. עם התובנות שנוצרו על ידי הכלי, אתה מצויד לתכנן ארכיטקטורות EMR עתידיות אופטימליות. במקרים רבים של שימוש, TCO של שנה אחת של ארכיטקטורת ה-refactored האופטימלית מספק חיסכון משמעותי בעלויות (הפחתה של 1-64%) על מחשוב ואחסון, בהשוואה להעברת Hadoop בהרמה והסטה.
למידע נוסף על האצת העברות Hadoop שלך לאמזון EMR ולכלי HMDK CTO, עיין ב- Hadoop Migration Delivery Kit TCO Repo GitHub, או לפנות אל AWS-HMDK@amazon.com.
על המחברים
 פארק סונגיאול הוא מנהל תרגול בכיר ב-AWS ProServe. הוא עוזר ללקוחות לחדש את העסק שלהם עם שירותי AWS Analytics, IoT ו-AI/ML. יש לו התמחות בשירותי וטכנולוגיות ביג דאטה ועניין בבניית תוצאות עסקיות של לקוחות ביחד.
פארק סונגיאול הוא מנהל תרגול בכיר ב-AWS ProServe. הוא עוזר ללקוחות לחדש את העסק שלהם עם שירותי AWS Analytics, IoT ו-AI/ML. יש לו התמחות בשירותי וטכנולוגיות ביג דאטה ועניין בבניית תוצאות עסקיות של לקוחות ביחד.
 ג'יזונג קים הוא ארכיטקט נתונים בכיר ב-AWS ProServe. הוא עובד בעיקר עם לקוחות ארגוניים כדי לסייע בהגירה ומודרניזציה של אגם נתונים, ומספק הדרכה וסיוע טכני בפרויקטי ביג דאטה כגון Hadoop, Spark, מחסני נתונים, עיבוד נתונים בזמן אמת ולמידת מכונה בקנה מידה גדול. הוא גם מבין כיצד ליישם טכנולוגיות כדי לפתור בעיות ביג דאטה ולבנות ארכיטקטורת נתונים מתוכננת היטב.
ג'יזונג קים הוא ארכיטקט נתונים בכיר ב-AWS ProServe. הוא עובד בעיקר עם לקוחות ארגוניים כדי לסייע בהגירה ומודרניזציה של אגם נתונים, ומספק הדרכה וסיוע טכני בפרויקטי ביג דאטה כגון Hadoop, Spark, מחסני נתונים, עיבוד נתונים בזמן אמת ולמידת מכונה בקנה מידה גדול. הוא גם מבין כיצד ליישם טכנולוגיות כדי לפתור בעיות ביג דאטה ולבנות ארכיטקטורת נתונים מתוכננת היטב.
 ג'ורג 'ג'או הוא ארכיטקט נתונים בכיר ב-AWS ProServe. הוא מנהיג ניתוח מנוסה שעובד עם לקוחות AWS כדי לספק פתרונות נתונים מודרניים. הוא גם מומחה לתחום ProServe Amazon EMR המאפשר ליועצי ProServe בנושא שיטות עבודה מומלצות וערכות משלוח עבור העברות Hadoop לאמזון EMR. תחום העניין שלו הוא אגמי נתונים ואספקת ארכיטקטורת נתונים מודרנית בענן.
ג'ורג 'ג'או הוא ארכיטקט נתונים בכיר ב-AWS ProServe. הוא מנהיג ניתוח מנוסה שעובד עם לקוחות AWS כדי לספק פתרונות נתונים מודרניים. הוא גם מומחה לתחום ProServe Amazon EMR המאפשר ליועצי ProServe בנושא שיטות עבודה מומלצות וערכות משלוח עבור העברות Hadoop לאמזון EMR. תחום העניין שלו הוא אגמי נתונים ואספקת ארכיטקטורת נתונים מודרנית בענן.
 קאלן ג'אנג היה ה-Global Segment Tech Lead של נתוני שותפים ואנליטיקס ב-AWS. כיועצת אמינה לנתונים וניתוחים, היא אצרה יוזמות אסטרטגיות לטרנספורמציה של נתונים, הובילה תוכניות העברת עומסי עבודה ומודרניזציה של נתונים וניתוח, והאצה מסעות העברת לקוחות עם שותפים בקנה מידה. היא מתמחה במערכות מבוזרות, ניהול נתונים ארגוניים, אנליטיקה מתקדמת ויוזמות אסטרטגיות בקנה מידה גדול.
