לארגונים בכל התעשיות יש דרישות מורכבות לעיבוד נתונים עבור מקרי השימוש האנליטיים שלהם במערכות ניתוח שונות, כגון אגמי נתונים ב-AWS, מחסני נתונים (האדום של אמזון), לחפש (שירות חיפוש פתוח של אמזון), NoSQL (אמזון דינמו), למידת מכונה (אמזון SageMaker), ועוד. על אנשי מקצוע ב-Analytics מוטלת המשימה להפיק ערך מנתונים המאוחסנים במערכות מבוזרות אלו כדי ליצור חוויות טובות יותר, מאובטחות ומותאמות לעלות עבור הלקוחות שלהם. לדוגמה, חברות מדיה דיגיטלית מבקשות לשלב ולעבד מערכי נתונים במסדי נתונים פנימיים וחיצוניים כדי לבנות תצוגות מאוחדות של פרופילי הלקוחות שלהן, לדרבן רעיונות לתכונות חדשניות ולהגביר את המעורבות בפלטפורמה.
בתרחישים אלה, משתמשים המחפשים שילוב נתונים ללא שרת המציע שימוש דבק AWS כמרכיב ליבה לעיבוד וקטלוג נתונים. AWS Glue משולב היטב עם שירותי AWS ומוצרי שותפים, ומספק אפשרויות לחילוץ, טרנספורמציה וטעינה (ETL) נמוכים/ללא קוד כדי לאפשר ניתוח, למידת מכונה (ML) או תהליכי עבודה של פיתוח יישומים. עבודות AWS Glue ETL עשויות להיות מרכיב אחד בצנרת מורכבת יותר. תזמור ריצה וניהול התלות בין רכיבים אלה היא יכולת מפתח באסטרטגיית נתונים. אמזון ניהלה זרימות עבודה עבור זרימות אוויר של Apache (Amazon MWAA) מתזמר צינורות נתונים באמצעות טכנולוגיות מבוזרות כולל משאבים מקומיים, שירותי AWS ורכיבי צד שלישי.
בפוסט זה, אנו מראים כיצד לפשט את הניטור של עבודת דבק AWS המתוזמרת על ידי Airflow באמצעות התכונות העדכניות ביותר של Amazon MWAA.
סקירה כללית של הפיתרון
פוסט זה דן בדברים הבאים:
- כיצד לשדרג סביבת MWAA של אמזון לגרסה 2.4.3.
- כיצד לתזמן עבודת דבק AWS מזרימת אוויר בימוי גרף Acyclic (DAG).
- שיפורי הנראות של חבילת ה-Airflow Amazon באמזון MWAA. כעת תוכל לאחד יומני ריצה של עבודות דבק של AWS במסוף Airflow כדי לפשט את פתרון הבעיות בצינורות הנתונים. קונסולת ה-MWAA של אמזון הופכת לאסמכתא יחידה לניטור וניתוח של ריצות עבודות דבק של AWS. בעבר, צוותי תמיכה היו צריכים לגשת ל- קונסולת הניהול של AWS ולנקוט בצעדים ידניים לנראות זו. תכונה זו זמינה כברירת מחדל מגרסה 2.4.3 של Amazon MWAA.
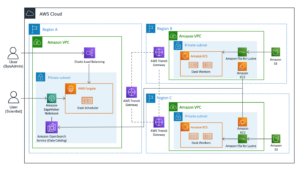
התרשים הבא ממחיש את ארכיטקטורת הפתרונות שלנו.
