Le organizzazioni di tutti i settori hanno complessi requisiti di elaborazione dei dati per i loro casi d'uso analitici attraverso diversi sistemi di analisi, come ad esempio data lake su AWS, data warehouse (Amazon RedShift), ricerca (Servizio Amazon OpenSearch), NoSQL (Amazon DynamoDB), apprendimento automatico (Amazon Sage Maker), e altro ancora. I professionisti dell'analisi hanno il compito di trarre valore dai dati archiviati in questi sistemi distribuiti per creare esperienze migliori, sicure e ottimizzate in termini di costi per i propri clienti. Ad esempio, le società di media digitali cercano di combinare ed elaborare set di dati in database interni ed esterni per creare visualizzazioni unificate dei profili dei propri clienti, stimolare idee per funzionalità innovative e aumentare il coinvolgimento della piattaforma.
In questi scenari, i clienti che cercano un'offerta di integrazione dati serverless utilizzano Colla AWS come componente fondamentale per l'elaborazione e la catalogazione dei dati. AWS Glue è ben integrato con i servizi AWS e i prodotti dei partner e offre opzioni di estrazione, trasformazione e caricamento (ETL) a basso contenuto di codice/senza codice per abilitare analisi, machine learning (ML) o flussi di lavoro di sviluppo di applicazioni. I lavori ETL di AWS Glue possono essere un componente in una pipeline più complessa. Orchestrare l'esecuzione e gestire le dipendenze tra questi componenti è una funzionalità chiave in una strategia di dati. Flussi di lavoro gestiti da Amazon per Apache Airflows (Amazon MWAA) orchestra le pipeline di dati utilizzando tecnologie distribuite tra cui risorse locali, servizi AWS e componenti di terze parti.
In questo post, mostriamo come semplificare il monitoraggio di un processo AWS Glue orchestrato da Airflow utilizzando le funzionalità più recenti di Amazon MWAA.
Panoramica della soluzione
Questo post discute quanto segue:
- Come aggiornare un ambiente Amazon MWAA alla versione 2.4.3.
- Come orchestrare un processo AWS Glue da un flusso d'aria Grafico aciclico diretto (DAG).
- I miglioramenti dell'osservabilità del pacchetto del provider Airflow Amazon in Amazon MWAA. Ora puoi consolidare i log di esecuzione dei processi di AWS Glue sulla console Airflow per semplificare la risoluzione dei problemi delle pipeline di dati. La console Amazon MWAA diventa un unico riferimento per monitorare e analizzare le esecuzioni dei processi di AWS Glue. In precedenza, i team di supporto dovevano accedere al file Console di gestione AWS e adottare misure manuali per questa visibilità. Questa funzione è disponibile per impostazione predefinita da Amazon MWAA versione 2.4.3.