קאלן ג'אנג היה ה-Global Segment Tech Lead של נתוני שותפים ואנליטיקס ב-AWS. כיועצת אמינה לנתונים וניתוחים, היא אצרה יוזמות אסטרטגיות לטרנספורמציה של נתונים, הובילה תוכניות העברת עומסי עבודה ומודרניזציה של נתונים וניתוח, והאצה מסעות העברת לקוחות עם שותפים בקנה מידה. היא מתמחה במערכות מבוזרות, ניהול נתונים ארגוניים, אנליטיקה מתקדמת ויוזמות אסטרטגיות בקנה מידה גדול.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- יכול
- אודות
- להאיץ
- מוּאָץ
- מאיץ
- מאיצה
- האצה
- נגישות
- חֶשְׁבּוֹן
- לרוחב
- Ad
- תוספת
- נוסף
- מידע נוסף
- בנוסף
- מתקדם
- יועץ
- לאחר
- נגד
- AI / ML
- תעשיות
- אמזון בעברית
- אמזון
- אמזון EMR
- בין
- אנליזה
- ניתוח
- לנתח
- ניתוח
- ו
- API
- בקשה
- יישומים
- החל
- כראוי
- ארכיטקטורה
- AREA
- הערכה
- סיוע
- המשויך
- באופן אוטומטי
- זמינות
- AWS
- AWS CloudFormation
- מבוסס
- בסיס
- כי
- להיות
- הטבות
- הטוב ביותר
- שיטות עבודה מומלצות
- מוטב
- בֵּין
- גָדוֹל
- נתונים גדולים
- בקצרה
- לִבנוֹת
- בִּניָן
- עסקים
- לחשב
- מחושב
- מחשב
- חישוב
- יומן אירועים
- נקרא
- קוראים
- יכולות
- קיבולת
- מקרים
- תאים
- מסוים
- אתגר
- תרשים
- תרשימים
- בחרו
- בחירה
- ענן
- אשכול
- לגבות
- איסוף
- אוסף
- אספן
- אוסף
- COM
- השוואה
- לְהַשְׁווֹת
- לעומת
- להשלים
- לחשב
- להתרכז
- ריכוז
- לנהל
- מוליך
- לְחַבֵּר
- הקשר
- מתחבר
- רצופים
- התחשבות
- קונסול
- יועצים
- צְרִיכָה
- מכיל
- תוֹאֵם
- עלות
- חיסכון עלויות
- עלויות
- CPU
- נוצר
- יוצר
- הקריטריונים
- מכריע
- ראש אגף טכנולוגיה
- אוצר
- מַטְבֵּעַ
- נוֹכְחִי
- לקוח
- לקוחות
- מחזורי
- יומי
- לוח מחוונים
- נתונים
- אגם דאטה
- ניהול נתונים
- עיבוד נתונים
- מערכי נתונים
- יְוֹם
- ימים
- מוקדש
- עמוק
- צלילה לעומק
- למסור
- מסירה
- מופגן
- פריסה
- עיצוב
- תכנון
- פרטים
- לקבוע
- צעצועי התפתחות
- סטייה
- אחר
- הנחה
- לְהָפִיץ
- מופץ
- מערכות מבוזרות
- הפצה
- תחום
- מטה
- בְּמַהֲלָך
- כל אחד
- בקלות
- ebs
- מהדורה
- השפעה
- יְעִילוּת
- מַאֲמָצִים
- מוטבע
- לאפשר
- מופעל
- מאפשר
- מקצה לקצה
- מנוע
- מנועים
- לְהַבטִיחַ
- זן
- מִפְעָל
- לקוחות ארגוניים
- מְצוּיָד
- להקים
- Ether (ETH)
- אירועים
- כל
- דוגמה
- דוגמאות
- Excel
- קיימים
- מנוסה
- הקלה
- משפחות
- משפחה
- מאפיין
- תכונות
- שדה
- תרשים
- שלח
- קבצים
- גימור
- הבא
- פוּרמָט
- החל מ-
- פונקציות
- נוסף
- עתיד
- כללי
- נוצר
- מייצר
- לקבל
- מקבל
- GitHub
- גלוֹבָּלִי
- ירוק
- קְבוּצָה
- הנחיות
- Hadoop
