תמונה מאת המחבר
ישנם קורסים ומשאבים רבים זמינים על למידת מכונה ומדעי נתונים, אך מעטים מאוד על הנדסת נתונים. זה מעלה כמה שאלות. האם זה תחום קשה? האם זה מציע שכר נמוך? האם זה לא נחשב מרגש כמו תפקידי טכנולוגיה אחרים? עם זאת, המציאות היא שחברות רבות מחפשות באופן פעיל כישרון בהנדסת נתונים ומציעות משכורות משמעותיות, שלעיתים עולות על $200,000 דולר. מהנדסי נתונים ממלאים תפקיד מכריע כארכיטקטים של פלטפורמות נתונים, מתכננים ובונים את המערכות הבסיסיות המאפשרות למדעני נתונים ומומחי למידת מכונה לתפקד ביעילות.
כדי להתמודד עם פער זה בתעשייה, DataTalkClub הציגה Bootcamp טרנספורמטיבי וחינמי, "Zoomcamp הנדסת נתונים". קורס זה נועד להעצים מתחילים או מקצוענים המעוניינים להחליף קריירה, עם מיומנויות חיוניות וניסיון מעשי בהנדסת נתונים.
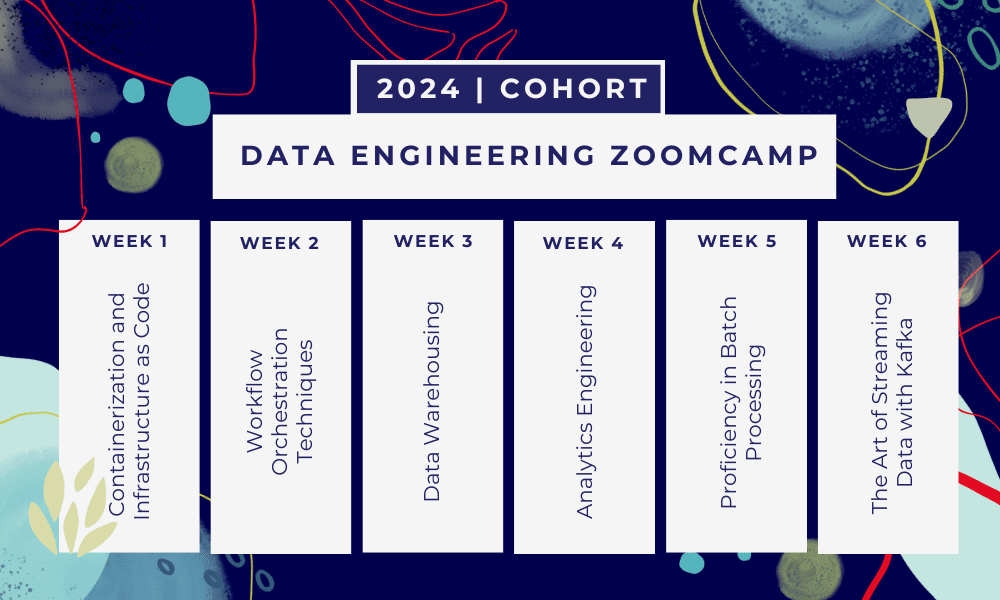
זה Bootcamp של 6 שבועות שבו תלמדו באמצעות קורסים מרובים, חומרי קריאה, סדנאות ופרויקטים. בסוף כל מודול, תקבלו שיעורי בית כדי לתרגל את מה שלמדת.
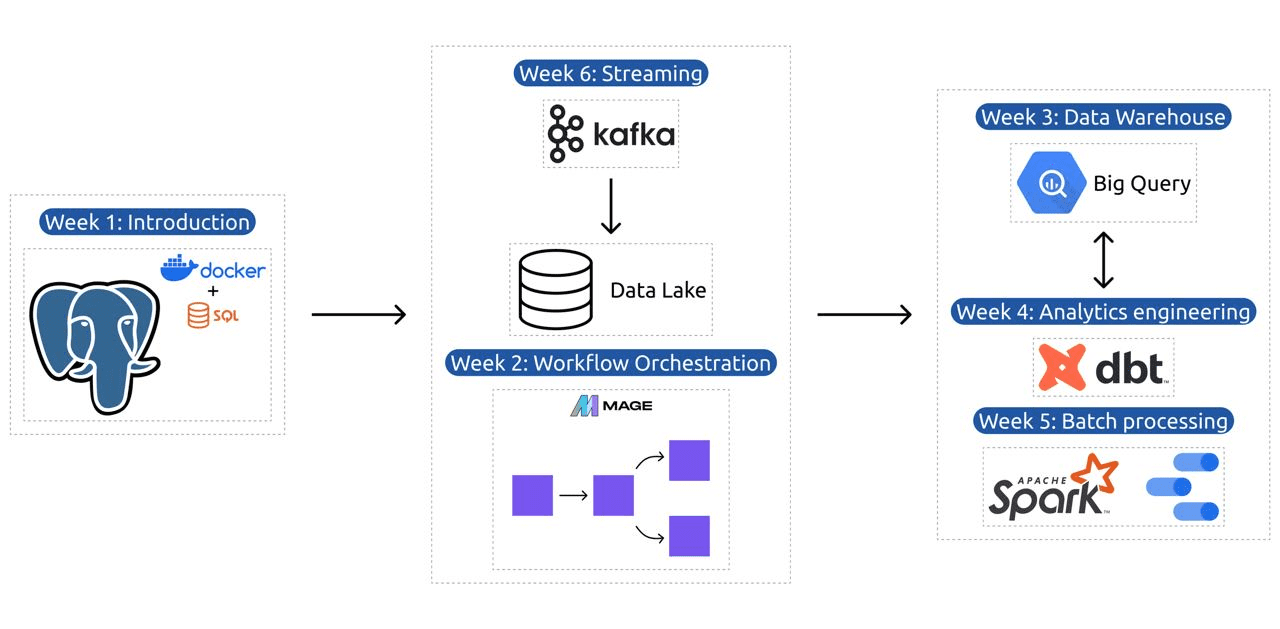
- שבוע 1: מבוא להגדרות GCP, Docker, Postgres, Terraform וסביבה.
- שבוע 2: תזמור זרימת עבודה עם Mage.
- שבוע 3: אחסון נתונים עם BigQuery ולמידת מכונה עם BigQuery.
- שבוע 4: מהנדס אנליטי עם dbt, Google Data Studio ו- Metabase.
- שבוע 5: עיבוד אצווה עם Spark.
- שבוע 6: סטרימינג עם קפקא.
תמונה מתוך DataTalksClub/data-engineering-zoomcamp
הסילבוס מכיל 6 מודולים, 2 סדנאות ופרויקט המכסה את כל הדרוש כדי להפוך למהנדס נתונים מקצועי.
מודול 1: שליטה במכולות ובתשתית כקוד
במודול זה תלמדו על Docker ו-Postgres, החל מהיסודות ותתקדם דרך הדרכות מפורטות על יצירת צינורות נתונים, הפעלת Postgres עם Docker ועוד.
המודול מכסה גם כלים חיוניים כמו pgAdmin, Docker-compose ו-SQL נושאי רענון, עם תוכן אופציונלי על רשת Docker והדרכה מיוחדת עבור משתמשי Linux תת-מערכת של Windows. בסופו של דבר, הקורס מציג לך את GCP ו- Terraform, ומספק הבנה הוליסטית של קונטיינריזציה ותשתית כקוד, חיוני לסביבות מודרניות מבוססות ענן.
מודול 2: טכניקות תזמורת זרימת עבודה
המודול מציע חקר מעמיק של Mage, מסגרת היברידית חדשנית בקוד פתוח לטרנספורמציה ואינטגרציה של נתונים. מודול זה מתחיל עם היסודות של תזמור זרימת עבודה, מתקדם לתרגילים מעשיים עם Mage, כולל הגדרתו באמצעות Docker ובניית צינורות ETL מ-API ל-Postgres ו-Google Cloud Storage (GCS), ולאחר מכן ל-BigQuery.
השילוב של סרטונים, משאבים ומשימות מעשיות של המודול מבטיח חווית למידה מקיפה, המציידת את הלומדים במיומנויות לנהל זרימות עבודה מתוחכמות של נתונים באמצעות Mage.
סדנה 1: אסטרטגיות להטמעת נתונים
בסדנה הראשונה תשלוט בבניית צינורות קליטת נתונים יעילים. הסדנה מתמקדת במיומנויות חיוניות כמו חילוץ נתונים ממשקי API וקבצים, נרמול וטעינת נתונים וטכניקות טעינה מצטברות. לאחר השלמת סדנה זו, תוכל ליצור צינורות נתונים יעילים כמו מהנדס נתונים בכיר.
מודול 3: אחסון נתונים
המודול הוא חקירה מעמיקה של אחסון וניתוח נתונים, תוך התמקדות באחסון נתונים באמצעות BigQuery. הוא מכסה מושגי מפתח כמו חלוקה למחיצות ואשכולות, וצולל לשיטות העבודה המומלצות של BigQuery. המודול מתקדם לנושאים מתקדמים, במיוחד השילוב של Machine Learning (ML) עם BigQuery, הדגשת השימוש ב-SQL עבור ML, ומתן משאבים על כוונון היפרפרמטרים, עיבוד מקדים של תכונות ופריסה של מודלים.
מודול 4: הנדסת אנליטיקה
מודול הנדסת האנליטיקה מתמקד בבניית פרויקט באמצעות dbt (כלי לבניית נתונים) עם מחסן נתונים קיים, או BigQuery או PostgreSQL.
המודול מכסה הגדרת dbt הן בסביבות ענן והן בסביבות מקומיות, תוך הצגת מושגי הנדסה אנליטית, ETL לעומת ELT, ומידול נתונים. זה מכסה גם תכונות dbt מתקדמות כמו דגמים מצטברים, תגים, ווים ותצלומים.
בסופו של דבר, המודול מציג טכניקות להמחשת נתונים שעברו טרנספורמציה באמצעות כלים כמו Google Data Studio ו- Metabase, והוא מספק משאבים לפתרון בעיות וטעינת נתונים יעילה.
מודול 5: מיומנות בעיבוד אצווה
מודול זה מכסה עיבוד אצווה באמצעות Apache Spark, החל בהיכרות לעיבוד אצווה ו-Spark, יחד עם הוראות התקנה עבור Windows, Linux ו- MacOS.
זה כולל חקירת Spark SQL ו-DataFrames, הכנת נתונים, ביצוע פעולות SQL והבנת התוכן הפנימי של Spark. לבסוף, הוא מסתיים בהפעלת Spark בענן ושילוב Spark עם BigQuery.
מודול 6: אומנות הזרמת הנתונים עם קפקא
המודול מתחיל עם היכרות עם מושגי עיבוד זרם, ולאחר מכן חקירה מעמיקה של קפקא, כולל יסודותיו, אינטגרציה עם Confluent Cloud, ויישומים מעשיים המערבים יצרנים וצרכנים.
המודול מכסה גם את התצורה והזרמים של Kafka, תוך התייחסות לנושאים כמו חיבורי זרמים, בדיקות, חלונות ושימוש ב-Kafka ksqldb & Connect. בנוסף, הוא מרחיב את המיקוד שלו לסביבות Python ו-JVM, כולל Faust לעיבוד זרם Python, Pyspark – Structured Streaming ודוגמאות Scala עבור Kafka Streams.
סדנה 2: עיבוד זרם עם SQL
תלמדו לעבד ולנהל נתונים סטרימינג עם RisingWave, המספקת פתרון חסכוני עם חוויה בסגנון PostgreSQL כדי להעצים את יישומי עיבוד הזרם שלכם.
פרויקט: יישום הנדסת נתונים בעולם האמיתי
מטרת הפרויקט היא ליישם את כל המושגים שלמדנו בקורס זה כדי לבנות צינור נתונים מקצה לקצה. אתה תיצור ליצירת לוח מחוונים המורכב משני אריחים על ידי בחירת מערך נתונים, בניית צינור לעיבוד הנתונים ואחסוןם באגם נתונים, בניית צינור להעברת הנתונים המעובדים מאגם הנתונים למחסן נתונים, טרנספורמציה הנתונים במחסן הנתונים והכנתם לדשבורד, ולבסוף בניית דשבורד להצגת הנתונים בצורה ויזואלית.
2024 פרטי קבוצה
- הַרשָׁמָה: הירשם עכשיו
- תאריך התחלה: 15 בינואר 2024, בשעה 17:00 CET
- למידה בקצב עצמי עם תמיכה מודרכת
- תיקיית Cohort עם שיעורי בית ומועדים
- אינטרקטיווי קהילת סלאק ללמידת עמיתים
תנאים מוקדמים
- כישורי קידוד ושורת פקודה בסיסיים
- יסוד ב-SQL
- פייתון: מועיל אך לא חובה
מדריכים מומחים מובילים את המסע שלך
- אנקוש חאנה
- ויקטוריה פרז מולה
- אלכסיי גריגורב
- מאט פאלמר
- לואיס אוליביירה
- מייקל סנדלר
הצטרף לקבוצת 2024 שלנו והתחל ללמוד עם קהילה מדהימה של הנדסת נתונים. עם הכשרה בהנחיית מומחה, ניסיון מעשי ותכנית לימודים המותאמת לצרכי התעשייה, בוטקאמפ זה לא רק מצייד אותך בכישורים הדרושים אלא גם ממצב אותך בחזית מסלול קריירה משתלם ומבוקש. הירשמו עוד היום והפכו את השאיפות שלכם למציאות!
עביד עלי אוואן (@1abidaliawan) הוא איש מקצוע מוסמך של מדען נתונים שאוהב לבנות מודלים של למידת מכונה. נכון לעכשיו, הוא מתמקד ביצירת תוכן וכתיבת בלוגים טכניים על למידת מכונה וטכנולוגיות מדעי נתונים. עביד הוא בעל תואר שני בניהול טכנולוגיה ותואר ראשון בהנדסת טלקומוניקציה. החזון שלו הוא לבנות מוצר בינה מלאכותית באמצעות רשת עצבית גרפית עבור תלמידים הנאבקים במחלות נפש.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :יש ל
- :הוא
- :לֹא
- :איפה
- $ למעלה
- 000
- 1
- 15%
- 17
- 2024
- a
- יכול
- אודות
- באופן פעיל
- בנוסף
- פְּנִיָה
- מתקדם
- מתקדם
- לאחר
- AI
- תעשיות
- לאורך
- גם
- מדהים
- an
- אנליזה
- אנליטית
- ניתוח
- ו
- תשתיות
- אַפָּשׁ
- אפאצ 'י ספארק
- API
- ממשקי API
- יישומים
- אדריכלים
- ARE
- אמנות
- AS
- At
- זמין
- יסודות
- BE
- להיות
- התהוות
- למתחילים
- מועיל
- הטוב ביותר
- שיטות עבודה מומלצות
- bigquery
- להתמזג
- בלוגים
- שניהם
- לִבנוֹת
- בִּניָן
- אבל
- by
- קריירה
- קריירות
- מוסמך
- ענן
- אחסון ענן
- קיבוץ
- קוד
- סִמוּל
- עוקבים
- קהילה
- חברות
- מַשׁלִים
- מַקִיף
- מושגים
- מסכם
- תְצוּרָה
- צומת
- לְחַבֵּר
- נחשב
- מורכב
- לבנות
- צרכנים
- מכיל
- תוכן
- יצירת תוכן
- קורס
- קורסים
- מכסה
- לִיצוֹר
- יוצרים
- יצירה
- מכריע
- כיום
- תכנית לימודים
- לוח מחוונים
- נתונים
- מהנדס נתונים
- אגם דאטה
- מדע נתונים
- מדען נתונים
- אחסון נתונים
- מחסן נתונים
- תַאֲרִיך
- תואר
- פריסה
- מעוצב
- תכנון
- מְפוֹרָט
- קשה
- סַוָר
- כל אחד
- יעילות
- יעיל
- או
- להסמיך
- לאפשר
- סוף
- מקצה לקצה
- מהנדס
- הנדסה
- מהנדסים
- להירשם
- מבטיח
- סביבה
- סביבות
- חיוני
- Ether (ETH)
- הכל
- דוגמאות
- מרגש
- קיימים
- ניסיון
- מומחים
- חקירה
- היכרות
- משתרע
- מאפיין
- תכונות
- משתתפים
- מעטים
- שדה
- קבצים
- בסופו של דבר
- ראשון
- להתמקד
- מתמקד
- התמקדות
- בעקבות
- בעד
- בחזית
- יסוד
- מסגרת
- חופשי
- החל מ-
- פונקציה
- יסודות
- פער
- GCP
- נתן
- Google Cloud
- גרף
- גרף רשת עצבית
- מוּדרָך
- ידות על
- יש
- he
- הדגשה
- שֶׁלוֹ
- מחזיק
- הוליסטית
- שיעורי בית
- הוקס
- אולם
- HTTPS
- היברידי
- כוונון היפר-פרמטר
- מחלה
- ליישם
- in
- מעמיק
- כולל
- כולל
- מצטבר
- תעשייה
- תשתית
- חדשני
- התקנה
- הוראות
- שילוב
- השתלבות
- אל תוך
- הציג
- מציג
- החדרה
- מבוא
- היכרות
- מעורב
- IT
- שֶׁלָה
- יָנוּאָר
- מצטרף
- קפקא
- KDnuggets
- מפתח
- אגם
- מוביל
- לִלמוֹד
- למד
- לומדים
- למידה
- כמו
- קו
- לינקדין
- לינוקס
- טוען
- מקומי
- הסתכלות
- אוהב
- נמוך
- משתלם
- מכונה
- למידת מכונה
- MacOS
- לנהל
- ניהול
- מנדטורי
- רב
- אב
- מאסטרינג
- חומרים
- נפשי
- מחלת נפש
- ML
- מודל
- דוגמנות
- מודלים
- מודרני
- מודול
- מודולים
- יותר
- מספר
- הכרחי
- צורך
- נחוץ
- צרכי
- רשת
- רשתות
- עצביים
- רשת עצבית
- מטרה
- of
- הצעה
- המיוחדות שלנו
- on
- רק
- קוד פתוח
- תפעול
- or
- תזמור
- אחר
- שלנו
- עולה רגל
- במיוחד
- נתיב
- תשלום
- להציץ
- ביצוע
- צינור
- פלטפורמות
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- לְשַׂחֵק
- עמדות
- פוסטגרסל
- מעשי
- יישומים מעשיים
- תרגול
- פרקטיקות
- העריכה
- להציג
- תהליך
- מעובד
- תהליך
- מפיק
- המוצר
- מקצועי
- אנשי מקצוע
- מתקדם
- פּרוֹיֶקט
- פרויקטים
- מספק
- מתן
- פיתון
- שאלות
- מעלה
- קריאה
- עולם אמיתי
- מציאות
- משאבים
- תפקיד
- תפקידים
- ריצה
- s
- משכורות
- סולם
- מדע
- מַדְעָן
- מדענים
- מחפשים
- בחירה
- לחצני מצוקה לפנסיונרים
- הצבה
- התקנה
- מיומנויות
- רָפוּי
- פִּתָרוֹן
- כמה
- לפעמים
- מתוחכם
- לעורר
- מיוחד
- SQL
- התחלה
- החל
- אחסון
- זרם
- נהירה
- זרמים
- מובנה
- נאבק
- סטודנטים
- סטודיו
- ניכר
- כזה
- תמיכה
- מתג
- מערכות
- מותאם
- כִּשָׁרוֹן
- משימות
- טק
- טכני
- טכניקות
- טכנולוגיות
- טכנולוגיה
- טֵלֵקוֹמוּנִיקַציָה
- Terraform
- בדיקות
- זֶה
- השמיים
- היסודות
- אז
- זֶה
- דרך
- ל
- היום
- כלי
- כלים
- נושאים
- הדרכה
- מעביר
- לשנות
- טרנספורמציה
- טרנספורמטיבית
- טרנספורמציה
- הפיכה
- הדרכות
- שתיים
- הבנה
- ש״ח
- להשתמש
- משתמשים
- באמצעות
- Ve
- מאוד
- באמצעות
- וידאו
- חזון
- מבחינה ויזואלית
- vs
- מחסן
- אחסון
- we
- מה
- אשר
- מי
- יצטרך
- חלונות
- עם
- זרימת עבודה
- זרימות עבודה
- סדנה
- סדנות
- כתיבה
- אתה
- זפירנט