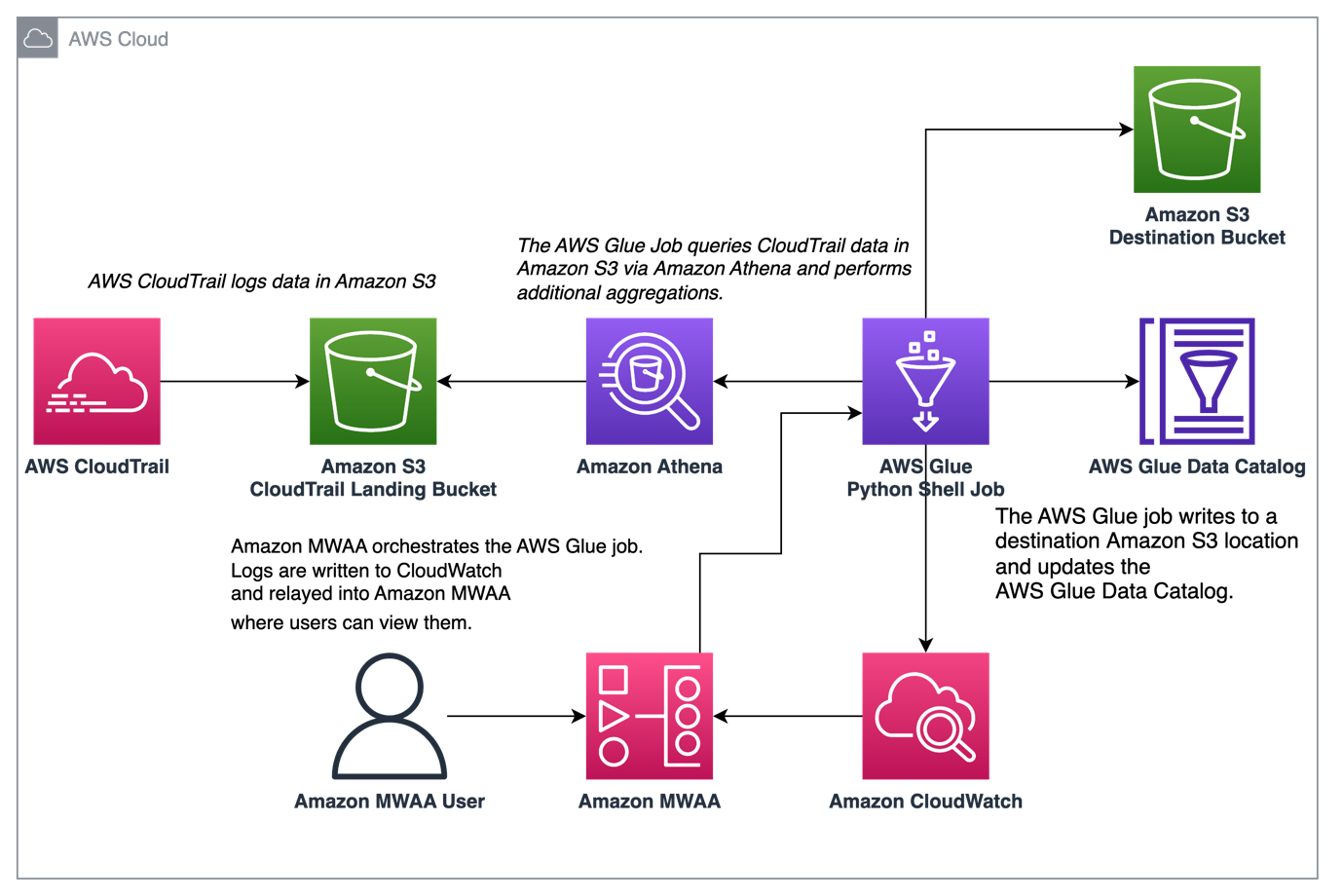
תנאים מוקדמים
אתה צריך את התנאים המוקדמים הבאים:
הגדר את סביבת Amazon MWAA
להנחיות ליצירת הסביבה שלך, עיין ב צור סביבת MWAA של אמזון. עבור משתמשים קיימים, אנו ממליצים לשדרג לגרסה 2.4.3 כדי לנצל את שיפורי הנראות המופיעים בפוסט זה.
השלבים לשדרוג Amazon MWAA לגרסה 2.4.3 שונים בהתאם אם הגרסה הנוכחית היא 1.10.12 או 2.2.2. אנו דנים בשתי האפשרויות בפוסט זה.
תנאים מוקדמים להגדרת סביבת MWAA של אמזון
עליך לעמוד בדרישות הקדם הבאות:
שדרוג מגרסה 1.10.12 ל-2.4.3
אם אתה משתמש בגרסת אמזון MWAA 1.10.12, מתייחס מעבר לסביבת MWAA חדשה של אמזון לשדרג ל-2.4.3.
שדרג מגרסה 2.0.2 או 2.2.2 ל-2.4.3
אם אתה משתמש בסביבת Amazon MWAA גרסה 2.2.2 ומטה, השלם את השלבים הבאים:
- צור requirements.txt עבור תלות מותאמות אישית עם גרסאות ספציפיות הנדרשות ל-DAG שלך.