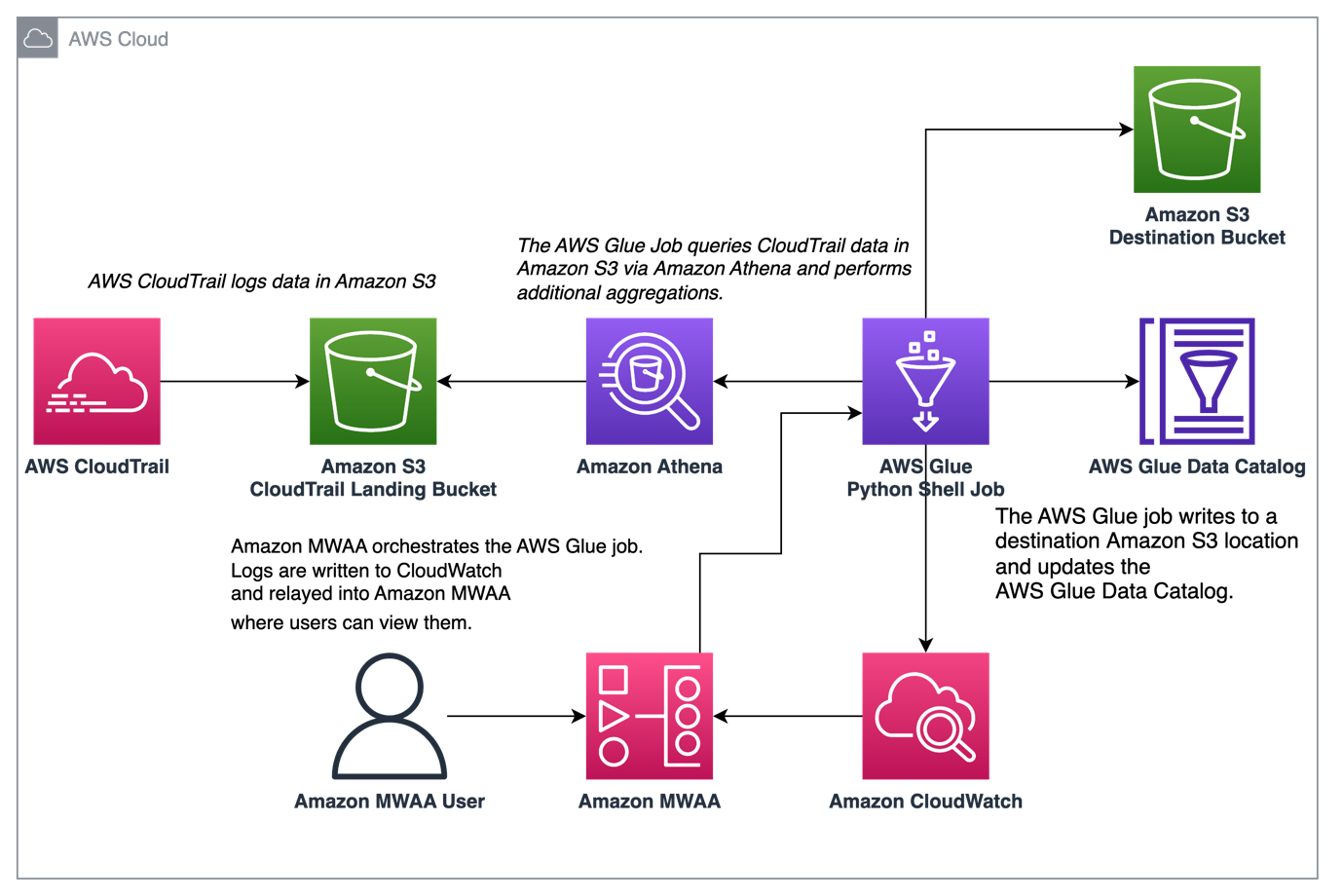
Il diagramma seguente illustra l'architettura della nostra soluzione.
Prerequisiti
Sono necessari i seguenti prerequisiti:
Configura l'ambiente Amazon MWAA
Per istruzioni sulla creazione dell'ambiente, fare riferimento a Crea un ambiente Amazon MWAA. Per gli utenti esistenti, consigliamo di eseguire l'aggiornamento alla versione 2.4.3 per sfruttare i miglioramenti dell'osservabilità descritti in questo post.
I passaggi per aggiornare Amazon MWAA alla versione 2.4.3 variano a seconda che la versione corrente sia 1.10.12 o 2.2.2. Discutiamo entrambe le opzioni in questo post.
Prerequisiti per la configurazione di un ambiente Amazon MWAA
È necessario soddisfare i seguenti prerequisiti:
Aggiornamento dalla versione 1.10.12 alla 2.4.3
Se utilizzi la versione Amazon MWAA 1.10.12, fare riferimento a Migrazione a un nuovo ambiente Amazon MWAA per aggiornare a 2.4.3.
