Amazzone Atena è un servizio di query interattivo che semplifica l'analisi dei dati in Servizio di archiviazione semplice Amazon (Amazon S3) e origini dati che risiedono in AWS, in locale o in altri sistemi cloud che utilizzano SQL o Python. Athena è basato su motori Trino e Presto open source e framework Apache Spark, senza necessità di provisioning o configurazione. Athena è serverless, quindi non c'è alcuna infrastruttura da gestire e paghi solo per le query che esegui.
Apache Iceberg è un formato di tabella aperto per set di dati analitici di grandi dimensioni. Gestisce grandi raccolte di file come tabelle e supporta moderne operazioni di data Lake analitiche come query di inserimento, aggiornamento, eliminazione e viaggio nel tempo a livello di record. Athena supporta query di lettura, viaggio nel tempo, scrittura e DDL per le tabelle Apache Iceberg che utilizzano il formato Apache Parquet per i dati e le query Catalogo dati di AWS Glue per il loro metastore.
Ingegneria delle funzionalità è un processo di identificazione e trasformazione dei dati grezzi (immagini, file di testo, video e così via), di riempimento dei dati mancanti e di aggiunta di uno o più elementi di dati significativi per fornire contesto in modo che un modello di machine learning (ML) possa imparare da essi. L'etichettatura dei dati è necessaria per vari casi d'uso, tra cui previsione, visione artificiale, elaborazione del linguaggio naturale e riconoscimento vocale.
In combinazione con le funzionalità di Athena, Apache Iceberg offre un flusso di lavoro semplificato ai data scientist per creare nuove funzionalità di dati senza la necessità di copiare o ricreare l'intero set di dati. Puoi creare funzionalità utilizzando SQL standard su Athena senza utilizzare altri servizi per l'ingegneria delle funzionalità. I data scientist possono ridurre il tempo impiegato nella preparazione e nella copia dei set di dati e concentrarsi invece sulla progettazione delle funzionalità dei dati, sulla sperimentazione e sull'analisi dei dati su larga scala.
In questo post, esaminiamo i vantaggi derivanti dall'utilizzo di Athena con il formato di tabella aperta Apache Iceberg e come semplifica le attività comuni di progettazione delle funzionalità per i data scientist. Dimostriamo come Athena può convertire una tabella esistente nel formato Apache Iceberg, quindi aggiungere colonne, eliminare colonne e modificare i dati nella tabella senza ricreare o copiare il set di dati e utilizzare queste funzionalità per creare nuove funzionalità sulle tabelle Apache Iceberg.
Panoramica della soluzione
I data scientist sono generalmente abituati a lavorare con set di dati di grandi dimensioni. I set di dati vengono generalmente archiviati in JSON, CSV, ORC o Parquet Apache formato o formati simili ottimizzati per la lettura per prestazioni di lettura veloci. I data scientist spesso creano nuove funzionalità di dati e riempiono tali funzionalità di dati con dati aggregati e accessori. Storicamente, questa attività veniva eseguita creando una vista sopra la tabella con i dati sottostanti in formato Apache Parquet, dove tali colonne e dati venivano aggiunti in fase di runtime o creando una nuova tabella con colonne aggiuntive. Sebbene questo flusso di lavoro sia adatto a molti casi d'uso, è inefficiente per set di dati di grandi dimensioni, perché i dati dovrebbero essere generati in fase di runtime oppure i set di dati dovrebbero essere copiati e trasformati.
Atena ha presentato Transazione ACID (Atomicità, Coerenza, Isolamento, Durabilità). funzionalità su cui si aggiungono operazioni INSERT, UPDATE, DELETE, MERGE e viaggi nel tempo Tavoli Apache Iceberg. Queste funzionalità consentono ai data scientist di creare nuove funzionalità di dati e di rilasciare funzionalità di dati esistenti su set di dati esistenti senza preoccuparsi di copiare o trasformare il set di dati o di astrarlo con una vista. I data scientist possono concentrarsi sul lavoro di ingegneria delle funzionalità ed evitare di copiare e trasformare i set di dati.
