I modelli linguistici di grandi dimensioni (LLM) stanno diventando sempre più popolari, con nuovi casi d’uso costantemente esplorati. In generale, puoi creare applicazioni basate su LLM incorporando il prompt engineering nel tuo codice. Tuttavia, ci sono casi in cui la promozione di un LLM esistente non è sufficiente. È qui che la messa a punto del modello può aiutare. Il prompt engineering consiste nel guidare l'output del modello creando prompt di input, mentre il fine tuning consiste nell'addestrare il modello su set di dati personalizzati per renderlo più adatto ad attività o domini specifici.
Prima di poter mettere a punto un modello, è necessario trovare un set di dati specifico per l'attività. Un set di dati comunemente utilizzato è il Set di dati di scansione comune. Il corpus Common Crawl contiene petabyte di dati, raccolti regolarmente dal 2008, e contiene dati grezzi di pagine web, estratti di metadati ed estratti di testo. Oltre a determinare quale set di dati utilizzare, è necessaria la pulizia e l'elaborazione dei dati in base alle esigenze specifiche dell'ottimizzazione.
Di recente abbiamo collaborato con un cliente che desiderava preelaborare un sottoinsieme dell'ultimo set di dati Common Crawl e quindi ottimizzare il proprio LLM con dati puliti. Il cliente stava cercando come raggiungere questo obiettivo nel modo più conveniente su AWS. Dopo aver discusso i requisiti, si consiglia di utilizzare Amazon EMR senza server come piattaforma per la preelaborazione dei dati. EMR Serverless è particolarmente adatto per l'elaborazione dati su larga scala ed elimina la necessità di manutenzione dell'infrastruttura. In termini di costo, addebita solo in base alle risorse e alla durata utilizzata per ciascun lavoro. Il cliente è stato in grado di preelaborare centinaia di TB di dati in una settimana utilizzando EMR Serverless. Dopo aver preelaborato i dati, hanno utilizzato Amazon Sage Maker per mettere a punto il LLM.
In questo post ti guideremo attraverso il caso d'uso del cliente e l'architettura utilizzata.
Nelle sezioni seguenti, introduciamo innanzitutto il set di dati Common Crawl e come esplorare e filtrare i dati di cui abbiamo bisogno. Amazzone Atena addebita solo la dimensione dei dati scansionati e viene utilizzato per esplorare e filtrare i dati rapidamente, pur essendo conveniente. EMR Serverless fornisce un'opzione conveniente e che non richiede manutenzione per l'elaborazione dei dati Spark e viene utilizzato per elaborare i dati filtrati. Successivamente, usiamo JumpStart di Amazon SageMaker per mettere a punto il Modello lama 2 con il set di dati preelaborato. SageMaker JumpStart fornisce una serie di soluzioni per i casi d'uso più comuni che possono essere implementati con pochi clic. Non è necessario scrivere alcun codice per mettere a punto un LLM come Llama 2. Infine, distribuiamo il modello ottimizzato utilizzando Amazon Sage Maker e confrontare le differenze nell'output del testo per la stessa domanda tra il modello Llama 2 originale e quello ottimizzato.
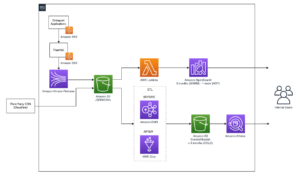
Il diagramma seguente illustra l'architettura di questa soluzione.
Prima di approfondire i dettagli della soluzione, completare i seguenti passaggi prerequisiti:
Common Crawl è un set di dati di corpus aperto ottenuto eseguendo la scansione di oltre 50 miliardi di pagine web. Include enormi quantità di dati non strutturati in più lingue, a partire dal 2008 e raggiungendo il livello di petabyte. È continuamente aggiornato.
Nell'addestramento di GPT-3, il dataset Common Crawl rappresenta il 60% dei suoi dati di addestramento, come mostrato nel diagramma seguente (fonte: I modelli linguistici sono studenti con pochi spari).
Un altro importante set di dati che vale la pena menzionare è il Set di dati C4. C4, abbreviazione di Colossal Clean Crawled Corpus, è un set di dati derivato dalla postelaborazione del set di dati Common Crawl. Nel documento LLaMA di Meta, hanno delineato i set di dati utilizzati, con Common Crawl che rappresenta il 67% (utilizzando 3.3 TB di dati) e C4 per il 15% (utilizzando 783 GB di dati). Il documento sottolinea l'importanza di incorporare dati preelaborati in modo diverso per migliorare le prestazioni del modello. Nonostante i dati C4 originali facessero parte di Common Crawl, Meta ha optato per la versione rielaborata di questi dati.
In questa sezione vengono trattati i modi comuni per interagire, filtrare ed elaborare il set di dati Common Crawl.
Il set di dati grezzi di Common Crawl include tre tipi di file di dati: dati di pagine Web grezze (WARC), metadati (WAT) ed estrazione di testo (WET).
I dati raccolti dopo il 2013 sono archiviati in formato WARC e includono i metadati corrispondenti (WAT) e i dati di estrazione del testo (WET). Il set di dati si trova in Amazon S3, aggiornato su base mensile ed è possibile accedervi direttamente tramite Mercato AWS.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzIl set di dati Common Crawl fornisce anche una tabella degli indici per filtrare i dati, denominata cc-index-table.
La tabella cc-index è un indice dei dati esistenti, che fornisce un indice basato su tabella dei file WARC. Consente una facile ricerca di informazioni, ad esempio quale file WARC corrisponde a un URL specifico.
Ad esempio, puoi creare una tabella Athena per mappare i dati cc-index con il seguente codice:
Le istruzioni SQL precedenti dimostrano come creare una tabella Athena, aggiungere partizioni ed eseguire una query.
Filtra i dati dal set di dati di scansione comune
Come puoi vedere dall'istruzione SQL create table, ci sono diversi campi che possono aiutare a filtrare i dati. Ad esempio, se desideri ottenere il conteggio dei documenti cinesi durante un periodo specifico, l'istruzione SQL potrebbe essere la seguente:
Se desideri eseguire un'ulteriore elaborazione, puoi salvare i risultati in un altro bucket S3.
Analizzare i dati filtrati
I Repository GitHub di scansione comune fornisce diversi esempi PySpark per l'elaborazione dei dati grezzi.
Consideriamo un esempio di corsa server_count.py (script di esempio fornito dal repository Common Crawl GitHub) sui dati che si trovano in s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Innanzitutto, è necessario un ambiente Spark, come EMR Spark. Ad esempio, puoi avviare un Amazon EMR sul cluster EC2 in us-east-1 (perché il set di dati è in us-east-1). L'utilizzo di un EMR sul cluster EC2 può aiutarti a eseguire test prima di inviare i lavori all'ambiente di produzione.
Dopo aver avviato un EMR sul cluster EC2, è necessario effettuare un accesso SSH al nodo primario del cluster. Quindi, crea il pacchetto dell'ambiente Python e invia lo script (fai riferimento al file Documentazione Conda per installare Miniconda):
L'elaborazione di tutti i riferimenti nel warc.path può richiedere del tempo. A scopo dimostrativo, è possibile migliorare i tempi di elaborazione con le seguenti strategie:
- Scarica il file
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzsul tuo computer locale, decomprimilo e quindi caricalo su HDFS o Amazon S3. Questo perché il file .gzip non è divisibile. È necessario decomprimerlo per elaborare questo file in parallelo. - modificare la
warc.pathfile, elimina la maggior parte delle sue righe e mantieni solo due righe per rendere il lavoro molto più veloce.
Una volta completato il lavoro, puoi vedere il risultato in s3://xxxx-common-crawl/output/, nel formato Parquet.
Implementare una logica di possesso personalizzata
Il repository Common Crawl GitHub fornisce un approccio comune per elaborare i file WARC. In generale è possibile estendere il CCSparkJob per sovrascrivere un singolo metodo (process_record), che è sufficiente per molti casi.
Diamo un'occhiata ad un esempio per ottenere le recensioni IMDB dei film recenti. Innanzitutto, devi filtrare i file sul sito IMDB:
Quindi puoi ottenere elenchi di file WARC che contengono dati di revisione IMDB e salvare i nomi di file WARC come elenco in un file di testo.
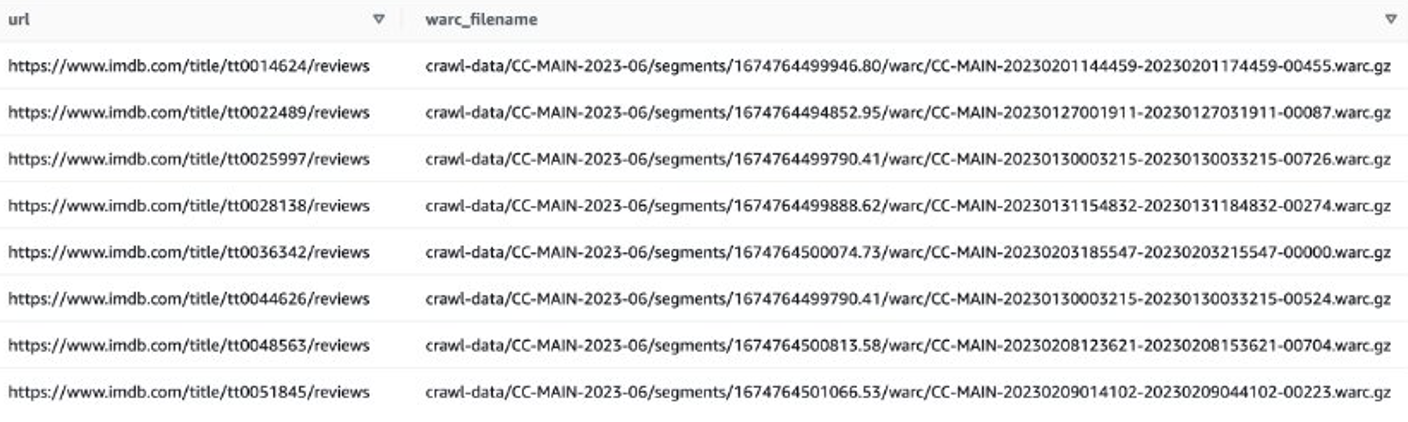
In alternativa, puoi utilizzare EMR Spark per ottenere l'elenco dei file WARC e archiviarlo in Amazon S3. Per esempio:
Il file di output dovrebbe essere simile a s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Il passo successivo è estrarre le recensioni degli utenti da questi file WARC. Puoi estendere il CCSparkJob per ignorare il process_record() Metodo:
Puoi salvare lo script precedente come imdb_extractor.py, che utilizzerai nei passaggi seguenti. Dopo aver preparato i dati e gli script, è possibile utilizzare EMR Serverless per elaborare i dati filtrati.
EMR senza server
EMR Serverless è un'opzione di distribuzione serverless per eseguire applicazioni di analisi di Big Data utilizzando framework open source come Apache Spark e Hive senza configurare, gestire e ridimensionare cluster o server.
Con EMR Serverless, puoi eseguire carichi di lavoro di analisi su qualsiasi scala con scalabilità automatica che ridimensiona le risorse in pochi secondi per soddisfare i mutevoli volumi di dati e i requisiti di elaborazione. EMR Serverless aumenta e riduce automaticamente le risorse per fornire la giusta quantità di capacità per la tua applicazione e paghi solo per ciò che utilizzi.
L'elaborazione del set di dati Common Crawl è generalmente un'attività di elaborazione una tantum, che la rende adatta ai carichi di lavoro EMR Serverless.
Crea un'applicazione EMR Serverless
È possibile creare un'applicazione EMR Serverless sulla console EMR Studio. Completa i seguenti passaggi:
- Nella console EMR Studio, scegli Applicazioni per serverless nel pannello di navigazione.
- Scegli Crea applicazione.

- Fornisci un nome per l'applicazione e scegli una versione Amazon EMR.

- Se è richiesto l'accesso alle risorse VPC, aggiungi un'impostazione di rete personalizzata.

- Scegli Crea applicazione.
Il tuo ambiente serverless Spark sarà quindi pronto.
Prima di poter inviare un lavoro a EMR Spark Serverless, è comunque necessario creare un ruolo di esecuzione. Fare riferimento a Nozioni di base su Amazon EMR Serverless per ulteriori dettagli.
Elabora i dati di scansione comune con EMR Serverless
Una volta pronta l'applicazione EMR Spark Serverless, completare i seguenti passaggi per elaborare i dati:
- Preparare un ambiente Conda e caricarlo su Amazon S3, che verrà utilizzato come ambiente in EMR Spark Serverless.
- Carica gli script da eseguire su un bucket S3. Nell'esempio seguente sono presenti due script:
- imbd_extractor.py – Logica personalizzata per estrarre i contenuti dal set di dati. I contenuti li trovate in precedenza in questo post.
- cc-pyspark/sparkcc.py – Il framework PySpark di esempio da Scansione comune del repository GitHub, che è necessario includere.
- Invia il lavoro PySpark a EMR Serverless Spark. Definisci i seguenti parametri per eseguire questo esempio nel tuo ambiente:
- ID applicazione – L'ID dell'applicazione EMR Serverless.
- ruolo-di-esecuzione-arn – Il tuo ruolo di esecuzione EMR Serverless. Per crearlo fare riferimento a Creare un ruolo runtime lavoro.
- Posizione del file WARC – La posizione dei tuoi file WARC.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtcontiene l'elenco dei file WARC filtrati, ottenuto in precedenza in questo post. - spark.sql.warehouse.dir – La posizione del magazzino predefinita (utilizza la directory S3).
- spark.archives – La posizione S3 dell'ambiente Conda preparato.
- spark.submit.pyFiles – Lo script PySpark preparato sparkcc.py.
Vedi il seguente codice:
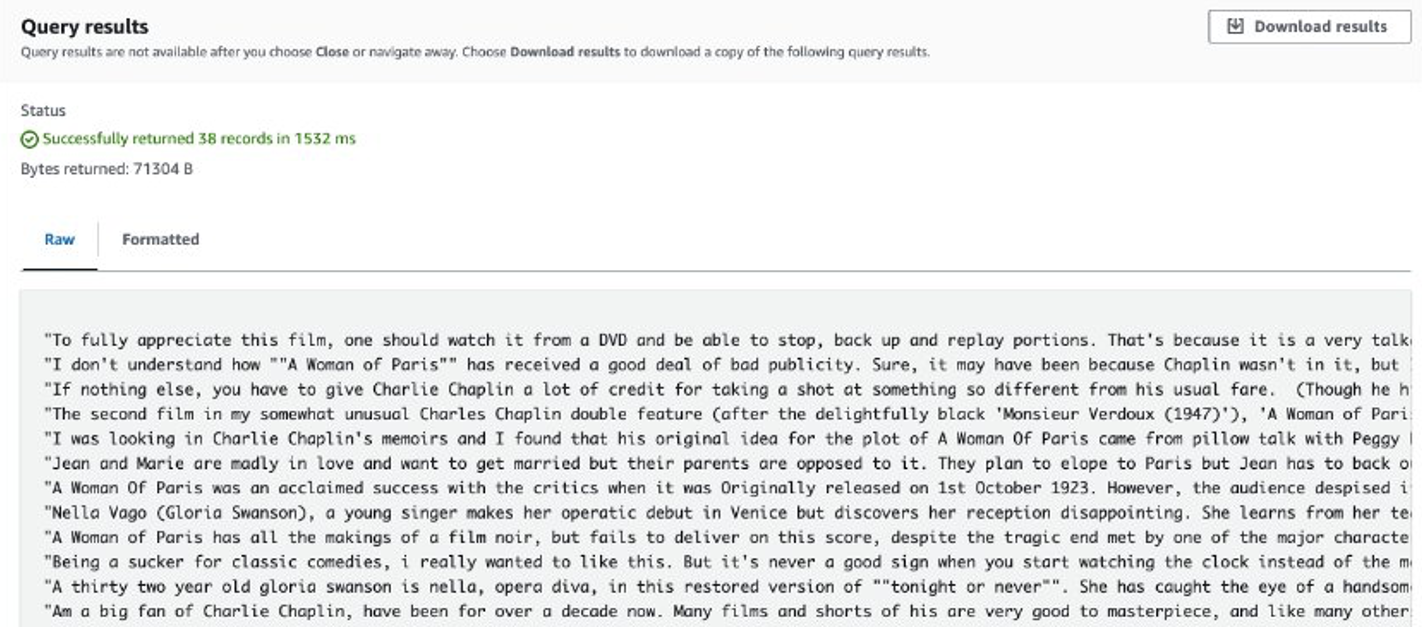
Una volta completato il lavoro, le recensioni estratte vengono archiviate in Amazon S3. Per controllare i contenuti, puoi utilizzare Amazon S3 Select, come mostrato nello screenshot seguente.
Considerazioni
Di seguito sono riportati i punti da considerare quando si ha a che fare con enormi quantità di dati con codice personalizzato:
- Alcune librerie Python di terze parti potrebbero non essere disponibili in Conda. In questi casi, puoi passare a un ambiente virtuale Python per creare l'ambiente runtime PySpark.
- Se la quantità di dati da elaborare è enorme, prova a creare e utilizzare più applicazioni EMR Serverless Spark per parallelizzarli. Ogni applicazione si occupa di un sottoinsieme di elenchi di file.
- Potresti riscontrare un problema di rallentamento con Amazon S3 durante il filtraggio o l'elaborazione dei dati di scansione comune. Questo perché il bucket S3 in cui sono archiviati i dati è accessibile pubblicamente e altri utenti possono accedere ai dati contemporaneamente. Per mitigare questo problema, puoi aggiungere un meccanismo di ripetizione o sincronizzare dati specifici dal bucket Common Crawl S3 al tuo bucket.
Perfeziona Llama 2 con SageMaker
Dopo che i dati sono stati preparati, puoi mettere a punto un modello Llama 2 con essi. Puoi farlo utilizzando SageMaker JumpStart, senza scrivere alcun codice. Per ulteriori informazioni, fare riferimento a Ottimizza Llama 2 per la generazione di testo su Amazon SageMaker JumpStart.
In questo scenario, esegui una messa a punto dell'adattamento del dominio. Con questo set di dati, l'input è costituito da un file CSV, JSON o TXT. Devi inserire tutti i dati della recensione in un file TXT. A tale scopo, è possibile inviare un processo Spark semplice a EMR Spark Serverless. Consulta il seguente snippet di codice di esempio:
Dopo aver preparato i dati di addestramento, inserisci la posizione dei dati per Set di dati di addestramento, Quindi scegliere Treni.
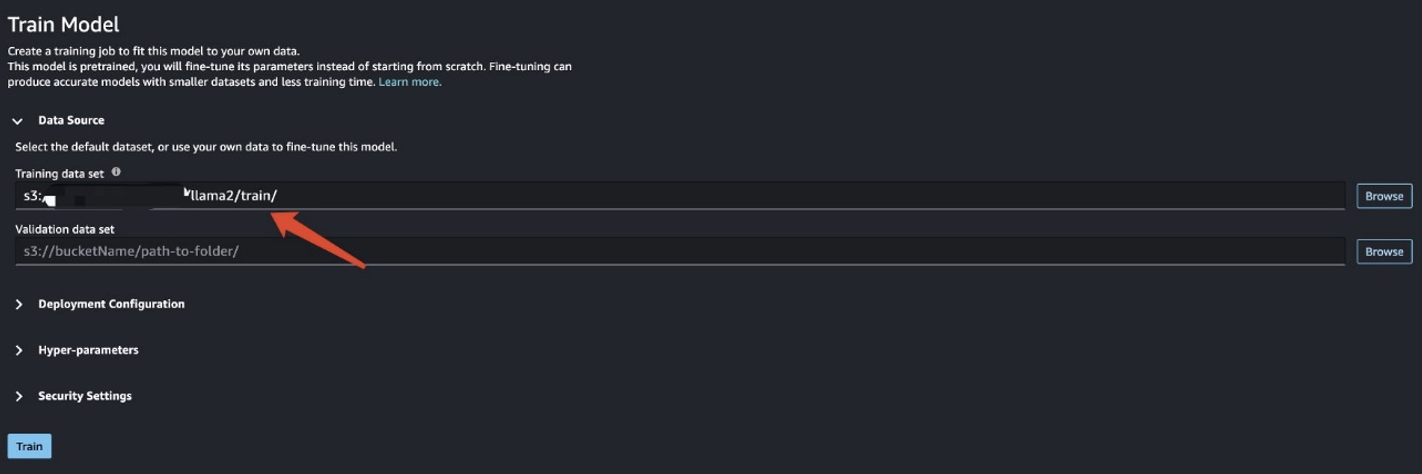
È possibile tenere traccia dello stato del lavoro di formazione.
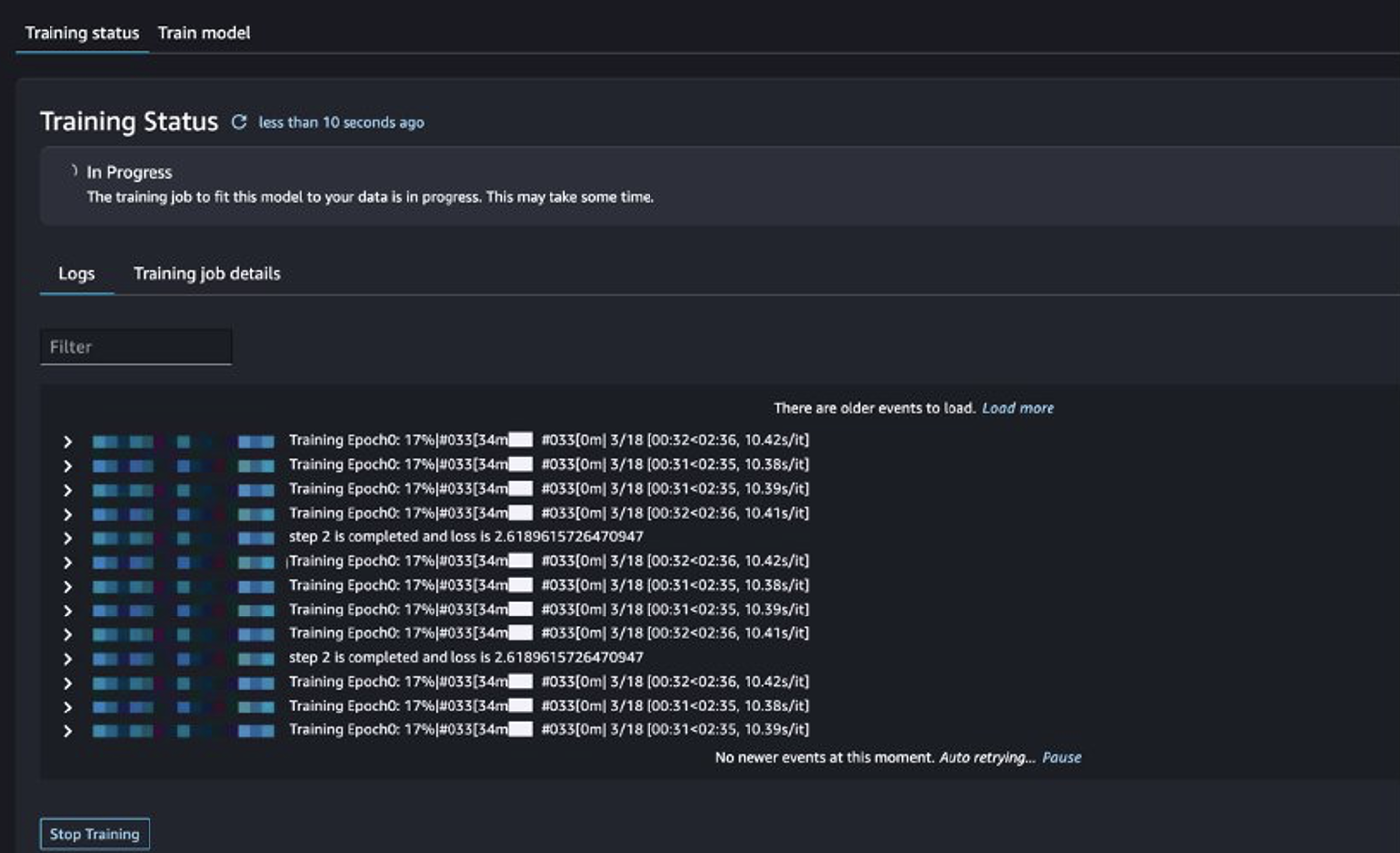
Valutare il modello ottimizzato
Una volta completata la formazione, scegli Schierare in SageMaker JumpStart per distribuire il modello ottimizzato.

