Immagine dell'autore
Quando inizi a utilizzare il machine learning, la regressione logistica è uno dei primi algoritmi che aggiungerai alla tua cassetta degli attrezzi. È un algoritmo semplice e robusto, comunemente utilizzato per attività di classificazione binaria.
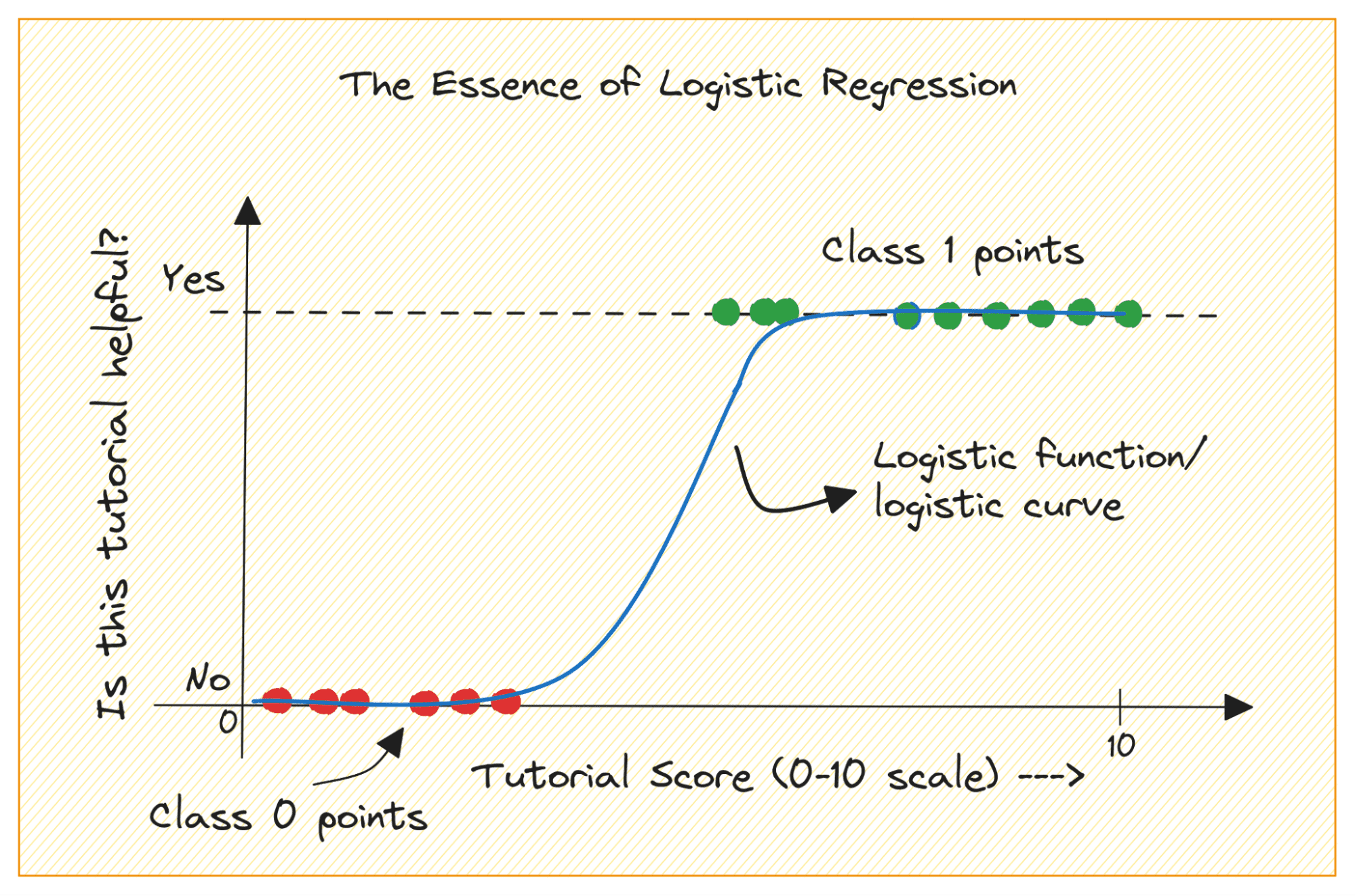
Considera un problema di classificazione binaria con le classi 0 e 1. La regressione logistica adatta una funzione logistica o sigmoide ai dati di input e prevede la probabilità che un punto dati di query appartenga alla classe 1. Interessante, sì?
In questo tutorial impareremo la regressione logistica da zero coprendo:
- La funzione logistica (o sigmoidea).
- Come si passa dalla regressione lineare a quella logistica
- Come funziona la regressione logistica
Infine, costruiremo un semplice modello di regressione logistica classificare i ritorni RADAR dalla ionosfera.
Prima di saperne di più sulla regressione logistica, esaminiamo come funziona la funzione logistica. La funzione logistica (o sigmoidea) è data da:

Quando disegni la funzione sigmoidea, apparirà così:
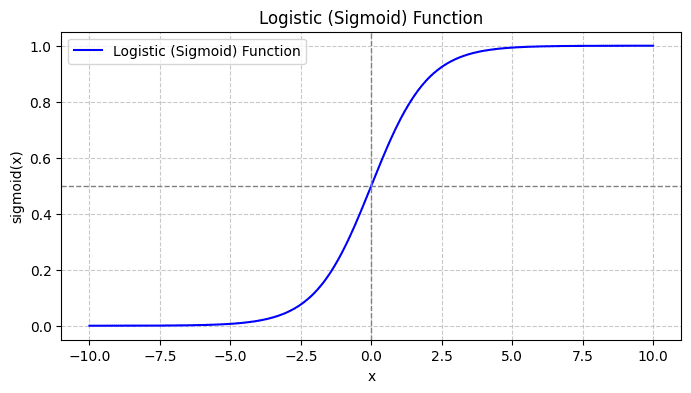
Dalla trama vediamo che:
- Quando x = 0, σ(x) assume un valore pari a 0.5.
- Quando x si avvicina a +∞, σ(x) si avvicina a 1.
- Quando x si avvicina a -∞, σ(x) si avvicina a 0.
Quindi, per tutti gli input reali, la funzione sigmoide li schiaccia per assumere valori nell'intervallo [0, 1].
Parliamo innanzitutto del motivo per cui non possiamo utilizzare la regressione lineare per un problema di classificazione binaria.
In un problema di classificazione binaria, l'output è un'etichetta categoriale (0 o 1). Poiché la regressione lineare prevede output a valori continui che possono essere inferiori a 0 o superiori a 1, non ha senso per il problema in questione.
Inoltre, una linea retta potrebbe non essere la soluzione migliore quando le etichette di output appartengono a una delle due categorie.