- העלה את הקובץ לאמזון S3 במיקום המתאים שבו סביבת ה-MWAA של אמזון מצביעה על ה- requirements.txt להתקנת תלות.
- עקוב אחר השלבים ב מעבר לסביבת MWAA חדשה של אמזון ובחר בגרסה 2.4.3.
עדכן את ה-DAG שלך
ייתכן שלקוחות ששדרגו מסביבת MWAA ישנה יותר של אמזון יצטרכו לבצע עדכונים ל-DAGs קיימים. בגירסת Airflow 2.4.3, סביבת Airflow תשתמש בחבילת ספק אמזון בגרסה 6.0.0 כברירת מחדל. חבילה זו עשויה לכלול כמה שינויים שעלולים להישבר, כגון שינויים בשמות המפעילים. לדוגמה, ה AWSGlueJobOperator הוצא משימוש והוחלף ב- GlueJobOperator. כדי לשמור על תאימות, עדכן את ה-Airflow DAGs שלך על ידי החלפת מפעילים שהוצאו משימוש או שאינם נתמכים מגירסאות קודמות בחדשות. השלם את השלבים הבאים:
- נווט אל מפעילי אמזון AWS.
- בחר את הגרסה המתאימה המותקנת במופע ה-MWAA של Amazon שלך (6.0.0. כברירת מחדל) כדי למצוא רשימה של מפעילי זרימת אוויר נתמכים.
- בצע את השינויים הדרושים בקוד ה-DAG הקיים והעלה את הקבצים ששונו למיקום DAG באמזון S3.
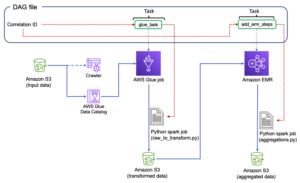
תזמר את עבודת הדבק של AWS מ-Airflow
סעיף זה מכסה את הפרטים של תזמור עבודת דבק AWS בתוך Airflow DAGs. זרימת אוויר מקלה על פיתוח צינורות נתונים עם תלות בין מערכות הטרוגניות כגון תהליכים מקומיים, תלות חיצונית, שירותי AWS אחרים ועוד.
תזמר צבירת יומני CloudTrail עם AWS Glue ו-Amazon MWAA
בדוגמה זו, אנו עוברים על מקרה שימוש של שימוש ב-MWAA של אמזון כדי לתזמן עבודת AWS Glue Python Shell שנמשכת מדדים מצטברים המבוססים על יומני CloudTrail.
CloudTrail מאפשר נראות לתוך קריאות AWS API שמתבצעות בחשבון AWS שלך. מקרה שימוש נפוץ בנתונים אלה הוא איסוף מדדי שימוש על מנהלים הפועלים על המשאבים של חשבונך לצורכי ביקורת ורגולציה.
כאשר אירועי CloudTrail נרשמים, הם מועברים כקובצי JSON באמזון S3, שאינם אידיאליים לשאילתות אנליטיות. אנו רוצים לצבור נתונים אלה ולהמשיך אותם כקבצי Parquet כדי לאפשר ביצועי שאילתות מיטביים. כשלב ראשוני, אנו יכולים להשתמש ב- Athena כדי לבצע את השאילתה הראשונית של הנתונים לפני ביצוע צבירה נוספת בעבודת ה- AWS Glue שלנו. למידע נוסף על יצירת טבלת קטלוג נתוני דבק של AWS, עיין ב יצירת הטבלה עבור יומני CloudTrail באתנה באמצעות הקרנת מחיצות נתונים. לאחר שחקרנו את הנתונים דרך Athena והחלטנו אילו מדדים אנו רוצים לשמור בטבלאות מצטברות, נוכל ליצור עבודת AWS Glue.
צור טבלת CloudTrail באתנה
ראשית, עלינו ליצור טבלה בקטלוג הנתונים שלנו המאפשרת שאילתה לנתוני CloudTrail דרך Athena. השאילתה לדוגמה הבאה יוצרת טבלה עם שתי מחיצות באזור והתאריך (נקרא snapshot_date). הקפד להחליף את מצייני המיקום עבור דלי CloudTrail, מזהה חשבון AWS ושם טבלת CloudTrail שלך:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')הפעל את השאילתה הקודמת בקונסולת Athena, וציין את שם הטבלה ואת מסד הנתונים של AWS Glue Data Catalog שבו היא נוצרה. אנו משתמשים בערכים אלה מאוחר יותר בקוד Airflow DAG.