Aggiornamento dalla versione 2.0.2 o 2.2.2 alla 2.4.3
Se utilizzi l'ambiente Amazon MWAA versione 2.2.2 o precedente, completa i seguenti passaggi:
- Creare un requirements.txt per eventuali dipendenze personalizzate con versioni specifiche richieste per i tuoi DAG.
- Carica il file su Amazon S3 nella posizione appropriata in cui l'ambiente Amazon MWAA punta al file requirements.txt per l'installazione delle dipendenze.
- Segui i passaggi Migrazione a un nuovo ambiente Amazon MWAA e selezionare la versione 2.4.3.
Aggiorna i tuoi DAG
I clienti che hanno eseguito l'upgrade da un ambiente Amazon MWAA precedente potrebbero dover aggiornare i DAG esistenti. In Airflow versione 2.4.3, l'ambiente Airflow utilizzerà per impostazione predefinita il pacchetto del provider Amazon versione 6.0.0. Questo pacchetto può includere alcune modifiche potenzialmente dannose, come le modifiche ai nomi degli operatori. Ad esempio, il Operatore AWSGlueJob è stato deprecato e sostituito con il GlueJobOperator. Per mantenere la compatibilità, aggiorna i tuoi DAG Airflow sostituendo tutti gli operatori obsoleti o non supportati dalle versioni precedenti con quelli nuovi. Completa i seguenti passaggi:
- Spostarsi Operatori Amazon AWS.
- Seleziona la versione appropriata installata nella tua istanza Amazon MWAA (6.0.0. per impostazione predefinita) per trovare un elenco di operatori Airflow supportati.
- Apporta le modifiche necessarie al codice DAG esistente e carica i file modificati nella posizione DAG in Amazon S3.
Orchestra il processo AWS Glue da Airflow
Questa sezione tratta i dettagli dell'orchestrazione di un processo AWS Glue all'interno di DAG Airflow. Airflow facilita lo sviluppo di pipeline di dati con dipendenze tra sistemi eterogenei come processi locali, dipendenze esterne, altri servizi AWS e altro ancora.
Orchestra l'aggregazione dei log di CloudTrail con AWS Glue e Amazon MWAA
In questo esempio, esaminiamo un caso d'uso di utilizzo di Amazon MWAA per orchestrare un processo AWS Glue Python Shell che persiste i parametri aggregati basati sui log di CloudTrail.
CloudTrail consente la visibilità delle chiamate API AWS effettuate nel tuo account AWS. Un caso d'uso comune con questi dati sarebbe quello di raccogliere metriche di utilizzo sulle entità che agiscono sulle risorse del tuo account per esigenze di controllo e normative.
Quando gli eventi CloudTrail vengono registrati, vengono forniti come file JSON in Amazon S3, che non sono l'ideale per le query analitiche. Vogliamo aggregare questi dati e mantenerli come file Parquet per consentire prestazioni di query ottimali. Come passaggio iniziale, possiamo utilizzare Athena per eseguire l'interrogazione iniziale dei dati prima di eseguire ulteriori aggregazioni nel nostro lavoro AWS Glue. Per ulteriori informazioni sulla creazione di una tabella Catalogo dati di AWS Glue, consulta Creazione della tabella per i log di CloudTrail in Athena utilizzando la proiezione della partizione dati. Dopo aver esplorato i dati tramite Athena e deciso quali parametri conservare nelle tabelle aggregate, possiamo creare un processo AWS Glue.
Crea una tabella CloudTrail in Athena
Innanzitutto, dobbiamo creare una tabella nel nostro catalogo dati che consenta di eseguire query sui dati di CloudTrail tramite Athena. La query di esempio seguente crea una tabella con due partizioni in Region e date (denominata snapshot_date). Assicurati di sostituire i segnaposto per il bucket CloudTrail, l'ID account AWS e il nome della tabella CloudTrail:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Esegui la query precedente sulla console Athena e annota il nome della tabella e il database del catalogo dati di AWS Glue in cui è stato creato. Utilizziamo questi valori più avanti nel codice DAG Airflow.
Esempio di codice processo AWS Glue
Il codice seguente è un esempio Lavoro AWS Glue Python Shell che fa quanto segue:
- Prende gli argomenti (che passiamo dal nostro Amazon MWAA DAG) sui dati del giorno da elaborare
- Usa il SDK AWS per Panda per eseguire una query Athena per eseguire il filtraggio iniziale dei dati JSON di CloudTrail all'esterno di AWS Glue
- Utilizza Pandas per eseguire semplici aggregazioni sui dati filtrati
- Invia i dati aggregati al Catalogo dati di AWS Glue in una tabella
- Utilizza la registrazione durante l'elaborazione, che sarà visibile in Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Di seguito sono riportati alcuni vantaggi chiave in questo processo AWS Glue:
- Utilizziamo una query Athena per garantire che il filtraggio iniziale venga eseguito al di fuori del nostro lavoro AWS Glue. Pertanto, un job Python Shell con un calcolo minimo è ancora sufficiente per aggregare un set di dati CloudTrail di grandi dimensioni.
- Assicuriamo il opzione del set di librerie di analisi è attivato durante la creazione del processo AWS Glue per utilizzare la libreria SDK AWS per Pandas.
Crea un processo AWS Glue
Completa i seguenti passaggi per creare il tuo processo AWS Glue:
- Copia lo script nella sezione precedente e salvalo in un file locale. Per questo post, il file si chiama
script.py. - Nella console AWS Glue, scegli Lavori ETL nel pannello di navigazione.
- Crea un nuovo lavoro e seleziona Editor di script Python Shell.
- Seleziona Carica e modifica uno script esistente e carica il file che hai salvato in locale.
- Scegli Creare.

- Sulla Dettagli di lavoro scheda, inserisci un nome per il tuo processo AWS Glue.
- Nel Ruolo IAM, scegli un ruolo esistente o creane uno nuovo che disponga delle autorizzazioni necessarie per Amazon S3, AWS Glue e Athena. Il ruolo deve eseguire una query sulla tabella CloudTrail creata in precedenza e scrivere in un percorso di output.
È possibile utilizzare il seguente codice di criteri di esempio. Sostituisci i segnaposto con il tuo bucket di log CloudTrail, il nome della tabella di output, il database AWS Glue di output, il bucket S3 di output, il nome della tabella CloudTrail, il database AWS Glue contenente la tabella CloudTrail e il tuo ID account AWS.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Nel Versione Pythonscegli Python 3.9.
- Seleziona Carica librerie di analisi comuni.
- Nel Unità di elaborazione datiscegli 1 DP.
- Lascia le altre opzioni come predefinite o regolale secondo necessità.

- Scegli Risparmi per salvare la configurazione del lavoro.
Configura un DAG Amazon MWAA per orchestrare il processo AWS Glue
Il codice seguente è per un DAG in grado di orchestrare il processo AWS Glue che abbiamo creato. Sfruttiamo le seguenti funzionalità chiave in questo DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Aumenta l'osservabilità dei lavori di AWS Glue in Amazon MWAA
I processi AWS Glue scrivono i log in Amazon Cloud Watch. Con i recenti miglioramenti dell'osservabilità al pacchetto del provider Amazon di Airflow, questi registri sono ora integrati con i registri delle attività di Airflow. Questo consolidamento offre agli utenti di Airflow una visibilità end-to-end direttamente nell'interfaccia utente di Airflow, eliminando la necessità di effettuare ricerche in CloudWatch o nella console AWS Glue.
Per utilizzare questa funzionalità, assicurati che il ruolo IAM collegato all'ambiente Amazon MWAA disponga delle seguenti autorizzazioni per recuperare e scrivere i log necessari:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Se verbose=true, i log di esecuzione del processo di AWS Glue vengono visualizzati nei log delle attività di Airflow. L'impostazione predefinita è false. Per ulteriori informazioni, fare riferimento a parametri.
Se abilitati, i DAG leggono dal flusso di log CloudWatch del lavoro AWS Glue e li inoltrano ai log delle fasi del lavoro AWS Glue del DAG Airflow. Ciò fornisce informazioni dettagliate sull'esecuzione di un lavoro di AWS Glue in tempo reale tramite i log DAG. Tieni presente che i processi di AWS Glue generano un gruppo di log CloudWatch di output e di errore in base rispettivamente a STDOUT e STDERR del processo. Tutti i log nel gruppo di log di output e i log delle eccezioni o degli errori del gruppo di log degli errori vengono inoltrati in Amazon MWAA.
Gli amministratori AWS ora possono limitare l'accesso di un team di supporto solo ad Airflow, rendendo Amazon MWAA l'unico punto di riferimento per l'orchestrazione dei lavori e la gestione dello stato dei lavori. In precedenza, gli utenti dovevano controllare lo stato di esecuzione del lavoro di AWS Glue nelle fasi del DAG di Airflow e recuperare l'identificatore di esecuzione del lavoro. Avevano quindi bisogno di accedere alla console AWS Glue per trovare la cronologia di esecuzione del lavoro, cercare il lavoro di interesse utilizzando l'identificatore e infine passare ai log di CloudWatch del lavoro per risolvere i problemi.
Creare il DAG
Per creare il DAG, completare i seguenti passaggi:
- Salva il codice DAG precedente in un file .py locale, sostituendo i segnaposto indicati.
I valori per l'ID account AWS, il nome del processo AWS Glue, il database AWS Glue con la tabella CloudTrail e il nome della tabella CloudTrail dovrebbero essere già noti. Puoi modificare il bucket S3 di output, il database AWS Glue di output e il nome della tabella di output in base alle esigenze, ma assicurati che il ruolo IAM del processo AWS Glue utilizzato in precedenza sia configurato di conseguenza.
- Nella console Amazon MWAA, accedi al tuo ambiente per vedere dove è archiviato il codice DAG.
La cartella DAG è il prefisso all'interno del bucket S3 in cui deve essere posizionato il file DAG.
- Carica lì il tuo file modificato.

- Apri la console Amazon MWAA per verificare che il DAG sia visualizzato nella tabella.

Esegui il DAG
Per eseguire il DAG, completare i seguenti passaggi:
- Scegli tra le seguenti opzioni:
- Attiva DAG – In questo modo i dati di ieri vengono utilizzati come dati da elaborare
- Attiva DAG con config – Con questa opzione è possibile passare una data diversa, potenzialmente per i backfill, che viene recuperata utilizzando
dag_run.confnel codice DAG e quindi passato nel processo AWS Glue come parametro

Lo screenshot seguente mostra le opzioni di configurazione aggiuntive, se lo desideri Attiva DAG con config.

- Monitorare il DAG durante l'esecuzione.
- Quando il DAG è completo, apri i dettagli dell'esecuzione.
Nel riquadro di destra è possibile visualizzare i registri o scegliere Dettagli dell'istanza di attività per una visione completa.

- Visualizza i log di output del lavoro AWS Glue in Amazon MWAA senza utilizzare la console AWS Glue grazie a
GlueJobOperatorbandiera prolissa.

Il processo AWS Glue avrà i risultati scritti nella tabella di output specificata.
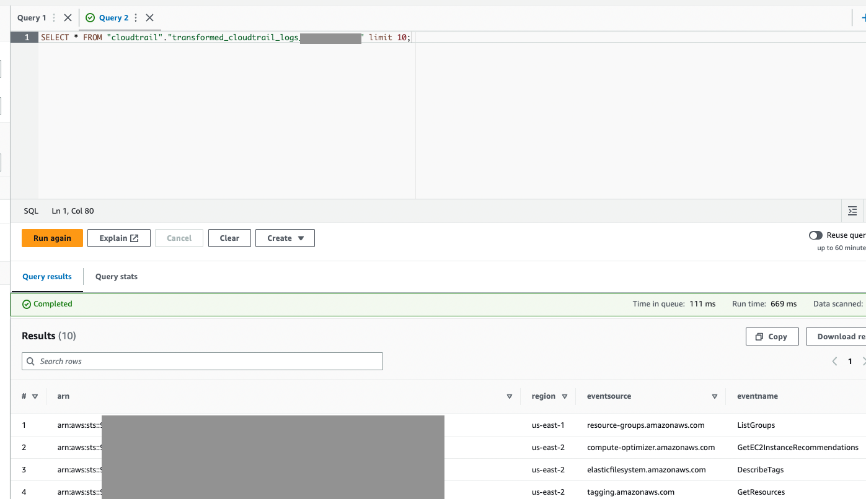
- Interroga questa tabella tramite Athena per confermare che ha avuto successo.
Sommario
Amazon MWAA ora offre un'unica posizione per tenere traccia dello stato dei processi di AWS Glue e ti consente di utilizzare la console Airflow come unico pannello di controllo per l'orchestrazione dei processi e la gestione dello stato. In questo post, abbiamo seguito i passaggi per orchestrare i lavori di AWS Glue tramite Airflow utilizzando GlueJobOperator. Con i nuovi miglioramenti dell'osservabilità, puoi risolvere facilmente i problemi dei processi di AWS Glue in un'esperienza unificata. Abbiamo anche dimostrato come aggiornare il tuo ambiente Amazon MWAA a una versione compatibile, aggiornare le dipendenze e modificare la policy del ruolo IAM di conseguenza.
Per ulteriori informazioni sui passaggi comuni per la risoluzione dei problemi, fare riferimento a Risoluzione dei problemi: creazione e aggiornamento di un ambiente Amazon MWAA. Per dettagli approfonditi sulla migrazione a un ambiente Amazon MWAA, fare riferimento a Aggiornamento da 1.10 a 2. Per informazioni sulle modifiche al codice open source per una maggiore osservabilità dei lavori di AWS Glue nel pacchetto del provider Airflow Amazon, fare riferimento al inoltrare i log dai processi di AWS Glue.
Infine, ti consigliamo di visitare il Blog sui Big Data di AWS per altro materiale su analisi, ML e governance dei dati su AWS.
Informazioni sugli autori
 Rushab Lokhande è un Data & ML Engineer con AWS Professional Services Analytics Practice. Aiuta i clienti a implementare soluzioni di big data, machine learning e analisi. Al di fuori del lavoro, ama passare il tempo con la famiglia, leggere, correre e giocare a golf.
Rushab Lokhande è un Data & ML Engineer con AWS Professional Services Analytics Practice. Aiuta i clienti a implementare soluzioni di big data, machine learning e analisi. Al di fuori del lavoro, ama passare il tempo con la famiglia, leggere, correre e giocare a golf.
 Ryan Gomes è un Data & ML Engineer con AWS Professional Services Analytics Practice. È appassionato di aiutare i clienti a ottenere risultati migliori attraverso soluzioni di analisi e apprendimento automatico nel cloud. Al di fuori del lavoro, ama il fitness, cucinare e trascorrere del tempo di qualità con amici e familiari.
Ryan Gomes è un Data & ML Engineer con AWS Professional Services Analytics Practice. È appassionato di aiutare i clienti a ottenere risultati migliori attraverso soluzioni di analisi e apprendimento automatico nel cloud. Al di fuori del lavoro, ama il fitness, cucinare e trascorrere del tempo di qualità con amici e familiari.
 Vishwa Gupta è Senior Data Architect con AWS Professional Services Analytics Practice. Aiuta i clienti a implementare soluzioni di analisi e big data. Al di fuori del lavoro, gli piace passare il tempo con la famiglia, viaggiare e provare nuovi cibi.
Vishwa Gupta è Senior Data Architect con AWS Professional Services Analytics Practice. Aiuta i clienti a implementare soluzioni di analisi e big data. Al di fuori del lavoro, gli piace passare il tempo con la famiglia, viaggiare e provare nuovi cibi.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Coniare il futuro con Adryenn Ashley. Accedi qui.
- Acquista e vendi azioni in società PRE-IPO con PREIPO®. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 10
- 100
- 12
- 8
- a
- Chi siamo
- accesso
- di conseguenza
- Il mio account
- Raggiungere
- operanti in
- Action
- aciclico
- aggiuntivo
- Vantaggio
- vantaggi
- Dopo shavasana, sedersi in silenzio; saluti;
- aggregazione
- Tutti
- consentire
- consente
- già
- anche
- Amazon
- Amazon Web Services
- an
- Analitico
- analitica
- analizzare
- ed
- in qualsiasi
- Apache
- api
- Applicazioni
- Sviluppo di applicazioni
- opportuno
- architettura
- SONO
- argomento
- argomenti
- AS
- At
- gli attributi
- revisione
- disponibile
- AWS
- Colla AWS
- Servizi professionali AWS
- basato
- BE
- diventa
- stato
- prima
- essendo
- Meglio
- fra
- Big
- Big Data
- entrambi
- Rottura
- costruire
- ma
- by
- detto
- Bandi
- Materiale
- Custodie
- casi
- catalogo
- cause
- il cambiamento
- Modifiche
- dai un'occhiata
- Scegli
- Cloud
- codice
- COM
- combinare
- commento
- Uncommon
- Aziende
- compatibilità
- compatibile
- completamento di una
- complesso
- componente
- componenti
- Calcolare
- Configurazione
- Confermare
- consolle
- consolidare
- consolidamento
- cucina
- Nucleo
- copre
- creare
- creato
- crea
- Creazione
- Corrente
- costume
- cliente
- Clienti
- GIORNO
- dati
- integrazione dei dati
- elaborazione dati
- strategia di dati
- data warehouse
- Banca Dati
- banche dati
- dataset
- Data
- Date
- datetime
- Giorni
- deciso
- Predefinito
- consegnato
- dimostrato
- Dipendente
- deprecato
- dettagliati
- dettagli
- Mercato
- differire
- diverso
- digitale
- Media digitali
- direttamente
- discutere
- distribuito
- sistemi distribuiti
- do
- effettua
- fare
- fatto
- durante
- e
- In precedenza
- Facilita
- effetto
- eliminando
- altro
- enable
- abilitato
- Abilita
- da un capo all'altro
- Fidanzamento
- ingegnere
- miglioramenti
- garantire
- entrare
- Ambiente
- errore
- Etere (ETH)
- eventi
- esempio
- Tranne
- eccezione
- esistere
- esistente
- esiste
- esperienza
- Esperienze
- Esplorazione
- espressione
- esterno
- estratto
- fallito
- falso
- famiglia
- caratteristica
- In primo piano
- Caratteristiche
- Compila il
- File
- filtraggio
- Infine
- Trovare
- fitness
- i seguenti
- cibo
- Nel
- formato
- amici
- da
- pieno
- raccogliere
- generare
- vetro.
- Go
- golf
- la governance
- Gruppo
- Hadoop
- Avere
- he
- Salute e benessere
- aiutare
- aiuta
- storia
- Alveare
- Come
- Tutorial
- HTML
- http
- HTTPS
- IAM
- ID
- ideale
- idee
- identificatore
- if
- illustra
- realizzare
- importare
- in
- Uno sguardo approfondito sui miglioramenti dei pneumatici da corsa di Bridgestone.
- includere
- Compreso
- Aumento
- è aumentato
- indicato
- industrie
- info
- informazioni
- inizialmente
- creativi e originali
- intuizioni
- installazione
- esempio
- istruzioni
- integrato
- integrazione
- interesse
- interno
- ai miglioramenti
- IT
- Lavoro
- Offerte di lavoro
- jpg
- json
- Le
- conosciuto
- grandi
- dopo
- con i più recenti
- IMPARARE
- apprendimento
- Biblioteca
- LIMITE
- Lista
- caricare
- locale
- a livello locale
- località
- ceppo
- registrati
- registrazione
- cerca
- macchina
- machine learning
- fatto
- mantenere
- make
- Fare
- gestito
- gestione
- gestione
- Manuale
- materiale
- Maggio..
- Media
- Soddisfare
- messaggio
- Metrica
- la migrazione
- minimo
- ML
- modificato
- modulo
- Monitorare
- monitoraggio
- Scopri di più
- devono obbligatoriamente:
- Nome
- nomi
- Navigare
- Navigazione
- necessaria
- Bisogno
- di applicazione
- esigenze
- New
- Niente
- adesso
- of
- offerta
- on
- ONE
- quelli
- esclusivamente
- aprire
- open source
- codice open source
- operatore
- Operatori
- ottimale
- Opzione
- Opzioni
- or
- orchestrato
- orchestrazione
- Altro
- nostro
- risultati
- produzione
- al di fuori
- pacchetto
- panda
- vetro
- parametri
- partner
- passare
- Passato
- appassionato
- performance
- permessi
- persiste
- conduttura
- posto
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- punti
- politica
- Post
- potenzialmente
- pratica
- prerequisiti
- precedente
- in precedenza
- processi
- i processi
- lavorazione
- Prodotti
- professionale
- Scelto dai professionisti
- Profili
- Proiezione
- fornitore
- fornitori
- fornisce
- Python
- qualità
- query
- aumentare
- gamma
- Leggi
- Lettura
- di rose
- tempo reale
- recente
- raccomandare
- regione
- normativo
- staffetta
- sostituire
- sostituito
- necessario
- Requisiti
- risorsa
- Risorse
- rispettivamente
- risposta
- Risultati
- conservare
- destra
- Ruolo
- RIGA
- Correre
- running
- s
- Risparmi
- Scenari
- sdk
- senza soluzione di continuità
- Cerca
- Sezione
- sicuro
- vedere
- Cercare
- anziano
- serverless
- Servizi
- regolazione
- flessibile.
- Conchiglia
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- Un'espansione
- semplificare
- da
- singolo
- Istantanea
- soluzione
- Soluzioni
- alcuni
- specifico
- specificato
- Spendere
- dichiarazione
- Stato dei servizi
- step
- Passi
- Ancora
- conservazione
- memorizzati
- Strategia
- ruscello
- Corda
- di successo
- tale
- sufficiente
- supporto
- supportato
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- presa
- Task
- le squadre
- Tecnologie
- modello
- Grazie
- che
- Il
- loro
- Li
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- di parti terze standard
- questo
- Attraverso
- tempo
- a
- pista
- Trasformare
- Di viaggio
- vero
- prova
- Martedì
- Turned
- seconda
- Digitare
- ui
- unificato
- unità
- Aggiornanento
- Aggiornamenti
- aggiornamento
- upgrade
- aggiornato
- Caricamento
- Impiego
- uso
- caso d'uso
- utilizzato
- utenti
- utilizzando
- APPREZZIAMO
- Valori
- versione
- via
- Visualizza
- visualizzazioni
- visibilità
- visibile
- camminava
- volere
- Prima
- we
- sito web
- servizi web
- WELL
- Che
- quando
- se
- quale
- OMS
- volere
- con
- entro
- senza
- Lavora
- flussi di lavoro
- sarebbe
- scrivere
- scritto
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro