Il 29 gennaio è il National Puzzle Day e, per festeggiarlo, abbiamo creato un blog divertente che spiega dettagliatamente come risolvere il Sudoku utilizzando l'intelligenza artificiale (AI).
Introduzione
Prima Wordle, le Rompicapo di sudoku era di gran moda ed è ancora molto popolare. Negli ultimi anni, l'uso di ottimizzazione metodi per risolvere il puzzle è stato un tema dominante. Vedere “Risolvere il puzzle del Sudoku utilizzando l'ottimizzazione in Arkieva".
Al giorno d’oggi, l’uso dell’intelligenza artificiale è focalizzato sull’apprendimento automatico che comprende un’ampia gamma di metodi, dalla regressione al lazo all’apprendimento per rinforzo. L'uso dell'intelligenza artificiale ha riemerse per affrontare complessi programmazione sfide. Un metodo, la ricerca con backtracking, è comunemente usato ed è perfetto per il Sudoku.
Questo blog fornirà una descrizione dettagliata su come utilizzare questo metodo per risolvere il Sudoku. A quanto pare, il “backtracking” può essere trovato all’interno dei motori di ottimizzazione e di machine learning ed è una pietra angolare dell’euristica avanzata utilizzata da Arkieva per la pianificazione. L'algoritmo è implementato in un "Array Programming Language", un linguaggio di programmazione orientato alle funzioni che gestisce a ricco insieme di strutture di array.
Nozioni di base sul Sudoku
Da Wikipedia: Il Sudoku è un puzzle combinatorio basato sulla logica e sul posizionamento dei numeri. L'obiettivo è riempire una griglia 9×9 con cifre in modo che ogni colonna, ogni riga e ciascuna delle nove sottogriglie 3×3 che compongono la griglia (chiamate anche “riquadri”, “blocchi”, “regioni”, o "sottoquadrati") contiene tutte le cifre da 1 a 9. Il puzzle fornisce una griglia parzialmente completata, che in genere ha una soluzione unica. I puzzle completati sono sempre una sorta di quadrato latino con un vincolo aggiuntivo sul contenuto delle singole regioni. Ad esempio, lo stesso singolo numero intero non può apparire due volte nella stessa riga o colonna del tabellone da gioco 9×9 o in nessuna delle nove sottoregioni 3×3 del tabellone da gioco 9×9.
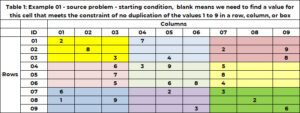
La tabella 1 presenta un problema di esempio. Ci sono 9 righe e 9 colonne per un totale di 81 celle. Ciascuno può avere uno e solo uno dei nove numeri interi compresi tra 1 e 9. Nella soluzione iniziale, una cella ha un singolo valore, che fissa il valore in questa cella a quel valore, oppure la cella è vuota, indicando che abbiamo bisogno per trovare un valore per questa cella. La cella (1,1) ha il valore 2 e la cella (6,5) ha il valore 6. La cella (1,2) e la cella (2,3) sono vuote e l'algoritmo troverà un valore per queste celle.
La complicazione
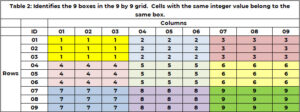
Oltre ad appartenere ad una ed una sola riga e colonna, una cella appartiene ad una ed una sola casella. Sono presenti 1 riquadri e sono indicati in base al colore nella Tabella 9. La Tabella 1 utilizza un numero intero univoco compreso tra 2 e 1 per identificare ciascuna casella o griglia. Le celle con un valore di riga pari a (9, 1 o 2) e un valore di colonna pari a (3, 1 o 2) appartengono alla casella 3. La casella 1 contiene valori di riga di (6, 4, 5) e valori di colonna (6, 7 , 8). L'ID della casella è determinato dalla formula BOX_ID = {9x(floor((ROW_ID-3) /1)} + soffitto (COL_ID/3). Per la cella (3), 5,7 = 6x(floor(3-5 ))/1) + soffitto (3/8)= 3×3 + 1 = 3+3.
Il cuore del puzzle
Trovare un valore intero compreso tra 1 e 9 per ogni cella sconosciuta in modo tale che i numeri interi da 1 a 9 vengano utilizzati una e una sola volta per ogni colonna, ogni riga e ogni casella.
