מהן הטבעות וקטוריות?
הטבעות וקטוריות הן ייצוגים מספריים הלוכדים את הקשרים והמשמעות של מילים, ביטויים וסוגי נתונים אחרים. באמצעות הטבעות וקטוריות, מאפיינים או מאפיינים חיוניים של אובייקט מתורגמים למערך תמציתי ומאורגן של מספרים, המסייעים למחשבים לאחזר מידע במהירות. נקודות נתונים דומות מתקבצות קרוב יותר זו לזו לאחר שתורגמו לנקודות במרחב רב ממדי.
משמש במגוון רחב של יישומים, במיוחד בעיבוד שפה טבעית (NLP) ולמידת מכונה (ML), הטמעות וקטור עוזרות לתפעל ולעבד נתונים עבור משימות כגון השוואות דמיון, אשכולות וסיווג. לדוגמה, כאשר מסתכלים על נתוני טקסט, מילים כגון חתול ו חתלתול להעביר משמעויות דומות למרות הבדלים בהרכב האותיות שלהם. חיפוש סמנטי אפקטיבי מסתמך על ייצוגים מדויקים הלוכדים בצורה מספקת את הדמיון הסמנטי הזה בין מונחים.
[תוכן מוטבע]
האם הטבעות ווקטורים זה אותו הדבר?
התנאים וקטורים ו הטבעות ניתן להשתמש בהחלפה בהקשר של הטבעות וקטוריות. שניהם מתייחסים לייצוגי נתונים מספריים שבהם כל אחד נקודת נתונים מיוצג כווקטור במרחב בעל מימד גבוה.
וקטור מתייחס למערך של מספרים עם מימד מוגדר, בעוד שהטבעות וקטוריות משתמשות בוקטורים אלה כדי לייצג נקודות נתונים במרחב רציף.
מאמר זה הוא חלק מ-
הטבעות מתייחסות לביטוי נתונים כווקטורים ללכידת מידע משמעותי, קישורים סמנטיים, איכויות הקשריות או ייצוג מאורגן של נתונים שנלמדו באמצעות אלגוריתמי אימון או מודלים ללימוד מכונה.
סוגי הטבעות וקטוריות
הטבעות וקטוריות מגיעות במגוון צורות, שלכל אחת מהן פונקציה ייחודית לייצוג סוגים שונים של נתונים. להלן כמה סוגים נפוצים של הטבעות וקטוריות:
- הטמעות מילים. הטבעות מילים הן ייצוגים וקטוריים של מילים בודדות במרחב רציף. הם משמשים לעתים קרובות כדי ללכוד קישורים סמנטיים בין מילים במשימות כגון ניתוח הסנטימנט, תרגום שפה ודמיון מילים.
- הטבעות משפטים. ייצוגים וקטוריים של משפטים שלמים נקראים הטבעת משפטים. הם מועילים למשימות כולל ניתוח סנטימנטים, סיווג טקסט ואחזור מידע מכיוון שהם לוכדים את המשמעות וההקשר של המשפט.
- הטמעת מסמכים. הטבעות מסמכים הן ייצוגים וקטוריים של מסמכים שלמים, כגון מאמרים או דוחות. בדרך כלל בשימוש במשימות כגון דמיון מסמכים, מערכות אשכולות והמלצות, הן לוכדות את המשמעות והתוכן הכללי של המסמך.
- וקטורים של פרופיל משתמש. אלו הם ייצוגים וקטוריים של העדפות, פעולות או תכונות של משתמש. הם משמשים ב - פילוח לקוחות, מערכות המלצות מותאמות אישית ופרסום ממוקד לאיסוף נתונים ספציפיים למשתמש.
- וקטורי תמונה. אלו הם ייצוגים וקטוריים של פריטים חזותיים, כגון תמונות או מסגרות וידאו. הם משמשים במשימות כגון זיהוי אובייקט, חיפוש תמונות ומערכות המלצות מבוססות תוכן ללכידת תכונות ויזואליות.
