Amazon RedShift, un data warehouse sul cloud ampiamente utilizzato, si è evoluto in modo significativo per soddisfare i requisiti prestazionali dei carichi di lavoro più impegnativi. Questo post tratta una di queste nuove funzionalità: la chiave di ordinamento del layout dei dati multidimensionali.
Amazon Redshift ora migliora le prestazioni delle query supportando le chiavi di ordinamento del layout dei dati multidimensionali, ovvero un nuovo tipo di chiave di ordinamento che ordina i dati di una tabella in base ai predicati di filtro anziché alle colonne fisiche della tabella. Le chiavi di ordinamento del layout dei dati multidimensionali miglioreranno in modo significativo le prestazioni delle scansioni delle tabelle, soprattutto quando il carico di lavoro delle query contiene filtri di scansione ripetitivi.
Amazon Redshift offre già la funzionalità di ottimizzazione automatica della tabella (ATO), che ottimizza automaticamente la progettazione delle tabelle applicando chiavi di ordinamento e distribuzione senza la necessità dell'intervento dell'amministratore. In questo post presentiamo le chiavi di ordinamento del layout dei dati multidimensionali come funzionalità aggiuntiva offerta da ATO e rafforzata dall'algoritmo del consulente delle chiavi di ordinamento di Amazon Redshift.
Chiavi di ordinamento del layout dei dati multidimensionali
Quando definisci una tabella con la chiave di ordinamento AUTO, Amazon Redshift ATO analizzerà la cronologia delle query e selezionerà automaticamente una chiave di ordinamento a colonna singola o una chiave di ordinamento di layout dati multidimensionale per la tabella, in base all'opzione migliore per il tuo carico di lavoro. Quando viene selezionato il layout dei dati multidimensionali, Amazon Redshift costruirà una funzione di ordinamento multidimensionale che co-localizza le righe a cui in genere accedono le stesse query e la funzione di ordinamento viene successivamente utilizzata durante l'esecuzione delle query per ignorare i blocchi di dati e persino evitare la scansione del singolo predicato colonne.
Considera la seguente query utente, che è un modello di query dominante nel carico di lavoro dell'utente:
Amazon Redshift archivia i dati per ciascuna colonna in blocchi del disco da 1 MB e archivia i valori minimo e massimo in ciascun blocco come parte dei metadati della tabella. Se una query utilizza a predicato con intervallo limitato, Amazon Redshift può utilizzare i valori minimo e massimo per saltare rapidamente un gran numero di blocchi durante le scansioni delle tabelle. Tuttavia, il filtro di questa query sulla colonna della sottoregione non può essere utilizzato per determinare quali blocchi ignorare in base ai valori minimo e massimo e, di conseguenza, Amazon Redshift esegue la scansione di tutte le righe dalla tabella dei titoli:
Quando è stata eseguita la query dell'utente con titles utilizzando una chiave di ordinamento a colonna singola attiva subregion, il risultato della query precedente è il seguente:
Ciò mostra che la scansione della tabella ha letto 2,164,081,640 righe.
Per migliorare le scansioni su titles tabella, Amazon Redshift potrebbe decidere automaticamente di utilizzare una chiave di ordinamento del layout dati multidimensionale. Tutte le righe che soddisfano il lower(subregion) like '%United States%' Il predicato verrebbe collocato in una regione dedicata della tabella e pertanto Amazon Redshift analizzerà solo i blocchi di dati che soddisfano il predicato.
Quando la query dell'utente viene eseguita con titles utilizzando una chiave di ordinamento del layout dati multidimensionale che include lower(subregion) like '%United States%' come predicato, il risultato di sys_query_detail la domanda è la seguente:
Ciò dimostra che la scansione della tabella ha letto 152,324,046 righe, ovvero solo il 7% dell'originale, e ha utilizzato la chiave di ordinamento del layout dei dati multidimensionali.
Tieni presente che questo esempio utilizza una singola query per mostrare la funzionalità di layout dei dati multidimensionali, ma Amazon Redshift prenderà in considerazione tutte le query eseguite sulla tabella e potrà creare più regioni per soddisfare i predicati eseguiti più comunemente.
Prendiamo un altro esempio, questa volta con predicati più complessi e query multiple.
