תמונה מאת עורך
המנות העיקריות
- מבחן ה-t הוא מבחן סטטיסטי שניתן להשתמש בו כדי לקבוע אם יש הבדל מובהק בין האמצעים של שני מדגמים בלתי תלויים של נתונים.
- אנו מדגים כיצד ניתן ליישם מבחן t באמצעות מערך הנתונים של הקשתית וספריית Scipy של Python.
מבחן ה-t הוא מבחן סטטיסטי שניתן להשתמש בו כדי לקבוע אם יש הבדל מובהק בין האמצעים של שני מדגמים בלתי תלויים של נתונים. במדריך זה, נמחיש את הגרסה הבסיסית ביותר של מבחן ה-t, שעבורו נניח שלשתי הדגימות יש שונות שוות. גרסאות מתקדמות אחרות של מבחן ה-t כוללות את מבחן ה-t של Welch, שהוא התאמה של מבחן ה-t, והוא אמין יותר כאשר לשתי המדגמים יש שונות לא שוות ואולי גדלי מדגם לא שווים.
הסטיסטיקה t או ערך t מחושב באופן הבא:
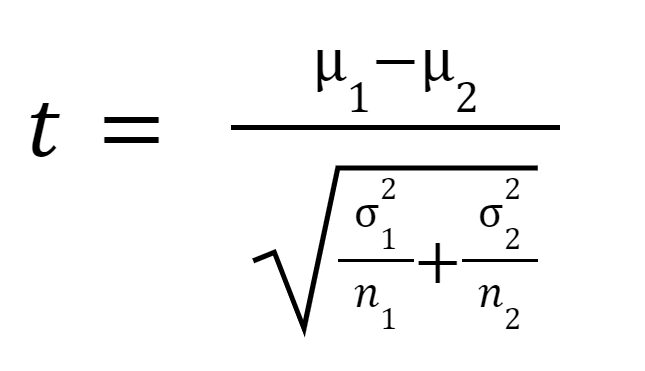
איפה
הוא הממוצע של מדגם 1,
הוא הממוצע של מדגם 2,
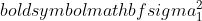 היא השונות של מדגם 1,
היא השונות של מדגם 1, 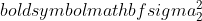 היא השונות של מדגם 2,
היא השונות של מדגם 2, 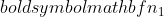 הוא גודל המדגם של מדגם 1, ו
הוא גודל המדגם של מדגם 1, ו 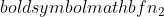 הוא גודל המדגם של מדגם 2.
הוא גודל המדגם של מדגם 2.
כדי להמחיש את השימוש במבחן t, נציג דוגמה פשוטה באמצעות מערך הנתונים של הקשתית. נניח שאנו צופים בשתי דגימות עצמאיות, למשל אורכי גביע פרחים, ואנו שוקלים אם שתי הדגימות נלקחו מאותה אוכלוסייה (למשל מאותו מין של פרחים או שני מינים בעלי מאפיינים דומים של גביעון) או שתי אוכלוסיות שונות.
מבחן ה-t מכמת את ההבדל בין הממוצעים האריתמטיים של שתי הדגימות. ערך ה-p מכמת את ההסתברות להשגת התוצאות הנצפות, בהנחה שהשערת האפס (שהדגימות נלקחות מאוכלוסיות עם אותו ממוצע אוכלוסיה) נכונה. ערך p גדול מסף שנבחר (למשל 5% או 0.05) מצביע על כך שההתבוננות שלנו לא כל כך לא סביר שהתרחשה במקרה. לכן, אנו מקבלים את השערת האפס של שווי אוכלוסיה. אם ערך ה-p קטן מהסף שלנו, אז יש לנו ראיות נגד השערת האפס של ממוצע אוכלוסיה שווה.
קלט T-Test
התשומות או הפרמטרים הדרושים לביצוע בדיקת t הם:
- שני מערכים a ו b המכיל את הנתונים עבור מדגם 1 ומדגם 2
יציאות T-Test
מבחן ה-t מחזיר את הדברים הבאים:
- סטטיסטיקת ה-t המחושבת
- ערך ה- p
ייבוא ספריות נחוצות
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
טען את מערך הנתונים של Iris
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
חשב את ממוצעי המדגם ואת השונות המדגם
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
יישום t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
תְפוּקָה
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
תְפוּקָה
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
תְפוּקָה
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)תצפיות
אנו רואים שהשימוש ב-"true" או "false" עבור הפרמטר "equal-var" אינו משנה כל כך את תוצאות מבחן ה-t. כמו כן, אנו רואים שהחלפת הסדר של מערכי המדגם a_1 ו-b_1 מניב ערך מבחן t שלילי, אך אינו משנה את גודל ערך מבחן ה-t, כצפוי. מכיוון שערך ה-p המחושב גדול בהרבה מערך הסף של 0.05, אנו יכולים לדחות את השערת האפס שההבדל בין הממוצע של מדגם 1 למדגם 2 משמעותי. זה מראה כי אורכי הגלב של מדגם 1 ומדגם 2 נמשכו מאותם נתוני אוכלוסייה.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
חשב את ממוצעי המדגם ואת השונות המדגם
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
יישום t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
תְפוּקָה
stats.ttest_ind(a_1, b_1, equal_var = False)תצפיות
אנו רואים ששימוש בדגימות בגודל לא שווה אינו משנה את סטטיסטיקת ה-t ואת ערך ה-p באופן משמעותי.
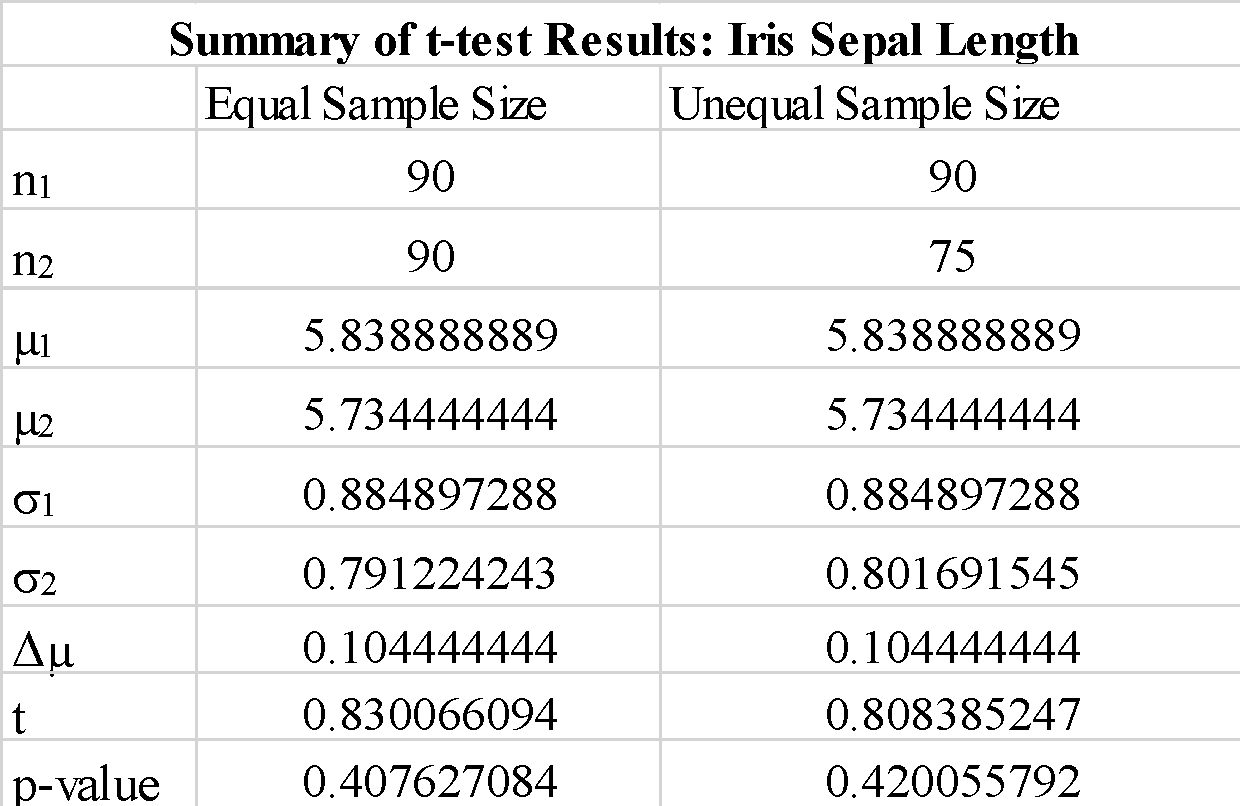
לסיכום, הראינו כיצד ניתן ליישם מבחן t פשוט באמצעות ספריית scipy ב-python.
בנג'מין או. טאיו הוא פיזיקאי, מחנך למדעי נתונים וכותב, כמו גם הבעלים של DataScienceHub. בעבר, בנג'מין לימד הנדסה ופיזיקה ב-U. of Central Oklahoma, Grand Canyon U., ו-Pittsburgh State U.
- הפצת תוכן ויחסי ציבור מופעל על ידי SEO. קבל הגברה היום.
- Platoblockchain. Web3 Metaverse Intelligence. ידע מוגבר. גישה כאן.
- מקור: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- לְקַבֵּל
- מתקדם
- נגד
- ו
- יישומית
- בסיסי
- בנימין
- בֵּין
- מחושב
- מֶרכָּזִי
- סיכוי
- שינוי
- מאפיינים
- נבחר
- בהתחשב
- יכול
- נתונים
- מדע נתונים
- מערכי נתונים
- לקבוע
- הבדל
- אחר
- נמשך
- הנדסה
- עדות
- דוגמה
- צפוי
- פרח
- הבא
- כדלקמן
- החל מ-
- איך
- HTTPS
- יושם
- לייבא
- in
- לכלול
- עצמאי
- מצביע על
- KDnuggets
- גדול יותר
- סִפְרִיָה
- לינקדין
- matplotlib
- אומר
- יותר
- רוב
- הכרחי
- שלילי
- קהות
- להתבונן
- להשיג
- התרחשה
- אוקלהומה
- להזמין
- אחר
- בעלים
- פרמטר
- פרמטרים
- ביצוע
- פיסיקה
- פיטסבורג
- אפלטון
- מודיעין אפלטון
- אפלטון נתונים
- אוכלוסייה
- אוכלוסיות
- קוֹדֶם
- הסתברות
- פיתון
- אָמִין
- תוצאות
- החזרות
- אותו
- מדע
- לְהַצִיג
- הראה
- הופעות
- משמעותי
- באופן משמעותי
- דומה
- פָּשׁוּט
- since
- מידה
- גדל
- קטן יותר
- So
- מדינה
- סטטיסטי
- סטטיסטיקות
- סיכום
- הוראה
- מבחן
- השמיים
- לכן
- סף
- ל
- נָכוֹן
- הדרכה
- להשתמש
- ערך
- גרסה
- אם
- אשר
- יצטרך
- סופר
- תשואות
- זפירנט