Oggi sul palco del keynote di AWS re:Invent, Swami Sivasubramanian, VP of Data and AI, AWS, ha parlato del rapporto vantaggioso tra dati, intelligenza artificiale generativa e esseri umani, che lavorano tutti insieme per liberare nuove possibilità in termini di efficienza e creatività. Non c’è mai stato un momento più emozionante per la tecnologia moderna. L’innovazione sta accelerando ovunque e il futuro è pieno di possibilità. Mentre Swami ha esplorato molti aspetti di questa relazione vantaggiosa nel keynote di oggi, un'area particolarmente critica per i nostri clienti da risolvere se vogliono vedere il successo nell'intelligenza artificiale generativa sono i dati. Quando desideri creare applicazioni di intelligenza artificiale generativa uniche per le tue esigenze aziendali, i dati sono l'elemento di differenziazione. Questa settimana abbiamo lanciato molti nuovi strumenti per aiutarti a trasformare i tuoi dati in un elemento di differenziazione. Ciò include strumenti che ti aiutano a personalizzare i tuoi modelli di base e nuovi servizi e funzionalità per creare una solida base di dati per alimentare le tue applicazioni di intelligenza artificiale generativa.
Personalizzazione dei modelli di fondazione
La necessità di dati è abbastanza ovvia se stai costruendo i tuoi modelli di base (FM). Questi modelli necessitano di grandi quantità di dati. Ma i dati sono necessari anche quando si costruisce su FM. Se ci pensi, tutti hanno accesso agli stessi modelli per creare applicazioni di intelligenza artificiale generativa. Sono i dati la chiave per passare da applicazioni generiche ad applicazioni di intelligenza artificiale generativa che creano valore reale per i tuoi clienti e la tua azienda. Ad esempio, il nuovo assistente generativo basato sull’intelligenza artificiale di Intuit, Intuit Assist, utilizza set di dati contestuali pertinenti che abbracciano piccole imprese, finanza al consumo e informazioni fiscali per fornire informazioni finanziarie personalizzate ai propri clienti. Con Roccia Amazzonica, puoi personalizzare privatamente gli FM per il tuo caso d'uso specifico utilizzando un piccolo set di dati etichettati tramite un'interfaccia visiva senza scrivere alcun codice. Oggi abbiamo annunciato la possibilità di perfezionare Cohere Command e Meta Llama 2 oltre a Titano Amazzonico. Oltre alla messa a punto, stiamo anche semplificando la fornitura di modelli con informazioni aggiornate e contestualmente pertinenti dalle origini dati utilizzando Retrieval Augmented Generation (RAG). La funzionalità Knowledge Base di Amazon Bedrock, resa disponibile a livello generale oggi, supporta l'intero flusso di lavoro RAG, dall'acquisizione, al recupero e all'incremento tempestivo. Le basi di conoscenza funzionano con i database e i motori vettoriali più diffusi, inclusi Amazon OpenSearch senza server, Redis Enterprise Cloud e Pinecone, con supporto per Amazon Aurora e MongoDB in arrivo.
Costruire una solida base di dati
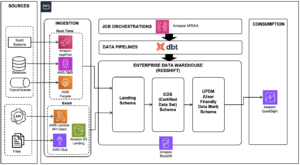
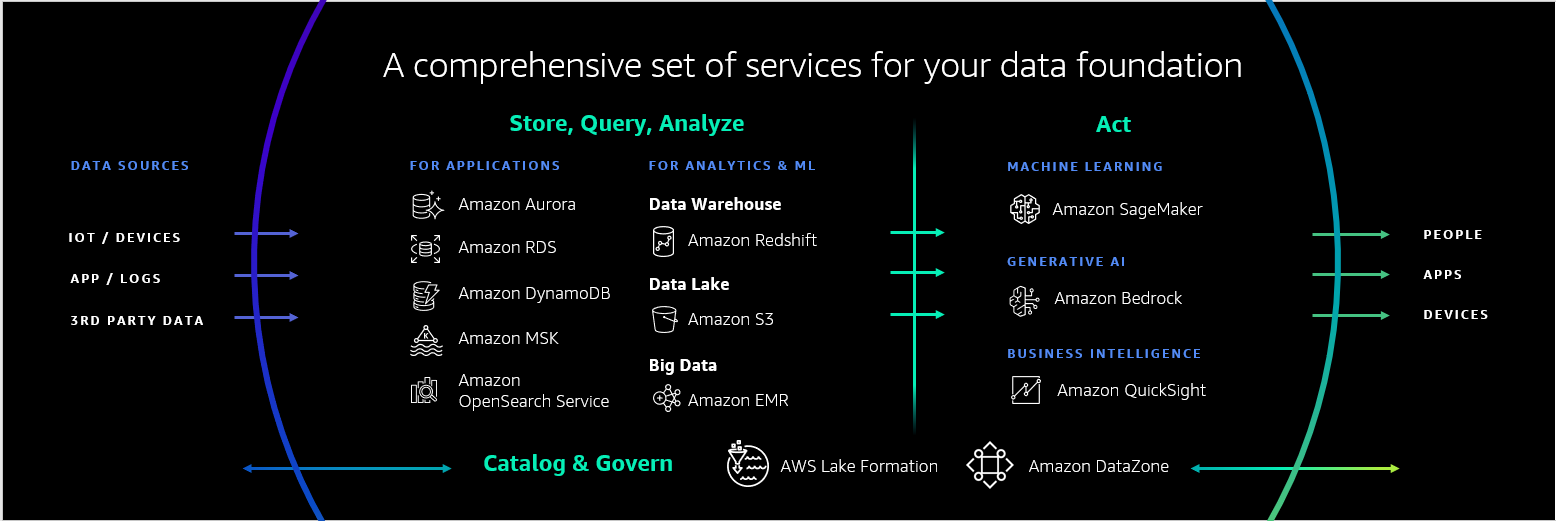
Per produrre i dati di alta qualità necessari per creare o personalizzare FM per l'intelligenza artificiale generativa, è necessaria una solida base di dati. Naturalmente, il valore di una solida base di dati non è nuovo e la necessità di averla va ben oltre l’intelligenza artificiale generativa. In tutti i tipi di casi d'uso, dall'intelligenza artificiale generativa alla business intelligence (BI), abbiamo scoperto che una solida base di dati include un set completo di servizi per soddisfare tutte le esigenze dei casi d'uso, integrazioni tra tali servizi per abbattere i silos di dati, e strumenti per gestire i dati nel flusso di lavoro end-to-end in modo da poter innovare più rapidamente. Questi strumenti devono anche essere intelligenti per rimuovere il lavoro pesante dalla gestione dei dati.
Globale
Innanzitutto, hai bisogno di un set completo di servizi dati in modo da poter ottenere il rapporto prezzo/prestazioni, velocità, flessibilità e funzionalità per qualsiasi caso d'uso. AWS offre un'ampia gamma di strumenti che ti consentono di archiviare, organizzare, accedere e agire su vari tipi di dati. Disponiamo della più ampia selezione di servizi di database, inclusi database relazionali come Aurora e Servizio di database relazionale Amazon (Amazon RDS) e lunedì abbiamo presentato l'ultima aggiunta alla famiglia RDS: Amazon RDS per Db2. Ora i clienti Db2 possono facilmente configurare, utilizzare e scalare database Db2 ad alta disponibilità nel cloud. Offriamo anche database non relazionali come Amazon DynamoDB, utilizzato da oltre 1 milione di clienti per le sue prestazioni serverless a una cifra in millisecondi su qualsiasi scala. Sono inoltre necessari servizi per archiviare dati per l'analisi e l'apprendimento automatico (ML). Servizio di archiviazione semplice Amazon (Amazon S3). I clienti hanno creato centinaia di migliaia di data lake su Amazon S3. Include anche il nostro data warehouse, Amazon RedShift, che offre un rapporto prezzo/prestazioni più di 6 volte migliore rispetto ad altri data warehouse su cloud. Disponiamo inoltre di strumenti che ti consentono di agire sui tuoi dati, inclusi Amazon QuickSight per la BI, Amazon Sage Maker per il machine learning e, naturalmente, Amazon Bedrock per l'intelligenza artificiale generativa.
Miglioramenti senza server
La natura dinamica dei dati li rende perfettamente adatti alle tecnologie serverless, motivo per cui AWS offre un'ampia gamma di offerte di database e analisi serverless che aiutano a supportare i carichi di lavoro più impegnativi dei nostri clienti. Questa settimana abbiamo apportato ulteriori miglioramenti alle nostre opzioni serverless in quest'area, inclusa una nuova funzionalità Aurora che si adatta automaticamente a milioni di transazioni di scrittura al secondo e gestisce petabyte di dati mantenendo la semplicità di gestione di un singolo database. Abbiamo anche rilasciato una nuova opzione serverless per Amazon Elastic Cache, che rende più semplice e veloce la creazione di cache a disponibilità elevata e si adatta istantaneamente alla domanda delle applicazioni. Infine, abbiamo annunciato nuove ottimizzazioni e scalabilità basate sull'intelligenza artificiale per Amazon Redshift senza server che consentono al servizio di apprendere dai tuoi modelli e di scalare in modo proattivo su più dimensioni, inclusi utenti simultanei, variabilità dei dati e complessità delle query. Fa tutto questo tenendo conto degli obiettivi di prezzo/prestazioni in modo da poter ottimizzare costi e prestazioni.
Funzionalità vettoriali su più database
La base dati deve includere anche servizi per archiviare, indicizzare, recuperare ed eseguire ricerche sui dati vettoriali. Poiché i nostri clienti necessitano di incorporamenti di vettori come parte dei flussi di lavoro delle loro applicazioni di intelligenza artificiale generativa, ci hanno detto che desiderano utilizzare le funzionalità vettoriali nei loro database esistenti per eliminare la ripida curva di apprendimento per nuovi strumenti di programmazione, API e SDK. Si sentono inoltre più sicuri sapendo che i loro database esistenti sono collaudati in produzione e soddisfano i requisiti di scalabilità, disponibilità, archiviazione ed elaborazione. E quando i tuoi vettori e i dati aziendali vengono archiviati nello stesso posto, le tue applicazioni verranno eseguite più velocemente e non c'è bisogno di sincronizzare o spostare i dati di cui preoccuparsi.
Per tutti questi motivi, abbiamo investito nell'aggiunta di funzionalità vettoriali ad alcuni dei nostri servizi dati più popolari, tra cui Servizio Amazon OpenSearch e OpenSearch Serverless, Aurora e Amazon RDS. Oggi ne abbiamo aggiunti altri quattro all'elenco, con l'aggiunta del supporto vettoriale Amazon MemoryDB per Redis, AmazonDocumentDB (con compatibilità MongoDB), DynamoDB e Amazon Nettuno. Ora puoi utilizzare i vettori e l'intelligenza artificiale generativa con il tuo database preferito.
Integrato
Un'altra chiave per la tua base dati è l'integrazione dei dati tra le tue origini dati per una visione più completa della tua attività. In genere, la connessione dei dati tra diverse origini dati richiede complesse pipeline di estrazione, trasformazione e caricamento (ETL), la cui creazione può richiedere ore, se non giorni. Anche queste condutture devono essere sottoposte a manutenzione continua e possono essere fragili. AWS sta investendo in un futuro a zero ETL in modo che tu possa connetterti e agire in modo rapido e semplice su tutti i tuoi dati, indipendentemente da dove risiedano. Stiamo realizzando questa visione in diversi modi, comprese le integrazioni zero-ETL tra i nostri datastore più popolari. All'inizio di quest'anno vi abbiamo offerto la nostra integrazione zero-ETL completamente gestita between Edizione compatibile con Amazon Aurora MySQL e Amazon Redshift. Entro pochi secondi dalla scrittura dei dati in Aurora, puoi utilizzare Amazon Redshift per eseguire analisi e ML quasi in tempo reale su petabyte di dati. Woolworths, pioniere nel settore della vendita al dettaglio che ha contribuito a costruire il modello di vendita al dettaglio odierno, è riuscito a ridurre i tempi di sviluppo per l'analisi di promozioni e altri eventi da 2 mesi a 1 giorno utilizzando l'integrazione Aurora zero-ETL con Amazon Redshift.
Altre opzioni ETL zero
Al re:Invent abbiamo annunciato altre tre integrazioni zero-ETL con Amazon Redshift, tra cui Edizione compatibile con Amazon Aurora PostgreSQL, Amazon RDS per MySQLe DynamoDB, per sfruttare più facilmente i vantaggi dell'analisi quasi in tempo reale per migliorare i risultati aziendali. Oltre ad Amazon Redshift, abbiamo anche ampliato il nostro supporto zero ETL al servizio OpenSearch, che decine di migliaia di clienti utilizzano per la ricerca, il monitoraggio e l'analisi in tempo reale di dati aziendali e operativi. Ciò include integrazioni zero-ETL con DynamoDB e Amazon S3. Con tutte queste integrazioni zero ETL, stiamo rendendo ancora più semplice sfruttare i dati rilevanti per le tue applicazioni, inclusa l’intelligenza artificiale generativa.
governata
Infine, la base dati deve essere sicura e governata per garantire che i dati utilizzati durante il ciclo di sviluppo delle applicazioni di intelligenza artificiale generativa siano di alta qualità e conformi. Per aiutare in questo, abbiamo lanciato Amazon DataZone l'anno scorso. Amazon DataZone viene utilizzato da aziende come Guardant Health e Bristol Meyers Squibb per catalogare, scoprire, condividere e gestire i dati all'interno della propria organizzazione. Amazon DataZone utilizza il machine learning per aggiungere automaticamente metadati al tuo catalogo dati, rendendo tutti i tuoi dati più rilevabili. Questa settimana abbiamo aggiunto una nuova funzionalità ad Amazon DataZone che utilizza l'intelligenza artificiale generativa per creare automaticamente descrizioni aziendali e contesto per i tuoi set di dati con pochi clic, rendendo i dati ancora più facili da comprendere e applicare. Sebbene Amazon DataZone ti aiuti a condividere i dati in modo regolamentato all'interno della tua organizzazione, molti clienti desiderano anche condividere i dati in modo sicuro con i propri partner.
Infondere intelligenza nella base dati
Non solo abbiamo aggiunto l'intelligenza artificiale generativa ad Amazon DataZone, ma stiamo sfruttando la tecnologia intelligente nei nostri servizi dati per rendere i dati più facili da usare, più intuitivi da utilizzare e più accessibili. Amazon Q, il nostro nuovo assistente AI generativo, ti aiuta in QuickSight a creare dashboard e creare storie visive avvincenti dai dati della dashboard utilizzando il linguaggio naturale. Abbiamo inoltre annunciato che Amazon Q può aiutarti a creare pipeline di integrazione dei dati utilizzando il linguaggio naturale. Ad esempio, puoi chiedere a Q di "leggere i file JSON da S3, unirti a 'accountid' e caricarli in DynamoDB" e Q restituirà un processo di integrazione dei dati end-to-end per eseguire questa azione. Amazon Q semplifica inoltre l'esecuzione di query sui dati nel data warehouse con SQL AI generativo nell'editor di query di Amazon Redshift (in anteprima). Ora analisti di dati, scienziati e ingegneri possono essere più produttivi utilizzando la funzionalità text-to-code dell'intelligenza artificiale generativa. Puoi anche migliorare la precisione consentendo l'accesso alla cronologia delle query a utenti specifici, senza compromettere la privacy dei dati.
Queste nuove innovazioni ti consentiranno di sfruttare facilmente i dati per differenziare le tue applicazioni di intelligenza artificiale generativa e creare nuovo valore per i tuoi clienti e la tua azienda. Non vediamo l'ora di vedere cosa creerai!
Circa gli autori
 G2 Krishnamoorthy è VP of Analytics, leader nei servizi data Lake AWS, integrazione dei dati, Amazon OpenSearch Service e Amazon QuickSight. Prima del suo ruolo attuale, G2 ha creato ed eseguito la piattaforma di analisi e machine learning presso Facebook/Meta e ha creato varie parti del database SQL Server, Azure Analytics e Azure ML presso Microsoft.
G2 Krishnamoorthy è VP of Analytics, leader nei servizi data Lake AWS, integrazione dei dati, Amazon OpenSearch Service e Amazon QuickSight. Prima del suo ruolo attuale, G2 ha creato ed eseguito la piattaforma di analisi e machine learning presso Facebook/Meta e ha creato varie parti del database SQL Server, Azure Analytics e Azure ML presso Microsoft.
