Il runtime di Amazon EMR per Apache Spark è un runtime ottimizzato per le prestazioni per Apache Spark, compatibile al 100% con l'API con Apache Spark open source. Insieme a Amazon EMR release 6.9.0, il runtime EMR per Apache Spark supporta l'equivalente Spark versione 3.3.0.
Con Amazon EMR 6.9.0, ora puoi eseguire le tue applicazioni Apache Spark 3.x più velocemente e a un costo inferiore senza richiedere alcuna modifica alle tue applicazioni. Nei nostri test di benchmark delle prestazioni, derivati dai test delle prestazioni TPC-DS su una scala di 3 TB, abbiamo riscontrato che il runtime EMR per Apache Spark 3.3.0 fornisce un miglioramento delle prestazioni di 3.5 volte (utilizzando il runtime totale) in media rispetto ad Apache Spark 3.3.0 open source. XNUMX.
In questo post, analizziamo i risultati dei nostri test di benchmark che eseguono un'applicazione TPC-DS Apache Spark open-source e poi su Amazon EMR 6.9, che viene fornito con un runtime Spark ottimizzato compatibile con Spark open source. Esaminiamo un'analisi dettagliata dei costi e infine forniamo istruzioni dettagliate per eseguire il benchmark.
Risultati osservati
Per valutare i miglioramenti delle prestazioni, abbiamo utilizzato un'utilità di test delle prestazioni Spark open source derivata dal toolkit di test delle prestazioni TPC-DS. Abbiamo eseguito i test su un cluster EMR c5d.9xlarge a sette nodi (sei nodi principali e un nodo primario) con il runtime EMR per Apache Spark e un secondo cluster autogestito a sette nodi su Cloud di calcolo elastico di Amazon (Amazon EC2) con la versione open source equivalente di Spark. Abbiamo eseguito entrambi i test con i dati inseriti Servizio di archiviazione semplice Amazon (Amazon S3).
L'allocazione dinamica delle risorse (DRA) è un'ottima funzionalità da utilizzare per carichi di lavoro variabili. Tuttavia, per un esercizio di benchmarking in cui confrontiamo due piattaforme esclusivamente in termini di prestazioni e i volumi dei dati di test non cambiano (3 TB nel nostro caso), riteniamo che sia meglio evitare la variabilità per eseguire un confronto tra mele e mele. Nei nostri test sia in Spark open source che in Amazon EMR, abbiamo disabilitato DRA durante l'esecuzione dell'applicazione di benchmarking.
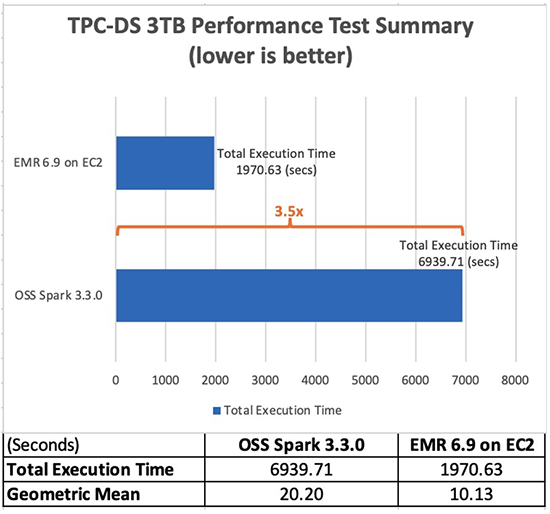
La tabella seguente mostra il runtime totale del lavoro per tutte le query (in secondi) nel set di dati di query da 3 TB tra Amazon EMR versione 6.9.0 e Spark open source versione 3.3.0. Abbiamo osservato che i nostri test TPC-DS avevano un runtime di lavoro totale su Amazon EMR su Amazon EC2 che era 3.5 volte più veloce rispetto a quello utilizzando un cluster Spark open source della stessa configurazione.
La velocità per query su Amazon EMR 6.9 con e senza il runtime EMR per Apache Spark è illustrata nel grafico seguente. L'asse orizzontale mostra ogni query nel benchmark da 3 TB. L'asse verticale mostra l'accelerazione di ogni query dovuta al runtime EMR. Notevoli miglioramenti delle prestazioni sono oltre 10 volte più veloci per le query TPC-DS 24b, 72, 95 e 96.

Analisi dei costi
I miglioramenti delle prestazioni del runtime EMR per Apache Spark si traducono direttamente in costi inferiori. Siamo stati in grado di realizzare un risparmio sui costi del 67% eseguendo l'applicazione di riferimento su Amazon EMR rispetto al costo sostenuto per eseguire la stessa applicazione su Spark open source su Amazon EC2 con le stesse dimensioni del cluster grazie alle ore ridotte di Amazon EMR e Amazon Utilizzo dell'EC2. I prezzi di Amazon EMR si riferiscono alle applicazioni EMR in esecuzione su cluster EMR con istanze EC2. Il prezzo di Amazon EMR viene aggiunto ai prezzi di calcolo e storage sottostanti, come il prezzo dell'istanza EC2 e Negozio di blocchi elastici di Amazon (Amazon EBS) costo (se si allegano volumi EBS). Complessivamente, il costo di riferimento stimato nella regione Stati Uniti orientali (Virginia settentrionale) è di $ 27.01 per esecuzione per Spark open source su Amazon EC2 e $ 8.82 per esecuzione per Amazon EMR.
| Lavoro di riferimento | Autonomia (ora) | Costo stimato | Istanza EC2 totale | vCPU totale | Memoria totale (GiB) | Dispositivo di root (Amazon EBS) |
|
Spark open source su Amazon EC2 (1 nodo primario e 6 nodi principali) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GB gp2 |
|
Amazon EMR su Amazon EC2 (1 nodo primario e 6 nodi principali) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GB gp2 |
Abbattimento dei costi
Di seguito è riportato il dettaglio dei costi per il lavoro open source Spark su Amazon EC2 ($ 27.01):
- Costo totale di Amazon EC2 – (7 * $ 1.728 * 2.23) = (numero di istanze * tariffa oraria c5d.9xlarge * tempo di esecuzione del lavoro in un'ora) = $ 26.97
- Costo Amazon EBS – ($ 0.1/730 * 20 * 7 * 2.23) = (Amazon EBS per GB/tariffa oraria * dimensione root EBS * numero di istanze * tempo di esecuzione del lavoro in un'ora) = $ 0.042
Di seguito è riportato il dettaglio dei costi per il lavoro Amazon EMR su Amazon EC2 ($ 8.82):
- Costo totale di Amazon EMR – (7 * $ 0.27 * 0.63) = ((numero di nodi principali + numero di nodi primari)* c5d.9xlarge Prezzo Amazon EMR * tempo di esecuzione del lavoro in ore) = $ 1.19
- Costo totale di Amazon EC2 – (7 * 1.728 USD * 0.63) = ((numero di nodi principali + numero di nodi primari)* prezzo istanza c5d.9xlarge * tempo di esecuzione del lavoro in ore) = 7.62 USD
- Costo Amazon EBS – ($ 0.1/730 * 20 GiB * 7 * 0.63) = (Amazon EBS per GB/tariffa oraria * dimensione EBS * numero di istanze * tempo di esecuzione del processo in un'ora) = $ 0.012
Impostare il benchmark OSS Spark
Nelle sezioni seguenti, forniamo una breve descrizione dei passaggi coinvolti nella creazione del benchmarking. Per istruzioni dettagliate con esempi, fare riferimento a Repository GitHub.
Per il nostro benchmark OSS Spark, utilizziamo lo strumento open source Flintrock per lanciare il nostro servizio basato su Amazon EC2 Apache Spark grappolo. Flintrock offre un modo rapido per avviare un cluster Apache Spark su Amazon EC2 utilizzando la riga di comando.
Prerequisiti
Completa i seguenti passaggi prerequisiti:
- Avere Python 3.7.x o superiore.
- Avere Pip3 22.2.2 o superiore.
- Aggiungi la directory bin di Python al percorso dell'ambiente. Il binario Flintrock verrà installato in questo percorso.
- Correre
aws configureper configurare il tuo Interfaccia della riga di comando di AWS (AWS CLI) per puntare all'account di benchmarking. Fare riferimento a Configurazione rapida con aws configure per le istruzioni. - Avere un coppia di chiavi con autorizzazioni file restrittive per accedere al nodo primario OSS Spark.
- Crea un nuovo bucket S3 nel tuo account di prova, se necessario.
- Copia i dati di origine TPC-DS come input nel tuo bucket S3.
- Crea l'applicazione di benchmark seguendo i passaggi forniti in Passaggi per creare l'applicazione spark-benchmark-assembly. In alternativa, puoi scaricare un file predefinito spark-benchmark-assembly-3.3.0.jar se desideri un'applicazione basata su Spark 3.3.0.
Distribuisci il cluster Spark ed esegui il processo di benchmark
Completa i seguenti passi:
- Installa lo strumento Flintrock tramite pip come mostrato in Passaggi per configurare OSS Spark Benchmarking.
- Esegui il comando flintrock configure, che apre un file di configurazione predefinito.
- Modifica il valore predefinito
config.yamlfile in base alle vostre esigenze. In alternativa, copia e incolla il file config.yaml content al file di configurazione predefinito. Quindi salva il file dove si trovava. - Infine, avvia il cluster Spark a 7 nodi su Amazon EC2 tramite Flintrock.
Questo dovrebbe creare un cluster Spark con un nodo primario e sei nodi di lavoro. Se vengono visualizzati messaggi di errore, ricontrolla i valori del file di configurazione, in particolare le versioni Spark e Hadoop e gli attributi di download-source e AMI.
Il cluster OSS Spark non viene fornito con il gestore risorse YARN. Per abilitarlo, dobbiamo configurare il cluster.
- Scarica la sito-filato.xml ed abilita-filato.sh file dal repository GitHub.
- Sostituire con l'indirizzo IP del nodo primario nel tuo cluster Flintrock.
Puoi recuperare l'indirizzo IP dalla console Amazon EC2.
- Carica i file in tutti i nodi del cluster Spark.
- Eseguire lo script enable-yarn.
- Abilita il supporto Snappy in Hadoop (il processo di benchmark legge i dati compressi Snappy).
- Scarica il file JAR dell'applicazione di utilità di riferimento spark-benchmark-assembly-3.3.0.jar al computer locale.
- Copia questo file nel cluster.
- Accedi al nodo primario e avvia YARN.
- Invia il processo di benchmark nel cluster Spark open source come mostrato in Invia il lavoro di riferimento.
Riassumi i risultati
Scarica il file dei risultati del test dal bucket S3 di output s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Sostituire $YOUR_S3_BUCKET con il nome del tuo bucket S3.) Puoi utilizzare la console Amazon S3 e passare alla posizione S3 di output oppure utilizzare l'AWS CLI.
L'applicazione benchmark Spark crea una cartella timestamp e scrive un file di riepilogo all'interno di un prefisso summary.csv. Il timestamp e il nome del file saranno diversi da quelli mostrati nell'esempio precedente.
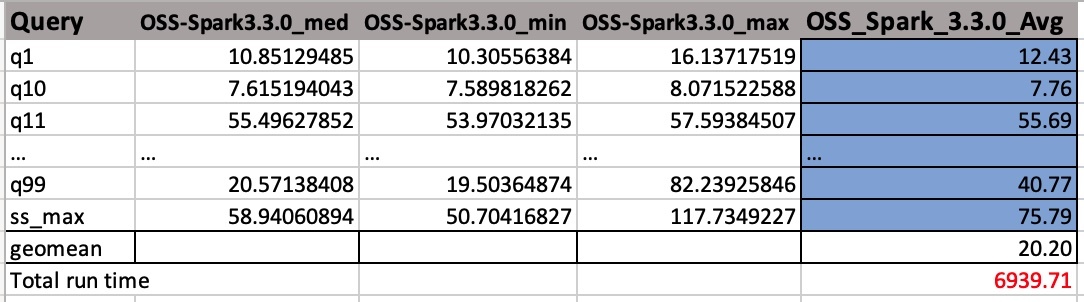
I file CSV di output hanno quattro colonne senza nomi di intestazione. Sono:
- Nome della domanda
- Tempo mediano
- Tempo minimo
- Tempo massimo
Lo screenshot seguente mostra un output di esempio. Abbiamo aggiunto manualmente i nomi delle colonne. Il modo in cui calcoliamo la media geografica e il tempo di esecuzione totale del lavoro si basa su medie aritmetiche. Per prima cosa prendiamo la media dei valori med, min e max usando la formula AVERAGE(B2:D2). Quindi prendiamo una media geometrica della colonna Avg utilizzando la formula GEOMEAN(E2:E105).