- וקטורים של מוצר. המייצגים מוצרים או פריטים כווקטורים, הם משמשים בחיפושי מוצרים, סיווג מוצרים ומערכות המלצות לאיסוף תכונות ודמיון בין מוצרים.
- וקטורים של פרופיל משתמש. וקטורים של פרופיל משתמש מייצגים העדפות, פעולות או תכונות של משתמש. הם משמשים בפילוח משתמשים, מערכות המלצות מותאמות אישית ו פרסום ממוקד לאסוף נתונים ספציפיים למשתמש.
כיצד נוצרות הטבעות וקטוריות?
הטבעות וקטוריות נוצרות באמצעות גישת ML המאמנת מודל להפוך נתונים לוקטורים מספריים. בדרך כלל, עמוק רשת עצבית convolutional משמש להכשרת דגמים מסוג זה. ההטבעות המתקבלות הן לרוב צפופות - כל הערכים אינם אפס - ובעלי ממדים גבוהים - עד 2,000 ממדים. דגמים פופולריים כגון Word2Vec, GLoVE ו ברט המרת מילים, ביטויים או פסקאות להטבעות וקטוריות עבור נתוני טקסט.
השלבים הבאים מעורבים בדרך כלל בתהליך:
- הרכיב מערך נתונים גדול. מערכת נתונים הלוכדת את קטגוריית הנתונים הספציפית שעבורה מיועדות ההטמעות - בין אם היא נוגעת לטקסט או לתמונות - מורכבת.
- עבד מראש את הנתונים. בהתאם לסוג הנתונים, הניקוי, ההכנה ו עיבוד מקדים של נתונים כולל ביטול רעשים, שינוי גודל תמונות, נרמול טקסט וביצוע פעולות נוספות.
- הרכבת הדגם. כדי לזהות קישורים ודפוסים בנתונים, המודל מאומן באמצעות מערך הנתונים. כדי לצמצם את הפער בין היעד לוקטורים החזויים, הפרמטרים של המודל המאומן מראש משתנים במהלך שלב האימון.
- צור הטבעות וקטוריות. לאחר ההכשרה, המודל יכול להמיר נתונים טריים לוקטורים מספריים, תוך הצגת ייצוג משמעותי ומובנה שמכיל ביעילות את המידע הסמנטי של הנתונים המקוריים.
הטבעות וקטוריות יכולות להתבצע עבור מגוון רחב של סוגי נתונים, כולל נתוני סדרות זמן, טקסט, תמונות, אודיו, מודלים תלת מימדיים (3D). ווידאו. בגלל האופן שבו ההטמעות נוצרות, לאובייקטים עם סמנטיקה דומה יהיו וקטורים במרחב הווקטור הקרובים זה לזה.
היכן מאוחסנות הטבעות וקטוריות?
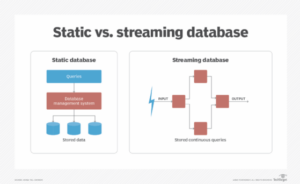
הטבעות וקטור מאוחסנות בתוך מסדי נתונים מיוחדים הידועים בשם מסדי נתונים וקטוריים. מסדי נתונים אלה הם ייצוגים מתמטיים בעלי מימד גבוה של תכונות נתונים. שלא כמו מסדי נתונים סטנדרטיים מבוססי סקלרים או אינדקסים וקטוריים עצמאיים, מסדי נתונים וקטוריים מספקים יעילות ספציפית לאחסון ושליפה של הטבעות וקטוריות בקנה מידה. הם מציעים את היכולת לאחסן ולאחזר כמויות אדירות של נתונים עבור פונקציות חיפוש וקטוריות.