L'operazione Athena Iceberg UPDATE scrive i file di eliminazione della posizione di Apache Iceberg e le righe appena aggiornate come file di dati nella stessa transazione. È possibile apportare correzioni ai record tramite una singola istruzione UPDATE.
Con il rilascio del motore Athena versione 3, le funzionalità per le tabelle Apache Iceberg vengono migliorate con il supporto per operazioni come CREA TABELLA COME SELEZIONE (CTAS) e comandi MERGE che semplificano la gestione del ciclo di vita dei dati Iceberg. CTAS rende veloce ed efficiente la creazione di tabelle da altri formati come Apache Paquet e UNISCI IN aggiornamenti condizionali, elimina o inserisce righe in una tabella Iceberg. Una singola istruzione può combinare azioni di aggiornamento, eliminazione e inserimento.
Prerequisiti
Configura un gruppo di lavoro Athena con il motore Athena versione 3 per utilizzare i comandi CTAS e MERGE con una tabella Apache Iceberg. Per aggiornare il tuo motore Athena esistente alla versione 3 nel tuo gruppo di lavoro Athena, segui le istruzioni in Esegui l'upgrade alla versione 3 del motore Athena per aumentare le prestazioni delle query e accedere a più funzionalità di analisi o fare riferimento a Modifica della versione del motore nella console Athena.
dataset
A scopo dimostrativo, utilizziamo una tabella Apache Parquet che contiene diversi milioni di record di dati di vendita fittizi distribuiti in modo casuale degli ultimi anni archiviati in un bucket S3. Scaricare il set di dati, decomprimilo sul tuo computer locale e caricalo nel tuo bucket S3. In questo post abbiamo caricato il nostro set di dati su s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
La tabella seguente mostra il layout della tabella customer_orders.
| Nome colonna | Tipo di dati | Descrizione |
| orderkey | stringa | Numero d'ordine per l'ordine |
| chiave inglese | stringa | Numero di identificazione del cliente |
| lo stato dell'ordine | stringa | Stato dell'ordine |
| prezzo totale | stringa | Prezzo totale dell'ordine |
