
Immagine da Adobe Firefly
“Eravamo troppi. Avevamo accesso a troppi soldi, troppe attrezzature e, a poco a poco, siamo impazziti”.
Francis Ford Coppola non stava creando una metafora per le aziende di intelligenza artificiale che spendono troppo e perdono la strada, ma avrebbe potuto esserlo. Apocalisse ora è stato epico ma anche un progetto lungo, difficile e costoso da realizzare, proprio come GPT-4. Suggerirei che lo sviluppo degli LLM abbia gravitato su troppi soldi e troppe attrezzature. E parte del clamore pubblicitario “abbiamo appena inventato l’intelligenza generale” è un po’ folle. Ma ora è il turno delle comunità open source di fare ciò che sanno fare meglio: fornire software competitivo e gratuito utilizzando molto meno denaro e attrezzature.
OpenAI ha assorbito finanziamenti per oltre 11 miliardi di dollari e si stima che GPT-3.5 costi dai 5 ai 6 milioni di dollari per ogni ciclo di formazione. Sappiamo molto poco di GPT-4 perché OpenAI non lo dice, ma penso che sia lecito ritenere che non sia più piccolo di GPT-3.5. Attualmente c’è una carenza di GPU a livello mondiale e, tanto per cambiare, non è a causa dell’ultima criptovaluta. Le start-up di intelligenza artificiale generativa stanno ottenendo round di serie A da oltre 100 milioni di dollari con valutazioni enormi quando non possiedono alcuna proprietà intellettuale per il LLM che utilizzano per alimentare il loro prodotto. Il carrozzone LLM è in marcia alta e il denaro scorre.
Sembrava che il dado fosse tratto: solo aziende dalle tasche profonde come Microsoft/OpenAI, Amazon e Google potevano permettersi di addestrare modelli di parametri da centinaia di miliardi. Si presumeva che i modelli più grandi fossero modelli migliori. GPT-3 ha qualcosa che non va? Aspetta solo che ci sia una versione più grande e andrà tutto bene! Le aziende più piccole che cercavano di competere dovevano raccogliere molto più capitale o essere costrette a costruire integrazioni di materie prime nel mercato ChatGPT. Il mondo accademico, con budget di ricerca ancora più limitati, è stato relegato ai margini.
Fortunatamente, un gruppo di persone intelligenti e di progetti open source hanno preso questo come una sfida piuttosto che come una restrizione. I ricercatori di Stanford hanno rilasciato Alpaca, un modello da 7 miliardi di parametri le cui prestazioni si avvicinano al modello da 3.5 miliardi di parametri di GPT-175. Non avendo le risorse per creare un set di formazione delle dimensioni utilizzate da OpenAI, hanno scelto abilmente di prendere un LLM open source addestrato, LLaMA, e di perfezionarlo invece su una serie di prompt e output GPT-3.5. Essenzialmente il modello ha imparato cosa fa GPT-3.5, il che risulta essere una strategia molto efficace per replicarne il comportamento.
Alpaca è concesso in licenza solo per uso non commerciale sia nel codice che nei dati poiché utilizza il modello LLaMA open source non commerciale e OpenAI vieta esplicitamente qualsiasi utilizzo delle sue API per creare prodotti concorrenti. Ciò crea l’allettante prospettiva di mettere a punto un diverso LLM open source sui suggerimenti e sull’output di Alpaca… creando un terzo modello simile a GPT-3.5 con diverse possibilità di licenza.
C’è un altro livello di ironia qui, in quanto tutti i principali LLM sono stati formati su testi e immagini protetti da copyright disponibili su Internet e non hanno pagato un centesimo ai titolari dei diritti. Le aziende rivendicano l’esenzione dal “fair use” ai sensi della legge statunitense sul copyright sostenendo che l’uso è “trasformativo”. Tuttavia, quando si tratta dell’output dei modelli che costruiscono con dati gratuiti, non vogliono davvero che nessuno faccia loro la stessa cosa. Mi aspetto che la situazione cambierà man mano che i detentori dei diritti si renderanno conto, e ad un certo punto potrebbero finire in tribunale.