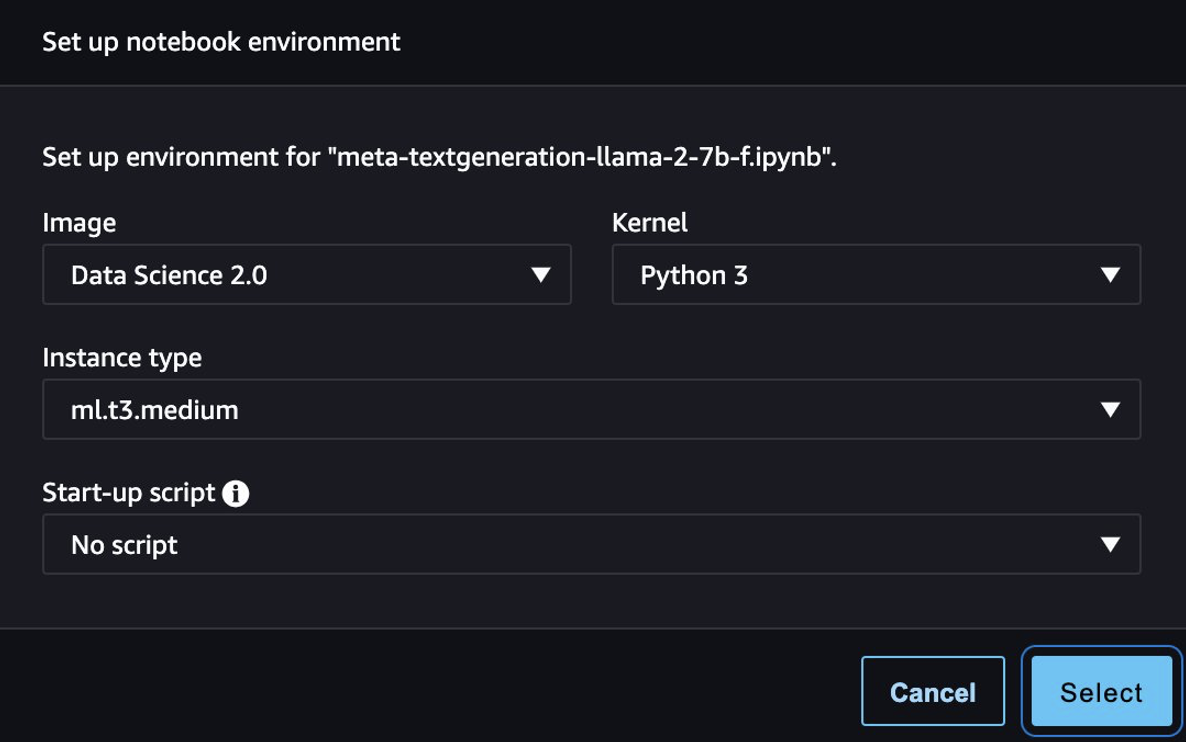
Dopo che il modello è stato distribuito correttamente, scegli Apri taccuino, che ti reindirizza a un notebook Jupyter preparato in cui puoi eseguire il codice Python.

È possibile utilizzare l'immagine Data Science 2.0 e il kernel Python 3 per il notebook.
Quindi, puoi valutare il modello perfezionato e il modello originale in questo taccuino.
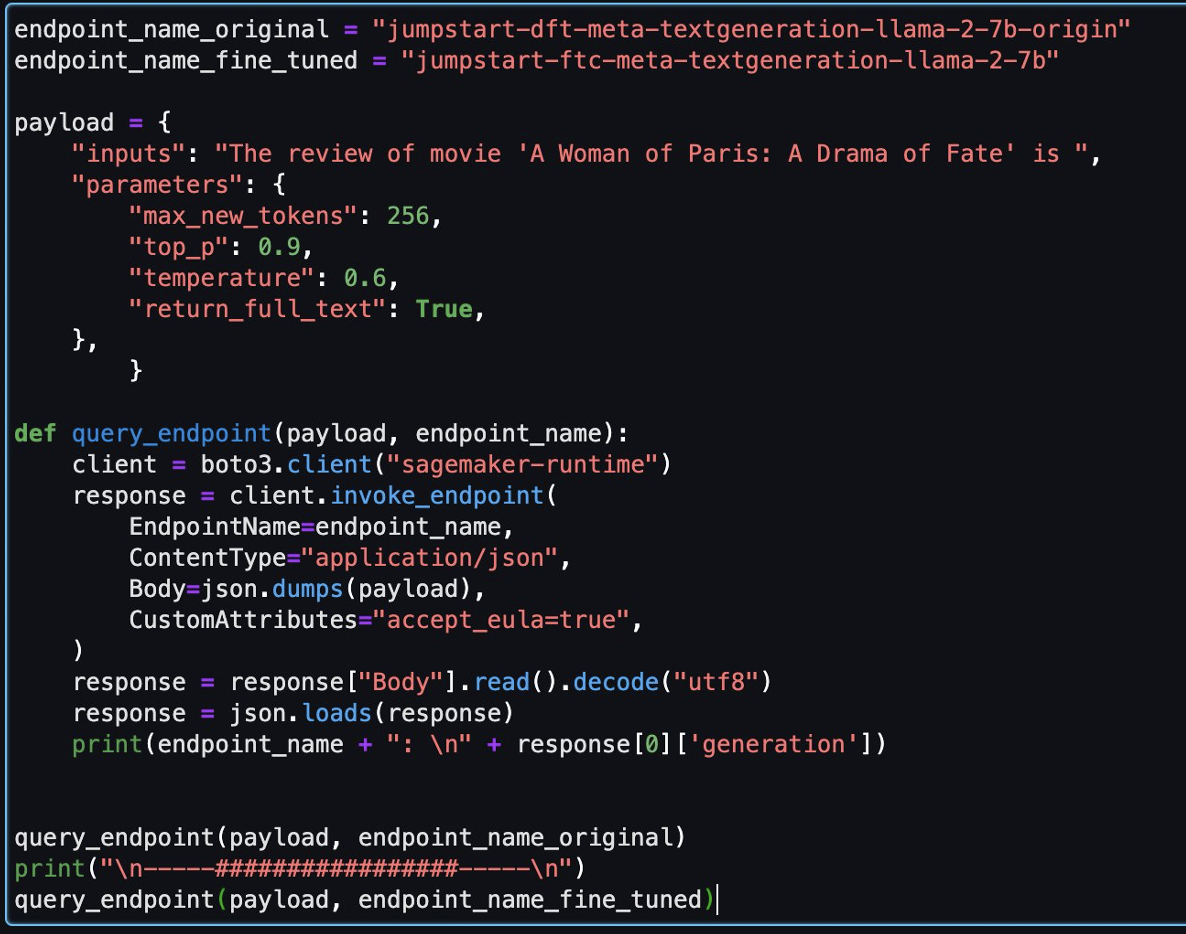
Di seguito sono riportate due risposte restituite dal modello originale e dal modello ottimizzato per la stessa domanda.

Abbiamo fornito a entrambi i modelli la stessa frase: "La recensione del film 'A Woman of Paris: A Drama of Fate' è" e abbiamo lasciato che completassero la frase.
Il modello originale produce frasi senza senso:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
Al contrario, i risultati del modello ottimizzato sono più simili a una recensione di un film:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Ovviamente, il modello ottimizzato offre prestazioni migliori in questo scenario specifico.
ripulire
Una volta terminato questo esercizio, completa i seguenti passaggi per ripulire le risorse:
- Elimina il bucket S3 che memorizza il set di dati pulito.
- Arresta l'ambiente EMR Serverless.
- Elimina l'endpoint SageMaker che ospita il modello LLM.
- Elimina il dominio SageMaker che gestisce i tuoi notebook.
Per impostazione predefinita, l'applicazione creata dovrebbe arrestarsi automaticamente dopo 15 minuti di inattività.
In genere, non è necessario ripulire l'ambiente Athena perché non ci sono costi quando non lo utilizzi.
Conclusione
In questo post, abbiamo introdotto il set di dati Common Crawl e come utilizzare EMR Serverless per elaborare i dati per la messa a punto di LLM. Quindi abbiamo dimostrato come utilizzare SageMaker JumpStart per ottimizzare LLM e distribuirlo senza alcun codice. Per ulteriori casi d'uso di EMR Serverless, fare riferimento a Amazon EMR senza server. Per ulteriori informazioni sui modelli di hosting e ottimizzazione su Amazon SageMaker JumpStart, consulta il file Documentazione Sagemaker JumpStart.
Informazioni sugli autori
 Shijian Tang è un Solution Architect di Analytics Specialist presso Amazon Web Services.
Shijian Tang è un Solution Architect di Analytics Specialist presso Amazon Web Services.
 Matteo Liem è Senior Solution Architecture Manager presso Amazon Web Services.
Matteo Liem è Senior Solution Architecture Manager presso Amazon Web Services.
 Dalei Xu è un Solution Architect di Analytics Specialist presso Amazon Web Services.
Dalei Xu è un Solution Architect di Analytics Specialist presso Amazon Web Services.
 Yuanjun Xiao è un Senior Solution Architect presso Amazon Web Services.
Yuanjun Xiao è un Senior Solution Architect presso Amazon Web Services.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :È
- :non
- :Dove
- $ SU
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- capace
- Chi siamo
- accesso
- accessibile
- accessibile
- Contabilità
- conti
- Raggiungere
- attivare
- aggiungere
- aggiunta
- Africa
- Dopo shavasana, sedersi in silenzio; saluti;
- Tutti
- consente
- anche
- stupefacente
- Amazon
- Amazon EMR
- Amazon Sage Maker
- JumpStart di Amazon SageMaker
- Amazon Web Services
- quantità
- importi
- an
- analitica
- ed
- Un altro
- in qualsiasi
- Apache
- Apache Spark
- Applicazioni
- applicazioni
- approccio
- architettura
- SONO
- AS
- At
- Australiano
- Automatico
- automaticamente
- disponibile
- AWS
- sfondo
- basato
- base
- BE
- bellissimo
- perché
- diventando
- prima
- iniziare
- essendo
- Meglio
- fra
- Big
- Big Data
- Miliardo
- stile di vita
- entrambi
- costruire
- by
- detto
- Materiale
- Può ottenere
- Ultra-Grande
- trasportare
- Custodie
- casi
- cambiando
- carattere
- oneri
- dai un'occhiata
- Cinese
- Scegli
- classe
- cavedano
- cliente
- Cluster
- codice
- COM
- Uncommon
- comunemente
- confrontare
- completamento di una
- configurazione
- Prendere in considerazione
- consiste
- consolle
- costantemente
- contenere
- contiene
- testuali
- continuamente
- contrasto
- Corrispondente
- corrisponde
- Costo
- costo effettivo
- potuto
- contare
- coprire
- creare
- creato
- costume
- cliente
- personalizzate
- dati
- Dati Analytics
- elaborazione dati
- scienza dei dati
- dataset
- Davis
- trattare
- Offerte
- deep
- Predefinito
- definire
- Dimo
- dimostrare
- dimostrato
- schierare
- schierato
- deployment
- derivato
- Nonostante
- dettagli
- determinazione
- diagramma
- differenze
- diversamente
- indirizzato
- direttamente
- discutere
- immersione
- do
- documenti
- dominio
- domini
- donald
- Dont
- giù
- Dramma
- autista
- durata
- durante
- ogni
- In precedenza
- facile
- elimina
- sottolinea
- incontrare
- Ingegneria
- migliorando
- entrare
- Ambiente
- Etere (ETH)
- valutare
- esempio
- Esempi
- esecuzione
- Esercitare
- esistente
- esiste
- esplora
- Esplorazione
- estendere
- esterno
- estratto
- estrazione
- estratti
- cadute
- falso
- più veloce
- destino
- In primo piano
- pochi
- campi
- Compila il
- File
- filtro
- filtraggio
- Infine
- Trovare
- finire
- Nome
- i seguenti
- segue
- Nel
- formato
- essere trovato
- Contesto
- quadri
- da
- ulteriormente
- Generale
- generalmente
- la generazione di
- ELETTRICA
- ottenere
- Idiota
- GitHub
- guidare
- Avere
- Aiuto
- Alveare
- di hosting
- padroni di casa
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- centinaia
- i
- IAM
- ID
- if
- illustra
- Immagine
- importare
- importante
- competenze
- in
- incluso
- inclusi
- incorporando
- crescente
- Index
- informazioni
- Infrastruttura
- ingresso
- Ingressi
- install
- interagire
- ai miglioramenti
- introdurre
- introdotto
- problema
- IT
- SUO
- martinetto
- Lavoro
- Offerte di lavoro
- json
- Notebook Jupyter
- ad appena
- mantenere
- Le
- Lingua
- Le Lingue
- larga scala
- con i più recenti
- lanciare
- lancio
- portare
- lasciare
- Livello
- biblioteche
- piace
- LIMITE
- Linee
- Lista
- elenchi
- Lama
- lm
- locale
- collocato
- località
- logica
- accesso
- Guarda
- cerca
- ricerca
- macchina
- manutenzione
- make
- Fare
- direttore
- gestione
- molti
- carta geografica
- massiccio
- Maggio..
- meccanismo
- Soddisfare
- Soddisfa
- menzionare
- Meta
- Metadati
- metodo
- verbale
- Ridurre la perdita dienergia con una
- modello
- modelli
- mensile
- Scopri di più
- maggior parte
- film
- Film
- molti
- multiplo
- Nome
- nomi
- Navigazione
- necessaria
- Bisogno
- Rete
- New
- GENERAZIONE
- no
- nodo
- taccuino
- computer portatili
- ottenuto
- ottobre
- of
- on
- ONE
- esclusivamente
- aprire
- open source
- Opzione
- or
- i
- Altro
- su
- delineato
- produzione
- uscite
- ancora
- Override
- proprio
- PACK
- pacchetto
- vetro
- Carta
- Parallel
- parametri
- Parigi
- parte
- sentiero
- percorsi
- Paga le
- Persone
- performance
- prestazioni
- esegue
- periodo
- petabyte
- Peter
- fotografo
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- trama
- punti
- Popolare
- Post
- alimentato
- pre
- precedente
- Preparare
- preparato
- primario
- processi
- elaborati
- lavorazione
- Produzione
- istruzioni
- fornire
- purché
- fornisce
- fornitura
- pubblicamente
- fini
- metti
- Python
- domanda
- domanda
- rapidamente
- Crudo
- dati grezzi
- raggiungendo
- Leggi
- pronto
- recente
- recentemente
- raccomandato
- record
- riferimento
- Riferimenti
- regolarmente
- rapporto
- rilasciato
- riparazione
- sostituire
- richieste
- necessario
- Requisiti
- Risorse
- risposta
- risposte
- colpevole
- Risultati
- recensioni
- Recensioni
- destra
- Ruolo
- rory
- Correre
- running
- corre
- sagemaker
- stesso
- Risparmi
- Scala
- bilancia
- scala
- scansioni
- scenario
- Scienze
- copione
- script
- secondo
- Sezione
- sezioni
- vedere
- segmento
- select
- AUTO
- anziano
- condanna
- serverless
- server
- Servizi
- set
- regolazione
- alcuni
- lei
- Corti
- dovrebbero
- mostrato
- significato
- simile
- da
- singolo
- site
- Taglia
- Rallenta
- frammento
- So
- soluzione
- Soluzioni
- zuppa
- Fonte
- Scintilla
- specialista
- specifico
- SQL
- SSH
- iniziato
- Di partenza
- dichiarazione
- dichiarazioni
- Stato dei servizi
- step
- Passi
- Ancora
- Fermare
- Tornare al suo account
- memorizzati
- negozi
- Storia
- lineare
- strategie
- Corda
- studio
- inviare
- la presentazione
- Con successo
- tale
- sufficiente
- adatto
- Interruttore
- sync.
- tavolo
- Fai
- Target
- Task
- task
- tensorflow
- condizioni
- test
- testo
- generazione di testo
- che
- I
- loro
- Li
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- di parti terze standard
- questo
- tre
- Attraverso
- tempo
- timestamp
- a
- pista
- Training
- viaggia
- vero
- prova
- seconda
- Tipi di
- per
- non strutturati
- aggiornato
- URL
- uso
- caso d'uso
- utilizzato
- Utente
- recensioni degli utenti
- utenti
- utilizzando
- Utilizzando
- versione
- virtuale
- volumi
- camminare
- volere
- ricercato
- Magazzino
- Prima
- Modo..
- modi
- we
- sito web
- servizi web
- settimana
- WELL
- Che
- quando
- mentre
- quale
- while
- OMS
- Natura
- volere
- william
- con
- entro
- senza
- donna
- lavorato
- valore
- scrivere
- scrittura
- dare la precedenza
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro