Immagine dell'editore
Il 14 marzo 2023, OpenAI ha lanciato GPT-4, la versione più recente e potente del proprio modello linguistico.
A poche ore dal suo lancio, GPT-4 ha sbalordito le persone girando a schizzo disegnato a mano in un sito web funzionale, superare l'esame di abilitazionee generare riassunti accurati degli articoli di Wikipedia.
Supera anche il suo predecessore, GPT-3.5, nella risoluzione di problemi matematici e nel rispondere a domande basate sulla logica e sul ragionamento.
ChatGPT, il chatbot costruito su GPT-3.5 e rilasciato al pubblico, era noto per le sue "allucinazioni". Genererebbe risposte apparentemente corrette e difenderebbe le sue risposte con "fatti", anche se carichi di errori.
Un utente è andato su Twitter dopo che il modello ha insistito sul fatto che le uova di elefante erano i più grandi di tutti gli animali terrestri:
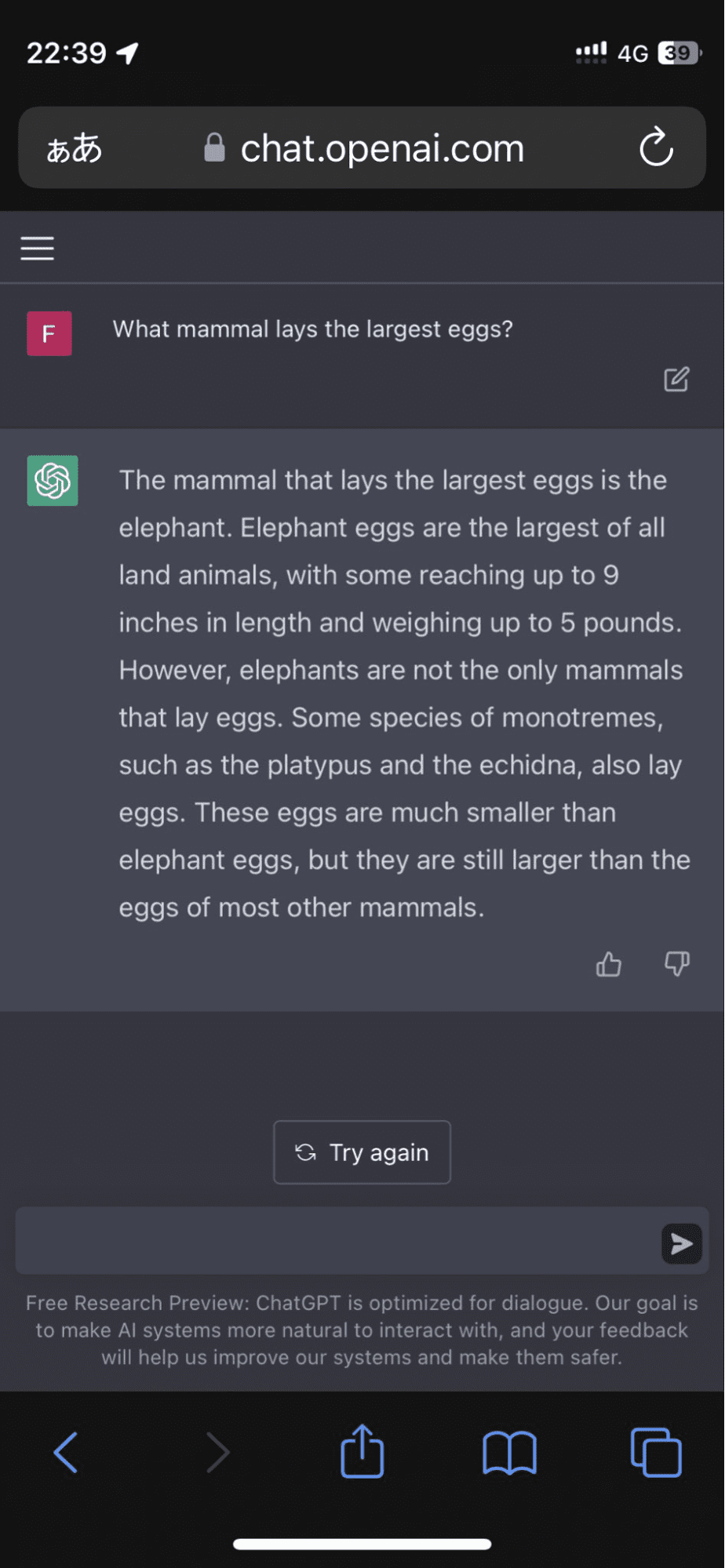
Immagine da FioraAeterna
E non si è fermato qui. L'algoritmo ha continuato a confermare la sua risposta con fatti inventati che mi hanno quasi convinto per un momento.
GPT-4, d'altra parte, è stato addestrato ad "allucinare" meno spesso. L'ultimo modello di OpenAI è più difficile da ingannare e non genera con sicurezza falsità così frequentemente.
In qualità di data scientist, il mio lavoro mi richiede di trovare fonti di dati pertinenti, pre-elaborare set di dati di grandi dimensioni e creare modelli di machine learning altamente accurati che promuovano il valore aziendale.