מסדי נתונים וקטוריים כוללים מספר מרכיבי מפתח, כולל ביצועים ו סובלנות לתקלות. כדי להבטיח שמסדי נתונים וקטוריים עמידים בפני תקלות, רפליקציה ו sharding נעשה שימוש בטכניקות. שכפול הוא תהליך של הפקת עותקים של נתונים על פני צמתים רבים, ואילו ריסוק הוא תהליך של חלוקת נתונים על פני מספר צמתים. זה מספק סובלנות לתקלות וביצועים ללא הפרעה גם אם צומת נכשל.
מסדי נתונים וקטוריים יעילים בלמידת מכונה ובינה מלאכותית (AI) יישומים, שכן הם מתמחים בניהול נתונים לא מובנים ומובנים למחצה.
יישומים של הטבעות וקטוריות
ישנם מספר שימושים להטמעה וקטורית בתעשיות שונות. יישומים נפוצים של הטבעות וקטוריות כוללים את הדברים הבאים:
- מערכות המלצות. הטמעות וקטוריות ממלאות תפקיד מכריע במערכות ההמלצות של ענקיות התעשייה, כולל נטפליקס ואמזון. הטמעות אלו מאפשרות לארגונים לחשב את קווי הדמיון בין משתמשים ופריטים, לתרגם העדפות משתמש ותכונות פריט לוקטורים. תהליך זה מסייע במסירת הצעות מותאמות אישית המותאמות לטעם המשתמש האישי.
- מנועי חיפוש. מנועי חיפוש השתמש בהטבעות וקטוריות באופן נרחב כדי לשפר את האפקטיביות והיעילות של אחזור מידע. מכיוון שהטבעות וקטוריות חורגות מהתאמת מילות מפתח, הן עוזרות למנועי החיפוש לפרש את המשמעות של מילים ומשפטים. גם כאשר הביטויים המדויקים אינם תואמים, מנועי החיפוש עדיין יכולים למצוא ולאחזר מסמכים או מידע אחר שרלוונטי להקשר על ידי מודלים של מילים כווקטורים במרחב סמנטי.
- צ'טבוטים ומערכות תשובות לשאלות. סיוע להטמעות וקטוריות צ'אט בוטים ומערכות תשובות לשאלות המבוססות בינה מלאכותית בהבנה והפקה של תגובות דמויות אדם. על ידי לכידת ההקשר והמשמעות של טקסט, הטמעות עוזרות לצ'אטבוטים להגיב לפניות משתמשים בצורה משמעותית והגיונית. לדוגמה, מודלים של שפות וצ'אטבוטים של AI, כולל GPT-4 ומעבדי תמונה כגון Dall-E2, זכו לפופולריות עצומה על הפקת שיחות ותגובות דמויות אדם.
- גילוי הונאה וזיהוי חריגים. ניתן להשתמש בהטבעות וקטוריות כדי לזהות חריגות או פעילויות הונאה על ידי הערכת הדמיון בין וקטורים. דפוסים לא שכיחים מזוהים על ידי הערכת המרחק בין הטבעות לאיקוד חריגים.
- עיבוד מקדים של נתונים. להפוך נתונים לא מעובדים לפורמט המתאים ל-ML ומודלים של למידה עמוקה, הטמעות משמשות בפעילויות עיבוד מקדים של נתונים. הטבעות מילים, למשל, משמשות לייצוג מילים כווקטורים, מה שמקל על עיבוד וניתוח נתוני טקסט.
- למידה חד-שוט ואפס-שוט. למידה ב-One-shot ואפס-shot הן גישות הטמעה וקטוריות המסייעות למודלים של למידת מכונה לחזות תוצאות עבור כיתות חדשות, גם כשהן מסופקות עם נתונים מוגבלים בתווית. מודלים יכולים להכליל וליצור תחזיות אפילו עם מספר קטן של מופעי אימון על ידי שימוש במידע הסמנטי הכלול בהטבעות.
- דמיון וסמנטי מקבץ. הטבעות וקטוריות מקלים על מידת דומה של שני אובייקטים בסביבה בעלת מימדים גבוהים. זה מאפשר לבצע פעולות כמו מחשוב דמיון סמנטי, clustering והרכבה של דברים קשורים בהתבסס על ההטמעות שלהם.
איזה סוג של דברים ניתן להטמיע?
ניתן לייצג סוגים רבים ושונים של אובייקטים וסוגי נתונים באמצעות הטבעות וקטוריות. סוגים נפוצים של דברים שניתן להטביע כוללים את הדברים הבאים:
טקסט
מילים, ביטויים או מסמכים מיוצגים כווקטורים באמצעות הטבעת טקסט. משימות NLP - כולל ניתוח סנטימנטים, חיפוש סמנטי ותרגום שפה - משתמשות לעתים קרובות בהטבעות.
מקודד המשפטים האוניברסלי הוא אחד מדגמי הטבעת הקוד הפתוח הפופולריים ביותר והוא יכול לקודד ביעילות משפטים בודדים וגושי טקסט שלמים.
תמונות
הטבעות תמונה לוכדות ומייצגות מאפיינים חזותיים של תמונות כווקטורים. מקרי השימוש בהם כוללים זיהוי אובייקטים, סיווג תמונות וחיפוש תמונות הפוך, הידוע לרוב בשם חפש לפי תמונה.
ניתן להשתמש בהטמעות תמונות גם כדי לאפשר יכולות חיפוש חזותי. על ידי חילוץ הטבעות מתמונות מסד נתונים, משתמש יכול להשוות את ההטמעות של תמונת שאילתה עם ההטבעות של תמונות מסד הנתונים כדי לאתר התאמות דומות מבחינה ויזואלית. זה משמש בדרך כלל ב מסחר אלקטרוני אפליקציות, שבהן משתמשים יכולים לחפש פריטים על ידי העלאת תמונות של מוצרים דומים.
Google Lens היא אפליקציה לחיפוש תמונות המשווה תמונות ממצלמה למוצרים דומים מבחינה ויזואלית. לדוגמה, ניתן להשתמש בו כדי להתאים מוצרי אינטרנט הדומים לזוג נעלי ספורט או פריט לבוש.
אודיו
הטבעות אודיו הן ייצוגים וקטוריים של אותות אודיו. הטבעות וקטור לוכדות מאפייני שמיעה, ומאפשרות למערכות לפרש נתוני אודיו בצורה יעילה יותר. לדוגמה, ניתן להשתמש בהטמעות אודיו עבור המלצות מוזיקה, סיווגי ז'אנרים, חיפושי דמיון אודיו, זיהוי דיבור ואימות דובר.
בעוד ש-AI נמצא בשימוש עבור סוגים שונים של הטמעות, AI אודיו קיבל פחות תשומת לב מאשר AI של טקסט או תמונה. Google Speech-to-Text ו OpenAI Whisper הם יישומי הטבעת אודיו המשמשים בארגונים כגון מוקדים טלפוניים, טכנולוגיה רפואית, נגישות ויישומי דיבור לטקסט.
גרפים
הטמעות גרפים משתמשות בוקטורים כדי לייצג צמתים וקצוות בגרף. הם משמש במשימות הקשורות לניתוח גרפים כגון חיזוי קישור, הכרה קהילתית ומערכות המלצות.
כל צומת מייצג ישות, כגון אדם, דף אינטרנט או מוצר וכל קצה מסמל את הקישור או החיבור הקיים בין הישויות הללו. הטבעות וקטוריות אלו יכולות להשיג הכל, החל מהמלצות על חברים רשתות חברתיות לאיתור בעיות אבטחת סייבר.
נתוני סדרות זמן ומודלים תלת מימדיים
הטבעות של סדרות זמן לוכדות דפוסים זמניים בנתונים עוקבים. הם משמשים ב אינטרנט של דברים יישומים, נתונים פיננסיים ונתוני חיישנים עבור פעילויות כולל זיהוי חריגות, תחזית סדרת זמן וזיהוי דפוסים.
היבטים גיאומטריים של אובייקטים תלת מימדיים יכולים לבוא לידי ביטוי גם כווקטורים באמצעות הטבעת מודל תלת מימד. הם מיושמים במשימות כגון שחזור תלת מימד, זיהוי אובייקטים והתאמת צורות.
מולקולות
הטבעות מולקולות מייצגות תרכובות כימיות כווקטורים. הם משמשים בגילוי תרופות, חיפוש דמיון כימי וחיזוי מאפיינים מולקולריים. הטמעות אלו משמשות גם בכימיה חישובית ובפיתוח תרופות כדי ללכוד את התכונות המבניות והכימיות של מולקולות.

מה זה Word2Vec?
Word2Vec היא גישה פופולרית להטמעת מילים וקטורית של NLP. נוצר על ידי גוגל, Word2Vec נועד לייצג מילים כווקטורים צפופים במרחב וקטור רציף. זה יכול לזהות את ההקשר של מילה במסמך והוא נפוץ במשימות NLP כמו סיווג טקסט, ניתוח סנטימנטים ו מכונת תרגום לעזור למכונות להבין ולעבד שפה טבעית בצורה יעילה יותר.
Word2Vec מבוסס על העיקרון שלפיו למילים בעלות משמעויות דומות יהיו ייצוגים וקטוריים דומים, מה שמאפשר למודל ללכוד קישורים סמנטיים בין מילים.
ל-Word2Vec יש שתי ארכיטקטורות בסיסיות, CBOW (שק מתמשך של מילים) ודילג-גרם:
- CBOW. ארכיטקטורה זו חוזה את מילת היעד על סמך מילות ההקשר. המודל מקבל הקשר או מילים מסביב ומוטל עליו לחזות את מילת המטרה במרכז. לדוגמה, במשפט, "השועל החום המהיר קופץ מעל הכלב העצלן", CBOW משתמש בהקשר או במילים שמסביב כדי לחזות שועל בתור מילת המטרה.
- דלג-גרם. שלא כמו CBOW, ארכיטקטורת Skip-Gram חוזה את מילות ההקשר על סמך מילת היעד. המודל מקבל מילת מטרה ומתבקש לחזות את מונחי ההקשר שמסביב. אם ניקח את המשפט לדוגמה לעיל של "השועל החום המהיר קופץ מעל הכלב העצלן", דילוג-גרם ייקח את מילת המטרה שועל ולגלות מילות הקשר כגון "ה", "מהיר", "חום", "קופץ", "מעל", "ה", "עצלן" ו"כלב".
מגוון רחב של עסקים מתחילים לאמץ את הבינה המלאכותית הגנרטיבית, מה שמוכיח את הפוטנציאל ההפרתי שלה. לִבחוֹן כיצד AI גנרטיבי מתפתח, לאיזה כיוון זה ילך בעתיד וכל אתגרים שעלולים להתעורר.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.techtarget.com/searchenterpriseai/definition/vector-embeddings
- :יש ל
- :הוא
- :איפה
- $ למעלה
- 000
- 1
- 26
- 27
- 31
- 360
- 3d
- 40
- 43
- a
- מֵעַל
- נגישות
- להשיג
- לרוחב
- פעולות
- פעילויות
- נוסף
- כראוי
- פרסום
- לאחר
- AI
- סיוע
- איידס
- אלגוריתמים
- תעשיות
- גם
- אמזון בעברית
- an
- אנליזה
- ו
- גילוי חריגות
- אחר
- כל
- בקשה
- יישומים
- יישומית
- גישה
- גישות
- מתאים
- אפליקציות
- ארכיטקטורה
- ARE
- לְהִתְעוֹרֵר
- מערך
- מאמר
- מאמרים
- מלאכותי
- בינה מלאכותית
- AS
- היבטים
- התאסף
- הערכה
- At
- תשומת לב
- אודיו
- תיק
- תיק מילים
- מבוסס
- בסיסי
- BE
- כי
- ההתחלה
- להיות
- בֵּין
- מעבר
- שניהם
- חום
- עסקים
- by
- לחשב
- שיחה
- נקרא
- חדר
- CAN
- יכולות
- קיבולת
- ללכוד
- לכידה
- נושאת
- מקרים
- קטגוריה
- מרכז
- מרכזים
- האתגרים
- השתנה
- מאפיינים
- chatbots
- כימי
- כימיה
- כיתות
- מיון
- ניקוי
- סְגוֹר
- קרוב יותר
- ביגוד
- קיבוץ
- COM
- איך
- Common
- בדרך כלל
- קהילה
- לְהַשְׁווֹת
- השוואות
- להשלים
- רכיבים
- הרכב
- לִהַבִין
- חישובית
- מחשבים
- מחשוב
- תמציתית
- הקשר
- תוכן
- הקשר
- קשר
- רציף
- שיחות
- להמיר
- עותקים
- נוצר
- מכריע
- אבטחת סייבר
- נתונים
- נקודות מידע
- מערך נתונים
- מסד נתונים
- מאגרי מידע
- עמוק
- למידה עמוקה
- מוגדר
- הגדרה
- מסירה
- הפגנה
- צפוף
- תלוי
- מעוצב
- למרות
- לאתר
- איתור
- צעצועי התפתחות
- ההבדלים
- אחר
- מֵמַד
- ממדים
- כיוון
- לגלות
- תגלית
- מְשַׁבֵּשׁ
- מרחק
- מובהק
- do
- מסמך
- מסמכים
- כֶּלֶב
- דון
- תרופה
- פיתוח תרופות
- גילוי תרופות
- בְּמַהֲלָך
- כל אחד
- קל יותר
- אדג '
- אפקטיבי
- יעילות
- יְעִילוּת
- יעילות
- יְעִילוּת
- יעילות
- חיסול
- מוטבע
- הטבעה
- לחבק
- לאפשר
- מה שמאפשר
- עוטף
- מנועים
- לְהַבטִיחַ
- ישויות
- ישות
- סביבה
- במיוחד
- חיוני
- Ether (ETH)
- הערכה
- אֲפִילוּ
- הכל
- לִבחוֹן
- דוגמה
- קיים
- ביטא
- מביע
- בהרחבה
- מקל
- נכשל
- תכונות
- כספי
- מידע פיננסי
- הבא
- בעד
- טופס
- פוּרמָט
- נוצר
- צורות
- שועל
- רמאי
- בתדירות גבוהה
- טרי
- חברים
- החל מ-
- פונקציה
- פונקציות
- עתיד
- צבר
- ללקט
- מד
- כללי
- ליצור
- נוצר
- גנרטטיבית
- AI Generative
- ז'ָאנר
- ענקים
- נתן
- כפפה
- Go
- גרף
- יש
- לעזור
- מועיל
- עזרה
- גָבוֹהַ
- איך
- HTTPS
- עצום
- ICON
- הזדהות
- מזוהה
- לזהות
- if
- תמונה
- חיפוש תמונה
- תמונות
- עָצוּם
- לשפר
- in
- לכלול
- כלול
- כולל
- עצמאי
- אינדקסים
- בנפרד
- תעשיות
- תעשייה
- מידע
- פניות
- בתוך
- למשל
- מקרים
- מוֹדִיעִין
- התכוון
- אינטרנט
- אל תוך
- מעורב
- כרוך
- בעיות
- IT
- פריטים
- שֶׁלָה
- קפיצות
- מפתח
- ידוע
- שפה
- גָדוֹל
- למד
- למידה
- Lens
- פחות
- לתת
- מכתב
- לתת
- מוגבל
- קשר
- קישורים
- הגיוני
- הסתכלות
- מכונה
- למידת מכונה
- מכונה
- עשוי
- לעשות
- עושה
- ניהול
- דרך
- להתאים
- גפרורים
- תואם
- מתימטי
- משמעות
- משמעותי
- משמעויות
- רפואי
- יכול
- ML
- מודל
- דוגמנות
- מודלים
- מולקולרי
- יותר
- רוב
- הכי פופולארי
- כלי נגינה
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- נטפליקס
- עצביים
- חדש
- NLP
- צומת
- צמתים
- רעש
- מספר
- מספרים
- רב
- אובייקט
- זיהוי אובייקט
- אובייקטים
- of
- הַצָעָה
- לעתים קרובות
- on
- ONE
- לפתוח
- קוד פתוח
- תפעול
- or
- ארגונים
- מאורגן
- מְקוֹרִי
- אחר
- הַחוּצָה
- תוצאות
- חריג,יוצא דופן
- יותר
- עמוד
- זוג
- פרמטרים
- חלק
- תבנית
- דפוסי
- ביצועים
- אדם
- אישית
- שלב
- תמונות
- ביטויים
- תמונה
- תמונות
- לְחַבֵּר
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- לְשַׂחֵק
- נקודות
- פופולרי
- פופולריות
- אפשרי
- פוטנציאל
- צורך
- לחזות
- חזה
- ניבוי
- נבואה
- התחזיות
- תחזית
- העדפות
- הכנה
- עקרון
- תהליך
- תהליך
- מעבדים
- הפקת
- המוצר
- הפקה
- מוצרים
- פּרוֹפִיל
- נכסים
- רכוש
- לספק
- מספק
- תכונות
- מָהִיר
- רכס
- מהר
- RE
- קיבלו
- הכרה
- להכיר
- המלצה
- המלצות
- ממליץ
- להפחית
- להתייחס
- מתייחס
- קָשׁוּר
- מערכות יחסים
- רלוונטי
- שכפול
- דוחות לדוגמא
- לייצג
- נציגות
- מיוצג
- המייצג
- מייצג
- להגיב
- תגובות
- וכתוצאה מכך
- שליפה
- להפוך
- תפקיד
- s
- אותו
- סולם
- חיפוש
- מנועי חיפוש
- חיפושים
- חיפוש
- סעיף
- פילוח
- סמנטי
- סמנטיקה
- חיישן
- משפט
- רגש
- סדרה
- סט
- סטים
- כמה
- sharding
- צריך
- הצגה
- אותות
- משמעותי
- דומה
- הדמיון
- since
- קטן
- נעלי ספורט
- כמה
- מָקוֹר
- מֶרחָב
- רַמקוֹל
- מתמחים
- מיוחד
- ספציפי
- נאום
- זיהוי דיבור
- דיבור-לטקסט
- תֶקֶן
- צעדים
- עוד
- חנות
- מאוחסן
- מִבנִי
- מובנה
- כזה
- שסופק
- הסובב
- מסמל
- מערכות
- T
- מותאם
- לקחת
- נטילת
- יעד
- ממוקד
- משימות
- טכניקות
- טכנולוגיה
- מונחים
- טֶקסט
- מֵאֲשֶׁר
- זֶה
- השמיים
- העתיד
- שֶׁלָהֶם
- אלה
- הֵם
- דבר
- דברים
- זֶה
- אלה
- דרך
- זמן
- סדרת זמן
- ל
- יַחַד
- סובלנות
- רכבת
- מְאוּמָן
- הדרכה
- רכבות
- לשנות
- תרגום
- תור
- שתיים
- סוג
- סוגים
- בדרך כלל
- נדיר
- הבנה
- רָצוּף
- אוניברסלי
- בניגוד
- העלאה
- להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- שימושים
- באמצעות
- ערכים
- מגוון
- שונים
- אימות
- באמצעות
- וִידֵאוֹ
- חזותי
- מבחינה ויזואלית
- דֶרֶך..
- אינטרנט
- מה
- מה
- מתי
- ואילו
- אם
- אשר
- בזמן
- Whisper
- כל
- רָחָב
- טווח רחב
- יצטרך
- עם
- Word
- מילים
- YouTube
- זפירנט
- למידה אפס-שוט