Immagina di avere un tavolo items (cost int, available int, demand int) con quattro righe come mostrato nell'esempio seguente.
| #ID | costo | disponibile | domanda |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Il tuo carico di lavoro dominante è costituito da due query:
- Modello di query al 70%:
- Modello di query al 20%:
Con le tecniche di ordinamento tradizionali, potresti scegliere di ordinare la tabella in base alla colonna dei costi, in modo tale che la valutazione di cost > 3 trarranno beneficio da questo ordinamento. Quindi, la tabella degli articoli dopo l'ordinamento utilizza un singolo cost la colonna sarà simile alla seguente.
| #ID | costo | disponibile | domanda |
| Regione n. 1, con costo <= 3 | |||
| Regione n. 2, con costo > 3 | |||
| #ID | costo | disponibile | domanda |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Utilizzando questo ordinamento tradizionale, possiamo escludere immediatamente le prime due righe (blu) con ID 4 e ID 2, perché non soddisfano cost > 3.
D'altro canto, con una chiave di ordinamento del layout dati multidimensionale, la tabella verrà ordinata in base a una combinazione dei due predicati comunemente presenti nel carico di lavoro dell'utente, che sono cost > 3 ed available < demand. Di conseguenza, le righe della tabella vengono ordinate in quattro regioni.
| #ID | costo | disponibile | domanda |
| Regione n. 1, con costo <= 3 e disponibilità < domanda | |||
| Regione n. 2, con costo <= 3 e disponibilità >= domanda | |||
| Regione n. 3, con costo > 3 e disponibilità < domanda | |||
| Regione n. 4, con costo > 3 e disponibilità >= domanda | |||
| #ID | costo | disponibile | domanda |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Questo concetto è ancora più potente se applicato a interi blocchi invece che a singole righe, se applicato a predicati complessi che utilizzano operatori non adatti alle tradizionali tecniche di ordinamento (come like) e quando applicato a più di due predicati.
Tabelle di sistema
Le seguenti tabelle di sistema Amazon Redshift mostreranno agli utenti se nelle tabelle e nelle query vengono utilizzati layout di dati multidimensionali:
- Per determinare se una determinata tabella utilizza una chiave di ordinamento del layout dati multidimensionale, è possibile verificare se
sortkey1in svv_tabella_info è uguale aAUTO(SORTKEY(padb_internal_mddl_key_col)). - Per determinare se una particolare query utilizza un layout di dati multidimensionali per accelerare le scansioni delle tabelle, puoi controllare