Trascorro gran parte della mia giornata estraendo dati da diversi formati di file e consolidandoli in un unico posto.
Dopo il lancio di ChatGPT nel novembre 2022, mi sono rivolto al chatbot per avere indicazioni sui miei flussi di lavoro quotidiani. Ho utilizzato lo strumento per risparmiare la quantità di tempo spesa in lavori umili, in modo da potermi concentrare invece sull'elaborazione di nuove idee e sulla creazione di modelli migliori.
Una volta rilasciato GPT-4, ero curioso di sapere se avrebbe fatto la differenza nel lavoro che stavo facendo. Ci sono stati vantaggi significativi nell'utilizzo di GPT-4 rispetto ai suoi predecessori? Mi aiuterebbe a risparmiare più tempo di quanto non fossi già con GPT-3.5?
In questo articolo, ti mostrerò come utilizzo ChatGPT per automatizzare i flussi di lavoro di data science.
Creerò gli stessi prompt e li inserirò sia in GPT-4 che in GPT-3.5, per vedere se il primo funziona davvero meglio e si traduce in un maggiore risparmio di tempo.
Se desideri seguire tutto ciò che faccio in questo articolo, devi avere accesso a GPT-4 e GPT-3.5.
GPT-3.5
GPT-3.5 è pubblicamente disponibile sul sito web di OpenAI. Basta navigare verso https://chat.openai.com/auth/login, compila i dati richiesti e avrai accesso al modello linguistico:
Immagine da ChatGPT
GPT-4
GPT-4, d'altra parte, è attualmente nascosto dietro un paywall. Per accedere al modello, è necessario eseguire l'upgrade a ChatGPTPlus facendo clic su "Aggiorna a Plus".
C'è una quota di abbonamento mensile di $ 20 al mese che può essere annullata in qualsiasi momento:
Immagine da ChatGPT
Se non vuoi pagare la quota di abbonamento mensile, puoi anche iscriverti al Lista d'attesa dell'API per GPT-4. Una volta ottenuto l'accesso all'API, puoi seguire questo guida per usarlo in Python.
Va bene se al momento non hai accesso a GPT-4.
Puoi comunque seguire questo tutorial con la versione gratuita di ChatGPT che utilizza GPT-3.5 nel back-end.
1. Visualizzazione dei dati
Quando si esegue un'analisi esplorativa dei dati, la generazione di una rapida visualizzazione in Python spesso mi aiuta a comprendere meglio il set di dati.
Sfortunatamente, questa attività può richiedere molto tempo, soprattutto quando non si conosce la sintassi corretta da utilizzare per ottenere il risultato desiderato.
Mi ritrovo spesso a cercare nell'ampia documentazione di Seaborn e ad utilizzare StackOverflow per generare un singolo grafico Python.
Vediamo se ChatGPT può aiutare a risolvere questo problema.
Useremo il Diabete degli indiani Pima set di dati in questa sezione. Puoi scaricare il set di dati se desideri seguire i risultati generati da ChatGPT.
Dopo aver scaricato il dataset, carichiamolo in Python utilizzando la libreria Pandas e stampiamo l'head del dataframe:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
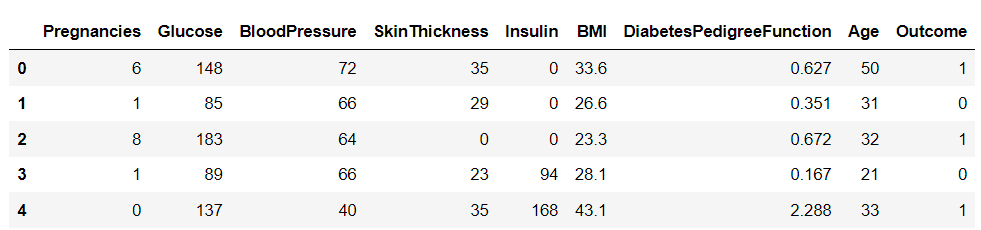
Ci sono nove variabili in questo set di dati. Uno di questi, "Risultato", è la variabile target che ci dice se una persona svilupperà il diabete. Le restanti sono variabili indipendenti utilizzate per prevedere il risultato.
Va bene! Quindi voglio vedere quali di queste variabili hanno un impatto sul fatto che una persona svilupperà il diabete.
Per raggiungere questo obiettivo, possiamo creare un grafico a barre raggruppato per visualizzare la variabile "Diabete" in tutte le variabili dipendenti nel set di dati.
Questo è in realtà abbastanza facile da codificare, ma iniziamo in modo semplice. Passeremo a suggerimenti più complicati man mano che avanziamo nell'articolo.
Visualizzazione dei dati con GPT-3.5
Poiché ho un abbonamento a pagamento a ChatGPT, lo strumento mi consente di selezionare il modello sottostante che vorrei utilizzare ogni volta che vi accedo.
Selezionerò GPT-3.5:
Immagine da ChatGPT Plus
Se non disponi di un abbonamento, puoi utilizzare la versione gratuita di ChatGPT poiché il chatbot utilizza GPT-3.5 per impostazione predefinita.
Digitiamo ora il prompt seguente per generare una visualizzazione utilizzando il dataset del diabete:
Ho un set di dati con 8 variabili indipendenti e 1 variabile dipendente. La variabile dipendente, "Risultato", ci dice se una persona svilupperà il diabete.