קוד עבודה של AWS Glue לדוגמה
הקוד הבא הוא דוגמה עבודת AWS Glue Python Shell שעושה את הדברים הבאים:
- לוקח טיעונים (שאותם אנו מעבירים מה-Amazon MWAA DAG שלנו) לגבי הנתונים של איזה יום לעבד
- משתמש ב- AWS SDK עבור פנדות להריץ שאילתת Athena כדי לבצע את הסינון הראשוני של נתוני CloudTrail JSON מחוץ ל-AWS Glue
- משתמש ב-Pandas כדי לבצע צבירה פשוטה על הנתונים המסוננים
- מוציא את הנתונים המצטברים לקטלוג הנתונים של דבק AWS בטבלה
- משתמש ברישום במהלך העיבוד, אשר יהיה גלוי באמזון MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
להלן כמה יתרונות מרכזיים בעבודת דבק AWS זו:
- אנו משתמשים בשאילתת Athena כדי להבטיח שהסינון הראשוני נעשה מחוץ לעבודת הדבק שלנו ב-AWS. ככזה, עבודת Python Shell עם מחשוב מינימלי עדיין מספיקה לצבירה של מערך נתונים גדול של CloudTrail.
- אנו מבטיחים את אפשרות הגדרת ספריית אנליטיקס מופעל בעת יצירת עבודת הדבק של AWS כדי להשתמש בספריית AWS SDK עבור Pandas.
צור עבודת דבק של AWS
השלם את השלבים הבאים כדי ליצור את עבודת הדבק שלך ב-AWS:
- העתק את הסקריפט בסעיף הקודם ושמור אותו בקובץ מקומי. עבור פוסט זה נקרא הקובץ
script.py. - במסוף הדבק של AWS בחר משרות ETL בחלונית הניווט.
- צור עבודה חדשה ובחר עורך סקריפט של Python Shell.
- בחר העלה וערוך סקריפט קיים והעלה את הקובץ ששמרת באופן מקומי.
- בחרו צור.

- על פרטי עבודה בכרטיסייה, הזן שם עבור עבודת הדבק שלך ב-AWS.
- בעד תפקיד IAM, בחר תפקיד קיים או צור תפקיד חדש שיש לו את ההרשאות הנדרשות עבור Amazon S3, AWS Glue, ואתנה. התפקיד צריך לבצע שאילתה בטבלת CloudTrail שיצרת קודם לכן ולכתוב למיקום פלט.
אתה יכול להשתמש בקוד המדיניות לדוגמה הבא. החלף את מצייני המיקום בדלי היומנים של CloudTrail, שם טבלת הפלט, מסד הנתונים של פלט AWS Glue, דלי פלט S3, שם טבלת CloudTrail, מסד הנתונים של AWS Glue המכיל את טבלת CloudTrail ומזהה חשבון AWS שלך.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
בעד גרסת פייתון, בחר פייתון 3.9.
- בחר טען ספריות ניתוח נפוצות.
- בעד יחידות עיבוד נתונים, בחר 1 DPU.
- השאר את האפשרויות האחרות כברירת מחדל או התאם לפי הצורך.

- בחרו שמור כדי לשמור את תצורת העבודה שלך.
הגדר MWAA DAG של אמזון לתזמור את עבודת הדבק של AWS
הקוד הבא מיועד ל-DAG שיכול לתזמן את עבודת הדבק של AWS שיצרנו. אנו מנצלים את התכונות העיקריות הבאות ב-DAG זה:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
הגדל את יכולת הצפייה של עבודות דבק AWS ב-Amazon MWAA
משימות הדבק של AWS כותבות יומנים אמזון CloudWatch. עם שיפורי הצפייה האחרונים בחבילת הספקים של Airflow של אמזון, יומנים אלה משולבים כעת ביומני משימות Airflow. איחוד זה מספק למשתמשי Airflow נראות מקצה לקצה ישירות בממשק המשתמש של Airflow, ומבטל את הצורך לחפש ב-CloudWatch או בקונסולת AWS Glue.
כדי להשתמש בתכונה זו, ודא שלתפקיד IAM המצורף לסביבת Amazon MWAA יש את ההרשאות הבאות לאחזור ולכתוב את היומנים הדרושים:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}אם verbose=true, יומני ריצת העבודה של AWS Glue מוצגים ביומני המשימות של Airflow. ברירת המחדל היא שקר. למידע נוסף, עיין ב פרמטרים.