step_attributenel sys_query_detail visualizzazione. Il valore sarà uguale amulti-dimensionalse durante la scansione è stata utilizzata la chiave di ordinamento del layout dei dati multidimensionali della tabella.
Benchmark delle prestazioni
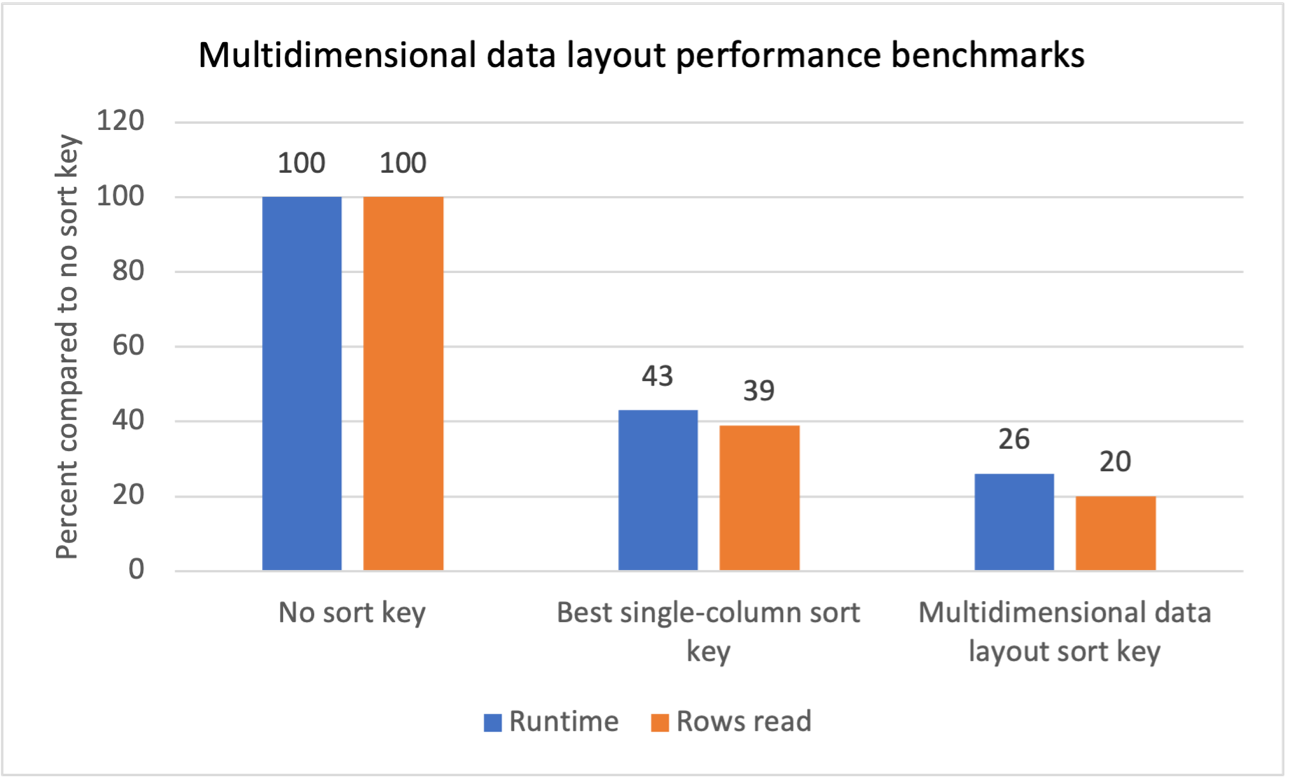
Abbiamo eseguito test di benchmark interni per più carichi di lavoro con filtri di scansione ripetitivi e abbiamo riscontrato che l'introduzione di chiavi di ordinamento del layout dei dati multidimensionali ha prodotto i seguenti risultati:
- Una riduzione totale del tempo di esecuzione del 74% rispetto all'assenza di una chiave di ordinamento.
- Una riduzione del tempo di esecuzione totale del 40% rispetto alla migliore chiave di ordinamento a colonna singola su ciascuna tabella.
- Una riduzione dell'80% del numero totale di righe lette dalle tabelle rispetto all'assenza di una chiave di ordinamento.
- Una riduzione del 47% del numero totale di righe lette dalle tabelle rispetto alla migliore chiave di ordinamento a colonna singola su ciascuna tabella.
Confronto delle funzionalità
Con l'introduzione delle chiavi di ordinamento del layout dei dati multidimensionali, le tabelle possono ora essere ordinate in base alle espressioni in base ai predicati di filtro comunemente presenti nel carico di lavoro. La tabella seguente fornisce un confronto delle funzionalità di Amazon Redshift rispetto a due concorrenti.
| caratteristica | Amazon RedShift | Concorrente A | Concorrente B |
| Supporto per l'ordinamento in colonne | Sì | Sì | Sì |
| Supporto per l'ordinamento per espressione | Sì | Sì | Non |
| Selezione automatica delle colonne per l'ordinamento | Sì | Non | Sì |
| Selezione automatica delle espressioni per l'ordinamento | Sì | Non | Non |
| Selezione automatica tra l'ordinamento delle colonne o l'ordinamento delle espressioni | Sì | Non | Non |
| Utilizzo automatico delle proprietà di ordinamento per le espressioni durante le scansioni | Sì | Non | Non |
Considerazioni
Tieni presente quanto segue quando utilizzi un layout di dati multidimensionali:
- Il layout dei dati multidimensionali è abilitato quando imposti la tabella come SORTKEY AUTO.
- Amazon Redshift Advisor sceglierà automaticamente una chiave di ordinamento a colonna singola o un layout di dati multidimensionali per la tabella analizzando il carico di lavoro storico.
- Amazon Redshift ATO regola i risultati dell'ordinamento del layout dei dati multidimensionali in base al modo in cui le query in corso interagiscono con il carico di lavoro.
- Amazon Redshift ATO mantiene le chiavi di ordinamento del layout dei dati multidimensionali nello stesso modo in cui lo fa attualmente per le chiavi di ordinamento esistenti. Fare riferimento a Lavorare con l'ottimizzazione automatica della tabella per maggiori dettagli sull'ATO.
- Le chiavi di ordinamento del layout dei dati multidimensionali funzioneranno sia con i cluster forniti che con i gruppi di lavoro serverless.
- Le chiavi di ordinamento del layout dei dati multidimensionali funzioneranno con i dati esistenti purché AUTO SORTKEY sia abilitato sulla tabella e venga rilevato un carico di lavoro con filtri di scansione ripetitivi. La tabella verrà riorganizzata in base ai risultati della funzione di ordinamento multidimensionale.
- Per disabilitare le chiavi di ordinamento del layout dei dati multidimensionali per una tabella, utilizzare alter table:
ALTER TABLE table_name ALTER SORTKEY NONE. Ciò disabilita la funzionalità del tasto di ordinamento AUTO sulla tabella. - Le chiavi di ordinamento del layout dei dati multidimensionali vengono conservate durante il ripristino o la migrazione del cluster sottoposto a provisioning in un cluster serverless o viceversa.
Conclusione
In questo post abbiamo dimostrato che le chiavi di ordinamento del layout dei dati multidimensionali possono migliorare significativamente le prestazioni di runtime delle query per carichi di lavoro in cui le query dominanti hanno filtri di scansione ripetitivi.
Per creare un cluster di anteprima dalla console Amazon Redshift, vai al file Cluster pagina e scegli Crea cluster di anteprima. Puoi creare un cluster nelle regioni Stati Uniti orientali (Ohio), Stati Uniti orientali (Virginia settentrionale), Stati Uniti occidentali (Oregon), Asia Pacifico (Tokyo), Europa (Irlanda) ed Europa (Stoccolma) e testare i tuoi carichi di lavoro.
Ci piacerebbe sentire il tuo feedback su questa nuova funzionalità e attendiamo con ansia i tuoi commenti su questo post.
Circa gli autori
 Gentile Oke è un Data Warehouse Specialist Solutions Architect con sede a New York. Costruisce soluzioni di data warehouse da oltre 15 anni ed è specializzato in Amazon Redshift.
Gentile Oke è un Data Warehouse Specialist Solutions Architect con sede a New York. Costruisce soluzioni di data warehouse da oltre 15 anni ed è specializzato in Amazon Redshift.
 Jialin Ding è uno scienziato applicato nel Learned Systems Group, specializzato nell'applicazione di tecniche di machine learning e ottimizzazione per migliorare le prestazioni dei sistemi dati come Amazon Redshift.
Jialin Ding è uno scienziato applicato nel Learned Systems Group, specializzato nell'applicazione di tecniche di machine learning e ottimizzazione per migliorare le prestazioni dei sistemi dati come Amazon Redshift.
 Yanzu Ji è un Product Manager nel team di Amazon Redshift. Ha esperienza nella visione del prodotto e nella strategia in prodotti e piattaforme di dati leader del settore. Ha un'eccezionale abilità nella creazione di prodotti software sostanziali utilizzando tecniche di sviluppo web, progettazione di sistemi, database e programmazione distribuita. Nella sua vita personale, a Yanzhu piace dipingere, fotografare e giocare a tennis.