Le variabili indipendenti "Gravidanze", "Glucosio", "Pressione sanguigna", "Spessore della pelle", "Insulina", "IMC", "Funzione pedigree del diabete" e "Età" vengono utilizzate per prevedere questo risultato.
Puoi generare codice Python per visualizzare tutte queste variabili indipendenti in base al risultato? L'output dovrebbe essere un grafico a barre raggruppato colorato dalla variabile "Risultato". Dovrebbero esserci 16 barre in totale, 2 per ciascuna variabile indipendente.
Ecco la risposta del modello alla richiesta precedente:
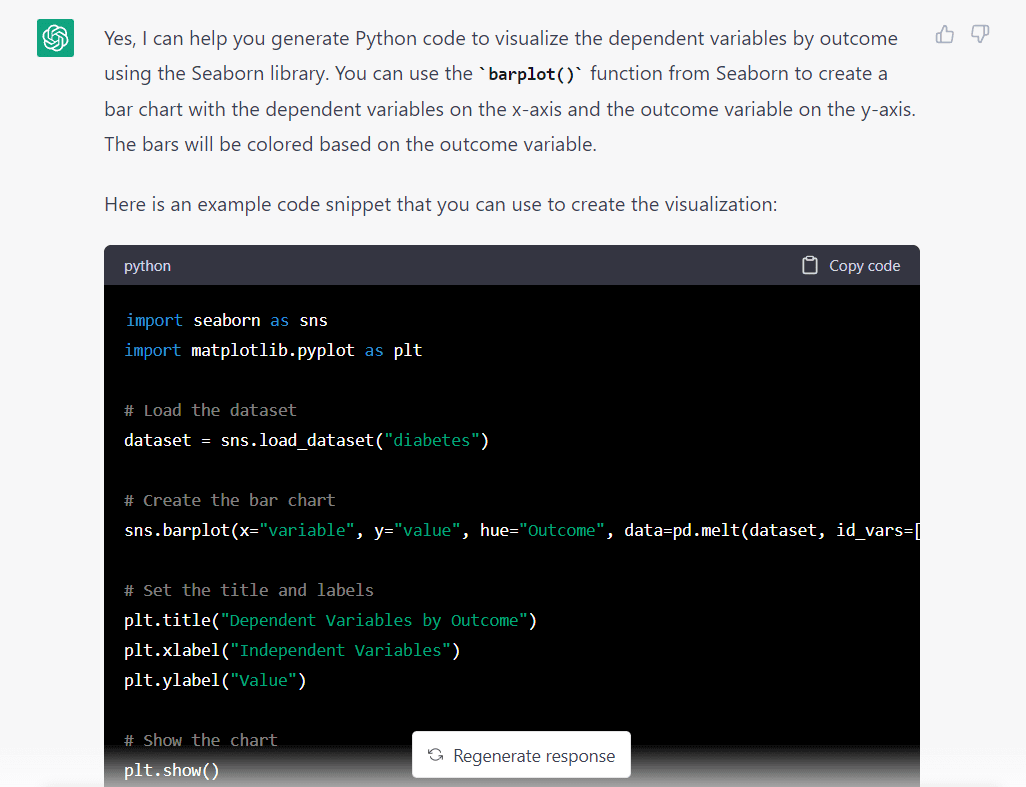
Una cosa che salta subito all'occhio è che il modello presupponeva che volessimo importare un set di dati da Seaborn. Probabilmente ha fatto questa ipotesi poiché gli abbiamo chiesto di utilizzare la libreria Seaborn.
Questo non è un grosso problema, dobbiamo solo cambiare una riga prima di eseguire i codici.
Ecco lo snippet di codice completo generato da GPT-3.5:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
Puoi copiarlo e incollarlo nel tuo IDE Python.
Ecco il risultato generato dopo aver eseguito il codice precedente:
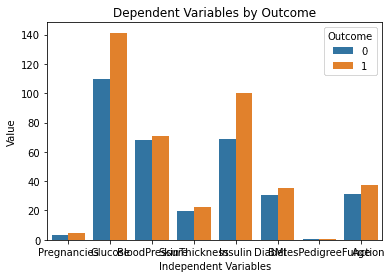
Questo grafico sembra perfetto! È esattamente come l'ho immaginato quando ho digitato il prompt in ChatGPT.
Un problema che spicca, tuttavia, è che il testo su questo grafico si sovrappone. Chiederò al modello se può aiutarci a risolvere questo problema, digitando il seguente prompt:
L'algoritmo ha spiegato che potremmo evitare questa sovrapposizione ruotando le etichette del grafico o regolando la dimensione della figura. Ha anche generato un nuovo codice per aiutarci a raggiungere questo obiettivo.
Eseguiamo questo codice per vedere se ci dà i risultati desiderati:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
Le righe di codice precedenti dovrebbero generare il seguente output:
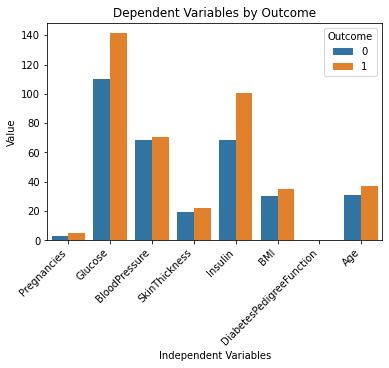
Sembra fantastico!
