בפוסט זה, אנו מדגימים כיצד להשתמש בגיזום מבני מבוסס חיפוש ארכיטקטורה עצבית (NAS) כדי לדחוס מודל BERT מכוון עדין כדי לשפר את ביצועי המודל ולצמצם את זמני ההסקה. מודלים של שפה מאומנים מראש (PLMs) עוברים אימוץ מהיר מסחרי וארגוני בתחומים של כלי פרודוקטיביות, שירות לקוחות, חיפוש והמלצות, אוטומציה של תהליכים עסקיים ויצירת תוכן. פריסת נקודות קצה של מסקנות PLM קשורה בדרך כלל להשהייה גבוהה יותר ולעלויות תשתית גבוהות יותר בשל דרישות המחשוב ויעילות חישובית מופחתת בשל מספר הפרמטרים הרב. גיזום PLM מפחית את הגודל והמורכבות של המודל תוך שמירה על יכולות הניבוי שלו. PLMs גזומים משיגים טביעת זיכרון קטנה יותר והשהייה נמוכה יותר. אנו מדגימים כי על ידי חיתוך PLM וביטול ספירת פרמטרים ושגיאת אימות עבור משימת יעד ספציפית, ומסוגלים להשיג זמני תגובה מהירים יותר בהשוואה למודל ה-PLM הבסיסי.
אופטימיזציה רב-אובייקטיבית היא תחום של קבלת החלטות המייעל יותר מתפקוד אובייקטיבי אחד, כגון צריכת זיכרון, זמן אימון ומשאבי מחשוב, למיטוב בו-זמנית. גיזום מבני הוא טכניקה לצמצום הגודל והדרישות החישוביות של PLM על ידי גיזום שכבות או נוירונים/צמתים תוך ניסיון לשמר את דיוק המודל. על ידי הסרת שכבות, גיזום מבני משיג שיעורי דחיסה גבוהים יותר, מה שמוביל לדלילות מובנית ידידותית לחומרה שמפחיתה את זמני הריצה וזמני התגובה. יישום טכניקת גיזום מבנית על מודל PLM מביא למודל קל משקל עם טביעת זיכרון נמוכה יותר, שכאשר מתארח כנקודת קצה ב- SageMaker, מציע יעילות משאבים משופרת ועלות מופחתת בהשוואה ל-PLM המקורי המכוונן עדין.
ניתן ליישם את המושגים המוצגים בפוסט זה על יישומים המשתמשים בתכונות PLM, כגון מערכות המלצות, ניתוח סנטימנטים ומנועי חיפוש. באופן ספציפי, אתה יכול להשתמש בגישה זו אם יש לך צוותי למידת מכונה (ML) ומדעי נתונים ייעודיים שמכוונים את מודלי ה-PLM שלהם באמצעות מערכי נתונים ספציפיים לתחום ופורסים מספר רב של נקודות קצה באמצעות אמזון SageMaker. דוגמה אחת היא קמעונאי מקוון שפורס מספר רב של נקודות קצה עבור סיכום טקסט, סיווג קטלוג מוצרים וסיווג סנטימנט משוב על מוצרים. דוגמה נוספת עשויה להיות ספק שירותי בריאות המשתמש בנקודות קצה של מסקנות PLM עבור סיווג מסמכים קליניים, זיהוי ישות מדוחות רפואיים, צ'אטבוטים רפואיים וריבוד סיכון של חולים.
סקירת פתרונות
בחלק זה, אנו מציגים את זרימת העבודה הכוללת ומסבירים את הגישה. ראשית, אנו משתמשים ב-an סטודיו SageMaker של אמזון מחברה כדי לכוונן מודל BERT מאומן מראש על משימת יעד באמצעות מערך נתונים ספציפי לתחום. ברט (ייצוגי קודן דו-כיווני מרובוטריקים) הוא מודל שפה מיומן מראש המבוסס על ארכיטקטורת שנאים משמש למשימות עיבוד שפה טבעית (NLP). חיפוש ארכיטקטורה עצבית (NAS) היא גישה לאוטומציה של תכנון רשתות עצביות מלאכותיות וקשורה קשר הדוק לאופטימיזציה של היפרפרמטרים, גישה בשימוש נרחב בתחום למידת מכונה. המטרה של NAS היא למצוא את הארכיטקטורה האופטימלית לבעיה נתונה על ידי חיפוש על קבוצה גדולה של ארכיטקטורות מועמדות תוך שימוש בטכניקות כגון אופטימיזציה ללא גרדיאנט או על ידי אופטימיזציה של המדדים הרצויים. ביצועי הארכיטקטורה נמדדים בדרך כלל באמצעות מדדים כגון אובדן אימות. SageMaker כוונון דגם אוטומטי (AMT) ממכן את התהליך המייגע והמורכב של מציאת השילובים האופטימליים של היפרפרמטרים של מודל ה-ML שמניבים את ביצועי המודל הטובים ביותר. AMT משתמש באלגוריתמי חיפוש חכמים והערכות איטרטיביות תוך שימוש במגוון של פרמטרים היפר שאתה מציין. הוא בוחר את ערכי ההיפרפרמטרים שיוצרים מודל שמבצע את הביצועים הטובים ביותר, כפי שנמדד על ידי מדדי ביצועים כגון דיוק וציון F-1.
גישת הכוונון המתוארת בפוסט זה היא כללית וניתנת ליישום על כל מערך נתונים מבוסס טקסט. המשימה שהוקצתה ל-BERT PLM יכולה להיות משימה מבוססת טקסט כגון ניתוח סנטימנטים, סיווג טקסט או שאלות ותשובות. בהדגמה זו, משימת היעד היא בעיית סיווג בינארי שבה משתמשים ב-BERT כדי לזהות, מתוך מערך נתונים המורכב מאוסף של זוגות של קטעי טקסט, האם ניתן להסיק את המשמעות של קטע טקסט אחד מהמקטע השני. אנו משתמשים ב- זיהוי מערך נתונים של תוכן טקסטואלי מחבילת הבנצ'מרקינג של GLUE. אנו מבצעים חיפוש רב-אובייקטיבי באמצעות SageMaker AMT כדי לזהות את תת-הרשתות המציעות פשרות אופטימליות בין ספירת פרמטרים ודיוק חיזוי עבור משימת היעד. בעת ביצוע חיפוש רב-אובייקטיבי, אנו מתחילים בהגדרת הדיוק וספירת הפרמטרים כיעדים שאנו שואפים לייעל.