| data dell'ordine | stringa | Data dell'ordine |
| priorità dell'ordine | stringa | Priorità dell'ordine |
| impiegato | stringa | Nome dell'addetto che ha elaborato l'ordine |
| priorità della nave | stringa | Priorità sulla spedizione |
| Nome | stringa | Nome del cliente |
| indirizzo | stringa | Indirizzo cliente |
| chiave nazionale | stringa | Chiave della nazione del cliente |
| telefono | stringa | Numero di telefono del cliente |
| acctbal | stringa | Saldo del conto cliente |
| mktsegment | stringa | Segmento di mercato dei clienti |
Eseguire l'ingegneria delle funzionalità
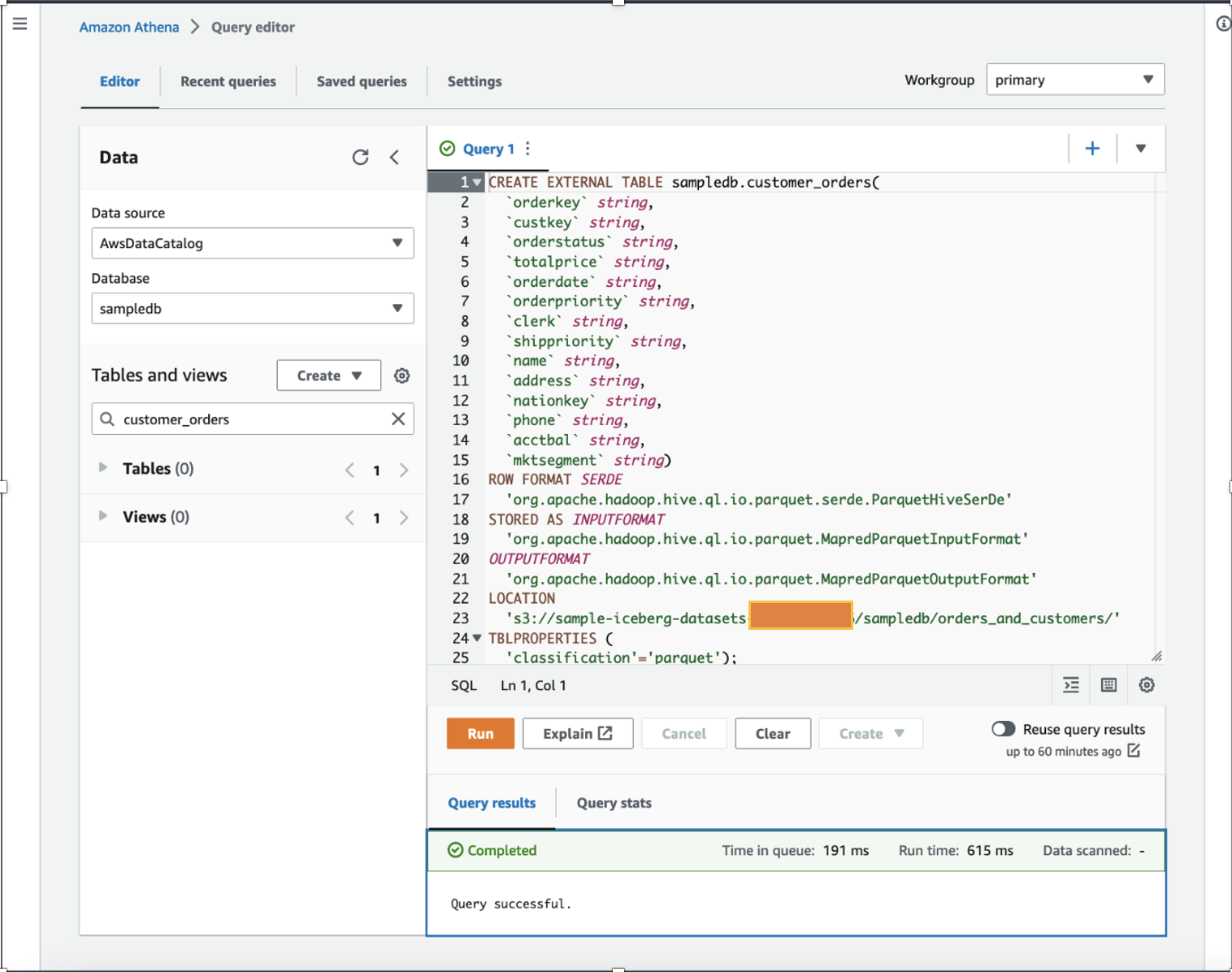
In qualità di data scientist, vogliamo esibirci ingegneria delle caratteristiche sui dati degli ordini dei clienti aggiungendo gli acquisti totali calcolati su un anno e gli acquisti medi su un anno per ciascun cliente nel set di dati esistente. A scopo dimostrativo, abbiamo creato il file customer_orders tavolo in sampledb database utilizzando Athena come mostrato nel seguente comando DDL. (Puoi utilizzare uno qualsiasi dei tuoi set di dati esistenti e seguire i passaggi menzionati in questo post.) The customer_orders il set di dati è stato generato e archiviato nella posizione del bucket S3 s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ nel formato Parquet. Questa tabella non è una tabella Apache Iceberg.
![]()
Convalida i dati nella tabella eseguendo una query:
![]()
Vogliamo aggiungere nuove funzionalità a questa tabella per ottenere una comprensione più approfondita delle vendite dei clienti, che può comportare una formazione del modello più rapida e informazioni più preziose. Per aggiungere nuove funzionalità al set di dati, convertire il file customer_orders Dal tavolo Athena al tavolo Apache Iceberg su Athena. Emettere a CTAS istruzione query per creare una nuova tabella con il formato Apache Iceberg dal file customer_orders tavolo. Facendo ciò, viene aggiunta una nuova funzionalità per ottenere l'importo totale degli acquisti effettuati nell'ultimo anno (anno massimo del set di dati) da ciascun cliente.
Nella seguente query CTAS, una nuova colonna denominata one_year_sales_aggregate con il valore predefinito come 0.0 del tipo di dati double viene aggiunto e table_type è impostato su ICEBERG:
![]()
Emetti la seguente query per verificare i dati nella tabella Apache Iceberg con la nuova colonna one_year_sales_aggregate valori come 0.0:
![]()
Vogliamo popolare i valori per la nuova funzionalità one_year_sales_aggregate nel set di dati per ottenere l'importo totale dell'acquisto per ciascun cliente in base agli acquisti effettuati nell'ultimo anno (anno massimo del set di dati). Emettere un'istruzione di query MERGE alla tabella Apache Iceberg utilizzando Athena per popolare i valori per one_year_sales_aggregate funzione:
![]()
Emetti la seguente query per convalidare il valore aggiornato della spesa totale di ciascun cliente nell'ultimo anno:
![]()
Decidiamo di aggiungere un'altra funzionalità a una tabella Apache Iceberg esistente per calcolare e archiviare l'importo medio di acquisto nell'ultimo anno da parte di ciascun cliente. Emettere un'istruzione di query ALTER per aggiungere una nuova colonna a una tabella esistente per la funzionalità one_year_sales_average:
![]()
Prima di inserire i valori in questa nuova funzionalità, è possibile impostare il valore predefinito per la funzionalità one_year_sales_average a 0.0. Utilizzando la stessa tabella Apache Iceberg su Athena, emettere un'istruzione di query UPDATE per popolare il valore della nuova funzionalità come 0.0:
![]()
Emetti la seguente query per verificare che sia impostato il valore aggiornato della spesa media di ciascun cliente nell'ultimo anno 0.0:
![]()
Ora vogliamo popolare i valori per la nuova funzionalità one_year_sales_average nel set di dati per ottenere l'importo medio di acquisto per ciascun cliente in base agli acquisti effettuati nell'ultimo anno (anno massimo del set di dati). Emettere un'istruzione di query MERGE alla tabella Apache Iceberg esistente su Athena utilizzando il motore Athena per popolare i valori per la funzionalità one_year_sales_average:
![]()
Emetti la seguente query per verificare i valori aggiornati per la spesa media di ciascun cliente:
![]()
Una volta aggiunte funzionalità di dati aggiuntive al set di dati, i data scientist generalmente procedono all'addestramento dei modelli ML e fanno inferenze utilizzando Amazon Sagemaker o un set di strumenti equivalenti.
Conclusione
In questo post, abbiamo dimostrato come eseguire l'ingegneria delle funzionalità utilizzando Athena con Apache Iceberg. Abbiamo anche dimostrato l'utilizzo della query CTAS per creare una tabella Apache Iceberg su Athena da un set di dati esistente in formato Apache Parquet, aggiungendo nuove funzionalità in una tabella Apache Iceberg esistente su Athena utilizzando la query ALTER e utilizzando le istruzioni di query UPDATE e MERGE per aggiornare la tabella valori delle caratteristiche delle colonne esistenti.
Ti invitiamo a utilizzare le query CTAS per creare tabelle in modo rapido ed efficiente e a utilizzare l'istruzione di query MERGE per sincronizzare le tabelle in un unico passaggio per semplificare la preparazione dei dati e aggiornare le attività durante la trasformazione delle funzionalità utilizzando Athena con Apache Iceberg. Se hai commenti o feedback, lasciali nella sezione commenti.
Informazioni sugli autori
![]() Vivek Gautam è un Data Architect con specializzazione in data lake presso AWS Professional Services. Lavora con clienti aziendali creando prodotti dati, piattaforme di analisi e soluzioni su AWS. Quando non costruisce e progetta moderne piattaforme dati, Vivek è un appassionato di cibo a cui piace anche esplorare nuove destinazioni di viaggio e fare escursioni.
Vivek Gautam è un Data Architect con specializzazione in data lake presso AWS Professional Services. Lavora con clienti aziendali creando prodotti dati, piattaforme di analisi e soluzioni su AWS. Quando non costruisce e progetta moderne piattaforme dati, Vivek è un appassionato di cibo a cui piace anche esplorare nuove destinazioni di viaggio e fare escursioni.
![]() Michail Vaynshteyn è un architetto di soluzioni con Amazon Web Services. Mikhail lavora con i clienti del settore sanitario e delle scienze della vita per creare soluzioni che aiutino a migliorare i risultati dei pazienti. Mikhail è specializzato in servizi di analisi dei dati.
Michail Vaynshteyn è un architetto di soluzioni con Amazon Web Services. Mikhail lavora con i clienti del settore sanitario e delle scienze della vita per creare soluzioni che aiutino a migliorare i risultati dei pazienti. Mikhail è specializzato in servizi di analisi dei dati.
![]() Naresh Gautam è un leader di analisi dei dati e AI/ML presso AWS con 20 anni di esperienza, a cui piace aiutare i clienti a progettare soluzioni di analisi dei dati e AI/ML altamente disponibili, ad alte prestazioni e convenienti per consentire ai clienti un processo decisionale basato sui dati . Nel tempo libero ama meditare e cucinare.
Naresh Gautam è un leader di analisi dei dati e AI/ML presso AWS con 20 anni di esperienza, a cui piace aiutare i clienti a progettare soluzioni di analisi dei dati e AI/ML altamente disponibili, ad alte prestazioni e convenienti per consentire ai clienti un processo decisionale basato sui dati . Nel tempo libero ama meditare e cucinare.
![]() Harsha Tadiparti è un Principal Solutions Architect specializzato, Analytics presso AWS. Gli piace risolvere problemi complessi dei clienti in database e analisi e fornire risultati di successo. Al di fuori del lavoro, ama passare il tempo con la sua famiglia, guardare film e viaggiare quando possibile.
Harsha Tadiparti è un Principal Solutions Architect specializzato, Analytics presso AWS. Gli piace risolvere problemi complessi dei clienti in database e analisi e fornire risultati di successo. Al di fuori del lavoro, ama passare il tempo con la sua famiglia, guardare film e viaggiare quando possibile.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- EVM Finance. Interfaccia unificata per la finanza decentralizzata. Accedi qui.
- Quantum Media Group. IR/PR amplificato. Accedi qui.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :ha
- :È
- :non
- :Dove
- $ SU
- 10
- 100
- 12
- 17
- 20
- 20 anni
- 23
- 27
- 7
- a
- WRI
- accelerare
- accesso
- compiuto
- Il mio account
- azioni
- aggiungere
- aggiunto
- l'aggiunta di
- aggiuntivo
- indirizzo
- AI / ML
- anche
- Sebbene il
- Amazon
- Amazzone Atena
- Amazon Sage Maker
- Amazon Web Services
- quantità
- an
- Analitico
- Analitico
- analitica
- analizzare
- l'analisi
- ed
- Un altro
- in qualsiasi
- Apache
- Apache Spark
- SONO
- AS
- At
- disponibile
- media
- evitare
- AWS
- Servizi professionali AWS
- basato
- BE
- perché
- stato
- vantaggi
- costruire
- Costruzione
- costruito
- by
- calcolato
- Materiale
- funzionalità
- casi
- classificazione
- Cloud
- collezioni
- Colonna
- colonne
- combinare
- Commenti
- Uncommon
- complesso
- Calcolare
- computer
- Visione computerizzata
- Configurazione
- contiene
- contesto
- convertire
- cucina
- copiatura
- Correzioni
- costo effettivo
- creare
- creato
- Creazione
- cliente
- Clienti
- dati
- Dati Analytics
- Lago di dati
- scienza dei dati
- scienziato di dati
- data-driven
- Banca Dati
- banche dati
- dataset
- Data
- decide
- Decision Making
- più profondo
- Predefinito
- consegna
- fornisce un monitoraggio
- dimostrare
- dimostrato
- progettazione
- Destinazioni
- distribuito
- fare
- doppio
- Cadere
- durevolezza
- ogni
- facile
- efficiente
- in modo efficiente
- sforzo
- o
- elementi
- e potenza
- enable
- incoraggiare
- motore
- Ingegneria
- Motori
- migliorata
- Impresa
- clienti aziendali
- appassionato
- Intero
- Equivalente
- Etere (ETH)
- esistente
- esperienza
- esplora
- esterno
- falso
- famiglia
- FAST
- più veloce
- caratteristica
- Caratteristiche
- feedback
- File
- Focus
- seguire
- i seguenti
- cibo
- Nel
- formato
- quadri
- Gratis
- da
- generalmente
- generato
- ottenere
- Go
- Gruppo
- Hadoop
- Avere
- he
- assistenza sanitaria
- Aiuto
- aiutare
- Alte prestazioni
- vivamente
- escursioni
- il suo
- storicamente
- Alveare
- Come
- Tutorial
- HTML
- HTTPS
- Identificazione
- identificazione
- if
- immagini
- competenze
- in
- Compreso
- Aumento
- inefficiente
- Infrastruttura
- Inserti
- intuizioni
- invece
- istruzioni
- interattivo
- ai miglioramenti
- introdotto
- da solo
- problema
- IT
- jpg
- json
- etichettatura
- lago
- Lingua
- grandi
- Cognome
- disposizione
- leader
- IMPARARE
- apprendimento
- Lasciare
- Vita
- Life Sciences
- ciclo di vita
- LIMITE
- locale
- località
- ama
- macchina
- machine learning
- make
- FA
- gestire
- gestione
- gestisce
- molti
- Rappresentanza
- abbinato
- max
- significativo
- Meditazione
- menzionato
- Unire
- milione
- mancante
- ML
- modello
- modelli
- moderno
- modificare
- Scopri di più
- Film
- Nome
- Detto
- nazione
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Bisogno
- che necessitano di
- New
- nuova funzione
- Nuove funzionalità
- recentemente
- no
- numero
- of
- di frequente
- on
- ONE
- esclusivamente
- aprire
- open source
- operazione
- Operazioni
- or
- ordini
- Altro
- nostro
- risultati
- al di fuori
- passato
- Paga le
- eseguire
- performance
- telefono
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- per favore
- posizione
- possibile
- Post
- preparazione
- prezzo
- Direttore
- problemi
- processi
- elaborati
- lavorazione
- Prodotti
- professionale
- fornire
- Acquista
- acquisti
- fini
- Python
- query
- rapidamente
- Crudo
- dati grezzi
- Leggi
- riconoscimento
- record
- record
- ridurre
- rilasciare
- necessario
- colpevole
- recensioni
- RIGA
- Correre
- running
- sagemaker
- vendite
- stesso
- Scala
- Scienze
- SCIENZE
- Scienziato
- scienziati
- Sezione
- serverless
- servizio
- Servizi
- set
- alcuni
- mostrato
- Spettacoli
- simile
- Un'espansione
- semplificata
- semplificare
- singolo
- So
- Soluzioni
- Soluzione
- fonti
- Scintilla
- specialista
- specializzata
- discorso
- Riconoscimento vocale
- spendere
- esaurito
- SQL
- Standard
- dichiarazione
- dichiarazioni
- step
- Passi
- conservazione
- Tornare al suo account
- memorizzati
- snellire
- Corda
- di successo
- tale
- supporto
- supporti
- SISTEMI DI TRATTAMENTO
- tavolo
- Task
- task
- che
- Il
- la fusione
- loro
- Li
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- tempo
- tempo di percorrenza
- a
- top
- Totale
- Treni
- Training
- delle transazioni
- transazionale
- trasformato
- trasformazione
- viaggiare
- Digitare
- sottostante
- e una comprensione reciproca
- Aggiornanento
- aggiornato
- Aggiornamenti
- upgrade
- caricato
- uso
- utilizzando
- generalmente
- CONVALIDARE
- Prezioso
- APPREZZIAMO
- Valori
- vario
- verificare
- versione
- molto
- via
- Video
- Visualizza
- visione
- volere
- Prima
- Orologio
- we
- sito web
- servizi web
- sono stati
- quando
- ogni volta che
- quale
- while
- OMS
- con
- senza
- Lavora
- flusso di lavoro
- Gruppo di lavoro
- lavoro
- lavori
- sarebbe
- scrivere
- anno
- anni
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- Codice postale