Capisco molto meglio il set di dati ora semplicemente guardando questo grafico. Sembra che le persone con livelli più elevati di glucosio e insulina abbiano maggiori probabilità di sviluppare il diabete.
Inoltre, si noti che la variabile "DiabetesPedigreeFunction" non ci fornisce alcuna informazione in questo grafico. Questo perché la funzione è su una scala più piccola (tra 0 e 2.4). Se desideri sperimentare ulteriormente con ChatGPT, puoi chiedergli di generare più sottotrame all'interno di un singolo grafico per risolvere questo problema.
Visualizzazione dei dati con GPT-4
Ora inseriamo le stesse richieste in GPT-4 per vedere se otteniamo una risposta diversa. Selezionerò il modello GPT-4 all'interno di ChatGPT e digiterò lo stesso prompt di prima:
Nota come GPT-4 non presuppone che utilizzeremo un dataframe integrato in Seaborn.
Ci dice che utilizzerà un dataframe chiamato "df" per costruire la visualizzazione, che è un miglioramento rispetto alla risposta generata da GPT-3.5.
Ecco il codice completo generato da questo algoritmo:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
Il codice sopra dovrebbe generare il seguente grafico:
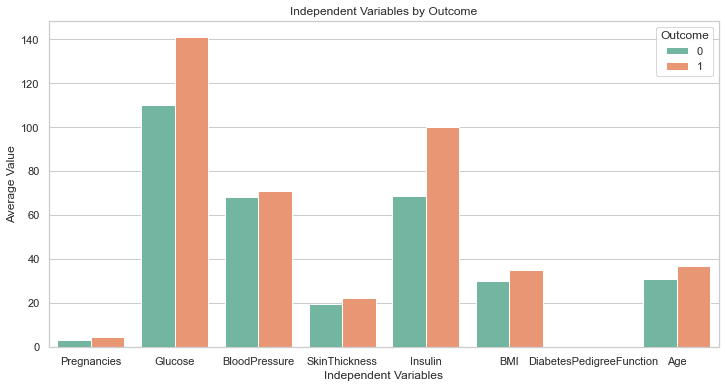
Questo è perfetto!
Anche se non l'abbiamo chiesto, GPT-4 ha incluso una riga di codice per aumentare le dimensioni del grafico. Le etichette su questo grafico sono tutte chiaramente visibili, quindi non dobbiamo tornare indietro e modificare il codice come abbiamo fatto in precedenza.
Questo è un gradino sopra la risposta generata da GPT-3.5.
Nel complesso, tuttavia, sembra che GPT-3.5 e GPT-4 siano entrambi efficaci nel generare codice per eseguire attività come la visualizzazione e l'analisi dei dati.
È importante notare che poiché non è possibile caricare dati nell'interfaccia di ChatGPT, è necessario fornire al modello una descrizione accurata del set di dati per ottenere risultati ottimali.
2. Lavorare con documenti PDF
Sebbene questo non sia un caso d'uso comune della scienza dei dati, ho dovuto estrarre dati di testo da centinaia di file PDF per creare un modello di analisi del sentimento una volta. I dati non erano strutturati e ho passato molto tempo a estrarli e preelaborarli.
Lavoro spesso anche con ricercatori che leggono e creano contenuti su eventi attuali che si svolgono in settori specifici. Devono rimanere aggiornati sulle notizie, analizzare i rapporti aziendali e leggere le potenziali tendenze del settore.
Invece di leggere 100 pagine del rapporto di un'azienda, non è più semplice estrarre semplicemente le parole che ti interessano e leggere solo le frasi che contengono quelle parole chiave?
Oppure, se sei interessato alle tendenze, puoi creare un flusso di lavoro automatizzato che mostri la crescita delle parole chiave nel tempo invece di esaminare ogni rapporto manualmente.
In questa sezione, utilizzeremo ChatGPT per analizzare i file PDF in Python. Chiederemo al chatbot di estrarre il contenuto di un file PDF e di scriverlo in un file di testo.
Ancora una volta, questo verrà fatto utilizzando sia GPT-3.5 che GPT-4 per vedere se c'è una differenza significativa nel codice generato.
Leggere file PDF con GPT-3.5
In questa sezione, analizzeremo un documento PDF pubblicamente disponibile intitolato Una breve introduzione all'apprendimento automatico per ingegneri. Assicurati di scaricare questo file se desideri codificare insieme a questa sezione.
Innanzitutto, chiediamo all'algoritmo di generare codice Python per estrarre i dati da questo documento PDF e salvarlo in un file di testo:
Ecco il codice completo fornito dall'algoritmo:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(Nota: assicurati di cambiare il nome del file PDF con quello che hai salvato prima di eseguire questo codice.)
Sfortunatamente, dopo aver eseguito il codice generato da GPT-3.5, ho riscontrato il seguente errore Unicode:

Torniamo a GPT-3.5 e vediamo se il modello può risolvere questo problema:
Ho incollato l'errore in ChatGPT e il modello ha risposto che poteva essere risolto modificando la codifica utilizzata in "utf-8". Mi ha anche fornito del codice modificato che riflette questo cambiamento:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
Questo codice è stato eseguito correttamente e ha creato un file di testo chiamato "output_file.txt". Tutto il contenuto del documento PDF è stato scritto nel file:
Leggere file PDF con GPT-4
Ora incollerò lo stesso prompt in GPT-4 per vedere cosa viene fuori dal modello:
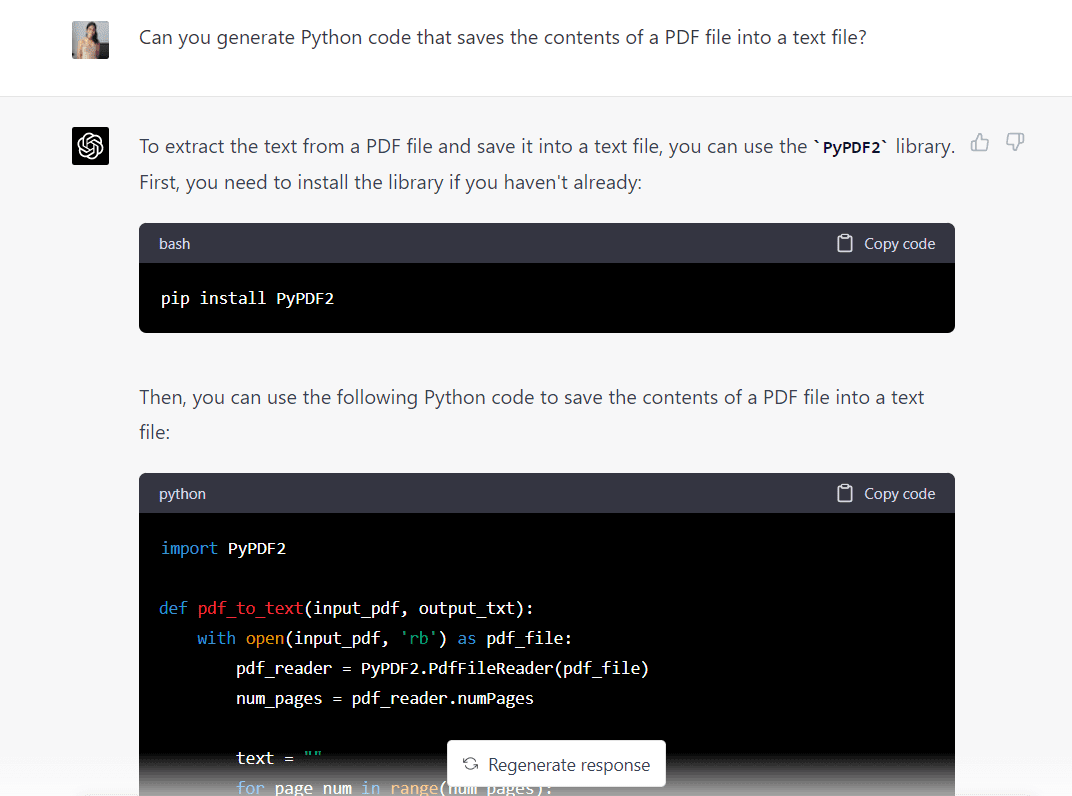
Ecco il codice completo generato da GPT-4:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
Guarda quello!
A differenza di GPT-3.5, GPT-4 ha già specificato che la codifica "utf-8" deve essere utilizzata per aprire il file di testo. Non abbiamo bisogno di tornare indietro e modificare il codice come abbiamo fatto in precedenza.
Il codice fornito da GPT-4 dovrebbe essere eseguito correttamente e dovresti vedere il contenuto del documento PDF nel file di testo che è stato creato.
Esistono molte altre tecniche che puoi utilizzare per automatizzare i documenti PDF con Python. Se desideri esplorare ulteriormente questo aspetto, ecco alcuni altri suggerimenti che puoi digitare in ChatGPT:
- Puoi scrivere codice Python per unire due file PDF?
- Come posso contare le occorrenze di una parola o frase specifica in un documento PDF con Python?
- Puoi scrivere codice Python per estrarre tabelle da PDF e scriverle in Excel?
Ti suggerisco di provarne alcuni durante il tuo tempo libero: rimarrai sorpreso dalla rapidità con cui GPT-4 può aiutarti a svolgere compiti umili che di solito richiedono ore per essere eseguiti.
3. Invio di e-mail automatizzate
Trascorro ore della mia settimana lavorativa leggendo e rispondendo alle e-mail. Non solo questo richiede molto tempo, ma può anche essere incredibilmente stressante rimanere al passo con le e-mail quando si inseguono scadenze ravvicinate.
E anche se non puoi ottenere ChatGPT per scrivere tutte le tue e-mail per te (lo vorrei), puoi comunque usarlo per scrivere programmi che inviano e-mail programmate in un momento specifico o modificare un singolo modello di e-mail che può essere inviato a più persone .
In questa sezione, otterremo GPT-3.5 e GPT-4 per aiutarci a scrivere uno script Python per inviare e-mail automatizzate.
Invio di e-mail automatizzate con GPT-3.5
Innanzitutto, digitiamo il seguente prompt per generare i codici per inviare un'e-mail automatica:
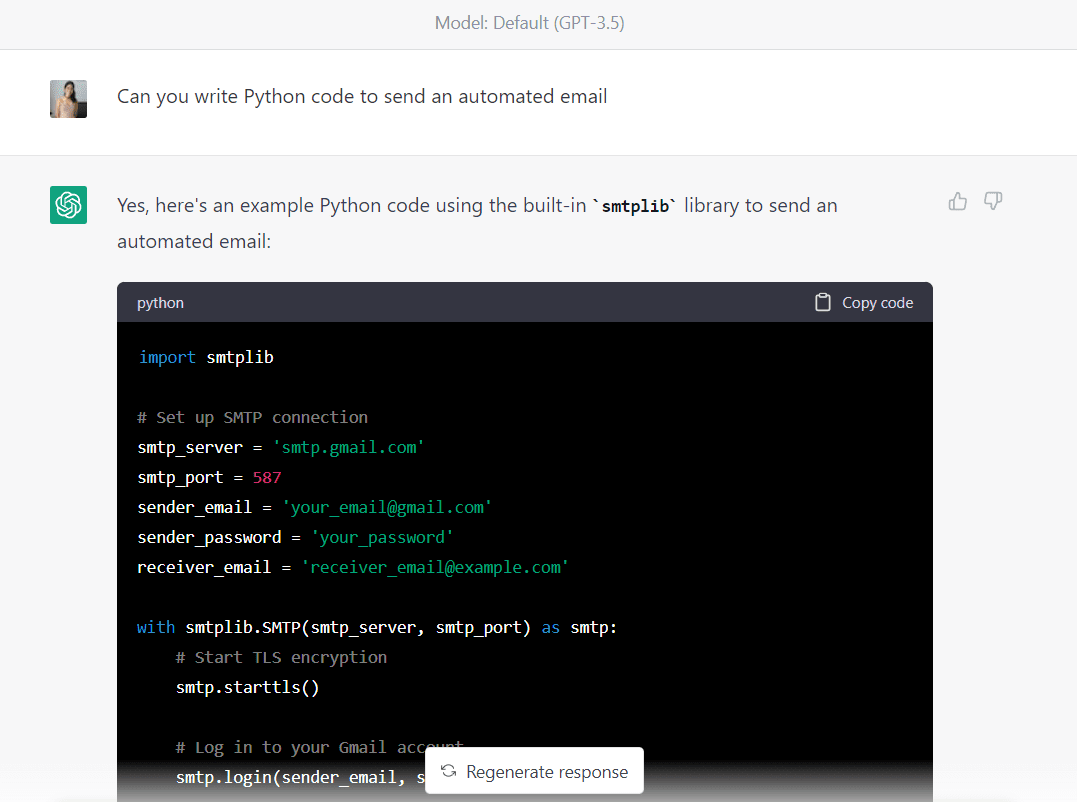
Ecco il codice completo generato da GPT-3.5 (assicurati di modificare gli indirizzi e-mail e la password prima di eseguire questo codice):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Sfortunatamente, questo codice non è stato eseguito correttamente per me. Ha generato il seguente errore:
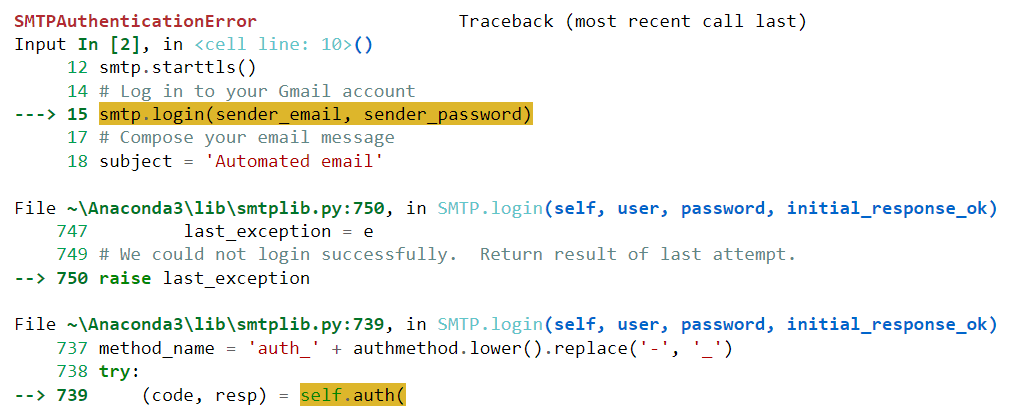
Incolliamo questo errore in ChatGPT e vediamo se il modello può aiutarci a risolverlo:

Ok, quindi l'algoritmo ha indicato alcuni motivi per cui potremmo incorrere in questo errore.
So per certo che le mie credenziali di accesso e gli indirizzi e-mail erano validi e che non c'erano errori di battitura nel codice. Quindi questi motivi possono essere esclusi.
GPT-3.5 suggerisce inoltre che consentire app meno sicure potrebbe risolvere questo problema.
Se provi questo, tuttavia, non troverai un'opzione nel tuo account Google per consentire l'accesso ad app meno sicure.
Questo perché Google non più consente agli utenti di consentire app meno sicure a causa di problemi di sicurezza.
Infine, GPT-3.5 menziona anche che dovrebbe essere generata una password per l'app se è stata abilitata l'autenticazione a due fattori.
Non ho abilitato l'autenticazione a due fattori, quindi rinuncerò (temporaneamente) a questo modello e vedrò se GPT-4 ha una soluzione.
Invio di e-mail automatizzate con GPT-4
Ok, quindi se digiti lo stesso prompt in GPT-4, scoprirai che l'algoritmo genera un codice molto simile a quello che ci ha fornito GPT-3.5. Ciò causerà lo stesso errore in cui ci siamo imbattuti in precedenza.
Vediamo se GPT-4 può aiutarci a correggere questo errore:

I suggerimenti di GPT-4 sono molto simili a quanto visto in precedenza.
Tuttavia, questa volta, ci fornisce un'analisi dettagliata di come eseguire ogni passaggio.
GPT-4 suggerisce anche di creare una password per l'app, quindi proviamo.
Innanzitutto, visita il tuo account Google, vai su "Sicurezza" e abilita l'autenticazione a due fattori. Quindi, nella stessa sezione, dovresti vedere un'opzione che dice "Password app".
Cliccaci sopra e apparirà la seguente schermata:
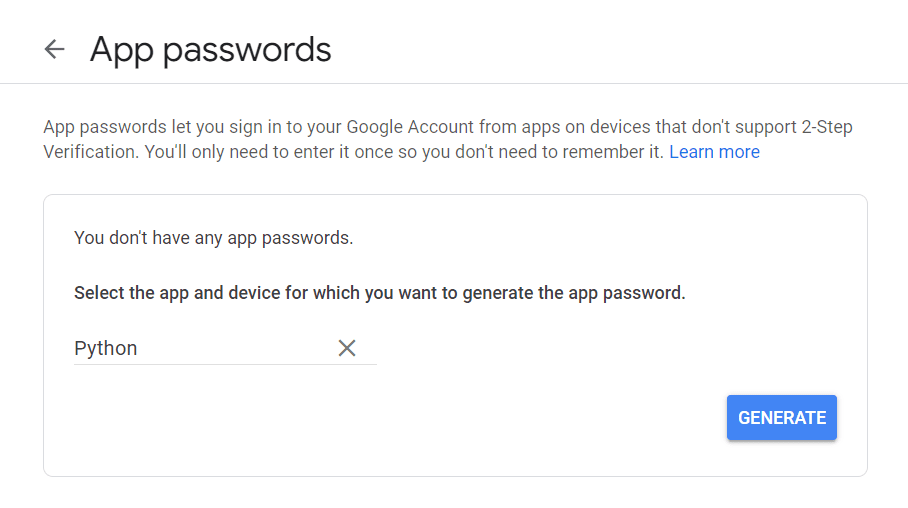
Puoi inserire qualsiasi nome che ti piace e fare clic su "Genera".
Apparirà una nuova password per l'app.
Sostituisci la tua password esistente nel codice Python con questa password dell'app ed esegui nuovamente il codice:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Questa volta dovrebbe funzionare correttamente e il destinatario riceverà un'e-mail simile a questa:
Perfetto!
Grazie a ChatGPT, abbiamo inviato con successo un'e-mail automatizzata con Python.
Se desideri fare un ulteriore passo avanti, ti suggerisco di generare prompt che ti consentano di:
- Invia email di massa a più destinatari contemporaneamente
- Invia e-mail pianificate a un elenco predefinito di indirizzi e-mail
- Invia ai destinatari un'e-mail personalizzata adattata alla loro età, sesso e posizione.
Natasha Selvaraj è un data scientist autodidatta con la passione per la scrittura. Puoi connetterti con lei LinkedIn.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python
- :È
- $ SU
- 1
- 100
- 2022
- 2023
- 7
- 8
- a
- Chi siamo
- sopra
- accesso
- realizzare
- Il mio account
- preciso
- Raggiungere
- operanti in
- effettivamente
- indirizzi
- Dopo shavasana, sedersi in silenzio; saluti;
- algoritmo
- Tutti
- Consentire
- consente
- già
- Sebbene il
- quantità
- .