Questo è un punto separato e distinto da quello sollevato dagli autori di licenze open source restrittive che, per prodotti AI for Code generativi come CoPilot, si oppongono all'utilizzo del loro codice per la formazione sulla base del fatto che la licenza non viene rispettata. Il problema per i singoli autori open source è che devono dimostrare di essere in piedi – ovvero di copiare in modo sostanziale – e di aver subito danni. E poiché i modelli rendono difficile collegare il codice di output all’input (le righe del codice sorgente dell’autore) e non vi è alcuna perdita economica (dovrebbe essere gratuito), è molto più difficile sostenere un caso. Questo è diverso dai creatori a scopo di lucro (ad esempio, i fotografi) il cui intero modello di business è nel concedere in licenza/vendere il proprio lavoro e che sono rappresentati da aggregatori come Getty Images che possono mostrare copie sostanziali.
Un'altra cosa interessante di LLaMA è che è uscito da Meta. Originariamente è stato rilasciato solo ai ricercatori e poi è trapelato tramite BitTorrent al mondo. Meta opera in un business fondamentalmente diverso da OpenAI, Microsoft, Google e Amazon in quanto non sta cercando di venderti servizi cloud o software, e quindi ha incentivi molto diversi. In passato ha reso open source i suoi progetti di elaborazione (OpenCompute) e ha visto la comunità migliorarli: comprende il valore dell'open source.
Meta potrebbe rivelarsi uno dei più importanti contributori di intelligenza artificiale open source. Non solo dispone di enormi risorse, ma trae vantaggio dalla proliferazione di una grande tecnologia di intelligenza artificiale generativa: ci saranno più contenuti da monetizzare sui social media. Meta ha rilasciato altri tre modelli di intelligenza artificiale open source: ImageBind (indicizzazione dei dati multidimensionali), DINOv2 (visione artificiale) e Segment Anything. Quest'ultimo identifica oggetti unici nelle immagini e viene rilasciato sotto la licenza Apache altamente permissiva.
Infine abbiamo anche avuto la presunta fuga di un documento interno di Google “We Have No Moat, and Neither Does OpenAI” che ha una visione negativa dei modelli chiusi rispetto all’innovazione delle comunità che producono modelli molto più piccoli ed economici che funzionano vicino o meglio di le loro controparti closed source. Dico presumibilmente perché non c'è modo di verificare che la fonte dell'articolo sia interna a Google. Tuttavia, contiene questo grafico avvincente:
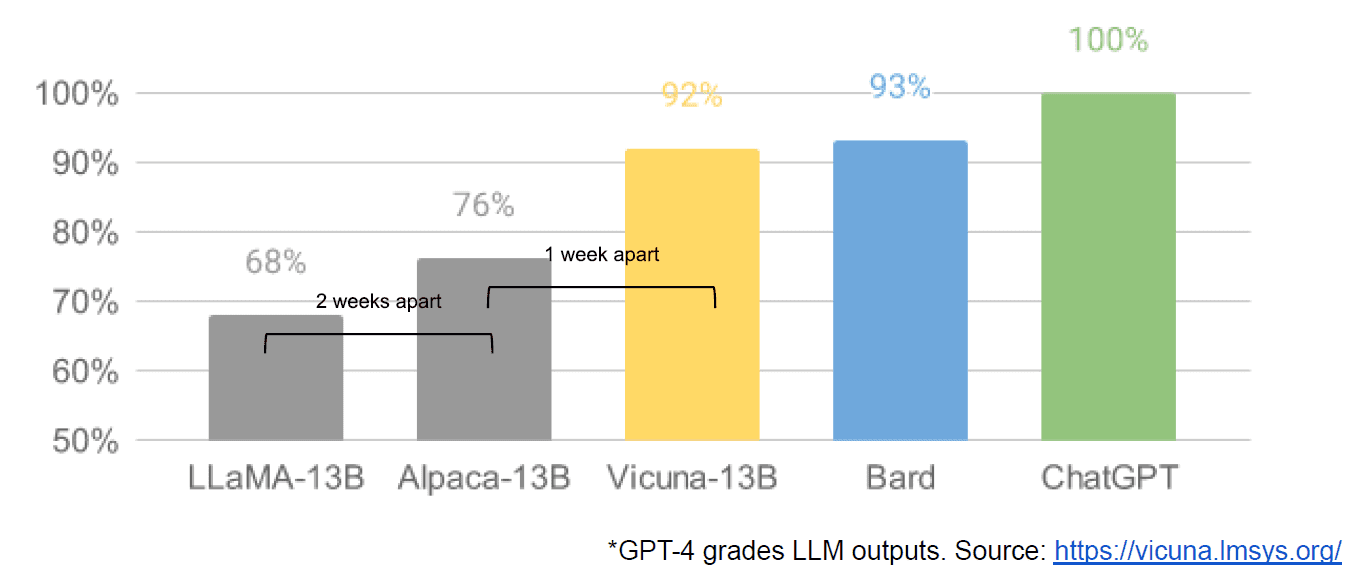
L'asse verticale è la valutazione degli output LLM da parte di GPT-4, per essere chiari.
Stable Diffusion, che sintetizza immagini dal testo, è un altro esempio di come l’intelligenza artificiale generativa open source sia stata in grado di avanzare più velocemente rispetto ai modelli proprietari. Una recente iterazione di quel progetto (ControlNet) lo ha migliorato in modo tale da superare le capacità di Dall-E2. Ciò è il risultato di un sacco di tentativi in tutto il mondo, che hanno portato a un ritmo di progresso difficile da eguagliare per qualsiasi singola istituzione. Alcuni di questi armeggiatori hanno capito come rendere Stable Diffusion più veloce da addestrare ed eseguire su hardware più economico, consentendo cicli di iterazione più brevi da parte di più persone.
E così abbiamo chiuso il cerchio. Non avere troppi soldi e troppe attrezzature ha ispirato un astuto livello di innovazione da parte di un’intera comunità di persone comuni. Che momento per essere uno sviluppatore di intelligenza artificiale.
Matteo Loggia è CEO di Diffblue, una startup AI For Code. Ha oltre 25 anni di esperienza diversificata nella leadership di prodotto presso aziende come Anaconda e VMware. Lodge fa attualmente parte del consiglio di amministrazione del Good Law Project ed è vicepresidente del consiglio di amministrazione della Royal Photographic Society.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Coniare il futuro con Adryenn Ashley. Accedi qui.
- Acquista e vendi azioni in società PRE-IPO con PREIPO®. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :ha
- :È
- :non
- :Dove
- $ SU
- 9
- a
- capace
- Chi siamo
- Accademia
- accesso
- Adobe
- avanzare
- Aggregatori
- AI
- Tutti
- presunta
- presumibilmente
- anche
- Amazon
- an
- ed
- Un altro
- in qualsiasi
- chiunque
- nulla
- Apache
- API
- SONO
- argomento
- articolo
- AS
- assunto
- At
- autore
- gli autori
- disponibile
- Axis
- BE
- perché
- stato
- essendo
- vantaggi
- MIGLIORE
- Meglio
- maggiore
- BitTorrent
- tavola
- entrambi
- Per i bilanci
- costruire
- Costruzione
- Mazzo
- affari
- modello di business
- ma
- by
- è venuto
- Materiale
- funzionalità
- capitale
- Custodie
- ceo
- Chair
- Challenge
- il cambiamento
- ChatGPT
- più economico
- ha scelto
- Cerchio
- rivendicare
- pulire campo
- Chiudi
- chiuso
- Cloud
- servizi cloud
- codice
- Venire
- viene
- merce
- Comunità
- comunità
- Aziende
- avvincente
- competere
- concorrenti
- Calcolare
- computer
- Visione computerizzata
- contenuto
- contributori
- copiatura
- copyright
- Costi
- potuto
- Corte
- creare
- Creazione
- creatori
- criptomoneta
- Attualmente
- cicli
- dati
- consegna
- vice
- disegni
- Costruttori
- Mercato
- *
- diverso
- difficile
- Emittente
- distinto
- paesaggio differenziato
- do
- documento
- effettua
- Dont
- e
- Economico
- Efficace
- consentendo
- fine
- Intero
- EPIC
- usate
- essenzialmente
- stimato
- Anche
- esempio
- attenderti
- costoso
- esperienza
- lontano
- più veloce
- capito
- fluente
- seguito
- Nel
- guado
- Gratis
- da
- pieno
- fondamentalmente
- finanziamento
- ingranaggio
- Generale
- generativo
- AI generativa
- buono
- GPU
- grafico
- grande
- ha avuto
- Hard
- Hardware
- Avere
- avendo
- he
- qui
- Alta
- vivamente
- titolari
- Come
- Tutorial
- Tuttavia
- HTTPS
- Enorme
- Montatura
- i
- identifica
- if
- immagini
- importante
- competenze
- migliorata
- in
- Incentive
- individuale
- Innovazione
- ingresso
- INSANE
- fonte di ispirazione
- invece
- Istituzione
- integrazioni
- interessante
- interno
- Internet
- Inventato
- IP
- ironia
- IT
- iterazione
- SUO
- ad appena
- KDnuggets
- Sapere
- atterraggio
- con i più recenti
- Legge
- strato
- Leadership
- imparato
- a sinistra
- meno
- Livello
- Licenza
- Autorizzato
- Licenze
- piace
- Linee
- LINK
- piccolo
- Lama
- Lunghi
- guardò
- cerca
- perdere
- spento
- lotto
- maggiore
- make
- Fare
- molti
- mercato
- massiccio
- partita
- Maggio..
- Media
- Meta
- Microsoft
- modello
- modelli
- monetizzare
- soldi
- Scopri di più
- maggior parte
- molti
- Bisogno
- Nessuno dei due
- no
- non commerciale
- adesso
- oggetto
- oggetti
- of
- on
- ONE
- esclusivamente
- aprire
- open source
- progetti open source
- OpenAI
- or
- ordinario
- originariamente
- Altro
- su
- produzione
- ancora
- proprio
- Pace
- parametro
- passato
- Paga le
- Persone
- eseguire
- performance
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- possibilità
- energia
- Problema
- Prodotto
- Prodotti
- progetto
- progetti
- proprio
- prospettiva
- aumentare
- sollevato
- piuttosto
- veramente
- recente
- rilasciato
- rappresentato
- riparazioni
- ricercatori
- Risorse
- restrizione
- risultante
- diritti
- round
- reale
- Correre
- s
- sicura
- stesso
- dire
- visto
- segmento
- venda
- separato
- Serie
- Serie A
- serve
- Servizi
- set
- carenza
- mostrare attraverso le sue creazioni
- da
- singolo
- Taglia
- inferiore
- smart
- So
- Social
- Social Media
- Società
- Software
- alcuni
- qualcosa
- Fonte
- codice sorgente
- spendere
- stabile
- stanford
- start-up
- startup
- Strategia
- tale
- suggerire
- suppone
- superato
- Fai
- preso
- prende
- Tecnologia
- di
- che
- I
- L’ORIGINE
- il mondo
- loro
- Li
- poi
- Là.
- di
- cosa
- think
- Terza
- questo
- quelli
- tre
- tempo
- a
- pure
- ha preso
- Treni
- allenato
- Training
- TURNO
- si
- per
- capisce
- unico
- a differenza di
- fino a quando
- us
- uso
- utilizzato
- usa
- utilizzando
- valutazioni
- APPREZZIAMO
- verificare
- versione
- verticale
- molto
- via
- Visualizza
- visione
- vmware
- vs
- aspettare
- volere
- Prima
- Modo..
- we
- è andato
- sono stati
- Che
- quando
- quale
- OMS
- tutto
- di chi
- volere
- WISE
- con
- Lavora
- mondo
- Wrong
- Tu
- zefiro