כאשר מופעלת, ה-DAGs קוראים מזרם היומן של CloudWatch של עבודת AWS Glue ומעבירים אותם ליומני השלבים של ה-Airflow DAG AWS Glue. זה מספק תובנות מפורטות על הפעלת עבודת דבק של AWS בזמן אמת באמצעות יומני DAG. שים לב שמשרות דבק של AWS מייצרות פלט ושגיאות של קבוצת יומן CloudWatch המבוססת על STDOUT ו-STDERR של העבודה, בהתאמה. כל היומנים בקבוצת יומן הפלט ויומני החריגים או השגיאות מקבוצת יומן השגיאות מועברים ל-Amazon MWAA.
מנהלי AWS יכולים כעת להגביל את הגישה של צוות תמיכה ל-Airflow בלבד, מה שהופך את Amazon MWAA לחלונית הזכוכית היחידה בתזמור עבודה וניהול בריאות העבודה. בעבר, המשתמשים היו צריכים לבדוק את מצב ריצת העבודה של AWS Glue בשלבי Airflow DAG ולאחזר את מזהה ריצת העבודה. לאחר מכן הם היו צריכים לגשת למסוף AWS Glue כדי למצוא את היסטוריית ריצת העבודה, לחפש את המשרה המעניינת באמצעות המזהה, ולבסוף לנווט ליומני CloudWatch של העבודה כדי לפתור בעיות.
צור את ה-DAG
כדי ליצור את ה-DAG, בצע את השלבים הבאים:
- שמור את קוד ה-DAG הקודם בקובץ py מקומי, תוך החלפת מצייני המיקום המצוינים.
הערכים עבור מזהה חשבון AWS שלך, שם העבודה AWS Glue, מסד הנתונים של AWS Glue עם טבלת CloudTrail ושם טבלת CloudTrail כבר אמורים להיות ידועים. אתה יכול להתאים את דלי הפלט S3, את מסד הנתונים של פלט AWS Glue ואת שם טבלת הפלט לפי הצורך, אך וודא שתפקיד IAM של עבודת AWS Glue שהשתמשת בו קודם מוגדר בהתאם.
- במסוף MWAA של אמזון, נווט אל הסביבה שלך כדי לראות היכן מאוחסן קוד ה-DAG.
תיקיית DAGs היא הקידומת בתוך דלי S3 שבו יש למקם את קובץ ה-DAG שלך.
- העלה לשם את הקובץ הערוך שלך.

- פתח את מסוף ה-MWAA של אמזון כדי לאשר שה-DAG מופיע בטבלה.

הפעל את ה- DAG
כדי להפעיל את ה-DAG, בצע את השלבים הבאים:
- בחר מהאפשרויות הבאות:
- טריגר DAG - זה גורם לנתונים של אתמול לשמש כנתונים לעיבוד
- טריגר DAG עם תצורה - עם אפשרות זו, אתה יכול לעבור בתאריך אחר, פוטנציאלי למילוי חוזר, אשר מאוחזר באמצעות
dag_run.confבקוד DAG ולאחר מכן הועבר ל-AWS Glue Job כפרמטר

צילום המסך הבא מציג את אפשרויות התצורה הנוספות אם תבחר טריגר DAG עם תצורה.

- עקוב אחר ה-DAG בזמן שהוא פועל.
- כאשר ה-DAG הושלם, פתח את פרטי הריצה.
בחלונית הימנית, אתה יכול להציג את היומנים, או לבחור פרטי מופע משימה לצפייה מלאה.

- הצג את יומני הפלט של AWS Glue ב-Amazon MWAA מבלי להשתמש בקונסולת AWS Glue הודות ל-
GlueJobOperatorדגל מילולי.

לעבודת AWS Glue יהיו תוצאות כתובות לטבלת הפלט שציינת.
- בצע שאילתות בטבלה זו דרך Athena כדי לאשר שהיא הצליחה.
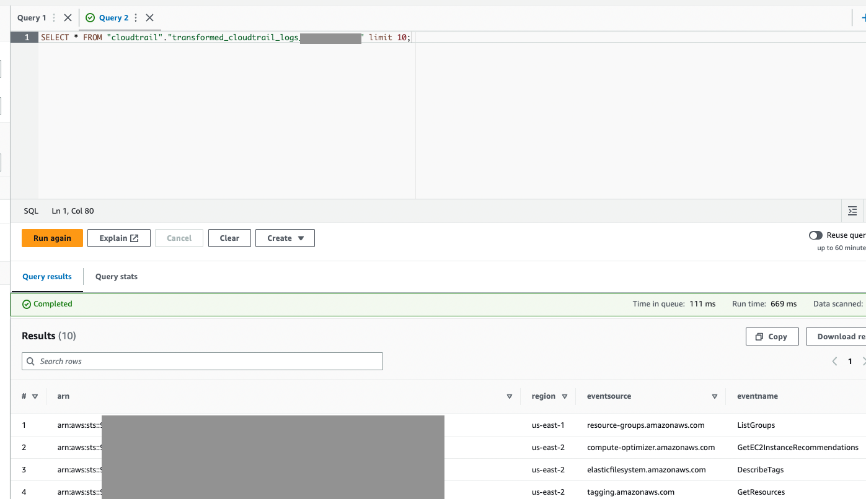
<br> סיכום
אמזון MWAA מספקת כעת מקום יחיד לעקוב אחר מצב עבודת ה-AWS Glue ומאפשרת לך להשתמש בקונסולת Airflow כחלונית הזכוכית היחידה לתזמור עבודה וניהול בריאות. בפוסט זה, עברנו על השלבים לתזמור עבודות AWS Glue באמצעות Airflow באמצעות GlueJobOperator. עם שיפורי הנראות החדשים, אתה יכול לפתור בעיות בצורה חלקה בעבודות דבק AWS בחוויה מאוחדת. הדגמנו גם כיצד לשדרג את סביבת ה-MWAA של Amazon לגרסה תואמת, לעדכן תלות ולשנות את מדיניות התפקידים של IAM בהתאם.
למידע נוסף על שלבים נפוצים לפתרון בעיות, עיין ב פתרון בעיות: יצירה ועדכון של סביבת MWAA של אמזון. לפרטים מעמיקים על מעבר לסביבת MWAA של אמזון, עיין ב שדרוג מ-1.10 ל-2. כדי ללמוד על השינויים בקוד הפתוח להגברת הצפייה בעבודות דבק AWS בחבילת ספקי Airflow Amazon, עיין ב- יומני ממסר מעבודות דבק של AWS.
לבסוף, אנו ממליצים לבקר ב בלוג Big Data של AWS לחומר אחר על ניתוח, ML וממשל נתונים ב-AWS.
על הכותבים
 רושאב לוכאנדה הוא מהנדס נתונים ו-ML עם AWS Professional Services Analytics Practice. הוא עוזר ללקוחות ליישם פתרונות ביג דאטה, למידת מכונה וניתוח. מחוץ לעבודה, הוא נהנה לבלות עם המשפחה, קריאה, ריצה וגולף.
רושאב לוכאנדה הוא מהנדס נתונים ו-ML עם AWS Professional Services Analytics Practice. הוא עוזר ללקוחות ליישם פתרונות ביג דאטה, למידת מכונה וניתוח. מחוץ לעבודה, הוא נהנה לבלות עם המשפחה, קריאה, ריצה וגולף.
 ריאן גומס הוא מהנדס נתונים ו-ML עם AWS Professional Services Analytics Practice. הוא נלהב לעזור ללקוחות להשיג תוצאות טובות יותר באמצעות פתרונות ניתוח ולמידת מכונה בענן. מחוץ לעבודה, הוא נהנה מכושר, בישול, ובילוי זמן איכות עם חברים ובני משפחה.
ריאן גומס הוא מהנדס נתונים ו-ML עם AWS Professional Services Analytics Practice. הוא נלהב לעזור ללקוחות להשיג תוצאות טובות יותר באמצעות פתרונות ניתוח ולמידת מכונה בענן. מחוץ לעבודה, הוא נהנה מכושר, בישול, ובילוי זמן איכות עם חברים ובני משפחה.
 וישווה גופטה הוא ארכיטקט נתונים בכיר עם AWS Professional Services Analytics Practice. הוא עוזר ללקוחות ליישם פתרונות ביג דאטה וניתוח. מחוץ לעבודה, הוא נהנה לבלות עם המשפחה, לטייל ולנסות אוכל חדש.
וישווה גופטה הוא ארכיטקט נתונים בכיר עם AWS Professional Services Analytics Practice. הוא עוזר ללקוחות ליישם פתרונות ביג דאטה וניתוח. מחוץ לעבודה, הוא נהנה לבלות עם המשפחה, לטייל ולנסות אוכל חדש.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoAiStream. Web3 Data Intelligence. הידע מוגבר. גישה כאן.
- הטבעת העתיד עם אדריאן אשלי. גישה כאן.
- קנה ומכירה של מניות בחברות PRE-IPO עם PREIPO®. גישה כאן.
- מקור: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 1
- 10
- 100
- 12
- 8
- a
- אודות
- גישה
- לפיכך
- חֶשְׁבּוֹן
- להשיג
- לרוחב
- פעולה
- מחזורי
- נוסף
- יתרון
- יתרונות
- לאחר
- - צבירה
- תעשיות
- להתיר
- מאפשר
- כְּבָר
- גם
- אמזון בעברית
- אמזון שירותי אינטרנט
- an
- אנליטית
- ניתוח
- לנתח
- ו
- כל
- אַפָּשׁ
- API
- בקשה
- פיתוח אפליקציות
- מתאים
- ארכיטקטורה
- ARE
- טענה
- טיעונים
- AS
- At
- תכונות
- ביקורת
- זמין
- AWS
- דבק AWS
- שירותים מקצועיים של AWS
- מבוסס
- BE
- הופך להיות
- היה
- לפני
- להיות
- מוטב
- בֵּין
- גָדוֹל
- נתונים גדולים
- שניהם
- שבירה
- לִבנוֹת
- אבל
- by
- נקרא
- שיחות
- CAN
- מקרה
- מקרים
- קטלוג
- גורמים
- שינוי
- שינויים
- לבדוק
- בחרו
- ענן
- קוד
- COM
- לשלב
- הערה
- Common
- חברות
- תאימות
- תואם
- להשלים
- מורכב
- רְכִיב
- רכיבים
- לחשב
- תְצוּרָה
- לאשר
- קונסול
- לְגַבֵּשׁ
- קונסולידציה
- בישול
- ליבה
- מכסה
- לִיצוֹר
- נוצר
- יוצר
- יוצרים
- נוֹכְחִי
- מנהג
- לקוח
- לקוחות
- DAG
- נתונים
- שילוב נתונים
- עיבוד נתונים
- אסטרטגיית נתונים
- מחסני נתונים
- מסד נתונים
- מאגרי מידע
- מערכי נתונים
- תַאֲרִיך
- תאריכים
- datetime
- ימים
- החליט
- בְּרִירַת מֶחדָל
- נתן
- מופגן
- תלוי
- הוצא משימוש
- מְפוֹרָט
- פרטים
- צעצועי התפתחות
- נבדלים
- אחר
- דיגיטלי
- מדיה דיגיטלית
- ישירות
- לדון
- מופץ
- מערכות מבוזרות
- do
- עושה
- עושה
- עשה
- בְּמַהֲלָך
- e
- מוקדם יותר
- קלות
- השפעה
- חיסול
- אחר
- לאפשר
- מופעל
- מאפשר
- מקצה לקצה
- התעסקות
- מהנדס
- שיפורים
- לְהַבטִיחַ
- זן
- סביבה
- שגיאה
- Ether (ETH)
- אירועים
- דוגמה
- אלא
- יוצא מן הכלל
- להתקיים
- קיימים
- קיים
- ניסיון
- חוויות
- חקר
- ביטוי
- חיצוני
- תמצית
- נכשל
- שקר
- משפחה
- מאפיין
- מומלצים
- תכונות
- שלח
- קבצים
- סינון
- בסופו של דבר
- כושר גופני
- הבא
- מזון
- בעד
- פוּרמָט
- חברים
- החל מ-
- מלא
- ללקט
- ליצור
- זכוכית
- Go
- גולף
- ממשל
- קְבוּצָה
- Hadoop
- יש
- he
- בְּרִיאוּת
- עזרה
- עוזר
- היסטוריה
- כוורת
- איך
- איך
- HTML
- http
- HTTPS
- IAM
- ID
- אידאל
- רעיונות
- מזהה
- if
- מדגים
- ליישם
- לייבא
- in
- מעמיק
- לכלול
- כולל
- להגדיל
- גדל
- הצביע
- תעשיות
- מידע
- מידע
- בתחילה
- חדשני
- תובנות
- התקנה
- למשל
- הוראות
- משולב
- השתלבות
- אינטרס
- פנימי
- אל תוך
- IT
- עבודה
- מקומות תעסוקה
- jpg
- ג'סון
- מפתח
- ידוע
- גָדוֹל
- מאוחר יותר
- האחרון
- לִלמוֹד
- למידה
- סִפְרִיָה
- להגביל
- רשימה
- לִטעוֹן
- מקומי
- באופן מקומי
- מיקום
- היכנס
- מחובר
- רישום
- הסתכלות
- מכונה
- למידת מכונה
- עשוי
- לתחזק
- לעשות
- עשייה
- הצליח
- ניהול
- ניהול
- מדריך ל
- חוֹמֶר
- מאי..
- מדיה
- לִפְגוֹשׁ
- הודעה
- מדדים
- נודד
- מינימלי
- ML
- שונים
- מודול
- צג
- ניטור
- יותר
- צריך
- שם
- שמות
- נווט
- ניווט
- הכרחי
- צורך
- נחוץ
- צרכי
- חדש
- שום דבר
- עַכשָׁיו
- of
- הצעה
- on
- ONE
- יחידות
- רק
- לפתוח
- קוד פתוח
- קוד קוד פתוח
- מפעיל
- מפעילי
- אופטימלי
- אפשרות
- אפשרויות
- or
- מתוזמר
- תזמור
- אחר
- שלנו
- תוצאות
- תפוקה
- בחוץ
- חבילה
- דובי פנדה
- זגוגית
- פרמטרים
- שותף
- לעבור
- עבר
- לוהט
- ביצועים
- הרשאות
- נמשכת
- צינור
- מקום
- פלטפורמה
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודות
- מדיניות
- הודעה
- פוטנציאל
- תרגול
- תנאים מוקדמים
- קודם
- קוֹדֶם
- תהליך
- תהליכים
- תהליך
- מוצרים
- מקצועי
- אנשי מקצוע
- פרופילים
- הקרנה
- ספק
- ספקים
- מספק
- פיתון
- איכות
- שאילתות
- להעלות
- רכס
- חומר עיוני
- קריאה
- ממשי
- זמן אמת
- לאחרונה
- להמליץ
- באזור
- רגולטורים
- ממסר
- להחליף
- החליף
- נדרש
- דרישות
- משאב
- משאבים
- בהתאמה
- תגובה
- תוצאות
- לִשְׁמוֹר
- תקין
- תפקיד
- שׁוּרָה
- הפעלה
- ריצה
- s
- שמור
- תרחישים
- Sdk
- בצורה חלקה
- חיפוש
- סעיף
- לבטח
- לִרְאוֹת
- לחפש
- לחצני מצוקה לפנסיונרים
- ללא שרת
- שירותים
- הצבה
- התקנה
- פָּגָז
- צריך
- לְהַצִיג
- הופעות
- פָּשׁוּט
- לפשט
- since
- יחיד
- תמונת בזק
- פִּתָרוֹן
- פתרונות
- כמה
- ספציפי
- מפורט
- הוצאה
- הצהרה
- מצב
- שלב
- צעדים
- עוד
- אחסון
- מאוחסן
- אִסטרָטֶגִיָה
- זרם
- מחרוזת
- מוצלח
- כזה
- מספיק
- תמיכה
- נתמך
- מערכות
- שולחן
- לקחת
- נטילת
- המשימות
- צוותי
- טכנולוגיות
- תבנית
- תודה
- זֶה
- השמיים
- שֶׁלָהֶם
- אותם
- אז
- שם.
- אלה
- הֵם
- צד שלישי
- זֶה
- דרך
- זמן
- ל
- לעקוב
- לשנות
- נסיעה
- נָכוֹן
- לנסות
- יום שלישי
- הסתובב
- שתיים
- סוג
- ui
- מאוחד
- יחידה
- עדכון
- עדכונים
- עדכון
- שדרוג
- משודרג
- העלאה
- נוֹהָג
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמשים
- באמצעות
- ערך
- ערכים
- גרסה
- באמצעות
- לצפיה
- נופים
- ראות
- נראה
- הלך
- רוצה
- היה
- we
- אינטרנט
- שירותי אינטרנט
- טוֹב
- מה
- מתי
- אם
- אשר
- מי
- יצטרך
- עם
- בתוך
- לְלֹא
- תיק עבודות
- זרימות עבודה
- היה
- לכתוב
- כתוב
- אתה
- זפירנט