Poiché l’ingegneria dei dati diventa sempre più complessa, le organizzazioni sono alla ricerca di nuovi modi per semplificare i flussi di lavoro di elaborazione dei dati. Molti ingegneri dei dati oggi utilizzano Apache Airflow per creare, pianificare e monitorare le proprie pipeline di dati.
Tuttavia, man mano che il volume dei dati cresce, la gestione e il ridimensionamento di queste pipeline possono diventare un compito arduo. Flussi di lavoro gestiti da Amazon per Apache Airflow (Amazon MWAA) può aiutare a semplificare il processo di creazione, esecuzione e gestione delle pipeline di dati. Fornendo Apache Airflow come piattaforma completamente gestita, Amazon MWAA consente agli ingegneri dei dati di concentrarsi sulla creazione di flussi di lavoro dei dati invece di preoccuparsi dell'infrastruttura.
Oggi, le aziende e le organizzazioni necessitano di metodi efficienti ed economici per elaborare grandi quantità di dati. Amazon EMR senza server è una soluzione economica e scalabile per l'elaborazione di big data in grado di gestire grandi volumi di dati. Il provider Amazon in Apache Airflow viene fornito con operatori EMR Serverless ed è già incluso in Amazon MWAA, consentendo agli ingegneri dei dati di creare facilmente pipeline di elaborazione dati scalabili e affidabili. Puoi utilizzare EMR Serverless per eseguire processi Spark sui dati e utilizzare Amazon MWAA per gestire i flussi di lavoro e le dipendenze tra questi processi. Questa integrazione può anche contribuire a ridurre i costi ridimensionando automaticamente le risorse necessarie per elaborare i dati.
Amazon Athena è un servizio di analisi interattivo serverless basato su framework open source, che supporta formati di file e tabelle aperte. È possibile utilizzare SQL standard per interagire con i dati. Athena, un servizio di analisi serverless e interattivo, rende tutto ciò possibile senza la necessità di gestire infrastrutture complesse.
In questo post utilizziamo Amazon MWAA, EMR Serverless e Athena per creare una pipeline completa di elaborazione dati end-to-end.
Panoramica della soluzione
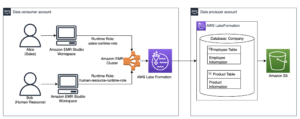
Il diagramma seguente illustra l'architettura della soluzione.
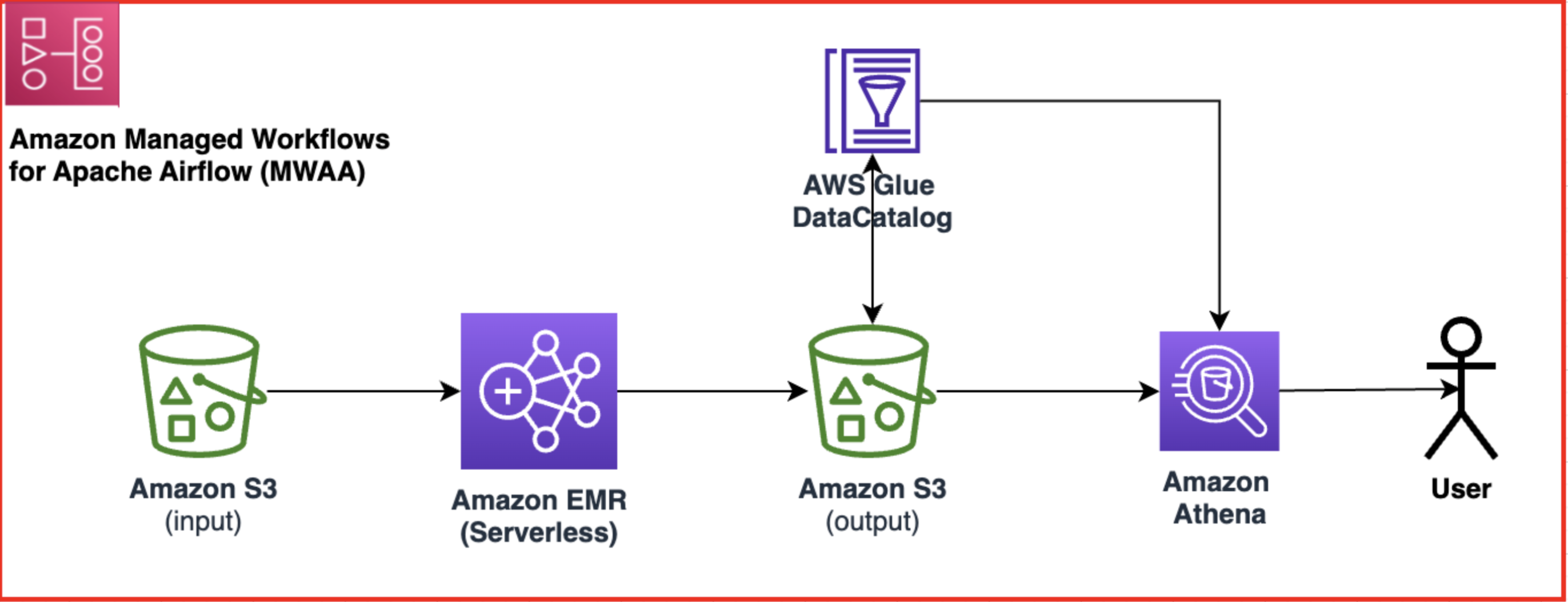
Il flusso di lavoro include i seguenti passaggi:
- Crea un flusso di lavoro Amazon MWAA che recuperi i dati dal tuo input Servizio di archiviazione semplice Amazon (Amazon S3) secchio.
- Utilizza EMR Serverless per elaborare i dati archiviati in Amazon S3. EMR Serverless si dimensiona automaticamente verso l'alto o verso il basso in base al carico di lavoro, quindi non devi preoccuparti del provisioning o della gestione di alcuna infrastruttura.
- Utilizza EMR Serverless per trasformare i dati utilizzando il codice PySpark e quindi archivia nuovamente i dati trasformati nel tuo bucket S3.
- Utilizza Athena per creare una tabella esterna basata sul set di dati S3 ed eseguire query per analizzare i dati trasformati. Atena usa il Colla AWS Data Catalog per archiviare i metadati della tabella.
Prerequisiti
Dovresti avere i seguenti prerequisiti:
Preparazione dei dati
Per illustrare l'utilizzo dei processi EMR Serverless con Apache Spark tramite Amazon MWAA e la convalida dei dati utilizzando Athena, utilizziamo il set di dati sui taxi di New York disponibile pubblicamente. Scarica i seguenti set di dati sul tuo computer locale:
- Record di viaggio dei taxi verdi e dei taxi gialli – Record di viaggio per taxi gialli e verdi, che includono informazioni quali date e orari di ritiro e riconsegna, posizioni, distanze di viaggio e tipi di pagamento. Nel nostro esempio, utilizziamo gli ultimi file Parquet per il 2022.
- Set di dati per la ricerca della zona dei taxi – Un set di dati che fornisce gli ID di posizione e i dettagli della zona corrispondente per i taxi.
Nelle fasi successive, carichiamo questi set di dati su Amazon S3.
Crea risorse per le soluzioni
Questa sezione descrive i passaggi per impostare l'elaborazione e la trasformazione dei dati.
Crea un'applicazione EMR Serverless
Puoi creare una o più applicazioni EMR Serverless che utilizzano framework di analisi open source come Apache Spark o Apache Hive. A differenza di EMR su EC2, non è necessario eliminare o terminare le applicazioni EMR Serverless. L'applicazione EMR Serverless è solo una definizione e, una volta creata, può essere riutilizzata per tutto il tempo necessario. Ciò semplifica la pipeline MWAA poiché ora devi solo inviare i lavori a un'applicazione Serverless EMR precreata.
Di default, l'applicazione EMR Serverless si avvierà automaticamente all'invio del lavoro e si arresterà automaticamente quando inattiva per 15 minuti per impostazione predefinita per garantire efficienza in termini di costi. È possibile modificare la quantità di tempo di inattività o scegliere di disattivare la funzione.
Per creare un'applicazione utilizzando la console EMR Serverless, seguire le istruzioni in "Crea un'applicazione EMR Serverless". Annotare l'ID dell'applicazione poiché lo utilizzeremo nei passaggi successivi.
![]()
Crea un bucket S3 e cartelle
Completa i seguenti passaggi per configurare il bucket e le cartelle S3:
- Sulla console Amazon S3, crea un bucket S3 per memorizzare il set di dati.
- Prendi nota del nome del bucket S3 da utilizzare nei passaggi successivi.
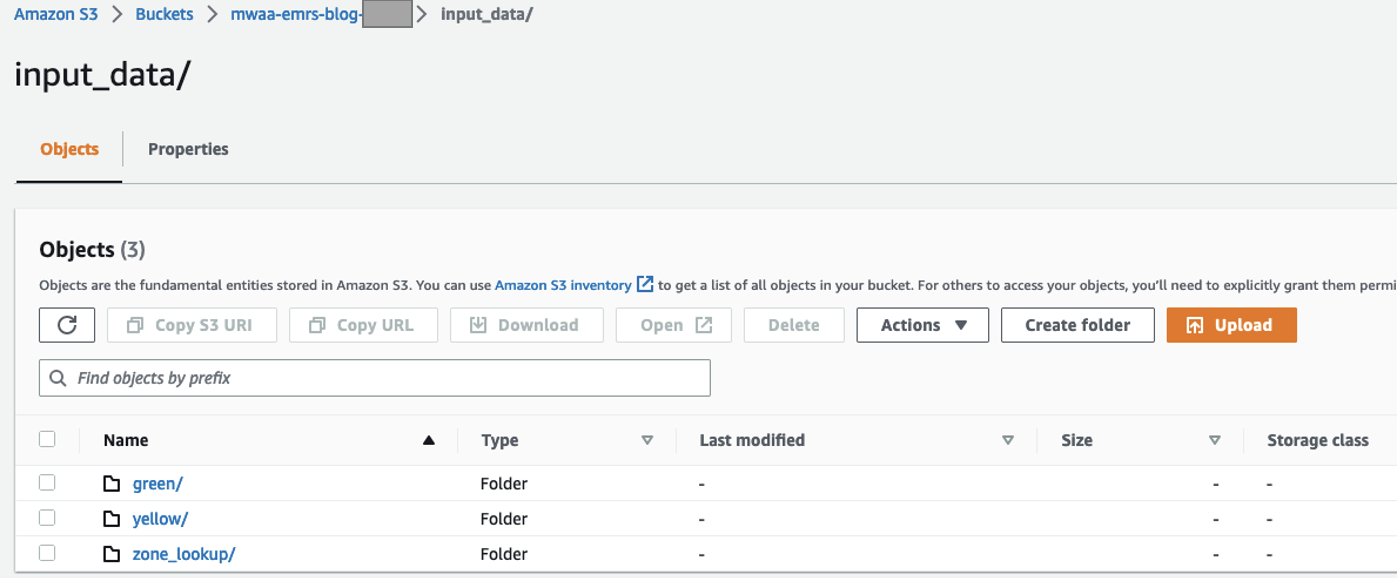
- Creare un
input_datacartella per la memorizzazione dei dati di input. - All'interno di tale cartella, crea tre cartelle separate, una per ciascun set di dati:
green,yellowezone_lookup.
È possibile scaricare e lavorare con i set di dati più recenti disponibili. Per i nostri test utilizziamo i seguenti file:
- Il
green/la cartella contiene il filegreen_tripdata_2022-06.parquet - Il
yellow/la cartella contiene il fileyellow_tripdata_2022-06.parquet - Il
zone_lookup/la cartella contiene il filetaxi_zone_lookup.csv
Configura gli script DAG Amazon MWAA
Completa i seguenti passaggi per configurare gli script DAG:
- Scarica i seguenti script sul tuo computer locale:
- requirements.txt – Una dipendenza Python è qualsiasi pacchetto o distribuzione non inclusa nell'installazione di base di Apache Airflow per la versione di Apache Airflow nell'ambiente Amazon MWAA. Per questo post utilizziamo Boto3
version >=1.23.9. - blog_dag_mwaa_emrs_ny_taxi.py – Questo script fa parte del DAG Amazon MWAA ed è costituito dalle seguenti attività:
yellow_taxi_zone_lookup,green_taxi_zone_lookupeny_taxi_summary,. Queste attività prevedono l'esecuzione di processi Spark per la ricerca di zone taxi e la generazione di un riepilogo dei dati. - green_zone.py – Questo script PySpark legge i file di dati per le corse dei taxi verdi e la ricerca delle zone, esegue un'operazione di unione per combinarli e genera un file di output contenente le corse dei taxi verdi con informazioni sulla zona. Utilizza visualizzazioni temporanee per il file
df_greeneddf_zoneframe di dati, esegue join basati su colonne e aggrega dati come il conteggio dei passeggeri, la distanza del viaggio e l'importo della tariffa. Infine, crea iloutput_datacartella nel bucket S3 specificato per scrivere il frame di dati risultante,df_green_zone, come file Parquet. - giallo_zona.py – Questo script PySpark elabora i file di dati sulle corse dei taxi gialli e sulla ricerca delle zone unendoli per generare un file di output contenente le corse dei taxi gialli con le informazioni sulla zona. Lo script accetta un nome di bucket S3 fornito dall'utente e avvia una sessione Spark con il nome dell'applicazione
yellow_zone. Legge i file dei taxi gialli e il file di ricerca delle zone dal bucket S3 specificato, crea visualizzazioni temporanee, esegue un join in base all'ID della posizione e calcola statistiche come il conteggio dei passeggeri, la distanza del viaggio e l'importo della tariffa. Infine, crea iloutput_datacartella nel bucket S3 specificato per scrivere il frame di dati risultante,df_yellow_zone, come file Parquet. - ny_taxi_summary.py – Questo script PySpark elabora il file
green_zoneedyellow_zonefile per aggregare statistiche sulle corse in taxi, raggruppando i dati per zone di servizio e ID di posizione. Richiede un nome di bucket S3 come argomento della riga di comando e crea una SparkSession denominatany_taxi_summary, legge i file da S3, esegue un join e genera un nuovo frame di dati denominatony_taxi_summary. Crea una cartella output_data nel bucket S3 specificato per scrivere il frame di dati risultante nei nuovi file Parquet.
- requirements.txt – Una dipendenza Python è qualsiasi pacchetto o distribuzione non inclusa nell'installazione di base di Apache Airflow per la versione di Apache Airflow nell'ambiente Amazon MWAA. Per questo post utilizziamo Boto3
- Sul tuo computer locale, aggiorna il file
blog_dag_mwaa_emrs_ny_taxi.pyscript con le seguenti informazioni:- Aggiorna il nome del tuo bucket S3 nelle due righe seguenti:
- Aggiorna l'ARN del nome del tuo ruolo:
- Aggiorna l'ID dell'applicazione serverless EMR. Utilizza l'ID applicazione creato in precedenza.
- Carica il
requirements.txtfile nel bucket S3 creato in precedenza
- Nel bucket S3, crea una cartella denominata
dagse caricare l'aggiornamentoblog_dag_mwaa_emrs_ny_taxi.pyfile dal tuo computer locale.
- Nella console Amazon S3, crea una nuova cartella denominata
scriptsall'interno del bucket S3 e carica gli script in questa cartella dal tuo computer locale.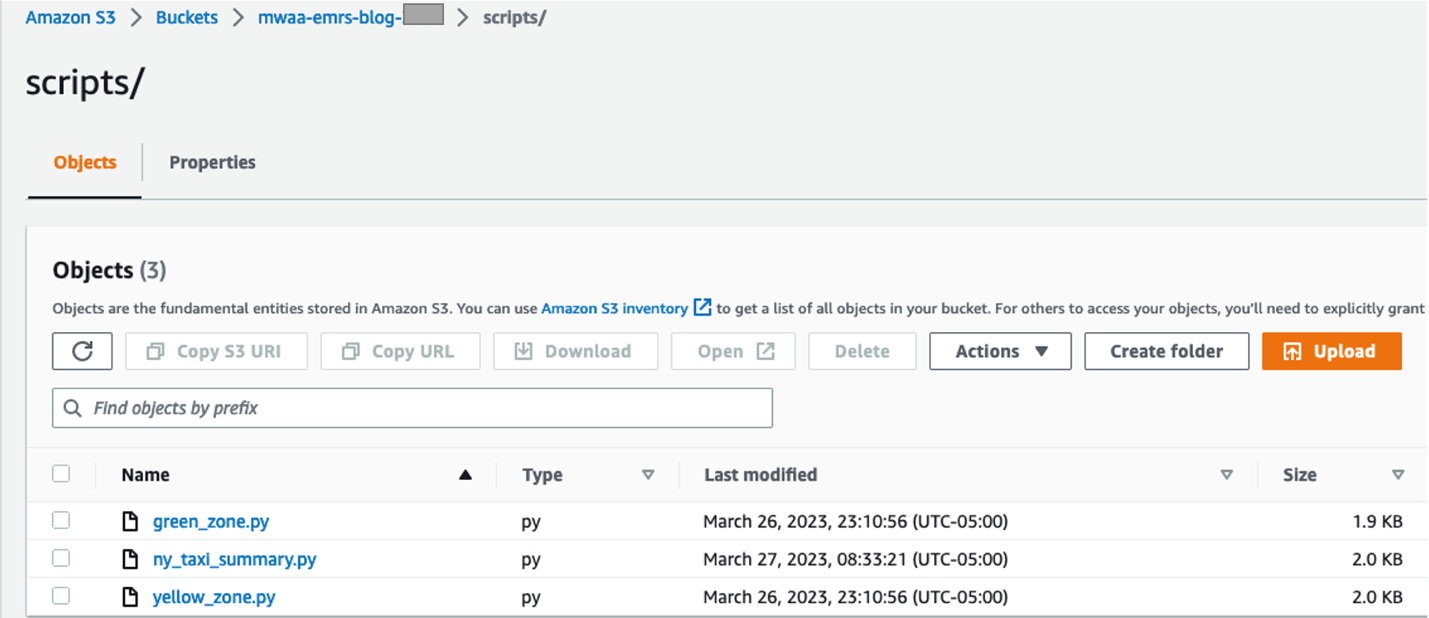
Crea un ambiente Amazon MWAA
Per creare un ambiente Airflow, completare i seguenti passaggi:
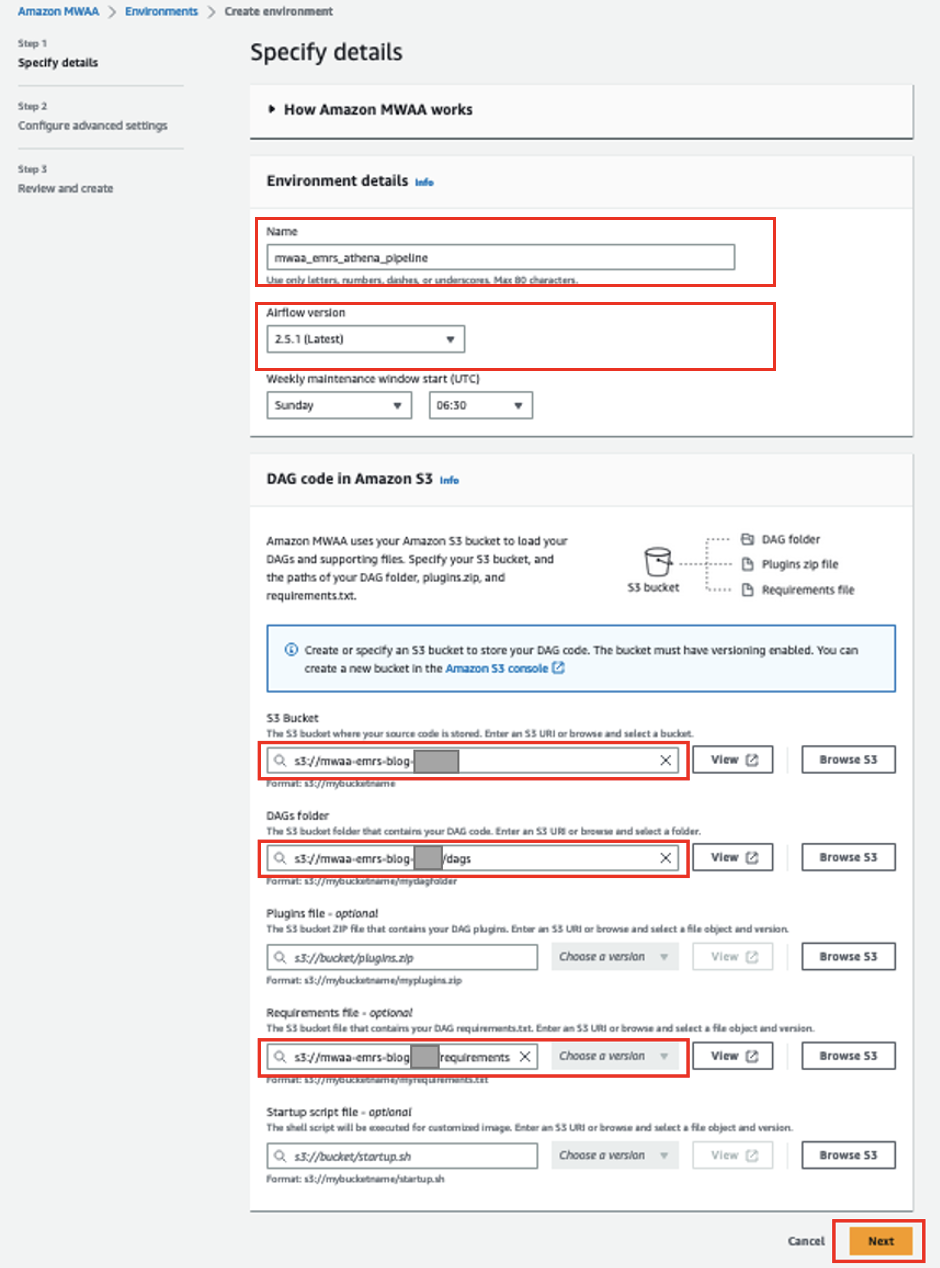
- Sulla console Amazon MWAA, scegli Crea ambiente.

- Nel Nome, accedere
mwaa_emrs_athena_pipeline. - Nel Versione con flusso d'aria, scegli la versione più recente (per questo post, 2.5.1).
- Nel Secchio S3, inserisci il percorso del tuo bucket S3.
- Nel Cartella DAG, inserisci il percorso del tuo
dagscartella. - Nel File dei requisiti, inserisci il percorso per il
requirements.txtfile. - Scegli Avanti.
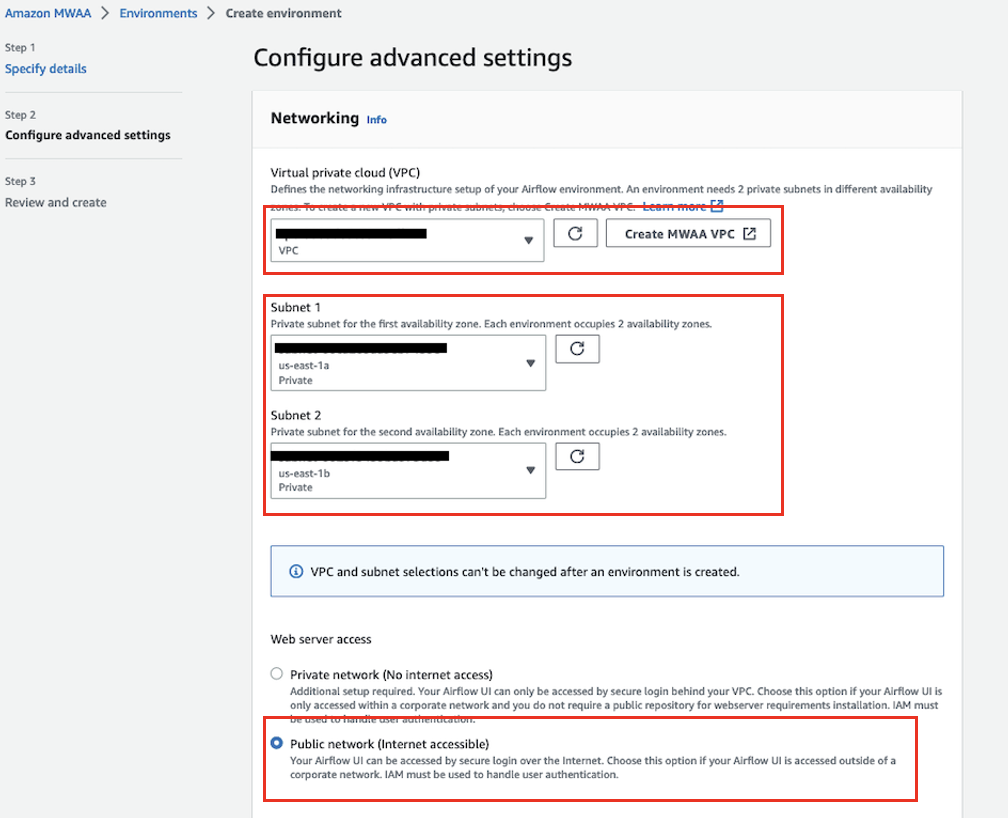
- Nel Cloud privato virtuale (VPC), scegli un VPC che abbia un minimo di due sottoreti private.
Ciò popolerà due delle sottoreti private nel tuo VPC.
- Sotto Accesso al server web, selezionare Rete pubblica.
Ciò consente agli utenti autorizzati ad accedere all'interfaccia utente di Apache Airflow tramite Internet Policy IAM per il tuo ambiente.
- Nel Gruppi di sicurezza, selezionare Crea un nuovo gruppo di sicurezza.
- Nel Classe ambientale, selezionare mw1.piccolo.
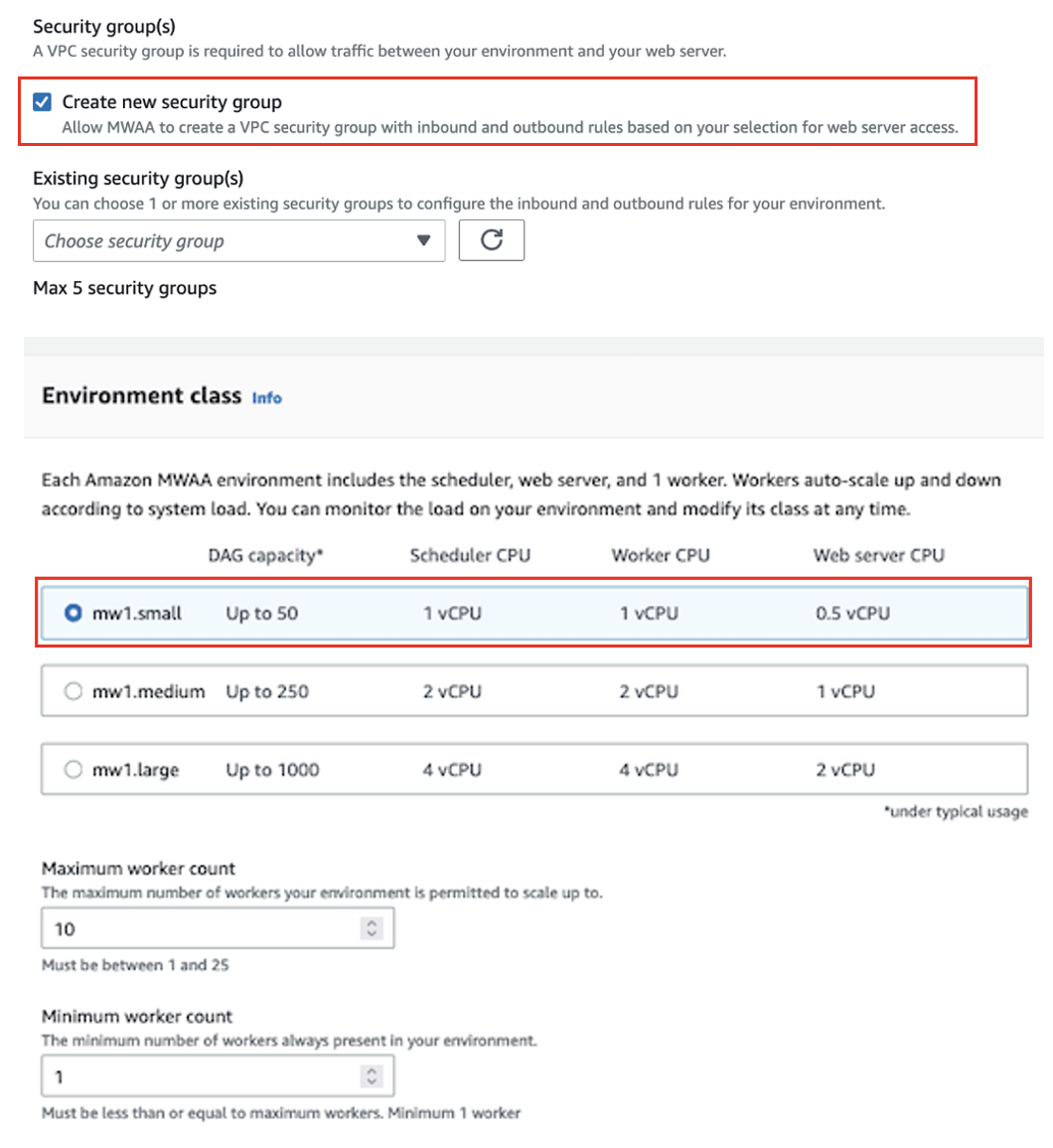
- Nel Ruolo di esecuzionescegli Crea un nuovo ruolo.
- Nel Nome del ruolo, inserisci un nome.
- Lascia le altre configurazioni come predefinite e scegli Avanti.

- Nella pagina successiva, scegli Creare ambiente.
Potrebbero essere necessari circa 20-30 minuti per creare il tuo ambiente Amazon MWAA.
- Quando lo stato dell'ambiente Amazon MWAA cambia in A disposizione, accedere alla console IAM e aggiornare il ruolo di esecuzione del cluster da aggiungere trasferire i privilegi del ruolo a
emr_serverless_execution_role.
Attiva il DAG Amazon MWAA
Per attivare il DAG, completare i seguenti passaggi:
- Sulla console Amazon MWAA, scegli Ambienti nel pannello di navigazione.
- Apri il tuo ambiente e scegli Apri l'interfaccia utente del flusso d'aria.
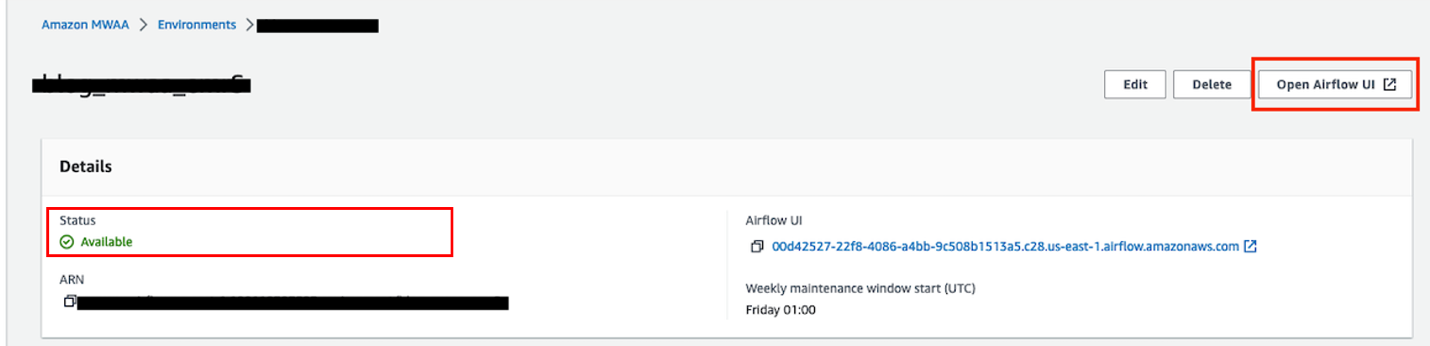
- Seleziona
blog_dag_mwaa_emr_ny_taxi, scegli l'icona di riproduzione e scegli Attiva DAG.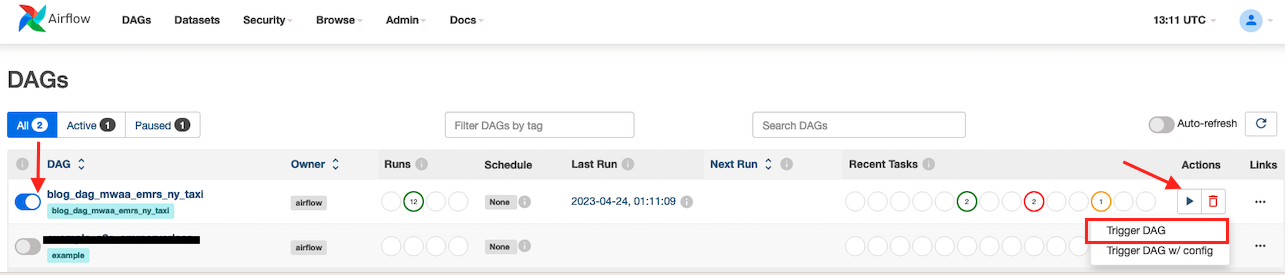
- Quando il DAG è in esecuzione, scegli il DAG
blog_dag_mwaa_emrs_ny_taxie scegli Grafico per individuare il flusso di lavoro di esecuzione del DAG.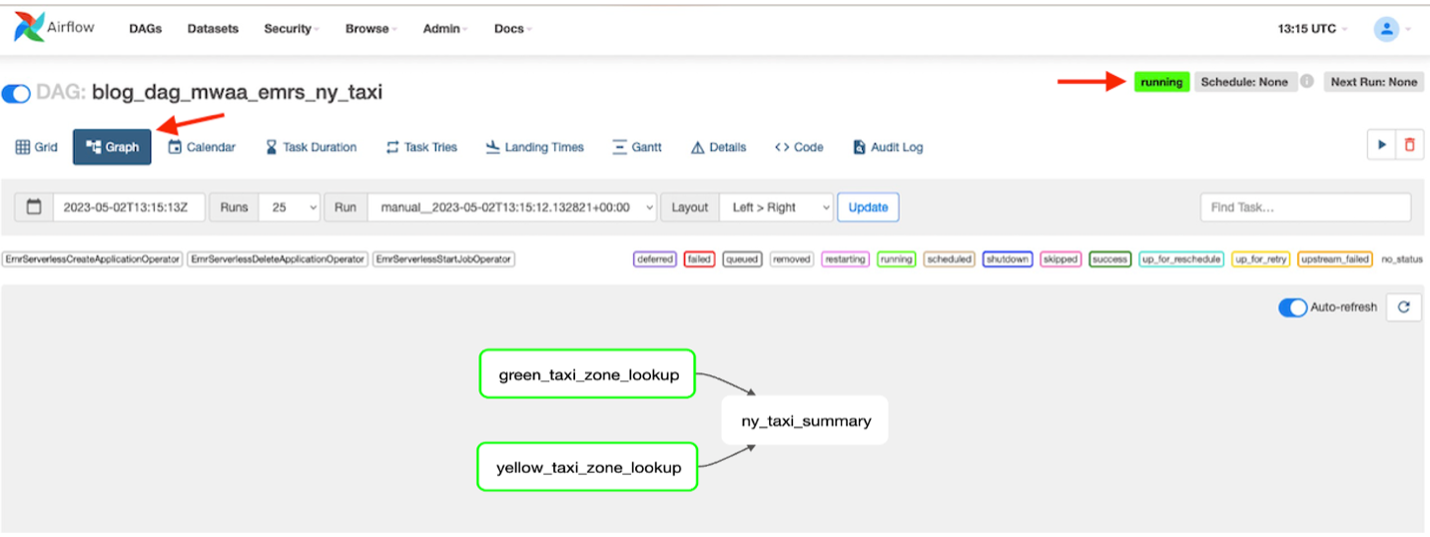
Il DAG impiegherà circa 4-6 minuti per eseguire tutti gli script. Vedrai tutte le attività complete e lo stato generale del DAG verrà visualizzato come il successo.

Per eseguire nuovamente il DAG, rimuovere s3://<<your_s3_bucket here >>/output_data/.
Facoltativamente, per comprendere come Amazon MWAA esegue queste attività, scegli l'attività che desideri controllare.

Scegli Correre per visualizzare i dettagli dell'esecuzione dell'attività.
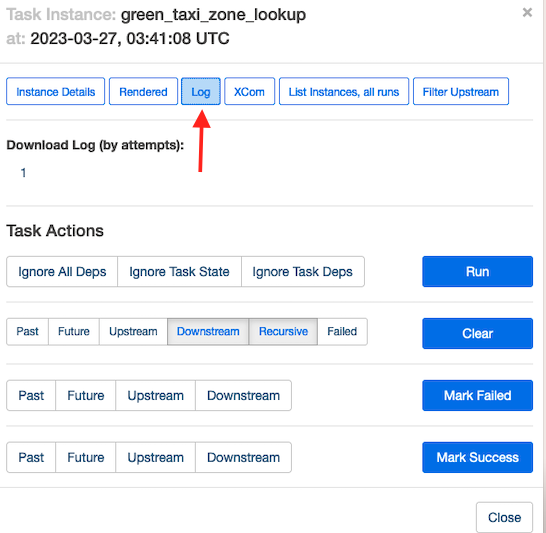
La schermata seguente mostra un esempio dei registri delle attività.
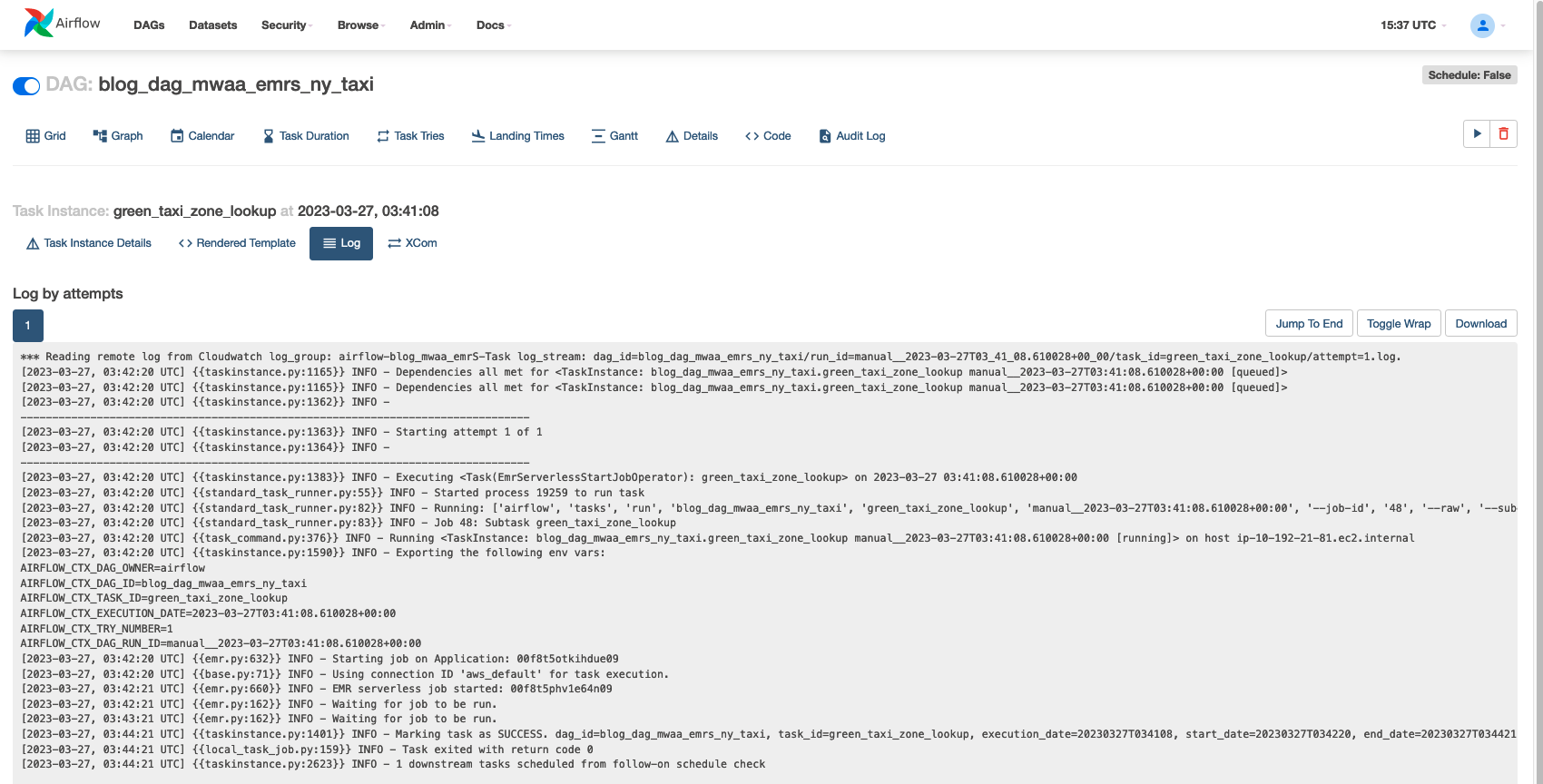
Se desideri approfondire i log di esecuzione, sulla console EMR Serverless, vai su "Applicazioni". I registri del driver Apache Spark indicheranno l'avvio del lavoro insieme ai dettagli per esecutori, fasi e attività create da EMR Serverless. Questi registri possono essere utili per monitorare l'avanzamento del lavoro e risolvere gli errori.
Per impostazione predefinita, EMR Serverless archivierà i log delle applicazioni in modo sicuro nello storage gestito di Amazon EMR per un periodo di 30 giorni. Tuttavia è anche possibile specificare Amazon S3 o Amazon CloudWatch come opzioni di consegna del registro durante l'invio del lavoro.

Convalida il risultato finale impostato con Atena
Convalidiamo i dati caricati dal processo utilizzando le query Athena SQL.
- Sulla console Athena, scegli Editor di query nel pannello di navigazione.
- Se stai usando Athena per la prima volta, sotto Impostazioni profiloscegli gestire e inserisci la posizione del bucket S3 che hai creato in precedenza (
<S3_BUCKET_NAME>/athena), quindi scegliere Risparmi.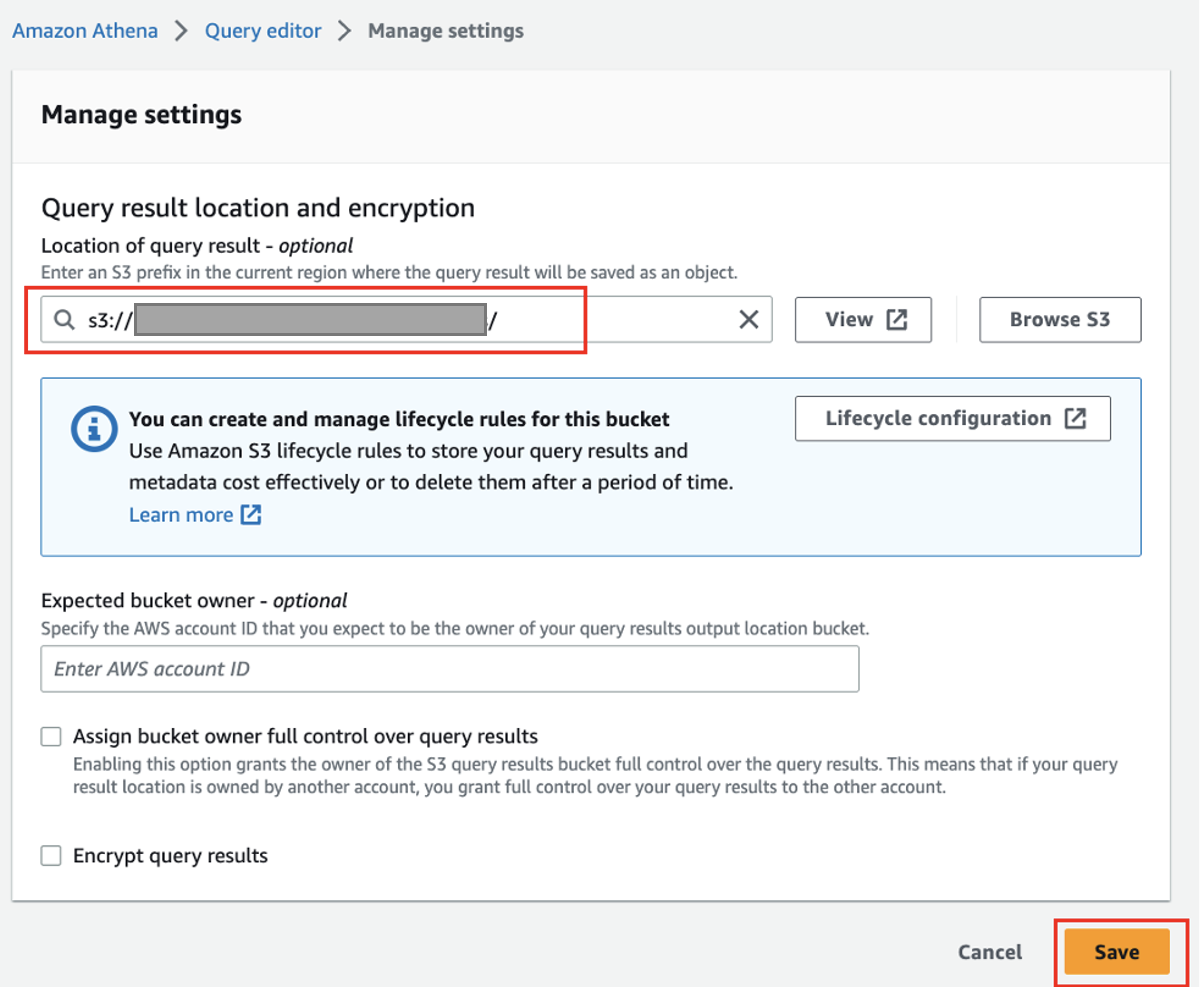
- Nell'editor di query, inserisci la seguente query per creare una tabella esterna:

Esegui la seguente query sul file creato di recente ny_taxi_summary tabella per recuperare le prime 10 righe per convalidare i dati:

ripulire
Per evitare addebiti futuri, completare i seguenti passaggi:
- Nella console Amazon S3, elimina il bucket S3 creato per archiviare il DAG, gli script e i log Amazon MWAA.
- Sulla console Athena, rilascia la tabella che hai creato:
- Nella console Amazon MWAA, accedi all'ambiente che hai creato e scegli Elimina.

- Sulla console EMR Studio, eliminare l'applicazione.
Per eliminare l'applicazione, accedere a Elenca le applicazioni pagina. Seleziona l'applicazione che hai creato e scegli Azioni → Interrompi per interrompere l'applicazione. Dopo che l'applicazione è nello stato STOPPED, seleziona la stessa applicazione e scegli Azioni → Elimina.

Conclusione
L'ingegneria dei dati è una componente fondamentale di molte organizzazioni e, poiché i volumi di dati continuano a crescere, è essenziale trovare modi per semplificare i flussi di lavoro di elaborazione dei dati. La combinazione di Amazon MWAA, EMR Serverless e Athena fornisce una potente soluzione per creare, eseguire e gestire pipeline di dati in modo efficiente. Con questa pipeline di elaborazione dati end-to-end, i data engineer possono elaborare e analizzare facilmente grandi quantità di dati in modo rapido ed economico senza la necessità di gestire infrastrutture complesse. L'integrazione di questi servizi AWS fornisce una soluzione solida e scalabile per l'elaborazione dei dati, aiutando le organizzazioni a prendere decisioni informate in base alle informazioni sui dati.
Ora che hai visto come inviare lavori Spark su EMR Serverless tramite Amazon MWAA, ti invitiamo a utilizzare Amazon MWAA per creare un flusso di lavoro che eseguirà lavori PySpark tramite EMR Serverless.
Accogliamo con favore i vostri feedback e richieste. Non esitate a contattarci se avete domande o commenti.
Circa gli autori
 Raul Sonawane è Principal Analytics Solutions Architect presso AWS con AI/ML e Analytics come sua area di specializzazione.
Raul Sonawane è Principal Analytics Solutions Architect presso AWS con AI/ML e Analytics come sua area di specializzazione.
 Gaurav Parech è un Solutions Architect che aiuta i clienti AWS a creare un'architettura moderna su larga scala. È specializzato in analisi dei dati e networking. Al di fuori del lavoro, Gaurav ama giocare a cricket, calcio e pallavolo.
Gaurav Parech è un Solutions Architect che aiuta i clienti AWS a creare un'architettura moderna su larga scala. È specializzato in analisi dei dati e networking. Al di fuori del lavoro, Gaurav ama giocare a cricket, calcio e pallavolo.
Cronologia dell'audit
Dicembre 2023: questo post è stato esaminato per verificarne l'accuratezza tecnica da Santosh Gantaram, Sr. Technical Account Manager.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/orchestrate-amazon-emr-serverless-spark-jobs-with-amazon-mwaa-and-data-validation-using-amazon-athena/
- :ha
- :È
- :non
- $ SU
- 1
- 10
- 100
- 118
- 15%
- 16
- 2022
- 2023
- 23
- 25
- 30
- 300
- 7
- 700
- 8
- 9
- 990
- a
- WRI
- accetta
- accesso
- accessibile
- Il mio account
- precisione
- aggiungere
- Dopo shavasana, sedersi in silenzio; saluti;
- aggregato
- AI / ML
- Tutti
- consente
- lungo
- già
- anche
- Amazon
- Amazzone Atena
- Amazon EMR
- Amazon Web Services
- quantità
- importi
- an
- analitica
- analizzare
- ed
- in qualsiasi
- Apache
- Apache Spark
- Applicazioni
- applicazioni
- circa
- architettura
- SONO
- RISERVATA
- argomento
- AS
- At
- automaticamente
- disponibile
- AWS
- precedente
- base
- basato
- BE
- diventare
- diventa
- fra
- Big
- Big Data
- costruire
- Costruzione
- costruito
- aziende
- by
- calcola
- Materiale
- catalogo
- il cambiamento
- Modifiche
- oneri
- Scegli
- classificazione
- Cloud
- Cluster
- codice
- combinazione
- combinare
- viene
- Commenti
- completamento di una
- complesso
- componente
- consiste
- consolle
- continua
- Corrispondente
- Costo
- costo effettivo
- Costi
- creare
- creato
- crea
- cricket
- critico
- Clienti
- GIORNO
- dati
- Dati Analytics
- elaborazione dati
- dataset
- Date
- Giorni
- decisioni
- deep
- Predefinito
- definizione
- consegna
- dipendenze
- Dipendenza
- dettagli
- distanza
- distribuzione
- immersione
- do
- Dont
- doppio
- giù
- scaricare
- autista
- Cadere
- durante
- e
- ogni
- In precedenza
- facilmente
- facile
- editore
- efficienza
- efficiente
- in modo efficiente
- incoraggiare
- da un capo all'altro
- Ingegneria
- Ingegneri
- garantire
- entrare
- Ambiente
- essential
- Etere (ETH)
- esempio
- esecuzione
- esterno
- extra
- fallimenti
- caratteristica
- feedback
- sentire
- Compila il
- File
- finale
- Trovate
- Nome
- prima volta
- Focus
- seguire
- i seguenti
- Nel
- formato
- TELAIO
- quadri
- Gratis
- da
- completamente
- futuro
- generare
- genera
- la generazione di
- concesso
- Green
- Crescere
- cresce
- Hadoop
- maniglia
- Avere
- he
- Aiuto
- utile
- aiutare
- qui
- il suo
- Alveare
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- IAM
- ICON
- ID
- Idle
- ids
- if
- illustrare
- illustra
- in
- includere
- incluso
- inclusi
- sempre più
- indicare
- informazioni
- informati
- Infrastruttura
- iniziati
- iniziazione
- ingresso
- Richieste
- interno
- intuizioni
- install
- invece
- istruzioni
- integrazione
- interagire
- interattivo
- Internet
- coinvolgere
- IT
- Lavoro
- Offerte di lavoro
- join
- accoppiamento
- Entra a far parte
- jpg
- ad appena
- grandi
- infine
- dopo
- con i più recenti
- piace
- LIMITE
- linea
- Linee
- locale
- località
- posizioni
- ceppo
- Lunghi
- cerca
- ricerca
- macchina
- make
- FA
- Fare
- gestire
- gestito
- direttore
- gestione
- molti
- Maggio..
- Metadati
- ordine
- verbale
- moderno
- modificare
- Monitorare
- Scopri di più
- Nome
- Detto
- Navigare
- Navigazione
- Bisogno
- di applicazione
- internazionale
- New
- GENERAZIONE
- Nessuna
- adesso
- NYC
- of
- MENO
- on
- una volta
- ONE
- esclusivamente
- aprire
- open source
- operazione
- Operatori
- Opzioni
- or
- organizzazioni
- Altro
- nostro
- su
- lineamenti
- produzione
- al di fuori
- ancora
- complessivo
- pacchetto
- pagina
- vetro
- parte
- sentiero
- Pagamento
- esegue
- periodo
- conduttura
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Giocare
- gioco
- per favore
- politica
- possibile
- Post
- potente
- prerequisiti
- prevenire
- Direttore
- un bagno
- processi
- i processi
- lavorazione
- Progressi
- fornitore
- fornisce
- fornitura
- pubblicamente
- Python
- query
- Domande
- rapidamente
- raggiungere
- recentemente
- record
- ridurre
- affidabile
- rimuovere
- richiedere
- richiede
- Risorse
- colpevole
- risultante
- rivisto
- VIAGGIO
- corse
- robusto
- Ruolo
- RIGA
- Correre
- running
- corre
- s
- stesso
- scalabile
- Scala
- bilancia
- scala
- programma
- copione
- script
- Sezione
- in modo sicuro
- problemi di
- vedere
- visto
- select
- separato
- server
- serverless
- servizio
- Servizi
- Sessione
- set
- regolazione
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- Un'espansione
- semplificare
- So
- Calcio
- soluzione
- Soluzioni
- Fonte
- Scintilla
- specializzata
- Specialità
- specificato
- SQL
- tappe
- Standard
- Regione / Stato
- statistica
- Stato dei servizi
- Passi
- Fermare
- fermato
- conservazione
- Tornare al suo account
- memorizzati
- snellire
- Corda
- studio
- sottomissione
- inviare
- sottoreti
- tale
- SOMMARIO
- Supporto
- tavolo
- Fai
- Task
- task
- Consulenza
- temporaneo
- Testing
- che
- Il
- loro
- Li
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- tre
- tempo
- volte
- a
- oggi
- Trasformare
- Trasformazione
- trasformato
- innescare
- viaggio
- TURNO
- seconda
- Tipi di
- ui
- per
- capire
- a differenza di
- Aggiornanento
- aggiornato
- us
- uso
- utenti
- usa
- utilizzando
- utilizza
- CONVALIDARE
- convalida
- versione
- via
- Visualizza
- visualizzazioni
- volume
- volumi
- volere
- Prima
- modi
- we
- sito web
- servizi web
- il benvenuto
- sono stati
- quando
- quale
- volere
- con
- senza
- Lavora
- flusso di lavoro
- flussi di lavoro
- preoccuparsi
- preoccupante
- scrivere
- giallo
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- zone