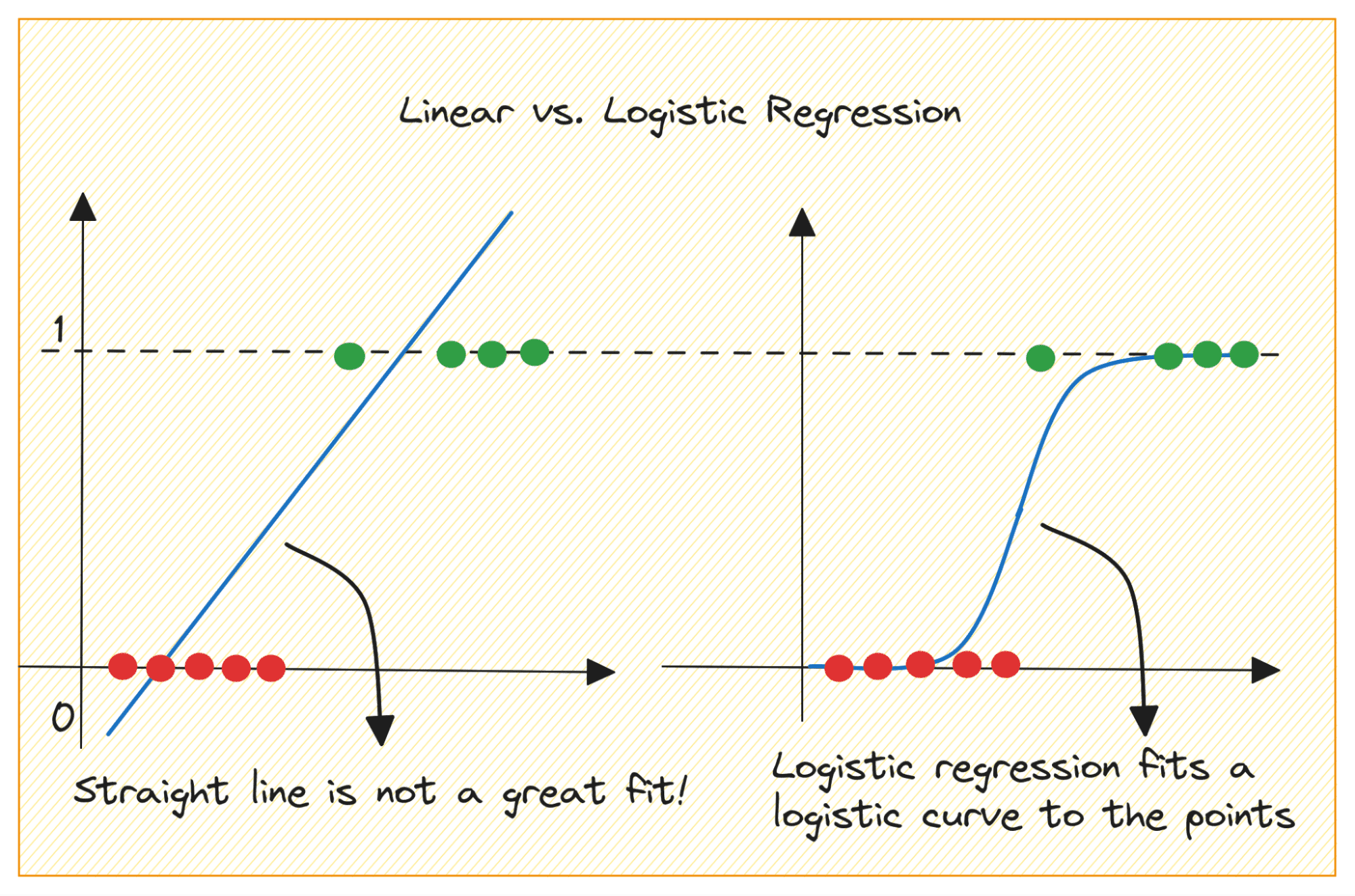
Immagine dell'autore
Allora come si passa dalla regressione lineare a quella logistica? Nella regressione lineare l'output previsto è dato da:
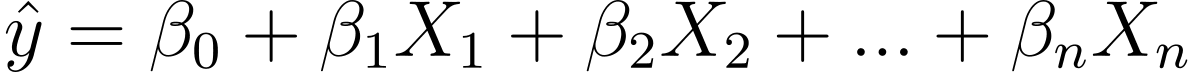
Dove β sono i coefficienti e X_is sono i predittori (o caratteristiche).
Senza perdita di generalità, supponiamo X_0 = 1:

Quindi possiamo avere un'espressione più concisa:
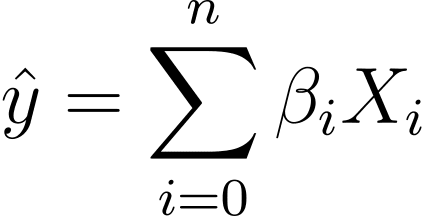
Nella regressione logistica, abbiamo bisogno della probabilità prevista p_i nell'intervallo [0,1]. Sappiamo che la funzione logistica comprime gli input in modo che assumano valori nell'intervallo [0,1].
Quindi, inserendo questa espressione nella funzione logistica, abbiamo la probabilità prevista come:
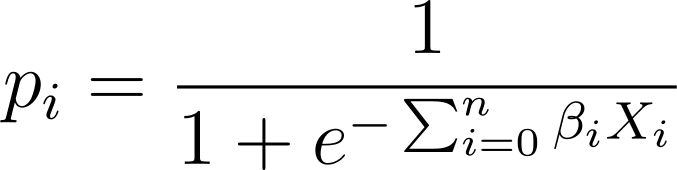
Quindi, come troviamo la curva logistica più adatta per il set di dati fornito? Per rispondere a questa domanda, comprendiamo la stima di massima verosimiglianza.
Stima della massima verosimiglianza (MLE) viene utilizzato per stimare i parametri del modello di regressione logistica massimizzando la funzione di verosimiglianza. Analizziamo il processo di MLE nella regressione logistica e il modo in cui la funzione di costo viene formulata per l'ottimizzazione utilizzando la discesa del gradiente.
Abbattere la stima della massima verosimiglianza
Come discusso, modelliamo la probabilità che si verifichi un risultato binario in funzione di una o più variabili predittive (o caratteristiche):
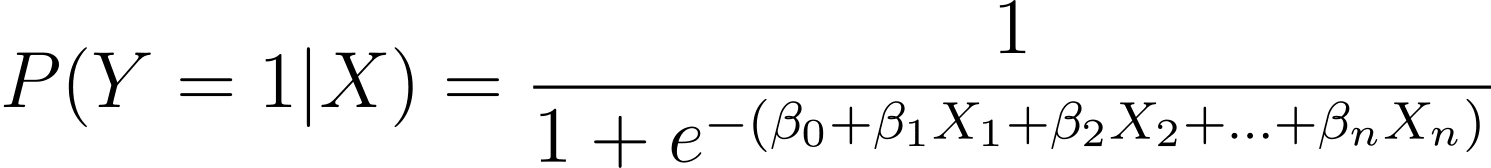
Qui, i β sono i parametri o coefficienti del modello. X_1, X_2,…, X_n sono le variabili predittive.
MLE mira a trovare i valori di β che massimizzano la verosimiglianza dei dati osservati. La funzione di verosimiglianza, indicata come L(β), rappresenta la probabilità di osservare i risultati dati per i valori predittivi dati nel modello di regressione logistica.
Formulazione della funzione di verosimiglianza
Per semplificare il processo di ottimizzazione, è normale lavorare con la funzione log-verosimiglianza. Perché trasforma i prodotti delle probabilità in somme di probabilità logaritmiche.
La funzione di verosimiglianza per la regressione logistica è data da:
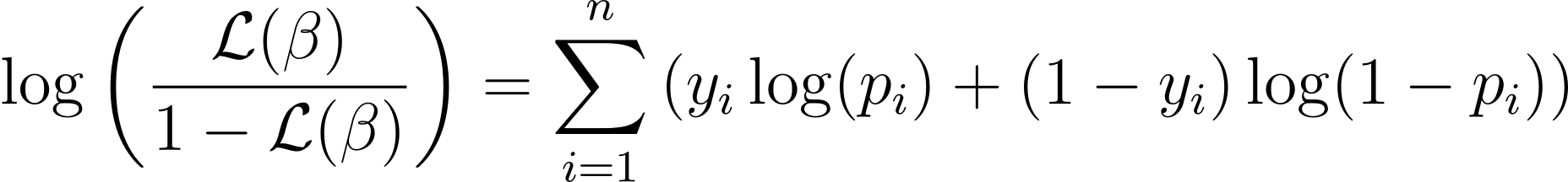
Ora che conosciamo l'essenza della verosimiglianza, procediamo a formulare la funzione di costo per la regressione logistica e successivamente la discesa del gradiente per trovare i migliori parametri del modello
Funzione di costo per la regressione logistica
Per ottimizzare il modello di regressione logistica, dobbiamo massimizzare la probabilità di log. Quindi possiamo utilizzare la probabilità di log negativa come funzione di costo da minimizzare durante l'addestramento. La log-verosimiglianza negativa, spesso definita perdita logistica, è definita come:
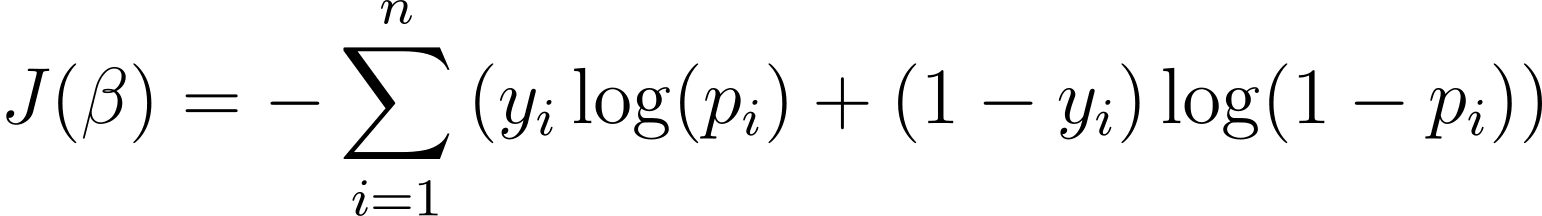
L'obiettivo dell'algoritmo di apprendimento, quindi, è trovare i valori di ? che minimizzano questa funzione di costo. La discesa del gradiente è un algoritmo di ottimizzazione comunemente utilizzato per trovare il minimo di questa funzione di costo.
Discesa del gradiente nella regressione logistica
Discesa in pendenza è un algoritmo di ottimizzazione iterativo che aggiorna i parametri del modello β nella direzione opposta del gradiente della funzione di costo rispetto a β. La regola di aggiornamento al passaggio t+1 per la regressione logistica utilizzando la discesa del gradiente è la seguente:
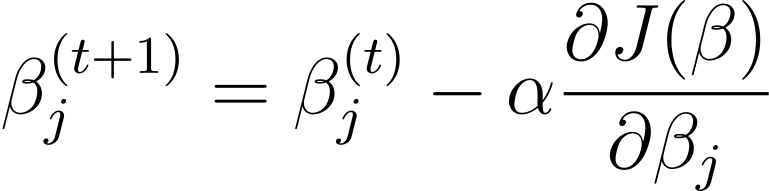
Dove α è il tasso di apprendimento.
Le derivate parziali possono essere calcolate utilizzando la regola della catena. La discesa del gradiente aggiorna iterativamente i parametri, fino alla convergenza, con l'obiettivo di ridurre al minimo la perdita logistica. Mentre converge, trova i valori ottimali di β che massimizzano la verosimiglianza dei dati osservati.
Ora che sai come funziona la regressione logistica, creiamo un modello predittivo utilizzando la libreria scikit-learn.
Useremo il Set di dati della ionosfera dal repository di machine learning dell'UCI per questo tutorial. Il set di dati comprende 34 caratteristiche numeriche. L'output è binario, uno tra "buono" o "cattivo" (indicato con "g" o "b"). L’etichetta di output “buono” si riferisce ai ritorni RADAR che hanno rilevato alcune strutture nella ionosfera.
Passaggio 1: caricamento del set di dati
Innanzitutto, scarica il set di dati e leggilo in un dataframe panda:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Passaggio 2: esplorazione del set di dati
Diamo un'occhiata alle prime righe del dataframe:
# Display the first few rows of the DataFrame
df.head()
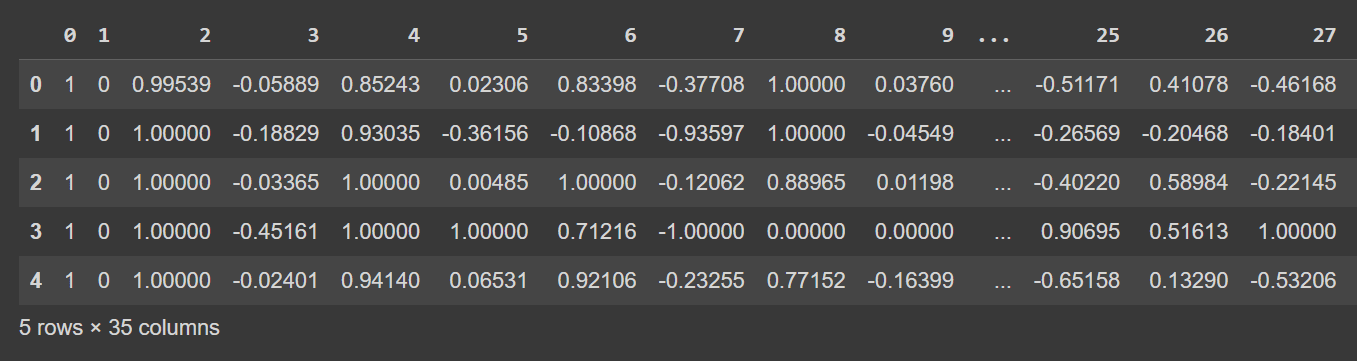
Output troncato di df.head()
Otteniamo alcune informazioni sul set di dati: il numero di valori non nulli e i tipi di dati di ciascuna colonna:
# Get information about the dataset
print(df.info())
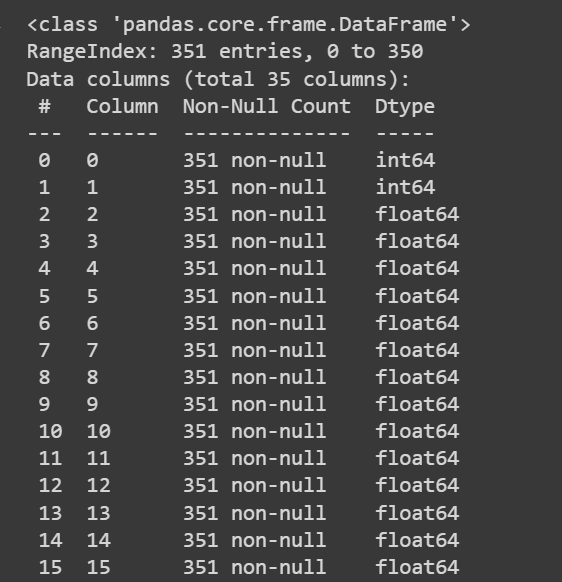 Output troncato di df.info()
Output troncato di df.info()
Poiché abbiamo tutte caratteristiche numeriche, possiamo anche ottenere alcune statistiche descrittive utilizzando il metodo describe() metodo sul dataframe:
# Get descriptive statistics of the dataset
print(df.describe())
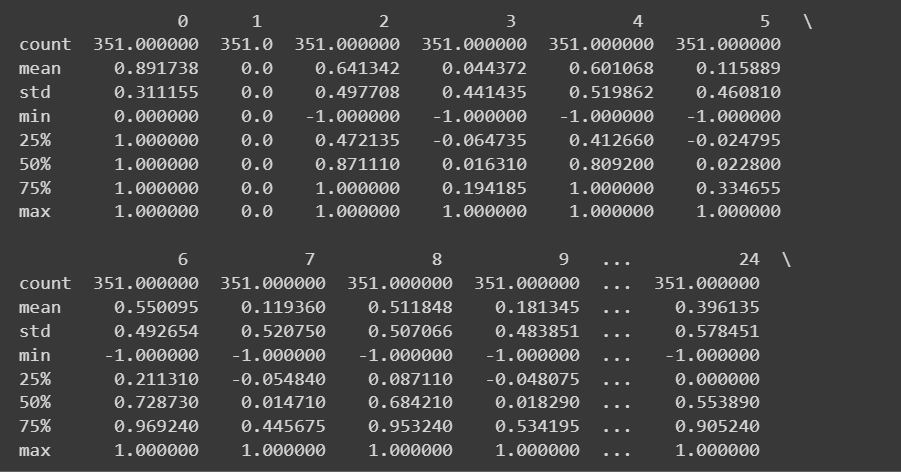
Output troncato di df.describe()
I nomi delle colonne sono attualmente compresi tra 0 e 34, inclusa l'etichetta. Poiché il set di dati non fornisce nomi descrittivi per le colonne, si riferisce semplicemente ad esse come da attributo_1 a attributo_34, se desideri puoi rinominare le colonne del data frame come mostrato:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Nota: questo passaggio è puramente facoltativo. Se preferisci, puoi procedere con i nomi delle colonne predefiniti.
# Display the first few rows of the DataFrame
df.head()
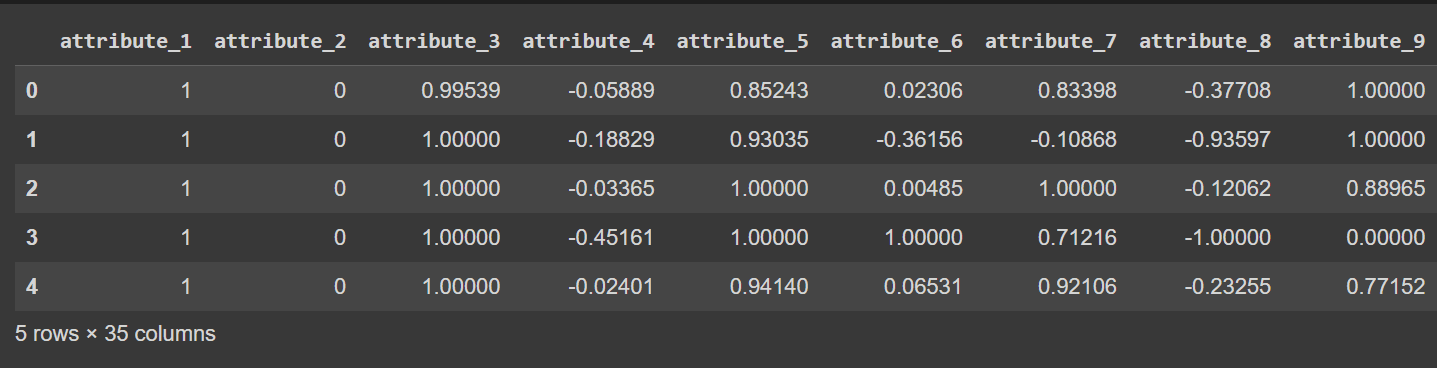
Output troncato di df.head() [dopo aver rinominato le colonne]
Passaggio 3: rinominare le etichette delle classi e visualizzare la distribuzione delle classi
Poiché le etichette della classe di output sono "g" e "b", dobbiamo mapparle rispettivamente su 1 e 0 . Puoi farlo usando map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Visualizziamo anche la distribuzione delle etichette delle classi:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
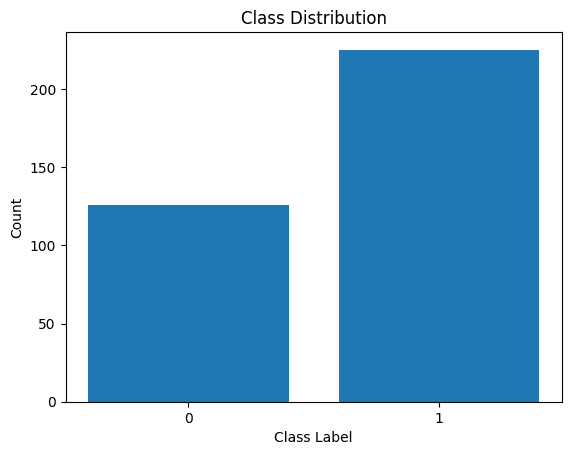
Distribuzione delle etichette di classe
Vediamo che c'è uno squilibrio nella distribuzione. Esistono più record appartenenti alla classe 1 che alla classe 0. Gestiremo questo squilibrio di classi durante la costruzione del modello di regressione logistica.
Passaggio 5: preelaborazione del set di dati
Raccogliamo le caratteristiche e le etichette di output in questo modo:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Dopo aver suddiviso il set di dati in set di training e test, è necessario preelaborare il set di dati.
Quando sono presenti molte caratteristiche numeriche, ciascuna su una scala potenzialmente diversa, è necessario preelaborare le caratteristiche numeriche. Un metodo comune è trasformarli in modo tale che seguano una distribuzione con media zero e varianza unitaria.
Il StandardScaler dal modulo di preelaborazione di scikit-learn ci aiuta a raggiungere questo obiettivo.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Passaggio 6: creazione di un modello di regressione logistica
Ora possiamo istanziare un classificatore di regressione logistica. IL LogisticRegression class fa parte del modulo linear_model di scikit-learn.
Nota che abbiamo impostato il file class_weight parametro su "bilanciato". Questo ci aiuterà a spiegare lo squilibrio di classe. Assegnando pesi a ciascuna classe, inversamente proporzionali al numero di record nelle classi.
Dopo aver istanziato la classe, possiamo adattare il modello al set di dati di training:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Passaggio 7: valutazione del modello di regressione logistica
Puoi chiamare il predict() metodo per ottenere le previsioni del modello.
Oltre al punteggio di precisione, possiamo anche ottenere un rapporto di classificazione con metriche come precisione, ricordo e punteggio F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
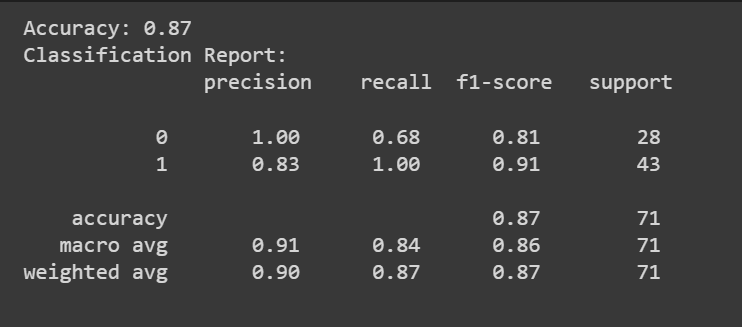
Congratulazioni, hai codificato il tuo primo modello di regressione logistica!
In questo tutorial abbiamo appreso in dettaglio la regressione logistica: dalla teoria e matematica alla codifica di un classificatore di regressione logistica.
Come passaggio successivo, prova a creare un modello di regressione logistica per un set di dati adatto di tua scelta.
Il set di dati Ionosphere è concesso in licenza con a Creative Commons Attribuzione 4.0 Internazionale (CC BY 4.0) licenza:
Sigillito,V., Wing,S., Hutton,L., e Baker,K.. (1989). Ionosfera. Repository per l'apprendimento automatico dell'UCI. https://doi.org/10.24432/C5W01B.
Bala Priya C è uno sviluppatore e scrittore tecnico dall'India. Le piace lavorare all'intersezione tra matematica, programmazione, scienza dei dati e creazione di contenuti. Le sue aree di interesse e competenza includono DevOps, data science ed elaborazione del linguaggio naturale. Le piace leggere, scrivere, programmare e il caffè! Attualmente, sta lavorando all'apprendimento e alla condivisione delle sue conoscenze con la comunità degli sviluppatori creando tutorial, guide pratiche, articoli di opinione e altro ancora.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :È
- :non
- $ SU
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- WRI
- Il mio account
- precisione
- Raggiungere
- aggiungere
- aggiunta
- Dopo shavasana, sedersi in silenzio; saluti;
- mira
- algoritmo
- Algoritmi
- Tutti
- anche
- an
- ed
- rispondere
- approcci
- SONO
- aree
- AS
- assumere
- At
- autore
- b
- panettiere
- equilibrato
- bar
- BE
- perché
- appartenente
- MIGLIORE
- Rompere
- costruire
- Costruzione
- by
- chiamata
- Materiale
- non può
- categoria
- catena
- scegliere
- classe
- classi
- classificazione
- codificato
- codifica
- raccogliere
- Colonna
- colonne
- Uncommon
- comunemente
- Popolo
- comunità
- incluso
- conciso
- contenuto
- creazione di contenuti
- convertire
- Costo
- copertura
- creare
- creazione
- Attualmente
- curva
- dati
- punti dati
- scienza dei dati
- set di dati
- Predefinito
- definito
- Derivati
- dettaglio
- rilevato
- Costruttori
- DevOps
- diverso
- direzione
- discutere
- discusso
- Dsiplay
- distribuzione
- do
- effettua
- giù
- scaricare
- durante
- ogni
- essenza
- stima
- la valutazione
- competenza
- Esplorare
- espressione
- Caratteristiche
- pochi
- Trovate
- ricerca
- trova
- Nome
- in forma
- seguire
- segue
- Nel
- TELAIO
- da
- function
- ottenere
- ottenere
- dato
- Go
- scopo
- maggiore
- Terra
- Guide
- cura
- maniglia
- Avere
- Aiuto
- aiuta
- suo
- Come
- HTTPS
- ICS
- if
- squilibrio
- importare
- in
- includere
- Index
- India
- Indici
- informazioni
- ingresso
- Ingressi
- interesse
- interessante
- intersezione
- ai miglioramenti
- IT
- ad appena
- KDnuggets
- Sapere
- conoscenze
- Discografica
- per il tuo brand
- Lingua
- IMPARARE
- imparato
- apprendimento
- meno
- lasciare
- Biblioteca
- Licenza
- Autorizzato
- piace
- probabilità
- piace
- linea
- Caricamento in corso
- ceppo
- Guarda
- una
- spento
- macchina
- machine learning
- make
- molti
- carta geografica
- matematica
- matplotlib
- Massimizzare
- massimizzando
- massimo
- Maggio..
- significare
- metodo
- Metrica
- ridurre al minimo
- ordine
- modello
- modelli
- modulo
- Scopri di più
- cambiano
- nomi
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Bisogno
- negativo.
- GENERAZIONE
- numero
- osservato
- of
- di frequente
- on
- ONE
- Opinione
- di fronte
- ottimale
- ottimizzazione
- OTTIMIZZA
- or
- Risultato
- risultati
- produzione
- uscite
- panda
- parametro
- parametri
- parte
- pezzi
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- punti
- potenzialmente
- Precisione
- previsto
- Previsioni
- predittiva
- Predictor
- predice
- preferire
- probabilità
- Problema
- procedere
- processi
- lavorazione
- Prodotti
- Programmazione
- fornire
- puramente
- Python
- radar
- gamma
- tasso
- Leggi
- Lettura
- di rose
- record
- di cui
- si riferisce
- regressione
- rapporto
- deposito
- rappresenta
- richiesta
- rispetto
- rispettivamente
- problemi
- recensioni
- robusto
- Regola
- s
- Scienze
- scikit-impara
- Punto
- vedere
- senso
- set
- Set
- compartecipazione
- lei
- mostrato
- Un'espansione
- semplificare
- So
- alcuni
- dividere
- iniziato
- statistica
- step
- dritto
- La struttura
- Successivamente
- tale
- adatto
- somme
- Fai
- prende
- Target
- task
- Consulenza
- test
- Testing
- di
- che
- Il
- Li
- teoria
- Là.
- perciò
- di
- questo
- Attraverso
- a
- Strumenti
- Treni
- allenato
- Training
- Trasformare
- trasforma
- prova
- lezione
- esercitazioni
- seconda
- Tipi di
- per
- capire
- unità
- Aggiornanento
- Aggiornamenti
- URL
- us
- Conto USA
- uso
- utilizzato
- utilizzando
- APPREZZIAMO
- Valori
- visualizzare
- we
- quando
- quale
- perché
- wikipedia
- volere
- Ala
- con
- Lavora
- lavoro
- lavori
- sarebbe
- scrittore
- scrittura
- X
- sì
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- zero