Configura il benchmarking di Amazon EMR
Per istruzioni dettagliate, vedere Passaggi per impostare il benchmarking EMR.
Prerequisiti
Completa i seguenti passaggi prerequisiti:
- Correre
aws configureper configurare la tua shell AWS CLI in modo che punti all'account di benchmarking. Fare riferimento a Configurazione rapida con aws configure per le istruzioni. - Carica l'applicazione di benchmark su Amazon S3.
Distribuisci il cluster EMR ed esegui il processo di benchmark
Completa i seguenti passi:
- Avvia Amazon EMR nella tua shell AWS CLI utilizzando la riga di comando come mostrato in Distribuisci il cluster EMR ed esegui il processo di benchmark.
- Configura Amazon EMR con un nodo primario (c5d.9xlarge) e sei nodi principali (c5d.9xlarge). Fare riferimento a creare-cluster per una descrizione dettagliata delle opzioni AWS CLI.
- Memorizza l'ID cluster dalla risposta. Ne avrai bisogno nel passaggio successivo.
- Invia il processo di benchmark in Amazon EMR utilizzando i passaggi di aggiunta nell'AWS CLI.
Riassumi i risultati
Riepiloga i risultati del bucket di output s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT nello stesso modo in cui abbiamo fatto per i risultati OSS e confrontare.
ripulire
Per evitare di incorrere in futuri addebiti, elimina le risorse che hai creato seguendo le istruzioni nel file Sezione di pulizia del repository GitHub.
- Arrestare i cluster EMR e OSS Spark. Puoi anche eliminarli se non desideri conservare il contenuto. Puoi eliminare queste risorse eseguendo lo script cleanup-benchmark-env.sh da un terminale nel tuo ambiente di riferimento.
- Se hai usato AWS Cloud9 come IDE per la creazione del file JAR dell'applicazione di riferimento utilizzando Passaggi per creare l'applicazione spark-benchmark-assembly, potresti voler eliminare anche l'ambiente.
Conclusione
Puoi eseguire i tuoi carichi di lavoro Apache Spark 3.5 volte (in base al runtime totale) più velocemente e a un costo inferiore senza apportare modifiche alle tue applicazioni utilizzando Amazon EMR 6.9.0.
Per essere sempre aggiornato, iscriviti al Big Data Blog's RSS feed per saperne di più sul runtime EMR per Apache Spark, sulle best practice di configurazione e sui consigli per l'ottimizzazione.
Per i precedenti test di benchmark, vedere Esegui i carichi di lavoro Apache Spark 3.0 1.7 volte più velocemente con il runtime di Amazon EMR per Apache Spark. Si noti che il risultato del benchmark precedente di 1.7 volte la performance era basato sulla media geometrica. In base alla media geometrica, le prestazioni in Amazon EMR 6.9 sono state due volte più veloci.
Circa gli autori
 Sekar Srivasan è un Sr. Specialist Solutions Architect presso AWS specializzato in Big Data e Analytics. Sekar ha oltre 20 anni di esperienza nel lavoro con i dati. È appassionato di aiutare i clienti a creare soluzioni scalabili modernizzando la loro architettura e generando insight dai loro dati. Nel tempo libero gli piace lavorare su progetti senza scopo di lucro, in particolare quelli incentrati sull'educazione dei bambini svantaggiati.
Sekar Srivasan è un Sr. Specialist Solutions Architect presso AWS specializzato in Big Data e Analytics. Sekar ha oltre 20 anni di esperienza nel lavoro con i dati. È appassionato di aiutare i clienti a creare soluzioni scalabili modernizzando la loro architettura e generando insight dai loro dati. Nel tempo libero gli piace lavorare su progetti senza scopo di lucro, in particolare quelli incentrati sull'educazione dei bambini svantaggiati.
 Prabu Ravichandran è un Senior Data Architect con Amazon Web Services, specializzato in analisi, architettura e implementazione di data lake. Aiuta i clienti a progettare e creare soluzioni scalabili e robuste utilizzando i servizi AWS. Nel tempo libero, Prabu ama viaggiare e passare il tempo con la famiglia.
Prabu Ravichandran è un Senior Data Architect con Amazon Web Services, specializzato in analisi, architettura e implementazione di data lake. Aiuta i clienti a progettare e creare soluzioni scalabili e robuste utilizzando i servizi AWS. Nel tempo libero, Prabu ama viaggiare e passare il tempo con la famiglia.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 anni
- 7
- 9
- a
- capace
- WRI
- sopra
- accesso
- Il mio account
- aggiunto
- indirizzo
- consigli
- Tutti
- assegnazione
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- .
- analitica
- analizzare
- ed
- Apache
- Apache Spark
- api
- Applicazioni
- applicazioni
- architettura
- gli attributi
- media
- AVG
- AWS
- Axis
- basato
- CREDIAMO
- Segno di riferimento
- MIGLIORE
- best practice
- fra
- Big
- Big Data
- Bloccare
- Guasto
- costruire
- Costruzione
- Custodie
- il cambiamento
- Modifiche
- oneri
- Grafico
- Cluster
- Colonna
- colonne
- Venire
- confrontare
- confronto
- compatibile
- Calcolare
- Configurazione
- consolle
- contenuto
- Nucleo
- Costo
- risparmi
- Costi
- creare
- creato
- crea
- Clienti
- dati
- Lago di dati
- Data
- Predefinito
- derivato
- descrizione
- dettagliati
- dispositivo
- DID
- diverso
- direttamente
- disabile
- non
- Dont
- scaricare
- ogni
- est
- ebs
- Istruzione
- enable
- Ambiente
- Equivalente
- errore
- particolarmente
- stimato
- Etere (ETH)
- valutare
- esempio
- Esempi
- Esercitare
- esperienza
- famiglia
- più veloce
- caratteristica
- Compila il
- File
- Infine
- Nome
- concentrato
- focalizzata
- i seguenti
- formula
- essere trovato
- Gratis
- da
- futuro
- Guadagni
- la generazione di
- GitHub
- grande
- Hadoop
- aiutare
- aiuta
- Orizzontale
- ORE
- Tuttavia
- HTML
- HTTPS
- implementazione
- miglioramento
- miglioramenti
- in
- ingresso
- intuizioni
- esempio
- istruzioni
- coinvolto
- IP
- Indirizzo IP
- IT
- Lavoro
- mantenere
- lago
- lanciare
- IMPARARE
- linea
- locale
- località
- macchina
- Fare
- direttore
- modo
- manualmente
- max
- si intende
- Memorie
- messaggi
- Scopri di più
- Nome
- nomi
- Navigare
- Bisogno
- di applicazione
- esigenze
- New
- GENERAZIONE
- nodo
- nodi
- senza scopo di lucro
- notevole
- numero
- ONE
- open source
- ottimizzati
- Opzioni
- minimo
- Oss
- contorno
- complessivo
- appassionato
- passato
- sentiero
- performance
- permessi
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- Pops
- Post
- pratiche
- prezzo
- Prezzi
- prezzi
- primario
- un bagno
- progetti
- fornire
- purché
- fornisce
- puramente
- Python
- Presto
- tasso
- rendersi conto
- Ridotto
- regione
- rilasciare
- sostituire
- risorsa
- Risorse
- risposta
- restrittivo
- colpevole
- Risultati
- robusto
- radice
- Correre
- running
- stesso
- Risparmi
- Risparmio
- scalabile
- Scala
- Secondo
- secondo
- Sezione
- sezioni
- anziano
- Servizi
- regolazione
- flessibile.
- Conchiglia
- dovrebbero
- mostrato
- Spettacoli
- Un'espansione
- SIX
- Taglia
- Soluzioni
- Fonte
- Scintilla
- specialista
- Spendere
- inizia a
- step
- Passi
- conservazione
- sottoscrivi
- tale
- SOMMARIO
- supporto
- supporti
- tavolo
- Fai
- terminal
- test
- test
- Il
- loro
- Attraverso
- tempo
- volte
- timestamp
- a
- toolkit
- Totale
- tradurre
- Di viaggio
- sottostante
- diseredati
- us
- Impiego
- uso
- utilità
- Valori
- versione
- via
- Virginia
- volumi
- sito web
- servizi web
- quale
- while
- volere
- senza
- Lavora
- lavoratore
- lavoro
- X
- XML
- YAML
- anni
- Trasferimento da aeroporto a Sharm
- zefiro