 Raul Pathak è vicepresidente dei motori di database relazionali, alla guida di Amazon Aurora, Amazon Redshift e Amazon QLDB. Prima del suo ruolo attuale, è stato VP of Analytics presso AWS, dove ha lavorato sull'intero portafoglio di database AWS. Ha co-fondato due società, una focalizzata sull'analisi dei media digitali e l'altra sulla geolocalizzazione IP.
Raul Pathak è vicepresidente dei motori di database relazionali, alla guida di Amazon Aurora, Amazon Redshift e Amazon QLDB. Prima del suo ruolo attuale, è stato VP of Analytics presso AWS, dove ha lavorato sull'intero portafoglio di database AWS. Ha co-fondato due società, una focalizzata sull'analisi dei media digitali e l'altra sulla geolocalizzazione IP.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/unlocking-the-value-of-data-as-your-differentiator/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 100
- 521
- a
- capacità
- capace
- WRI
- a proposito
- accelerando
- accesso
- accessibile
- precisione
- operanti in
- Legge
- Action
- aggiungere
- aggiunto
- l'aggiunta di
- aggiunta
- Vantaggio
- AI
- Assistente AI
- AI-alimentato
- Tutti
- anche
- Amazon
- Amazon QuickSight
- Amazon RDS
- Amazon Web Services
- tra
- importi
- an
- .
- Gli analisti
- analitica
- ed
- ha annunciato
- in qualsiasi
- API
- Applicazioni
- applicazioni
- APPLICA
- SONO
- RISERVATA
- AS
- chiedere
- assistere
- Assistant
- At
- aumentata
- Aurora
- autore
- automaticamente
- disponibilità
- disponibile
- AWS
- AWS re: Invent
- azzurro
- BE
- stato
- essendo
- benefico
- Meglio
- fra
- Al di là di
- Rompere
- Bristol
- ampio
- portato
- costruire
- Costruzione
- costruito
- affari
- business intelligence
- ma
- by
- Materiale
- Può ottenere
- funzionalità
- capacità
- Custodie
- casi
- catalogo
- scegliere
- Cloud
- codice
- arrivo
- presto disponibile
- Aziende
- compatibilità
- avvincente
- completamento di una
- complesso
- complessità
- compiacente
- globale
- compromettendo
- Calcolare
- concorrente
- fiducioso
- Connettiti
- Collegamento
- Consumer
- finanza al consumo
- contesto
- contestuale
- continuamente
- Costo
- corso
- creare
- creato
- la creatività
- critico
- Corrente
- curva
- Clienti
- personalizzare
- ciclo
- cruscotto
- cruscotti
- dati
- integrazione dei dati
- Lago di dati
- gestione dei dati
- privacy dei dati
- data warehouse
- data warehouse
- Banca Dati
- banche dati
- dataset
- giorno
- consegnare
- consegna
- fornisce un monitoraggio
- Richiesta
- esigente
- Mercato
- diverso
- differenziare
- differenziatore
- digitale
- Media digitali
- dimensioni
- scopri
- do
- effettua
- giù
- dinamico
- In precedenza
- più facile
- facilmente
- facile
- editore
- efficienza
- eliminato
- enable
- consentendo
- da un capo all'altro
- Ingegneri
- Motori
- garantire
- Impresa
- Intero
- particolarmente
- Etere (ETH)
- Anche
- eventi
- tutti
- ovunque
- esempio
- coinvolgenti
- esistente
- ampliato
- Esplorazione
- estratto
- sfaccettature
- factoring
- famiglia
- più veloce
- caratteristica
- Caratteristiche
- sentire
- pochi
- File
- Infine
- finanziare
- finanziario
- Flessibilità
- concentrato
- Nel
- Avanti
- essere trovato
- Fondazione
- quattro
- da
- Carburante
- completamente
- funzionalità
- futuro
- G2
- Generale
- ELETTRICA
- generativo
- AI generativa
- ottenere
- andando
- governati
- Avere
- he
- Salute e benessere
- pesante
- sollevamento pesante
- Aiuto
- aiutato
- aiuta
- Alta
- alta qualità
- vivamente
- il suo
- storia
- http
- HTTPS
- centinaia
- if
- competenze
- miglioramenti
- in
- includere
- inclusi
- Compreso
- Index
- informazioni
- innovare
- Innovazione
- innovazioni
- intuizioni
- esempio
- immediatamente
- Integrazione
- integrazione
- integrazioni
- Intelligence
- Intelligente
- Interfaccia
- ai miglioramenti
- introdotto
- Intuit
- intuitivo
- investito
- investire
- IT
- SUO
- Lavoro
- join
- jpg
- json
- ad appena
- Le
- Nota fondamentale
- Conoscere
- conoscenze
- lago
- laghi
- Lingua
- Cognome
- L'anno scorso
- lanciato
- principale
- IMPARARE
- apprendimento
- Leva
- leveraging
- di sollevamento
- piace
- Lista
- Lives
- Lama
- caricare
- Guarda
- macchina
- machine learning
- fatto
- mantenimento
- make
- FA
- Fare
- gestito
- gestione
- gestisce
- molti
- Importanza
- Media
- Soddisfare
- Meta
- Metadati
- Microsoft
- milione
- milioni di clienti
- milioni
- millisecondo
- ML
- modello
- modelli
- moderno
- Lunedì
- MongoDB
- monitoraggio
- mese
- Scopri di più
- maggior parte
- Più popolare
- movimento
- in movimento
- multiplo
- Naturale
- Linguaggio naturale
- Natura
- necessaria
- Bisogno
- esigenze
- mai
- New
- nuova funzione
- Nuovi Arrivi
- no
- adesso
- numero
- ovvio
- of
- offrire
- offerte
- Offerte
- on
- ONE
- esclusivamente
- operare
- operativo
- operativa
- OTTIMIZZA
- Opzione
- Opzioni
- or
- organizzazione
- Altro
- nostro
- risultati
- ancora
- proprio
- parte
- partner
- Ricambi
- modelli
- per
- perfettamente
- eseguire
- performance
- Personalizzata
- pioniere
- posto
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Popolare
- lavori
- possibilità
- possibilità
- Anteprima
- Precedente
- Privacy
- produrre
- Produzione
- produttivo
- Programmazione
- Promozioni
- comprovata
- fornire
- qualità
- rapidamente
- abbastanza
- gamma
- RE
- di rose
- valore reale
- tempo reale
- motivi
- ridurre
- rapporto
- rilasciato
- pertinente
- rimuovere
- Requisiti
- richiede
- nello specifico retail
- ritorno
- destra
- Ruolo
- Correre
- stesso
- Scalabilità
- Scala
- bilancia
- scala
- scienziati
- sdk
- Cerca
- Secondo
- secondo
- sicuro
- in modo sicuro
- vedere
- vedendo
- prodotti
- server
- serverless
- servizio
- Servizi
- set
- Condividi
- silos
- Un'espansione
- semplicità
- singolo
- piccole
- piccola impresa
- So
- alcuni
- Arrivo
- fonti
- tensione
- campate
- specifico
- velocità
- SQL
- Stage
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- Storie
- forte
- il successo
- supporto
- supporti
- sync.
- Fai
- obiettivi
- imposta
- Tecnologie
- Tecnologia
- decine
- di
- che
- Il
- Il futuro
- loro
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- think
- questo
- questa settimana
- quest'anno
- quelli
- migliaia
- tre
- Attraverso
- per tutto
- tempo
- volte
- a
- oggi
- insieme
- detto
- strumenti
- top
- Le transazioni
- transazioni al secondo
- Trasformare
- TURNO
- seconda
- Tipi di
- tipicamente
- capire
- unico
- sguinzagliare
- sblocco
- up-to-date
- su
- us
- uso
- caso d'uso
- utilizzato
- utenti
- usa
- utilizzando
- APPREZZIAMO
- vario
- Fisso
- Visualizza
- visione
- visivo
- vp
- volere
- Magazzino
- Prima
- Modo..
- modi
- we
- sito web
- servizi web
- settimana
- WELL
- è andato
- Che
- quando
- quale
- while
- OMS
- perché
- volere
- con
- entro
- senza
- Lavora
- lavorato
- flusso di lavoro
- flussi di lavoro
- lavoro
- lavori
- preoccuparsi
- scrivere
- scrittura
- scritto
- anno
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- zero