Generato con Midjourney
La conferenza NeurIPS 2023, tenutasi nella vivace città di New Orleans dal 10 al 16 dicembre, ha posto un'enfasi particolare sull'intelligenza artificiale generativa e sui modelli linguistici di grandi dimensioni (LLM). Alla luce dei recenti progressi rivoluzionari in questo campo, non è stata una sorpresa che questi argomenti abbiano dominato le discussioni.
Uno dei temi centrali della conferenza di quest’anno è stata la ricerca di sistemi di intelligenza artificiale più efficienti. Ricercatori e sviluppatori stanno cercando attivamente modi per costruire un’intelligenza artificiale che non solo apprenda più velocemente degli attuali LLM, ma possieda anche capacità di ragionamento migliorate consumando meno risorse di elaborazione. Questa ricerca è cruciale nella corsa verso il raggiungimento dell’Intelligenza Generale Artificiale (AGI), un obiettivo che sembra sempre più raggiungibile nel prossimo futuro.
Le conferenze invitate a NeurIPS 2023 riflettevano questi interessi dinamici e in rapida evoluzione. Relatori provenienti da vari ambiti della ricerca sull'intelligenza artificiale hanno condiviso i loro ultimi risultati, offrendo una finestra sugli sviluppi all'avanguardia dell'intelligenza artificiale. In questo articolo, approfondiamo questi discorsi, estraendo e discutendo i principali insegnamenti e insegnamenti, essenziali per comprendere gli scenari attuali e futuri dell'innovazione dell'intelligenza artificiale.
NextGenAI: l'illusione della scalabilità e il futuro dell'intelligenza artificiale generativa
In il suo discorso, Björn Ommer, responsabile del Computer Vision & Learning Group presso l'Università Ludwig Maximilian di Monaco, ha raccontato come il suo laboratorio è arrivato a sviluppare la diffusione stabile, alcune lezioni apprese da questo processo e i recenti sviluppi, compreso il modo in cui possiamo fondere modelli di diffusione con corrispondenza del flusso, aumento del recupero e approssimazioni LoRA, tra gli altri.
Le prelibatezze chiave:
- Nell’era dell’intelligenza artificiale generativa, siamo passati dall’attenzione alla percezione nei modelli di visione (ad esempio, il riconoscimento degli oggetti) alla previsione delle parti mancanti (ad esempio, generazione di immagini e video con modelli di diffusione).
- Per 20 anni, la visione artificiale si è concentrata sulla ricerca di benchmark, che ha contribuito a focalizzare l’attenzione sui problemi più importanti. Nell’intelligenza artificiale generativa, non abbiamo parametri di riferimento per cui ottimizzare, il che ha aperto il campo affinché ognuno possa andare nella propria direzione.
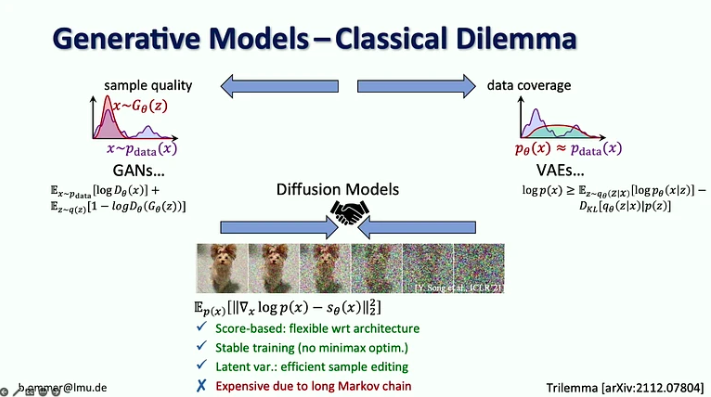
- I modelli di diffusione combinano i vantaggi dei precedenti modelli generativi essendo basati su punteggi con una procedura di addestramento stabile e un'efficiente modifica dei campioni, ma sono costosi a causa della loro lunga catena di Markov.
- La sfida con i modelli a forte verosimiglianza è che la maggior parte dei bit entra in dettagli difficilmente percepibili dall’occhio umano, mentre la codifica della semantica, che conta di più, richiede solo pochi bit. Il solo ridimensionamento non risolverebbe questo problema perché la domanda di risorse di elaborazione sta crescendo 9 volte più velocemente dell’offerta di GPU.