- חומרה
- לעזור
- עוזר
- גָבוֹהַ
- היסטוריה
- כוורת
- חגים
- הוליסטית
- שעות
- איך
- איך
- HTML
- HTTPS
- ICON
- השבחה
- in
- לכלול
- כולל
- בנפרד
- אנשים
- מידע
- יוזמות
- לחדש
- קלט
- תובנות
- למשל
- הוראות
- אינטרס
- אינטרסים
- הציג
- IOT
- IT
- עבודה
- מקומות תעסוקה
- מסעות
- ג'סון
- מפתח
- ערכה
- אגם
- גָדוֹל
- בקנה מידה גדול
- לשגר
- עוֹפֶרֶת
- מנהיג
- לִלמוֹד
- למידה
- הוביל
- Led Data
- רשימות
- לִטעוֹן
- מקומי
- ארוך
- הרבה זמן
- נראה
- מגרש
- מכונה
- למידת מכונה
- פקודות מאקרו
- ראשי
- לעשות
- ניהול
- מנהל
- מנהלים
- רב
- אומר
- בינתיים
- זכרון
- מיזוג
- מדדים
- הֲגִירָה
- דקות
- מעורב
- מודרני
- מוֹדֶרנִיזָצִיָה
- חוֹדֶשׁ
- אחת לחודש
- יותר
- מספר
- טבע
- צורך
- הבא
- צומת
- צמתים
- מספר
- מספרים
- להתבונן
- להשיג
- ONE
- לפתוח
- פועל
- מבצע
- אופטימלי
- אופטימיזציה
- מיטוב
- אופטימלית
- ארגונים
- אחר
- מסוים
- שותף
- שותפים
- דפוסי
- שִׂיא
- לבצע
- ביצועים
- תקופה
- רשות
- מקומות
- תכנון
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- מדיניות
- אפשרי
- הודעה
- תרגול
- פרקטיקות
- תנאים מוקדמים
- קוֹדֶם
- תמחור
- יְסוֹדִי
- קודם
- בעיות
- תהליך
- תוכניות
- פרויקטים
- תָקִין
- מוּצָע
- לספק
- מספק
- פיתון
- מהירות
- ציון
- יחס
- לְהַגִיעַ
- מוכן
- זמן אמת
- נתונים בזמן אמת
- להמליץ
- מוּמלָץ
- רשום
- מפחית
- בדבר
- באזור
- רגיל
- הסרת
- שכפול
- משאב
- משאבים
- תוצאות
- שייר
- סיבובים
- הפעלה
- ריצה
- אותו
- חיסכון
- סולם
- לוח זמנים
- צילומי מסך
- סעיפים
- קטע
- לחצני מצוקה לפנסיונרים
- סדרה
- שירותים
- סט
- הצבה
- כמה
- משותף
- לְהַצִיג
- ראווה
- משמעותי
- באופן משמעותי
- דומה
- פָּשׁוּט
- הדמיה
- מדמה
- מצב
- מידה
- קטן
- So
- פתרונות
- לפתור
- כמה
- לעורר
- מומחה
- מתמחה
- התמחות
- ספציפי
- מפרטים
- לערום
- החל
- סטטיסטיקה
- מצב
- שלב
- צעדים
- אחסון
- אסטרטגי
- להגיש
- כזה
- נתמך
- מערכת
- מערכות
- שולחן
- מותאם
- לוקח
- יעד
- משימות
- נבחרת
- צוותי
- טק
- טכני
- טכנולוגיות
- תבנית
- תבניות
- בדיקות
- השמיים
- העתיד
- שֶׁלָהֶם
- לכן
- דרך
- זמן
- סדרת זמן
- דורש זמן רב
- ציר זמן
- ל
- יַחַד
- כלי
- לשנות
- טרנספורמציה
- טרנספורמציה
- נָכוֹן
- מהימן
- סוגים
- תחת
- להבין
- הבנה
- מבין
- נוֹהָג
- להשתמש
- משתמש
- משתמשים
- בְּדֶרֶך כְּלַל
- שונים
- לאמת
- ראיה
- כֶּרֶך
- הליכה
- אחסון
- שבוע
- שבועי
- שבועות
- מה
- מה
- אשר
- מי
- חלונות
- לְלֹא
- זרימת עבודה
- עובד
- עובד
- יאמל
- זפירנט