בתוך רשת BERT PLM, יכולות להיות תת-רשתות מודולריות עצמאיות המאפשרות למודל יכולות מיוחדות כגון הבנת שפה וייצוג ידע. BERT PLM משתמש בתת-רשת מרובת ראשים לתשומת לב עצמית ותת-רשת להזנה קדימה. שכבת תשומת לב עצמית מרובת ראשים מאפשרת ל-BERT לקשר מיקומים שונים של רצף בודד על מנת לחשב ייצוג של הרצף על ידי מתן אפשרות למספר ראשים לטפל במספר אותות הקשר. הקלט מפוצל למספר תת-מרחבים ותשומת לב עצמית מוחלת על כל אחד מתתי-המרחבים בנפרד. מספר ראשים בשנאי PLM מאפשרים למודל לטפל במשותף במידע מתתי מרחבי ייצוג שונים. תת-רשת הזנה קדימה היא רשת עצבית פשוטה שלוקחת את הפלט מתת-הרשת מרובת הראשים, מעבדת את הנתונים ומחזירה את ייצוגי המקודד הסופיים.
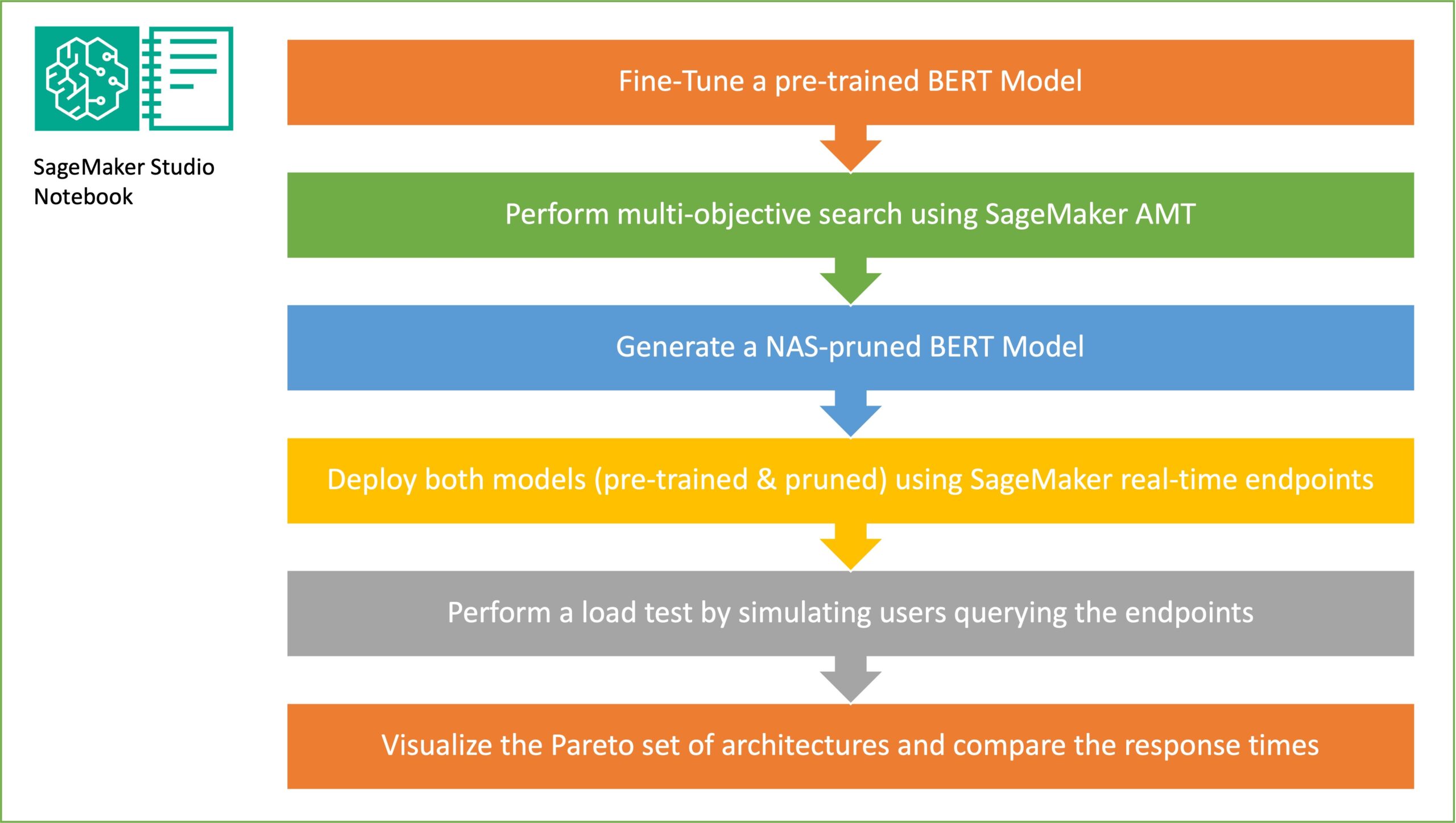
המטרה של דגימת תת-רשת אקראית היא להכשיר מודלים קטנים יותר של BERT שיכולים לבצע מספיק טוב במשימות היעד. אנו דוגמים 100 רשתות משנה אקראיות ממודל הבסיס המכוונן של BERT ומעריכים 10 רשתות בו-זמנית. תת הרשתות המאומנות מוערכות עבור המדדים האובייקטיביים והמודל הסופי נבחר על סמך הפשרות שנמצאו בין המדדים האובייקטיביים. אנו מדמיינים את חזית פארטו עבור תת-הרשתות שנדגמו, המכילה את המודל הגזום המציע את הפשרה האופטימלית בין דיוק הדגם לגודל הדגם. אנו בוחרים את רשת המשנה המועמדת (מודל BERT גזום ב-NAS) בהתבסס על גודל הדגם ודיוק המודל שאנו מוכנים להתפשר עליו. לאחר מכן, אנו מארחים את נקודות הקצה, את מודל הבסיס של BERT שהוכשר מראש, ואת מודל ה-BERT שנגזם ב-NAS באמצעות SageMaker. כדי לבצע בדיקת עומס, אנו משתמשים אַרְבֶּה, כלי לבדיקת עומסים בקוד פתוח שתוכל ליישם באמצעות Python. אנו מפעילים בדיקות עומס בשתי נקודות הקצה באמצעות Locust ומדמיינים את התוצאות באמצעות חזית Pareto כדי להמחיש את הפשרה בין זמני תגובה ודיוק עבור שני הדגמים. התרשים הבא מספק סקירה כללית של זרימת העבודה המוסברת בפוסט זה.
תנאים מוקדמים
לפוסט זה נדרשים הדרישות המוקדמות הבאות:
אתה גם צריך להגדיל את מכסת שירות כדי לגשת לפחות לשלושה מופעים של מופעי ml.g4dn.xlarge ב- SageMaker. סוג המופע ml.g4dn.xlarge הוא מופע ה-GPU החסכוני המאפשר לך להפעיל את PyTorch באופן מקורי. כדי להגדיל את מכסת השירות, בצע את השלבים הבאים:
- במסוף, נווט אל מכסות שירות.
- בעד ניהול מכסות, בחר אמזון SageMaker, ואז לבחור צפה במכסות.

- חפש "ml-g4dn.xlarge עבור שימוש בעבודה באימון" ובחר בפריט המכסה.
- בחרו בקש הגדלה ברמת החשבון.
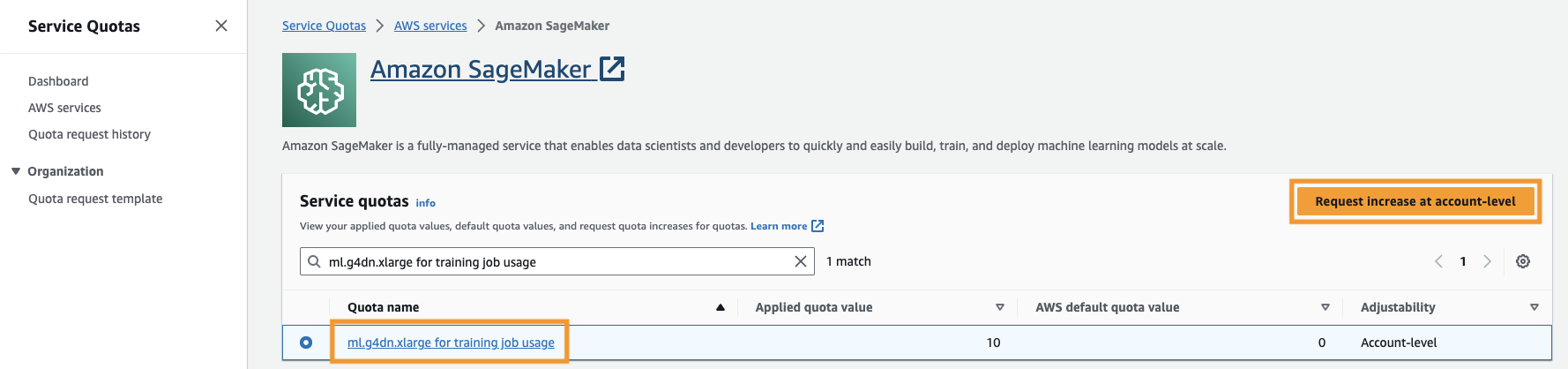
- בעד הגדל את ערך המכסה, הזן ערך של 5 ומעלה.
- בחרו בקש.
אישור המכסה המבוקש עשוי להימשך זמן מה, בהתאם להרשאות החשבון.

- פתח את SageMaker Studio מקונסולת SageMaker.

- בחרו מסוף מערכת תחת כלי עזר וקבצים.

- הפעל את הפקודה הבאה כדי לשכפל את GitHub ריפו למופע SageMaker Studio:
- נווט אל
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - פתח את הקובץ
nas_for_llm_with_amt.ipynb. - הגדר את הסביבה עם א
ml.g4dn.xlargeדוגמה ובחר בחר.

הגדר את מודל BERT שהוכשר מראש
בסעיף זה, אנו מייבאים את מערך הנתונים של Recognizing Textual Entailment מספריית הנתונים ומפצלים את מערך הנתונים לקבוצות הדרכה ואימות. מערך נתונים זה מורכב מזוגות של משפטים. המשימה של BERT PLM היא לזהות, בהינתן שני קטעי טקסט, האם ניתן להסיק את המשמעות של קטע טקסט אחד מהמקטע השני. בדוגמה הבאה, נוכל להסיק את המשמעות של הביטוי הראשון מהביטוי השני:
אנו טוענים את מערך הנתונים של זיהוי טקסטואלי מה- דבק חבילת ההשוואה דרך ה ספריית נתונים מ-Huging Face בתוך תסריט ההדרכה שלנו (./training.py). חילקנו את מערך ההדרכה המקורי מ-GLUE לסט הדרכה ואימות. בגישה שלנו, אנו מכווננים את מודל ה-BERT הבסיסי באמצעות מערך ההדרכה, ולאחר מכן אנו מבצעים חיפוש רב-אובייקטיבי כדי לזהות את קבוצת המשנה של רשתות המאזנות בצורה מיטבית בין המדדים האובייקטיביים. אנו משתמשים במערך ההדרכה באופן בלעדי לכוונון עדין של מודל BERT. עם זאת, אנו משתמשים בנתוני אימות לחיפוש רב-אובייקטיבי על ידי מדידת דיוק במערך הנתונים של אימות ה-holdout.
כוונן עדין את BERT PLM באמצעות מערך נתונים ספציפי לתחום
מקרי השימוש האופייניים למודל BERT גולמי כוללים חיזוי המשפט הבא או מודלים של שפה במסכה. כדי להשתמש במודל BERT הבסיסי עבור משימות במורד הזרם, כגון זיהוי טקסטואלי, עלינו לכוונן עוד יותר את המודל באמצעות מערך נתונים ספציפי לתחום. אתה יכול להשתמש במודל BERT מכוון למשימות כגון סיווג רצף, מענה על שאלות וסיווג אסימון. עם זאת, למטרות הדגמה זו, אנו משתמשים במודל המכוון לסיווג בינארי. אנו מכווננים את מודל ה-BERT המאומן מראש עם מערך ההדרכה שהכנו קודם לכן, באמצעות הפרמטרים הבאים:
אנו שומרים את המחסום של הכשרת המודל ל- an שירות אחסון פשוט של אמזון (Amazon S3) דלי, כך שניתן לטעון את הדגם במהלך החיפוש הרב-אובייקטיבי מבוסס NAS. לפני שנאמן את המודל, אנו מגדירים את המדדים כגון עידן, אובדן אימון, מספר פרמטרים ושגיאת אימות:
לאחר תחילת תהליך הכוונון, מלאכת ההדרכה נמשכת כ-15 דקות.
בצע חיפוש רב-אובייקטיבי לבחירת רשתות משנה ולדמיין את התוצאות
בשלב הבא, אנו מבצעים חיפוש רב-אובייקטיבי על מודל הבסיס המכוונן של BERT על ידי דגימת תת-רשתות אקראיות באמצעות SageMaker AMT. כדי לגשת לרשת משנה בתוך רשת העל (מודל BERT המכוונן עדין), אנו מסווים את כל הרכיבים של ה-PLM שאינם חלק מתת הרשת. מיסוך רשת-על כדי למצוא רשתות משנה ב-PLM היא טכניקה המשמשת לבידוד וזיהוי דפוסי התנהגות המודל. שימו לב ששנאי Hugging Face צריכים שהגודל הנסתר יהיה כפול של מספר הראשים. הגודל הנסתר בשנאי PLM שולט בגודל המרחב הווקטור של המצב הנסתר, מה שמשפיע על יכולתו של המודל ללמוד ייצוגים ודפוסים מורכבים בנתונים. ב-BERT PLM, וקטור המצב הנסתר הוא בגודל קבוע (768). אנחנו לא יכולים לשנות את הגודל הנסתר, ולכן מספר הראשים צריך להיות ב-[1, 3, 6, 12].
בניגוד לאופטימיזציה חד-אובייקטיבית, בהגדרה מרובה-מטרות, בדרך כלל אין לנו פתרון אחד שמייעל בו זמנית את כל היעדים. במקום זאת, אנו שואפים לאסוף קבוצה של פתרונות השולטים בכל שאר הפתרונות במטרה אחת לפחות (כגון שגיאת אימות). כעת נוכל להתחיל את החיפוש הרב-אובייקטיבי דרך AMT על ידי הגדרת המדדים שאנו רוצים להפחית (שגיאת אימות ומספר פרמטרים). תת הרשתות האקראיות מוגדרות על ידי הפרמטר max_jobs ומספר המשרות בו זמנית מוגדר על ידי הפרמטר max_parallel_jobs. הקוד לטעינת נקודת ביקורת הדגם ולהערכת רשת המשנה זמין ב- evaluate_subnetwork.py תַסרִיט.
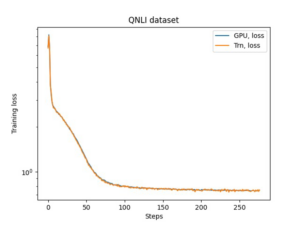
עבודת הכוונון של AMT אורכת כשעתיים ו-2 דקות. לאחר שעבודת הכוונון של AMT פועלת בהצלחה, אנו מנתחים את היסטוריית העבודה ואוספים את התצורות של תת הרשת, כגון מספר ראשים, מספר שכבות, מספר יחידות, והמדדים המתאימים כגון שגיאת אימות ומספר פרמטרים. צילום המסך הבא מציג את הסיכום של עבודת טיונר AMT מוצלחת.
לאחר מכן, אנו מדמיינים את התוצאות באמצעות ערכת Pareto (הידועה גם בשם Pareto frontier או Pareto optimal set), שעוזרת לנו לזהות קבוצות אופטימליות של תת-רשתות השולטות בכל שאר תת-הרשתות במדד האובייקטיבי (שגיאת אימות):
ראשית, אנו אוספים את הנתונים מעבודת הכוונון של AMT. לאחר מכן אנו מתווים את סט פארטו באמצעות matplotlob.pyplot עם מספר פרמטרים בציר x ושגיאת אימות בציר y. זה מרמז שכאשר אנו עוברים מתת-רשת אחת של ערכת Pareto לאחרת, עלינו להקריב ביצועים או גודל דגם אך לשפר את השני. בסופו של דבר, ערכת Pareto מספקת לנו את הגמישות לבחור את תת הרשת המתאימה ביותר להעדפות שלנו. אנחנו יכולים להחליט כמה אנחנו רוצים להקטין את גודל הרשת שלנו וכמה ביצועים אנחנו מוכנים להקריב.

פרוס את מודל BERT המכוונן עדין ואת מודל המשנה המותאם ל-NAS באמצעות SageMaker
לאחר מכן, אנו פורסים את הדגם הגדול ביותר בסט Pareto שלנו שמוביל לכמות הקטנה ביותר של ניוון ביצועים ל- נקודת קצה של SageMaker. המודל הטוב ביותר הוא זה שמספק פתרון אופטימלי בין שגיאת האימות למספר הפרמטרים למקרה השימוש שלנו.
השוואה מודל
לקחנו מודל BERT בסיס מאומן מראש, כיוונו אותו עדין באמצעות מערך נתונים ספציפי לתחום, הרצנו חיפוש NAS כדי לזהות רשתות משנה דומיננטיות על סמך המדדים האובייקטיביים, ופרסנו את המודל הגזום על נקודת קצה של SageMaker. בנוסף, לקחנו את מודל ה-BERT הבסיסי שהוכשר מראש ופרסנו את מודל הבסיס על נקודת קצה שניה של SageMaker. לאחר מכן, רצנו בדיקת עומס באמצעות Locust בשתי נקודות הקצה והעריכו את הביצועים במונחים של זמן תגובה.
ראשית, אנו מייבאים את ספריות Locust ו-Boto3 הדרושות. לאחר מכן אנו בונים מטא נתונים של בקשה ומתעדים את שעת ההתחלה שתשמש לבדיקת עומס. לאחר מכן המטען מועבר ל-API של נקודת הקצה של SageMaker באמצעות ה-BotoClient כדי לדמות בקשות משתמש אמיתיות. אנו משתמשים ב-Locust כדי להוליד מספר משתמשים וירטואליים לשלוח בקשות במקביל ולמדוד את ביצועי נקודות הקצה תחת העומס. בדיקות מופעלות על ידי הגדלת מספר המשתמשים עבור כל אחת משתי נקודות הקצה, בהתאמה. לאחר השלמת הבדיקות, Locust מוציא קובץ CSV סטטיסטיקת בקשה עבור כל אחד מהדגמים הפרוסים.
לאחר מכן, אנו יוצרים את עלילות זמן התגובה מקובצי ה-CSV שהורדו לאחר הפעלת הבדיקות עם Locust. מטרת התווים של זמן התגובה לעומת מספר המשתמשים היא לנתח את תוצאות בדיקת העומס על ידי הדמיה של ההשפעה של זמן התגובה של נקודות הקצה של המודל. בתרשים הבא, אנו יכולים לראות שנקודת הקצה של הדגם הגזום ב-NAS משיגה זמן תגובה נמוך יותר בהשוואה לנקודת הקצה הבסיסית של מודל BERT.
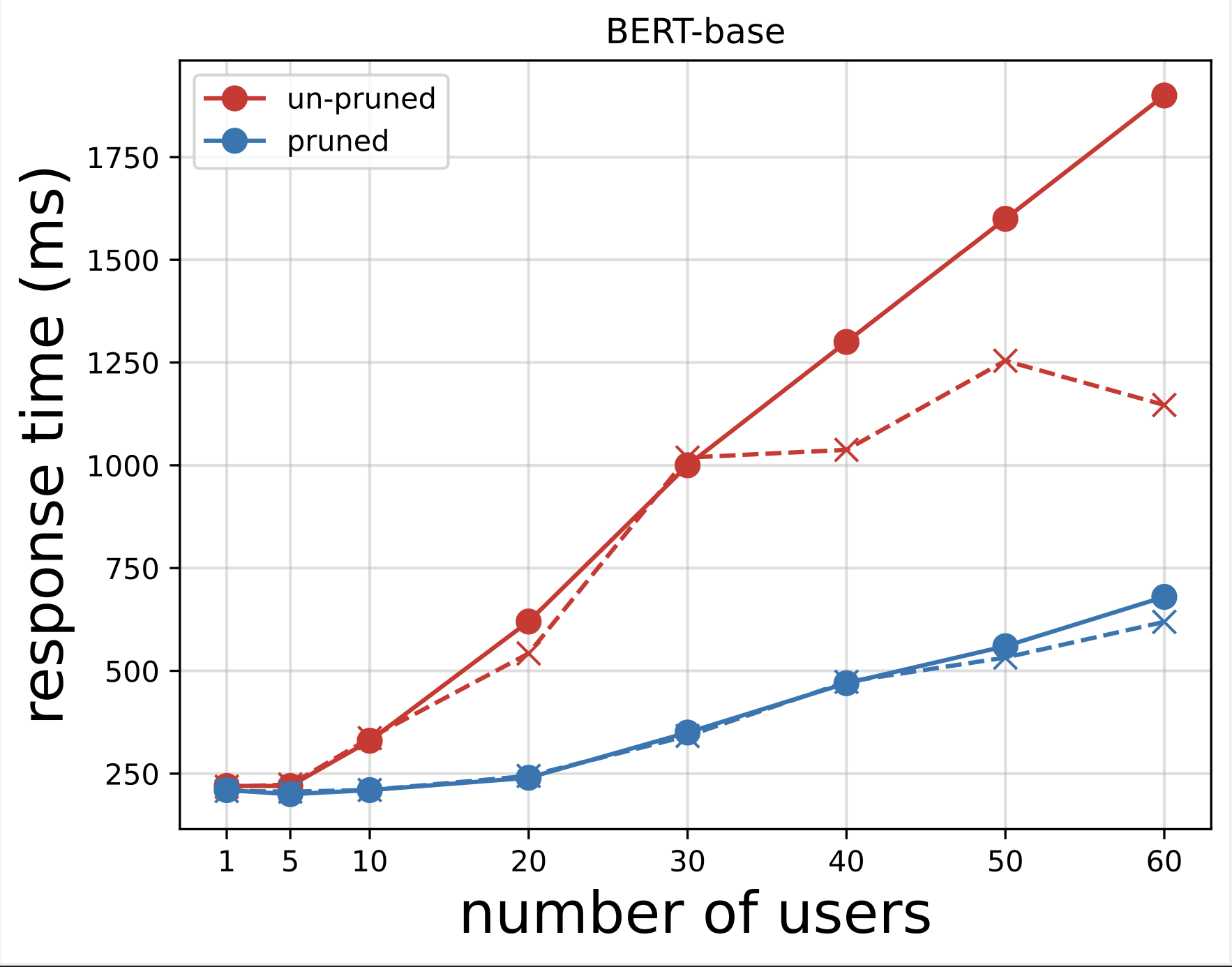
בתרשים השני, שהוא הרחבה של התרשים הראשון, אנו רואים שאחרי כ-70 משתמשים, SageMaker מתחיל לחנוק את נקודת הקצה הבסיסית של דגם BERT וזורק חריג. עם זאת, עבור נקודת הקצה של הדגם הגזום ב-NAS, המצערת מתרחשת בין 90-100 משתמשים ועם זמן תגובה נמוך יותר.

משני התרשימים, אנו רואים שלדגם הגזום יש זמן תגובה מהיר יותר והוא מתקדם טוב יותר בהשוואה לדגם הלא גזום. ככל שאנו מדרגים את מספר נקודות הקצה המסקנות, כמו במקרה של משתמשים שפורסים מספר רב של נקודות קצה עבור יישומי ה-PLM שלהם, יתרונות העלות ושיפור הביצועים מתחילים להיות משמעותיים למדי.
לנקות את
כדי למחוק את נקודות הקצה של SageMaker עבור מודל הבסיס המכוונן עדין של BERT והדגם הגזום ב-NAS, בצע את השלבים הבאים:
- במסוף SageMaker בחר הסקה ו נקודות קצה בחלונית הניווט.
- בחר את נקודת הקצה ומחק אותה.
לחלופין, מהמחברת של SageMaker Studio, הפעל את הפקודות הבאות על ידי מתן שמות נקודות הקצה:
סיכום
בפוסט זה, דנו כיצד להשתמש ב-NAS כדי לגזום מודל BERT מכוון. תחילה אימנו מודל BERT בסיסי באמצעות נתונים ספציפיים לתחום ופרסנו אותו לנקודת קצה של SageMaker. ביצענו חיפוש רב-אובייקטיבי על מודל הבסיס המכוונן של BERT באמצעות SageMaker AMT עבור משימת יעד. דמיינו את חזית Pareto ובחרנו את דגם ה-BERT האופטימלי של Pareto עם NAS ופרסו את המודל לנקודת קצה שנייה של SageMaker. ביצענו בדיקות עומסים באמצעות Locust כדי לדמות משתמשים המבקשים את שתי נקודות הקצה, ומדדנו ותיעדנו את זמני התגובה בקובץ CSV. שרטטנו את זמן התגובה מול מספר המשתמשים בשני הדגמים.
ראינו שמודל ה-BERT הגזום פעל טוב יותר באופן משמעותי הן בזמן התגובה והן בסף המצערת. הגענו למסקנה שהמודל הגזום ב-NAS היה עמיד יותר לעומס מוגבר על נקודת הקצה, תוך שמירה על זמן תגובה נמוך יותר גם כשיותר משתמשים הדגישו את המערכת בהשוואה למודל BERT הבסיסי. אתה יכול ליישם את טכניקת ה-NAS המתוארת בפוסט זה על כל מודל שפה גדול כדי למצוא דגם גזום שיכול לבצע את משימת היעד עם זמן תגובה נמוך משמעותית. אתה יכול לייעל עוד יותר את הגישה על ידי שימוש בהשהיה כפרמטר בנוסף לאובדן אימות.
למרות שאנו משתמשים ב-NAS בפוסט זה, קוונטיזציה היא גישה נפוצה נוספת המשמשת לאופטימיזציה ולדחיסת מודלים של PLM. קוונטיזציה מפחיתה את הדיוק של המשקולות וההפעלה ברשת מאומנת מנקודה צפה של 32 סיביות לרוחבי סיביות נמוכים יותר כגון מספרים שלמים של 8 סיביות או 16 סיביות, מה שמביא למודל דחוס שיוצר הסקה מהירה יותר. קוונטיזציה אינה מפחיתה את מספר הפרמטרים; במקום זאת הוא מפחית את הדיוק של הפרמטרים הקיימים כדי לקבל מודל דחוס. גיזום NAS מסיר רשתות מיותרות ב-PLM, מה שיוצר מודל דליל עם פחות פרמטרים. בדרך כלל, חיתוך NAS וכימות משמשים יחד לדחיסת PLMs גדולים כדי לשמור על דיוק המודל, להפחית את הפסדי האימות תוך שיפור הביצועים ולהקטין את גודל הדגם. הטכניקות האחרות הנפוצות להקטנת גודלן של PLMs כוללות זיקוק ידע, פירוק מטריצה, ו מפלי זיקוק.
הגישה המוצעת בבלוג מתאימה לצוותים המשתמשים ב- SageMaker כדי לאמן ולכוון את המודלים באמצעות נתונים ספציפיים לתחום ולפרוס את נקודות הקצה כדי ליצור מסקנות. אם אתה מחפש שירות מנוהל במלואו המציע מבחר של דגמי יסוד בעלי ביצועים גבוהים הדרושים לבניית יישומי בינה מלאכותית, שקול להשתמש סלע אמזון. אם אתם מחפשים מודלים מאומנים מראש, קוד פתוח עבור מגוון רחב של מקרי שימוש עסקיים וברצונכם לגשת לתבניות פתרונות ולמחברות לדוגמה, שקול להשתמש אמזון SageMaker JumpStart. גרסה מאומנת מראש של הדגם הבסיסי של Hugging Face BERT שבו השתמשנו בפוסט הזה זמינה גם מ- SageMaker JumpStart.
על הכותבים
 Aparajithan Vaidyanathan הוא אדריכל פתרונות ארגוניים ראשיים ב-AWS. הוא אדריכל ענן עם 24+ שנות ניסיון בתכנון ופיתוח מערכות תוכנה ארגוניות, בקנה מידה גדול ומבוזר. הוא מתמחה בהנדסת נתונים גנרטיבית בינה מלאכותית ולמידת מכונה. הוא רץ מרתון שואף ותחביביו כוללים טיולים רגליים, רכיבה על אופניים ובילוי עם אשתו ושני בנים.
Aparajithan Vaidyanathan הוא אדריכל פתרונות ארגוניים ראשיים ב-AWS. הוא אדריכל ענן עם 24+ שנות ניסיון בתכנון ופיתוח מערכות תוכנה ארגוניות, בקנה מידה גדול ומבוזר. הוא מתמחה בהנדסת נתונים גנרטיבית בינה מלאכותית ולמידת מכונה. הוא רץ מרתון שואף ותחביביו כוללים טיולים רגליים, רכיבה על אופניים ובילוי עם אשתו ושני בנים.
 אהרון קליין הוא Sr Applied Scientist ב-AWS שעובד על שיטות למידת מכונה אוטומטיות עבור רשתות עצביות עמוקות.
אהרון קליין הוא Sr Applied Scientist ב-AWS שעובד על שיטות למידת מכונה אוטומטיות עבור רשתות עצביות עמוקות.
 יאצק גולביובסקי הוא Sr Applied Scientist ב-AWS.
יאצק גולביובסקי הוא Sr Applied Scientist ב-AWS.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :יש ל
- :הוא
- :לֹא
- :איפה
- ][עמ'
- $ למעלה
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- יכולת
- יכול
- גישה
- חֶשְׁבּוֹן
- דיוק
- להשיג
- משיגה
- הפעלות
- תוספת
- אימוץ
- לאחר
- AI
- המטרה
- מכוון
- אלגוריתמים
- תעשיות
- להתיר
- מאפשר
- מאפשר
- גם
- אמזון בעברית
- אמזון שירותי אינטרנט
- כמות
- an
- אנליזה
- ניתוח
- לנתח
- ו
- אחר
- מענה
- כל
- API
- יישומים
- יישומית
- החל
- מריחה
- גישה
- הסכמה
- בערך
- ארכיטקטורה
- ARE
- AREA
- אזורים
- טיעונים
- סביב
- מלאכותי
- רשתות עצביות מלאכותיות
- AS
- שאפתן
- שהוקצה
- המשויך
- At
- מנסה
- השתתף
- אוטומטי
- למידת מכונות אוטומטית
- אוטומטית
- מכני עם סלילה אוטומטית
- אוטומציה
- אוטומציה
- זמין
- AWS
- צִיר
- איזון
- בסיס
- מבוסס
- BE
- להיות
- לפני
- התנהגות
- בהשוואות
- הטבות
- הטוב ביותר
- מוטב
- בֵּין
- קצת
- גוּף
- שניהם
- לִבנוֹת
- עסקים
- תהליך עסקי
- אוטומציה של תהליכים עסקיים
- אבל
- by
- CAN
- מועמד
- יכולות
- מקרה
- מקרים
- קטלוג
- שינוי
- תרשים
- תרשימים
- chatbots
- בחירה
- בחרו
- נבחר
- בכיתה
- מיון
- קליני
- מקרוב
- ענן
- קוד
- לגבות
- אוסף
- שילובים
- מסחרי
- Common
- בדרך כלל
- לעומת
- להשלים
- השלמת
- מורכב
- מורכבות
- רכיבים
- חישובית
- לחשב
- מושגים
- הגיע למסקנה
- לשקול
- מורכב
- קונסול
- אילוצים
- לבנות
- צְרִיכָה
- מכיל
- תוכן
- יצירת תוכן
- הקשר
- להמשיך
- לעומת זאת
- בקרות
- תוֹאֵם
- עלות
- עלויות
- לספור
- לִיצוֹר
- יוצר
- יצירה
- לקוח
- שירות לקוחות
- נתונים
- מדע נתונים
- מערכי נתונים
- datetime
- להחליט
- קבלת החלטות
- מוקדש
- עמוק
- רשתות עצביות עמוקות
- לְהַגדִיר
- מוגדר
- הגדרה
- הַדגָמָה
- להפגין
- תלוי
- לפרוס
- פרס
- פריסה
- פורס
- מְתוּאָר
- עיצוב
- תכנון
- רצוי
- מתפתח
- אחר
- נָדוֹן
- מופץ
- מסמך
- לא
- דומיננטי
- לשלוט
- לא
- ראוי
- בְּמַהֲלָך
- e
- כל אחד
- יְעִילוּת
- יעיל
- או
- נקודת קצה
- נקודות קצה
- הנדסה
- מנועים
- מספיק
- זן
- מִפְעָל
- אימוץ ארגוני
- פתרונות ארגוניים
- ישות
- כניסה
- סביבה
- תקופה
- שגיאה
- Ether (ETH)
- להעריך
- העריך
- הערכות
- אֲפִילוּ
- אירועים
- דוגמה
- אלא
- יוצא מן הכלל
- אך ורק
- קיימים
- ניסיון
- להסביר
- מוסבר
- הארכה
- פָּנִים
- שקר
- מהר יותר
- תכונות
- מָשׁוֹב
- פחות
- שדה
- שלח
- קבצים
- סופי
- מציאת
- ראשון
- קבוע
- גמישות
- צף
- הבא
- עָקֵב
- בעד
- מצא
- קרן
- החל מ-
- חזית
- גבול
- לגמרי
- פונקציה
- נוסף
- ליצור
- מייצר
- גנרטטיבית
- AI Generative
- לקבל
- נתן
- מטרה
- GPU
- אפור
- קורה
- יש
- he
- ראש
- ראשי
- בריאות
- עוזר
- מוּסתָר
- ביצועים גבוהים
- גבוה יותר
- טיולים
- שֶׁלוֹ
- היסטוריה
- תחביבים
- המארח
- אירח
- שעות
- איך
- איך
- אולם
- HTML
- http
- HTTPS
- חיבוק פנים
- אופטימיזציה של היפר-פרמטרים
- כוונון היפר-פרמטר
- i
- לזהות
- IDX
- if
- להמחיש
- פְּגִיעָה
- השפעות
- ליישם
- לייבא
- לשפר
- משופר
- השבחה
- שיפור
- in
- לכלול
- להגדיל
- גדל
- גדל
- מידע
- תשתית
- קלט
- למשל
- מקרים
- במקום
- אינטליגנטי
- אל תוך
- IT
- שֶׁלָה
- עבודה
- מקומות תעסוקה
- jpg
- ג'סון
- ידע
- ידוע
- שפה
- גָדוֹל
- בקנה מידה גדול
- הגדול ביותר
- חֶבִיוֹן
- שכבה
- שכבות
- מוביל
- לִלמוֹד
- למידה
- הכי פחות
- לתת
- ספריות
- סִפְרִיָה
- קו
- לִטעוֹן
- היכנס
- רישום
- הסתכלות
- את
- אבדות
- להוריד
- מכונה
- למידת מכונה
- לתחזק
- שמירה
- איש
- הצליח
- מרתון
- מסכה
- matplotlib
- מקסימום
- מאי..
- משמעות
- למדוד
- נמדד
- מדידת
- רפואי
- לִפְגוֹשׁ
- זכרון
- מידע נוסף
- שיטות
- מטרי
- מדדים
- יכול
- לצמצם
- דקות
- ML
- מודל
- דוגמנות
- מודלים
- מודולרי
- יותר
- המהלך
- הרבה
- מספר
- צריך
- שם
- שם
- שמות
- ב
- טבעי
- שפה טבעית
- עיבוד שפה טבעית
- נווט
- ניווט
- הכרחי
- צורך
- נחוץ
- צרכי
- רשת
- רשתות
- עצביים
- רשת עצבית
- רשתות עצביות
- הבא
- NLP
- ללא חתימה
- הערות
- מחברה
- מחשבים ניידים
- עַכשָׁיו
- מספר
- אובייקט
- מטרה
- יעדים
- להתבונן
- שנצפה
- of
- כבוי
- הַצָעָה
- המיוחדות שלנו
- on
- ONE
- באינטרנט
- קמעונאי מקוון
- רק
- לפתוח
- קוד פתוח
- אופטימלי
- אופטימיזציה
- מטב
- אופטימיזציה
- מייעל
- מיטוב
- or
- להזמין
- מְקוֹרִי
- אחר
- שלנו
- הַחוּצָה
- תפוקה
- פלטים
- יותר
- מקיף
- סקירה
- שֶׁלוֹ
- זוגות
- זגוגית
- מקביל
- פרמטר
- פרמטרים
- פארטו
- חלק
- עבר
- נתיב
- חולה
- דפוסי
- לבצע
- ביצועים
- ביצעתי
- ביצוע
- מבצע
- הרשאות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- נקודה
- נקודות
- עמדות
- הודעה
- דיוק
- נבואה
- מנבא
- חיזוי
- העדפות
- מוּכָן
- תנאים מוקדמים
- להציג
- קוֹדֶם
- מנהל
- בעיה
- תהליך
- אוטומציה של תהליכים
- תהליכים
- תהליך
- המוצר
- פִּריוֹן
- כלי פרודוקטיביות
- מוּצָע
- ספק
- מספק
- מתן
- מושך
- מושך
- מטרה
- למטרות
- פיתון
- פיטורך
- שאלות ותשובות
- שאלה
- דַי
- אקראי
- רכס
- מהיר
- תעריפים
- חי
- ממשי
- הכרה
- להכיר
- זיהוי
- המלצה
- המלצות
- שיא
- מוקלט
- Red
- להפחית
- מופחת
- מפחית
- נסיגה
- קָשׁוּר
- מסיר
- הסרת
- דוחות לדוגמא
- נציגות
- לבקש
- בקשתי
- בקשות
- נדרש
- דרישות
- מִתאוֹשֵׁשׁ מַהֵר
- משאב
- משאבים
- בהתאמה
- תגובה
- תוצאות
- קִמעוֹנַאִי
- שמירה
- החזרות
- רכיבה
- הסיכון
- שׁוּרָה
- הפעלה
- רץ
- ריצה
- פועל
- s
- להקריב
- בעל חכמים
- SageMaker Inference
- שמור
- סולם
- מאזניים
- מדע
- מַדְעָן
- ציון
- תסריט
- חיפוש
- מנועי חיפוש
- חיפוש
- שְׁנִיָה
- סעיף
- לִרְאוֹת
- בחר
- נבחר
- עצמי
- לשלוח
- משפט
- רגש
- רצף
- שרות
- שירותים
- מושב
- סט
- סטים
- הצבה
- הופעות
- אותות
- באופן משמעותי
- פָּשׁוּט
- בו זמנית
- בו זמנית
- יחיד
- מידה
- קטן יותר
- So
- תוכנה
- פִּתָרוֹן
- פתרונות
- כמה
- מָקוֹר
- מֶרחָב
- תַפטִיר
- מיוחד
- מתמחה
- ספציפי
- במיוחד
- הוצאה
- לפצל
- התחלה
- התחלות
- מדינה
- סטטיסטיקה
- שלב
- צעדים
- אחסון
- מִבנִי
- מובנה
- סטודיו
- ניכר
- מוצלח
- בהצלחה
- כזה
- מַתְאִים
- מערכת
- סיכום
- מערכת
- מערכות
- T
- לקחת
- לוקח
- יעד
- המשימות
- משימות
- צוותי
- טכניקה
- טכניקות
- תבניות
- מונחים
- בדיקות
- בדיקות
- טֶקסט
- סיווג טקסט
- טקסטואלית
- מֵאֲשֶׁר
- זֶה
- השמיים
- שֶׁלָהֶם
- אז
- שם.
- לכן
- אלה
- זֶה
- שְׁלוֹשָׁה
- סף
- דרך
- זמן
- פִּי
- ל
- יַחַד
- אסימון
- לקח
- כלי
- כלים
- סחר
- מסחר
- רכבת
- מְאוּמָן
- הדרכה
- שנאי
- רוֹבּוֹטרִיקִים
- נָכוֹן
- לנסות
- שתיים
- סוג
- סוגים
- טיפוסי
- בדרך כלל
- בסופו של דבר
- תחת
- עוברת
- הבנה
- יחידות
- us
- להשתמש
- במקרה להשתמש
- מְשׁוּמָשׁ
- משתמש
- משתמשים
- שימושים
- באמצעות
- אימות
- ערך
- ערכים
- גרסה
- באמצעות
- וירטואלי
- לחזות
- vs
- רוצה
- היה
- we
- אינטרנט
- שירותי אינטרנט
- טוֹב
- מתי
- אם
- אשר
- בזמן
- מי
- רָחָב
- טווח רחב
- באופן נרחב
- רעיה
- ויקיפדיה
- יצטרך
- מוכן
- עם
- בתוך
- תיק עבודות
- זרימת עבודה
- עובד
- X
- שנים
- תְשׁוּאָה
- אתה
- זפירנט