- La soluzione suggerita è quella di combinare i punti di forza dei modelli di diffusione e di ConvNet, in particolare l'efficienza delle convoluzioni per rappresentare i dettagli locali e l'espressività dei modelli di diffusione per il contesto a lungo raggio.
- Björn Ommer suggerisce inoltre di utilizzare un approccio di corrispondenza del flusso per consentire la sintesi di immagini ad alta risoluzione da piccoli modelli di diffusione latente.
- Un altro approccio per aumentare l'efficienza della sintesi delle immagini consiste nel concentrarsi sulla composizione della scena utilizzando l'aumento del recupero per riempire i dettagli.
- Infine, ha introdotto l'approccio iPoke per la sintesi video stocastica controllata.
Se questo contenuto di approfondimento ti è utile, iscriviti alla nostra mailing list AI per essere avvisato quando rilasciamo nuovo materiale.
I tanti volti dell’intelligenza artificiale responsabile
In la sua presentazione, Lora Aroyo, ricercatrice presso Google Research, ha evidenziato un limite fondamentale negli approcci tradizionali al machine learning: la loro dipendenza dalle categorizzazioni binarie dei dati come esempi positivi o negativi. Questa semplificazione eccessiva, ha sostenuto, trascura la complessa soggettività inerente agli scenari e ai contenuti del mondo reale. Attraverso vari casi d’uso, Aroyo ha dimostrato come l’ambiguità dei contenuti e la naturale variazione dei punti di vista umani spesso portino a inevitabili disaccordi. Ha sottolineato l’importanza di trattare questi disaccordi come segnali significativi piuttosto che come semplici rumori.

Ecco i punti chiave del discorso:
- Il disaccordo tra laboratori umani può essere produttivo. Invece di trattare tutte le risposte come corrette o sbagliate, Lora Aroyo ha introdotto la “verità per disaccordo”, un approccio di verità distributiva per valutare l’affidabilità dei dati sfruttando il disaccordo dei valutatori.
- La qualità dei dati è difficile anche con gli esperti perché gli esperti non sono d'accordo tanto quanto i crowd laber. Questi disaccordi possono essere molto più informativi delle risposte di un singolo esperto.
- Nei compiti di valutazione della sicurezza, gli esperti non sono d’accordo sul 40% degli esempi. Invece di cercare di risolvere questi disaccordi, dobbiamo raccogliere più esempi simili e utilizzarli per migliorare i modelli e i parametri di valutazione.
- Anche Lora Aroyo ha presentato il suo Sicurezza con diversità metodo per esaminare i dati in termini di cosa contengono e chi li ha annotati.
- Questo metodo ha prodotto un set di dati di riferimento con variabilità nei giudizi sulla sicurezza LLM tra vari gruppi demografici di valutatori (2.5 milioni di valutazioni in totale).
- Per il 20% delle conversazioni, è stato difficile decidere se la risposta del chatbot fosse sicura o non sicura, poiché un numero più o meno uguale di intervistati li ha etichettati come sicuri o non sicuri.
- La diversità dei valutatori e dei dati gioca un ruolo cruciale nella valutazione dei modelli. Non riconoscere l’ampia gamma di prospettive umane e l’ambiguità presente nei contenuti può ostacolare l’allineamento delle prestazioni del machine learning con le aspettative del mondo reale.
- L’80% degli sforzi per la sicurezza dell’IA sono già abbastanza buoni, ma il restante 20% richiede il raddoppio degli sforzi per affrontare i casi limite e tutte le varianti nello spazio infinito della diversità.
Statistiche sulla coerenza, esperienza autogenerata e perché i giovani umani sono molto più intelligenti dell’attuale intelligenza artificiale
In il suo discorso, Linda Smith, eminente professoressa presso l'Università dell'Indiana Bloomington, ha esplorato il tema della scarsità di dati nei processi di apprendimento di neonati e bambini piccoli. Si è concentrata in particolare sul riconoscimento degli oggetti e sull'apprendimento dei nomi, approfondendo come le statistiche delle esperienze autogenerate dai bambini offrano potenziali soluzioni alla sfida della scarsità di dati.
Le prelibatezze chiave:
- Dall’età di tre anni, i bambini hanno sviluppato la capacità di imparare in vari ambiti. In meno di 16,000 ore di veglia fino al loro quarto compleanno, riescono ad apprendere oltre 1,000 categorie di oggetti, a padroneggiare la sintassi della loro lingua madre e ad assorbire le sfumature culturali e sociali del loro ambiente.
- La dottoressa Linda Smith e il suo team hanno scoperto tre principi dell'apprendimento umano che consentono ai bambini di catturare così tanto da dati così scarsi:
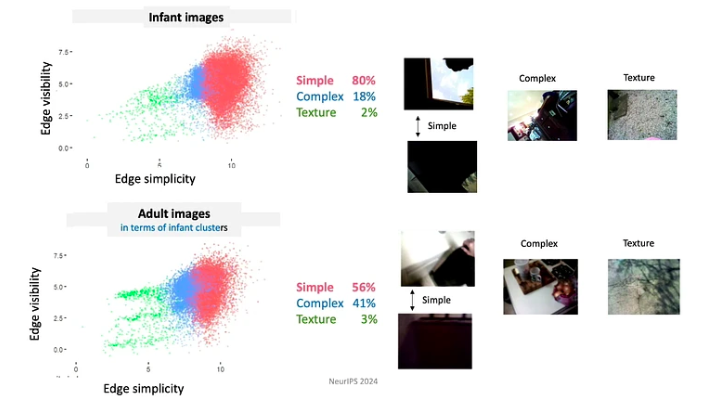
- Gli studenti controllano l'input, momento per momento lo modellano e lo strutturano. Ad esempio, durante i primi mesi di vita, i bambini tendono a guardare maggiormente gli oggetti dai bordi semplici.
- Poiché i bambini evolvono continuamente nelle loro conoscenze e capacità, seguono un curriculum altamente vincolato. I dati a cui sono esposti sono organizzati in modi profondamente significativi. Ad esempio, i bambini sotto i 4 mesi trascorrono la maggior parte del tempo guardando i volti, circa 15 minuti all’ora, mentre quelli di età superiore ai 12 mesi si concentrano principalmente sulle mani, osservandole per circa 20 minuti all’ora.
- Gli episodi di apprendimento consistono in una serie di esperienze interconnesse. Le correlazioni spaziali e temporali creano coerenza, che a sua volta facilita la formazione di ricordi duraturi da eventi avvenuti una volta. Ad esempio, quando viene loro presentato un assortimento casuale di giocattoli, i bambini spesso si concentrano su alcuni giocattoli “preferiti”. Si impegnano con questi giocattoli utilizzando schemi ripetitivi, che aiutano ad apprendere più rapidamente gli oggetti.
- Le memorie transitorie (funzionanti) persistono più a lungo dell'input sensoriale. Le proprietà che migliorano il processo di apprendimento includono la multimodalità, le associazioni, le relazioni predittive e l'attivazione dei ricordi passati.
- Per un apprendimento rapido è necessaria un’alleanza tra i meccanismi che generano i dati e i meccanismi che apprendono.
Schizzi: strumenti fondamentali, miglioramento dell'apprendimento e robustezza adattiva
Jelani Nelson, professore di ingegneria elettrica e informatica alla UC Berkeley, introdotto il concetto di “schizzi” di dati – una rappresentazione compressa in memoria di un set di dati che consente comunque di rispondere a domande utili. Sebbene l'intervento fosse piuttosto tecnico, ha fornito un'eccellente panoramica di alcuni strumenti fondamentali per lo sketch, compresi i recenti progressi.
Punti chiave:
- CountSketch, lo strumento principale di sketching, è stato introdotto per la prima volta nel 2002 per affrontare il problema dei "colpi pesanti", riportando un piccolo elenco degli elementi più frequenti da un determinato flusso di elementi. CountSketch è stato il primo algoritmo sublineare conosciuto utilizzato per questo scopo.
- Due applicazioni non streaming di battitori pesanti includono:
- Metodo basato sui punti interni (IPM) che fornisce un algoritmo asintoticamente più veloce conosciuto per la programmazione lineare.
- Metodo HyperAttention che affronta la sfida computazionale posta dalla crescente complessità dei contesti lunghi utilizzati nei LLM.
- Gran parte del lavoro recente si è concentrato sulla progettazione di schizzi robusti per l’interazione adattiva. L'idea principale è quella di utilizzare le informazioni provenienti dall'analisi adattiva dei dati.
Pannello Oltre il ridimensionamento
La sezione ottimo pannello sui modelli linguistici di grandi dimensioni è stato moderato da Alexander Rush, professore associato alla Cornell Tech e ricercatore presso Hugging Face. Tra gli altri partecipanti figuravano:
- Aakanksha Chowdhery - Ricercatore presso Google DeepMind con interessi di ricerca in sistemi, preformazione LLM e multimodalità. Ha fatto parte del team che ha sviluppato PaLM, Gemini e Pathways.
- Angela Fan – Ricercatrice presso Meta Generative AI con interessi di ricerca in allineamento, data center e multilinguismo. Ha partecipato allo sviluppo di Llama-2 e Meta AI Assistant.
- Percy Liang - Professore a Stanford che ricerca creatori, open source e agenti generativi. È il direttore del Center for Research on Foundation Models (CRFM) di Stanford e il fondatore di Together AI.
La discussione si è concentrata su quattro argomenti chiave: (1) architetture e ingegneria, (2) dati e allineamento, (3) valutazione e trasparenza e (4) creatori e contributori.
Ecco alcuni dei punti salienti di questo panel:
- La formazione degli attuali modelli linguistici non è intrinsecamente difficile. La sfida principale nell'addestramento di un modello come Llama-2-7b risiede nei requisiti dell'infrastruttura e nella necessità di coordinarsi tra più GPU, data center, ecc. Tuttavia, se il numero di parametri è sufficientemente piccolo da consentire l'addestramento su una singola GPU, anche uno studente universitario può gestirlo.
- Sebbene i modelli autoregressivi vengano solitamente utilizzati per la generazione di testo e i modelli di diffusione per la generazione di immagini e video, sono stati condotti esperimenti per invertire questi approcci. Nello specifico, nel progetto Gemini, viene utilizzato un modello autoregressivo per la generazione delle immagini. Sono state effettuate anche esplorazioni sull'utilizzo di modelli di diffusione per la generazione di testo, ma questi non si sono ancora dimostrati sufficientemente efficaci.
- Data la disponibilità limitata di dati in lingua inglese per i modelli di formazione, i ricercatori stanno esplorando approcci alternativi. Una possibilità è quella di addestrare modelli multimodali su una combinazione di testo, video, immagini e audio, con l'aspettativa che le competenze apprese da queste modalità alternative possano essere trasferite al testo. Un’altra opzione è l’uso di dati sintetici. È importante notare che i dati sintetici spesso si fondono con dati reali, ma questa integrazione non è casuale. Il testo pubblicato online in genere è sottoposto a cura e modifica da parte di persone, il che potrebbe aggiungere ulteriore valore per l'addestramento del modello.
- I modelli a base aperta sono spesso considerati vantaggiosi per l’innovazione ma potenzialmente dannosi per la sicurezza dell’intelligenza artificiale, poiché possono essere sfruttati da soggetti malintenzionati. Tuttavia, il dottor Percy Liang sostiene che anche i modelli aperti contribuiscono positivamente alla sicurezza. Sostiene che, essendo accessibili, offrono a più ricercatori l’opportunità di condurre ricerche sulla sicurezza dell’IA e di rivedere i modelli per potenziali vulnerabilità.
- Oggi, l’annotazione dei dati richiede molta più esperienza nel campo dell’annotazione rispetto a cinque anni fa. Tuttavia, se in futuro gli assistenti AI funzioneranno come previsto, riceveremo dati di feedback più preziosi dagli utenti, riducendo la dipendenza da dati estesi da parte degli annotatori.
Sistemi per modelli di fondazione e modelli di fondazione per sistemi
In questo discorso, Christopher Ré, professore associato presso il Dipartimento di Informatica dell'Università di Stanford, mostra come i modelli di fondazione hanno cambiato i sistemi che costruiamo. Esplora anche come costruire in modo efficiente modelli di fondazione, prendendo in prestito informazioni dalla ricerca sui sistemi di database e discute architetture potenzialmente più efficienti per i modelli di fondazione rispetto al Transformer.
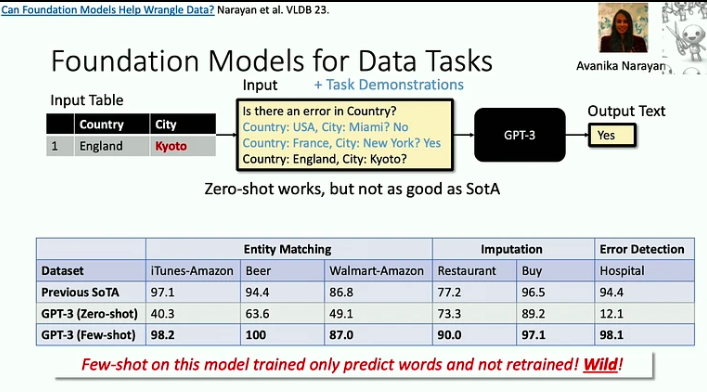
Ecco i punti salienti di questo discorso:
- I modelli di fondazione sono efficaci nell’affrontare i problemi della “morte per 1000 tagli”, in cui ogni singolo compito potrebbe essere relativamente semplice, ma l’ampiezza e la varietà dei compiti rappresentano una sfida significativa. Un buon esempio di ciò è il problema della pulizia dei dati, che i LLM possono ora aiutare a risolvere in modo molto più efficiente.
- Man mano che gli acceleratori diventano più veloci, la memoria spesso emerge come un collo di bottiglia. Questo è un problema che i ricercatori di database affrontano da decenni e noi possiamo adottare alcune delle loro strategie. Ad esempio, l’approccio Flash Attention minimizza i flussi input-output attraverso blocchi e fusioni aggressive: ogni volta che accediamo a un’informazione, eseguiamo su di essa quante più operazioni possibili.
- Esiste una nuova classe di architetture, radicata nell'elaborazione del segnale, che potrebbe essere più efficiente del modello Transformer, soprattutto nella gestione di lunghe sequenze. L'elaborazione del segnale offre stabilità ed efficienza, gettando le basi per modelli innovativi come S4.
Apprendimento rinforzato online negli interventi di sanità digitale
In il suo discorso, Susan Murphy, professoressa di statistica e informatica all'Università di Harvard, ha condiviso le prime soluzioni ad alcune delle sfide che devono affrontare nello sviluppo di algoritmi RL online da utilizzare negli interventi di sanità digitale.
Ecco alcuni spunti della presentazione:
- La dottoressa Susan Murphy ha discusso di due progetti su cui ha lavorato:
- HeartStep, dove le attività sono state suggerite sulla base dei dati provenienti da smartphone e tracker indossabili, e
- Oralytics per il coaching sulla salute orale, in cui gli interventi erano basati sui dati di coinvolgimento ricevuti da uno spazzolino elettronico.
- Nello sviluppare una politica comportamentale per un agente AI, i ricercatori devono garantire che sia autonomo e possa essere implementato in modo fattibile nel più ampio sistema sanitario. Ciò implica garantire che il tempo necessario per l’impegno di un individuo sia ragionevole e che le azioni raccomandate siano sia eticamente valide che scientificamente plausibili.
- Le sfide principali nello sviluppo di un agente RL per interventi di salute digitale includono la gestione di livelli di rumore elevati, poiché le persone conducono la loro vita e potrebbero non essere sempre in grado di rispondere ai messaggi, anche se lo desiderano, nonché la gestione di effetti negativi forti e ritardati. .
Come puoi vedere, NeurIPS 2023 ha fornito uno sguardo illuminante sul futuro dell’intelligenza artificiale. Le conferenze invitate hanno evidenziato una tendenza verso modelli più efficienti e attenti alle risorse e l'esplorazione di nuove architetture oltre i paradigmi tradizionali.
Ti piace questo articolo? Iscriviti per ulteriori aggiornamenti sulla ricerca AI.
Ti faremo sapere quando pubblicheremo altri articoli di riepilogo come questo.
Leggi Anche
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.topbots.com/neurips-2023-invited-talks/
- :ha
- :È
- :non
- :Dove
- $ SU
- 000
- 1
- 10
- 10°
- 11
- 110
- 12
- 12 mesi
- 125
- 13
- 14
- 15%
- 154
- 16
- 16°
- 17
- 20
- 20 anni
- 2023
- 32
- 35%
- 41
- 58
- 65
- 7
- 70
- 710
- 8
- 9
- a
- capacità
- capace
- Chi siamo
- acceleratori
- accesso
- accessibile
- realizzazioni
- il raggiungimento
- riconoscere
- operanti in
- azioni
- Attivazione
- attivamente
- attività
- attori
- adattabile
- aggiungere
- aggiuntivo
- indirizzo
- indirizzi
- indirizzamento
- adottare
- avanzamenti
- vantaggi
- Agente
- agenti
- aggressivo
- AGI
- fa
- AI
- Assistente AI
- ricerca ai
- Sistemi di intelligenza artificiale
- AIDS
- Alexander
- algoritmo
- Algoritmi
- allineamento
- Tutti
- alleanza
- consentire
- da solo
- già
- anche
- alternativa
- Sebbene il
- sempre
- Ambiguità
- tra
- an
- .
- ed
- Un altro
- in qualsiasi
- applicazioni
- approccio
- approcci
- circa
- SONO
- sostenuto
- sostiene
- articolo
- news
- artificiale
- intelligenza generale artificiale
- AS
- valutare
- Assistant
- assistenti
- Associate
- associazioni
- assortimento
- At
- Raggiungibile
- attenzione
- Audio
- autonomo
- disponibilità
- basato
- BE
- perché
- diventare
- stato
- comportamento
- essendo
- Segno di riferimento
- parametri di riferimento
- benefico
- Berkeley
- fra
- Al di là di
- Uvaggio:
- miscele
- blocco
- Prestiti
- entrambi
- ampiezza
- più ampia
- costruire
- ma
- by
- è venuto
- Materiale
- funzionalità
- catturare
- casi
- categoria
- centro
- centri
- catena
- Challenge
- sfide
- cambiato
- chatbot
- Bambini
- Christopher
- Città
- classe
- Pulizia
- istruire
- raccogliere
- combinazione
- combinare
- rispetto
- complesso
- complessità
- composizione
- computazionale
- computer
- Informatica
- Visione computerizzata
- informatica
- concetto
- Segui il codice di Condotta
- Convegno
- costruire
- contenuto
- contesto
- contesti
- continuamente
- contribuire
- contributori
- di controllo
- controllata
- Conversazioni
- coordinare
- Nucleo
- cornell
- correggere
- correlazioni
- potuto
- creare
- creatori
- folla
- cruciale
- la cultura della
- curation
- Corrente
- Programma scolastico
- bordo tagliente
- dati
- analisi dei dati
- data center
- Banca Dati
- trattare
- decenni
- Dicembre
- decide
- DeepMind
- Ritardato
- scavare
- Richiesta
- richieste
- demografico
- dimostrato
- Shirts Department
- progettazione
- dettaglio
- dettagli
- sviluppare
- sviluppato
- sviluppatori
- in via di sviluppo
- Mercato
- sviluppi
- difficile
- Emittente
- digitale
- Salute digitale
- direzione
- Direttore
- scoperto
- discusso
- discutere
- discussione
- discussioni
- Distinto
- Diversità
- dominio
- domini
- dominato
- Dont
- raddoppio
- dr
- dovuto
- durante
- dinamico
- e
- ogni
- bordo
- montaggio
- Efficace
- effetti
- efficienza
- efficiente
- in modo efficiente
- sforzo
- sforzi
- o
- Ingegneria Elettrica
- Elettronico
- emerge
- enfasi
- sottolineato
- enable
- Abilita
- codifica
- impegnarsi
- Fidanzamento
- Ingegneria
- accrescere
- migliorata
- abbastanza
- garantire
- assicurando
- Ambiente
- Episodi
- pari
- particolarmente
- essential
- eccetera
- Etere (ETH)
- la valutazione
- valutazione
- Anche
- eventi
- tutti
- evolvere
- evoluzione
- esempio
- Esempi
- eccellente
- aspettativa
- le aspettative
- previsto
- costoso
- esperienza
- Esperienze
- esperimenti
- esperto
- competenza
- esperti
- Exploited
- esplorazione
- Esplorazione
- esplora
- Esplorare
- esposto
- estensivo
- occhio
- Faccia
- facce
- facilita
- in mancanza di
- fan
- più veloce
- più veloce
- feedback
- pochi
- meno
- campo
- riempire
- Nome
- cinque
- Cromatografia
- flusso
- flussi
- Focus
- concentrato
- seguire
- Nel
- prevedibile
- formazione
- Fondazione
- fondatore
- quattro
- Quarto
- frequente
- frequentemente
- da
- fondamentale
- fusione
- futuro
- Il futuro dell'IA
- Gemini
- Generale
- intelligenza generale
- generare
- la generazione di
- ELETTRICA
- generativo
- AI generativa
- dato
- dà
- Intravedere
- Go
- scopo
- buono
- GPU
- GPU
- innovativo
- Gruppo
- Gruppo
- Crescita
- ha avuto
- Manovrabilità
- Mani
- dannoso
- Sfruttamento
- harvard
- Università di Harvard
- Avere
- he
- capo
- Salute e benessere
- assistenza sanitaria
- pesante
- Eroe
- Aiuto
- aiutato
- suo
- Alta
- ad alta risoluzione
- Evidenziato
- vivamente
- ostacolare
- il suo
- ora
- ORE
- Come
- Tutorial
- Tuttavia
- http
- HTTPS
- umano
- Gli esseri umani
- i
- idea
- if
- illuminante
- Immagine
- generazione di immagini
- immagini
- implementato
- importanza
- importante
- competenze
- in
- Uno sguardo approfondito sui miglioramenti dei pneumatici da corsa di Bridgestone.
- includere
- incluso
- Compreso
- crescente
- sempre più
- Indiana
- individuale
- inevitabile
- informazioni
- informativo
- Infrastruttura
- inerente
- intrinsecamente
- Innovazione
- creativi e originali
- ingresso
- intuizioni
- esempio
- invece
- integrazione
- Intelligence
- interazione
- interconnesso
- interessi
- interventi
- ai miglioramenti
- introdotto
- ha invitato
- IT
- elementi
- jpg
- sentenze
- Le
- Sapere
- conoscenze
- conosciuto
- laboratorio
- etichettatura
- Lingua
- grandi
- duraturo
- con i più recenti
- posa
- portare
- principale
- IMPARARE
- imparato
- discenti
- apprendimento
- Eredità
- meno
- Lezioni
- lasciare
- livelli
- si trova
- leggera
- piace
- probabilità
- limitazione
- Limitato
- linda
- Lista
- Lives
- locale
- Lunghi
- più a lungo
- Guarda
- cerca
- macchina
- machine learning
- mailing
- Principale
- gestire
- gestione
- molti
- Mastercard
- corrispondenza
- materiale
- Matters
- max-width
- Maggio..
- significativo
- meccanismi di
- memorie
- Memorie
- semplice
- messaggi
- Meta
- metodo
- Metrica
- forza
- milione
- minimizza
- verbale
- mancante
- modalità
- modello
- modelli
- momento
- mese
- Scopri di più
- più efficiente
- maggior parte
- mosso
- molti
- multiplo
- Monaco
- devono obbligatoriamente:
- Nome
- nativo
- Naturale
- Bisogno
- negativo.
- NeuIPS
- New
- New Orleans
- no
- Rumore
- Nessuna
- Nota
- romanzo
- adesso
- ombreggiatura
- numero
- oggetto
- oggetti
- of
- offrire
- offerta
- Offerte
- di frequente
- maggiore
- on
- ONE
- online
- esclusivamente
- aprire
- open source
- ha aperto
- Operazioni
- Opportunità
- OTTIMIZZA
- Opzione
- or
- orale
- Igiene orale
- Organizzato
- Orleans
- Altro
- Altri partecipanti
- Altri
- nostro
- ancora
- panoramica
- proprio
- palma
- pannello di eventi
- paradigmi
- parametri
- parte
- partecipanti
- partecipato
- particolare
- particolarmente
- Ricambi
- passato
- percorsi
- modelli
- Persone
- per
- pubblica
- eseguire
- performance
- prospettive
- pezzo
- Platone
- Platone Data Intelligence
- PlatoneDati
- plausibile
- gioca
- politica
- posto
- positivo
- positivamente
- possiede
- possibilità
- possibile
- potenziale
- potenzialmente
- previsione
- predittiva
- presenti
- presentazione
- presentata
- precedente
- principalmente
- primario
- principi
- Problema
- problemi
- procedura
- processi
- i processi
- lavorazione
- Prodotto
- produttivo
- Insegnante
- profondamente
- Programmazione
- progetto
- progetti
- prominente
- proprietà
- comprovata
- fornire
- purché
- pubblicato
- scopo
- ricerca
- qualità
- query
- ricerca
- abbastanza
- Gara
- casuale
- gamma
- veloce
- rapidamente
- piuttosto
- valutazioni
- di rose
- mondo reale
- ragionevole
- ricevere
- ricevuto
- recente
- riconoscimento
- raccomandato
- riducendo
- riflessione
- insegnamento rafforzativo
- relazioni
- relativamente
- rilasciare
- problemi di
- fiducia
- rimanente
- ripetitivo
- Reportistica
- rappresentazione
- che rappresenta
- richiedere
- necessario
- Requisiti
- riparazioni
- ricercatore
- ricercatori
- risolvere
- Risorse
- Rispondere
- intervistati
- risposta
- risposte
- responsabile
- recensioni
- robusto
- Ruolo
- radicato
- approssimativamente
- corsa
- sicura
- Sicurezza
- scala
- Scenari
- scena
- Scienze
- SCIENZE
- Scienziato
- vedere
- cerca
- sembra
- visto
- semantica
- Serie
- sagomatura
- condiviso
- lei
- Spettacoli
- segno
- Signal
- Segnali
- significativa
- significativamente
- Un'espansione
- singolo
- abilità
- piccole
- più intelligente
- smartphone
- fabbro
- So
- Social
- soluzione
- Soluzioni
- RISOLVERE
- alcuni
- Suono
- Fonte
- lo spazio
- Spaziale
- in particolare
- spendere
- Stabilità
- stabile
- stanford
- Università di Stanford
- statistica
- Ancora
- strategie
- ruscello
- punti di forza
- forte
- strutturazione
- tale
- suggerisce
- SOMMARIO
- fornire
- sorpresa
- Susan
- sintassi
- sintesi
- sintetico
- dati sintetici
- sistema
- SISTEMI DI TRATTAMENTO
- Takeaways
- prende
- Parlare
- trattativa
- Task
- task
- team
- Tech
- Consulenza
- Tendono
- condizioni
- testo
- generazione di testo
- di
- che
- I
- Il futuro
- loro
- Li
- temi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- quelli
- tre
- Attraverso
- tempo
- a
- insieme
- strumenti
- TOPBOT
- argomento
- Argomenti
- Totale
- verso
- Tracker
- tradizionale
- Training
- trasferimento
- trasformatore
- Trasparenza
- trattare
- Trend
- Verità
- cerca
- TURNO
- seconda
- tipicamente
- per
- subisce
- e una comprensione reciproca
- Università
- Aggiornamenti
- uso
- utilizzato
- utenti
- utilizzando
- generalmente
- utilizzati
- Prezioso
- APPREZZIAMO
- varietà
- vario
- vivace
- Video
- Video
- punti di vista
- visione
- vulnerabilità
- W3
- Prima
- modi
- we
- indossabile
- WELL
- sono stati
- Che
- quando
- ogni volta che
- mentre
- se
- quale
- while
- OMS
- perché
- largo
- Vasta gamma
- volere
- finestra
- con
- Lavora
- lavoro
- Wrong
- anni
- ancora
- Tu
- giovane
- zefiro