- analizzare
- l'analisi
- ed
- animali
- risposte
- api
- App
- apparire
- applicazioni
- SONO
- articolo
- AS
- assunto
- assunzione
- At
- Autenticazione
- automatizzare
- Automatizzata
- disponibile
- media
- precedente
- BACKEND
- bar
- bar
- basato
- BE
- perché
- diventare
- prima
- dietro
- vantaggi
- Meglio
- fra
- bmi
- stile di vita
- Noioso
- Guasto
- costruire
- costruito
- affari
- by
- detto
- Materiale
- annullato
- non può
- Causare
- il cambiamento
- cambiando
- Grafico
- chatbot
- ChatGPT
- chiaramente
- clicca
- codice
- COM
- arrivo
- Uncommon
- azienda
- Società
- completamento di una
- complicato
- preoccupazioni
- con fiducia
- Connettiti
- veloce
- consolidamento
- contenuto
- testuali
- corroborare
- potuto
- creare
- creato
- Creazione
- Credenziali
- curioso
- Corrente
- Attualmente
- personalizzare
- personalizzate
- alle lezioni
- dati
- analisi dei dati
- scienza dei dati
- scienziato di dati
- visualizzazione dati
- dataset
- giorno
- Predefinito
- dipendente
- descrizione
- dettagli
- sviluppare
- Diabete
- DID
- differenza
- diverso
- documento
- documentazione
- documenti
- non
- fare
- Dont
- scaricare
- guidare
- durante
- ogni
- In precedenza
- più facile
- Efficace
- Uova
- o
- elefante
- enable
- abilitato
- crittografia
- entrare
- errore
- errori
- particolarmente
- Etere (ETH)
- eventi
- Ogni
- qualunque cosa
- di preciso
- Excel
- eseguire
- esistente
- esperimento
- ha spiegato
- Analisi dei dati esplorativi
- esplora
- estensivo
- estratto
- caratteristica
- tassa
- pochi
- figura
- Compila il
- File
- riempire
- Trovare
- Nome
- Fissare
- fisso
- Focus
- seguire
- i seguenti
- Nel
- Ex
- Gratis
- frequentemente
- da
- funzionale
- ulteriormente
- Sesso
- generare
- generato
- genera
- la generazione di
- ottenere
- Dare
- dà
- gmail
- Go
- andando
- Crescita
- guida
- guida
- cura
- Avere
- capo
- Aiuto
- aiuta
- qui
- nascosto
- superiore
- vivamente
- Orizzontale
- ORE
- Come
- Tutorial
- Tuttavia
- HTTPS
- Enorme
- centinaia
- i
- idee
- subito
- Impact
- importare
- importante
- miglioramento
- in
- incluso
- Aumento
- incredibilmente
- studente indipendente
- industrie
- industria
- informazioni
- invece
- interessato
- Interfaccia
- Introduzione
- problema
- IT
- SUO
- Lavoro
- join
- KDnuggets
- Sapere
- per il tuo brand
- Paese
- Lingua
- grandi
- maggiore
- con i più recenti
- lanciare
- lanciato
- apprendimento
- Consente di
- livelli
- Biblioteca
- piace
- probabile
- linea
- Linee
- Lista
- caricare
- località
- guardò
- cerca
- SEMBRA
- lotto
- macchina
- machine learning
- fatto
- make
- manualmente
- molti
- Marzo
- matematica
- matplotlib
- menziona
- Unire
- messaggio
- forza
- Moda
- modello
- modelli
- modificato
- modificare
- momento
- mensile
- Abbonamento mensile
- Scopri di più
- maggior parte
- cambiano
- multiplo
- Nome
- Navigare
- Bisogno
- New
- nuova app
- Nuovi Arrivi
- notizie
- famigerato
- Novembre
- numero
- oggetto
- of
- Va bene
- on
- ONE
- aprire
- OpenAI
- ottimale
- Opzione
- Altro
- Risultato
- Sorpassa
- produzione
- pagina
- pagato
- panda
- passione
- Password
- Le password
- Paga le
- Persone
- eseguire
- esecuzione
- persona
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- più
- potenziale
- potente
- predecessore
- predire
- piuttosto
- prevenire
- in precedenza
- Stampa
- probabilmente
- Problema
- problemi
- Programmi
- Progressi
- fornire
- purché
- la percezione
- pubblicamente
- Python
- Domande
- Presto
- rapidamente
- Leggi
- Lettore
- Lettura
- motivi
- ricevere
- destinatari
- riflette
- rilasciato
- pertinente
- rimanente
- rapporto
- Report
- necessario
- richiede
- ricercatori
- risponde
- risposta
- colpevole
- Risultati
- Correre
- running
- stesso
- Risparmi
- Risparmio
- dice
- Scala
- in programma
- Scienze
- Scienziato
- allo
- Seaborn
- ricerca
- Sezione
- sicuro
- problemi di
- invio
- sentimento
- set
- dovrebbero
- mostrare attraverso le sue creazioni
- significativa
- simile
- Un'espansione
- semplicemente
- da
- singolo
- Taglia
- inferiore
- So
- soluzione
- RISOLVERE
- Soluzione
- alcuni
- fonti
- specifico
- specificato
- spendere
- esaurito
- si
- inizia a
- soggiorno
- step
- Ancora
- Fermare
- soggetto
- sottoscrizione
- Con successo
- suggerisce
- adatto
- sorpreso
- sintassi
- su misura
- Fai
- presa
- Target
- Task
- task
- tecniche
- dice
- modello
- che
- I
- loro
- Li
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- cosa
- Attraverso
- tempo
- richiede tempo
- Titolo
- titolato
- TLS
- a
- top
- Totale
- allenato
- tendenze
- Svolta
- lezione
- sottostante
- capire
- unicode
- upgrade
- us
- uso
- Utente
- utenti
- generalmente
- APPREZZIAMO
- versione
- visibile
- Visita
- visualizzazione
- W
- ricercato
- Sito web
- Che
- se
- quale
- OMS
- wikipedia
- volere
- con
- entro
- Word
- parole
- Lavora
- flusso di lavoro
- flussi di lavoro
- lavoro
- sarebbe
- scrivere
- scrittura
- scritto
- Trasferimento da aeroporto a Sharm
- zefiro