Yanzu Ji è un Product Manager nel team di Amazon Redshift. Ha esperienza nella visione del prodotto e nella strategia in prodotti e piattaforme di dati leader del settore. Ha un'eccezionale abilità nella creazione di prodotti software sostanziali utilizzando tecniche di sviluppo web, progettazione di sistemi, database e programmazione distribuita. Nella sua vita personale, a Yanzhu piace dipingere, fotografare e giocare a tennis.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :ha
- :È
- :non
- :Dove
- 1
- 100
- 15 anni
- 15%
- 152
- 7
- 8
- 9
- a
- accelerare
- accessibile
- aggiuntivo
- consulente
- Dopo shavasana, sedersi in silenzio; saluti;
- contro
- algoritmo
- Tutti
- già
- Amazon
- Amazon Web Services
- an
- analizzare
- l'analisi
- ed
- Un altro
- applicato
- AMMISSIONE
- SONO
- AS
- Asia
- asia pacifico
- auto
- Automatico
- automaticamente
- disponibile
- AWS
- basato
- BE
- perché
- stato
- Segno di riferimento
- beneficio
- MIGLIORE
- Meglio
- fra
- Bloccare
- Blocchi
- Blu
- entrambi
- Costruzione
- ma
- by
- Materiale
- capacità
- dai un'occhiata
- Scegli
- Cloud
- Cluster
- Colonna
- colonne
- combinazione
- Commenti
- comunemente
- rispetto
- confronto
- concorrenti
- complesso
- concetto
- Prendere in considerazione
- consiste
- consolle
- costruire
- contiene
- Costo
- copre
- creare
- Attualmente
- dati
- data warehouse
- Banca Dati
- decide
- dedicato
- definire
- Richiesta
- esigente
- Design
- dettagli
- rilevato
- Determinare
- Mercato
- distribuito
- distribuzione
- effettua
- dominante
- Dont
- durante
- ogni
- est
- o
- abilitato
- Intero
- pari
- particolarmente
- Etere (ETH)
- Europa
- valutazione
- Anche
- si è evoluta
- esempio
- esistente
- esperienza
- espressioni
- caratteristica
- feedback
- filtro
- filtri
- i seguenti
- segue
- Nel
- Avanti
- quattro
- da
- function
- Gruppo
- cura
- Avere
- avendo
- he
- sentire
- suo
- storico
- storia
- Tuttavia
- HTML
- HTTPS
- ID
- if
- subito
- competenze
- migliora
- in
- inclusi
- individuale
- leader del settore
- invece
- interagire
- interno
- intervento
- ai miglioramenti
- introdurre
- l'introduzione di
- Introduzione
- Irlanda
- IT
- elementi
- Le
- Tasti
- grandi
- disposizione
- imparato
- apprendimento
- Vita
- piace
- piace
- Lunghi
- Guarda
- una
- amore
- macchina
- machine learning
- mantiene
- direttore
- modo
- massimo
- Soddisfare
- Metadati
- forza
- la migrazione
- mente
- ordine
- Scopri di più
- maggior parte
- multiplo
- Navigare
- Bisogno
- New
- nuova funzione
- New York
- no
- adesso
- numeri
- verificano
- of
- MENO
- offerto
- Ohio
- on
- ONE
- in corso
- esclusivamente
- Operatori
- ottimizzazione
- Ottimizza
- Opzione
- or
- minimo
- Oregon
- i
- Altro
- su
- eccezionale
- ancora
- Pacifico
- pittura
- parte
- particolare
- Cartamodello
- performance
- eseguita
- cronologia
- fotografia
- Fisico
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- Post
- potente
- conservato
- Anteprima
- Prodotto
- Prodotto
- product manager
- Prodotti
- Programmazione
- proprietà
- fornisce
- query
- rapidamente
- Leggi
- riduzione
- riferimento
- regione
- regioni
- ripetitivo
- Requisiti
- il ripristino
- colpevole
- Risultati
- Correre
- running
- corre
- stesso
- scansione
- scansione
- scansioni
- Scienziato
- Stagione
- vedere
- select
- selezionato
- prodotti
- serverless
- Servizi
- set
- lei
- mostrare attraverso le sue creazioni
- vetrina
- ha mostrato
- mostrato
- Spettacoli
- significativamente
- singolo
- abilità
- So
- Software
- Soluzioni
- specialista
- specializzata
- specializzata
- negozi
- Strategia
- Successivamente
- sostanziale
- tale
- adatto
- Supporto
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- team
- tecniche
- tennis
- test
- Testing
- di
- che
- Il
- loro
- perciò
- di
- questo
- tempo
- titoli
- a
- Tokyo
- top
- Totale
- tradizionale
- seconda
- Digitare
- tipicamente
- us
- uso
- utilizzato
- Utente
- utenti
- usa
- utilizzando
- APPREZZIAMO
- Valori
- vice
- Visualizza
- Virginia
- visione
- Magazzino
- Prima
- Modo..
- we
- sito web
- Sviluppo Web
- servizi web
- ovest
- quando
- se
- quale
- ampiamente
- volere
- con
- senza
- Lavora
- sarebbe
- anni
- York
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro