תמונה מאת המחבר
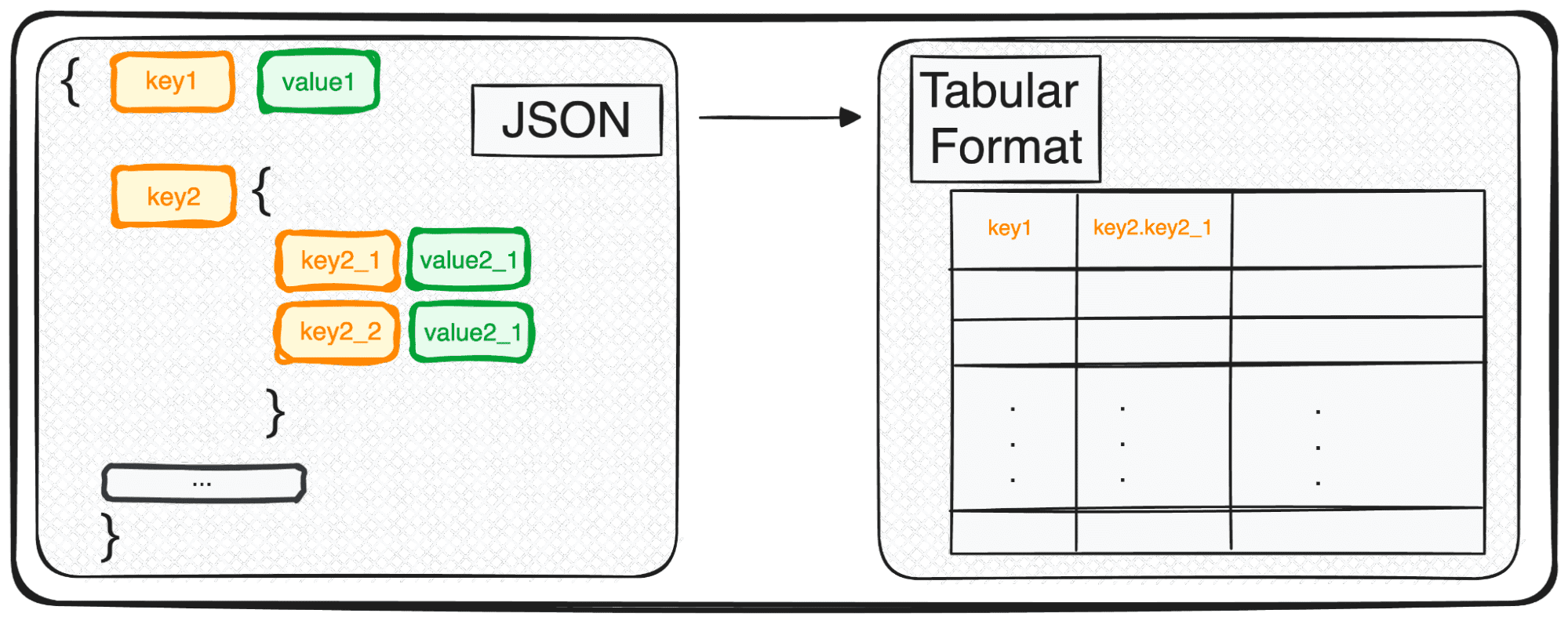
לצלול לתוך עולם מדעי הנתונים ולמידת מכונה, אחת המיומנויות הבסיסיות שתתקל בהן היא אומנות קריאת הנתונים. אם כבר יש לך ניסיון עם זה, אתה בוודאי מכיר את JSON (JavaScript Object Notation) - פורמט פופולרי לאחסון והחלפת נתונים.
תחשוב על איך מסדי נתונים של NoSQL כמו MongoDB אוהבים לאחסן נתונים ב-JSON, או איך ממשקי API של REST מגיבים לעתים קרובות באותו פורמט.
עם זאת, JSON, למרות שהוא מושלם לאחסון והחלפה, לא לגמרי מוכן לניתוח מעמיק בצורתו הגולמית. זה המקום שבו אנו הופכים אותו למשהו ידידותי יותר מבחינה אנליטית - פורמט טבלאי.
אז, בין אם אתה מתמודד עם אובייקט JSON בודד או עם מערך מענג שלהם, במונחים של Python, אתה בעצם מטפל ב-dict או ברשימת dicts.
בואו נחקור יחד כיצד הטרנספורמציה הזו מתפתחת, מה שהופך את הנתונים שלנו להבשילים לניתוח ????
היום אסביר פקודת קסם המאפשרת לנו לנתח בקלות כל JSON לפורמט טבלאי תוך שניות.
וזה... pd.json_normalize()
אז בואו נראה איך זה עובד עם סוגים שונים של JSONs.
הסוג הראשון של JSON שאנחנו יכולים לעבוד איתו הוא JSONs חד-רמה עם כמה מפתחות וערכים. אנו מגדירים את ה-JSONs הפשוטים הראשונים שלנו באופן הבא:
קוד לפי מחבר
אז בואו נדמה את הצורך לעבוד עם ה-JSON האלה. כולנו יודעים שאין הרבה מה לעשות בפורמט ה-JSON שלהם. אנחנו צריכים להפוך את ה-JSONs האלה לפורמט קריא וניתן לשינוי... כלומר Pandas DataFrames!
1.1 התמודדות עם מבני JSON פשוטים
ראשית, עלינו לייבא את ספריית הפנדות ולאחר מכן נוכל להשתמש בפקודה pd.json_normalize(), באופן הבא:
import pandas as pd
pd.json_normalize(json_string)
על ידי החלת פקודה זו על JSON עם רשומה בודדת, נקבל את הטבלה הבסיסית ביותר. עם זאת, כאשר הנתונים שלנו קצת יותר מורכבים ומציגים רשימה של JSONs, אנו עדיין יכולים להשתמש באותה פקודה ללא סיבוכים נוספים והפלט יתאים לטבלה עם מספר רשומות.

תמונה מאת המחבר
קל... נכון?
השאלה הטבעית הבאה היא מה קורה כאשר חלק מהערכים חסרים.
1.2 התמודדות עם ערכי אפס
תארו לעצמכם שחלק מהערכים אינם מעודכנים, כמו למשל, רשומת ההכנסה של דוד חסרה. בעת הפיכת ה-JSON שלנו למסגרת נתונים פשוטה של פנדה, הערך המתאים יופיע בתור NaN.
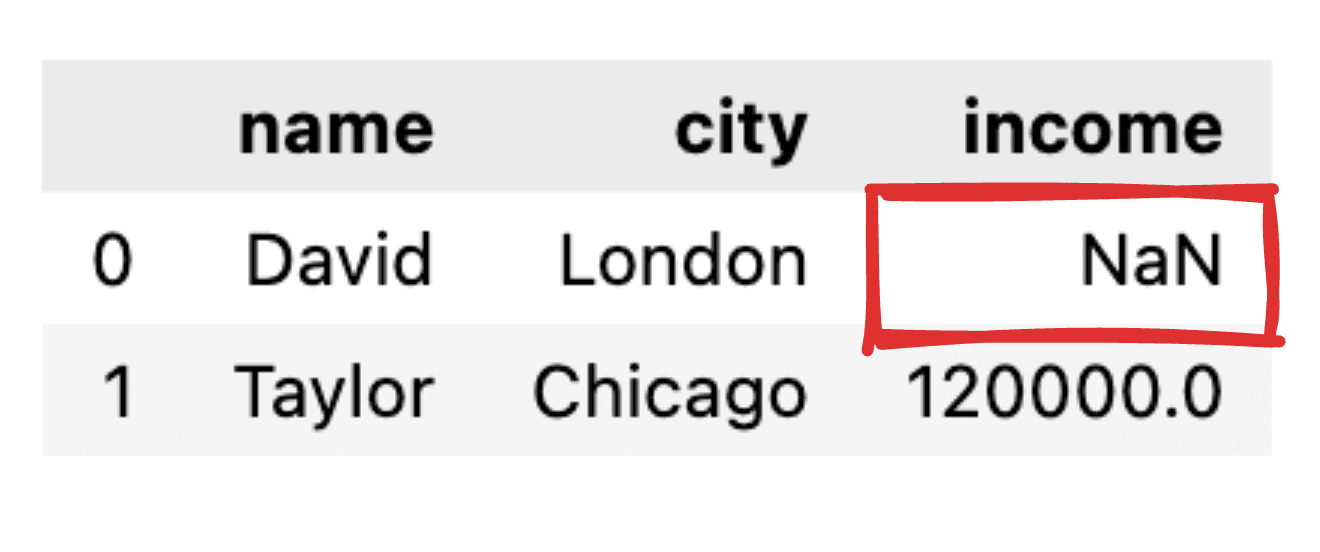
תמונה מאת המחבר
ומה לגבי אם אני רוצה לקבל רק חלק מהשדות?
1.3 בחירת עמודות עניין בלבד
במקרה שאנחנו רק רוצים להפוך כמה שדות ספציפיים ל-PandaFrame טבלאי, הפקודה json_normalize() לא מאפשרת לנו לבחור אילו שדות להמיר.
לכן, יש לבצע עיבוד מקדים קטן של ה-JSON שבו אנו מסננים רק את העמודות המעניינות.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
אז בואו נעבור למבנה JSON מתקדם יותר.
כאשר אנו מתמודדים עם JSONs מרובי רמות אנו מוצאים את עצמנו עם JSONs מקוננים בתוך רמות שונות. ההליך זהה לקודם, אבל במקרה זה, אנחנו יכולים לבחור כמה רמות אנחנו רוצים לשנות. כברירת מחדל, הפקודה תמיד תרחיב את כל הרמות ותיצור עמודות חדשות המכילות את השם המשורשר של כל הרמות המקוננות.
אז אם ננרמל את ה-JSONs הבאים.
קוד לפי מחבר
נקבל את הטבלה הבאה עם 3 עמודות תחת כישורי השטח:
- skills.python
- מיומנויות.SQL
- מיומנויות.GCP
ו-4 עמודות מתחת לתפקידי השדה
- תפקידים.מנהל פרויקט
- תפקידים.מהנדס נתונים
- roles.data scientist
- תפקידים. מנתח נתונים

תמונה מאת המחבר
עם זאת, דמיינו שאנחנו רק רוצים לשנות את הרמה העליונה שלנו. נוכל לעשות זאת על ידי הגדרה ספציפית של הפרמטר max_level ל-0 (ה-max_level שאנו רוצים להרחיב).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
הערכים הממתינים יישמרו בתוך JSONs בתוך ה-Pandas DataFrame שלנו.
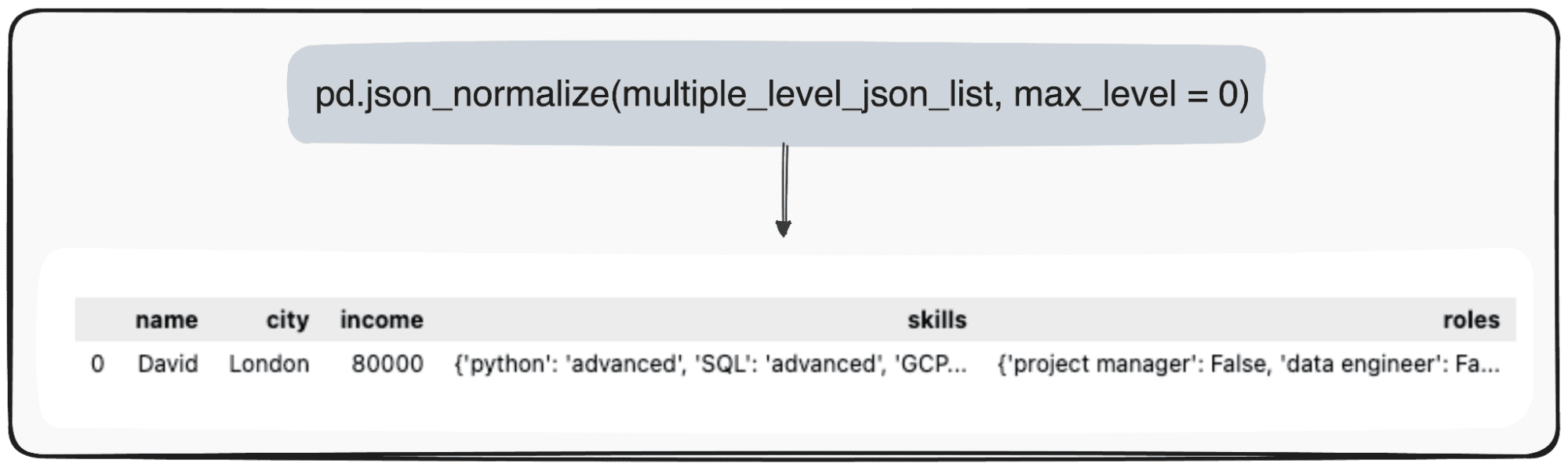
תמונה מאת המחבר
המקרה האחרון שנוכל למצוא הוא רשימה מקוננת בתוך שדה JSON. אז תחילה אנו מגדירים את ה-JSONs שלנו לשימוש.
קוד לפי מחבר
אנחנו יכולים לנהל את הנתונים האלה ביעילות באמצעות Pandas ב-Python. הפונקציה pd.json_normalize() שימושית במיוחד בהקשר זה. זה יכול לשטח את נתוני ה-JSON, כולל הרשימה המקוננת, לפורמט מובנה המתאים לניתוח. כאשר פונקציה זו מוחלת על נתוני ה-JSON שלנו, היא מייצרת טבלה מנורמלת המשלבת את הרשימה המקוננת כחלק מהשדות שלה.
יתרה מכך, Pandas מציעה את היכולת לחדד עוד יותר את התהליך הזה. על ידי שימוש בפרמטר record_path ב-pd.json_normalize(), נוכל לכוון את הפונקציה לנרמל באופן ספציפי את הרשימה המקוננת.
פעולה זו מביאה לטבלה ייעודית אך ורק לתוכן הרשימה. כברירת מחדל, תהליך זה יפתח רק את האלמנטים ברשימה. עם זאת, כדי להעשיר טבלה זו בהקשר נוסף, כגון שמירה על מזהה משויך לכל רשומה, אנו יכולים להשתמש בפרמטר המטא.

תמונה מאת המחבר
לסיכום, הפיכת נתוני JSON לקבצי CSV באמצעות ספריית Pandas של Python קלה ויעילה.
JSON הוא עדיין הפורמט הנפוץ ביותר באחסון והחלפת נתונים מודרניים, בעיקר במסדי נתונים של NoSQL וממשקי API של REST. עם זאת, הוא מציג כמה אתגרים אנליטיים חשובים בעת התמודדות עם נתונים בפורמט הגולמי שלו.
התפקיד המרכזי של pd.json_normalize() של Pandas מופיע כדרך מצוינת לטפל בפורמטים כאלה ולהמיר את הנתונים שלנו ל-Pandas DataFrame.
אני מקווה שהמדריך הזה היה שימושי, ובפעם הבאה שאתה עוסק ב-JSON, תוכל לעשות זאת בצורה יעילה יותר.
אתה יכול ללכת לבדוק את מחברת Jupyter המקבילה ב- בעקבות ריפו של GitHub.
ג'וזף פרר הוא מהנדס אנליטיקה מברצלונה. הוא סיים לימודי הנדסת פיזיקה וכיום הוא עובד בתחום מדעי הנתונים המיושם לניידות אנושית. הוא יוצר תוכן במשרה חלקית המתמקד במדעי הנתונים והטכנולוגיה. אתה יכול לפנות אליו ב לינקדין, טויטר or בינוני.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- PlatoData.Network Vertical Generative Ai. העצים את עצמך. גישה כאן.
- PlatoAiStream. Web3 Intelligence. הידע מוגבר. גישה כאן.
- PlatoESG. פחמן, קלינטק, אנרגיה, סביבה, שמש, ניהול פסולת. גישה כאן.
- PlatoHealth. מודיעין ביוטכנולוגיה וניסויים קליניים. גישה כאן.
- מקור: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :הוא
- :לֹא
- :איפה
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- אודות
- פעולה
- נוסף
- מתקדם
- תעשיות
- להתיר
- מאפשר
- כְּבָר
- תמיד
- an
- אנליזה
- מנתח
- אנליטי
- ניתוח
- ו
- כל
- ממשקי API
- לְהוֹפִיעַ
- יישומית
- מריחה
- ARE
- מערך
- אמנות
- AS
- המשויך
- ברצלונה
- בסיסי
- BE
- לפני
- קצת
- שניהם
- אבל
- by
- CAN
- יכולת
- מקרה
- האתגרים
- לבדוק
- בחרו
- עִיר
- עמודות
- Common
- מורכב
- סיבוכים
- צור קשר
- תוכן
- תוכן
- הקשר
- להמיר
- המרת
- גפרורים
- תוֹאֵם
- יוצר
- כיום
- נתונים
- אנליסט מידע
- מהנדס נתונים
- מדע נתונים
- מדען נתונים
- אחסון נתונים
- מאגרי מידע
- דוד
- התמודדות
- מוקדש
- בְּרִירַת מֶחדָל
- לְהַגדִיר
- הגדרה
- מענג
- DICT
- אחר
- ישיר
- do
- עושה
- כל אחד
- בקלות
- קל
- אפקטיבי
- יעילות
- אלמנטים
- מתגלה
- פְּגִישָׁה
- מהנדס
- הנדסה
- להעשיר
- למעשה
- חליפין
- מחליפים
- אך ורק
- לְהַרְחִיב
- ניסיון
- המסביר
- לחקור
- מוכר
- מעטים
- שדה
- שדות
- קבצים
- לסנן
- ראשון
- מרוכז
- הבא
- כדלקמן
- בעד
- טופס
- פוּרמָט
- ידידותי
- החל מ-
- פונקציה
- יסודי
- נוסף
- GCP
- ליצור
- לקבל
- GitHub
- Go
- גדול
- מדריך
- לטפל
- טיפול
- קורה
- יש
- יש
- he
- לו
- לקוות
- איך
- אולם
- HTTPS
- בן אנוש
- i
- חולה
- ID
- if
- תמונה
- לייבא
- חשוב
- in
- מעמיק
- לכלול
- כולל
- הַכנָסָה
- משלבת
- הודעה
- למשל
- אינטרס
- אל תוך
- J States
- IT
- שֶׁלָה
- JavaScript
- ג'סון
- מחברת צדק
- רק
- KDnuggets
- מפתח
- מפתחות
- לדעת
- אחרון
- למידה
- רמה
- רמות
- סִפְרִיָה
- כמו
- לינקדין
- רשימה
- קְצָת
- ll
- אהבה
- מכונה
- למידת מכונה
- קסם
- נשמר
- עשייה
- לנהל
- מנהל
- רב
- אומר
- meta
- חסר
- ניידות
- מודרני
- MongoDB
- יותר
- רוב
- המהלך
- הרבה
- מספר
- שם
- טבעי
- צורך
- קינון
- חדש
- הבא
- לא
- בייחוד
- מחברה
- אובייקט
- להשיג
- of
- המיוחדות שלנו
- לעתים קרובות
- on
- ONE
- רק
- or
- שלנו
- בעצמנו
- תפוקה
- דובי פנדה
- פרמטר
- חלק
- במיוחד
- תלוי ועומד
- ביצעתי
- פיסיקה
- מכריע
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- פופולרי
- מתנות
- כנראה
- הליך
- תהליך
- ייצור
- פּרוֹיֶקט
- פיתון
- שאלה
- דַי
- חי
- RE
- קריאה
- מוכן
- שיא
- רשום
- לחדד
- להגיב
- REST
- תוצאות
- שמירה
- תקין
- תפקיד
- s
- אותו
- מדע
- מדע וטכנולוגיה
- מַדְעָן
- שניות
- לִרְאוֹת
- בחירה
- צריך
- פָּשׁוּט
- לדמות
- יחיד
- מיומנויות
- קטן
- So
- כמה
- משהו
- ספציפי
- במיוחד
- SQL
- עוד
- אחסון
- חנות
- מִבְנֶה
- מובנה
- כזה
- מַתְאִים
- סיכום
- T
- שולחן
- טכנולוגיה
- מונחים
- זֶה
- השמיים
- העולם
- שֶׁלָהֶם
- אותם
- אז
- אלה
- זֶה
- אלה
- זמן
- ל
- יַחַד
- חלק עליון
- לשנות
- טרנספורמציה
- הפיכה
- סוג
- סוגים
- תחת
- us
- להשתמש
- מועיל
- באמצעות
- ניצול
- ערך
- ערכים
- רוצה
- היה
- דֶרֶך..
- we
- מה
- מתי
- אם
- אשר
- בזמן
- יצטרך
- עם
- בתוך
- תיק עבודות
- עובד
- עובד
- עוֹלָם
- היה
- אתה
- זפירנט