Diamo un'occhiata alla cella (1,3) che è vuota. La riga 1 contiene già i valori 2 e 7. Questi non sono consentiti in questa cella. La colonna 3 ha già i valori 3, 5,6, 7,9. Questi non sono consentiti. La casella 1 (gialla) ha i valori 2, 3 e 8. Questi non sono ammessi. Non sono ammessi i seguenti valori (2,7); (3, 5, 6, 7, 9); (2, 3, 8). I valori univoci non consentiti sono (2, 3, 5, 6, 7, 8, 9). Gli unici valori candidati sono (1,4).
Un approccio risolutivo sarebbe quello di assegnare temporaneamente 1 alla cella (1,3) e quindi provare a trovare valori candidati per un'altra cella.
Una soluzione per tornare indietro: componenti iniziali
Struttura dell'array
Il punto di partenza è decidere una struttura di array per memorizzare il problema di origine e supportare la ricerca. La Tabella 3 ha questa struttura di array. La colonna 1 è un ID intero univoco per ogni cella. I valori vanno da 1 a 81. La colonna 2 è l'ID riga della cella. La colonna 3 è l'ID della colonna della cella. La colonna 4 è l'ID della casella. La colonna 5 è il valore nella cella. Osservare che a una cella senza valore viene assegnato il valore zero anziché vuoto o null. Ciò mantiene questo "array solo intero" - di gran lunga superiore in termini di prestazioni.

In APL, questo array verrebbe memorizzato in un array bidimensionale la cui forma è 2 per 81. Supponiamo che gli elementi della Tabella 5 siano memorizzati nella variabile MAT. Le funzioni di esempio sono:
Il comando MAT[1 2 3;]prende le prime 3 righe di MAT
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MAT[1 2 3; 4 5] protegge le righe 1, 2, 3 e solo le colonne 4 e 5
1 2
1 0
1 0
(MAT[;5]=0)/MAT[;1] trova tutte le celle che necessitano di un valore.
INSERIRE TABELLA 3
Controllo di integrità: duplicati
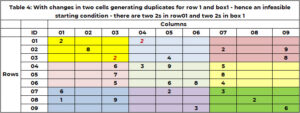
Prima di iniziare la ricerca, è fondamentale effettuare un controllo di integrità! Questa è la soluzione di partenza fattibile. È fattibile per il Sudoku se ora ci sono duplicati in qualsiasi riga, colonna o casella. L'attuale soluzione di partenza, ad esempio, 1 è fattibile. La Tabella 4 riporta un esempio in cui la soluzione iniziale presenta duplicati. La riga 1 ha due valori 2. L'area 1 ha due valori 2. La funzione "SANITY_DUPE" gestisce questa logica.
Controllo di integrità: opzioni per celle senza valori
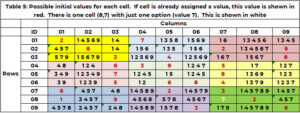
Un'informazione molto utile sarebbe tutti i possibili valori per una cella senza valore. Se non ci sono candidati, allora questo puzzle non è risolvibile. Una cella non può assumere un valore già rivendicato dal suo vicino. Utilizzando la Tabella 1 per Cella (1,3,'1' – quest'ultimo 1 è il boxid), i suoi vicini sono la riga 1, la colonna 3 e la casella 1. La riga 1 ha i valori (2,7); la colonna 3 ha i valori (3,5,6,7,9); la casella 1 contiene i valori (2,3,8). La cella (1,3.1) non può assumere i seguenti valori (2,3,5,6,7,8,9). Le uniche opzioni per la cella (1,3,1) sono (1,4). Per la cella (4,1,2) i valori 1, 2, 3, 5, 6, 7, 9 sono già utilizzati nella riga 4, colonna 1 e/o casella 4. Gli unici valori candidati sono (4,8) . L'unzione “SANITY_CAND” gestisce questa logica.
La tabella 5 mostra i candidati, ad esempio 1 all'inizio del processo di ricerca. Se a una cella è già stato assegnato un valore nelle condizioni iniziali (Tabella 1), allora questo valore viene ripetuto e mostrato in rosso. Se una cella che necessita di un valore ha una sola opzione, questa viene mostrata in bianco. La cella (8,7,9) ha il singolo valore 7 in bianco. (2,5,8,4,3) sono rivendicati dalla colonna vicina 7. (1, 2, 9) dalla riga 8. (3,2,6) dalla casella 9. Solo il valore 7 non è rivendicato.
Controllo di integrità: alla ricerca di conflitti
Le informazioni che identificano tutte le opzioni per le celle che necessitano di un valore (pubblicate nella Tabella 4), ci consentono di identificare un conflitto prima di iniziare il processo di ricerca. Un conflitto si verifica quando due celle che necessitano di un valore hanno un solo candidato, il valore candidato è lo stesso e le due celle sono vicine. Dalla Tabella 4 sappiamo che l'unica cella che necessita di un valore e ha un solo candidato è la cella (8,7,9). Ad esempio 1, non c'è conflitto.
Quale sarebbe un conflitto? Se l'unico valore possibile per la cella (3,7,3) era 7 (invece di 1, 6, 7), allora c'è un conflitto. La cella (8,7) e la cella (3,7) sono vicine: la stessa colonna. Tuttavia, se l'unico valore possibile per la cella (4,9,2) fosse 7 (invece di 1, 2, 7), ciò non costituirebbe un conflitto. Queste cellule non sono vicine.
Riepilogo del controllo di integrità
- Se sono presenti duplicati la soluzione di partenza non è fattibile.
- Se una cella che necessita di un valore non ha alcun candidato, allora non esiste una soluzione possibile a questo puzzle. L'elenco dei valori candidati per ciascuna cella può essere utilizzato per ridurre lo spazio di ricerca, sia per il backtracking che per l'ottimizzazione.
- La capacità di trovare conflitti identifica che il puzzle non è fattibile – non ha soluzione – senza un processo di ricerca. Inoltre, identifica le “celle problematiche”.
Una soluzione di backtracking: processo di ricerca
Una volta implementate le strutture dei dati principali e il controllo di integrità, rivolgiamo la nostra attenzione al processo di ricerca. Il tema ricorrente è ancora una volta quello di mettere in atto strutture di dati per supportare la ricerca.
Tracciamento della ricerca
L'array Tracker tiene traccia degli incarichi effettuati
- Col 1 è il contatore
- Col 2 è il numero di opzioni disponibili da assegnare a questa cella
- 1 significa 1 opzione disponibile, 2 significa due opzioni, ecc.
- 0 significa: nessuna opzione disponibile o reimpostazione a 0 (nessun valore assegnato) e backtracking
- Col 3 è la cella a cui è assegnato un numero di indice di valore (da 1 a 81)
- Col 4 è il valore assegnato alla cella nella cronologia traccia
- Un valore di 9999 significa che questa cella si trovava quando è stato trovato il vicolo cieco
- Il valore di un numero intero compreso tra 1 e 9 compreso è il valore assegnato a questa cella a questo punto del processo di ricerca.
- Un valore pari a 0 significa che questa cella necessita di un'assegnazione
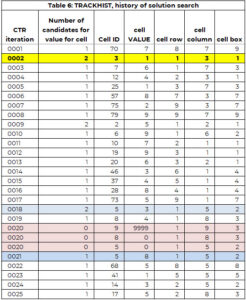
L'array tracker viene utilizzato per supportare il processo di ricerca. La matrice TRACKHIST ha la stessa struttura del tracker ma conserva la cronologia dell'intero processo di ricerca. La Tabella 6 contiene parte di TRACKHIST per l'esempio 1. Viene spiegato più dettagliatamente in una sezione successiva.
Inoltre, l'array PAV (un vettore di un vettore), tiene traccia dei valori precedentemente assegnati a questa cella. Ciò garantisce di non rivisitare una soluzione fallita, in modo simile a quanto avviene in TABU.
Esiste un processo di registro opzionale in cui il processo di ricerca scrive ogni passaggio.
Avvio della ricerca
Dopo aver effettuato la contabilità e il controllo di integrità, ora possiamo avviare il processo di ricerca. I passaggi sono:
- Sono rimaste delle celle che necessitano di un valore? – se no, allora abbiamo finito.
- Per ogni cella che necessita di un valore, trova tutte le opzioni candidate per ciascuna cella. La Tabella 4 presenta questi valori all'inizio del processo di soluzione. Ad ogni iterazione, questo viene aggiornato per accogliere i valori assegnati alle celle.
- Valuta le opzioni in questo ordine.
- Se una cella ha opzioni ZERO, istituisci il backtracking
- Trova tutte le celle con un'opzione, seleziona una di queste celle, esegui questo compito,
- e aggiornare la tabella di monitoraggio, la soluzione corrente e PAV.
- Se tutte le celle hanno più di un'opzione, seleziona una cella e un valore e aggiorna
- e aggiornare la tabella di monitoraggio, la soluzione corrente e PAV
Utilizzeremo la Tabella 6 che fa parte della cronologia del processo di soluzione (chiamata TRACKHIST) per illustrare ogni passaggio.
Nella prima iterazione (CTR=1), viene selezionata la cella 70 (riga 8, colonna 7, casella 9) per l'assegnazione di un valore. C'è solo il candidato (7) e questo valore viene assegnato alla cella 70. Inoltre, il valore 7 viene aggiunto al vettore dei valori precedentemente assegnati (PAV) per la cella 70.
Nella seconda iterazione alla cella 30 viene assegnato il valore 1. Questa cella aveva due valori candidati. Alla cella viene assegnato il valore candidato più piccolo (solo una regola arbitraria per rendere la logica facile da seguire).
Il processo di identificazione di una cella che necessita di un valore e di assegnazione di un valore funziona correttamente fino all'iterazione (CTR) 20. La cella 9 necessita di valore, ma il numero di candidati è ZERO. Ci sono due opzioni:
- Non esiste una soluzione a questo enigma.
- Annullamo (torniamo indietro) alcuni degli incarichi e prendiamo un'altra strada.
Abbiamo cercato l'assegnazione della cella più vicina a questa, dove c'era più di un'opzione. In questo esempio, ciò si è verificato all'iterazione 18, dove alla cella 5 è assegnato il valore 3, ma c'erano due valori candidati per la cella 5: valori 3 e 8.
Tra la cella 5 (CTR = 18) e la cella 9 (CTR = 20), alla cella 8 viene assegnato il valore 4 (CTR = 19). Rimettiamo le celle 8 e 5 nell'elenco "è necessario un valore". Questo viene catturato nella seconda e terza voce CTR=20, dove il valore è impostato su 0. Il valore 3 viene mantenuto nel vettore PAV per la cella 5. Ciò significa che il motore di ricerca non può assegnare il valore 3 alla cella 5.
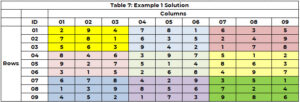
Il motore di ricerca si riavvia per identificare un valore per la cella 5 (con 3 non più disponibile) e assegna il valore 8 alla cella 5 (CTR=21). Continua finché tutte le celle non hanno un valore o c'è una cella senza opzioni e non esiste alcun percorso di ritorno. La soluzione è pubblicata nella tabella 7.
Osservare, dove c'è più di un candidato per una cella, questa è una possibilità per l'elaborazione parallela.
Confronto con la soluzione di ottimizzazione MILP
A livello superficiale, la rappresentazione del Sudoku è radicalmente diversa. L'approccio AI utilizza numeri interi e in ogni caso è una rappresentazione più precisa e intuitiva. Inoltre, i controlli di integrità forniscono informazioni utili per creare una formulazione più forte. La rappresentazione del MILP è infinita binari (0/1). Tuttavia, i binari sono rappresentazioni potenti data la forza dei moderni solutori MILP.
Tuttavia, internamente, il risolutore MILP non mantiene i file binari ma utilizza un metodo di array sparsi per eliminare la memorizzazione di tutti gli zeri. Inoltre, gli algoritmi per risolvere i sistemi binari non emergono fino agli anni ’1980 e ’1990. L'articolo del 1983 di Crowder, Johnson e Padberg riporta una delle prime soluzioni pratiche di ottimizzazione con i binari. Sottolineano l'importanza di una preelaborazione intelligente e di metodi branch and bound come fondamentali per una soluzione di successo.
La recente esplosione dell'uso della programmazione a vincoli e di software come risolutore locale ha chiarito l'importanza di utilizzare metodi di intelligenza artificiale con metodi di ottimizzazione originali come la programmazione lineare e i minimi quadrati.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 20
- 29
- 30
- 31
- 600
- 7
- 70
- 8
- 9
- a
- capacità
- ospitare
- aggiunto
- aggiunta
- aggiuntivo
- Inoltre
- Avanzate
- ancora
- AI
- algoritmo
- Algoritmi
- Tutti
- permesso
- già
- anche
- sempre
- Amazon
- an
- ed
- Un altro
- in qualsiasi
- apparire
- approccio
- arbitrario
- SONO
- RISERVATA
- Italia
- artificiale
- intelligenza artificiale
- Intelligenza artificiale (AI)
- AS
- addetto
- assumere
- At
- attenzione
- disponibile
- precedente
- BE
- stato
- prima
- appartenente
- appartiene
- fra
- vuoto
- Blog
- tavola
- entrambi
- legato
- Scatola
- scatole
- Branch di società
- ma
- by
- detto
- Materiale
- candidato
- i candidati
- non può
- catturato
- soffitto
- Celebration
- cella
- Celle
- sfide
- possibilità
- dai un'occhiata
- verifica
- rivendicato
- pulire campo
- colore
- Colonna
- colonne
- comunemente
- Completato
- complesso
- condizioni
- conflitto
- conflitti
- contiene
- testuali
- continua
- Nucleo
- pietra angolare
- creato
- critico
- Corrente
- dati
- giorno
- morto
- decide
- descrizione
- dettaglio
- dettagliati
- dettagli
- determinato
- diverso
- cifre
- do
- effettua
- dominante
- fatto
- Dont
- drammaticamente
- duplicati
- ogni
- facile
- o
- elementi
- eliminato
- emergere
- Abilita
- comprende
- fine
- Senza fine
- motore
- Motori
- assicura
- Intero
- eccetera
- esempio
- ha spiegato
- esplosione
- fallito
- lontano
- fattibile
- riempire
- Trovare
- trova
- sottile
- Nome
- correzioni
- concentrato
- seguire
- i seguenti
- Nel
- formula
- formulazione
- essere trovato
- da
- ti divertirai
- function
- funzioni
- ottenere
- dato
- Griglia
- ha avuto
- Maniglie
- Avere
- Cuore
- utile
- storia
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- ID
- identifica
- identificare
- identificazione
- if
- illustrare
- implementato
- importanza
- in
- Inclusivo
- Index
- indicato
- indicando
- individuale
- informazioni
- Informa
- interno
- invece
- Istituto
- Intelligence
- internamente
- intuitivo
- IT
- iterazione
- SUO
- Johnson
- jpg
- ad appena
- mantenere
- tenere
- Sapere
- Lingua
- Cognome
- dopo
- latino
- apprendimento
- meno
- a sinistra
- Livello
- lineare
- Lista
- ceppo
- logica
- più a lungo
- Guarda
- guardò
- cerca
- macchina
- machine learning
- fatto
- make
- max-width
- Maggio..
- si intende
- misurare
- metodo
- metodi
- moderno
- Scopri di più
- il
- Bisogno
- esigenze
- vicinato
- nove
- no
- Nota
- adesso
- numero
- obiettivo
- osservare
- si è verificato
- of
- on
- una volta
- ONE
- esclusivamente
- ottimizzazione
- Opzione
- Opzioni
- or
- minimo
- i
- nostro
- su
- Carta
- Parallel
- parte
- sentiero
- perfetta
- performance
- pezzo
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- punto
- Popolare
- possibile
- postato
- potente
- Pratico
- in precedenza
- Problema
- processi
- lavorazione
- Programmazione
- fornire
- fornisce
- metti
- puzzle
- Puzzle
- Rage
- gamma
- recente
- ricorrenti
- Rosso
- ridurre
- regioni
- regressione
- insegnamento rafforzativo
- ripetuto
- Report
- rappresentazione
- RIGA
- Regola
- stesso
- programmazione
- Cerca
- motore di ricerca
- Secondo
- Sezione
- Protegge
- vedere
- select
- selezionato
- set
- Forma
- mostrato
- Spettacoli
- simile
- singolo
- So
- Software
- soluzione
- Soluzioni
- RISOLVERE
- alcuni
- Fonte
- lo spazio
- quadrato
- piazze
- inizia a
- Di partenza
- inizio
- step
- Passi
- Ancora
- Tornare al suo account
- memorizzati
- forza
- più forte
- La struttura
- strutture
- di successo
- tale
- superiore
- supporto
- superficie
- tavolo
- attrezzatura
- Fai
- di
- che
- Il
- L’ORIGINE
- tema
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- Terza
- questo
- stretto
- volte
- a
- Totale
- pista
- Tracking
- prova
- TURNO
- si
- Due volte
- seconda
- Digitare
- tipicamente
- unico
- Sconosciuto
- fino a quando
- Aggiornanento
- aggiornato
- us
- uso
- utilizzato
- usa
- utilizzando
- APPREZZIAMO
- Valori
- variabile
- molto
- Prima
- we
- sono stati
- Che
- Che cosa è l'
- quando
- quale
- bianca
- largo
- Vasta gamma
- wikipedia
- volere
- con
- senza
- lavori
- sarebbe
- anni
- giallo
- zefiro
- zero