Pandas היא ספריית קוד פתוח חזקה ונפוצה למניפולציה וניתוח נתונים באמצעות Python. אחת מתכונות המפתח שלו היא היכולת לקבץ נתונים באמצעות פונקציית groupby על ידי פיצול DataFrame לקבוצות המבוססות על עמודה אחת או יותר ולאחר מכן החלת פונקציות צבירה שונות על כל אחת מהן.

תמונה מתוך Unsplash
השמיים groupby הפונקציה חזקה להפליא, מכיוון שהיא מאפשרת לך לסכם ולנתח במהירות מערכי נתונים גדולים. לדוגמה, אתה יכול לקבץ מערך נתונים לפי עמודה מסוימת ולחשב את הממוצע, הסכום או הספירה של העמודות הנותרות עבור כל קבוצה. אתה יכול גם לקבץ לפי מספר עמודות כדי לקבל הבנה מפורטת יותר של הנתונים שלך. בנוסף, זה מאפשר לך ליישם פונקציות צבירה מותאמות אישית, שיכולות להיות כלי חזק מאוד למשימות ניתוח נתונים מורכבות.
במדריך זה תלמדו כיצד להשתמש בפונקציית groupby ב-Pandas כדי לקבץ סוגים שונים של נתונים ולבצע פעולות צבירה שונות. בסוף מדריך זה, אתה אמור להיות מסוגל להשתמש בפונקציה זו כדי לנתח ולסכם נתונים בדרכים שונות.
מושגים מופנמים כאשר מתרגלים היטב וזה מה שאנחנו הולכים לעשות בשלב הבא, כלומר להתנסות בפונקציית Pandas groupby. מומלץ להשתמש ב- a מחברת צדק עבור הדרכה זו מכיוון שאתה יכול לראות את הפלט בכל שלב.
צור נתונים לדוגמה
ייבא את הספריות הבאות:
- פנדות: כדי ליצור מסגרת נתונים ולהחיל קבוצה לפי
- אקראי - ליצירת נתונים אקראיים
- Pprint - להדפסת מילונים
import pandas as pd
import random
import pprint
לאחר מכן, נאתחל מסגרת נתונים ריקה ונמלא ערכים עבור כל עמודה כפי שמוצג להלן:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
טיפ בונוס - דרך נקייה יותר לבצע את אותה משימה היא על ידי יצירת מילון של כל המשתנים והערכים ובהמשך המרתו ל-dataframe.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
מסגרת הנתונים נראית כמו זו שמוצגת למטה. בעת הפעלת קוד זה, חלק מהערכים לא יתאימו מכיוון שאנו משתמשים במדגם אקראי.
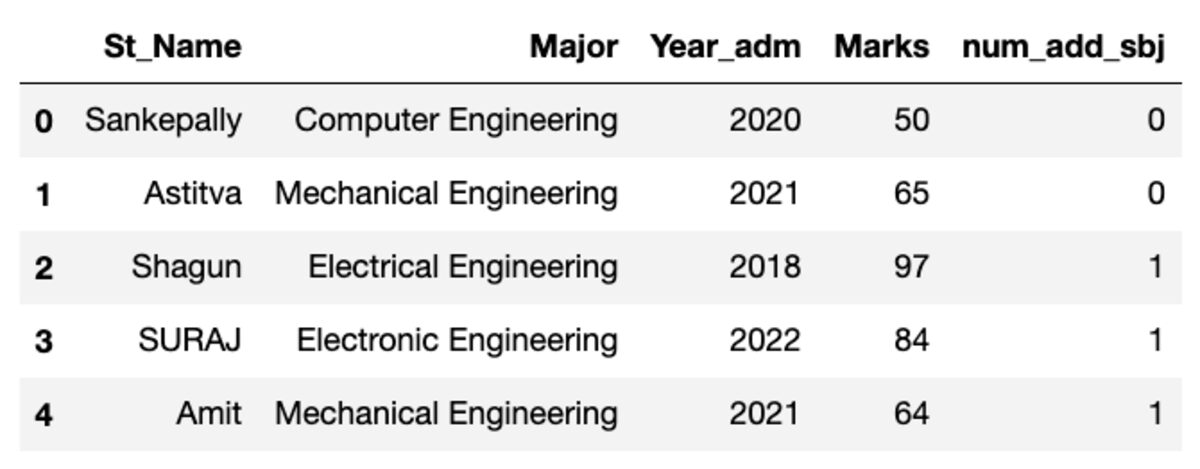
יצירת קבוצות
בואו נקבץ את הנתונים לפי הנושא "העיקרי" ונחיל את מסנן הקבוצה כדי לראות כמה רשומות נכנסות לקבוצה זו.
groups = df.groupby('Major')
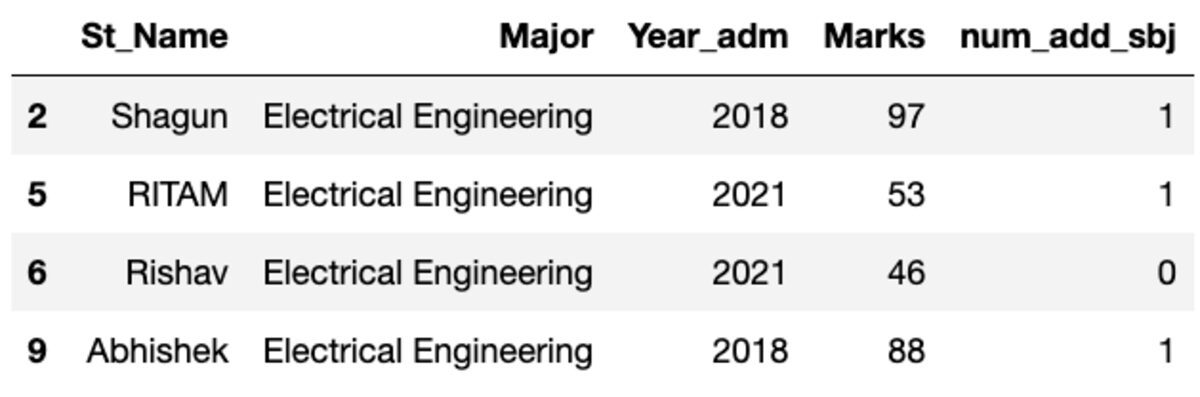
groups.get_group('Electrical Engineering')
אז, ארבעה סטודנטים שייכים למגמת הנדסת חשמל.
ניתן גם לקבץ לפי יותר מעמודה אחת (Major ו-num_add_sbj במקרה זה).
groups = df.groupby(['Major', 'num_add_sbj'])
שים לב שכל הפונקציות המצטברות שניתן להחיל על קבוצות עם עמודה אחת יכולות להיות מיושמות על קבוצות עם מספר עמודות. להמשך המדריך, בואו נתמקד בסוגים השונים של צבירה באמצעות עמודה אחת כדוגמה.
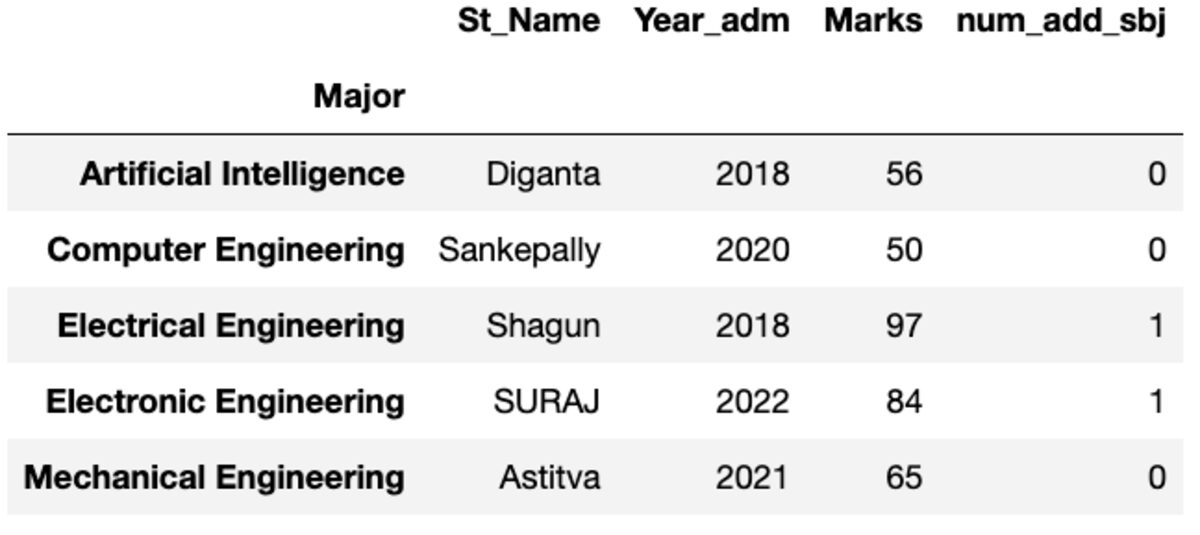
בואו ניצור קבוצות באמצעות groupby בעמודה "Major".
groups = df.groupby('Major')החלת פונקציות ישירות
נניח שאתה רוצה למצוא את ממוצע הציונים בכל מייג'ור. מה היית עושה?
- בחר בעמודת סימנים
- החל פונקציה ממוצעת
- החל פונקציית עגול לעיגול סימנים לשני מקומות עשרוניים (אופציונלי)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
מצטבר
דרך נוספת להשיג את אותה תוצאה היא באמצעות פונקציית צבירה כפי שמוצג להלן:
groups['Marks'].aggregate('mean').round(2)
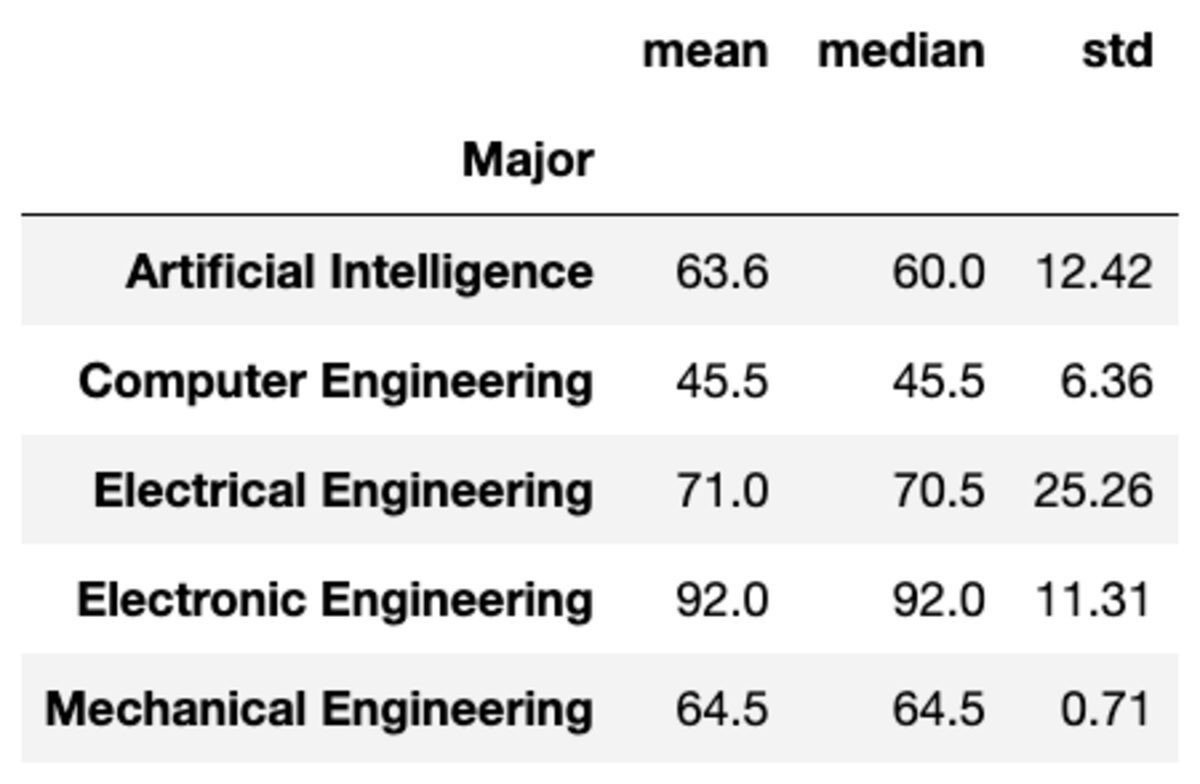
ניתן גם להחיל צבירות מרובות על הקבוצות על ידי העברת הפונקציות כרשימה של מחרוזות.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
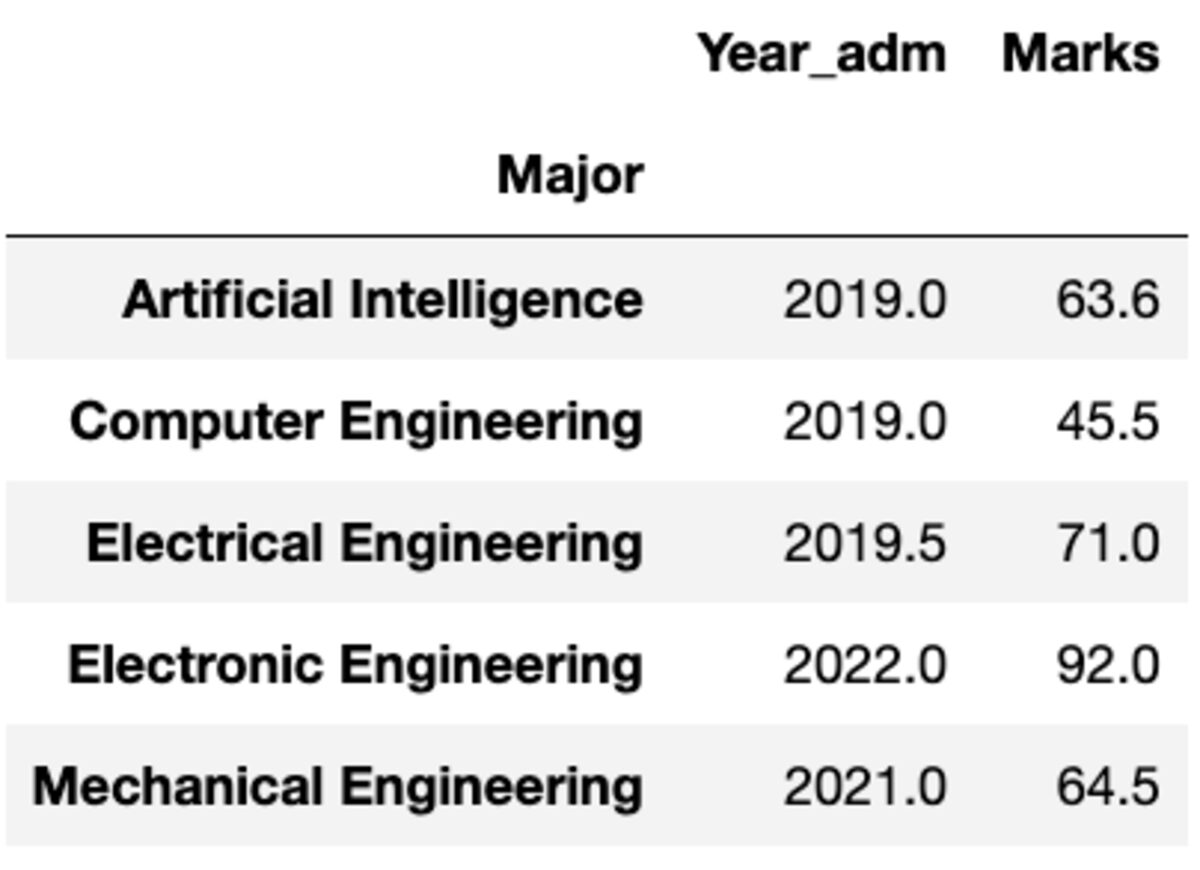
אבל מה אם אתה צריך להחיל פונקציה אחרת על עמודה אחרת. אל תדאג. אתה יכול גם לעשות זאת על ידי העברת צמד {עמודה: פונקציה}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
הופך
ייתכן מאוד שתצטרך לבצע טרנספורמציות מותאמות אישית לעמודה מסוימת שניתן להשיג בקלות באמצעות groupby(). בואו נגדיר סקלאר סטנדרטי דומה לזה הזמין במודול העיבוד המקדים של sklearn. ניתן להפוך את כל העמודות על ידי קריאה לשיטת הטרנספורמציה והעברת הפונקציה המותאמת אישית.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
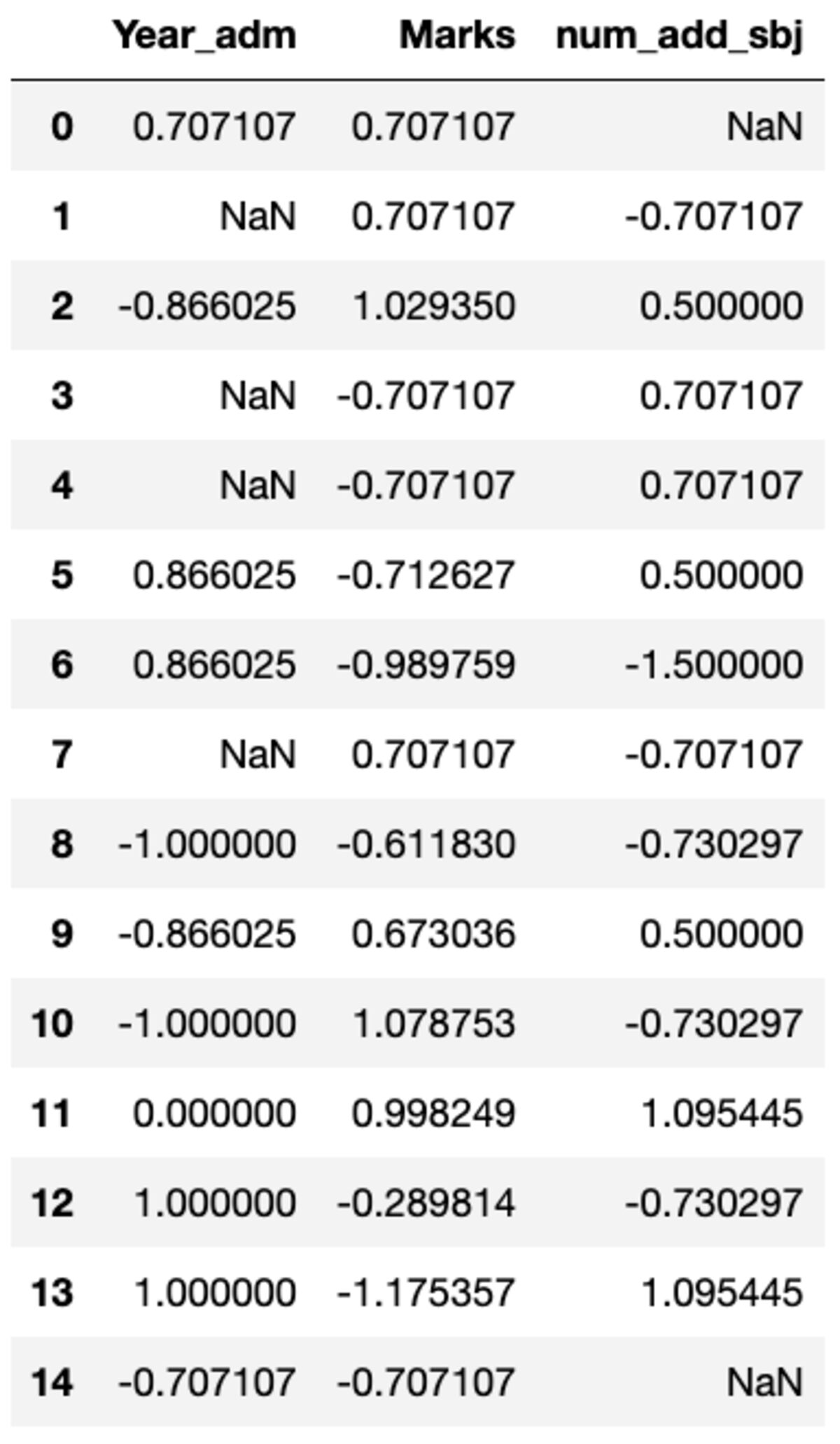
שים לב ש"NaN" מייצג קבוצות עם סטיית תקן אפס.
סינון
אולי תרצה לבדוק איזה "Major" מתפקד פחות, כלומר זה שבו "ציונים" של תלמיד ממוצע הם פחות מ-60. זה מחייב אותך להחיל שיטת סינון על קבוצות עם פונקציה בתוכה. הקוד שלהלן משתמש ב-a פונקצית למבדה כדי להשיג את התוצאות המסוננות.
groups.filter(lambda x: x['Marks'].mean() 60)

ראשון
זה נותן לך את המופע הראשון שלו ממוין לפי אינדקס.
groups.first()
לתאר
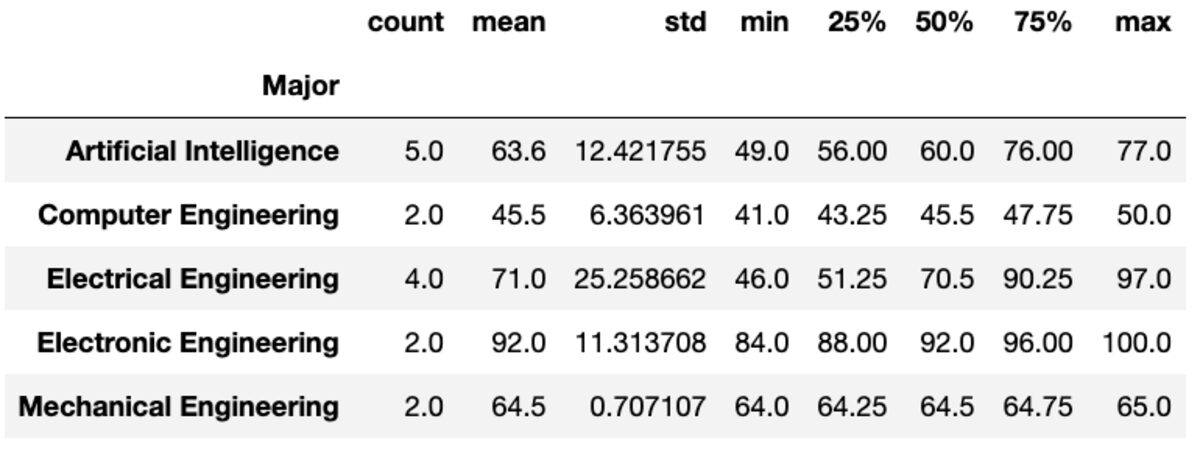
השיטה "תאר" מחזירה נתונים סטטיסטיים בסיסיים כמו ספירה, ממוצע, std, min, max וכו' עבור העמודות הנתונות.
groups['Marks'].describe()
מידה
גודל, כפי שהשם מרמז, מחזיר את הגודל של כל קבוצה מבחינת מספר הרשומות.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64הרוזן ונוניק
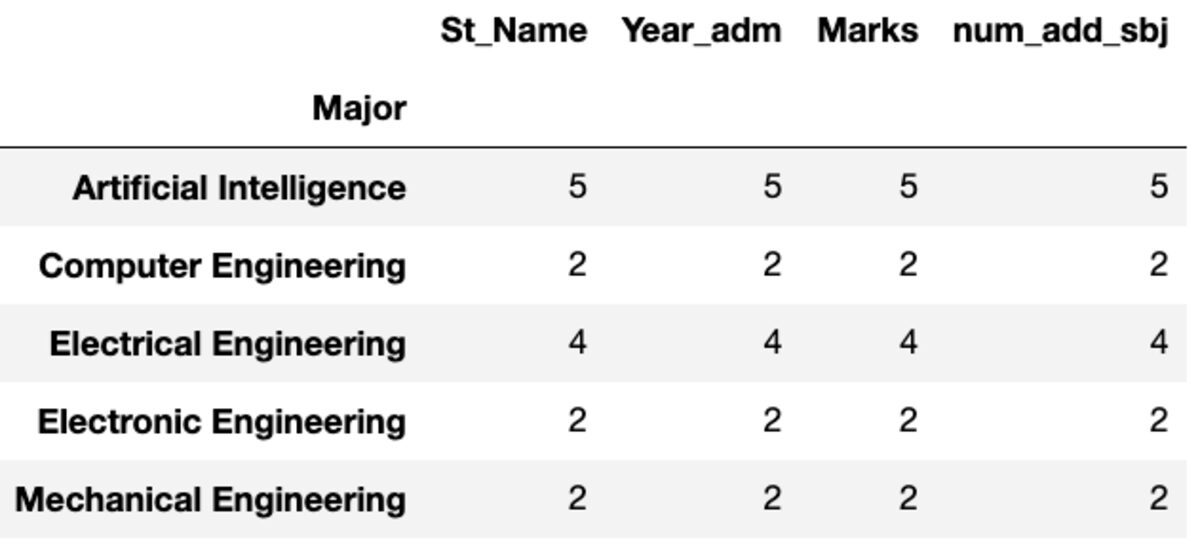
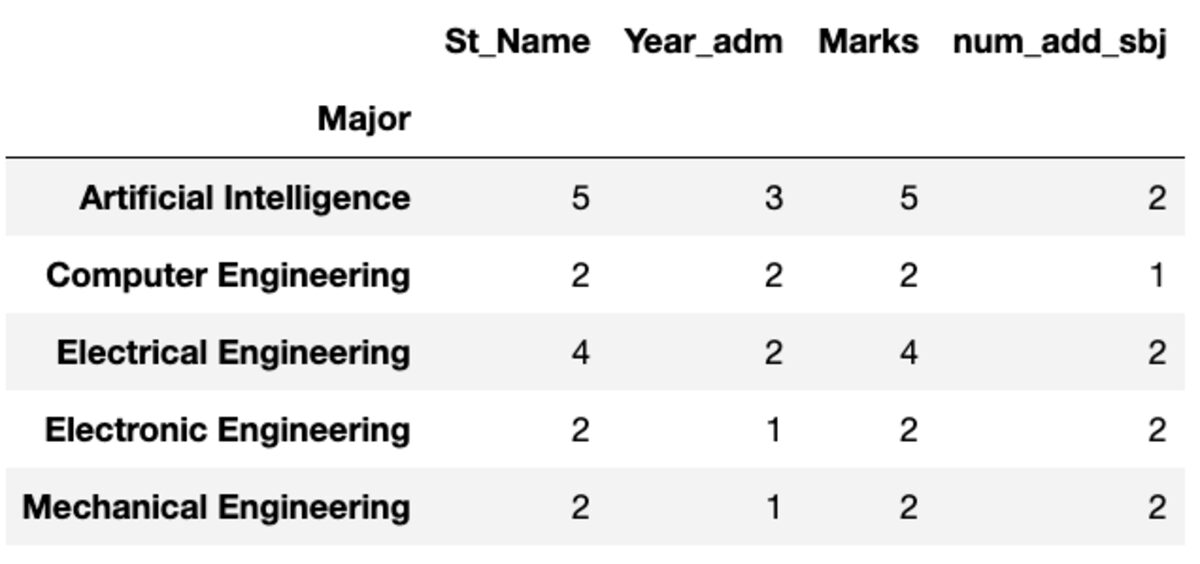
"ספירה" מחזירה את כל הערכים ואילו "Nunique" מחזירה רק את הערכים הייחודיים באותה קבוצה.
groups.count()
groups.nunique()
שינוי שם
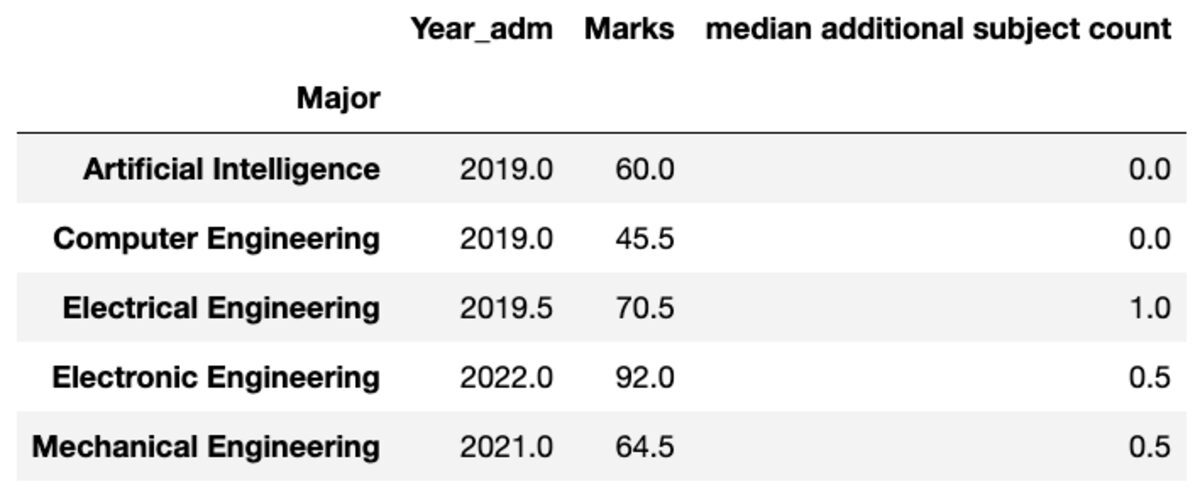
אתה יכול גם לשנות את שם העמודות המצטברות לפי העדפתך.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- היה ברור לגבי מטרת הקבוצה: האם אתה מנסה לקבץ את הנתונים לפי עמודה אחת כדי לקבל את הממוצע של עמודה אחרת? או שאתה מנסה לקבץ את הנתונים לפי מספר עמודות כדי לקבל את ספירת השורות בכל קבוצה?
- הבן את יצירת האינדקס של מסגרת הנתונים: הפונקציה groupby משתמשת באינדקס כדי לקבץ את הנתונים. אם ברצונך לקבץ את הנתונים לפי עמודה, ודא שהעמודה מוגדרת כאינדקס או שאתה יכול להשתמש ב-.set_index()
- השתמש בפונקציית הצבירה המתאימה: ניתן להשתמש בו עם פונקציות צבירה שונות כמו mean(), sum(), count(), min(), max()
- השתמש בפרמטר as_index: כאשר הוא מוגדר כ-False, פרמטר זה אומר לפנדות להשתמש בעמודות המקובצות כעמודות רגילות במקום כאינדקס.
אתה יכול גם להשתמש ב-groupby() בשילוב עם פונקציות פנדה אחרות כמו pivot_table(), crosstab() ו-cut() כדי לחלץ יותר תובנות מהנתונים שלך.
פונקציית groupby היא כלי רב עוצמה לניתוח ומניפולציה של נתונים מכיוון שהיא מאפשרת לך לקבץ שורות של נתונים על בסיס עמודה אחת או יותר ולאחר מכן לבצע חישובים מצטברים על הקבוצות. המדריך הדגים דרכים שונות להשתמש בפונקציית groupby בעזרת דוגמאות קוד. מקווה שזה מספק לך הבנה של האפשרויות השונות שמגיעות איתו וגם איך הם עוזרים בניתוח הנתונים.
וידי צ'וג הוא אסטרטג AI ומוביל טרנספורמציה דיגיטלית שעובד בצומת של מוצר, מדעים והנדסה לבניית מערכות למידת מכונה ניתנות להרחבה. היא מנהיגת חדשנות עטורת פרסים, סופרת ודוברת בינלאומית. היא במשימה לדמוקרטיזציה של למידת מכונה ולשבור את הז'רגון כדי שכולם יהיו חלק מהשינוי הזה.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- יכולת
- יכול
- להשיג
- הושג
- נוסף
- בנוסף
- - צבירה
- AI
- תעשיות
- מאפשר
- אנליזה
- לנתח
- ו
- אחר
- יישומית
- החל
- מריחה
- מתאים
- מלאכותי
- בינה מלאכותית
- מחבר
- זמין
- מְמוּצָע
- עטורת פרסים
- מבוסס
- בסיסי
- להלן
- ביוטכנולוגיה
- לשבור
- לִבנוֹת
- לחשב
- קוראים
- מקרה
- לבדוק
- ברור
- קוד
- טור
- עמודות
- איך
- מורכב
- המחשב
- הנדסת מחשבים
- לִיצוֹר
- יוצרים
- מנהג
- נתונים
- ניתוח נתונים
- מערכי נתונים
- דמוקרטיזציה
- מופגן
- סטייה
- אחר
- דיגיטלי
- טרנספורמציה דיגיטלית
- ישיר
- לא
- כל אחד
- בקלות
- יעילות
- הנדסת חשמל
- אֶלֶקטרוֹנִי
- הנדסה
- וכו '
- כולם
- דוגמה
- דוגמאות
- תמצית
- ליפול
- תכונות
- למלא
- לסנן
- ראשון
- להתמקד
- הבא
- מסגרת
- החל מ-
- פונקציה
- פונקציות
- ליצור
- לקבל
- נתן
- נותן
- הולך
- קְבוּצָה
- קבוצה
- ידות על
- לעזור
- לקוות
- איך
- איך
- HTML
- HTTPS
- לייבא
- in
- בצורה מדהימה
- מדד
- חדשנות
- תובנות
- למשל
- במקום
- מוֹדִיעִין
- ברמה בינלאומית
- הִצטַלְבוּת
- IT
- בז'רגון
- KDnuggets
- מפתח
- גָדוֹל
- מנהיג
- לִלמוֹד
- למידה
- ספריות
- סִפְרִיָה
- רשימה
- נראה
- מכונה
- למידת מכונה
- גדול
- לעשות
- מניפולציה
- רב
- להתאים
- מקסימום
- מֵכָנִי
- הנדסת מכונות
- בינוני
- שיטה
- משימה
- מודול
- יותר
- מספר
- שם
- שמות
- צורך
- הבא
- מספר
- ONE
- קוד פתוח
- תפעול
- אפשרויות
- אחר
- דובי פנדה
- פרמטר
- חלק
- מסוים
- חולף
- לבצע
- מקומות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- חזק
- קופונים להדפסה
- המוצר
- מספק
- מטרה
- פיתון
- מהירות
- אקראי
- מוּמלָץ
- רשום
- רגיל
- נותר
- מייצג
- דורש
- REST
- תוצאה
- תוצאות
- לַחֲזוֹר
- החזרות
- ריצ'רד
- עגול
- ריצה
- אותו
- להרחבה
- מדעים
- סט
- צריך
- הראה
- דומה
- יחיד
- מידה
- כמה
- רַמקוֹל
- ספציפי
- תֶקֶן
- סטטיסטיקה
- שלב
- תַכסִיסָן
- סטודנט
- סטודנטים
- נושא
- מציע
- לסכם
- מערכות
- המשימות
- משימות
- אומר
- מונחים
- השמיים
- טיפ
- ל
- כלי
- לשנות
- טרנספורמציה
- טרנספורמציות
- הדרכה
- סוגים
- הבנה
- ייחודי
- להשתמש
- ערכים
- שונים
- דרכים
- מה
- אשר
- יצטרך
- עובד
- היה
- X
- שנה
- זפירנט
- אפס






